In den letzten 3 Jahren ereigneten sich in Contour mehr als tausend Vorfälle mit unterschiedlichem Epos. Die Gründe sind unterschiedlich: Zum Beispiel werden 36% durch Freisetzung von schlechter Qualität und 14% durch die Wartung von Eisen im Rechenzentrum verursacht. Woher kommen die Statistiken? Nach jedem Vorfall wird ein Obduktionsbericht verfasst. Sie werden von den diensthabenden Ingenieuren verfasst, die auf die Meldung des Unfalls reagiert haben und als erste die Ursachen verstanden haben. Post-mortem werden analysiert, identifiziert und die Ursachen von Vorfällen beseitigt, so dass solche Vorfälle in Zukunft nicht mehr auftreten. Das war aber nicht immer der Fall.
Alexey Kirpichnikov (
BeeVee ) programmiert seit 2008 in Yandex. Staus, die an speziellen Sportprojekten arbeiteten, waren Teamleiter des Yandex.Taxi-Backends. Seit 2014 beschäftigt er sich mit DevOps und Infrastruktur in
Kontur - er entwickelt Tools, die Entwicklern aus Produktteams das Leben erleichtern. Die Idee, Post-Mortem-Themen zu schreiben und zu analysieren, entstand vor fünf Jahren, und während dieser Zeit wurden Post-Mortem-Themen mit Vorlagen, einem Glossar, Memos, Screenshots und Analysen überwachsen. Dies ist jedoch nicht das Schwierigste -
es war schwieriger, die Trägheit, Ängste und Missverständnisse über die Bedeutung von Ereignisberichten unter Ingenieuren zu überwinden . Was letztendlich passiert ist und welchen irreparablen Nutzen die "Sofa-Analyse" haben kann, ist die Entschlüsselung von Alexeys Bericht.
 Bitte beachten Sie, dass sich unter den unterschiedlich langen Tischbeinen die Bücher „Metrics“, „Tests“ und „Deploy“ befinden.
Bitte beachten Sie, dass sich unter den unterschiedlich langen Tischbeinen die Bücher „Metrics“, „Tests“ und „Deploy“ befinden.In Kontur geben sie nach der Einstellung eine Reihe von Souvenirs: einen Stift, einen Becher, ein Notizbuch. Ich bin vor 5 Jahren zu SKB Kontur zu einem neuen Infrastruktur-Team gekommen, als das Unternehmen 25 Jahre alt wurde.

Die Kontur jener Zeit und auch heute ist ein Produktunternehmen, in dem mehrere Dutzend Produkte die gleiche Anzahl von Teams entwickelten, unabhängig von der Auswahl der Technologien und Werkzeuge.
Zu dieser Zeit las ich zum ersten Mal „Project '' Phoenix ''“ und ließ mich von den neuen Ideen der DevOps-Praktiken inspirieren. Ich fing an, meine Verbesserungsvorschläge in ein Notizbuch zu schreiben, und jetzt ist es ein Artefakt mit Kaffeeflecken und historischen Aufzeichnungen.
- „ Überwachung! Lassen Sie uns Grafana setzen, Metriken sammeln und Diagramme erstellen. Wir werden besser verstehen, was in der Produktion passiert. " Für 2014 ist dies eine ziemlich frische, neue Idee und eine solide DevOps-Praxis. “
- " Autounfall!" Wie viele Zip-Dateien können in den freigegebenen Ordner hochgeladen, auf dem Server entpackt und exe im Taskplaner unter Windows ausgeführt werden? "Lassen Sie uns ein industrielles Bereitstellungssystem einführen und Releases darüber veröffentlichen, CI!"
- „ Obduktion ! Wenn es in der Produktion einen Unfall gibt, lassen Sie uns alle herausfinden, was es war, den Grund finden, einen Bericht schreiben und unsere Entwicklungs-, Test- und CI-Prozesse so ändern, dass es in Zukunft keine derartigen Vorfälle mehr gibt. “
Seit 5 Jahren sind wir in all diesen Bereichen vorangekommen. Wir haben unser eigenes
Moira- Warnsystem, ein Anwendungs-Orchestrierungssystem und eine Reihe von Tools. Aus all diesen
Gründen erwies sich das Schreiben von Ereignisberichten als die am schwierigsten zu implementierende technische Praxis . Ingenieure lieben alle Arten von Tools - befestigen Sie eine Art Hosting-System oder CI, schreiben Sie etwas, automatisieren Sie und schreiben Sie keine Berichte, obwohl diese Vorgehensweise von großem Nutzen ist.
Ich werde Ihnen sagen, wie wir Post-Mortem-Systeme implementiert haben und welche Vorteile wir erhalten. Vielleicht hilft unser Rechen dabei, diesen Weg schneller zu gehen und weniger Zapfen zu füllen. Bevor wir über Post-Mortem sprechen, werden wir die Definition verstehen.
Was ist ein Vorfall?
Welches davon ist der Vorfall?
- Beispiel Nr. 1. Auf einer Blog-Plattform mit einer Million Benutzern gehen aufgrund eines Fehlers alle Einträge eines Benutzers verloren.
- Beispiel Nr. 2. Der Service für Büromitarbeiter arbeitet wochentags von 9 bis 6 Uhr, zu anderen Zeiten sind keine Benutzer darin. Der Dienst war in der Nacht von Samstag auf Sonntag zwei Stunden hintereinander nicht verfügbar, niemand bemerkte es.
- Beispiel Nr. 3. Grafana mit Produktionsmetriken fiel um 15 Minuten. In der Produktion ist nichts kaputt gegangen, aber die Grafiken waren nicht verfügbar.
Um zu verstehen, was von dieser Fakapy ist, wenden wir uns der Erfahrung der Gurus zu - Google, Atlassian, PagerDuty. Gurus wissen, wie man Schichten und Bereitschaftsingenieure vorbereitet und wie man Berichte schreibt, um sie zu verstehen. Ihre Online-Anleitungen enthalten Definitionen für Vorfälle.
Definition von PagerDuty.
Ein Vorfall ist eine ungeplante Dienstunterbrechung oder -verschlechterung eines Dienstes, die sich auf die Verfügbarkeit des Dienstes für Benutzer auswirkt. Ein schwerwiegender Vorfall ist ein Vorfall, der eine koordinierte Reaktion mehrerer Teams erfordert.
Klingt logisch, ist aber vage definiert. In der Praxis hilft es wenig zu verstehen, was ein Vorfall ist und was nicht.
Das Google
Site Reliability Engineering- Buch enthält klare Kriterien:
- Benutzer bemerkten die Verschlechterung des Dienstes.
- Alle Daten gingen verloren.
- Es bedurfte beispielsweise der Intervention des diensthabenden Ingenieurs, um die Freigabe manuell zurückzusetzen.
- Die Lösung des Problems dauerte zu lange. Wenn ein Problem in 2 Stunden gelöst wurde und dann eine Woche dafür aufgewendet wurde, ist dies ein Vorfall, der untersucht werden muss.
- Die Überwachung hat nicht funktioniert. Sie haben beispielsweise von Benutzern von einem Problem erfahren.
Contour hat keine veröffentlichte Definition eines Fakap, aber wir haben unsere eigenen Kriterien formuliert, um zu bestimmen, was einen Vorfall darstellt.
Externe oder interne Benutzer haben eine Verschlechterung des Dienstes festgestellt . Beispiel Nr. 3 mit Grafana, das lag, ist ein klarer Vorfall. Die Produktion wurde nicht unterbrochen und externe Benutzer haben dies nicht bemerkt, aber trotzdem ist es für Contour eine Fälschung, da interne Tools nicht funktionierten.
Glück . In Beispiel Nr. 2 lag der Dienst für Büroangestellte 2 Stunden nachts - es war ein Glück, dass er nachts fiel. Das nächste Mal kann es unglücklich sein, und daher muss der nächtliche Vorfall auch vor Gericht gestellt werden, als ob er tagsüber passiert wäre.
Der Vorfall betrifft mehrere Teams . Wir übernehmen diese Definition von PagerDuty. Das Parsen eines Vorfalls ist ein guter Grund für die Zusammenarbeit mehrerer Teams. Die Kultur „Unsererseits ist die Kugel herausgeflogen, aber etwas ist für Sie kaputt gegangen - es ist Ihre Schuld“ wird durch eine gemeinsame Analyse beseitigt.
Mindestens ein Ingenieur betrachtet dies als Vorfall . Die vage, aber auch die wichtigste Definition. Eine einfache Regel: Wenn der Ingenieur glaubt, dass es den Bericht wert ist, dann ist es den Bericht wert. Wenn es Ihnen Angst macht, dass Ingenieure anfangen, Berichte für irgendjemanden zu schreiben und eine Kleinigkeit als Unfall bezeichnen, ist dies nicht der Fall.
Ingenieure sind vernünftige Leute, vertrauen Sie ihnen.Mit der Definition und verschiedenen Arten von Schaden aussortiert. Fahren wir fort mit der Frage, wie Sie von Vorfällen profitieren können.
Was nützt Fakap?
Die einfachen Anweisungen, die ich weiter geben werde, können Sie selbst beantragen, ohne den Artikel bis zum Ende durchzugehen. Aber noch bis zum Ende lesen.
Klassischer Unterricht
Finden Sie zuerst die Schuldigen. Dann machen Sie die „pädagogische“ Arbeit mit den Ingenieuren.
- Bitten Sie darum, beim nächsten Mal vorsichtiger zu sein.
- Wenn es nicht hilft, senden Sie es an Umschulungskurse. Vielleicht lernen sie dort vorsichtiger zu sein.
- Wenn dies nicht hilft, entfernen Sie die Täter von der Arbeit mit kritischen Teilen des Systems. Hören Sie auf, Entwickler in die Produktion zu lassen, wenn sie es dort vermasseln.
- Wenn nichts hilft, feuern Sie die schlechten und stellen Sie kompetente ein.
Wenn Sie die Anweisung stört, sind dies gute Nachrichten.
Dieser Ansatz gilt als traditionell für klassische vertikal ausgerichtete Unternehmen mit einem Chef, der jeden schimpft und ihn entlassen kann. Eine der Grundlagen der DevOps-Bewegung und der DevOps-Ideologie ist die Abkehr von vertikal integrierten zu horizontalen Organisationen mit größerem Vertrauen in die Mitarbeiter.
Ich werde diesen Paradigmenwechsel mit
Anweisungen von John Alspaw veranschaulichen, einem der Führer der DevOps-Bewegung, der zuvor für CTO bei Etsy gearbeitet hat. Die Anweisung stammt aus seinem kanonischen Artikel von 2013, Blameless Post Mortem und eine gerechte Kultur.
Fragen Sie die Ingenieure:
- welche Ereignisse sie beobachteten;
- wann und welche Maßnahmen ergriffen wurden;
- Welches Ergebnis wurde von diesen Maßnahmen erwartet?
- aus welchen Annahmen kam;
- wie durch die Abfolge der aufgetretenen Ereignisse verstanden.
Ingenieure müssen ohne Androhung einer Bestrafung gefragt werden.
Dies ist die Hauptsache in Johns Empfehlung.
Die Gefahr der Bestrafung: Umschulung, Ausschluss aus der Produktion oder Entlassung, motiviert die Menschen zum Lügen. Und die Wahrheit ist uns wichtig. Ereignisbericht - Dies ist der sehr fehlende Feedback-Link bei der Entwicklung und Bereitstellung von Funktionen in der Produktion.
Im alten Paradigma entwickelten die Entwickler das Fahrzeug, warfen es den Betriebsingenieuren über den Zaun und versuchten irgendwie, es zum Laufen zu bringen. Sie ärgern sich über jedes Update, weil es alles kaputt machen kann, und die Ingenieure haben alles mit solchen Schwierigkeiten gestartet.
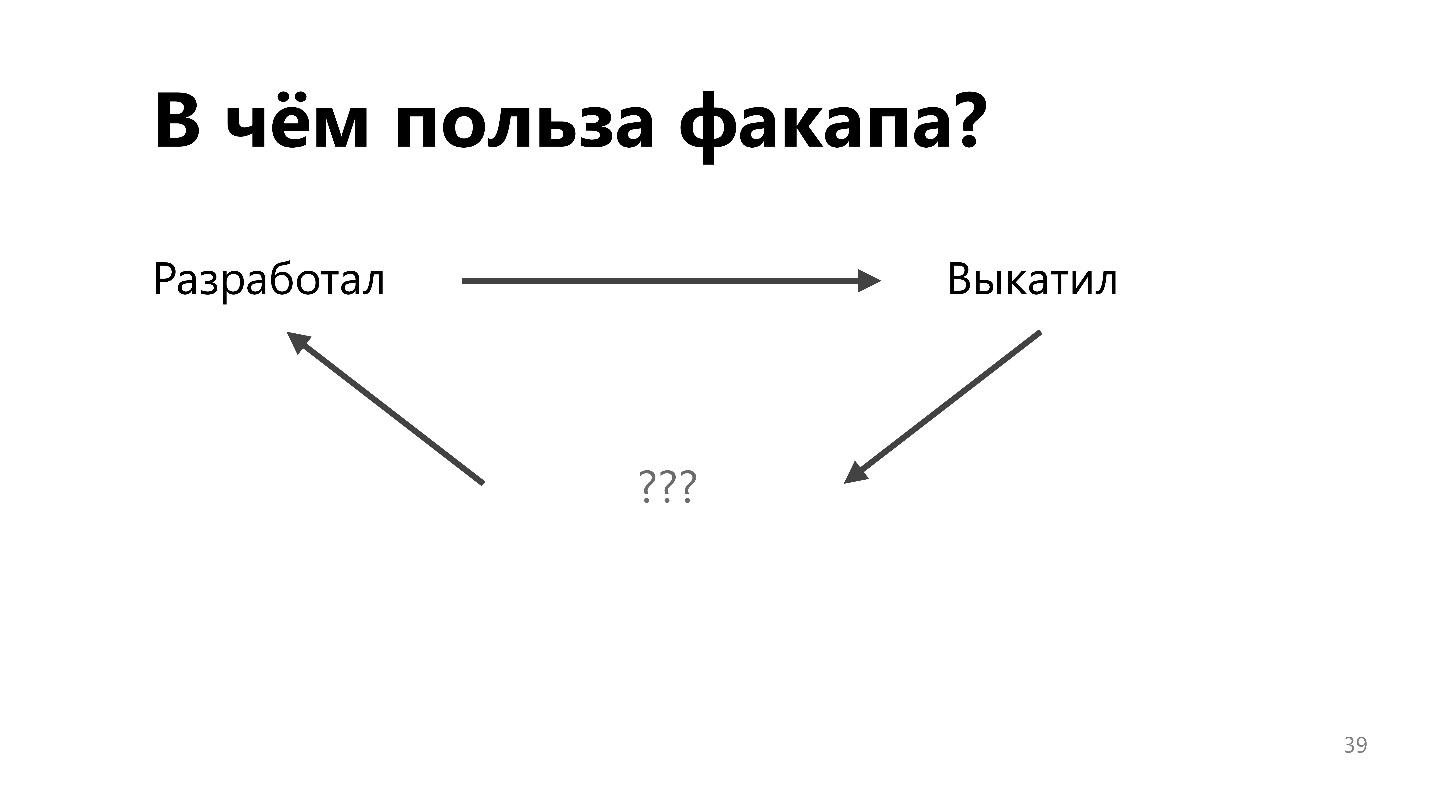
Der Feedback-Prozess hilft dabei, den Prozess, die Infrastruktur, die Tools und den Entwicklungsansatz so zu ändern, dass weniger Abstürze in der Produktion auftreten.
Dies wird Teamleiter und Entwicklungsmanager von der Nützlichkeit von Post-Mortem überzeugen. Aber der Haken ist, dass es schwierig ist, Ingenieure dazu zu bringen, das zu tun, was sie für sinnlos und nutzlos halten. Wir haben eine Ingenieurkultur in unserem Unternehmen, und ich kann nicht einfach kommen, das Dekret des CEO winken lassen und verlangen, dass jeder post mortem schreibt. Ich muss die Ingenieure davon überzeugen.
Wie kann man die Idee von Post-Mortem-Ingenieuren an Ingenieure "verkaufen"? Um die Einwände zu umgehen, um zu zeigen, warum Post-Mortem cool ist, um den Nutzen der Berichte zu demonstrieren, dass dies nicht nur eine Abmeldung ist, wenn nur der Chef im Rückstand ist.
Einwand Nr. 1: Einmal
Dies ist das erste Problem des Ingenieurs, der die Fakap zerlegt - der Krieg wird enden, dann werden wir reden! Wenn ein Fakap auftritt, möchte ich ihn schnell beheben, aber keine unverständlichen, langweiligen und langen Berichte schreiben.
Um das Problem zu lösen, gibt es einen Life-Hack, wie man während eines Unfalls etwas richtig schreibt. Er wurde von Artemy Lebedev populär gemacht:
„Es gibt eine einfache Möglichkeit, die Zeit zu organisieren - die„ progressive Jeepeg “-Methode. In jeder Sekunde ist jedes Projekt zu 100% fertig, obwohl es möglicherweise um 4% weiterentwickelt ist. Abhängig von der verfügbaren Zeit kann das Projekt bis zu einem Pixel ausgearbeitet oder in der Phase des konzeptionellen Skizzierens belassen werden. “
Ich werde die progressive Jeepeg-Methode anhand eines Bildes veranschaulichen. In einem langsamen Internet wird ein Bild nicht sofort, sondern schrittweise heruntergeladen.

Während eines Feuers müssen Sie keinen kühlen und langen Bericht schreiben. Es reicht Ihnen in der oberen linken Ecke. Es reicht aus, die Dinge zu markieren, die sich nur schwer aus dem Gedächtnis wiederherstellen lassen. Versuchen Sie nicht, einen zusammenhängenden literarischen Text zu einem Zeitpunkt zu schreiben, an dem bei der Produktion alles kaputt geht.
Führen Sie eine einfache Aktion aus - notieren Sie die Chronologie der Ereignisse.
Zeitleiste
Die Zeitleiste ist dann sehr schwer wiederherzustellen, wenn sie nicht sofort aufgezeichnet wird. Ein Beispiel für eine Aufnahme von einem echten Post-Mortem in der Schaltung.
15.01.18 17:25 YEKT PrefixSearch 50 . , .
Dies ist eine kurze und einfache Beobachtung mit Zeitstempel. Nach dieser Chronologie ist es später einfach, die Abfolge der Ereignisse wiederherzustellen und die Ursache für den Zusammenbruch zu finden. Wenn Sie jedoch während eines Brandes nichts direkt aufzeichnen, ist es schwierig oder unmöglich, Ereignisse später wiederherzustellen.
Screenshots
Eine praktische Sache, insbesondere wenn Sie mit einer Website oder einer Desktop-Anwendung arbeiten. Die Situation ist manchmal schwer in Worten zu beschreiben, und ein Screenshot ist nur ein Klick auf einen Hotkey.
Der erste Einwand hat geklappt. Ein kleiner Bericht während des Vorfalls ist nicht schwierig und nimmt keine wertvolle Zeit in Anspruch. Wenn alles vorbei ist, muss es in einem verständlichen und kohärenten Dokument ausgefüllt und ausgeführt werden.
Einwand Nr. 2: Faulheit
Sie haben zwei Tage lang nicht geschlafen und einen schweren Unfall behoben, der bei all den Aufgaben, die Sie diese Woche erledigen wollten, tödlich zurückgeblieben ist. Es stellt sich jedoch heraus, dass noch etwas getan werden muss, aber das Feuer wurde bereits gelöscht! In diesem Moment holt unvorstellbare Faulheit auf.
Das Problem vollständig zu besiegen wird nicht funktionieren. Sie können Ihre Arbeit jedoch im Voraus erleichtern.
Muster
Dies ist in erster Linie. Es besteht große Angst vor einem leeren Dokument, das mit aussagekräftigem Text ausgefüllt werden muss. Es ist viel einfacher, wenn die Vorlage vorbereitet ist. Normalerweise besteht es aus Abschnitten und Fragen in ihnen. Wir geben die Antworten auf die Fragen in jedem Abschnitt ein und die Vorlage wird ausgefüllt.
Vorlagen für Ereignisberichte sind groß. Lesen Sie mit dem Guru ausführlich darüber. Alle Dokumente und Bücher, auf die ich mich beziehe, enthalten Vorfallmuster, die von Unternehmen verwendet werden. Nach unserer Erfahrung kann ich Folgendes hinzufügen.
Erstellen Sie ein Memo mit Beispielen
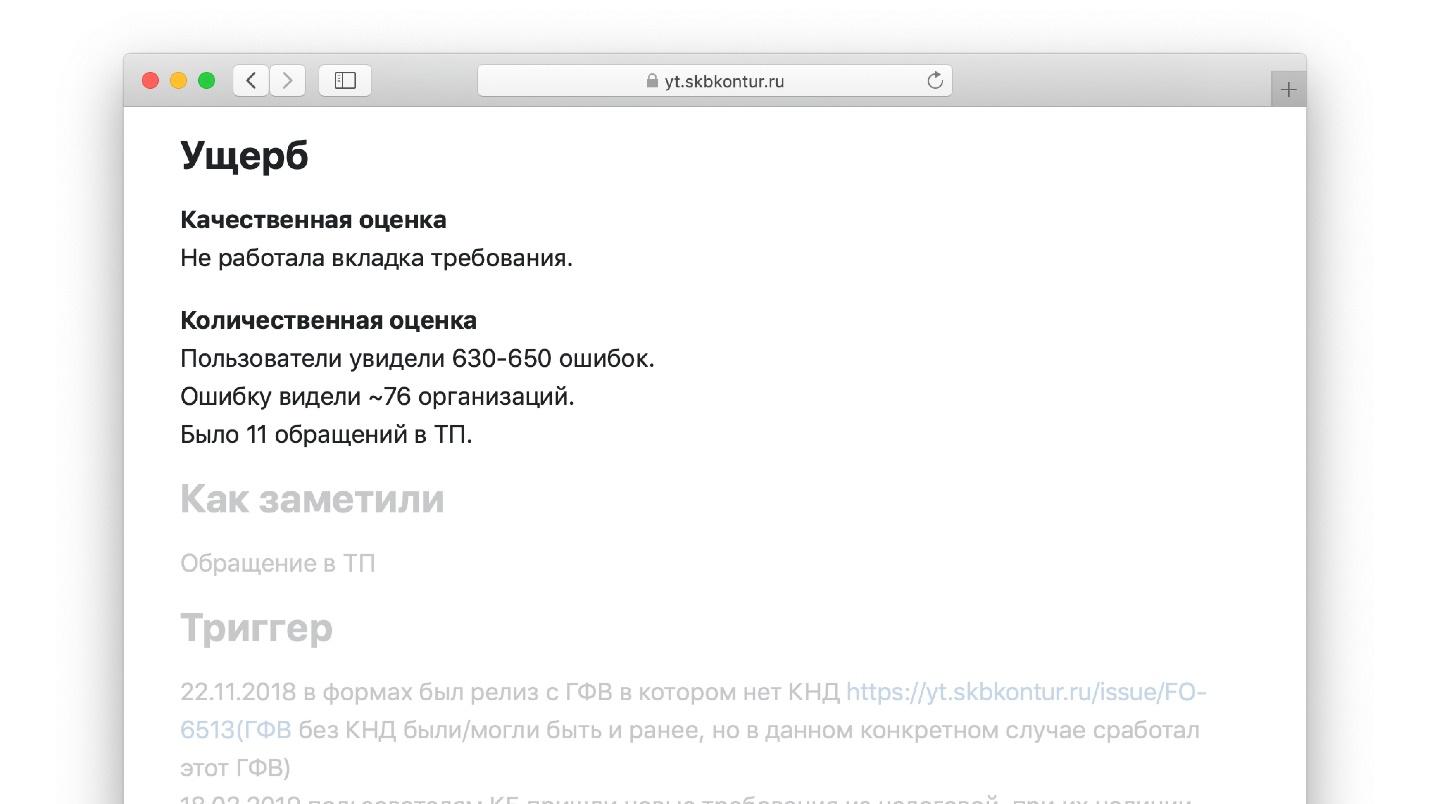
Unsere Vorlage enthält einen Abschnitt "Schaden" mit Unterabschnitten.
Abschnitt "Qualitative Bewertung". Es beschreibt, was der Ingenieur vor sich sieht, wenn er diesen Teil der Vorlage ausfüllt:
- Welche Funktionalität hat nicht funktioniert, wie lange und für wen?
- ob es einen Verlust oder eine Beschädigung von Daten gab.
Nachdem der Ingenieur diese Stelle in der Vorlage erreicht hat, schreibt er: „Unsere Blog-Plattform enthält eine Million Benutzer. Wir haben alle Einträge eines von ihnen verloren.“ Dies ist viel einfacher als das Schreiben eines Aufsatzes von Grund auf neu, wie in einer Literaturstunde.
Abschnitt "Quantifizierung":- wie viele Anfragen sind verschwunden;
- Wie viel Latenz ist bei den Metriken für Anwendungen und Clientanwendungen gestiegen?
- Wie viele Anrufe gehen verloren?
- Die Größe der Warteschlange für den technischen Support des Benutzers für das Problem.
Eine Reihe solcher Fragen ist das Muster.
Ein Beispiel für eine der fertigen Vorlagen.
Fügen Sie ein Glossar hinzu
Ein weiterer Lebenshack für Unfallberichte, den ich im Buch mit dem Guru nicht gesehen habe. Wenn Sie einen Bericht schreiben, ist es praktisch, Begriffe zu verwenden, die Sie gut kennen. Wenn ich beispielsweise mit Graphite arbeite, in dem Metriken gespeichert sind, weiß ich genau, was „Relais“ ist. Der Ingenieur, der den Bericht in einem Jahr lesen wird, ist möglicherweise nicht mit dem Begriff vertraut. Es ist unwahrscheinlich, dass er den Bericht lesen kann, der aus unbekannten Wörtern besteht. Wenn andererseits jeder Begriff und jede Definition im Bericht ständig gekaut wird, wird sie durch Faulheit einfach abgeschreckt und der Bericht wird nicht fertiggestellt.
Schreiben Sie ein kleines Glossar, in dem alle im Bericht verwendeten Begriffe beschrieben werden.
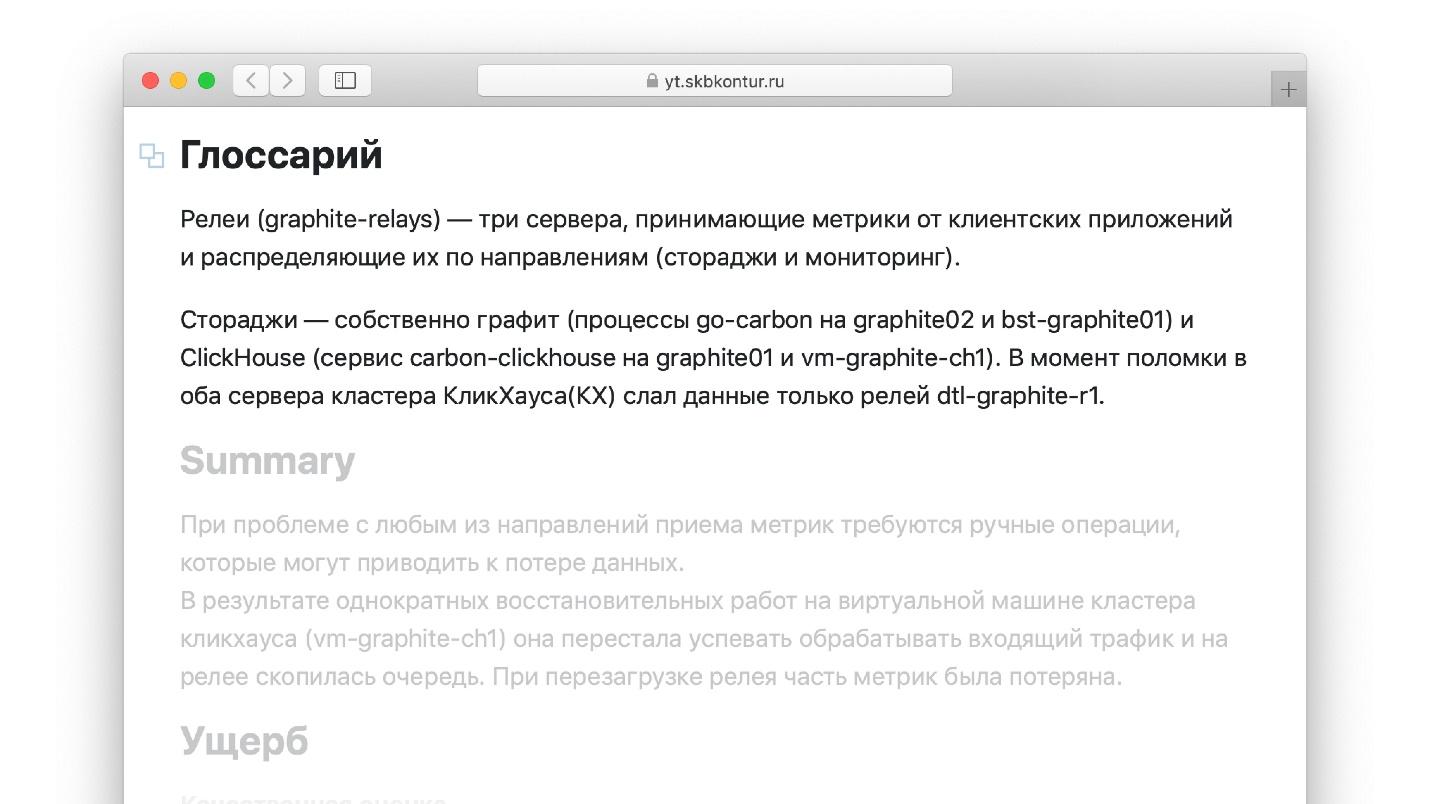
Kopieren Sie alle Artefakte
Wenn Sie dem Bericht Artefakte hinzufügen: Schnappschüsse in Grafana, erstellt der Verlauf der Nachrichten im Chat, in dem der Vorfall mit anderen Ingenieuren analysiert wurde, Kopien. Metriken können „verrotten“ und Chats ändern sich. Vor einem Jahr waren Sie in Slack, jetzt in Telegram - der Chat-Link ist veraltet und funktioniert nicht, und die Aufbewahrungsmetriken fallen ab - sie werden ein Jahr lang gespeichert.
Artefakte kopieren - dieser Life-Hack erleichtert das Ausfüllen von Berichten.
Einwand Nr. 3: Niemand wird lesen
Die größte und unverständliche Frage der Ingenieure lautet: „Wer wird diese Berichte lesen?“ Angenommen, ich habe die Faulheit überwunden und eine Chronologie der Ereignisse während des Unfalls geschrieben. Dann sammelte er seine Kräfte und fügte einen mehrseitigen Bericht über das Geschehen und die Ursachen des Unfalls hinzu. Wenn es jedoch kein Verständnis dafür gibt, wer all dies lesen und wer davon profitieren wird, besteht kein Wunsch, Berichte auszufüllen.
Post-mortem ist ein Feedback im Prozess der kontinuierlichen Verbesserung von Entwicklungsprozessen.
In jedem Guru-Buch, zum Beispiel im
Atlassian Incident Handbook , steht, dass es gemäß den Ergebnissen jedes Post-Mortem erforderlich ist:
- Aufgaben in der Entwicklung formulieren;
- Erstellen Sie Aufgaben im Bugtracker, von denen Ihre Entwickler sie übernehmen werden.
- Setzen Sie Links von Post-Mortem zu diesen Aufgaben.
Das Feedback ist geschlossen : Hier ist eine Obduktion, hier darin
Aktionselemente - Aufgaben, die erledigt werden müssen, damit der Unfall nicht erneut auftritt. Aufgaben fallen in den Rückstand des Teams, das Team entwickelt sie, rollt aus - wieder das Fakap und Post-Mortem. Das Rad von Samsara hat sich geschlossen.
Darauf laufen alle Gurus zusammen. Es gibt nichts zu streiten - die Vorteile liegen auf der Hand.
Ein Beispiel für Aufgaben mit Aktionselementen aus einer echten Obduktion.
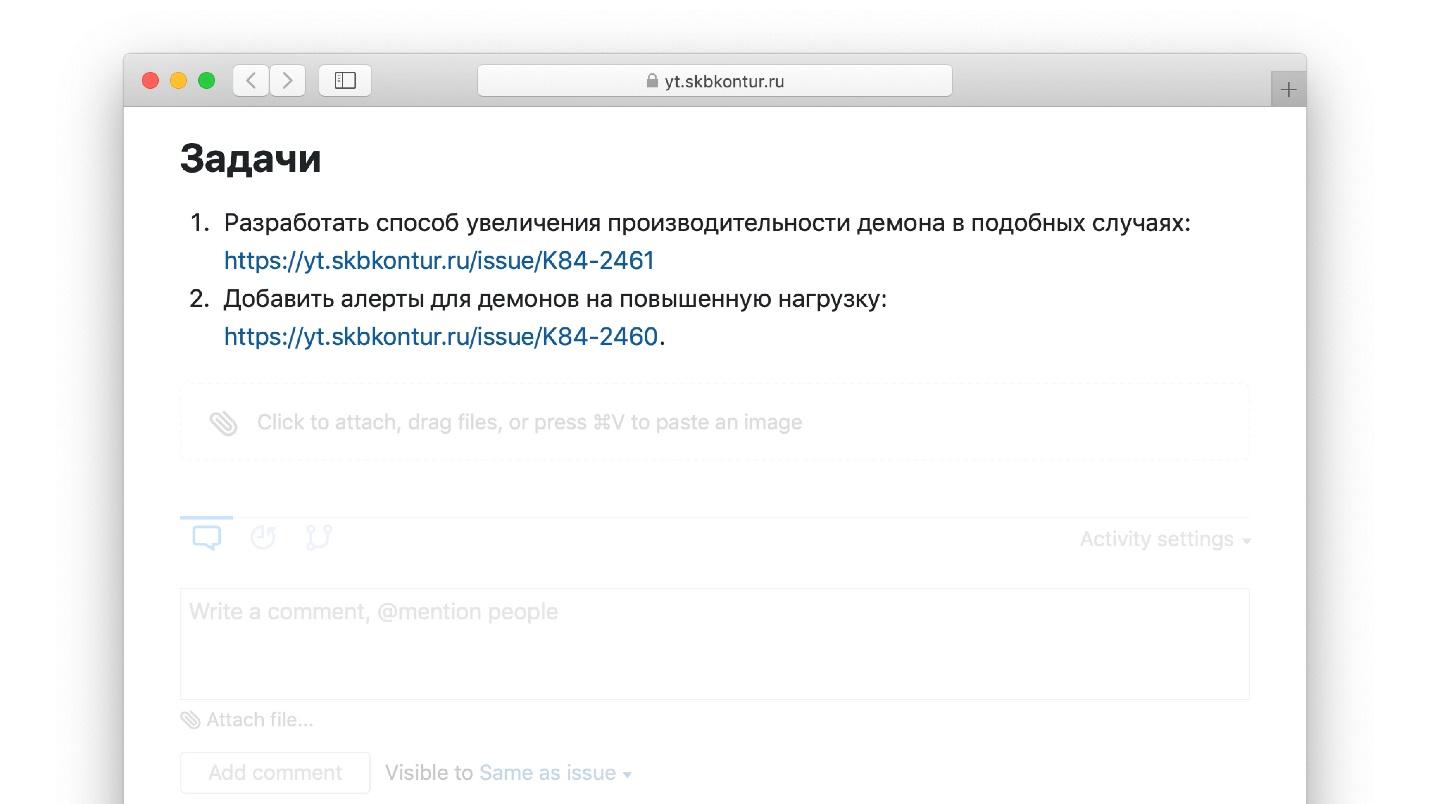
Aber wir bei Kontur haben dem einen Analysten hinzugefügt.
Sofa Analytics
Wir haben den Vorfall isoliert analysiert. Der Fehler trat alleine in einem Team, in einem Hosting-System auf - etwas ist kaputt gegangen, wir haben es behoben.
Aber es gibt viele Zwischenfälle. In den letzten drei Jahren haben sich mehr als 1.000 Ereignisberichte in der Rennstrecke angesammelt. Ich würde gerne wissen, ob es möglich ist, von der gesamten Masse der gesammelten Berichte zu profitieren, und nicht nur von jedem einzelnen. Ist es möglich, auf ihrer Grundlage die Statistiken des Systems zu berechnen und zu sehen, was im gesamten System verbessert werden kann?
In Kontur arbeitet ein spezielles Infrastruktur-Team, das sich mit der Analyse von Obduktionen befasst und die Ergebnisse und Schlussfolgerungen auf der Grundlage der gesamten Masse der gesammelten Berichte veröffentlicht. Wir nennen dies "Sofaanalyse". Ich werde Fragmente eines Artikels des Teams geben, der in unserem internen Netzwerk für Mitarbeiter veröffentlicht wird.
Was analysieren wir in der Sofaanalyse?
Fakap Dauer
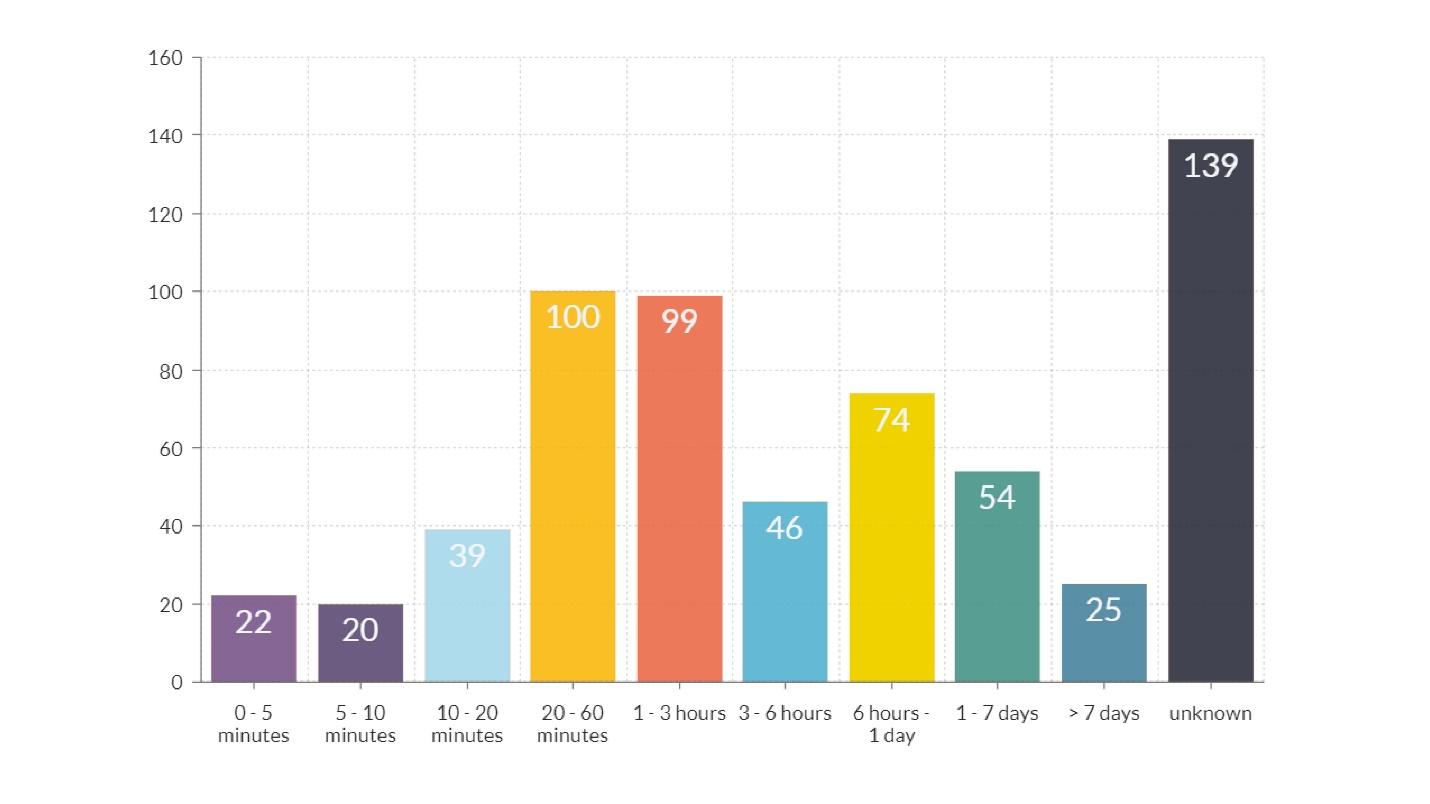 Im Diagramm gibt es neben der letzten Spalte, in der die Zeit unbekannt ist, zwei weitere offensichtliche Peaks.Dauer in der Größenordnung von einer Stunde
Im Diagramm gibt es neben der letzten Spalte, in der die Zeit unbekannt ist, zwei weitere offensichtliche Peaks.Dauer in der Größenordnung von einer Stunde - orange und rote Balken. Die meiste Zeit wurde damit verbracht, Informationen darüber zu übermitteln, was passiert ist, vom Ingenieur, der den Unfall bemerkt hat, an den Ingenieur, der weiß, wie man ihn repariert.
Das Problem ist die Kommunikation .
Wenn wir unsere Werkzeuge so reparieren, dass der Techniker, der das Problem behebt, schneller Informationen erhält, werden die Dauer der Fakaps und der Schaden durch sie erheblich reduziert. Dies ist etwas, das wir nicht erkennen würden, wenn wir einen Fakap einzeln betrachten würden.
Dauer ca. 12 Stunden - eine gelbe Säule. Die Erklärung für die Tatsache, dass es viele Fakaps gibt, die länger als 12 Stunden dauern, ist einfach: Sie haben die Veröffentlichung am Abend eingeführt, und am Morgen kamen Benutzer und alles brach zusammen. Die Schlussfolgerung, was zu tun ist, um die Anzahl solcher Fakaps zu verringern, liegt auf der Hand.
Qualitätsschaden

Qualitativer Schaden wird in mehrere Kategorien unterteilt. Top 3 beinhaltet:
- Unzugänglichkeit, Fehler;
- Bremsen, erhöhte Latenz;
- sichtbar falsches Verhalten.
Laut Analytik ist die überwiegende Mehrheit dieser Fehler. Einerseits sind dies gute Nachrichten. Drei Arten der häufigsten Fehler sind leicht zu erkennen: Wir passen die Metriken an die Latenz und die Anzahl der Fehler an und bemerken solche Dinge schnell.
Die schlechte Nachricht ist, dass es die meisten dieser Fehler gibt. Dies sind einfache technische Fehler, was bedeutet, dass wir bei den Pipeline-Tests etwas verbessern, mehr Stresstests durchführen und das Überwachungssystem verbessern können.
Auslöser
Dies führte direkt zum Zusammenbruch, das heißt nicht zur Grundursache des Unfalls, sondern zum „letzten Strohhalm“: Die Protokolle füllten die Festplatte und aus diesem Grund brach alles, wurde freigegeben - alles explodierte.

An erster Stelle steht die „Update-Installation“. Dieser Grund ermöglicht es uns zu verstehen, in was wir als Infrastruktur-Team investieren sollten. Zum Beispiel, um das Bereitstellungssystem zu verbessern und eine kanarische Bereitstellung einzuführen. Dies ist der Punkt der Anstrengung, der den größten Einfluss auf die Qualität unserer Systeme hat.
Dies ist der Punkt aller Analysen - um zu verstehen, wo ein kleines Infrastruktur-Team derzeit in die Bedingungen begrenzter Ressourcen investieren sollte.
Was kann verbessert werden - Alarm oder Bereitstellung? Was tun - Hosting oder die Schönheit von Grafiken?
Hier ist ein weiterer guter Einblick. An zweiter Stelle steht "die Ursache ist unbekannt". Dies ist ein Indikator für eine schlechte Berichterstattung über Vorfallberichte.
Mögliche "Pillen"
Dies ermöglicht eine einfache technische Lösung, um die Anzahl der Unfälle eines bestimmten Typs zu reduzieren. Zum Beispiel wissen wir, dass die wichtigsten Dinge, die die Anzahl der Fakaps reduzieren, Benachrichtigungen vom Überwachungssystem sind. Wenn es mehr Warnungen bei der Überwachung dieser Ereignisse gäbe, wie viele Vorfälle könnten wir verhindern? Der Prozentsatz gibt an, wie viel:
- auf die Anzahl der HTTP-Fehler vom Client - 10%;
- zum Auftreten neuer Arten von Fehlern in den Protokollen: Installation, Benachrichtigungseinstellungen - 8%;
- auf Systemressourcen: CPU, Speicher, Festplatte, Threads, GC - 6%.
Wenn die Warnung korrekt konfiguriert wurde und der gewünschte Techniker rechtzeitig eine Benachrichtigung erhielt, würden 24% der Vorfälle entweder nicht auftreten oder eine viel kürzere Dauer haben. Diese Schlussfolgerung kann auf der Grundlage der Analyse der gesamten Masse der Vorfälle gezogen werden.
Hier werde ich noch einmal für unser
Moira- Warnsystem werben, das sich in Open Source befindet.
Wenn Sie Graphit haben, können Sie es herunterladen und verwenden. Ich hoffe, es wird weniger Zwischenfälle geben.
Empfehlungen
Organisatorische Empfehlungen, denen das Team folgen kann, und die Anzahl der Unfälle reduzieren. Unsere Top 3.
- Die Ähnlichkeit der Test- und Kampfstätten . 5% der Vorfälle ereigneten sich aufgrund der Tatsache, dass die Teststelle der Kampfstelle nicht ähnlich genug war.
- Abwärtskompatibilität in Releases . Die Version wurde entleert, war nicht abwärtskompatibel mit der vorherigen, es traten Datenmigrationen auf - 4% der Fehler.
- Ablehnung von Nachtfreigaben . Wenn Sie aufhören, Veröffentlichungen zu verbreiten, die brechen, verschwinden am Abend weitere 4% der Vorfälle.
Ich betone, dass dies keine Anweisung ist, sondern eine Geschichte darüber, wie wir Analysen gesammelt haben. Ihre Analysen können unterschiedlich sein.
Wie schreibe ich?
Wenn Sie feststellen, dass Incident Analytics eine coole Sache ist und Sie Berichte schreiben müssen, erkläre ich Ihnen, wie es geht.
Post-Mortem und Aufgaben in einem Bug-Tracker
Im Bugtracker gibt es im Gegensatz zu Google Text & Tabellen oder Wiki feste Felder, für die Sie eine Reihe von Werten festlegen können. Dies erleichtert die spätere Analyse von Grafikstatistiken.
Im SRE-Buch stellt Google eine Vorlage in Google Text & Tabellen bereit, in der Berichte in das interne Dokument geschrieben werden. Ich kann mir nicht vorstellen, wie wir die Analysen sammeln können, die wir aus unstrukturierten Google-Dokumenten sammeln.
Wir schreiben Berichte im selben Bug-Tracker wie die Hauptaufgaben, da wir die Aufgabe mit dem Post-Mortem verbinden können. Schauen wir uns das Post-Mortem an und sehen sofort, welche Aufgaben geschlossen sind, welche nicht und welche noch zu erledigen sind.
Erstellen Sie spezielle Felder
Ich habe bereits über spezielle Bereiche gesprochen. Wir haben folgendes.
- Der Anfang und das Ende des Fakaps können automatisch analysiert werden. Wenn Sie maschinenlesbare Zeitstempel einfügen, können Sie die Dauer des Fakaps darstellen.
- Beginn und Ende der Untersuchung.
- Auslöser Richten Sie eine Dropdown-Liste mit Triggern ein.
- Wie bereits erwähnt.
- Quantitativer und qualitativer Schaden.
- Betroffene Teams und Dienste.
Mit allen Daten aus speziellen Feldern können Sie verstehen, wie Ihre Infrastruktur funktioniert.
Ein Beispiel für unseren vollständigen Vorfallbericht.

Die Felder der rechten Spalte werden nur durch die Auswahl aus den Dropdown-Listen ausgefüllt.
Stellen Sie ein Team von Ingenieuren zusammen, denen Qualität am Herzen liegt
Um Berichte zu erhalten, die Ihnen helfen, die Entwicklung Ihrer Infrastruktur zu verstehen, benötigen Sie Mitarbeiter, die sich um die Qualität Ihrer Dienste kümmern. Nicht unbedingt sind es Ingenieure, die sich ausschließlich mit der Vollzeitanalyse von Obduktionen befassen. Es ist wichtig, dass dies Menschen sind, die sehr besorgt darüber sind, was passiert. Von Zeit zu Zeit sammeln sie sich, analysieren die gesamte Masse der Vorfälle, schreiben große Artikel und bringen Vorteile - schließen Sie den Feedback-Ring.
Unser Team heißt Q-Team - vom Wort "Qualität". Es hat 3 Mitarbeiter - einer der talentiertesten Ingenieure des Unternehmens, die in der Infrastruktur arbeiten.
Insgesamt
Lesen Sie den Guru - John Allspaws Artikel und Incident Management-Bücher:
Site Reliability Engineering ,
PagerDuty Post-Mortem-Prozess ,
Atlassian Incident Handbook .
Und wenn Sie morgen zur Arbeit kommen, machen Sie einfach
die ersten Schritte :
- Starten Sie ein Projekt für Fakaps im Bugtracker, in dem Sie Aufgaben ausführen.
- Nehmen Sie eine Vorlage - versuchen Sie nicht, Ihre eigene, unsere oder Google in SRE zu schreiben.
- Wenn etwas explodiert, schreibe einfach.
In dem Moment, in dem Sie den ersten, zweiten und dritten Bericht schreiben, werden Sie keine schönen Analysen mit mehrfarbigen Spalten haben. Aber nach ein oder zwei Jahren, wenn sich die Daten angesammelt haben, blicken Sie zurück und bedanken sich für den ersten Schritt.
Wir hoffen, dann werden Sie sich an Alexei erinnern und ihm für die Geschichte einer solchen Erfahrung danken. Und wir werden wiederum versuchen, neue nützliche Berichte in das DevOpsConf- Programm aufzunehmen, Empfehlungen, von denen aus Sie sich bewerben können. Die Konferenz findet vom 30. bis 1. September 2019 statt . Bis zum 20. August warten wir noch auf Bewerbungen von DevOps-Unterstützern, aber 12 wurden bereits genehmigt, dh der Wettbewerb wird näher an der Frist höher sein.
Wenn Sie Ihre Erfahrungen teilen möchten, entscheiden Sie sich und senden Sie Ihre Abstracts . Wenn Sie Programmnachrichten erhalten möchten, abonnieren Sie unseren Newsletter und unseren Telegrammkanal .