Ende Juni zeigte uns ein Team der Carnegie Mellon University XLNet und legte sofort die
Veröffentlichung , den
Code und das fertige Modell vor (
XLNet-Large , Gehäuse: 24-
lagig , 1024-versteckt, 16-Kopf). Dies ist ein vorab trainiertes Modell zur Lösung verschiedener Probleme der Verarbeitung natürlicher Sprache.
In der Veröffentlichung gaben sie sofort einen Vergleich ihres Modells mit Googles
BERT an . Sie schreiben, dass XLNet BERT in einer Vielzahl von Aufgaben überlegen ist. Und zeigt Ergebnisse in 18 Aufgaben auf dem neuesten Stand der Technik.
BERT, XLNet und Transformatoren
Einer der jüngsten Trends beim Deep Learning ist das Transferlernen. Wir trainieren Modelle, um einfache Probleme mit einer großen Datenmenge zu lösen, und verwenden dann diese vorab trainierten Modelle, um jedoch andere, spezifischere Probleme zu lösen. BERT und XLNet sind genau solche vorgefertigten Netzwerke, mit denen Probleme bei der Verarbeitung natürlicher Sprache gelöst werden können.
Diese Modelle entwickeln die Idee von
Transformatoren - den derzeit vorherrschenden Ansatz zum Erstellen von Modellen für die Arbeit mit Sequenzen. Sehr detailliert und mit Beispielen für Code auf Transformatoren und dem Aufmerksamkeitsmechanismus ist in
The Annotated Transformer geschrieben .
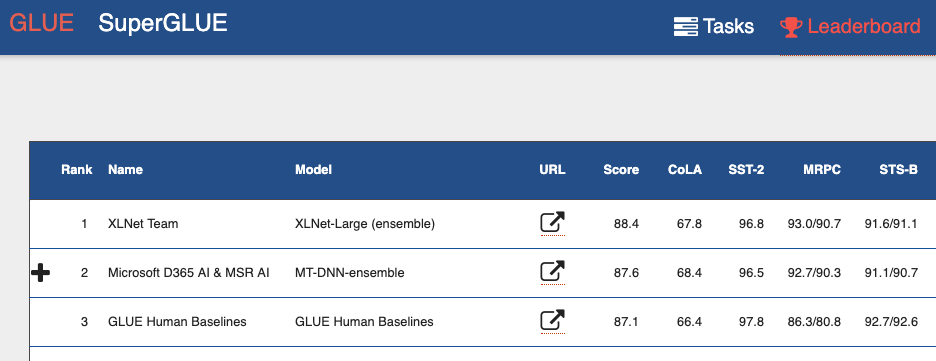
Wenn Sie sich das
GLUE-Benchmark-Leaderboard (General Language Understanding Evaluation) ansehen , sehen Sie von oben viele Modelle, die auf Transformatoren basieren. Einschließlich beider Modelle, die bessere Ergebnisse als Menschen zeigen. Wir können sagen, dass wir mit Transformatoren eine Mini-Revolution in der Verarbeitung natürlicher Sprache erleben.
BERT Nachteile
BERT ist ein Auto-Encoder (Autoencoder, AE). Er versteckt und verdirbt einige Wörter in der Sequenz und versucht, die ursprüngliche Sequenz von Wörtern aus dem Kontext wiederherzustellen.
Dies führt zu Nachteilen des Modells:
- Jedes versteckte Wort wird einzeln vorhergesagt. Wir verlieren Informationen über die möglichen Beziehungen zwischen maskierten Wörtern. Der Artikel enthält ein Beispiel namens "New York". Wenn wir versuchen, diese Wörter unabhängig im Kontext vorherzusagen, werden wir die Beziehung zwischen ihnen nicht berücksichtigen.
- Inkonsistenz zwischen den Trainingsphasen des BERT-Modells und der Verwendung des vorab trainierten BERT-Modells. Wenn wir das Modell trainieren - wir haben versteckte Wörter ([MASK] -Token), wenn wir das vorab trainierte Modell verwenden, liefern wir solche Token noch nicht an die Eingabe.
Trotz dieser Probleme zeigte BERT bei vielen Aufgaben der Verarbeitung natürlicher Sprache die neuesten Ergebnisse.
XLNet-Funktionen
XLNet ist eine autoregressive Sprachmodellierung, AR LM. Sie versucht, den nächsten Token aus der Reihenfolge der vorherigen vorherzusagen. In klassischen autoregressiven Modellen wird diese Kontextsequenz unabhängig von zwei Richtungen der ursprünglichen Zeichenfolge verwendet.
XLNet verallgemeinert diese Methode und bildet Kontext von verschiedenen Stellen in der Quellsequenz. Wie macht er das? Er nimmt alle (theoretisch) möglichen Permutationen der ursprünglichen Sequenz und sagt jedes Token in der Sequenz aus den vorherigen voraus.
Hier ist ein Beispiel aus dem Artikel, wie das x3-Token aus verschiedenen Permutationen der ursprünglichen Sequenz vorhergesagt wird.
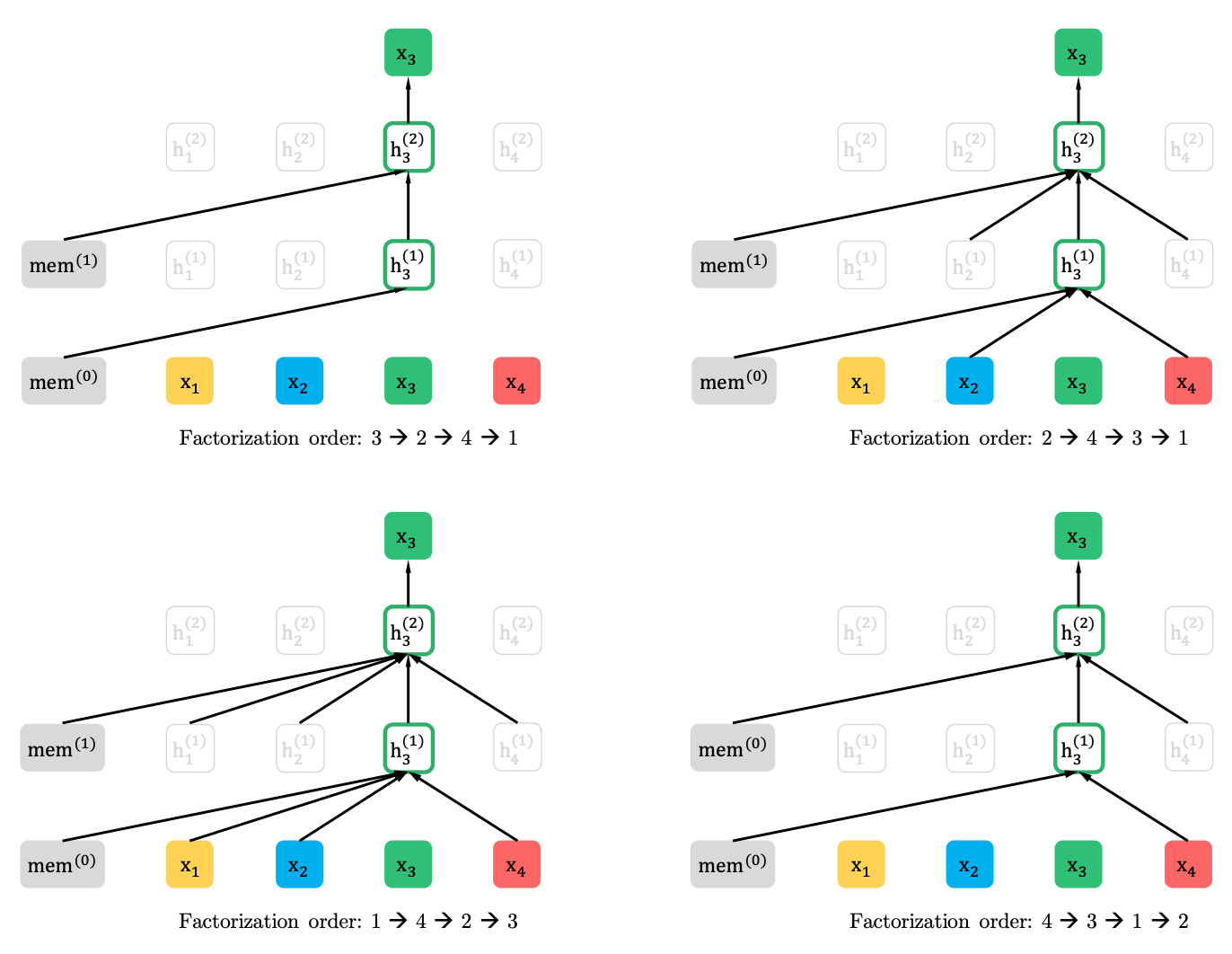
Darüber hinaus ist der Kontext keine Tüte mit Worten. Informationen zur Erstbestellung von Token werden ebenfalls an das Modell geliefert.
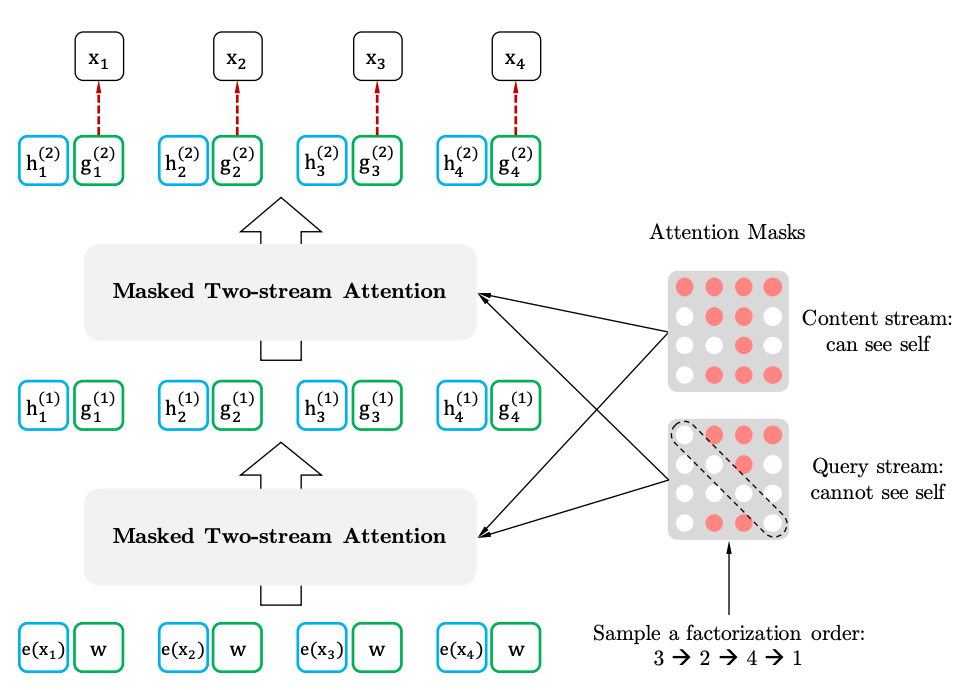
Wenn wir Analogien zum BERT ziehen, stellt sich heraus, dass wir die Token nicht im Voraus maskieren, sondern unterschiedliche Sätze versteckter Token für unterschiedliche Permutationen verwenden. Gleichzeitig verschwindet das zweite Problem von BERT - das Fehlen versteckter Token bei Verwendung des vorab trainierten Modells. Bei XLNet ist bereits die gesamte Sequenz ohne Masken eingegeben.
Woher kommt der XL im Namen? XL - weil XLNet den Aufmerksamkeitsmechanismus und die Ideen des Transformer-XL-Modells verwendet. Obwohl böse Sprachen behaupten, dass XL auf die Menge an Ressourcen hinweist, die zum Trainieren des Netzwerks benötigt werden.
Und über die Ressourcen. Auf Twitter veröffentlichten sie die
Berechnung der Kosten für das Training des Netzwerks mit den Parametern aus dem Artikel. Es stellte sich heraus, 245.000 Dollar. Es stimmt, dann kam ein Ingenieur von Google und
korrigierte, dass in dem Artikel 512 TPU-Chips erwähnt werden, von denen sich vier auf dem Gerät befinden. Das heißt, die Kosten betragen bereits 62.440 Dollar oder sogar 32.720 Dollar angesichts der 512 Kerne, die ebenfalls im Artikel erwähnt werden.
XLNet gegen BERT
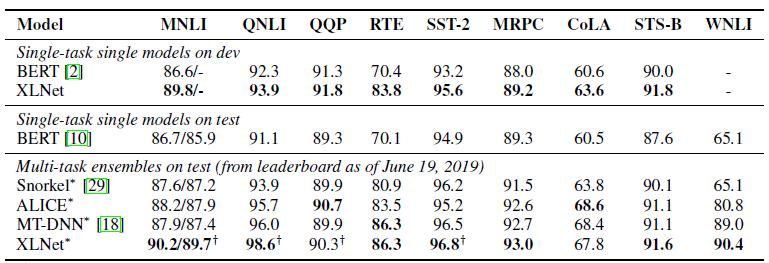
Bisher wurde nur ein vorab geschultes Modell für Englisch für den Artikel ausgelegt (XLNet-Large, Cased). Der Artikel erwähnt aber auch Experimente mit kleineren Modellen. Bei vielen Aufgaben zeigen XLNet-Modelle im Vergleich zu ähnlichen BERT-Modellen bessere Ergebnisse.
Das Aufkommen von BERT und insbesondere vorgefertigten Modellen zog die Aufmerksamkeit der Forscher auf sich und führte zu einer Vielzahl verwandter Arbeiten. Jetzt ist hier XLNet. Es ist interessant zu sehen, ob es für einige Zeit zum De-facto-Standard in NLP wird oder umgekehrt, um Forscher bei der Suche nach neuen Architekturen und Ansätzen für die Verarbeitung natürlicher Sprache anzuregen.