Hallo an alle. In diesem Artikel werde ich über unsere Erfahrungen bei der Teilnahme am Datenanalyse-Wettbewerb
Data Mining Cup 2019 (DMC) sprechen und darüber, wie wir es geschafft haben, in die TOP 10-Teams einzutreten und am persönlichen Meisterschaftsfinale in Berlin teilzunehmen.

Ich werde im Namen unseres Teams, in das ich eintrete (Alexander Perevalov), sowie meines Kollegen Sergey Bobkov erzählen. Wir sind Doktoranden der
Perm Polytechnic University und beschäftigen uns in unserer Freizeit von der Arbeit und dem Studium mit der Lösung von Data Science-Wettbewerben.
Was ist DMC und wie haben wir davon erfahren?
Der Data Mining Cup ist eine globale Meisterschaft zur Analyse von Studentendaten, die einmal im Jahr stattfindet. Seine Geschichte begann vor 20 Jahren, lange vor
Kaggle. Man kann sagen, dass das
DMC Datenanalyse-Wettbewerbe veranstaltete, bevor es zum Mainstream wurde .
DMC wird
von der deutschen Firma
PrudSys , einem
Retail-Intelligence- Unternehmen,
gehostet . Bisher war nur die Teilnahme mit einer Hand an der Meisterschaft erlaubt, dann durften sich die Teilnehmer in Teams der Universität zusammenschließen. Die maximale Anzahl der Teams der Universität beträgt übrigens nur 2. Die Mitgliedschaft an der Universität wird ebenfalls streng kontrolliert. Für die Teilnahme ist eine E-Mail mit der Domain Ihres Studenten erforderlich Institutionen, sowie senden Sie eine Kopie Ihres Studentenausweises.
Wenn wir heute das Niveau der Teilnehmer an DMC und Kaggle vergleichen, ist das Niveau von Kaggle natürlich viel höher. Dies ist auf die Beschränkung der Studenten im DMC und die Popularität von Kaggle zurückzuführen. Eine Besonderheit des DMC ist das
Fehlen einer Rangliste , wodurch die Probleme bei der Anpassung beseitigt werden.
Ich erfuhr von dem Data Mining Cup, als wir mit einer Gruppe von unserer Universität ein Praktikum in Deutschland machten. Als ich zu Hause ankam, lud mich mein Freund und Teamkollege zur Teilnahme ein, es war Mitte April. Ehrlich gesagt war ich skeptisch gegenüber dieser Idee, nachdem ich erfahren hatte, dass die Daten und die Aufgabe in diesem Jahr recht einfach sind - wir haben immer noch begonnen, sie zu lösen.
Wie wir die Aufgabe gelöst haben
Im Jahr 2019 lag die Aufgabe im Bereich der Self-Checkout-Betrugserkennung. Sicherlich sind Sie in Supermärkten bereits auf Selbstbedienungskassen gestoßen. Diese Geräte arbeiten sowohl unter Aufsicht eines Filialmitarbeiters als auch vollautomatisch. Mit Self-Service-Registrierkassen können Sie die Personalkosten optimieren und Warteschlangen in Supermärkten minimieren. Es gibt jedoch ein Problem: Die menschliche Natur ist so, dass auf die eine oder andere Weise der Wunsch besteht, die Waren, die wir in unserem Kühlschrank sehen möchten, nicht zu „durchbrechen“. Um dies zu vermeiden, ist eine Kontrolle erforderlich, die die Kunden jedoch nicht in Verlegenheit bringt oder stört.
Basierend auf den getaggten Daten zu Self-Checkout-Transaktionen ist es daher erforderlich, ein mathematisches Modell zu entwickeln, das eine bestimmte Transaktion automatisch als betrügerisch oder nicht betrügerisch klassifiziert. Also lösen wir das Problem der binären Klassifizierung.
Die Daten waren wie folgt:

Die Größe der Trainingsprobe betrug nur ~ 1800 Beispiele, während die Testprobe 499000 Beispiele betrug. Auch die Trainingsstichprobe
war nicht ausgewogen : Nur 4% der Transaktionen waren betrügerisch, es ist offensichtlich, dass
Genauigkeit (der Anteil der richtigen Antworten) hier nutzlos ist. Überraschenderweise fehlten keine Werte in den Daten, und einige der Attribute waren gleichmäßig verteilt. Daraus können wir schließen, dass die
Daten künstlich erzeugt werden.Außerdem schlugen die Organisatoren ihre Metrik in Form einer Verwirrungsmatrix vor, die in Geldeinheiten gemessen wird:
Nach der Analyse wurde uns klar, dass Präzision in diesem Fall wichtiger ist, weil
Wir tragen den maximalen Verlust, wenn wir einen ehrlichen Käufer fälschlicherweise als Betrüger bezeichnen.Der Verlauf unserer Lösung bestand aus klassischen Stufen:
- Grundlegende Datenanalyse
- Analyse der Zeichen, ihrer beschreibenden Statistiken und Verteilungen
- Ausreißerentfernung
- Zeichengenerierung
- Modell erstellen und Parameter einstellen
- Validierung und endgültige Prognose
Die Folien mit dem Inhalt unserer Lösung finden Sie unter:
www.docdroid.net/2XEDfYg/dmc-2019-1.pdfDas Repository auf GitHub ist hier:
github.com/Perevalov/dmc2019 (alles ist auf verschiedene Zweige verteilt, bis Zeit war, alles in Ordnung zu bringen)
Organisationsfinale
Nachdem wir Anfang Mai die endgültige Entscheidung getroffen hatten, erwarteten wir Ergebnisse. Die Bedingungen der Organisatoren sind so, dass die
Top-10-Teams zu einem persönlichen Finale nach Berlin eingeladen werden , das im Rahmen der Konferenz Retail Intelligence Summit 2019 stattfindet: Smart Decisions for Smart Retail.
Als Referenz nahmen
2019 149 Teams von 114 Universitäten in 28 Ländern an der DMC teil.Um ehrlich zu sein, hatten wir nicht einmal gehofft, das Finale zu erreichen , aber jetzt, Ende Mai, kommt dieser geschätzte Einladungsbrief. Darüber hinaus wurden alle Finalisten aufgefordert, Kosten von bis zu 500 Euro zu zahlen, und sie boten auch eine Unterkunft in einem Hotel für eine Nacht an, in der die Veranstaltung stattfand.
Ohne zu zögern kauften wir Tickets nach Berlin und holten uns ein Visum. Als arme Studenten stellte sich heraus, dass die Kosten für eine zweitägige Reise für uns ziemlich hoch waren. Die Kosten für Perm-Berlin-Perm-Tickets und die Bearbeitung von Visa beliefen sich auf rund 40.000 Rubel. pro Person sind das etwas mehr als 500 Euro.
Da wir unsere Universität bei der Veranstaltung vertreten, haben wir uns entschlossen, materielle Unterstützung von ihr zu erhalten. Darüber hinaus führt die Polytechnische Universität Perm ein Programm zur Entwicklung der deutsch-russischen Beziehungen durch und unterstützt nachdrücklich Initiativstudenten (so schien es uns). Mit der Genehmigung und Unterschrift des Leiters der Abteilung, in der wir studieren, gingen wir zur Abteilung für Wissenschaft und Innovation. Es begann ein einmonatiges bürokratisches Epos, das mit folgendem endete:
"Es gibt kein Geld, aber Sie halten fest .
" Natürlich waren wir etwas verärgert, haben aber nicht den Mut verloren. Jetzt ist es lächerlich, verschiedene Aussagen des Top-Managements unserer Universität über die "Notwendigkeit, junge Wissenschaftler zu unterstützen" und anderen Unsinn zu lesen. Nun, es ist ein Exkurs.
Wir haben in nur 2 Wochen ein Visum bekommen. Gleichzeitig haben wir einen Bericht für die Rede vorbereitet und sind am 2. Juli abends zum Flughafen gefahren.
Leistung beim Finale des Data Mining Cup und Auszeichnung
Als wir am 3. Juli morgens in Berlin ankamen, gingen wir zum nHow Hotel, wo die Konferenz stattfand. Der Organisationsgrad ist natürlich hoch. In der Tat betrugen die Kosten für die Teilnahme 1000 Euro pro Person (für uns ist es kostenlos). Und so sieht das Hotel aus:

Unser Auftritt war für 16:30 Uhr geplant. Es fand im Hauptkonferenzraum statt, natürlich in englischer Sprache. Übrigens wurde die Leistung selbst bei der endgültigen Bewertung nicht berücksichtigt, sondern nur auf der Grundlage der endgültigen Bewertung berechnet, zu der nur die Organisatoren Daten hatten.
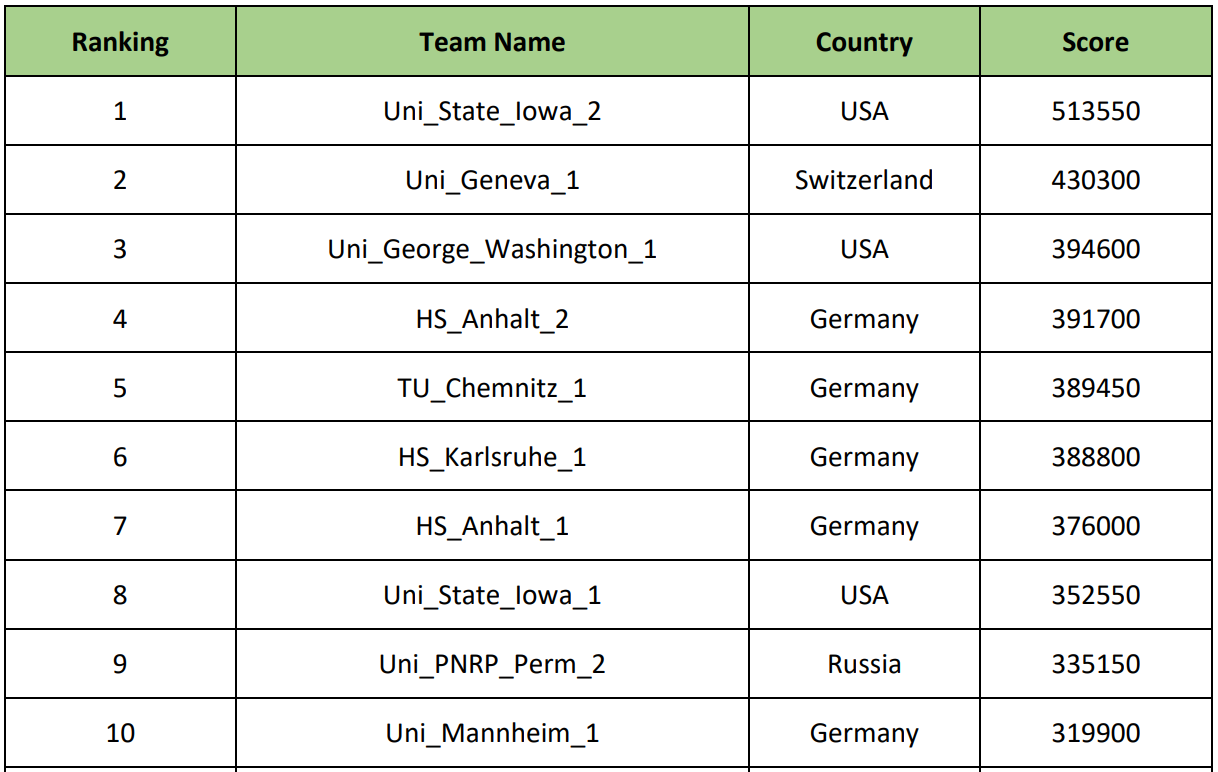
Zu den ersten 10 Teams gehörten Universitäten wie die George Washington University (USA), die Universität Genf (Schweiz), die Technologische Universität Chemnitz (Deutschland), die Universität Iowa (USA) usw. Und natürlich unsere Perm National Research Polytechnic University.
So sah der Konferenzraum aus:

Eine kleine Verlegenheit war die Tatsache, dass ich nicht mit Dias sprechen musste, sondern mit einem Poster, das auf dem Bildschirm angezeigt wurde. Daher waren die Leistungen der Teilnehmer nicht ausreichend informativ. Es bestand jedoch die Möglichkeit, sich dem Papierplakat jedes Teilnehmers im Konferenzraum zu nähern und es anzusehen. Grundsätzlich verwendeten die meisten Leute das
Stapeln, Mischen und Zusammenstellen (wir sind unter ihnen). Einige Teilnehmer verwendeten auch einen erhöhten
Schwellenwert für Klassifizierungsmodelle. Einige Teams konnten überhaupt keine Features generieren und bauten das Modell auf der Quelle auf.
Wir waren übrigens das kleinste Team - nur 2 Leute.
Nach den Vorstellungen begann ein Galadinner und eine Belohnung. Wir hofften auf Preise, erkannten jedoch, dass dies unwahrscheinlich war, und so war unser weltlicher Wunsch „mindestens nicht 10“. Es stellte sich genau so heraus, wie wir es wollten - wir haben den ehrenwerten 9. Platz belegt. Natürlich war es ein bisschen nervig, aber die Tatsache, dass wir unter so ernsthaften Universitäten im Finale standen, sagt schon viel aus. Die Gewinner waren Teilnehmer der University of Iowa (USA), obwohl man nicht sagen kann, dass sie aus den Staaten kamen (siehe Foto):
 Die Preise für den 1., 2. und 3. Platz betrugen 2.000, 1.000 bzw. 500 Euro.
Die Preise für den 1., 2. und 3. Platz betrugen 2.000, 1.000 bzw. 500 Euro. Die endgültige Bewertung lautet wie folgt:
Schlussfolgerungen
Wir haben nicht bereut, wie viel wir an diesem Wettbewerb teilgenommen haben. Zumindest ist dies eine Errungenschaft von +1 im Portfolio, bei den nützlichsten Kontakten mit Menschen und der Möglichkeit, unsere Stadt und unser Land bei einer internationalen Veranstaltung zu vertreten.
Ich rate allen Wissenschaftlern, an solchen Veranstaltungen teilzunehmen, es ist cool!