
Verwendung von Kubernetes durch Dailymotion: Anwendungsbereitstellung
Wir bei Dailymotion haben vor 3 Jahren begonnen, Kubernetes in der Produktion einzusetzen. Die Bereitstellung von Anwendungen in mehreren Clustern ist jedoch immer noch ein Vergnügen. In den letzten Jahren haben wir versucht, unsere Tools und Workflows zu verbessern.
Wo hat es angefangen?
Hier zeigen wir, wie wir unsere Anwendungen in mehreren Kubernetes-Clustern auf der ganzen Welt bereitstellen.
Um mehrere Kubernetes-Objekte gleichzeitig bereitzustellen, verwenden wir Helm und alle unsere Diagramme werden in einem Git-Repository gespeichert. Um den vollständigen Anwendungsstapel von mehreren Diensten bereitzustellen, verwenden wir das sogenannte generalisierte Diagramm. Im Wesentlichen ist dies ein Diagramm, das Abhängigkeiten deklariert und es Ihnen ermöglicht, die API und ihre Dienste mit einem einzigen Befehl zu initialisieren.
Wir haben auch ein kleines Python-Skript über Helm geschrieben, um Überprüfungen durchzuführen, Diagramme zu erstellen, Geheimnisse hinzuzufügen und Anwendungen bereitzustellen. Alle diese Aufgaben werden auf der zentralen CI-Plattform mithilfe des Docker-Images ausgeführt.
Kommen wir zum Punkt.
Hinweis Wenn Sie dies lesen, wurde bereits der erste Helm 3-Release-Kandidat angekündigt. Die Hauptversion enthält eine ganze Reihe von Verbesserungen, mit denen einige der Probleme gelöst werden sollen, auf die wir in der Vergangenheit gestoßen sind.
Diagrammentwicklungs-Workflow
Für Anwendungen verwenden wir Verzweigungen, und wir haben beschlossen, den gleichen Ansatz auf Diagramme anzuwenden.
- Der Entwicklungszweig wird verwendet, um Diagramme zu erstellen, die in Entwicklungsclustern getestet werden.
- Wenn die Poolanforderung an den Master übertragen wird , werden sie im Staging überprüft.
- Schließlich erstellen wir eine Poolanforderung, um die Änderungen in den Produktzweig zu übertragen und in der Produktion anzuwenden.
Jede Umgebung verfügt über ein eigenes privates Repository, in dem unsere Diagramme gespeichert sind, und wir verwenden das Diagrammmuseum mit sehr nützlichen APIs. Daher garantieren wir eine strikte Isolation zwischen den Umgebungen und überprüfen die Diagramme unter realen Bedingungen, bevor wir sie in der Produktion verwenden.
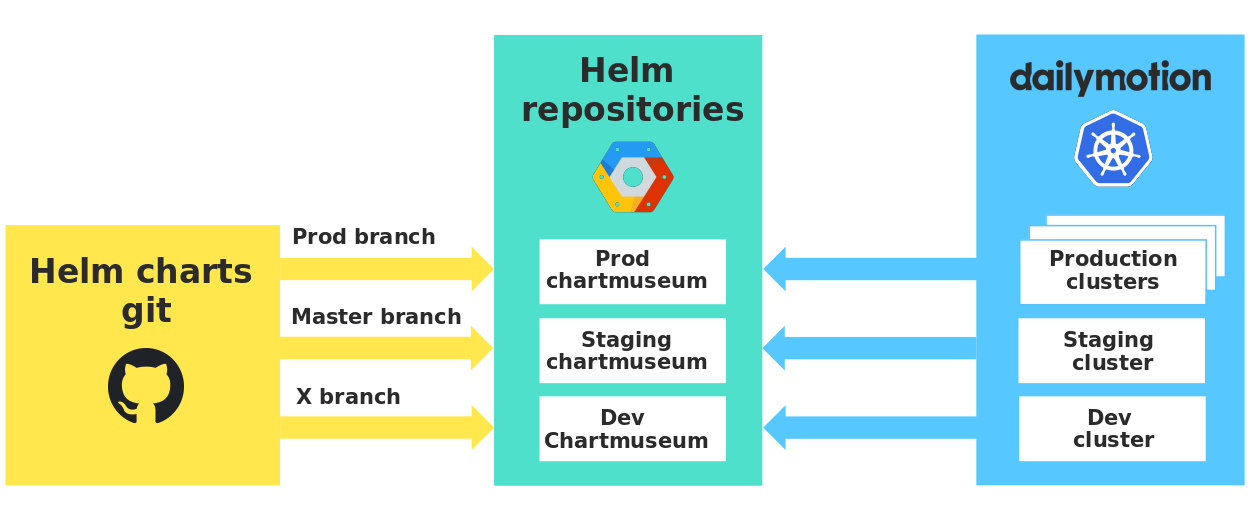
Diagramm-Repositorys in verschiedenen Umgebungen
Es ist erwähnenswert, dass beim Senden des Entwicklungszweigs durch Entwickler automatisch eine Version ihres Diagramms an das Entwickler-Chartmuseum gesendet wird. Daher verwenden alle Entwickler dasselbe Entwickler-Repository, und Sie müssen Ihre Version des Diagramms sorgfältig angeben, um die Änderungen anderer nicht versehentlich zu verwenden.
Darüber hinaus überprüft unser kleines Python-Skript Kubernetes-Objekte mit Kevnetes OpenAPI-Spezifikationen mit Kubeval, bevor sie in Chartmusem veröffentlicht werden.
Allgemeiner Diagrammentwicklungs-Workflow
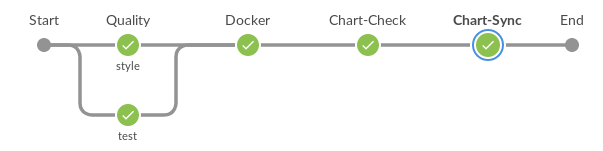
- Einrichten der Pipeline- Aufgabe gemäß der gazr.io- Spezifikation für die Qualitätskontrolle (Flusen, Unit-Test).
- Senden eines Docker-Images mit Python-Tools, die unsere Anwendungen bereitstellen.
- Festlegen der Umgebung anhand des Namens des Zweigs.
- Überprüfen Sie yaml Kubernetes-Dateien mit Kubeval.
- Erhöhen Sie automatisch die Version des Diagramms und seiner übergeordneten Diagramme (Diagramme, die vom zu ändernden Diagramm abhängen).
- Senden eines Diagramms an das Chartmuseum, das seiner Umgebung entspricht
Cluster-Differenzmanagement
Cluster Federation
Es gab eine Zeit, in der wir Kubernetes Cluster Federation verwendeten , in der Sie Kubernetes-Objekte von einem API-Endpunkt aus deklarieren konnten. Aber es gab Probleme. Beispielsweise konnten einige Kubernetes-Objekte am Endpunkt des Verbunds nicht erstellt werden, sodass es schwierig war, die kombinierten Objekte und andere Objekte für einzelne Cluster zu verwalten.
Um das Problem zu lösen, haben wir begonnen, Cluster unabhängig zu verwalten, was den Prozess erheblich vereinfacht hat (wir haben die erste Version des Verbunds verwendet; in der zweiten könnte sich etwas ändern).
Jetzt ist unsere Plattform in 6 Regionen verteilt - 3 lokal und 3 in der Cloud.
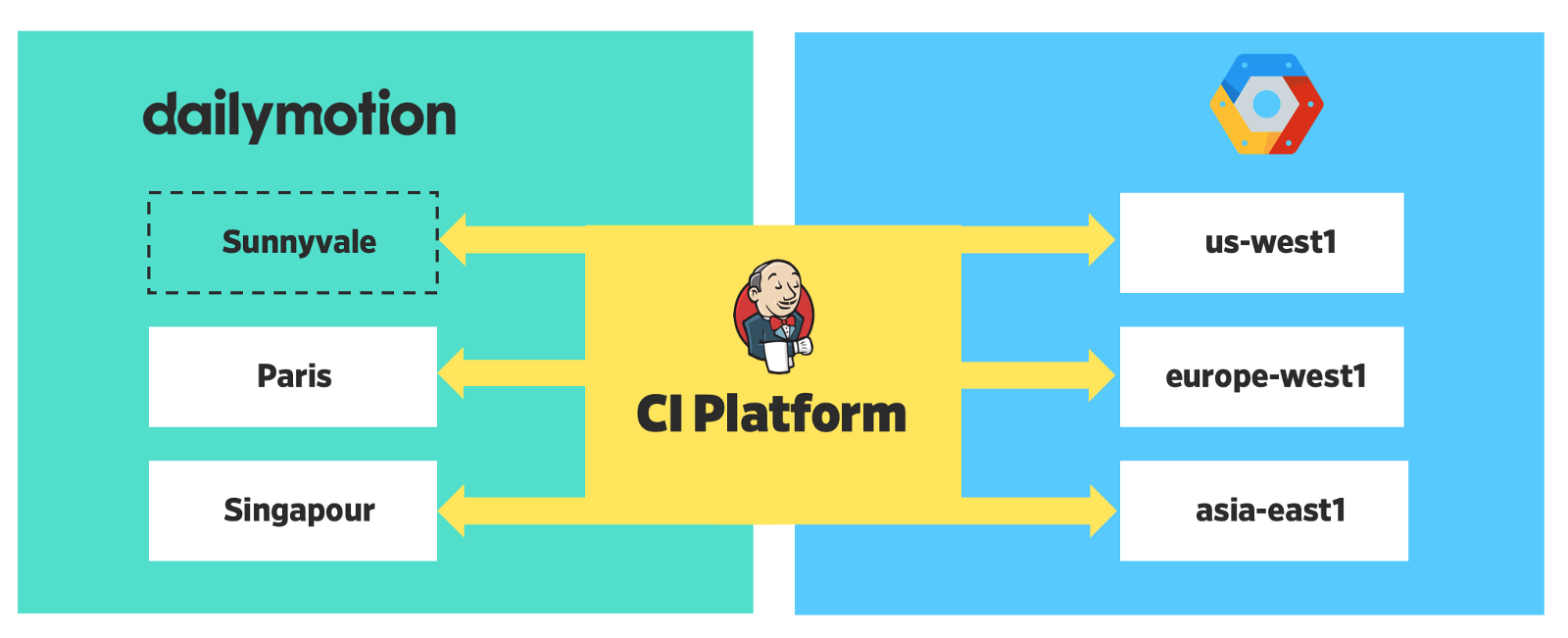
Verteilte Bereitstellung
Globale Helmwerte
Mit 4 globalen Helmwerten können Sie die Unterschiede zwischen den Clustern bestimmen. Für alle unsere Diagramme gibt es minimale Standardeinstellungen.
global: cloud: True env: staging region: us-central1 clusterName: staging-us-central1
Globale Werte
Diese Werte bestimmen den Kontext für unsere Anwendungen und werden für verschiedene Aufgaben verwendet: Überwachen, Nachverfolgen, Protokollieren, Tätigen externer Anrufe, Skalieren usw.
- "Cloud": Wir haben eine Hybridplattform Kubernetes. Beispielsweise wird unsere API in GCP-Zonen und in unseren Rechenzentren bereitgestellt.
- "Env": Einige Werte können für nicht funktionierende Umgebungen variieren. Zum Beispiel Ressourcendefinitionen und automatische Skalierungskonfigurationen.
- "Region": Mithilfe dieser Informationen können Sie den Standort des Clusters ermitteln und die nächstgelegenen Endpunkte für externe Dienste ermitteln.
- "Clustername": ob und wann wir den Wert für einen einzelnen Cluster bestimmen möchten.
Hier ist ein konkretes Beispiel:
{{/* Returns Horizontal Pod Autoscaler replicas for GraphQL*/}} {{- define "graphql.hpaReplicas" -}} {{- if eq .Values.global.env "prod" }} {{- if eq .Values.global.region "europe-west1" }} minReplicas: 40 {{- else }} minReplicas: 150 {{- end }} maxReplicas: 1400 {{- else }} minReplicas: 4 maxReplicas: 20 {{- end }} {{- end -}}
Beispiel für eine Helmvorlage
Diese Logik ist in der Hilfsvorlage definiert, um Kubernetes YAML nicht zu verstopfen.
Bewerbungsankündigung
Unsere Bereitstellungstools basieren auf mehreren YAML-Dateien. Das folgende Beispiel zeigt, wie wir einen Dienst und seine Skalierungstopologie (Anzahl der Replikate) in einem Cluster deklarieren.
releases: - foo.world foo.world: # Release name services: # List of dailymotion's apps/projects foobar: chart_name: foo-foobar repo: git@github.com:dailymotion/foobar contexts: prod-europe-west1: deployments: - name: foo-bar-baz replicas: 18 - name: another-deployment replicas: 3
Service-Definition
Dies ist ein Diagramm aller Schritte, die unseren Bereitstellungsworkflow definieren. Im letzten Schritt wird die Anwendung in mehreren Arbeitsclustern gleichzeitig bereitgestellt.
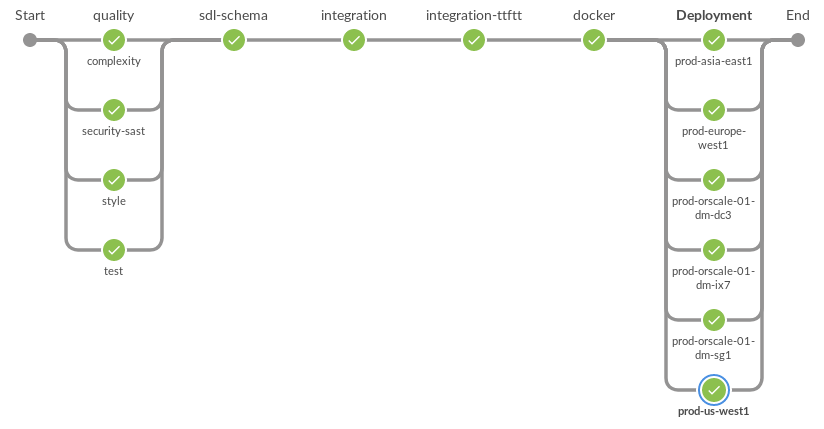
Jenkins-Bereitstellungsschritte
Was ist mit den Geheimnissen?
In Bezug auf die Sicherheit verfolgen wir alle Geheimnisse von verschiedenen Orten und speichern sie im einzigartigen Vault- Repository in Paris.
Unsere Bereitstellungstools extrahieren die Werte von Geheimnissen aus Vault und fügen sie zu gegebener Zeit in Helm ein.
Zu diesem Zweck haben wir die Zuordnung zwischen den Geheimnissen in Vault und den Geheimnissen ermittelt, die unsere Anwendungen benötigen:
secrets: - secret_id: "stack1-app1-password" contexts: - name: "default" vaultPath: "/kv/dev/stack1/app1/test" vaultKey: "password" - name: "cluster1" vaultPath: "/kv/dev/stack1/app1/test" vaultKey: "password"
- Wir haben die allgemeinen Regeln festgelegt, die Sie beim Schreiben von Geheimnissen in Vault befolgen müssen.
- Wenn sich das Geheimnis auf einen bestimmten Kontext oder Cluster bezieht, müssen Sie einen bestimmten Eintrag hinzufügen. (Hier hat der Kontext von Cluster1 einen eigenen Wert für das geheime Stack-App1-Passwort).
- Andernfalls wird der Standardwert verwendet.
- Für jedes Element in dieser Liste wird ein Schlüssel-Wert-Paar in das Kubernetes-Geheimnis eingefügt. Daher ist das geheime Muster in unseren Diagrammen sehr einfach.
apiVersion: v1 data: {{- range $key,$value := .Values.secrets }} {{ $key }}: {{ $value | b64enc | quote }} {{ end }} kind: Secret metadata: name: "{{ .Chart.Name }}" labels: chartVersion: "{{ .Chart.Version }}" tillerVersion: "{{ .Capabilities.TillerVersion.SemVer }}" type: Opaque
Probleme und Einschränkungen
Arbeiten Sie mit mehreren Repositorys
Jetzt teilen wir die Entwicklung von Diagrammen und Anwendungen. Dies bedeutet, dass Entwickler in zwei Git-Repositorys arbeiten müssen: eines für die Anwendung und das zweite für die Bestimmung der Bereitstellung in Kubernetes. 2 Git-Repositories sind 2 Workflows und es ist leicht für einen Neuling, verwirrt zu werden.
Das Verwalten von zusammengefassten Diagrammen ist mühsam
Wie bereits erwähnt, sind generische Diagramme sehr praktisch, um Abhängigkeiten zu definieren und mehrere Anwendungen schnell bereitzustellen. Wir verwenden jedoch --reuse-values , um zu vermeiden, dass bei jeder Bereitstellung der in diesem allgemeinen Diagramm enthaltenen Anwendung alle Werte übergeben werden.
Im Workflow für die kontinuierliche Bereitstellung haben wir nur zwei Werte, die sich regelmäßig ändern: die Anzahl der Replikate und das Image-Tag (Version). Andere, stabilere Werte werden manuell geändert, was ziemlich kompliziert ist. Darüber hinaus kann ein Fehler bei der Bereitstellung eines verallgemeinerten Diagramms zu schwerwiegenden Fehlern führen, wie wir aus eigener Erfahrung gesehen haben.
Aktualisieren mehrerer Konfigurationsdateien
Wenn ein Entwickler eine neue Anwendung hinzufügt, muss er mehrere Dateien ändern: die Ankündigung der Anwendung, die Liste der Geheimnisse und das Hinzufügen der Anwendung, je nachdem, ob sie in der allgemeinen Tabelle enthalten ist.
Jenkins Berechtigungen in Vault wurden ebenfalls erweitert
Jetzt haben wir eine AppRole , die alle Geheimnisse von Vault liest.
Der Rollback-Prozess ist nicht automatisiert
Zum Zurücksetzen müssen Sie den Befehl auf mehreren Clustern ausführen. Dies ist mit Fehlern behaftet. Wir führen diesen Vorgang manuell durch, um sicherzustellen, dass die richtige Versionskennung angegeben ist.
Wir bewegen uns in Richtung GitOps
Unser Ziel
Wir möchten das Diagramm an das Repository der Anwendung zurückgeben, die es bereitstellt.
Der Workflow ist der gleiche wie für die Entwicklung. Wenn beispielsweise ein Zweig an den Assistenten gesendet wird, wird die Bereitstellung automatisch gestartet. Der Hauptunterschied zwischen diesem Ansatz und dem aktuellen Workflow besteht darin, dass alles in Git verwaltet wird (die Anwendung selbst und wie sie in Kubernetes bereitgestellt wird).
Es gibt mehrere Vorteile:
- Viel klarer für den Entwickler. Es ist einfacher zu lernen, wie Sie Änderungen auf das lokale Diagramm anwenden.
- Eine Dienstbereitstellungsdefinition kann angegeben werden, wo sich der Dienstcode befindet .
- Verwaltung der Entfernung von verallgemeinerten Diagrammen . Der Dienst wird eine eigene Helm-Version haben. Auf diese Weise können Sie den Anwendungslebenszyklus (Rollback, Upgrade) auf der kleinsten Ebene verwalten, um andere Dienste nicht zu beeinträchtigen.
- Die Vorteile von git für die Verwaltung von Diagrammen sind: Rückgängigmachen von Änderungen, Prüfpfad usw. Wenn Sie eine Änderung an einem Diagramm rückgängig machen müssen, können Sie dies mit git tun. Die Bereitstellung wird automatisch gestartet.
- Sie können Ihren Entwicklungsworkflow mit Tools wie Skaffold verbessern , mit denen Entwickler Änderungen in einem produktionsähnlichen Kontext testen können.
Zweistufige Migration
Unsere Entwickler verwenden diesen Workflow seit 2 Jahren, daher benötigen wir die schmerzloseste Migration. Aus diesem Grund haben wir beschlossen, auf dem Weg zum Ziel eine Zwischenstufe hinzuzufügen.
Der erste Schritt ist einfach:
- Wir behalten eine ähnliche Struktur für die Konfiguration der Anwendungsbereitstellung bei, jedoch im selben Objekt namens DailymotionRelease.
apiVersion: "v1" kind: "DailymotionRelease" metadata: name: "app1.ns1" environment: "dev" branch: "mybranch" spec: slack_channel: "#admin" chart_name: "app1" scaling: - context: "dev-us-central1-0" replicas: - name: "hermes" count: 2 - context: "dev-europe-west1-0" replicas: - name: "app1-deploy" count: 2 secrets: - secret_id: "app1" contexts: - name: "default" vaultPath: "/kv/dev/ns1/app1/test" vaultKey: "password" - name: "dev-europe-west1-0" vaultPath: "/kv/dev/ns1/app1/test" vaultKey: "password"
- 1 Release pro Anwendung (ohne verallgemeinerte Diagramme).
- Diagramme im Git-Anwendungsrepository.
Wir haben mit allen Entwicklern gesprochen, daher hat der Migrationsprozess bereits begonnen. Die erste Phase wird weiterhin über die CI-Plattform gesteuert. Bald werde ich einen weiteren Beitrag über die zweite Phase schreiben: Wie wir mit Flux zum GitOps-Workflow gewechselt sind. Ich werde Ihnen sagen, wie wir uns alle eingerichtet haben und auf welche Schwierigkeiten wir gestoßen sind (mehrere Repositories, Geheimnisse usw.). Folgen Sie den Nachrichten.
Hier haben wir versucht, unsere Fortschritte im Workflow für die Anwendungsbereitstellung in den letzten Jahren zu beschreiben, was zu Überlegungen zum GitOps-Ansatz führte. Wir haben das Ziel nicht erreicht und werden über die Ergebnisse berichten, aber jetzt sind wir überzeugt, dass wir es richtig gemacht haben, als wir beschlossen haben, alles zu vereinfachen und es den Gewohnheiten der Entwickler näher zu bringen.