Einführung
Vor einiger Zeit musste ich das Problem der Segmentierung von Punkten in einer Punktwolke lösen (Punktwolken sind Daten, die von Lidars erhalten wurden).
Beispieldaten und die zu lösende Aufgabe:
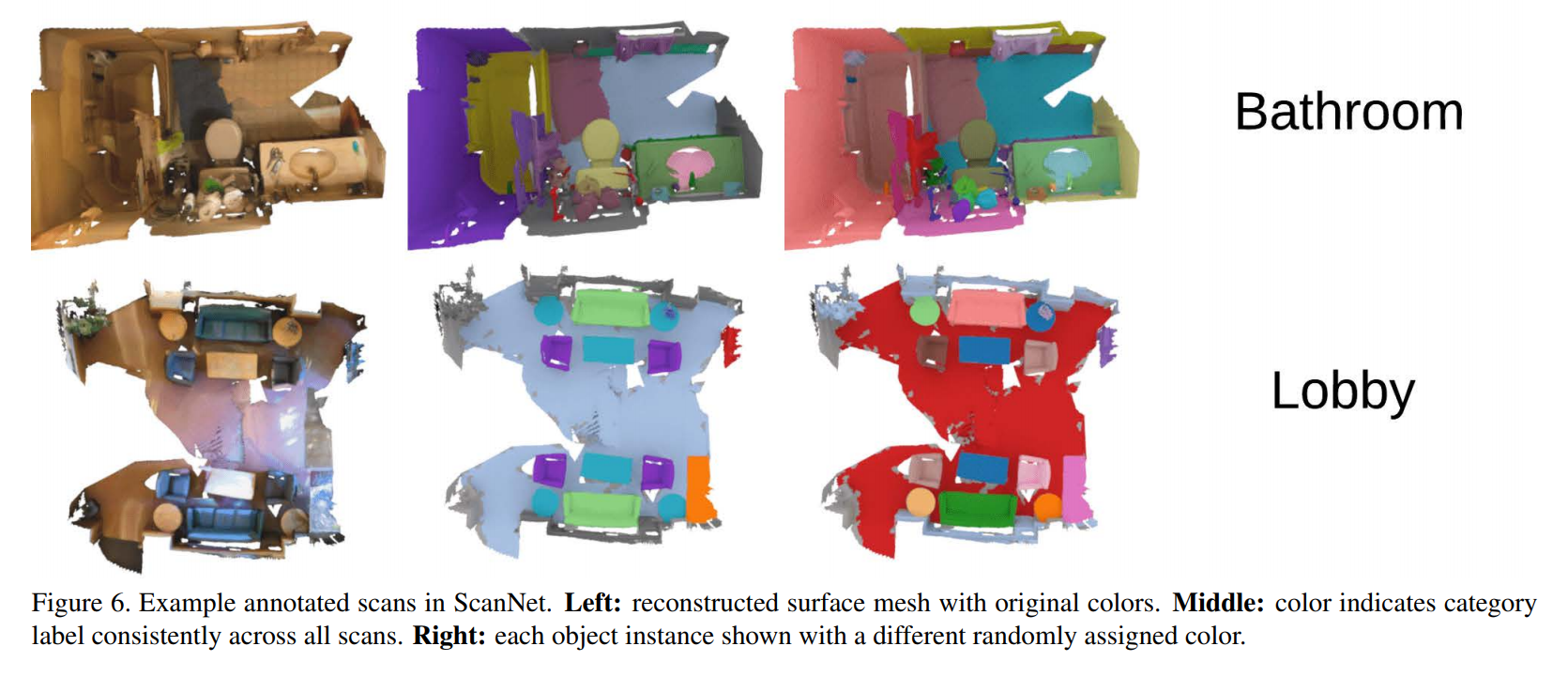
Die Suche nach einem allgemeinen Überblick über bestehende Methoden war erfolglos, so dass ich selbst Informationen sammeln musste. Sie können das Ergebnis sehen: Hier sind die wichtigsten und meiner Meinung nach wichtigsten Artikel der letzten Jahre zusammengefasst. Alle betrachteten Modelle lösen das Problem der Segmentierung einer Punktwolke (zu welcher Klasse jeder Punkt gehört).
Dieser Artikel ist nützlich für diejenigen, die mit neuronalen Netzen vertraut sind und verstehen möchten, wie sie auf unstrukturierte Daten (z. B. Diagramme) angewendet werden.
Vorhandene Datensätze
Jetzt im öffentlichen Bereich gibt es die folgenden Datensätze zu diesem Thema:
Funktionen der Arbeit mit Punktwolken
Neuronale Netze sind vor kurzem in dieses Gebiet gekommen. Und Standardarchitekturen wie vollständig verbundene und Faltungsnetzwerke sind nicht anwendbar, um dieses Problem zu lösen. Warum?
Weil die Reihenfolge der Punkte hier nicht wichtig ist. Ein Objekt besteht aus einer Reihe von Punkten, und es spielt keine Rolle, in welcher Reihenfolge sie angezeigt werden. Wenn jedes Pixel seinen Platz im Bild hat, können wir die Punkte sicher mischen und das Objekt ändert sich nicht. Das Ergebnis von Standard-Neuronalen Netzen hängt im Gegensatz dazu vom Ort der Daten ab. Wenn Sie Pixel auf das Bild mischen, erhalten Sie ein neues Objekt.
Nun wollen wir sehen, wie sich neuronale Netze angepasst haben, um dieses Problem zu lösen.
Wichtigste Artikel
In diesem Bereich gibt es nicht viele grundlegende Architekturen. Wenn Sie mit Grafiken oder unstrukturierten Daten arbeiten möchten, müssen Sie eine Vorstellung von den folgenden Modellen haben:
Betrachten wir sie genauer.
- PointNet: Deep Learning zu Punktmengen für die 3D-Klassifizierung und -Segmentierung
Pioniere bei der Arbeit mit unstrukturierten Daten.
- wie sie sich entscheiden: Der Artikel beschreibt zwei Modelle: zur Segmentierung von Punkten und zur Klassifizierung eines Objekts. Der allgemeine Teil besteht aus folgenden Blöcken:
- ein Netzwerk zur Bestimmung der Transformation (Übersetzung des Koordinatensystems), das dann für alle Punkte gilt
- Transformation wird auf jeden Punkt einzeln angewendet (regulärer Perzeptor)
- maxpooling, das Informationen aus verschiedenen Punkten kombiniert und einen globalen Merkmalsvektor für das gesamte Objekt erstellt.
- dann beginnen die Unterschiede zwischen den Modellen:
- Klassifizierungsmodell: Ein globaler Merkmalsvektor wird an die Eingabe einer vollständig verbundenen Ebene gesendet, um die Klasse der gesamten Punktwolke zu bestimmen
- Modell für die Segmentierung: Der globale Merkmalsvektor und die berechneten Merkmale für jeden Punkt gehen zur Eingabe der vollständig verbundenen Ebene, die die Klasse für jeden Punkt definiert.
- Code

- PointNet ++: Deep Hierarchical Feature Learning für Punktmengen in einem metrischen Raum
Die gleichen Leute aus Stanford, die PointNet beschrieben haben.
- wie sie sich entscheiden: pointNet wird rekursiv auf kleinere Subwolken angewendet, ähnlich wie Faltungsnetzwerke. Das heißt, Würfel teilen den Raum, PointNet wird auf jeden angewendet, dann bestehen neue Würfel aus diesen Würfeln. Auf diese Weise können Sie lokale Anzeichen dafür hervorheben, dass die vorherige Version des Netzwerks verloren gegangen ist.
- Code


Artikel basierend auf PointNet und PointNet ++:
Die meisten Artikel unterscheiden sich hinsichtlich der Fehleranzahl oder der Tiefe und Komplexität komplexer Blöcke.
PointWise: Ein unbeaufsichtigtes punktuelles Feature-Learning-Netzwerk
Merkmal der Arbeit - Ausbildung ohne Lehrer
- wie sie sich entscheiden: Für jeden Punkt wird der Vektor der Einbettungen trainiert, durch den sie dann segmentiert werden.
Das Hauptpostulat des Artikels lautet, dass ähnliche Objekte trotz ihrer Abgelegenheit ähnliche Einbettungen aufweisen sollten (z. B. zwei verschiedene Beine eines Stuhls). PointNet wird als Basismodell verwendet. Die Hauptinnovation ist die Fehlerfunktion. Es besteht aus zwei Teilen: Rekonstruktionsfehlern und Glättungsfehlern.
Der Rekonstruktionsfehler verwendet Punktkontextinformationen. Ihre Aufgabe ist es, die Einbettung von Punkten mit demselben geometrischen Kontext ähnlich zu gestalten. Zur Berechnung werden basierend auf dem Einbettungsvektor für den ausgewählten Punkt neue Punkte in der Nähe generiert. Das heißt, die Merkmalsbeschreibung des Punkts sollte Informationen über die Form des Objekts um den Punkt enthalten. Überlegen Sie als Nächstes, wie stark die generierten Punkte aus der tatsächlichen Form des Objekts herausfallen.
Der Glättungsfehler wird benötigt, damit die Einbettungen an den benachbarten Punkten ähnlich und an den entfernten Punkten anders sind. Das Schönste dabei ist die Messung der Nähe, nicht nur als Norm zwischen zwei Punkten im euklidischen Raum, sondern auch die Zählung der Entfernung durch die Punkte des Objekts. Für jeden Punkt wird ein Punkt aus k am nächsten und aus k weiter ausgewählt.
Die aktuelle Einbettung sollte um einen gewissen Abstand näher am nächsten Minimum liegen als zuvor.
SGPN: Ähnlichkeitsgruppen-Vorschlagsnetzwerk für die Segmentierung von 3D-Punktwolkeninstanzen
- wie sie sich entscheiden: Wie in PointWise ist hier das Interessanteste bei der Berechnung des Fehlers. PointNet ++ ist die Basis. Zuerst betrachten wir den Merkmalsvektor und das Objekt gehören zu jedem Punkt einzeln, analog zu PointNet ++.
Als nächstes betrachten wir basierend auf den Merkmalen 3 Matrizen (Ähnlichkeit, Vertrauen und Segmentierung).
Der Lernfehler ist die Summe von drei Fehlern, die durch die entsprechenden Matrizen berechnet werden: L = L1 + L2 + L3
Sei N die Anzahl der Punkte
Ähnlichkeitsmatrix - Quadrat, Größe N * N. Das Element am Schnittpunkt der i-ten Zeile und der j-ten Spalte gibt an, ob diese Punkte zum selben Objekt gehören oder nicht. Punkte, die zum selben Objekt gehören, müssen ähnliche Merkmalsvektoren haben. Elemente der Matrix können einen von drei Werten annehmen: Punkte i und j gehören zu einem Objekt, Punkte gehören zu einer Klasse von Objekten, aber zu verschiedenen Objekten (sowohl dieser als auch dieser Stuhl, aber die Stühle sind unterschiedlich) oder dies sind im Allgemeinen Punkte von Objekten verschiedener Klassen. Diese Matrix wird nach wahren Werten berechnet.

Die Konfidenzmatrix ist ein Vektor der Länge N. Für jeden Punkt wird der Schnittpunkt über der Vereinigung (IoU) zwischen der Menge von Punkten, die gemäß der Arbeit unseres Algorithmus zum Objekt gehören, und der Menge von Punkten, die tatsächlich zum Objekt mit dem aktuellen Punkt gehören, berücksichtigt. Der Fehler ist einfach die L2-Norm zwischen der Wahrheit und der berechneten Matrix. Das heißt, das Netzwerk versucht vorherzusagen, wie sicher es bei der Klassenvorhersage für Punkte auf einem Objekt ist.
Die Segmentierungsmatrix hat eine Größe - N * die Anzahl der Klassen. Der Fehler wird hier als Kreuzentropie im Mehrklassenklassifizierungsproblem betrachtet. - Code

- Wissen, was Ihre Nachbarn tun: 3D-semantische Segmentierung von Punktwolken
- wie sie sich entscheiden: Zuerst betrachten sie die Zeichen für eine lange Zeit, komplizierter als in PointNet, mit einer Reihe von Restverbindungen und Beträgen, aber im Allgemeinen - das Gleiche. Ein kleiner Unterschied - sie zählen die Vorzeichen für jeden Punkt in globalen und lokalen Koordinaten.
Der Hauptunterschied ist hier wieder die Fehlerzahl. Dies ist keine Standard-Crossentropie, sondern die Summe zweier Fehler:
- paarweiser Abstandsverlust - Punkte von einem Objekt sollten näher als τ_near sein und Punkte von verschiedenen Objekten sollten länger als τ_far sein .
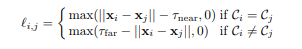
- Schwerpunktverlust - Punkte von einem Objekt sollten nahe beieinander liegen
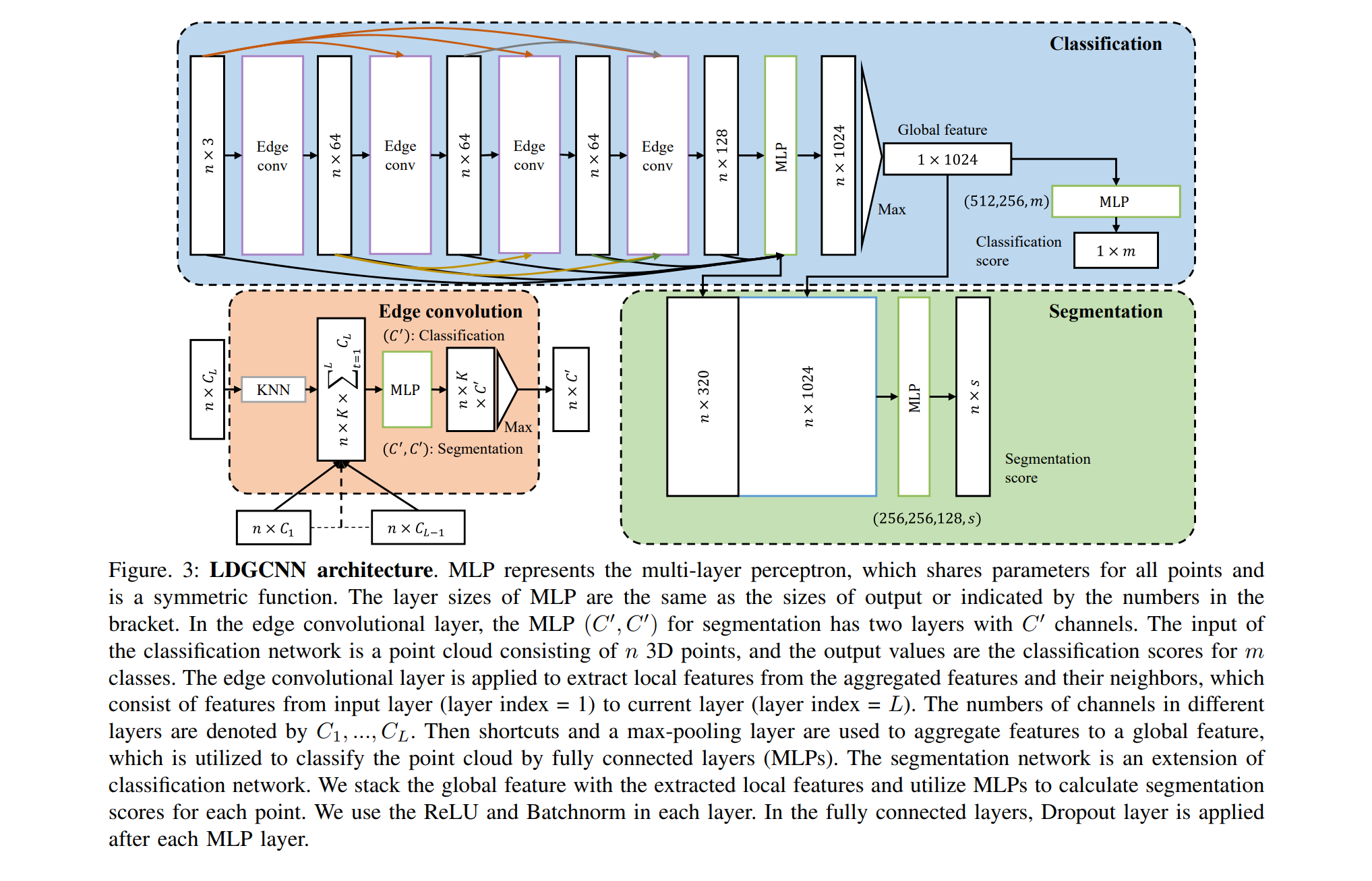
DGCNN-basierte Artikel:
DGCNN wurde kürzlich (2018) veröffentlicht, daher gibt es nur wenige Artikel, die auf dieser Architektur basieren. Ich möchte Ihre Aufmerksamkeit auf eine Sache lenken:
Fazit
Hier finden Sie kurze Informationen zu modernen Methoden zur Lösung von Klassifizierungs- und Segmentierungsproblemen in Punktwolken. Es gibt zwei Hauptmodelle (PointNet ++, DGCNN), deren Modifikationen jetzt zur Lösung dieser Probleme verwendet werden. In den meisten Fällen wird zur Änderung die Fehlerfunktion geändert, und diese Architekturen werden durch Hinzufügen von Ebenen und Verknüpfungen kompliziert.