GitHub hostet über 300 Programmiersprachen - von häufig verwendeten Sprachen wie Python, Java und Javascript bis zu esoterischen Sprachen wie
Befunge , die nur sehr kleinen Communities bekannt sind.
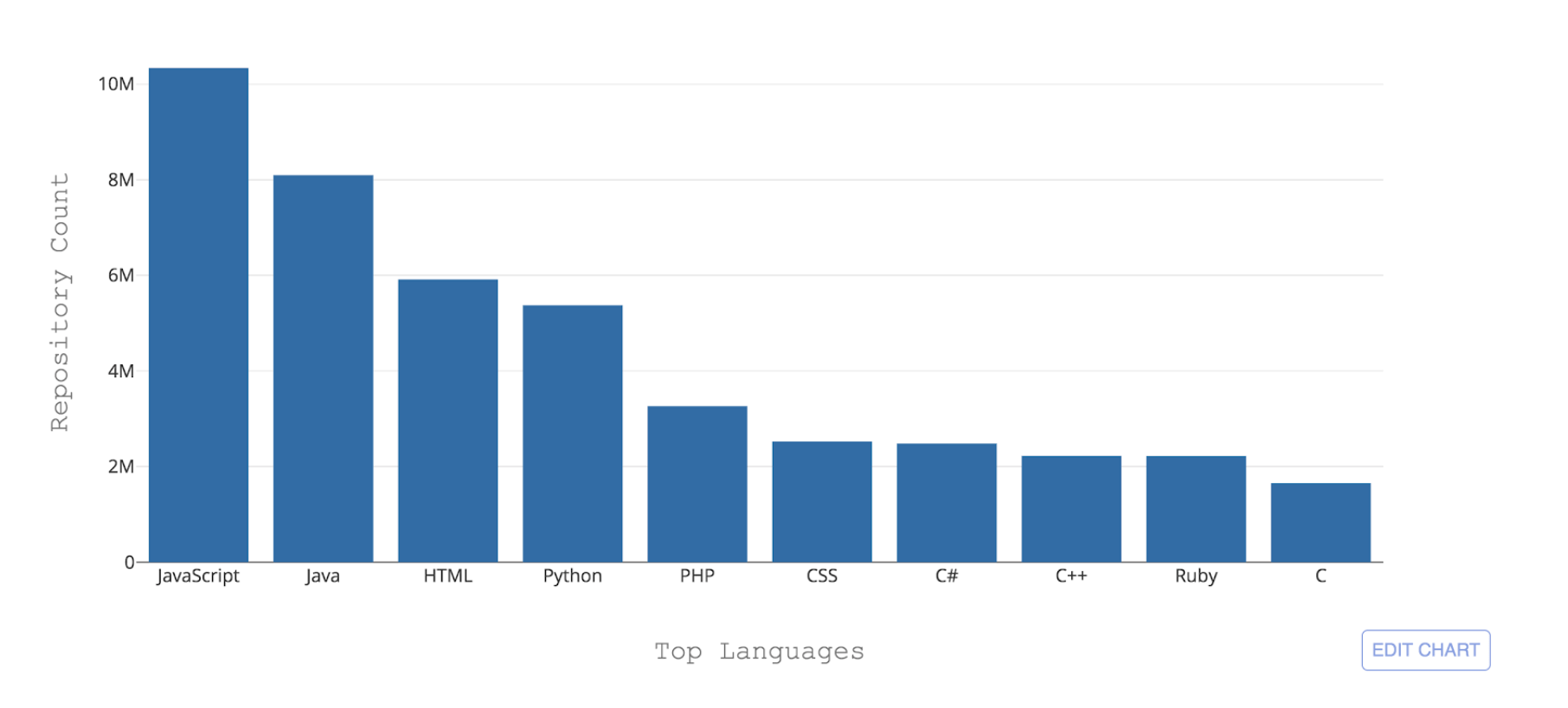 Abbildung 1: Top 10 der von GitHub gehosteten Programmiersprachen nach Repository-Anzahl
Abbildung 1: Top 10 der von GitHub gehosteten Programmiersprachen nach Repository-AnzahlEine der notwendigen Herausforderungen für GitHub besteht darin, diese verschiedenen Sprachen erkennen zu können. Wenn Code in ein Repository übertragen wird, ist es wichtig, den Codetyp zu erkennen, der zum Zwecke der Suche, der Warnung vor Sicherheitslücken und der Hervorhebung der Syntax hinzugefügt wurde, und den Benutzern die Inhaltsverteilung des Repositorys anzuzeigen.
Linguist ist das Tool, mit dem wir derzeit Codierungssprachen bei GitHub erkennen. Linguist ist eine Ruby-basierte Anwendung, die verschiedene Strategien zur Spracherkennung verwendet, Namenskonventionen und Dateierweiterungen nutzt und auch Vim- oder Emacs-Modelle sowie den Inhalt oben in der Datei (shebang) berücksichtigt. Der Linguist behandelt die Sprachdisambiguierung über Heuristiken und, falls dies nicht der Fall ist, über einen Naive Bayes-Klassifikator, der anhand einer kleinen Datenstichprobe trainiert wurde.
Obwohl Linguist gute Arbeit bei der Erstellung von Sprachvorhersagen auf Dateiebene leistet (84% Genauigkeit), nimmt die Leistung erheblich ab, wenn Dateien unerwartete Namenskonventionen verwenden und vor allem, wenn keine Dateierweiterung bereitgestellt wird. Dies macht Linguist für Inhalte wie GitHub Gists oder Codefragmente in README-Dateien, Problemen und Pull-Anforderungen ungeeignet.
Um die Spracherkennung auf lange Sicht robuster und wartbarer zu machen, haben wir einen Klassifikator für maschinelles Lernen namens Octo Lingua entwickelt, der auf einer ANN-Architektur (Artificial Neural Network) basiert und Sprachvorhersagen in schwierigen Szenarien verarbeiten kann. Die aktuelle Version des Modells kann Vorhersagen für die 50 von GitHub gehosteten Sprachen treffen und übertrifft Linguist in Genauigkeit und Leistung.
Die Schrauben und Muttern hinter OctoLingua
OctoLingua wurde mit Python, Keras und TensorFlow-Backend von Grund auf neu erstellt - und ist so aufgebaut, dass es genau, robust und einfach zu warten ist. In diesem Abschnitt beschreiben wir unsere Datenquellen, Modellarchitektur und Leistungsbenchmark für OctoLingua. Wir beschreiben auch, was erforderlich ist, um Unterstützung für eine neue Sprache hinzuzufügen.
Datenquellen
Die aktuelle Version von OctoLingua wurde auf Dateien trainiert, die aus
Rosetta Code und aus einer Reihe von Qualitäts-Repositories abgerufen wurden, die intern über Crowdsourcing bezogen wurden. Wir haben unsere Sprache auf die 50 besten Sprachen beschränkt, die auf GitHub gehostet werden.
Rosetta Code war ein ausgezeichneter Starter-Datensatz, da er Quellcode für dieselbe Aufgabe enthielt, der in verschiedenen Programmiersprachen ausgedrückt wurde. Zum Beispiel wird die Aufgabe des Erzeugens einer
Fibonacci-Sequenz in C, C ++, CoffeeScript, D, Java, Julia und mehr ausgedrückt. Die Abdeckung über Sprachen hinweg war jedoch nicht einheitlich, da einige Sprachen nur eine Handvoll Dateien enthalten und einige Dateien einfach zu dünn besiedelt waren. Es war daher notwendig, unser Trainingsset um einige zusätzliche Quellen zu erweitern und die Sprachabdeckung und -leistung erheblich zu verbessern.
Unser Prozess zum Hinzufügen einer neuen Sprache ist jetzt vollständig automatisiert. Wir sammeln programmgesteuert Quellcode aus öffentlichen Repositories auf GitHub. Wir wählen Repositorys aus, die ein Mindestkriterium für die Qualifizierung erfüllen, z. B. eine Mindestanzahl von Gabeln, die die Zielsprache und bestimmte Dateierweiterungen abdecken. Für diese Phase der Datenerfassung bestimmen wir die Primärsprache eines Repositorys anhand der Klassifizierung von Linguist.
Features: Nutzung von Vorkenntnissen
Traditionell werden für Textklassifizierungsprobleme mit neuronalen Netzen häufig speicherbasierte Architekturen wie wiederkehrende neuronale Netze (RNN) und Langzeit-Kurzzeitspeichernetzwerke (LSTM) verwendet. Angesichts der Tatsache, dass Programmiersprachen Unterschiede im Wortschatz, im Kommentarstil, in den Dateierweiterungen, in der Struktur, im Importstil der Bibliotheken und in anderen geringfügigen Unterschieden aufweisen, haben wir uns für einen einfacheren Ansatz entschieden, bei dem alle diese Informationen genutzt werden, indem einige relevante Funktionen in Tabellenform extrahiert werden, denen sie zugeführt werden unser Klassifikator. Die derzeit extrahierten Funktionen lauten wie folgt:
- Top fünf Sonderzeichen pro Datei
- Top 20 Token pro Datei
- Dateierweiterung
- Vorhandensein bestimmter Sonderzeichen, die häufig in Quellcodedateien verwendet werden, z. B. Doppelpunkte, geschweifte Klammern und Semikolons
Das ANN-Modell (Artificial Neural Network)
Wir verwenden die oben genannten Funktionen als Eingabe für ein zweischichtiges künstliches neuronales Netzwerk, das mit Keras mit Tensorflow-Backend erstellt wurde.
Das folgende Diagramm zeigt, dass der Merkmalsextraktionsschritt eine n-dimensionale tabellarische Eingabe für unseren Klassifizierer erzeugt. Während sich die Informationen entlang der Schichten unseres Netzwerks bewegen, werden sie durch Dropout reguliert und erzeugen letztendlich eine 51-dimensionale Ausgabe, die die vorhergesagte Wahrscheinlichkeit darstellt, dass der angegebene Code in jeder der 50 besten GitHub-Sprachen geschrieben ist, plus die Wahrscheinlichkeit, dass dies nicht der Fall ist geschrieben in einem von denen.
Abbildung 2: Die ANN-Struktur unseres ursprünglichen Modells (50 Sprachen + 1 für "andere")Wir haben 90% unseres Datensatzes für das Training in ungefähr acht Epochen verwendet. Darüber hinaus haben wir im Trainingsschritt einen Prozentsatz der Dateierweiterungen aus unseren Trainingsdaten entfernt, um das Modell zu ermutigen, aus dem Vokabular der Dateien zu lernen, und die Dateierweiterungsfunktion, die sehr aussagekräftig ist, nicht zu stark anzupassen.
Leistungsbenchmark
OctoLingua vs. SprachwissenschaftlerIn Abbildung 3 zeigen wir den
F1-Score (harmonisches Mittel zwischen Präzision und Rückruf) von OctoLingua und Linguist, der mit demselben Testsatz berechnet wurde (10% aus unserer ursprünglichen Datenquelle).
Hier zeigen wir drei Tests. Der erste Test ist mit dem Test-Set in keiner Weise unberührt. Der zweite Test verwendet denselben Satz von Testdateien, wobei die Dateierweiterungsinformationen entfernt wurden, und der dritte Test verwendet denselben Satz von Dateien, diesmal jedoch mit verschlüsselten Dateierweiterungen, um die Klassifizierer zu verwirren (z. B. kann eine Java-Datei ein "haben. Die Erweiterung txt "und eine Python-Datei haben möglicherweise die Erweiterung" .java ".
Die Intuition hinter dem Verwürfeln oder Entfernen der Dateierweiterungen in unserem Testsatz besteht darin, die Robustheit von OctoLingua bei der Klassifizierung von Dateien zu bewerten, wenn eine wichtige Funktion entfernt wird oder irreführend ist. Ein Klassifizierer, der sich nicht stark auf die Erweiterung stützt, wäre äußerst nützlich, um Gists und Snippets zu klassifizieren, da in diesen Fällen häufig keine genauen Erweiterungsinformationen angegeben werden (z. B. haben viele Code-bezogene Gists eine .txt-Erweiterung).
Die folgende Tabelle zeigt, wie OctoLingua unter verschiedenen Bedingungen eine gute Leistung beibehält, was darauf hindeutet, dass das Modell hauptsächlich aus dem Vokabular des Codes und nicht aus Metainformationen (dh Dateierweiterung) lernt, während Linguist fehlschlägt, sobald die Informationen zu Dateierweiterungen vorliegen verändert.
Abbildung 3: Leistung von OctoLingua vs. Linguist am selben TestsatzEffekt des Entfernens der Dateierweiterung während der TrainingszeitWie bereits erwähnt, haben wir während der Trainingszeit einen Prozentsatz der Dateierweiterungen aus unseren Trainingsdaten entfernt, um das Modell zu ermutigen, aus dem Vokabular der Dateien zu lernen. Die folgende Tabelle zeigt die Leistung unseres Modells mit verschiedenen Bruchteilen von Dateierweiterungen, die während der Trainingszeit entfernt wurden.
 Abbildung 4: Leistung von OctoLingua mit unterschiedlichem Prozentsatz an Dateierweiterungen, die bei unseren drei Testvarianten entfernt wurden
Abbildung 4: Leistung von OctoLingua mit unterschiedlichem Prozentsatz an Dateierweiterungen, die bei unseren drei Testvarianten entfernt wurdenBeachten Sie, dass die Leistung von OctoLingua bei Testdateien ohne Erweiterungen und randomisierten Erweiterungen erheblich geringer ist als bei den regulären Testdaten, wenn während der Trainingszeit keine Dateierweiterung entfernt wurde. Wenn das Modell hingegen in einem Dataset trainiert wird, in dem einige Dateierweiterungen entfernt werden, nimmt die Modellleistung des geänderten Testsatzes nicht wesentlich ab. Dies bestätigt, dass das Entfernen der Dateierweiterung aus einem Bruchteil der Dateien zur Trainingszeit unseren Klassifizierer dazu veranlasst, mehr aus dem Wortschatz zu lernen. Es zeigt auch, dass die Dateierweiterungsfunktion, obwohl sie sehr aussagekräftig ist, tendenziell dominiert und verhindert, dass den Inhaltsfunktionen mehr Gewichte zugewiesen werden.
Unterstützung einer neuen Sprache
Das Hinzufügen einer neuen Sprache in OctoLingua ist ziemlich einfach. Es beginnt mit dem Abrufen eines Großteils der Dateien in der neuen Sprache (wir können dies programmgesteuert tun, wie in Datenquellen beschrieben). Diese Dateien werden in ein Trainings- und ein Test-Set aufgeteilt und dann über unseren Präprozessor und Feature-Extraktor ausgeführt. Dieses neue Zug- und Test-Set wird unserem vorhandenen Pool an Trainings- und Testdaten hinzugefügt. Mit dem neuen Testsatz können wir überprüfen, ob die Genauigkeit unseres Modells akzeptabel bleibt.
Abbildung 5: Hinzufügen einer neuen Sprache mit OctoLinguaUnsere Pläne
OctoLingua befindet sich derzeit in der "fortgeschrittenen Prototyping-Phase". Unsere Sprachklassifizierungs-Engine ist bereits robust und zuverlässig, unterstützt jedoch noch nicht alle Codierungssprachen auf unserer Plattform. Abgesehen von der Erweiterung der Sprachunterstützung - was ziemlich einfach wäre - möchten wir die Spracherkennung auf verschiedenen Granularitätsstufen ermöglichen. Unsere aktuelle Implementierung ermöglicht es uns bereits, mit einer kleinen Modifikation unserer Engine für maschinelles Lernen Code-Schnipsel zu klassifizieren. Es wäre nicht zu weit hergeholt, das Modell so weit zu bringen, dass es eingebettete Sprachen zuverlässig erkennen und klassifizieren kann.
Wir erwägen auch die Möglichkeit eines Open-Sourcing unseres Modells und würden gerne von der Community hören, wenn Sie interessiert sind.
Zusammenfassung
Unser Ziel mit OctoLingua ist es, einen Service bereitzustellen, der eine robuste und zuverlässige Erkennung der Quellcode-Sprache auf mehreren Granularitätsebenen ermöglicht, von der Datei- oder Snippet-Ebene bis zur potenziellen Spracherkennung und -klassifizierung auf Zeilenebene. Letztendlich kann dieser Service unter anderem die Suchbarkeit von Code, die gemeinsame Nutzung von Code, das Hervorheben von Sprachen und das Rendern von Unterschieden unterstützen. All dies zielt darauf ab, Entwickler bei ihrer täglichen Entwicklungsarbeit zu unterstützen und ihnen beim Schreiben von qualitativ hochwertigem Code zu helfen. Wenn Sie daran interessiert sind, unsere Arbeit zu nutzen oder dazu beizutragen, können Sie sich
gerne auf Twitter
@github melden !