Der Artikel zeigt, wie die Fehlerbehandlung und -protokollierung auf der Grundlage des "Made and Forgot" -Prinzips in Go implementiert wird. Die Methode wurde für Microservices on Go entwickelt, die in einem Docker-Container arbeiten und den Prinzipien der Clean Architecture entsprechen.
Dieser Artikel ist eine detaillierte Version eines Berichts vom letzten Go-Treffen in Kasan . Wenn Sie sich für Go interessieren und in Kasan, Innopolis, im schönen Yoshkar-Ola oder in einer anderen Stadt in der Nähe wohnen, sollten Sie die Community-Seite besuchen: golangkazan.imtqy.com .
Während des Treffens zeigte unser Team in zwei Berichten, wie wir Microservices on Go entwickeln - welchen Prinzipien wir folgen und wie wir unser Leben vereinfachen. Dieser Artikel konzentriert sich auf unser Konzept der Fehlerbehandlung, das wir jetzt auf alle unsere neuen Mikrodienste ausweiten.
Microservice-Strukturvereinbarungen
Bevor wir auf die Regeln für die Fehlerbehandlung eingehen, sollten Sie entscheiden, welche Einschränkungen wir beim Entwerfen und Codieren beachten. Dazu lohnt es sich zu sagen, wie unsere Microservices aussehen.
Zuallererst respektieren wir saubere Architektur. Wir teilen den Code in drei Ebenen ein und beachten die Abhängigkeitsregel: Pakete auf einer tieferen Ebene sind unabhängig von externen Paketen und es gibt keine zyklischen Abhängigkeiten. Glücklicherweise sind direkte Round-Robin-Abhängigkeiten von Paketen in Go verboten. Indirekte Abhängigkeiten durch Ausleihterminologie, Annahmen über das Verhalten oder das Umwandeln in einen Typ können weiterhin auftreten. Sie sollten vermieden werden.
So sehen unsere Levels aus:
- Die Domänenebene enthält Geschäftslogikregeln, die vom Themenbereich vorgegeben werden.
- Manchmal verzichten wir auf Domain, wenn die Aufgabe einfach ist
- Regel: Code auf Domänenebene hängt nur von den Funktionen von Go, der Standard-Go-Bibliothek und ausgewählten Bibliotheken ab, die die Go-Sprache erweitern
- Die App-Schicht enthält Geschäftslogikregeln, die von den Aufgaben der Anwendung vorgegeben werden.
- Regel: Code auf App-Ebene kann von der Domain abhängen
- Die Infrastrukturebene enthält Infrastrukturcode, der die Anwendung mit verschiedenen Technologien für Speicher (MySQL, Redis), Transport (GRPC, HTTP), Interaktion mit der externen Umgebung und anderen Diensten verbindet
- Regel: Code auf Infrastrukturebene kann von Domäne und App abhängen
- Regel: Nur eine Technologie pro Go-Paket
- Das Hauptpaket erstellt alle Objekte - "Lifetime Singleton", verbindet sie miteinander und startet langlebige Coroutinen - beispielsweise beginnt es mit der Verarbeitung von HTTP-Anforderungen von Port 8081
So sieht der Microservice-Verzeichnisbaum aus (der Teil, in dem sich der Go-Code befindet):

Für jeden Anwendungskontext (Module) sieht die Paketstruktur folgendermaßen aus:
- Das App-Paket deklariert eine Service-Schnittstelle, die alle auf einer bestimmten Ebene möglichen Aktionen enthält, die die Service-Struktur-Schnittstelle und die Funktionsfunktion
func NewService(...) Service implementieren - Die Isolierung der Arbeit mit der Datenbank wird dadurch erreicht, dass das Domänen- oder App-Paket die Repository-Schnittstelle deklariert, die auf Infrastrukturebene im Paket mit dem visuellen Namen "mysql" implementiert ist.
- Der Transportcode befindet sich im
infrastructure/transport
- Wir verwenden GRPC, daher werden Server-Stubs aus der Protodatei generiert (d. h. Serverschnittstelle, Antwort- / Anforderungsstrukturen und der gesamte Client-Interaktionscode).
All dies ist im Diagramm dargestellt:

Prinzipien zur Fehlerbehandlung
Hier ist alles einfach:
- Wir glauben, dass Fehler und Panik auftreten, wenn Anforderungen an die API verarbeitet werden. Dies bedeutet, dass ein Fehler oder eine Panik nur eine Anforderung betreffen sollte
- Wir glauben, dass Protokolle nur für die Vorfallanalyse benötigt werden (und es gibt einen Debugger zum Debuggen). Daher werden Informationen zu Anforderungen im Protokoll empfangen und vor allem unerwartete Fehler bei der Verarbeitung von Anforderungen
- Wir glauben, dass eine ganze Infrastruktur für die Verarbeitung von Protokollen aufgebaut ist (zum Beispiel basierend auf ELK) - und der Microservice spielt dabei eine passive Rolle, indem er Protokolle an stderr schreibt
Wir werden uns nicht auf Panik konzentrieren: Vergessen Sie nur nicht, die Panik in jeder Goroutine und während der Verarbeitung jeder Anfrage, jeder Nachricht, jeder asynchronen Aufgabe, die von der Anfrage gestartet wird, zu behandeln. Fast immer kann Panik in einen Fehler umgewandelt werden, um zu verhindern, dass die gesamte Anwendung abgeschlossen wird.
Idiom Sentinel-Fehler
Auf der Ebene der Geschäftslogik werden nur erwartete Fehler verarbeitet, die durch Geschäftsregeln definiert sind. Sentinel-Fehler helfen Ihnen dabei, solche Fehler zu identifizieren. Wir verwenden diese Redewendung, anstatt unsere eigenen Datentypen für Fehler zu schreiben. Ein Beispiel:
package app import "errors" var ErrNoCake = errors.New("no cake found")
Hier wird eine globale Variable deklariert, die wir nach Zustimmung unseres Herrn nirgendwo ändern sollten. Wenn Sie globale Variablen nicht mögen und sie mit dem Linter erkennen, können Sie mit einigen Konstanten auskommen, wie Dave Cheney im Beitrag Konstantenfehler vorschlägt:
package app type Error string func (e Error) Error() string { return string(e) } const ErrNoCake = Error("no cake found")
Wenn Ihnen dieser Ansatz gefällt, möchten Sie möglicherweise den ConstError Typ zu Ihrer Go-Sprachbibliothek für Unternehmen hinzufügen.
Zusammensetzung der Fehler
Der Hauptvorteil von Sentinel-Fehlern ist die Möglichkeit, Fehler einfach zu komponieren. Insbesondere wenn ein Fehler erstellt oder ein Fehler von außen empfangen wird, ist es hilfreich, Stacktrace hinzuzufügen. Für solche Zwecke gibt es zwei beliebte Lösungen.
- xerrors-Paket, das in Go 1.13 als Experiment in die Standardbibliothek aufgenommen wird
- github.com/pkg/errors Paket von Dave Cheney
- Das Paket ist eingefroren und dehnt sich nicht aus, aber es ist trotzdem gut
Unser Team verwendet weiterhin github.com/pkg/errors und die errors.WithStack Funktionen (wenn wir nichts hinzufügen müssen, außer Stacktrace) oder errors.Wrap (wenn wir etwas zu diesem Fehler zu sagen haben). Beide Funktionen akzeptieren einen Fehler am Eingang und geben einen neuen Fehler zurück, jedoch mit Stacktrace. Beispiel aus der Infrastrukturschicht:
package mysql import "github.com/pkg/errors" func (r *repository) FindOne(...) { row := r.client.QueryRow(sql, params...) switch err := row.Scan(...) { case sql.ErrNoRows:
Wir empfehlen, jeden Fehler nur einmal zu verpacken. Dies ist einfach, wenn Sie die Regeln befolgen:
- Alle externen Fehler werden einmal in eines der Infrastrukturpakete eingeschlossen
- Alle durch Geschäftslogikregeln generierten Fehler werden zum Zeitpunkt der Erstellung durch Stacktrace ergänzt
Grundursache des Fehlers
Alle Fehler werden erwartungsgemäß in erwartete und unerwartete unterteilt. Um den erwarteten Fehler zu behandeln, müssen Sie die Auswirkungen der Komposition beseitigen. Die Pakete xerrors und github.com/pkg/errors alles, was Sie benötigen: Insbesondere das errors.Cause Funktion errors.Cause , die die Grundursache des Fehlers zurückgibt. Diese Funktion in einer Schleife ruft nacheinander frühere Fehler ab, während der nächste extrahierte Fehler die Fehlermethode Cause() error .
Ein Beispiel, mit dem wir die Grundursache extrahieren und direkt mit dem Sentinel-Fehler vergleichen:
func (s *service) SaveCake(...) error { state, err := s.repo.FindOne(...) if errors.Cause(err) == ErrNoCake { err = nil
Fehlerbehandlung beim Aufschieben
Möglicherweise verwenden Sie Linter, wodurch Sie alle Fehler manuell überprüfen können. In diesem Fall sind Sie wahrscheinlich wütend, wenn linter Sie .Close() , mit den .Close() -Methoden und anderen Methoden, die Sie nur defer .Close() , nach Fehlern zu .Close() . Haben Sie jemals versucht, den Fehler beim Aufschieben korrekt zu behandeln, insbesondere wenn zuvor ein anderer Fehler aufgetreten ist? Und wir haben versucht und haben es eilig, das Rezept zu teilen.
Stellen Sie sich vor, wir arbeiten ausschließlich mit Transaktionen in der Datenbank. Gemäß der Abhängigkeitsregel sollten die App- und Domänenebenen nicht direkt oder indirekt von der Infrastruktur und der SQL-Technologie abhängig sein. Dies bedeutet, dass auf App- und Domain-Ebene kein Wort "Transaktion" vorhanden ist .
Die einfachste Lösung besteht darin, das Wort "Transaktion" durch etwas Abstraktes zu ersetzen. So wird das Muster der Arbeitseinheit geboren. In unserer Implementierung empfängt der Service im App-Paket die Factory über die UnitOfWorkFactory-Schnittstelle und erstellt während jeder Operation ein UnitOfWork-Objekt, das die Transaktion verbirgt. Mit dem UnitOfWork-Objekt können Sie ein Repository abrufen.
Mehr zu UnitOfWorkSchauen Sie sich das Diagramm an, um die Verwendung von Arbeitseinheiten besser zu verstehen:
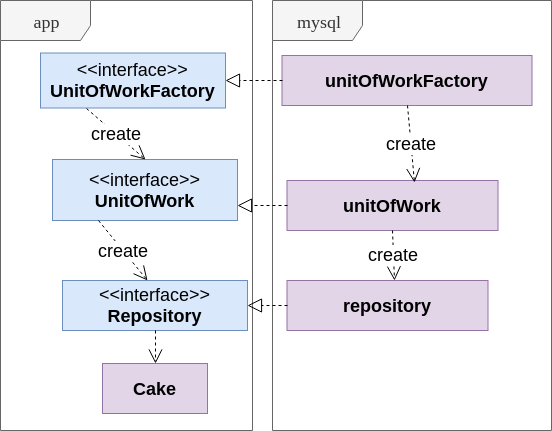
- Das Repository stellt eine abstrakte persistente Sammlung von Objekten (z. B. Aggregate auf Domänenebene) eines definierten Typs dar
- UnitOfWork versteckt die Transaktion und erstellt Repository-Objekte
- Mit UnitOfWorkFactory kann der Service einfach neue Transaktionen erstellen, ohne etwas über Transaktionen zu wissen.
Ist es nicht übertrieben, für jede Operation eine Transaktion zu erstellen, auch wenn diese zunächst atomar ist? Es liegt an dir; Wir glauben, dass die Wahrung der Unabhängigkeit der Geschäftslogik wichtiger ist als das Sparen beim Erstellen einer Transaktion.
Ist es möglich, UnitOfWork und Repository zu kombinieren? Es ist möglich, aber wir glauben, dass dies gegen das Prinzip der Einzelverantwortung verstößt.
So sieht die Benutzeroberfläche aus:
type UnitOfWork interface { Repository() Repository Complete(err *error) }
Die UnitOfWork-Schnittstelle bietet die Complete-Methode, die einen In-Out-Parameter verwendet: einen Zeiger auf die Fehlerschnittstelle. Ja, es ist der Zeiger und der In-Out-Parameter. In allen anderen Fällen ist der Code auf der aufrufenden Seite viel komplizierter.
Beispieloperation mit unitOfWork:
Achtung: Der Fehler muss als benannter Rückgabewert deklariert werden. Wenn Sie anstelle des genannten Rückgabewerts err die lokale Variable err verwenden, können Sie sie nicht in defer verwenden! Und noch kein einziger Linter wird dies erkennen - siehe Go-Kritiker # 801
func (s *service) CookCake() (err error) { unitOfWork, err := s.unitOfWorkFactory.New() if err != nil { return err } defer unitOfWork.Complete(&err) repo := unitOfWork.Repository() }
Damit ist die Fertigstellung realisiert Transaktionen UnitOfWork:
func (u *unitOfWork) Complete(err *error) { if *err == nil {
Die Funktion mergeErrors zwei Fehler zusammen, verarbeitet jedoch null ohne Probleme anstelle eines oder beider Fehler. Gleichzeitig glauben wir, dass beide Fehler während der Ausführung einer Operation in verschiedenen Phasen aufgetreten sind und der erste Fehler wichtiger ist. Wenn also beide Fehler nicht Null sind, speichern wir den ersten und vom zweiten Fehler nur die Nachricht:
package errors func mergeErrors(err error, nextErr error) error { if err == nil { err = nextErr } else if nextErr != nil { err = errors.Wrap(err, nextErr.Error()) } return err }
Vielleicht sollten Sie die Funktion mergeErrors zu Ihrer Unternehmensbibliothek für Go hinzufügen.
Protokollierungssubsystem
Artikel- Checkliste: Was Sie tun mussten, bevor Sie Microservices in Prod Advices starten :
- Protokolle werden in stderr geschrieben
- Protokolle sollten sich in JSON befinden, einem kompakten JSON-Objekt pro Zeile
- Es sollte einen Standardsatz von Feldern geben:
- Zeitstempel - Ereigniszeit in Millisekunden , vorzugsweise im RFC 3339-Format (Beispiel: "1985-04-12T23: 20: 50.52Z")
- level - Wichtigkeitsstufe, zum Beispiel "info" oder "error"
- Anwendungsname - Anwendungsname
- und andere Felder
Wir ziehen es vor, den Fehlermeldungen zwei weitere Felder hinzuzufügen: "error" und "stacktrace" .
Es gibt viele hochwertige Protokollierungsbibliotheken für die Golang-Sprache, zum Beispiel Sirupsen / Logrus , die wir verwenden. Wir nutzen die Bibliothek aber nicht direkt. Zunächst reduzieren wir in unserem log die übermäßig umfangreiche Bibliotheksschnittstelle auf eine Logger-Schnittstelle:
package log type Logger interface { WithField(string, interface{}) Logger WithFields(Fields) Logger Debug(...interface{}) Info(...interface{}) Error(error, ...interface{}) }
Wenn der Programmierer Protokolle schreiben möchte, muss er die Logger-Schnittstelle von außen beziehen. Dies sollte auf Infrastrukturebene erfolgen, nicht auf der Ebene der App oder Domäne. Die Logger-Oberfläche ist übersichtlich:
- Es reduziert die Anzahl der Schweregrade für Debugging, Informationen und Fehler, wie im Artikel empfohlen. Lassen Sie uns über die Protokollierung sprechen.
- Es werden spezielle Regeln für die Fehlermethode eingeführt: Die Methode akzeptiert immer ein Fehlerobjekt
Diese Strenge ermöglicht es, Programmierer in die richtige Richtung zu lenken: Wenn jemand das Protokollierungssystem selbst verbessern möchte, sollte er dies unter Berücksichtigung der gesamten Infrastruktur seiner Erfassung und Verarbeitung tun, die nur im Mikrodienst beginnt (und normalerweise irgendwo in Kibana und endet Zabbix).
Im Protokollpaket gibt es jedoch eine andere Schnittstelle, über die Sie das Programm unterbrechen können, wenn ein schwerwiegender Fehler auftritt, und die daher nur im Hauptpaket verwendet werden kann:
package log type MainLogger interface { Logger FatalError(error, ...interface{}) }
Jsonlog-Paket
Implementiert die Logger-Schnittstelle unseres jsonlog Pakets, das die Logrus-Bibliothek konfiguriert und die Arbeit damit abstrahiert. Sieht schematisch so aus:

Mit einem proprietären Paket können Sie die Anforderungen eines Mikrodienstes (ausgedrückt durch die log.Logger Schnittstelle), die Funktionen der logrus-Bibliothek und die Funktionen Ihrer Infrastruktur, die Protokollierung, verbinden.
Zum Beispiel verwenden wir ELK (Elastic Search, Logstash, Kibana) und daher im jsonlog-Paket:
- Legen Sie das Format
logrus.JSONFormatter für logrus.JSONFormatter
- Gleichzeitig setzen wir die FieldMap-Option, mit der wir das Feld
"time" in "@timestamp" und das Feld "msg" in "message" "@timestamp"
- Protokollstufe auswählen
- Fügen Sie einen Hook hinzu, der die Stapelverfolgung aus dem Fehlerobjekt extrahiert, das an die Methode
Error(error, ...interface{})
Der Microservice initialisiert den Logger in der Hauptfunktion:
func initLogger(config Config) (log.MainLogger, error) { logLevel, err := jsonlog.ParseLevel(config.LogLevel) if err != nil { return nil, errors.Wrap(err, "failed to parse log level") } return jsonlog.NewLogger(&jsonlog.Config{ Level: logLevel, AppName: "cookingservice" }), nil }
Fehlerbehandlung und Protokollierung mit Middleware
Wir wechseln in unseren Microservices on Go zu GRPC. Aber selbst wenn Sie die HTTP-API verwenden, sind die allgemeinen Prinzipien für Sie.
Zuallererst sollte die Fehlerbehandlung und -protokollierung auf infrastructure in dem für den Transport verantwortlichen Paket erfolgen, da er das Wissen über die Transportprotokollregeln und das Wissen über die Schnittstellenmethoden der app.Service . Erinnern Sie sich daran, wie die Paketbeziehung aussieht:

Es ist praktisch, Fehler zu verarbeiten und Protokolle mithilfe des Middleware-Musters zu verwalten (Middleware ist der Name des Decorator-Musters in der Welt von Golang und Node.js):
Wo kann man Middleware hinzufügen? Wie viele sollte es geben?
Sie haben verschiedene Möglichkeiten, Middleware hinzuzufügen:
- Sie können die
app.Service Schnittstelle dekorieren. app.Service wird jedoch nicht empfohlen, da diese Schnittstelle keine Informationen zur Transportschicht wie die Client-IP empfängt - Mit GRPC können Sie einen Handler an alle Anforderungen hängen (genauer gesagt zwei - unär und Steam), aber dann werden alle API-Methoden im selben Stil mit demselben Satz von Feldern protokolliert
- Mit GRPC erstellt der Codegenerator für uns eine Serverschnittstelle, in der wir die
app.Service Methode app.Service Wir dekorieren diese Schnittstelle, da sie Informationen auf Transportebene enthält und verschiedene API-Methoden auf unterschiedliche Weise protokollieren kann
Sieht schematisch so aus:

Sie können verschiedene Middlewares für die Fehlerbehandlung (und Panik) und für die Protokollierung erstellen. Sie können alles in einem kreuzen. Wir werden ein Beispiel betrachten, in dem alles in eine Middleware gekreuzt wird, die wie folgt erstellt wird:
func NewMiddleware(next api.BackendService, logger log.Logger) api.BackendService { server := &errorHandlingMiddleware{ next: next, logger: logger, } return server }
Wir erhalten die api.BackendService Schnittstelle als api.BackendService und dekorieren sie, wobei wir unsere Implementierung der api.BackendService Schnittstelle als api.BackendService .
Eine beliebige API-Methode in Middleware wird wie folgt implementiert:
func (m *errorHandlingMiddleware) ListCakes( ctx context.Context, req *api.ListCakesRequest) (*api.ListCakesResponse, error) { start := time.Now() res, err := m.next.ListCakes(ctx, req) m.logCall(start, err, "ListCakes", log.Fields{ "cookIDs": req.CookIDs, }) return res, translateError(err) }
Hier führen wir drei Aufgaben aus:
- Rufen Sie die ListCakes-Methode des dekorierten Objekts auf
- Wir
logCall Methode auf und übergeben ihr alle wichtigen Informationen, einschließlich eines individuell ausgewählten Satzes von Feldern, die in das Protokoll fallen - Am Ende ersetzen wir den Fehler durch den Aufruf von translateError.
Die Fehlerübersetzung wird später erläutert. Die logCall erfolgt über die logCall Methode, die einfach die richtige Logger-Schnittstellenmethode aufruft:
func (m *errorHandlingMiddleware) logCall(start time.Time, err error, method string, fields log.Fields) { fields["duration"] = fmt.Sprintf("%v", time.Since(start)) fields["method"] = method logger := m.logger.WithFields(fields) if err != nil { logger.Error(err, "call failed") } else { logger.Info("call finished") } }
Fehlerübersetzung
Wir müssen die Grundursache des Fehlers ermitteln und ihn in einen Fehler umwandeln, der auf Transportebene verständlich und in der API Ihres Dienstes dokumentiert ist.
In GRPC ist es einfach: Verwenden Sie die Funktion status.Errorf , um einen Fehler mit einem Statuscode zu erstellen. Wenn Sie über eine HTTP-API (REST-API) verfügen, können Sie einen eigenen Fehlertyp erstellen, den die App- und Domänenebenen nicht kennen sollten.
In erster Näherung sieht die Fehlerübersetzung folgendermaßen aus:
Bei der Überprüfung von Eingabeargumenten kann die dekorierte Schnittstelle einen Fehler vom Typ status.Status mit einem Statuscode zurückgeben, und die erste Version von translateError verliert diesen Statuscode.
Lassen Sie uns eine verbesserte Version erstellen, indem wir einen Schnittstellentyp verwenden (es lebe die Ententypisierung!):
type statusError interface { GRPCStatus() *status.Status } func isGrpcStatusError(er error) bool { _, ok := err.(statusError) return ok } func translateError(err error) error { if isGrpcStatusError(err) { return err } switch errors.Cause(err) { case app.ErrNoCake: err = status.Errorf(codes.NotFound, err.Error()) default: err = status.Errorf(codes.Internal, err.Error()) } return err }
Die Funktion translateError wird für jeden Kontext (unabhängiges Modul) in Ihrem Microservice einzeln erstellt und übersetzt Geschäftslogikfehler in Fehler auf Transportebene.
Zusammenfassend
Wir bieten Ihnen verschiedene Regeln für den Umgang mit Fehlern und das Arbeiten mit Protokollen. Ob Sie ihnen folgen oder nicht, liegt bei Ihnen.
- Befolgen Sie die Prinzipien der sauberen Architektur und brechen Sie nicht direkt oder indirekt die Abhängigkeitsregel. Die Geschäftslogik sollte nur von einer Programmiersprache und nicht von externen Technologien abhängen.
- Verwenden Sie ein Paket, das Fehlerkomposition und Stacktrace-Erstellung bietet. Zum Beispiel "github.com/pkg/errors" oder das xerrors-Paket, das bald Teil der Go-Standardbibliothek sein wird.
- Verwenden Sie keine Protokollierungsbibliotheken von Drittanbietern im Microservice. Erstellen Sie Ihre eigene Bibliothek mit den Paketen log und jsonlog, wodurch die Details der Protokollierungsimplementierung ausgeblendet werden
- Verwenden Sie das Middleware-Muster, um Fehler zu behandeln und Protokolle über die Transportrichtung der Infrastrukturebene des Programms zu schreiben
Hier haben wir nichts über Abfrageverfolgungstechnologien (z. B. OpenTracing), Metriküberwachung (z. B. Leistung von Datenbankabfragen) und andere Dinge wie die Protokollierung gesagt. Sie selbst werden sich darum kümmern, wir glauben an Sie.