In letzter Zeit wurde die Scala-Sprache von Data Science häufig verwendet. Es gewann Popularität vor allem durch das Aufkommen von Spark, das in Scala geschrieben ist. In der Praxis wird die Analyse und Erstellung des Modells häufig in der Forschungsphase in Python durchgeführt und dann in Scala implementiert, da diese Sprache für die Produktion besser geeignet ist.
Wir haben einen detaillierten Überblick über die interessantesten Bibliotheken erstellt, die zur Implementierung von maschinellem Lernen und datenwissenschaftlichen Aufgaben in Scala verwendet werden. Einige davon werden in unserem Bildungsprogramm " Data Analysis on Scala " verwendet.
Der Einfachheit halber wurden alle in der Bewertung vorgestellten Bibliotheken in fünf Gruppen unterteilt: Datenanalyse und Mathematik, NLP, Visualisierung, maschinelles Lernen und mehr.
Datenanalyse und Mathematik
Nr. 1. Breeze (Commits: 3316, Mitwirkende: 84)
Die Breeze-Bibliothek ist als primäre wissenschaftliche Bibliothek für Scala bekannt. Es hat ähnliche Dinge aus MATLAB (in Bezug auf Datenstrukturen) und aus Python, NumPy-Klassen. Breeze bietet eine schnelle und effiziente Bearbeitung von Datenarrays und ermöglicht Ihnen die Ausführung vieler anderer Vorgänge, einschließlich der folgenden:
- Matrix- und Vektoroperationen zum Erstellen, Transponieren, Ausführen elementweiser Operationen, Inversion, Berechnen von Determinanten und vielen anderen Dingen.
- Probabilistische und statistische Funktionen: von statistischen Verteilungen und der Berechnung deskriptiver Statistiken (wie Mittelwert, Varianz und Standardabweichung) bis hin zu Markov-Kettenmodellen. Die Hauptpakete für Statistiken sind Breeze.stats und Breeze.stats.distributions.
- Optimierung, bei der eine Funktion auf ein lokales oder globales Minimum untersucht wird. Optimierungsmethoden werden im Breeze.optimize-Paket gespeichert.
- Lineare Algebra: Alle grundlegenden Operationen basieren auf der Netlib-Java-Bibliothek, wodurch Breeze für algebraisches Rechnen extrem schnell ist.
- Signalverarbeitungsvorgänge. Beispiele für solche Operationen in Breeze sind Faltung und Fourier-Transformation, die diese Funktion in die Summe der Komponenten von Sinus und Cosinus aufteilen.
Es ist erwähnenswert, dass Sie mit Breeze auch Diagramme erstellen können, aber wir werden später darüber sprechen.
Nr. 2. Sattel (Commits: 184, Mitwirkende: 10)
Ein weiteres Datenwerkzeug für Scala ist Saddle. Dies ist ein Analogon zu Pandas in Python, jedoch nur für Scala. Wie Datenrahmen in Pandas oder R basiert Saddle auf einer Rahmenstruktur (zweidimensional indizierte Matrix).
Insgesamt gibt es fünf grundlegende Datenstrukturen:
Rahmen (2D indizierte Matrix)
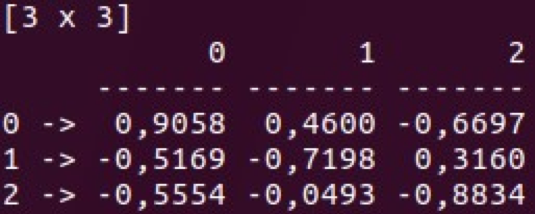
- Index (als Hashmap)
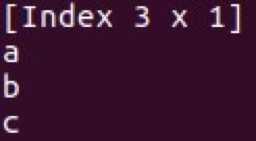
Die Klassen Vec und Mat befinden sich in Serie und Rahmen. Mit diesen Datenstrukturen können Sie verschiedene Manipulationen durchführen und diese für die grundlegende Datenanalyse verwenden. Ein weiteres großartiges Merkmal von Saddle ist seine Beständigkeit gegen Datenlücken.
Nummer 3. ScalaLab (Commits: 23, Mitwirkende: 1)
ScalaLab ist eine Art MATLAB in Scala. Darüber hinaus kann ScalaLab MATLAB-Skriptergebnisse direkt aufrufen und darauf zugreifen.
Der Hauptunterschied zu früheren Computerbibliotheken besteht darin, dass ScalaLab eine eigene domänenspezifische Sprache namens ScalaSci verwendet. Scalalab ist praktisch, da es auf viele wissenschaftliche Bibliotheken von Java und Scala zugreift, sodass Sie Ihre Daten einfach importieren und dann verschiedene Methoden verwenden können, um Manipulationen und Berechnungen durchzuführen. Die meisten Dinge ähneln Breeze und Saddle. Darüber hinaus gibt es wie in Breeze Diagramme, mit denen Sie die Daten weiter interpretieren können.
Nlp
Nummer 4. Epic (Commits: 1790, Contributors: 15) und Puck (Commits: 536, Contributors: 1)
Scala verfügt im Rahmen von ScalaNLP über einige gute Bibliotheken zur Verarbeitung natürlicher Sprache, darunter Epic und Puck. Diese Bibliotheken werden hauptsächlich als Textanalysewerkzeuge verwendet. Gleichzeitig ist Puck aufgrund seiner hohen Geschwindigkeit und der Verwendung einer GPU bequemer, wenn Sie Tausende von Angeboten analysieren müssen. Epic ist auch als Prognose-Framework bekannt, das strukturierte Prognosen verwendet , um komplexe Systeme zu erstellen.
Visualisierung
Nr. 5. Breeze-viz (Commits: 29, Mitwirkende: 3)
Wie der Name schon sagt, ist Breeze-viz eine Visualisierungsbibliothek, die von Breeze für Scala entwickelt wurde. Es basiert auf der bekannten Java-Bibliothek JFreeChart und das Diagramm ähnelt MATLAB. Obwohl Breeze-viz viel weniger Funktionen als MATLAB, matplotlib in Python oder R hat, ist es dennoch nützlich, um Modelle zu erstellen und Daten zu analysieren.
Nr. 6. Vegas (Commits: 210, Mitwirkende: 14)
Eine weitere Scala-Datenvisualisierungsbibliothek ist Vegas. Es ist viel funktionaler als Breeze-viz und ermöglicht es Ihnen, einige Transformationen vorzunehmen, die für Diagramme nützlich sind: Filtern, Transformationen und Aggregationen. Im Allgemeinen ähnelt die Bibliothek Bokeh und Plotly in Python.
In Vegas können Sie Code in einem deklarativen Stil schreiben, wodurch Sie sich hauptsächlich darauf konzentrieren können, zu bestimmen, was mit den Daten zu tun ist, und weitere Analysen von Visualisierungen durchzuführen, ohne sich um die Implementierung des Codes kümmern zu müssen.

Maschinelles Lernen
Nummer 7. Lächeln (Commits: 1019, Mitwirkende: 21)
Die Statistical Machine Intelligence and Learning Engine oder einfach Smile ist eine vielversprechende moderne Bibliothek für maschinelles Lernen, die dem Scikit-Lernen in Python ähnelt. Es wurde in Java entwickelt, verfügt aber auch über eine API für Scala. Die Bibliothek ist recht schnell und produktiv: effiziente Speichernutzung, eine große Anzahl von Algorithmen für maschinelles Lernen zur Klassifizierung, Regression, NNS, Funktionsauswahl usw.

Nummer 8. Spark ML
Eine maschinelle Lernbibliothek, die in Apache Spark sofort funktioniert. Spark selbst ist in Scala geschrieben und verfügt über eine entsprechende API für alle seine Bibliotheken.
Spark ML - Im Gegensatz zu Spark MLlib (einer älteren Bibliothek) funktioniert es mit Datenrahmen. Es ermöglicht auch das Erstellen von Pipelines mit verschiedenen Transformationen für Ihre Daten. Dies kann als eine Folge von Stufen betrachtet werden, wobei jede Stufe entweder ein Transformator ist, der einen Datenrahmen in einen anderen umwandelt, oder ein Schätzer, beispielsweise ein Algorithmus für maschinelles Lernen, der auf einem Datenrahmen trainiert wird.
Nr. 9. DeepLearning.scala (Commits: 1647, Mitwirkende: 14)
DeepLearning.scala ist ein alternatives Tool für maschinelles Lernen, mit dem Sie Deep-Learning-Modelle erstellen können. Die Bibliothek verwendet mathematische Formeln, um komplexe dynamische neuronale Netze durch eine Kombination aus objektorientierter und funktionaler Programmierung zu erstellen. Es verwendet eine breite Palette von Typen sowie Klassen von Anwendungstypen. Mit letzterem können Sie mehrere Berechnungen gleichzeitig starten, wodurch die Produktivität verbessert wird.
Nr. 10. Summing Bird (Commits: 1772, Mitwirkende: 31)
Summingbird ist ein Datenverarbeitungsframework, das die Verwendung von Batch- und Echtzeit-MapReduce-Berechnungen ermöglicht. Der Hauptkatalysator für die Entwicklung der Sprache waren Twitter-Entwickler, die oft zweimal denselben Code schrieben: zuerst für die Batche-Verarbeitung, dann wieder für das Streaming.
Summingbird verwendet und generiert zwei Arten von Daten: Streams (unendliche Folgen von Tupeln) und Snapshots, die zu einem bestimmten Zeitpunkt als vollständiger Status des Datensatzes betrachtet werden. Schließlich bietet Summingbird eine Plattform für Storm, Scalding und eine Speicher-Engine zu Testzwecken.
Nr. 11. PredictionIO (Commits: 4343, Mitwirkende: 125)
Erwähnenswert ist auch der maschinelle Lerndienst zum Erstellen und Bereitstellen von Vorhersagemechanismen namens PredictionIO. Es basiert auf Apache Spark MLlib und HBase und wurde sogar auf Github als das beliebteste maschinelle Lernprodukt basierend auf Apache Spark bewertet. Sie können damit einfach, effizient Services erstellen, bewerten und bereitstellen, Ihre eigenen Modelle für maschinelles Lernen implementieren und diese in Ihren Service integrieren.
Andere
Nr. 12. Akka (Commits: 21430, Mitwirkende: 467)
Akka wurde von Scala entwickelt und ist eine parallele Umgebung zum Erstellen verteilter JVM-Anwendungen. Es wird ein akteursbasiertes Modell verwendet, bei dem ein Akteur ein Objekt ist, das Nachrichten empfängt und entsprechende Aktionen ausführt.
Der Hauptunterschied ist die zusätzliche Ebene zwischen den Akteuren und dem Framework, bei der nur die Akteure Nachrichten verarbeiten müssen, während sich das Framework um alles andere kümmert. Alle Akteure sind hierarchisch organisiert. Dies hilft den Akteuren, effektiver miteinander zu interagieren, komplexe Probleme zu lösen und sie in kleinere Aufgaben zu unterteilen.
Nr. 13. Slick (Commits: 1940, Mitwirkende: 92)
Die neueste Bibliothek ist Slick, dh das Scala Language-Integrated Connection Kit. Dies ist eine Bibliothek zum Erstellen und Ausführen von Datenbankabfragen: H2, MySQL, PostgreSQL usw. Einige Datenbanken sind über Slick-Erweiterungen verfügbar.
Zum Erstellen von Abfragen bietet Slick ein leistungsstarkes DSL, das den Code so erstellt, als ob Sie Scala-Sammlungen verwenden würden. Slick unterstützt sowohl einfache SQL-Abfragen als auch stark typisierte Verknüpfungen mehrerer Tabellen. Darüber hinaus können einfache Unterabfragen verwendet werden, um komplexere zu erstellen.
Fazit
In diesem Artikel haben wir einige Scala-Bibliotheken identifiziert und kurz beschrieben, die bei der Ausführung grundlegender Datenverarbeitungsaufgaben sehr nützlich sein können.
Wenn Sie Erfahrung mit anderen nützlichen Scala-Bibliotheken oder -Plattformen haben, die es wert sind, dieser Liste hinzugefügt zu werden, können Sie diese gerne in den Kommentaren veröffentlichen.