
Eintrag
In den Jahren der Entwicklung von ML- und DL-Projekten hat unser Studio eine große Codebasis, viel Erfahrung sowie interessante Erkenntnisse und Schlussfolgerungen gesammelt. Wenn Sie ein neues Projekt starten, können Sie mit diesem nützlichen Wissen sicherer mit der Forschung beginnen, nützliche Methoden wiederverwenden und schneller erste Ergebnisse erzielen.
Es ist sehr wichtig, dass all diese Materialien nicht nur in den Köpfen der Entwickler sind, sondern auch in lesbarer Form auf der Festplatte. Dies ermöglicht eine effektivere Schulung neuer Mitarbeiter, bringt sie auf den neuesten Stand und taucht sie in das Projekt ein.
Dies war natürlich nicht immer der Fall. Wir hatten in der Anfangsphase viele Probleme
- Jedes Projekt war anders organisiert, insbesondere wenn sie von verschiedenen Personen initiiert wurden.
- Sie haben nicht nachverfolgt, was der Code tat, wie er ausgeführt wurde und wer der Autor war.
- Sie nutzten die Virtualisierung nicht in angemessenem Umfang und hinderten ihre Kollegen häufig daran, vorhandene Bibliotheken einer anderen Version zu installieren.
- Die Schlussfolgerungen aus den Karten, die sich im Berg der Jupiter-Notizbücher niederließen und starben, wurden vergessen.
- Verlorene Berichte über die Ergebnisse und den Fortschritt im Projekt.
Um diese Probleme ein für alle Mal zu lösen, haben wir beschlossen, sowohl an einer einheitlichen und ordnungsgemäßen Organisation des Projekts als auch an der Virtualisierung, Abstraktion einzelner Komponenten und Wiederverwendung von nützlichem Code zu arbeiten. Allmählich entwickelten sich alle unsere Fortschritte in diesem Bereich zu einem unabhängigen Rahmen - dem Ozean.
Kirsche auf dem Kuchen - die Projektprotokolle, die aggregiert und in eine schöne Site verwandelt werden, werden automatisch mit einem Befehl gesammelt.
In diesem Artikel werden wir Ihnen anhand eines kleinen künstlichen Beispiels erläutern, aus welchen Teilen Ocean besteht und wie es verwendet wird.
Warum Ozean
In der Welt von ML gibt es andere Optionen, die wir in Betracht gezogen haben. Zunächst müssen wir die Cookiecutter-Data-Science (im Folgenden: CDS) als ideologischen Inspirator erwähnen. Beginnen wir mit dem Guten: CDS bietet nicht nur eine praktische Projektstruktur, sondern erklärt auch, wie das Projekt so verwaltet wird, dass alles in Ordnung ist. Wir empfehlen daher, dass Sie abschweifen und die wichtigsten Ideen dieses Ansatzes im ursprünglichen CDS-Artikel betrachten .
Mit CDS im Arbeitsentwurf ausgestattet, haben wir sofort einige Verbesserungen vorgenommen: Wir haben einen praktischen Dateilogger, eine Koordinatorklasse, die für die Navigation im Projekt verantwortlich ist, und einen automatischen Generator für die Sphinx-Dokumentation hinzugefügt. Darüber hinaus wurden mehrere Befehle an das Makefile gesendet, so dass selbst ein in die Details des Projektmanagers nicht eingeweihter Benutzer diese bequem ausführen konnte.
Dabei zeigten sich jedoch die Nachteile des CDS-Ansatzes:
- Der Datenordner kann wachsen, aber welches der Skripte oder Notizbücher die nächste Datei generiert, ist nicht vollständig klar. In einer großen Anzahl von Dateien kann es leicht zu Verwirrung kommen. Es ist nicht klar, ob im Rahmen der Implementierung der neuen Funktionalität einige Dateien aus den vorhandenen verwendet werden müssen, da die Beschreibung oder Dokumentation zu ihrem Zweck nirgendwo gespeichert wird.
- In Daten gibt es nicht genügend Unterordner für Features, in denen Sie Zeichen speichern können: berechnete Statistiken, Vektoren und andere Merkmale, aus denen unterschiedliche endgültige Darstellungen der Daten erfasst werden. Dies wurde bereits in einem Blog-Beitrag bemerkenswert geschrieben.
- src ist ein weiterer Problemordner. Es verfügt über Funktionen, die für das gesamte Projekt relevant sind, z. B. das Vorbereiten und Bereinigen der Daten des src.data- Moduls. Es gibt aber auch das Modul src.models , das alle Modelle aus allen Experimenten enthält, und es kann Dutzende davon geben. Infolgedessen wird src sehr oft aktualisiert und mit sehr geringfügigen Änderungen erweitert. Gemäß der CDS-Philosophie muss das Projekt nach jedem Update neu erstellt werden. Dies ist auch die Zeit ..., - na ja, Sie verstehen.
- Referenzen werden vorgestellt, aber es gibt noch eine offene Frage: Wer, wann und in welcher Form soll die Materialien dorthin bringen. Und Sie können im Verlauf des Projekts viel erzählen: Welche Arbeit wurde geleistet, was ist ihr Ergebnis, was sind die Zukunftspläne.
Um die oben genannten Probleme zu lösen, wird in Ocean die folgende Essenz vorgestellt: Experiment . Ein Experiment ist ein Repository aller Daten, die zum Testen einer Hypothese erforderlich sind. Dies kann Folgendes umfassen: Welche Daten wurden verwendet, welche Daten (Artefakte) entstanden, die Version des Codes, die Start- und Endzeit des Experiments, die ausführbare Datei, Parameter, Metriken und Protokolle. Einige dieser Informationen können mithilfe spezieller Dienstprogramme, z. B. MLFlow, verfolgt werden. Die Struktur der in Ocean vorgestellten Experimente ist jedoch reicher und flexibler.
Das Modul eines Experiments ist wie folgt:
<project_root> └── experiments ├── exp-001-Tree-models │ ├── config <- yaml- │ ├── models <- │ ├── notebooks <- │ ├── scripts <- , , train.py predict.py │ ├── Makefile <- │ ├── requirements.txt <- │ └── log.md <- │ ├── exp-002-Gradient-boosting ...
Wir teilen die Codebasis: Wiederverwendbarer guter Code, der während des gesamten Projekts relevant ist, verbleibt im src- Modul der Projektebene. Es wird selten aktualisiert, so dass Sie seltener ein Projekt erstellen müssen. Das Skriptmodul eines Experiments sollte Code enthalten, der nur für das aktuelle Experiment relevant ist. Daher kann es häufig geändert werden: Es hat keinen Einfluss auf die Arbeit von Kollegen in anderen Experimenten.
Betrachten wir die Möglichkeiten unseres Frameworks am Beispiel eines abstrakten ML / DL-Projekts.
Projektworkflow
Initialisierung
Der Kunde - die Polizei von Chicago - hat uns die Daten und die Aufgabe hochgeladen: die in der Stadt zwischen 2011 und 2017 begangenen Verbrechen zu analysieren und Schlussfolgerungen zu ziehen.
Fangen wir an! Wir gehen zum Terminal und führen den Befehl aus:
ocean project new -n Crimes
Das Framework hat den entsprechenden Ordner für das Verbrechensprojekt erstellt . Wir betrachten seine Struktur:
crimes ├── crimes <- src- , ├── config <- , ├── data <- ├── demos <- ├── docs <- Sphinx- ├── experiments <- ├── notebooks <- EDA ├── Makefile <- ├── log.md <- ├── README.md └── setup.py
Der Koordinator des gleichnamigen Moduls, der bereits geschrieben und bereit ist, hilft beim Navigieren in all diesen Ordnern. Um es zu verwenden, muss das Projekt zusammengestellt werden:
make package
Dies ist ein Fehler : Wenn make-Befehle nicht ausgeführt werden sollen, fügen Sie ihnen das Flag -B hinzu, z. B. "make -B package". Dies gilt für alle weiteren Beispiele.
Protokolle und Experimente
Wir beginnen mit der Tatsache, dass die Kundendaten , in unserem Fall die Datei Crime.csv , im Ordner data / raw abgelegt werden.
Auf der Chicago-Website finden Sie Karten mit Stadtunterteilungen in Pfosten („Beats“ - der kleinste Ort, für den ein Streifenwagen zugewiesen ist), Sektoren („Sektoren“, bestehend aus 3-5 Pfosten), Abschnitte („Bezirke“) 3 Sektoren), Verwaltungsbezirke („Bezirke“) und schließlich öffentliche Bereiche („Gemeindebereich“). Diese Daten können zur Visualisierung verwendet werden. Gleichzeitig sind JSON-Dateien mit den Koordinaten der Polygonabschnitte jedes Typs keine vom Kunden gesendeten Daten, daher legen wir sie in data / external ab .
Als nächstes müssen Sie das Konzept des Experiments einführen. Alles ist einfach: Wir betrachten eine separate Aufgabe als separates Experiment. Müssen Sie Daten analysieren / pumpen und für die zukünftige Verwendung vorbereiten? Es lohnt sich, ein Experiment durchzuführen. Viele Visualisierungen und Berichte vorbereiten? Separates Experiment. Testen Sie die Hypothese, indem Sie ein Modell erstellen? Nun, du verstehst, worum es geht.
Um unser erstes Experiment aus dem Projektordner zu erstellen, führen wir Folgendes aus:
ocean exp new -n Parsing -a ivanov
Jetzt ist ein neuer Ordner mit dem Namen exp-001-Parsing im Ordner " Verbrechen / Experimente " erschienen, dessen Struktur oben angegeben ist.
Danach müssen Sie sich die Daten ansehen. Erstellen Sie dazu einen Laptop im entsprechenden Notizbuchordner . In Surf folgen wir der Bezeichnung "Laptop-Nummer - Name", und der erstellte Laptop heißt 001-Parse-data.ipynb . Im Inneren werden wir Daten für die weitere Arbeit vorbereiten.
Datenvorbereitungscode import numpy as np import pandas as pd pd.options.display.max_columns = 100
Damit Ihre Kollegen wissen, was Sie getan haben und ob Ihre Ergebnisse von ihnen verwendet werden können, müssen Sie dies im Protokoll kommentieren: in der Datei log.md. Die Struktur des Protokolls (das im Wesentlichen eine bekannte Markdown-Datei ist) ist wie folgt:

Die von Hand gefüllten Teile werden farblich hervorgehoben. Das Hauptmeta des Experiments (helle Pflaumenfarbe) ist der Autor und die Erklärung seiner Aufgabe, das Ergebnis, zu dem das Experiment geht. Links zu Daten, die während des Prozesses erfasst und generiert wurden (grüne Farbe), helfen dabei, Datendateien zu überwachen und zu verstehen, wer, in was und warum sie verwendet. Das Protokoll selbst (gelbe Farbe) gibt das Ergebnis der Arbeit, Schlussfolgerungen und Überlegungen an. Alle diese Daten werden später zum Inhalt der Projektprotokoll-Site.
Als nächstes folgt die EDA-Phase ( Exploratory Data Analysis - „Intelligence Data Analysis“ ). Vielleicht wird es von verschiedenen Personen durchgeführt, und natürlich benötigen wir später Ergebnisse in Form von Berichten und Grafiken. Diese Argumente sind eine Gelegenheit, ein neues Experiment zu erstellen. Wir führen aus:
ocean exp new -n Eda -a ivanov
Erstellen Sie im Notizbuchordner des Experiments das Notizbuch 001-EDA.ipynb . Vollständiger Code ist nicht sinnvoll, wird aber beispielsweise von Ihren Kollegen nicht benötigt. Aber Sie brauchen Grafiken und Schlussfolgerungen. Im Notebook wird viel Code ausgegeben, und es ist nicht das, was man dem Kunden zeigen möchte. Daher werden wir unsere Funde und Erkenntnisse in der Datei log.md aufzeichnen und die Bilder der Grafiken in Referenzen speichern.
Hier ist zum Beispiel eine Karte der sicheren Gebiete von Chicago, wenn das Schicksal Sie dorthin bringt:
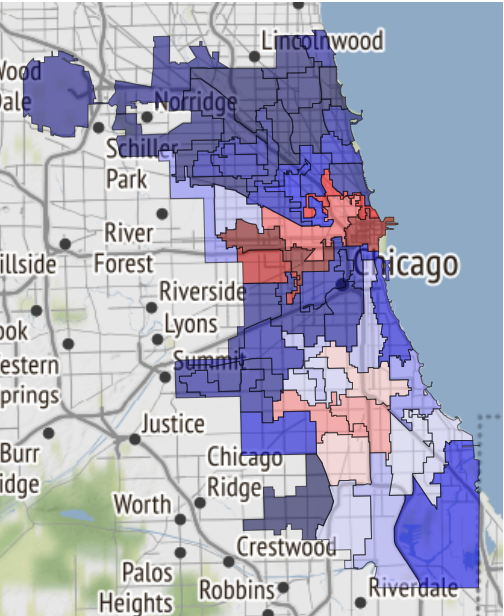
Es wurde gerade in einem Notizbuch empfangen und auf Referenzen übertragen .
Der folgende Eintrag wurde dem Protokoll hinzugefügt:
19.02.2019, 18:15 EDA conclusion: * The most common and widely spread crimes are theft (including burglary), battery and criminal damage done with firearms. * In 1 case out of 4 the suspect will be set free after detention. [!Criminal activity in different beats of the city](references/beats_activity.jpg) Actual exploration you can check in [the notebook](notebooks/001-Eda.ipynb)
Bitte beachten Sie: Das Diagramm ist wie das Einfügen eines Bildes in eine MD-Datei gestaltet. Wenn Sie einen Link zum Notizbuch hinterlassen, wird dieser in das HTML-Format konvertiert und als separate Seite auf der Website gespeichert.
Um es aus den Protokollen der Experimente zu sammeln, führen wir den folgenden Befehl auf Projektebene aus:
ocean log new
Danach wird der Ordner krimin / project_log erstellt und index.html darin ist das Projektprotokoll.
Dies ist ein Fehler : Wenn die Site in Jupyter angezeigt wird, wird sie aus Gründen der Sicherheit als Iframe implementiert, sodass Schriftarten nicht korrekt angezeigt werden. Mit Ocean können Sie daher sofort ein Archiv mit einer Kopie der Site erstellen, sodass Sie diese bequem herunterladen und auf einem lokalen Computer öffnen oder per E-Mail senden können. So:
ocean log archive [-n NAME] [-p PASSWORD]
Die Dokumentation
Werfen wir einen Blick auf die Gebäudedokumentation mit Sphinx. Erstellen Sie eine Funktion in der Datei Verbrechen / my_cool_module.py und dokumentieren Sie diese. Beachten Sie, dass Sphinx das reStructured Text- Format (RST) verwendet:
my_cool_module.py def my_super_cool_random(max_value): ''' Returns a random number from [0; max_value) interval. Considers the number to be taken from uniform distribution. :param max_value: Maximum value that defines range. :returns: Random number. ''' return 4
Und dann ist alles ganz einfach: Auf Projektebene führen wir das Dokumentationsgenerierungsteam aus, und Sie sind bereit:
ocean docs new
Frage des Publikums : Warum müssen Sie, wenn wir das Projekt über make gesammelt haben, Dokumentation über den ocean sammeln?
Antwort : Der Dokumentationsgenerierungsprozess ist nicht nur die Ausführung des Sphinx-Befehls, der in make platziert werden kann. Ocean übernimmt das Scannen des Katalogs Ihrer Quellcodes, erstellt daraus einen Index für Sphinx, und erst dann macht sich Sphinx selbst an die Arbeit.
Auf dem Weg Verbrechen / docs / _build / html / index.html erwartet Sie eine vorgefertigte HTML-Dokumentation. Und unser Modul mit Kommentaren ist dort bereits erschienen:

Modelle
Der nächste Schritt ist das Erstellen des Modells. Wir führen aus:
ocean exp new -n Model -a ivanov
Schauen Sie sich diesmal an, was sich im Skriptordner des Experiments befindet. Die Datei train.py ist leer für den zukünftigen Trainingsprozess. Die Datei enthält bereits den Boilerplate-Code, der mehrere Aufgaben gleichzeitig erledigt.
- Die Lernfunktion verwendet mehrere Dateipfade:
- In die Konfigurationsdatei, in die es sinnvoll ist, die Modellparameter, Trainingsparameter und andere Optionen, die bequem von außen gesteuert werden können, zu übertragen, ohne sich mit dem Code zu befassen.
- Zur Datendatei.
- Der Pfad zu dem Verzeichnis, in dem Sie den endgültigen Modellspeicherauszug speichern möchten.
- Verfolgt die im Lernprozess erhaltenen Metriken in mlflow . Alles, was dazu aufgefordert wurde, kann über die Benutzeroberfläche mlflow angezeigt werden, indem der Befehl
make dashboard im Experimentordner ausgeführt wird. - Sendet eine Benachrichtigung an Ihr Telegramm, dass der Lernprozess abgeschlossen wurde. Um diesen Mechanismus zu implementieren, wurde der Alarmerbot- Bot verwendet . Damit dies funktioniert, müssen Sie einige Schritte ausführen : Senden Sie den Befehl / start an den Bot und übertragen Sie das vom Bot ausgegebene Token in die Datei Crime / config / alarm_config.yml . Die Zeichenfolge kann folgendermaßen aussehen:
ivanov: a5081d-1b6de6-5f2762 - Es wird von der Konsole aus gesteuert.
Warum unser Skript von der Konsole aus verwalten? Alles ist so organisiert, dass der Prozess des Lernens oder Erhaltens von Vorhersagen eines Modells leicht von einem Drittentwickler organisiert werden kann, der mit den Details der Implementierung Ihres Experiments nicht vertraut ist. Damit alle Teile des Puzzles nach dem Entwurf von train.py zusammenpassen, müssen Sie das Makefile anordnen. Es enthält einen leeren Zugbefehl, und Sie müssen nur die Pfade zu den oben aufgeführten erforderlichen Konfigurationsdateien korrekt festlegen und alle, die Telegrammwarnungen erhalten möchten, im Parameterwert Benutzername auflisten. Insbesondere funktioniert der Alias all , wodurch eine Warnung an alle Teammitglieder gesendet wird.
Sobald alles fertig ist, beginnt unser Experiment einfach und elegant mit dem make train .
Wenn Sie die neuronalen Netze anderer Personen verwenden möchten, helfen virtuelle Umgebungen ( venv ). Das Erstellen und Löschen als Teil eines Experiments ist sehr einfach:
ocean env new schafft eine neue Umgebung. Es ist nicht nur standardmäßig aktiv, sondern erstellt auch einen zusätzlichen Kernel (Kernel) für Notebooks und für weitere Recherchen. Es wird auf die gleiche Weise wie der Name des Experiments aufgerufen.ocean env list zeigt eine Liste der Kerne an.ocean env delete im Experiment erstellte Umgebung.
Was fehlt?
- Ozean ist nicht mit conda befreundet (
weil wir es nicht benutzen ) - Projektvorlage nur in Englisch.
- Das Problem der Lokalisierung gilt weiterhin für die Site: Bei der Erstellung des Projektprotokolls wird davon ausgegangen, dass alle Protokolle in englischer Sprache vorliegen.
Fazit
Der Quellcode des Projekts liegt hier .
Wenn Sie interessiert sind - großartig! Weitere Informationen finden Sie in der README-Datei im Ocean-Repository .
Und wie in solchen Fällen normalerweise gesagt wird, sind Beiträge willkommen. Wir freuen uns nur, wenn Sie an der Verbesserung des Projekts teilnehmen.