Hallo liebe Leser! In diesem Artikel möchte ich über die Architektur meines Projekts sprechen, das ich beim Start viermal überarbeitet habe, da ich mit dem Ergebnis nicht zufrieden war. Ich werde über die Nachteile populärer Ansätze sprechen und meine eigenen zeigen.
Ich möchte sofort sagen, dass dies mein erster Artikel ist, ich sage nicht, was ich tun soll - richtig. Ich möchte nur zeigen, was ich getan habe, erzählen, wie ich zum Endergebnis gekommen bin, und vor allem - die Meinungen anderer einholen.
Ich habe in mehreren Kampagnen gearbeitet und eine Menge von allem gesehen, was ich anders gemacht hätte.
Zum Beispiel sehe ich oft eine N-Layer-Architektur, es gibt eine Schicht für die Arbeit mit Daten (DA), es gibt eine Schicht mit Geschäftslogik (BL), die mit DA und möglicherweise einigen anderen Diensten arbeitet, und es gibt auch eine Ansichtsebene \ API, in der Eine Anfrage wird empfangen und mit BL verarbeitet. Es scheint praktisch, aber wenn ich mir den Code ansehe, sehe ich diese Situation:
- [DA] zieht \ schreibt \ ändert Daten, auch wenn eine komplexe Abfrage - OK
- [BL] 80% ruft 1 Methode auf und würfelt das obige Ergebnis - Warum diese leere Ebene?
- [Anzeigen] 80% Aufrufe 1 BL-Methode wirft das obige Ergebnis - Warum diese leere Ebene?
Darüber hinaus ist es in Mode, Schnittstellen einzuschließen, damit Sie später sperren und testen können - wow, einfach wow!
- Warum nass werden?
- Nun, um Nebenwirkungen für die Dauer der Tests zu reduzieren.
- Das heißt, wir werden ohne Nebenwirkungen protestieren, aber mit ihnen?
...
Dies ist eine grundlegende Sache, die mir in dieser Architektur nicht gefallen hat, da das Lösen eines Problems wie "Benutzerlikes auflisten" ein großer Prozess ist, aber in Wirklichkeit gibt es 1 Abfrage in der Datenbank und möglicherweise eine Zuordnung.
Probenlösung1) [DA] Anfrage zu DA hinzufügen
2) [BL] DA-Antwort weiterleiten
3) [Anzeigen] BA-Ergebnis weiterleiten, kann fördern
Vergessen Sie nicht, dass all diese Methoden noch zur Benutzeroberfläche hinzugefügt werden müssen. Wir schreiben ein Projekt, um nass zu werden, und nicht für eine Lösung.
An anderer Stelle sah ich eine API-Implementierung mit einem CQRS-Ansatz.
Die Lösung sah nicht schlecht aus, 1 Ordner - 1 Funktion. Ein Entwickler, der ein Feature erstellt, befindet sich in seinem Ordner und kann fast immer den Einfluss seines Codes auf andere Features vergessen, aber es gab so viele Dateien, dass es nur ein Albtraum war. Anforderungs- / Antwortmodelle, Validatoren, Helfer, Logik selbst. Die Suche im Studio weigerte sich praktisch zu arbeiten, es wurden Erweiterungen hinzugefügt, um die notwendigen Dinge im Code zu finden.
Es gibt noch viel mehr zu sagen, aber ich habe die Hauptgründe hervorgehoben, warum ich es abgelehnt habe
Und schließlich zu meinem Projekt
Wie gesagt, ich habe mein Projekt mehrmals überarbeitet, in diesem Moment hatte ich eine „Programmierer-Depression“, war einfach nicht zufrieden mit meinem Code und habe ihn immer wieder überarbeitet. Am Ende habe ich mir ein Video über die Architektur der Anwendung angesehen, um zu sehen, wie andere tun es. Ich stieß auf Anton Moldovans Berichte über DDD und funktionale Programmierung und dachte: „Hier ist es, ich brauche F #!“.
Nachdem ich ein paar Tage mit F # verbracht hatte, wurde mir klar, dass ich im Prinzip dasselbe in C # machen würde und nicht schlechter. Das Video zeigte:
- Hier ist der C # -Code, es ist Scheiße
- Hier ist F # cool, weniger geschrieben - super.
Der Trick ist jedoch, dass die Lösung für F # anders implementiert wurde und dagegen eine schlechte Implementierung für C # gezeigt wurde. Das Hauptprinzip war, dass BL keine Sache ist, die DA-Dienste aufruft und die ganze Arbeit erledigt, sondern eine reine Funktion ist .
Natürlich ist F # gut, ich mochte einige Funktionen, aber wie C # ist dies nur ein Werkzeug, das auf verschiedene Arten verwendet werden kann.
Und ich ging zurück zu C # und fing an zu kreieren.
Ich habe solche Projekte in der Lösung erstellt:
- API
- Kern
- Dienstleistungen
- Tests
Ich habe auch C # 8-Funktionen verwendet, insbesondere den nullbaren Referenztyp. Ich werde seine Anwendung zeigen.
Kurz über die Aufgaben der Schichten, die ich ihnen gegeben habe.
API
1) Empfangen von Anfragen, Anforderungsmodellen + Validierung, Einschränkungen
2) Aufrufen von Funktionen von Core and Services
Weitere Details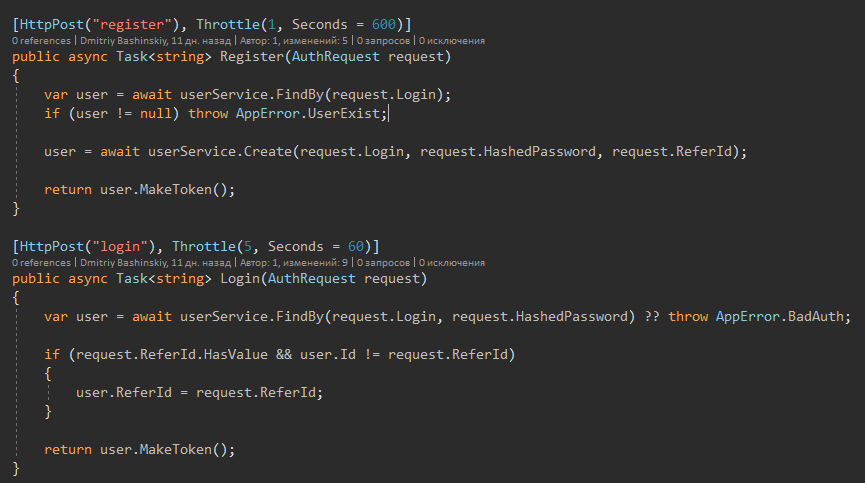
Hier sehen wir einen einfachen, lesbaren Code. Ich denke, jeder wird verstehen, was hier geschrieben steht.
Klares Muster beobachtet
1) Daten abrufen
2) Verarbeiten, Ändern usw. - Dieser Teil muss getestet werden.
3) Speichern.
3) Mapping, falls erforderlich
4) Fehlerbehandlung (Protokollierung + menschliche Reaktion)
Weitere DetailsDiese Klasse enthält alle möglichen Anwendungsfehler, auf die der Ausnahmebehandler reagiert.
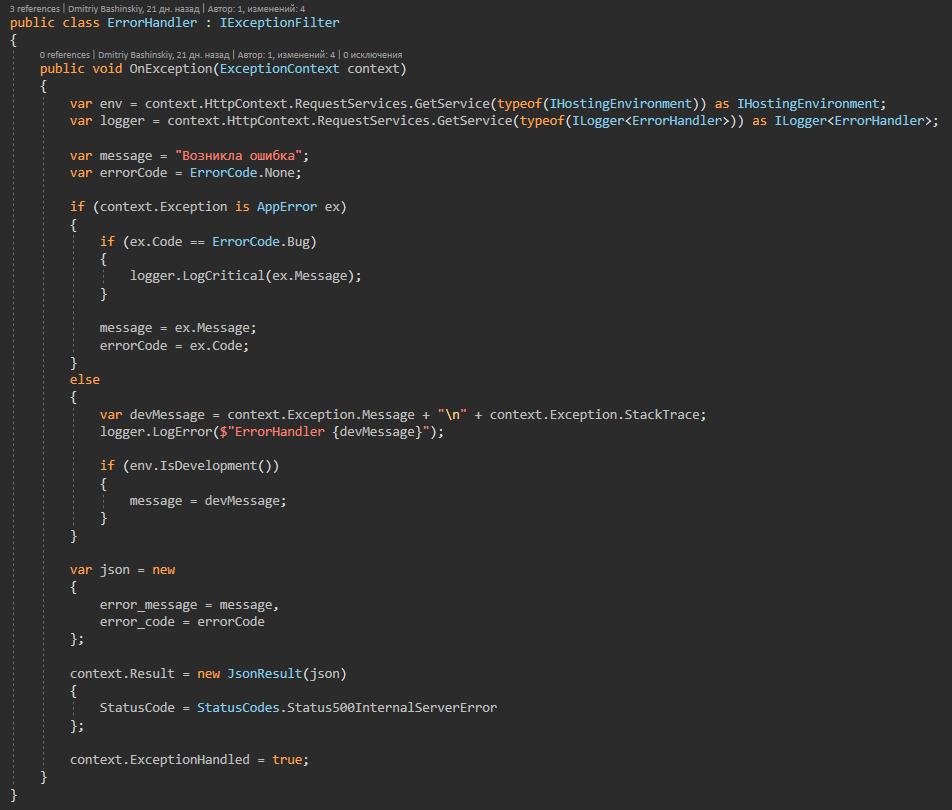
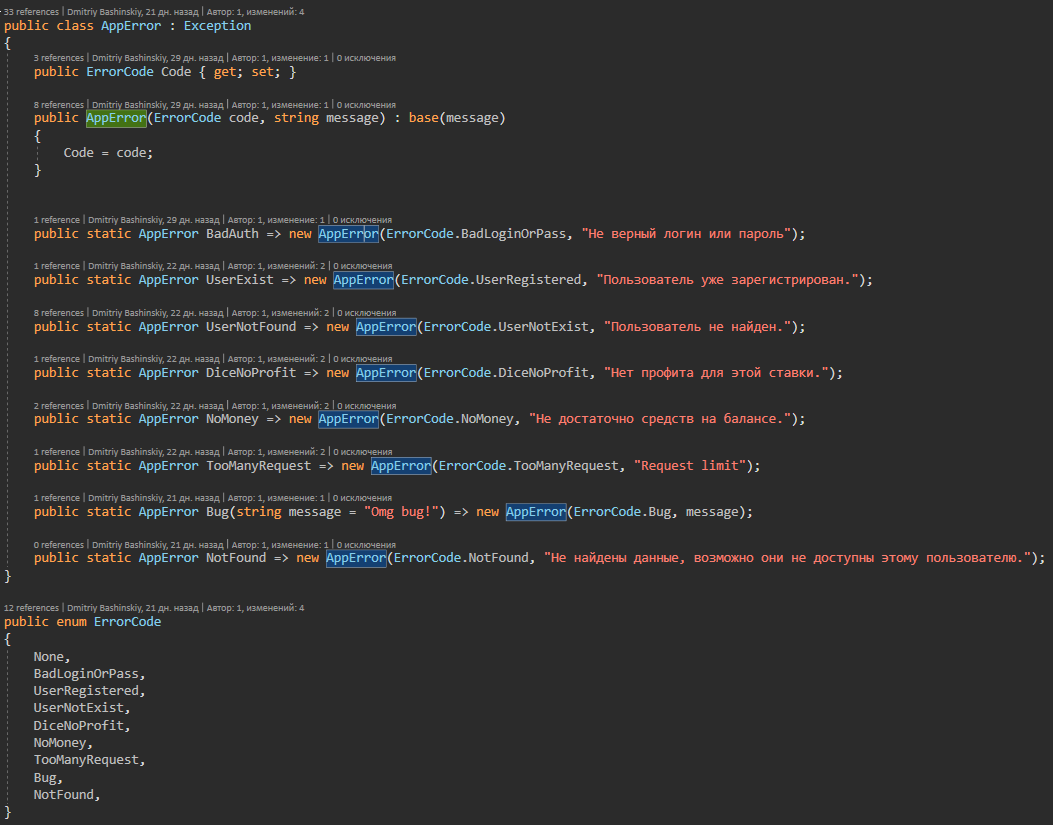
Es stellt sich heraus, dass die Anwendung entweder funktioniert oder einen bestimmten Fehler ausgibt und nicht die verarbeiteten Fehler entweder ein Nebeneffekt oder ein Fehler sind. Das Protokoll solcher Fehler wird mir sofort im Telegramm in einem Chat mit dem Bot angezeigt.
Ich habe AppError.Bug diesen Fehler für einen unklaren Fall.
Ich habe ein CallBack von einem anderen Dienst, es hat eine Benutzer-ID in meinem System, und wenn ich keinen Benutzer mit dieser ID finde, ist entweder etwas mit dem Benutzer passiert oder es ist überhaupt nicht klar, ein solcher Fehler fliegt mir wie KRITISCH, theoretisch sollte es nicht zu entstehen, aber wenn es tut, erfordert es mein Eingreifen.
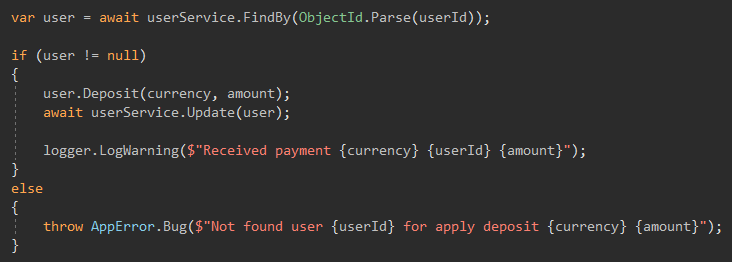
Kern, der interessanteste
Ich habe immer daran gedacht, dass BLs nur Funktionen sind, die das gleiche Ergebnis mit der gleichen Eingabe liefern. Die Komplexität des Codes in dieser Schicht lag auf der Ebene der Laborarbeit, nicht auf großartigen Funktionen, die ihre Arbeit klar und fehlerfrei erledigen. Und es war wichtig, dass es keine Nebenwirkungen innerhalb der Funktionen gab, alles, was die Funktion benötigte, war ihr Parameter.
Wenn die Funktion ein Benutzerguthaben benötigt, erhalten WIR das Guthaben und übertragen es an die Funktion. Pushen Sie den Benutzerdienst NICHT in BL.
1) Grundlegende Aktionen von Entitäten
Weitere Details
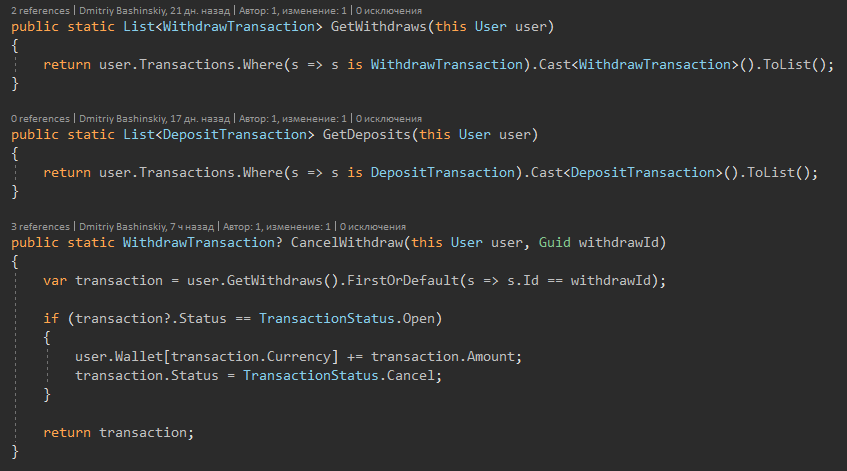
Ich habe Methoden als Erweiterungsmethoden entwickelt, damit die Klasse nicht aufgebläht wird und die Funktionalität nach Features gruppiert werden kann.
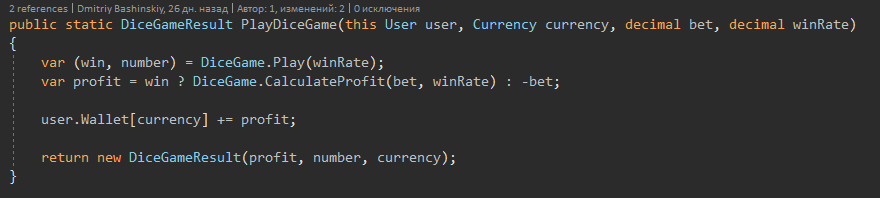
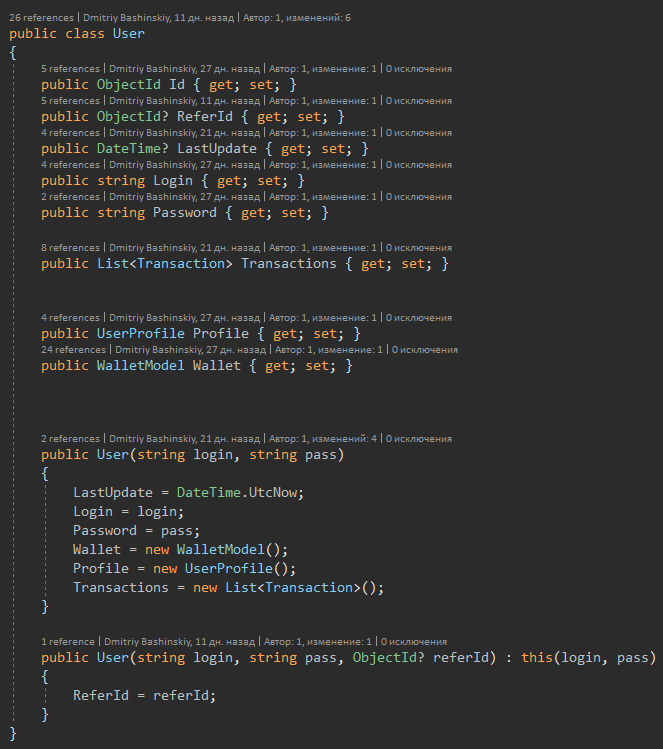
Ich halte eine gute Konstruktion von Entitätsmodellen für ein ebenso wichtiges Thema.
Zum Beispiel habe ich einen Benutzer, der Benutzer hat Guthaben in mehreren Währungen. Eine der typischen Entscheidungen, die ich ohne zu zögern getroffen habe, ist die Essenz von "Balance" und ich habe dem Benutzer nur eine Reihe von Salden hinzugefügt. Aber welche Art von Bequemlichkeit brachte eine solche Entscheidung?
1) Hinzufügen / Entfernen von Währungen. Diese Aufgabe bedeutet für uns sofort, nicht nur neuen Code zu schreiben, sondern auch zu migrieren, wobei alle vorhandenen Benutzer ausgefüllt / gelöscht werden. Dies ist die einfachste Option. Gott bewahre, um eine neue Währung hinzuzufügen, müssten Sie eine Schaltfläche für den Benutzer erstellen, auf die er klickt und die Erstellung einer neuen Brieftasche für eine Art Geschäftsprozess initiiert. Infolgedessen war es nur notwendig, die Aufzählung für die neue Währung zu erweitern, und sie schrieben eine weitere Funktion zum Erstellen von Brieftaschen per Knopfdruck. Sie warfen eine weitere Aufgabe nach vorne.
2) Im Code werden FirstOrDefault-Konstanten (s => s.Currency == Currency) und auf Null geprüft
Meine Entscheidung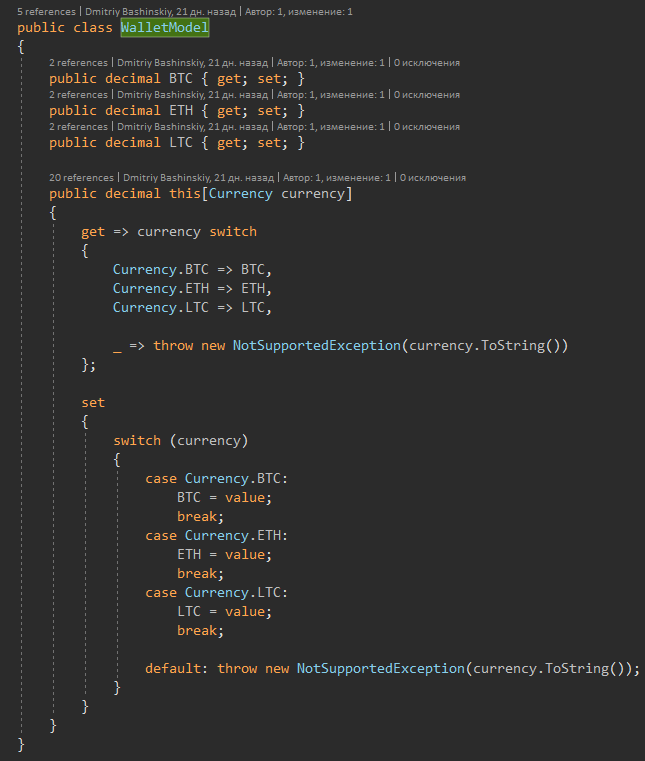
Durch das Modell selbst garantiere ich mir, dass es kein Null-Gleichgewicht gibt, und durch das Erstellen des Indexer-Operators habe ich meinen Code an allen Orten der Interaktion mit dem Gleichgewicht vereinfacht.
Dienstleistungen
Diese Ebene bietet mir praktische Tools für die Arbeit mit verschiedenen Diensten.
In meinem Projekt verwende ich MongoDB und habe die Sammlungen für eine bequeme Arbeit damit in ein solches Repository verpackt.
Weitere DetailsRepository selbst
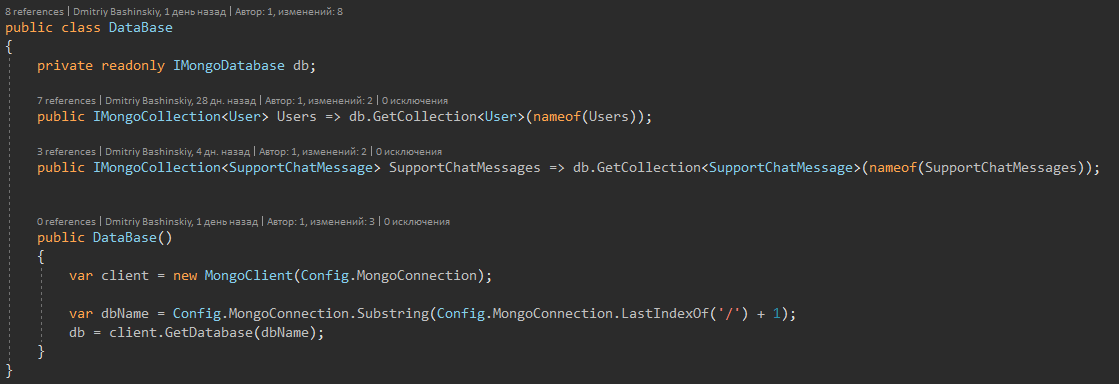
Monga blockiert das Dokument zum Zeitpunkt der Arbeit damit. Dies hilft uns bei der Lösung von Problemen im Wettbewerb der Anfragen. Und im Mong gibt es Methoden für die Suche nach einer Entität + die darauf einwirkt, zum Beispiel: "Finde einen Benutzer mit ID und addiere 10 zu seinem aktuellen Kontostand"
Und nun zum Feature von C # 8.
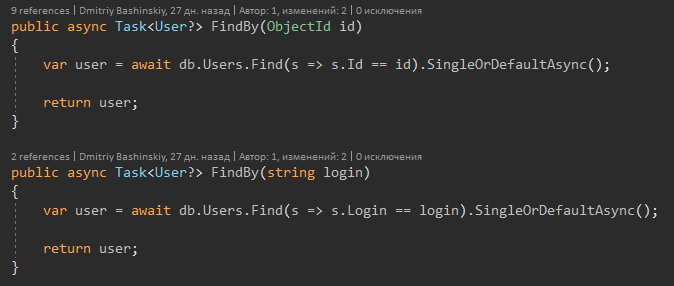
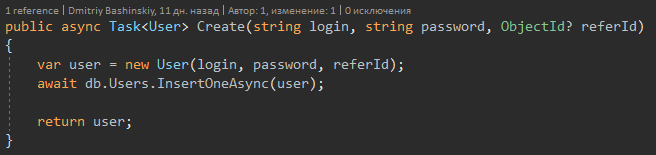
Die Methodensignatur sagt mir, dass Benutzer zurückgeben kann, und möglicherweise Null, wenn ich Benutzer sehe? Ich erhalte sofort eine Compiler-Warnung und führe eine Nullprüfung durch.
Wenn die Methode User zurückgibt, arbeite ich sicher damit.
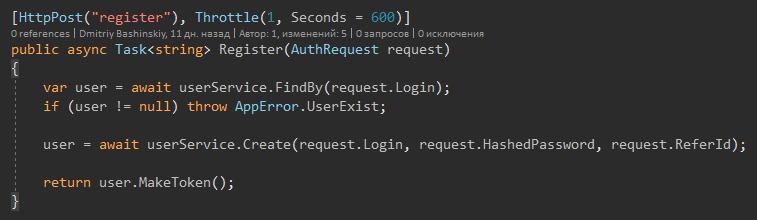
Ich möchte auch darauf aufmerksam machen, dass es keinen Try Catch gibt, da es nur Ausnahmen von "seltsamen Situationen" und falschen Daten geben kann, die hier nicht erreicht werden sollten, weil es eine Validierung gibt. Es gibt auch keinen Try-Catch in der API-Schicht, es gibt nur einen globalen Ausnahmebehandler.
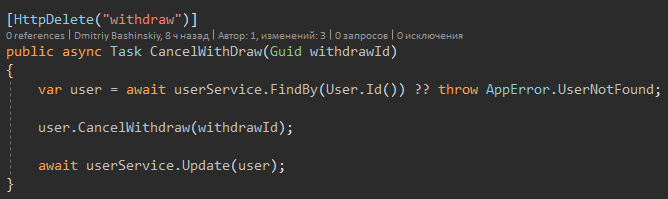
Es gibt nur eine Methode, die eine Ausnahme auslöst: die Update-Methode.
Es implementiert den Schutz vor Datenverlust im Multithread-Modus.
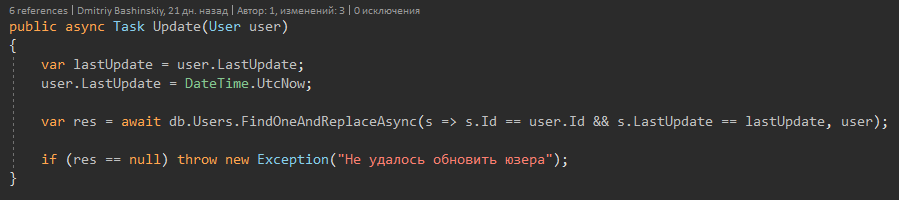
Warum haben Sie die oben genannten Monga-Methoden nicht angewendet?
Es gibt Orte, an denen ich immer noch nicht genau weiß, ob ich überhaupt mit dem Benutzer arbeiten kann. Vielleicht hat er kein Geld für diese Aktion. Am Anfang hole ich den Benutzer heraus und überprüfe sie, mutiere und speichere sie.
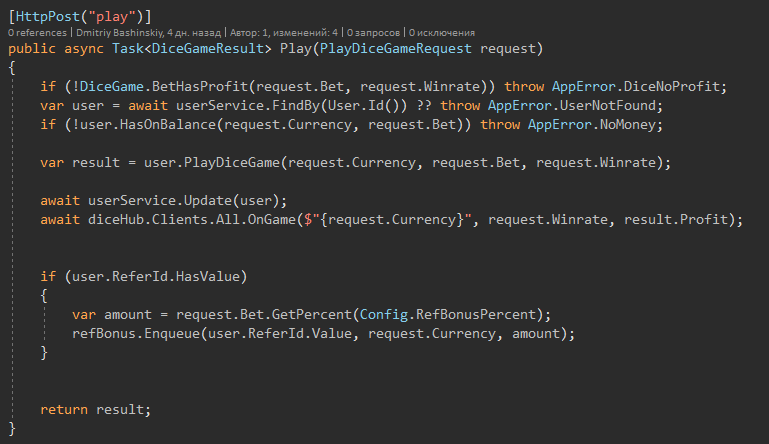
Meine theoretische Anwendung wird das Gleichgewicht des Benutzers mehr als einmal pro Sekunde verändern, da es sich um schnelle Spiele handelt.
Das Modell des Benutzers selbst zeigt jedoch deutlich, dass die Überweisung des Benutzers optional ist und Sie mit allem anderen arbeiten können, ohne an Null zu denken.
Schließlich Tests
Wie gesagt, Sie müssen nur die Logik testen, und die Logik unserer Funktion ist ohne Nebenwirkungen.
Daher können wir unsere Tests sehr schnell und mit unterschiedlichen Parametern ausführen.
Weitere DetailsIch habe Nuget FSCheck heruntergeladen, das zufällig eingehende Daten generiert und viele verschiedene Fälle berücksichtigt.
Ich muss nur verschiedene Benutzer erstellen, ihren Test füttern und die Änderungen überprüfen.
Es gibt einen kleinen Builder zum Erstellen solcher Benutzer, der jedoch leicht zu erweitern ist.

Und hier sind die Tests selbst
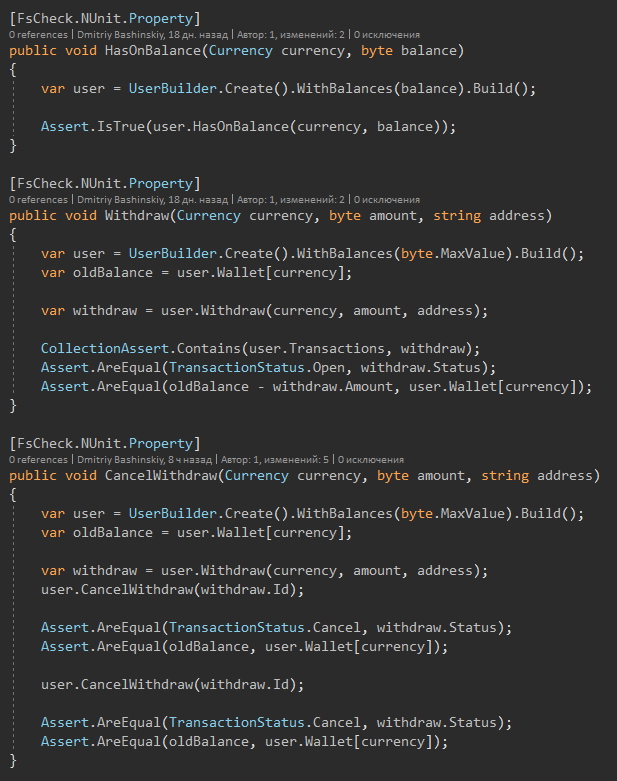
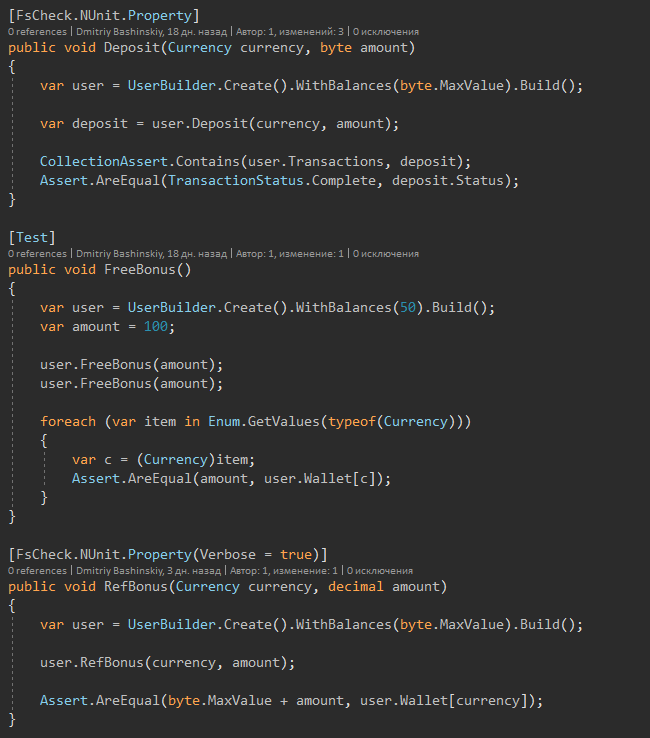
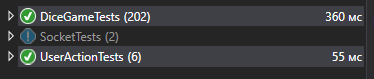
Nach einigen Änderungen führe ich die Tests aus, nach 1-2 Sekunden sehe ich, dass alles in Ordnung ist.
Es ist auch geplant, E2E-Tests zu schreiben, um die gesamte API von außen zu überprüfen und sicherzustellen, dass sie von der Anforderung bis zur Antwort ordnungsgemäß funktioniert.
Chips
Coole Sachen, die du vielleicht brauchstJede meiner Anforderungen ist dotiert. Wenn ein Fehler auftritt, finde ich requestId und kann den Fehler leicht reproduzieren, indem ich die Anforderung wiederhole, da meine API keinen Status hat und jede Anforderung nur von den Anforderungsparametern abhängt.
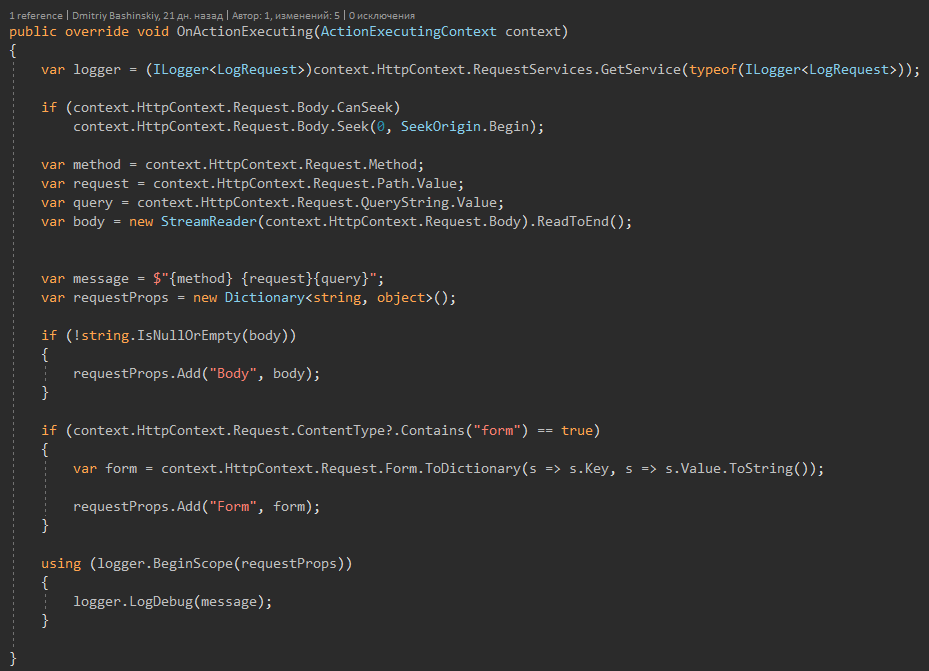
Zusammenfassend.
Wir haben wirklich eine Lösung geschrieben und kein Framework, in dem eine Reihe zusätzlicher Abstraktionen sowie Mok. Wir haben Fehler an einem Ort behandelt und sie sollten sehr selten auftreten. Wir haben BL und Nebenwirkungen getrennt, jetzt ist BL nur eine lokale Logik, die wiederverwendet werden kann. Wir haben keine zusätzlichen Funktionen geschrieben, die den Aufruf einfach an andere Funktionen weiterleiten. Ich werde Kommentare aktiv lesen und den Artikel ergänzen, danke!