Die Hauptprobleme beim Arbeiten mit der Datenbank hängen mit den Funktionen des Geräts des Betriebssystems zusammen, auf dem die Datenbank arbeitet. Linux ist jetzt das Hauptbetriebssystem für Datenbanken. Solaris, Microsoft und sogar HPUX werden immer noch im Unternehmen verwendet, aber sie werden niemals den ersten Platz einnehmen, selbst wenn sie kombiniert werden. Linux gewinnt zuversichtlich an Boden, da es immer mehr Open-Source-Datenbanken gibt. Daher geht es bei der Datenbankinteraktion mit dem Betriebssystem offensichtlich um Linux-Datenbanken. Dies überlagert das ewige DB-Problem - die E / A-Leistung. Es ist gut, dass Linux in den letzten Jahren den E / A-Stack grundlegend überarbeitet hat und Hoffnung auf Aufklärung besteht.
Ilya Kosmodemyansky (
Hydrobiont ) arbeitet für Data Egret, ein Unternehmen, das PostgreSQL
konsultiert und unterstützt, und weiß viel über die Interaktion zwischen Betriebssystem und Datenbanken. In einem Bericht über HighLoad ++ sprach Ilya am Beispiel von PostgreSQL über die Interaktion von E / A und Datenbanken, zeigte aber auch, wie andere Datenbanken mit E / A funktionieren. Ich habe mir den Linux IO-Stack angesehen, welche neuen und guten Dinge darin erschienen sind und warum nicht alles so ist, wie es vor ein paar Jahren war. Als nützliche Erinnerung - eine Checkliste mit PostgreSQL- und Linux-Einstellungen für maximale Leistung des E / A-Subsystems in den neuen Kerneln.
Das Berichtsvideo enthält viel Englisch, von dem wir die meisten im Artikel übersetzt haben.Warum über IO sprechen?
Schnelle E / A ist für Datenbankadministratoren das Wichtigste . Jeder weiß, was sich bei der Arbeit mit der CPU ändern lässt, dass der Speicher erweitert werden kann, aber E / A kann alles ruinieren. Wenn es mit Festplatten und zu viel E / A schlecht ist, stöhnt die Datenbank. IO wird zu einem Engpass.
Damit alles gut funktioniert, müssen Sie alles konfigurieren.
Nicht nur die Datenbank oder nur die Hardware - das war's. Sogar das Oracle auf hoher Ebene, das an einigen Stellen selbst ein Betriebssystem ist, muss konfiguriert werden. Wir lesen die Anweisungen im "Installationshandbuch" von Oracle: Ändern Sie solche Kernel-Parameter, ändern Sie andere - es gibt viele Einstellungen. Zusätzlich zu der Tatsache, dass in Unbreakable Kernel vieles bereits standardmäßig mit Oracle Linux verbunden ist.
Für PostgreSQL und MySQL sind noch weitere Änderungen erforderlich. Dies liegt daran, dass diese Technologien auf Betriebssystemmechanismen beruhen. Ein DBA, der mit PostgreSQL, MySQL oder modernem NoSQL funktioniert, muss ein Linux-Betriebsingenieur sein und verschiedene Betriebssysteme verrückt machen.
Jeder, der sich mit den
Kerneleinstellungen befassen möchte, wendet sich an
LWN . Die Ressource ist genial, minimalistisch, enthält viele nützliche Informationen, wurde jedoch
von Kernel-Entwicklern für Kernel-Entwickler geschrieben . Was schreiben Kernel-Entwickler gut? Der Kern, nicht der Artikel, wie man es benutzt. Deshalb werde ich versuchen, Ihnen alles für die Entwickler zu erklären und sie den Kernel schreiben zu lassen.
Alles wird oft dadurch kompliziert, dass die Entwicklung des Linux-Kernels und die Verarbeitung seines Stacks anfangs hinterherhinken und in den letzten Jahren sehr schnell gegangen sind. Weder Eisen noch Entwickler mit Artikeln hinter sich können mithalten.
Typische Datenbank
Beginnen wir mit den Beispielen für PostgreSQL - hier ist I / O gepuffert. Es verfügt über einen gemeinsam genutzten Speicher, der aus Sicht des Betriebssystems im
Benutzerbereich zugewiesen wird, und über denselben Cache im Kernel-Cache im
Kernel-Bereich .
 Die Hauptaufgabe einer modernen Datenbank
Die Hauptaufgabe einer modernen Datenbank :
- Nehmen Sie Seiten von der Festplatte im Speicher auf.
- Wenn eine Änderung auftritt, markieren Sie die Seiten als verschmutzt.
- in das Write-Ahead-Protokoll schreiben;
- Synchronisieren Sie dann den Speicher so, dass er mit der Festplatte übereinstimmt.
In einer PostgreSQL-Situation ist dies ein ständiger Roundtrip: vom gemeinsam genutzten Speicher, den PostgreSQL im Page Cache-Kernel steuert, und dann über den gesamten Linux-Stack auf die Festplatte. Wenn Sie eine Datenbank in einem Dateisystem verwenden, funktioniert dieser Algorithmus mit jedem UNIX-ähnlichen System und mit jeder Datenbank. Unterschiede sind, aber unbedeutend.
Die Verwendung von Oracle ASM ist anders - Oracle selbst interagiert mit der Festplatte. Das Prinzip ist jedoch dasselbe: Mit Direct IO oder mit Page Cache besteht die Aufgabe jedoch
darin, Seiten so schnell wie möglich durch den gesamten E / A-Stapel zu zeichnen , unabhängig davon, um was es sich handelt. Und in jeder Phase können Probleme auftreten.
Zwei Probleme von IO
Während alles
schreibgeschützt ist , gibt es keine Probleme. Sie lesen und wenn genügend Speicher vorhanden ist, werden alle zu lesenden Daten im RAM abgelegt. Die Tatsache, dass im Fall von PostgreSQL im
Puffer-Cache dieselbe ist, macht uns keine großen Sorgen.
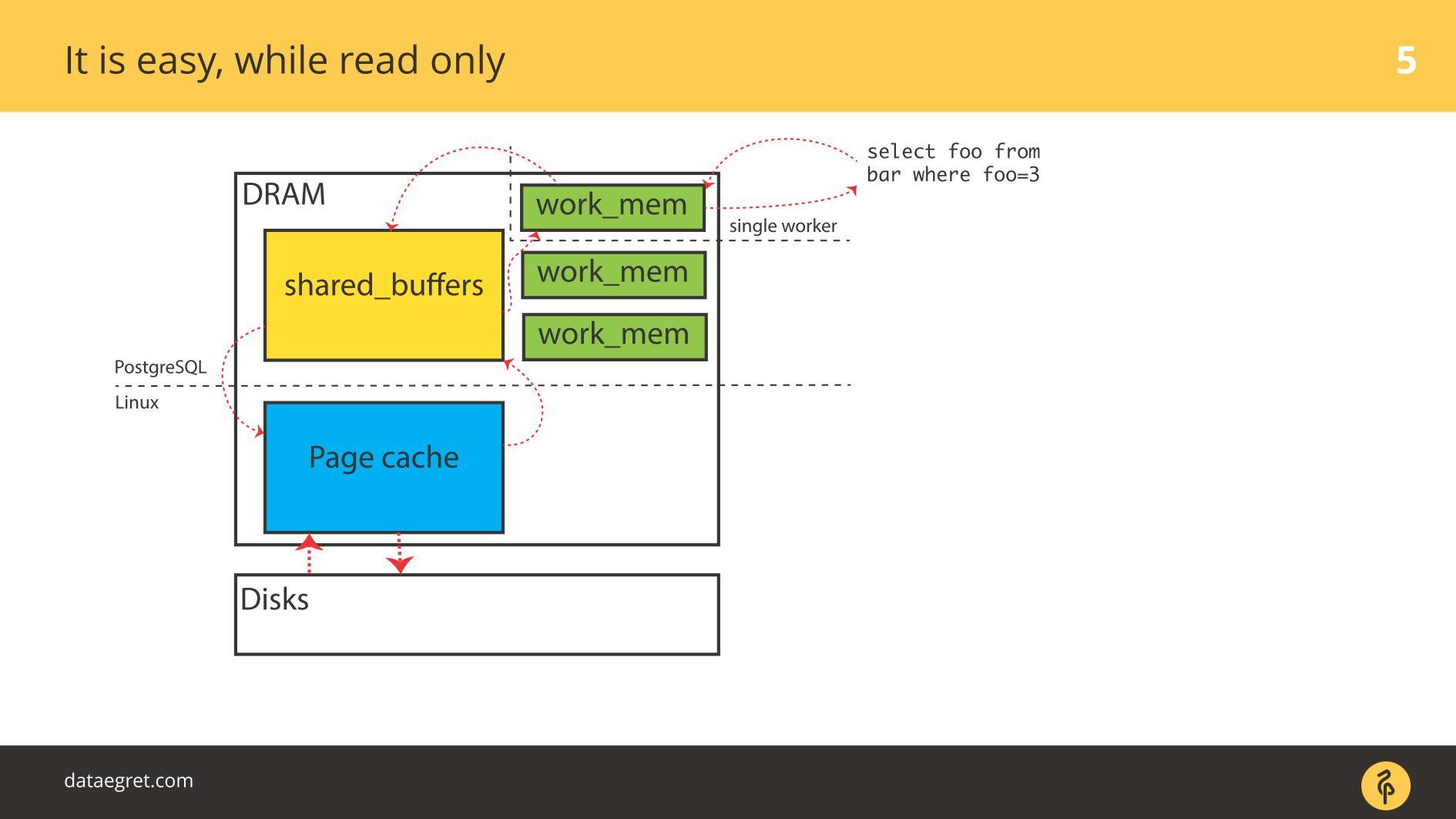 Das erste Problem mit E / A ist die Cache-Synchronisation.
Das erste Problem mit E / A ist die Cache-Synchronisation. Tritt auf, wenn eine Aufzeichnung erforderlich ist. In diesem Fall müssen Sie viel mehr Speicher hin und her fahren.
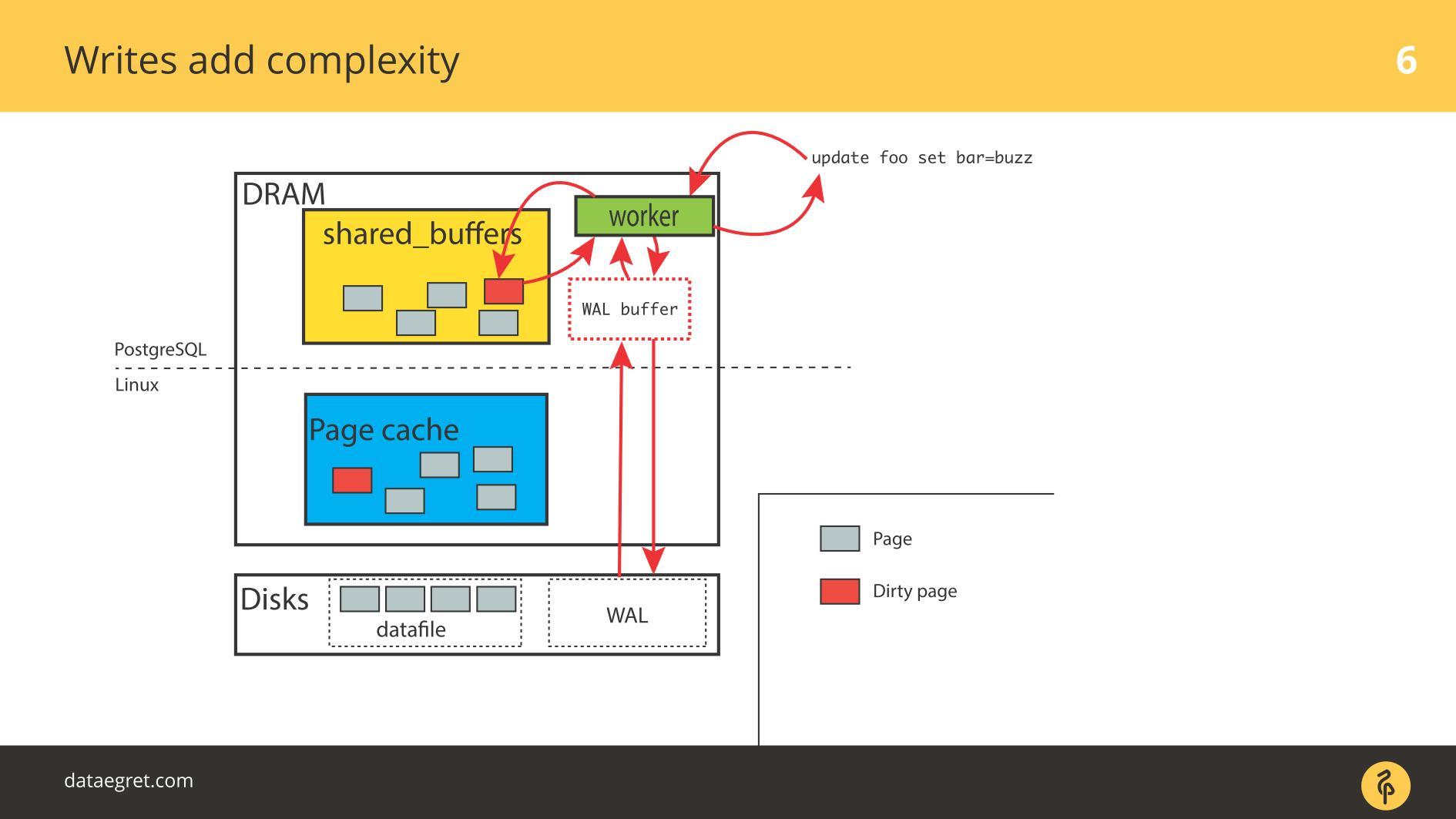
Dementsprechend müssen Sie PostgreSQL oder MySQL so konfigurieren, dass alles vom gemeinsam genutzten Speicher auf die Festplatte gelangt. Im Fall von PostgreSQL müssen Sie den Hintergrundbetrug schmutziger Seiten unter Linux noch optimieren, um alles auf die Festplatte zu senden.
Das zweite häufige Problem ist ein Schreibfehler beim Write-Ahead-Protokoll . Es wird angezeigt, wenn die Last so stark ist, dass sogar ein nacheinander aufgezeichnetes Protokoll auf der Festplatte liegt. In dieser Situation muss es auch schnell aufgezeichnet werden.
Die Situation unterscheidet sich nicht wesentlich von der
Cache-Synchronisation . In PostgreSQL arbeiten wir mit einer großen Anzahl gemeinsam genutzter Puffer. Die Datenbank verfügt über Mechanismen für eine effiziente Write-Ahead-Protokollaufzeichnung und ist bis zum Limit optimiert. Das einzige, was getan werden kann, um das Protokoll selbst effizienter zu gestalten, ist das Ändern der Linux-Einstellungen.
Die Hauptprobleme bei der Arbeit mit der Datenbank
Das gemeinsam genutzte Speichersegment kann sehr groß sein . Ich habe 2012 auf Konferenzen darüber gesprochen. Dann sagte ich, dass der Speicher im Preis gefallen ist, auch wenn es Server mit 32 GB RAM gibt. Im Jahr 2019 sind möglicherweise bereits mehr Laptops vorhanden, immer häufiger auf den Servern 128, 256 usw.
Wirklich viel Gedächtnis . Banale Aufnahmen erfordern Zeit und Ressourcen, und die
Technologien, die wir dafür verwenden, sind konservativ . Datenbanken sind alt, sie wurden lange entwickelt und entwickeln sich langsam weiter. Die Mechanismen in den Datenbanken stimmen mit der neuesten Technologie nicht genau überein.
Das Synchronisieren von Seiten im Speicher mit der Festplatte führt zu großen E / A-Vorgängen . Wenn wir Caches synchronisieren, entsteht ein großer Strom von E / A und ein weiteres Problem -
wir können etwas nicht verdrehen und den Effekt betrachten. In einem wissenschaftlichen Experiment ändern Forscher einen Parameter - erhalten Sie den Effekt, den zweiten - erhalten Sie den Effekt, den dritten. Wir werden es nicht schaffen. Wir verdrehen einige Parameter in PostgreSQL, konfigurieren Checkpoints - wir haben den Effekt nicht gesehen. Konfigurieren Sie dann erneut den gesamten Stapel, um zumindest einige Ergebnisse zu erhalten. Twist One-Parameter funktioniert nicht - wir müssen alles auf einmal konfigurieren.
Die meisten PostgreSQL-E / A generieren eine Seitensynchronisation: Prüfpunkte und andere Synchronisationsmechanismen. Wenn Sie mit PostgreSQL gearbeitet haben, haben Sie möglicherweise Checkpoints-Spitzen gesehen, wenn regelmäßig eine „Säge“ in den Diagrammen angezeigt wird. Früher waren viele mit diesem Problem konfrontiert, aber jetzt gibt es Handbücher zur Behebung. Es ist einfacher geworden.
SSDs retten heute die Situation erheblich. Bei PostgreSQL ruht etwas selten direkt auf dem Wertedatensatz. Alles hängt von der Synchronisation ab: Wenn ein Prüfpunkt auftritt, wird fsync aufgerufen und es gibt eine Art „Schlagen“ eines Prüfpunkts auf einen anderen. Zu viel IO. Ein Checkpoint ist noch nicht beendet, hat noch nicht alle Fsyncs abgeschlossen, hat aber bereits einen weiteren Checkpoint verdient und es hat begonnen!
PostgreSQL hat eine einzigartige Funktion -
Autovacuum . Dies ist eine lange Geschichte von Krücken für die Datenbankarchitektur. Wenn das Autovakuum ausfällt, wird es normalerweise so eingerichtet, dass es aggressiv funktioniert und den Rest nicht beeinträchtigt: Es gibt viele Autovakuumarbeiter, die häufig ein wenig stolpern und Tabellen schnell verarbeiten. Andernfalls treten Probleme mit DDL und Sperren auf.
Aber wenn Autovacuum aggressiv ist, beginnt es auf IO zu kauen.
Wenn Checkpoints mit Autovakuum überlagert werden, werden die Festplatten die meiste Zeit zu fast 100% recycelt, und dies ist die Ursache der Probleme.
Seltsamerweise gibt es ein
Cache-Nachfüllproblem . Sie ist normalerweise weniger bekannt für DBA. Ein typisches Beispiel: Die Datenbank wurde gestartet und für einige Zeit verlangsamt sich alles traurig. Kaufen Sie daher auch bei viel RAM gute Festplatten, damit der Stapel den Cache erwärmt.
All dies beeinträchtigt die Leistung erheblich. Probleme beginnen nicht unmittelbar nach dem Neustart der Datenbank, sondern später. Beispielsweise wurde der Prüfpunkt übergeben, und viele Seiten sind in der gesamten Datenbank verschmutzt. Sie werden auf die Festplatte kopiert, da Sie sie synchronisieren müssen. Dann fordern die Anforderungen eine neue Version der Seiten von der Festplatte an, und die Datenbank hängt ab. Die Grafiken zeigen, wie das Nachfüllen des Caches nach jedem Prüfpunkt einen bestimmten Prozentsatz zur Last beiträgt.
Das Unangenehmste an der Eingabe / Ausgabe der Datenbank ist
Worker IO. Wenn jeder von Ihnen angeforderte Mitarbeiter mit der Generierung seiner E / A beginnt. In Oracle ist es einfacher, aber in PostgreSQL ist es ein Problem.
Es gibt viele Gründe für Probleme mit
Worker IO : Es ist nicht genügend Cache vorhanden, um neue Seiten von der Festplatte zu "posten". Es kommt beispielsweise vor, dass alle Puffer gemeinsam genutzt werden, dass sie alle verschmutzt sind und dass noch keine Checkpoints vorhanden sind. Damit der Worker die einfachste Auswahl durchführen kann, müssen Sie den Cache von irgendwoher nehmen. Dazu müssen Sie zunächst alles auf der Festplatte speichern. Sie haben keinen speziellen Checkpointer-Prozess, und der Worker startet fsync, um ihn freizugeben und mit etwas Neuem zu füllen.
Dies wirft ein noch größeres Problem auf: Der Arbeiter ist nicht spezialisiert, und der gesamte Prozess ist überhaupt nicht optimiert. Es ist möglich, irgendwo auf Linux-Ebene zu optimieren, aber in PostgreSQL ist dies eine Notfallmaßnahme.
Haupt-E / A-Problem für DB
Welches Problem lösen wir, wenn wir etwas einrichten? Wir möchten den Transport schmutziger Seiten zwischen Festplatte und Speicher maximieren.
Es kommt jedoch häufig vor, dass diese Dinge die Festplatte nicht direkt berühren. Ein typischer Fall - Sie sehen einen sehr großen Lastdurchschnitt. Warum so? Weil jemand auf die Festplatte wartet und auch alle anderen Prozesse warten. Es scheint, dass es keine explizite Disc-Nutzung der Discs gibt, nur etwas hat die Disc dort blockiert, und das Problem liegt sowieso in der Ein- / Ausgabe.
Datenbank-E / A-Probleme betreffen nicht immer nur Festplatten.
An diesem Problem ist alles beteiligt: Festplatten, Speicher, CPU, E / A-Scheduler, Dateisysteme und Datenbankeinstellungen. Lassen Sie uns nun den Stapel durchgehen und sehen, was damit zu tun ist und welche guten Dinge in Linux erfunden wurden, damit alles besser funktioniert.
Festplatten
Viele Jahre lang waren die Festplatten furchtbar langsam und niemand war an der Latenz oder Optimierung der Übergangsphasen beteiligt. Die Optimierung von fsyncs ergab keinen Sinn. Die Scheibe drehte sich, die Köpfe bewegten sich wie eine Schallplatte darüber, und fsyncs war so lang, dass keine Probleme auftraten.
Die Erinnerung
Es ist sinnlos, sich Top-Abfragen anzusehen, ohne die Datenbank zu optimieren. Sie konfigurieren eine ausreichende Menge an gemeinsam genutztem Speicher usw. und haben eine neue Top-Abfrage - Sie müssen sie erneut konfigurieren. Hier ist die gleiche Geschichte. Aus dieser Berechnung wurde der gesamte Linux-Stack erstellt.
Bandbreite und Latenz
Die Maximierung der E / A-Leistung durch Maximierung des Durchsatzes ist bis zu einem gewissen Punkt einfach. In PostgreSQL wurde ein zusätzlicher PageWriter-Prozess erfunden, der den Checkpoint entlud. Die Arbeit ist parallel geworden, aber es gibt noch Grundlagen für die Hinzufügung von Parallelität. Und die Latenz zu minimieren, ist die Aufgabe der letzten Meile, für die Supertechnologien benötigt werden.
Diese Supertechnologien sind SSDs. Als sie erschienen, sank die Latenz stark. In allen anderen Phasen des Stacks traten jedoch Probleme auf: sowohl von Seiten der Datenbankhersteller als auch von Seiten der Linux-Hersteller. Probleme müssen angegangen werden.
Bei der Datenbankentwicklung ging es um die Maximierung des Durchsatzes, ebenso wie bei der Entwicklung des Linux-Kernels. Viele Methoden zur Optimierung der E / A-Ära von sich drehenden Festplatten sind für SSDs nicht so gut.
Zwischendurch mussten wir für die aktuelle Linux-Infrastruktur sichern, jedoch mit neuen Festplatten. Wir haben Leistungstests des Herstellers mit einer großen Anzahl verschiedener IOPS gesehen, und die Datenbank wurde nicht besser, da es in der Datenbank nicht nur und nicht so sehr um IOPS geht. Es kommt oft vor, dass wir 50.000 IOPS pro Sekunde überspringen können, was gut ist. Aber wenn wir die Latenz nicht kennen, ihre Verteilung nicht kennen, können wir nichts über die Leistung sagen. Irgendwann beginnt die Datenbank mit dem Checkpoint und die Latenz steigt dramatisch an.
Nach wie vor war dies ein großes Leistungsproblem bei Virtuala-Datenbanken. Virtuelle E / A zeichnen sich durch ungleichmäßige Latenz aus, was natürlich auch Probleme mit sich bringt.
IO-Stack. Wie es vorher war
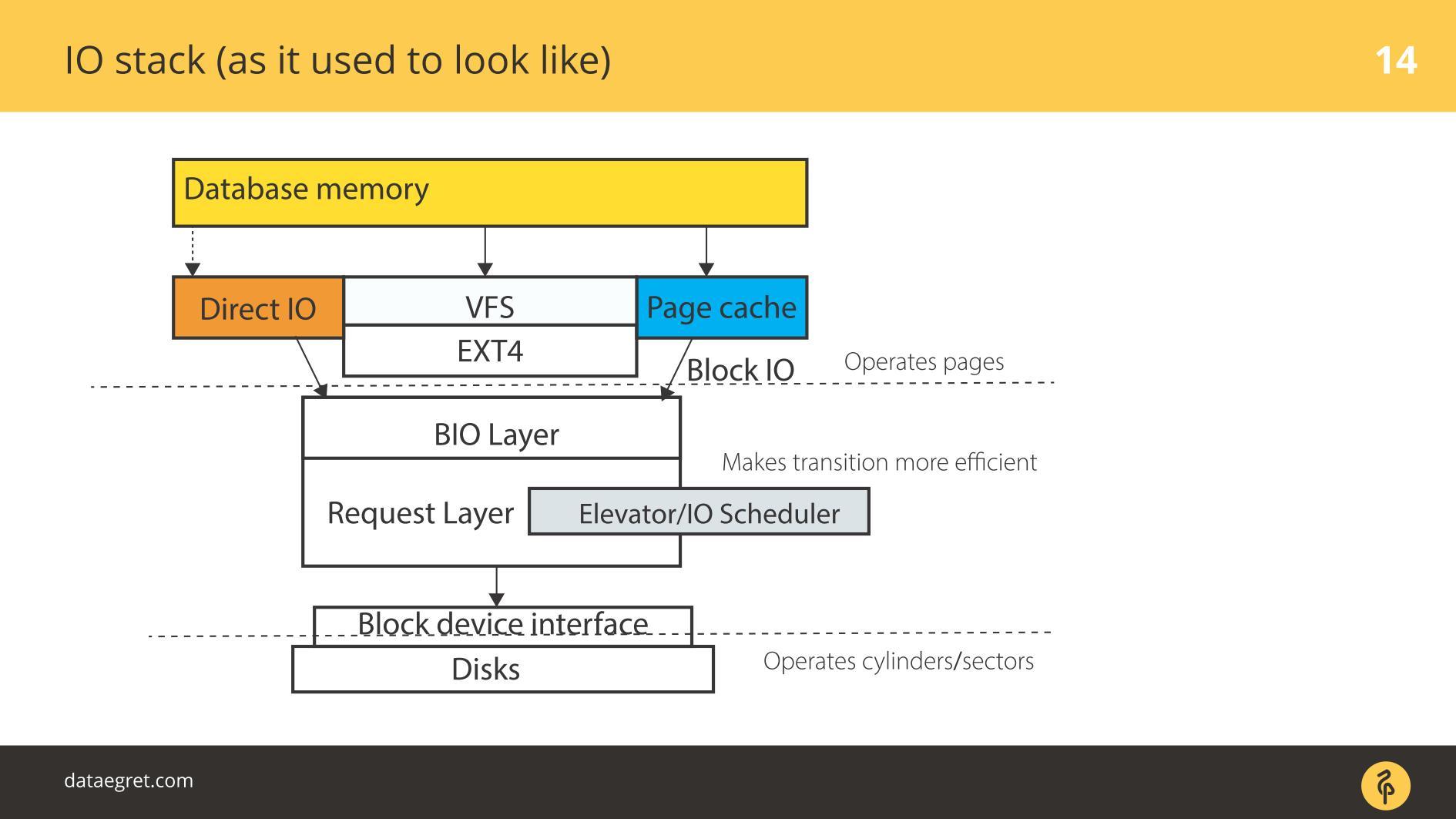
Es gibt User Space - diesen Speicher, der von der Datenbank selbst verwaltet wird. In einer DB so konfiguriert, dass alles so funktioniert, wie es sollte. Dies kann in einem separaten Bericht erfolgen und nicht einmal in einem. Dann geht alles unweigerlich durch den Seiten-Cache oder über die Direct IO-Schnittstelle in die
Block Input / Output-Schicht .
Stellen Sie sich eine Dateisystemschnittstelle vor. Die Seiten, die sich im Puffer-Cache befanden, wie sie ursprünglich in der Datenbank waren, dh Blöcke, werden durch diese entfernt. Die Block-E / A-Schicht behandelt Folgendes. Es gibt eine C-Struktur, die einen Block im Kernel beschreibt. Die Struktur nimmt diese Blöcke und sammelt daraus Vektoren (Arrays) von Eingabe- oder Ausgabeanforderungen. Unterhalb der BIO-Schicht befindet sich die Anforderungsschicht. Vektoren werden auf dieser Schicht gesammelt und gehen weiter.
Diese beiden Schichten in Linux wurden lange Zeit für eine effiziente Aufzeichnung auf Magnetplatten geschärft. Es war unmöglich, auf einen Übergang zu verzichten. Es gibt Blöcke, die bequem über die Datenbank verwaltet werden können. Es ist notwendig, diese Blöcke zu Vektoren zusammenzusetzen, die bequem auf die Platte geschrieben werden, so dass sie irgendwo in der Nähe liegen. Damit dies effektiv funktioniert, haben sie Elevators oder Schedulers IO entwickelt.
Aufzüge
Aufzüge waren hauptsächlich an der Kombination und Sortierung von Vektoren beteiligt. Alles, damit der Block-SD-Treiber - der Quasidisk-Treiber - die Aufzeichnungsblöcke in der für ihn passenden Reihenfolge eintreffen. Der Treiber übersetzte von Blöcken in seine Sektoren und schrieb auf die Festplatte.
Das Problem war, dass es notwendig war, mehrere Übergänge durchzuführen und bei jeder ihre eigene Logik des optimalen Prozesses zu implementieren.
Aufzüge: bis Kernel 2.6
Vor Kernel 2.6 gab es Linus Elevator - den primitivsten IO-Scheduler, der von Ihnen geschrieben wurde. Lange Zeit galt er als absolut unerschütterlich und gut, bis sie etwas Neues entwickelten.
Linus Elevator hatte viele Probleme.
Er kombinierte und sortierte , um effizienter aufzunehmen . Bei rotierenden mechanischen Scheiben führte dies zur Entstehung von "
Hunger" : Eine Situation, in der die Aufzeichnungseffizienz von der Drehung der Scheibe abhängt. Wenn Sie plötzlich gleichzeitig effektiv lesen müssen, es aber bereits falsch eingestellt wurde, wird es von einer solchen Festplatte schlecht gelesen.
Allmählich wurde klar, dass dies ein ineffizienter Weg ist. Aus diesem Grund wurde ab Kernel 2.6 ein ganzer Zoo von Schedulern angezeigt, der für verschiedene Aufgaben vorgesehen war.
Aufzüge: zwischen 2,6 und 3
Viele Leute verwechseln diese Scheduler mit Betriebssystem-Schedulern, weil sie ähnliche Namen haben.
CFQ - Völlig faires Queuing ist nicht dasselbe wie OS-Scheduler. Nur die Namen sind ähnlich. Es wurde als universeller Scheduler geprägt.
Was ist ein universeller Scheduler? Denken Sie, Sie haben eine durchschnittliche Belastung oder im Gegenteil eine einzigartige? Datenbanken sind sehr vielseitig einsetzbar. Die universelle Last kann man sich als normalen Laptop vorstellen. Dort passiert alles: Wir hören Musik, spielen, tippen Text. Dafür wurden nur universelle Scheduler geschrieben.
Die Hauptaufgabe des universellen Schedulers: Erstellen Sie unter Linux für jedes virtuelle Terminal und jeden virtuellen Prozess eine Anforderungswarteschlange. Wenn wir Musik in einem Audio-Player hören möchten, nimmt IO für den Player eine Warteschlange ein. Wenn wir etwas mit dem Befehl cp sichern möchten, ist etwas anderes beteiligt.
Bei Datenbanken tritt ein Problem auf. In der Regel ist eine Datenbank ein Prozess, der gestartet wurde, und während des Betriebs entstanden parallele Prozesse, die immer in derselben E / A-Warteschlange enden. Der Grund ist, dass dies dieselbe Anwendung ist, derselbe übergeordnete Prozess. Für sehr kleine Lasten war eine solche Planung geeignet, für den Rest war sie nicht sinnvoll. Es war einfacher auszuschalten und wenn möglich nicht zu benutzen.
Allmählich erschien der
Terminplaner - er funktioniert schlauer, aber im Grunde ist es Zusammenführen und Sortieren für sich drehende Datenträger. Angesichts des Entwurfs eines bestimmten Platten-Subsystems sammeln wir Blockvektoren, um sie optimal zu schreiben. Er hatte weniger Probleme mit dem
Hunger , aber sie waren da.
Daher erschien näher am dritten Linux-Kernel
noop oder
none , was mit der Verbreitung von SSDs viel besser funktionierte. Einschließlich Scheduler Noop deaktivieren wir die Scheduling-Funktion: Es gibt keine Sortierungen, Zusammenführungen und ähnliche Dinge, die CFQ und Deadline durchgeführt haben.
Dies funktioniert besser mit SSDs, da SSDs von Natur aus parallel sind: Sie haben Speicherzellen. Je mehr dieser Elemente auf einer PCIe-Karte gespeichert werden müssen, desto effizienter funktioniert sie.
Scheduler aus einigen seiner jenseitigen, aus Sicht der SSD, Überlegungen, sammelt einige Vektoren und sendet sie irgendwohin. Alles endet mit einem Trichter. Also töten wir die Parallelität von SSD, wir nutzen sie nicht in vollem Umfang. Daher funktionierte ein einfaches Herunterfahren, wenn die Vektoren zufällig ohne Sortierung ablaufen, hinsichtlich der Leistung besser. Aus diesem Grund wird angenommen, dass zufälliges Lesen und zufälliges Schreiben auf SSDs besser sind.
Aufzüge: ab 3.13
Beginnend mit Kernel 3.13 erschien
blk-mq . Etwas früher gab es einen Prototyp, aber in 3.13 erschien zuerst eine funktionierende Version.
Blk-mq begann als Scheduler, aber es ist schwierig, es als Scheduler zu bezeichnen - es steht architektonisch allein. Dies ist ein Ersatz für die Anforderungsschicht im Kernel. Langsam führte die Entwicklung von blk-mq zu einer umfassenden Überarbeitung des gesamten Linux-E / A-Stacks.
Die Idee ist folgende: Lassen Sie uns die native Fähigkeit von SSDs nutzen, um eine effiziente Parallelität für E / A zu erreichen. Abhängig davon, wie viele parallele E / A-Streams Sie verwenden können, gibt es ehrliche Warteschlangen, über die wir einfach so schreiben, wie es auf der SSD ist. CPU .
blk-mq . . , 4 ,
blk-mq — 5-10%, .
blk-mq — , SSD.
blk-mq NVMe driver Linux. Linux, Microsoft.
blk-mq NVMe driver — Linux, .
, . - PCIe SSD. , .
blk-mq NVMe , . .
, , . NVMe , , .
elevators

: CPU, , - .
Elevators -. CPU . - , , , , IO .
elevators
blk-mq — . CPU, NUMA- / . , , , . SD , , .
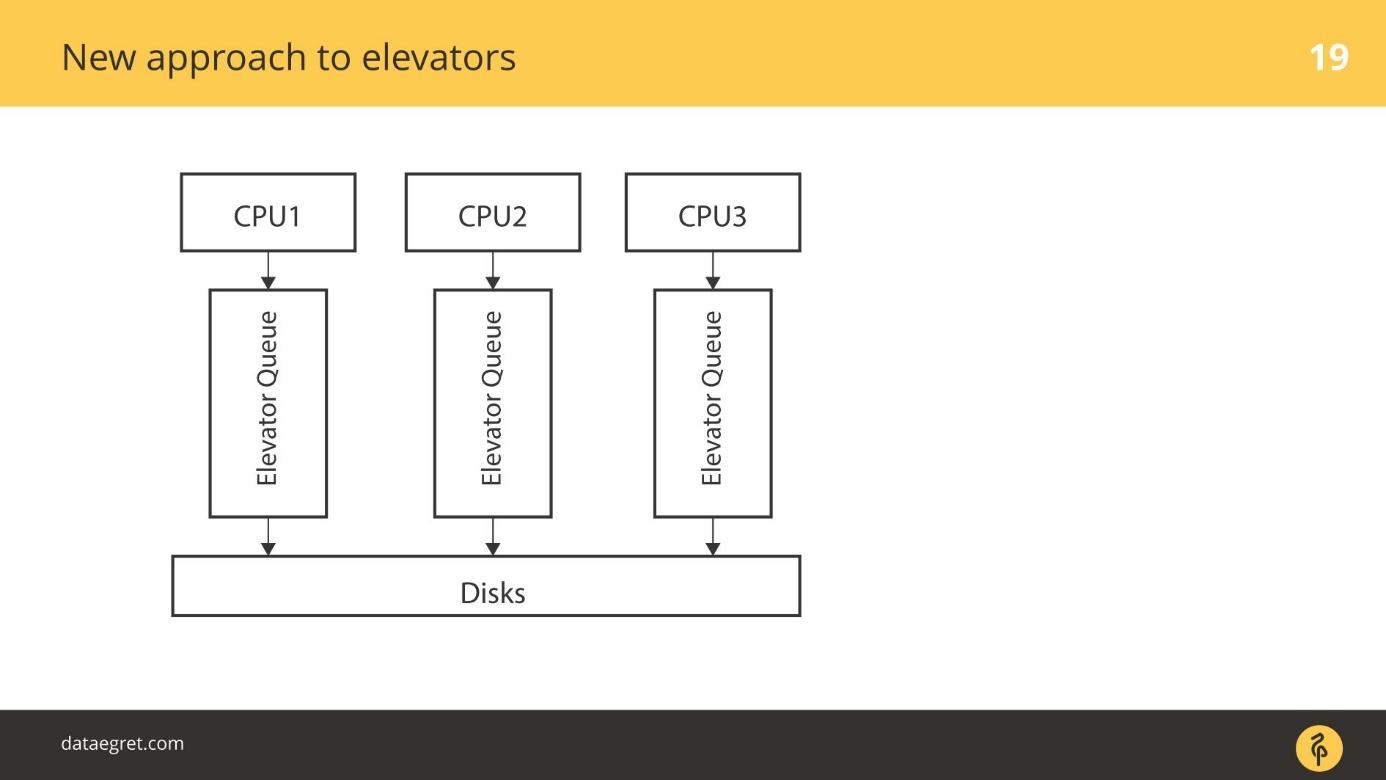
. - RAID- , RAID. SSD — . SD- , blq-mq.
blk-mq
.

. , . / , , Block IO-.
blk-mq , , scheduler.
3.13 , . schedulers
blk-mq , . Linux schedulers IO — Kyber BFQ.
blk-mq .
BFQ — Budget Fair Queueing — FQ . , . BFQ — scheduler . IO. IO, / . , . — . BFQ, , .
Kyber — . BFQ, . Kyber scheduler . — CPU . Kyber .
—
blk-mq SD- . , , , IO-. blk-mq NVMe driver . .
— latency, . SSD, — . -, , NVMe-, blk-mq , . .
Linux IO
/ Linux.
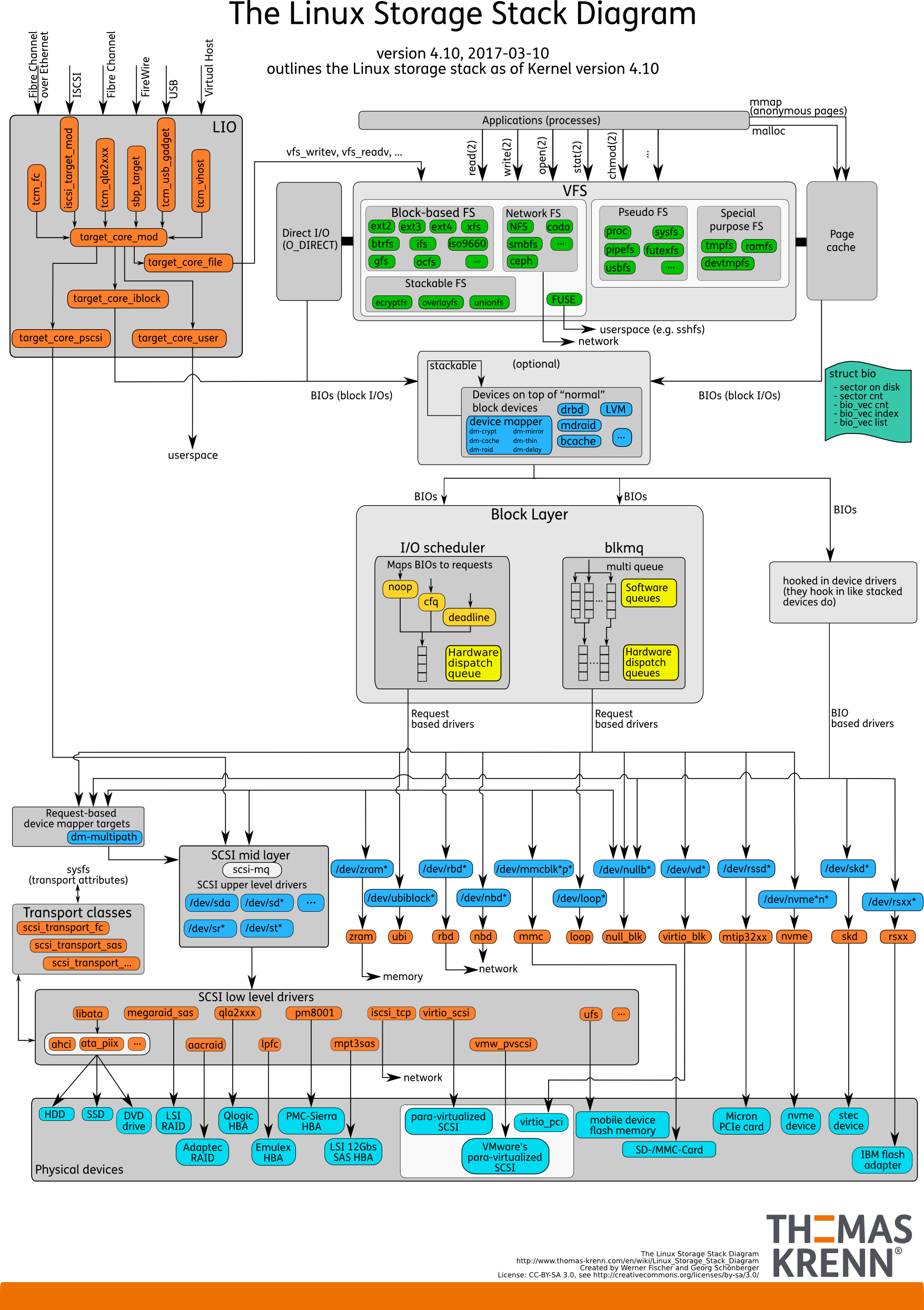
, , , Elevators, .
, , .
NVM Express
NVM Express oder NVMe ist eine Spezifikation, eine Reihe von Standards, mit denen Sie SSDs besser nutzen können. Die Spezifikation ist unter Linux gut gestellt. Linux ist eine der treibenden Kräfte des Standards.Jetzt in Produktion ist die dritte Version. Der Treiber dieser Version kann der Spezifikation folgen 20 GB / s pro SSD-Block und NVMe der falschen Version, die noch nicht verfügbar ist, bis zu 32 GB / s gehört . Der SD-Treiber wird weder über Schnittstellen noch über Steuern, um eine Rechte Bandbreite gehört.Diese Spezifikation ist Zugang schneller als alles, war ein Krieg.
Sobald die Datenbanken für rotierende Datenträger geschrieben und an diesen ausgerichtet wurden, haben sie beispielsweise Indizes in Form eines B-Baums. Es stellt sich die Frage:
Sind die Datenbanken für NVMe bereit ? Können Datenbanken eine solche Last kauen?
Noch nicht, aber sie passen sich an. Die PostgreSQL-Mailingliste hatte kürzlich einige
pwrite() und ähnliche Dinge. PostgreSQL- und MySQL-Entwickler interagieren mit Kernel-Entwicklern. Natürlich möchte ich mehr Interaktion.
Jüngste Entwicklungen
In den letzten anderthalb Jahren hat NVMe
IO-Polling hinzugefügt.
Anfangs gab es sich drehende Scheiben mit hoher Latenz. Dann kamen die SSDs, die viel schneller sind. Aber es gab einen Stau: fsync geht weiter, die Aufnahme beginnt und auf einer sehr niedrigen Ebene - tief im Treiber wird eine Anfrage direkt an die Hardware gesendet - schreiben Sie sie auf.
Der Mechanismus war einfach - sie haben ihn gesendet und wir warten, bis der Interrupt verarbeitet ist. Das Warten auf die Interrupt-Verarbeitung ist im Vergleich zum Schreiben auf eine sich drehende Festplatte kein Problem. Das Warten dauerte so lange, dass der Interrupt funktionierte, sobald die Aufnahme beendet war.
Da die SSD sehr schnell schreibt, ist zwangsweise ein Mechanismus zum Abfragen der Hardware über die Aufzeichnung erschienen. In den ersten Versionen erreichte die Erhöhung der E / A-Geschwindigkeit 50%, da wir nicht auf eine Unterbrechung warten, sondern das Stück Eisen aktiv nach dem Datensatz fragen.
Dieser Mechanismus wird als E / A-Abfrage bezeichnet .
Es wurde in neueren Versionen eingeführt. In Version 4.12 erschienen
IO-Scheduler , die speziell für die Arbeit mit
blk-mq und NVMe geschärft wurden und über die ich
Kyber und BFQ sagte. Sie sind bereits offiziell im Kernel, sie können verwendet werden.
In einer verwendbaren Form gibt es jetzt das sogenannte
IO-Tagging . Meist werden Hersteller von Clouds und virtuellen Maschinen zu dieser Entwicklung beitragen. Grob gesagt können Eingaben aus einer bestimmten Anwendung angegangen werden und ihr Vorrang eingeräumt werden. Die Datenbanken sind dafür noch nicht bereit, bleiben aber dran. Ich denke, es wird bald Mainstream sein.
Direkte E / A-Notizen
PostgreSQL unterstützt Direct IO nicht und es gibt eine Reihe von Problemen, die es schwierig machen, den Support zu aktivieren . Dies wird jetzt nur für den Wert unterstützt und nur, wenn die Replikation nicht aktiviert ist. Es ist erforderlich
, viel betriebssystemspezifischen
Code zu schreiben , und im Moment verzichtet jeder darauf.
Trotz der Tatsache, dass Linux stark auf die Idee von Direct IO und dessen Implementierung schwört, gehen alle Datenbanken dorthin. In Oracle und MySQL wird Direct IO häufig verwendet. PostgreSQL ist die einzige Datenbank, die Direct IO nicht toleriert.
Checkliste
So schützen Sie sich in PostgreSQL vor fsync-Überraschungen:
- Richten Sie Checkpoints so ein, dass sie weniger häufig und größer sind.
- Richten Sie den Hintergrundschreiber ein, um den Checkpoint zu unterstützen.
- Ziehen Sie am Autovakuum, damit keine unnötigen störenden E / A auftreten.
Der Tradition nach warten wir im November auf professionelle Entwickler hoch geladener Dienste in Skolkovo auf HighLoad ++ . Es bleibt noch ein Monat, um einen Bericht zu beantragen , aber wir haben bereits die ersten Berichte für das Programm akzeptiert. Melden Sie sich für unseren Newsletter an und erfahren Sie aus erster Hand mehr über neue Themen.