
Drücken Sie aus, was Wörter nicht vermitteln können. Fühle die verschiedensten Emotionen, die in einem Hurrikan von Gefühlen verflochten sind. Brechen Sie von der Erde, dem Himmel und sogar vom Universum selbst ab und begeben Sie sich auf eine Reise, auf der es keine Karten, keine Straßen, keine Zeichen gibt. eine ganze Geschichte zu erfinden, zu erzählen und erneut zu erleben, die immer einzigartig und unnachahmlich bleibt. All dies ermöglicht es Ihnen, Musik zu machen - eine Kunst, die es seit vielen tausend Jahren gibt und die unsere Ohren und Herzen erfreut.
Musik oder vielmehr Musik kann jedoch nicht nur zum ästhetischen Vergnügen dienen, sondern auch zur Übertragung von darin codierten Informationen, die für jedes Gerät bestimmt und für den Hörer unsichtbar sind. Heute werden wir mit Ihnen eine sehr ungewöhnliche Studie treffen, in der Doktoranden der Schweizerischen Technischen Hochschule Zürich bestimmte Daten unmerklich in Musikwerke für das menschliche Ohr einfügen konnten, wodurch Musik selbst zum Datenübertragungskanal wird. Wie genau haben sie ihre Technologie realisiert, sind die Melodien mit und ohne eingebettete Daten sehr unterschiedlich und was haben die praktischen Tests gezeigt? Dies erfahren wir aus dem Bericht der Forscher. Lass uns gehen.
Studienbasis
Forscher nennen ihre Technologie eine akustische Datenübertragungstechnik. Wenn der Sprecher die geänderte Melodie wiedergibt, nimmt eine Person sie wie gewohnt wahr, aber zum Beispiel kann ein Smartphone verschlüsselte Informationen zwischen Zeilen lesen, genauer gesagt zwischen Noten, wenn ich so sagen darf. Der wichtigste Aspekt bei der Implementierung dieser Methode der Datenübertragung ist, dass Wissenschaftler (die Tatsache, dass diese Leute noch Doktoranden sind, sie nicht davon abhalten, Wissenschaftler zu sein) die Geschwindigkeit und Zuverlässigkeit der Übertragung nennen, während sie den Pegel dieser Parameter unabhängig von der ausgewählten Audiodatei beibehalten. Die Psychoakustik, die die psychologischen und physiologischen Aspekte der menschlichen Wahrnehmung von Geräuschen untersucht, hilft, diese Aufgabe zu bewältigen.
Der Kern der akustischen Datenübertragung kann als OFDM (Orthogonal Frequency Division Multiplexing) bezeichnet werden, was zusammen mit der Anpassung der Unterträger an die Originalmusik im Laufe der Zeit die Maximierung der Nutzung des übertragenen Frequenzspektrums zur Übertragung von Informationen ermöglichte. Dank dessen konnte eine Übertragungsgeschwindigkeit von 412 Bit / s über eine Entfernung von 24 Metern erreicht werden (Fehlerrate <10%). Praktische Experimente mit 40 Freiwilligen bestätigten die Tatsache, dass es fast unmöglich ist, den Unterschied zwischen der ursprünglichen Melodie und der, in die die Informationen eingebettet waren, zu hören.
Wo kann diese Technologie in der Praxis angewendet werden? Die Forscher haben ihre eigene Antwort: Fast alle modernen Smartphones, Laptops und anderen Handheld-Geräte sind mit Mikrofonen ausgestattet, und an vielen öffentlichen Orten (Cafés, Restaurants, Einkaufszentren usw.) gibt es Lautsprecher mit Hintergrundmusik. Beispielsweise können Daten für die Verbindung mit einem Wi-Fi-Netzwerk in diese Hintergrundmelodie eingebettet werden, ohne dass zusätzliche Aktionen ausgeführt werden müssen.
Die allgemeinen Merkmale der akustischen Datenübertragung sind uns klar geworden. Nun wenden wir uns einer detaillierten Untersuchung der Struktur dieses Systems zu.
Systembeschreibung
Die Einbeziehung von Daten in eine Melodie erfolgt aufgrund der Frequenzmaskierung. In Zeitintervallen werden Maskierungsfrequenzen identifiziert und OFDM-Unterträger in der Nähe dieser Maskierungselemente werden mit Daten gefüllt.
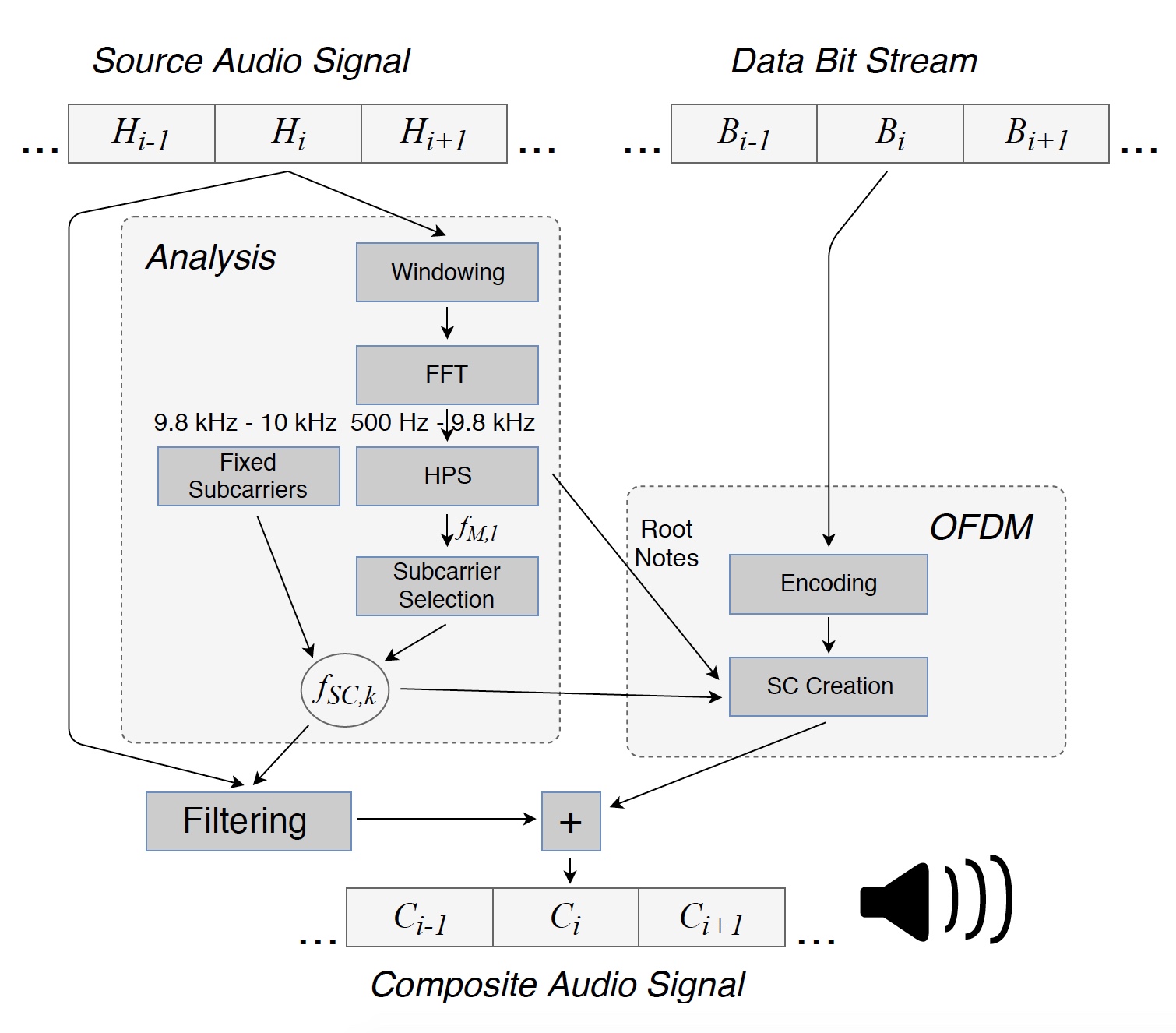 Bild 1: Konvertieren Sie die Quelldatei in ein zusammengesetztes Signal (Melodie + Daten), das über die Lautsprecher übertragen wird.
Bild 1: Konvertieren Sie die Quelldatei in ein zusammengesetztes Signal (Melodie + Daten), das über die Lautsprecher übertragen wird.Zunächst wird das ursprüngliche Audiosignal zur Analyse in aufeinanderfolgende Segmente unterteilt. Jedes solche Segment (H
i ) von L = 8820 Abtastwerten, das 200 ms entspricht, wird mit einem
Fenster * multipliziert, um Randeffekte zu minimieren.
Fenster * ist die Gewichtsfunktion, mit der Effekte aufgrund des Vorhandenseins von Nebenkeulen in Spektralschätzungen gesteuert werden.
Dann wurden die dominanten Frequenzen des Anfangssignals im Bereich von 500 Hz bis 9,8 kHz gefunden, was es ermöglichte, Maskierungsfrequenzen f
M, l für dieses Segment zu erhalten. Zusätzlich wurden Daten im kleinen Bereich von 9,8 bis 10 kHz übertragen, um den Ort der Unterträger im Empfänger zu bestimmen. Die Obergrenze des verwendeten Frequenzbereichs wurde aufgrund der geringen Empfindlichkeit des Mikrofons des Smartphones bei hohen Frequenzen auf 10 kHz eingestellt.
Die Maskierungsfrequenzen wurden für jedes analysierte Segment einzeln bestimmt. Unter Verwendung der HPS-Methode (harmonisches Produktspektrum) wurden drei dominante Frequenzen festgelegt, wonach sie auf die nächsten Noten der harmonischen chromatischen Skala gerundet wurden. So wurden die zwischen den Tasten C0 (16,35 Hz) und B0 (30,87 Hz) liegenden Hauptnoten f
F, i = 1 ... 3 erhalten. Basierend auf der Tatsache, dass die Hauptnoten für die Verwendung bei der Datenübertragung zu niedrig sind, wurden im Bereich von 500 Hz ... 9,8 kHz ihre höheren Oktaven 2
k f
F berechnet. Viele dieser Frequenzen (f
O, l 1 ) waren aufgrund der Natur von HPS stärker ausgeprägt.
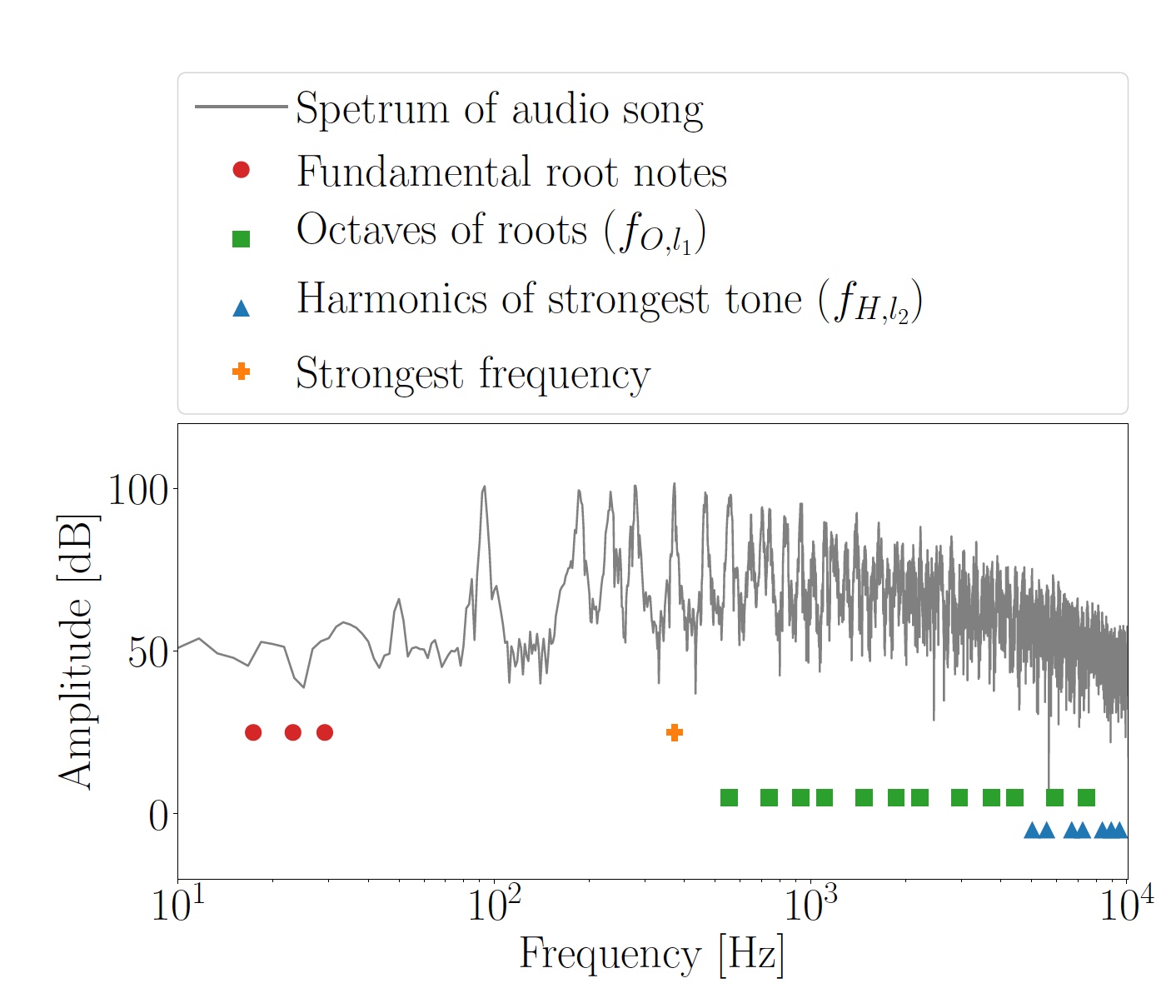 Bild Nr. 2: berechnete Oktaven f O, l 1 für die Hauptnoten und Harmonischen f H, l 2 des stärksten Tons.
Bild Nr. 2: berechnete Oktaven f O, l 1 für die Hauptnoten und Harmonischen f H, l 2 des stärksten Tons.Die Gesamtheit der Oktaven und Harmonischen wurde als Maskierungsfrequenzen verwendet, auf deren Grundlage OFDM-Frequenzen des Unterträgers f
SC, k erhalten wurden. Unterhalb und oberhalb jeder Maskierungsfrequenz wurden zwei Unterträger eingefügt.
Dann wurde das Spektrum des Audiosegments H
i bei den Unterträgerfrequenzen f
SC, k gefiltert. Dann wurde basierend auf den Informationsbits in Bi ein OFDM-Symbol erzeugt, aufgrund dessen das zusammengesetzte Segment C
i durch den Lautsprecher übertragen werden konnte. Die Werte und Phasen der Unterträger müssen so ausgewählt werden, dass der Empfänger die übertragenen Daten abrufen kann, während der Hörer keine Änderungen in der Melodie bemerkt.
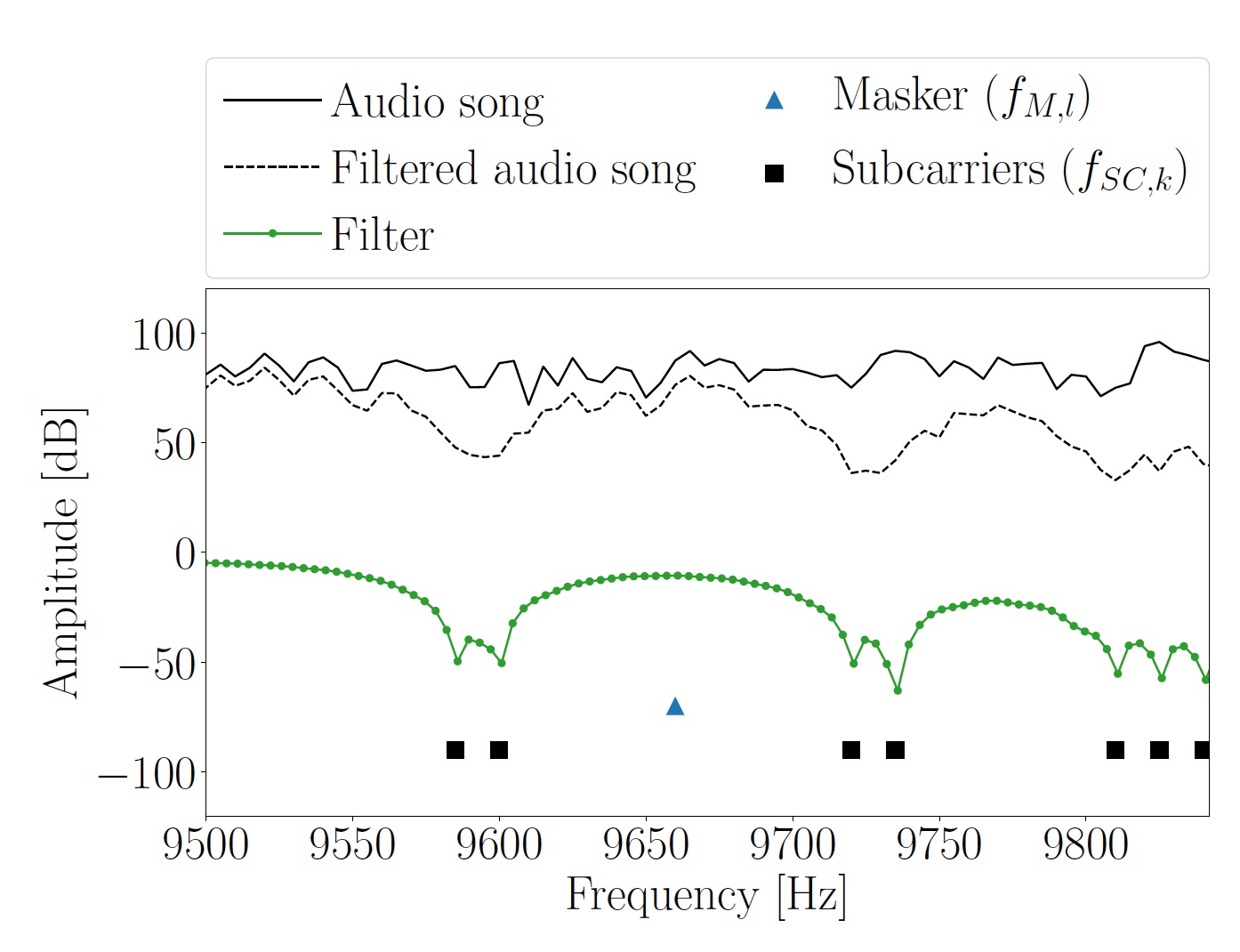 Bild 3: Darstellung des Spektrums und der Frequenz der Unterträger des Hi-Segments der Originalmelodie.
Bild 3: Darstellung des Spektrums und der Frequenz der Unterträger des Hi-Segments der Originalmelodie.Wenn ein Audiosignal mit den darin codierten Informationen über die Lautsprecher wiedergegeben wird, zeichnet es das Mikrofon des Empfangsgeräts auf. Um die Startpositionen der eingebetteten OFDM-Symbole zu ermitteln, müssen die Einträge zunächst durch die Bandpassfilterung übersprungen werden. Auf diese Weise wird der obere Frequenzbereich extrahiert, wenn zwischen den Unterträgern kein musikalisches Interferenzsignal vorhanden ist. Sie finden den Anfang von OFDM-Symbolen mit einem zyklischen Präfix.
Nach dem Erkennen des Beginns von OFDM-Symbolen erhält der Empfänger Informationen über die dominantesten Noten durch Decodieren des oberen Frequenzbereichs. Darüber hinaus ist OFDM gegenüber Schmalband-Interferenzquellen ausreichend robust, da sie nur einige der Unterträger betreffen.
Praktische Tests
Der KRK Rokit 8-Lautsprecher fungierte als Quelle für die veränderten Melodien, und das Nexus 5X-Smartphone spielte die Host-Seite.
 Bild 4: Der Unterschied zwischen den tatsächlichen Manifestationen von OFDM und den Korrelationsspitzen, die in Innenräumen in einem Abstand von 5 m zwischen Lautsprecher und Mikrofon gemessen wurden.
Bild 4: Der Unterschied zwischen den tatsächlichen Manifestationen von OFDM und den Korrelationsspitzen, die in Innenräumen in einem Abstand von 5 m zwischen Lautsprecher und Mikrofon gemessen wurden.Die meisten OFDM-Punkte reichen von 0 bis 25 ms, sodass Sie einen gültigen Start innerhalb des zyklischen Präfixes von 66,6 ms finden können. Die Forscher stellen fest, dass der Empfänger (in diesem Experiment ein Smartphone) berücksichtigt, dass OFDM-Symbole regelmäßig reproduziert werden, was ihre Erkennung verbessert.
Als erstes musste die Auswirkung der Entfernung auf die Bitfehlerrate (BER) überprüft werden. Zu diesem Zweck wurden drei Tests in verschiedenen Raumtypen durchgeführt: einem Korridor mit Teppichboden, einem Büro mit Linoleum auf dem Boden und einem Publikum mit Holzboden.
Das Lied „And The Cradle Will Rock“ von Van Halen wurde als „Testobjekt“ ausgewählt.Die Lautstärke wurde so eingestellt, dass der vom Smartphone in einem Abstand von 2 m vom Lautsprecher gemessene Schallpegel 63 dB betrug.
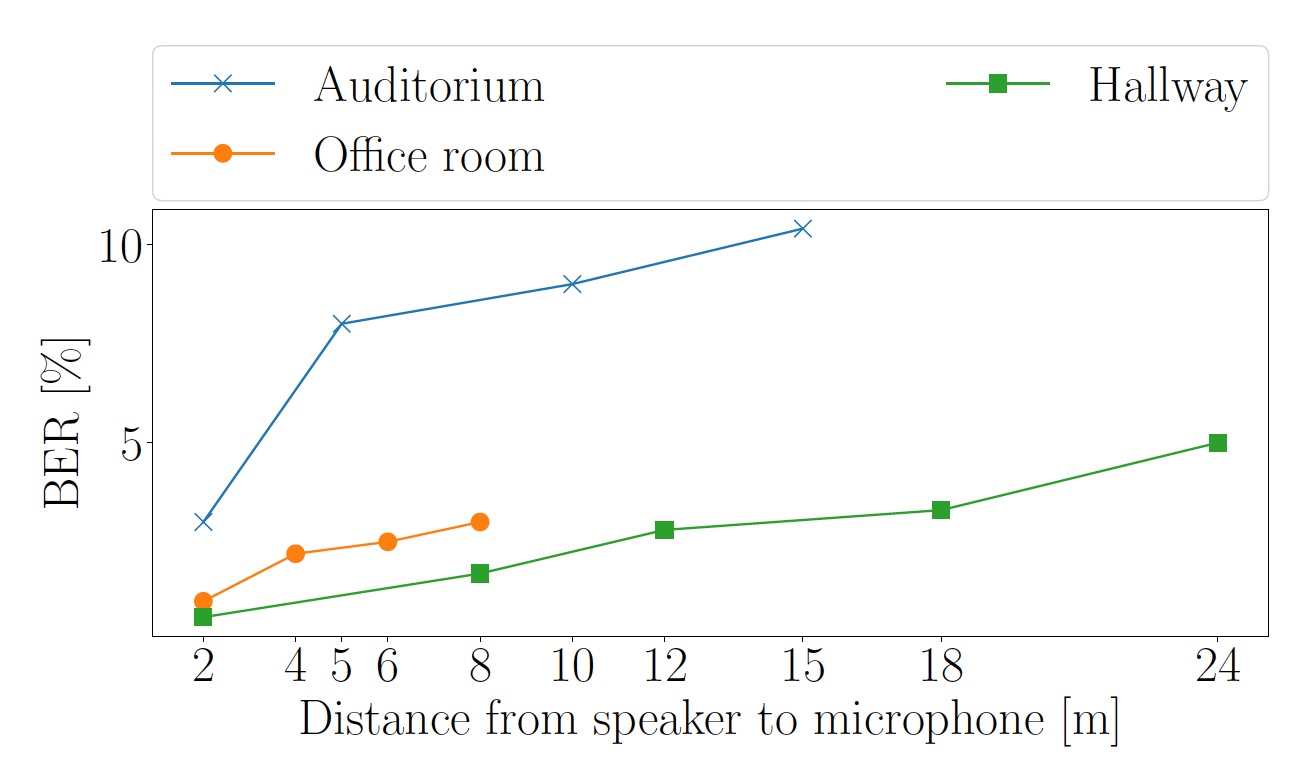 Bild Nr. 5: BER-Anzeigen in Abhängigkeit vom Abstand zwischen Lautsprecher und Mikrofon (blaue Linie - Publikum, grüner Korridor, orange - Büro).
Bild Nr. 5: BER-Anzeigen in Abhängigkeit vom Abstand zwischen Lautsprecher und Mikrofon (blaue Linie - Publikum, grüner Korridor, orange - Büro).Im Korridor wurde ein Geräusch von 40 dB von einem Smartphone in einer Entfernung von bis zu 24 Metern vom Lautsprecher aufgenommen. Im Publikum in einer Entfernung von 15 m betrug der Schall 55 dB, und im Büro in einer Entfernung von 8 Metern erreichte der vom Smartphone wahrgenommene Schallpegel 57 dB.
Aufgrund der Tatsache, dass das Publikum und das Büro nachhallen, überschreiten späte OFDM-Symbolechos die Länge des zyklischen Präfixes und erhöhen die BER.
Reverb * - eine allmähliche Abnahme der Schallintensität aufgrund ihrer Mehrfachreflexion.
Darüber hinaus demonstrierten die Forscher die Vielseitigkeit ihres Systems, indem sie es auf 6 verschiedene Songs aus drei Genres anwendeten (Tabelle unten).
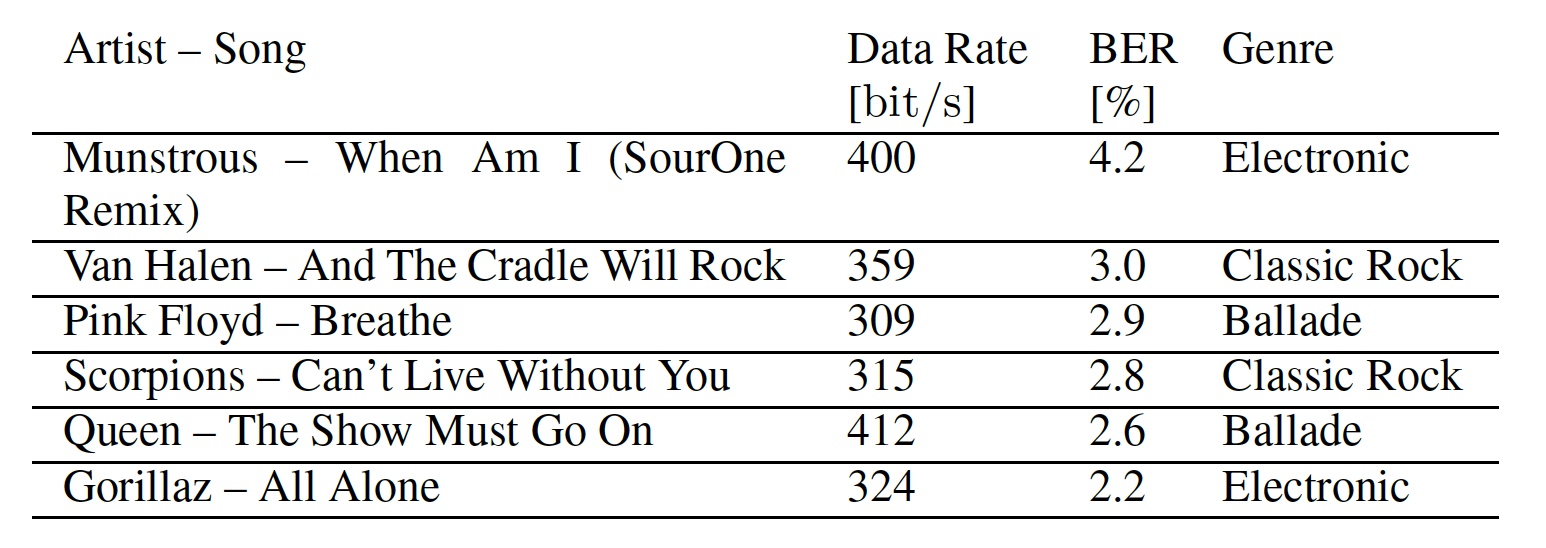 Tabelle Nr. 1: In Tests verwendete Songs.
Tabelle Nr. 1: In Tests verwendete Songs.Durch die Daten in der Tabelle können wir auch die Bitrate und die Bitfehlerraten für jeden Song sehen. Die Datenübertragungsgeschwindigkeit ist unterschiedlich, da die differentielle BPSK (Phase Shift Keying) besser funktioniert, wenn dieselben Unterträger verwendet werden. Dies ist möglich, wenn benachbarte Segmente dieselben Maskierungselemente enthalten. Kontinuierlich laute Songs bieten eine optimale Basis zum Ausblenden von Daten, da die Maskierungsfrequenzen in einem weiten Frequenzbereich stärker ausgeprägt sind. Schnell wechselnde Musik kann OFDM-Symbole aufgrund der festen Länge des Analysefensters nur teilweise maskieren.
Als nächstes begannen Leute, das System zu testen, die bestimmen sollten, welche Melodie original war und welche durch die darin eingebetteten Informationen modifiziert wurde. Zu diesem Zweck wurden 12-Sekunden-Auszüge von Liedern aus Tabelle Nr. 1 auf einer speziellen Website veröffentlicht.
Im ersten Experiment (E1) wurde jedem Teilnehmer entweder ein modifiziertes oder ein Originalfragment zum Hören zur Verfügung gestellt, und er musste entscheiden, ob dieses Fragment original oder verändert war. Im zweiten Experiment (E2) konnten die Teilnehmer beide Optionen so oft anhören, wie sie möchten, und dann entscheiden, welche original ist und welche geändert wird.
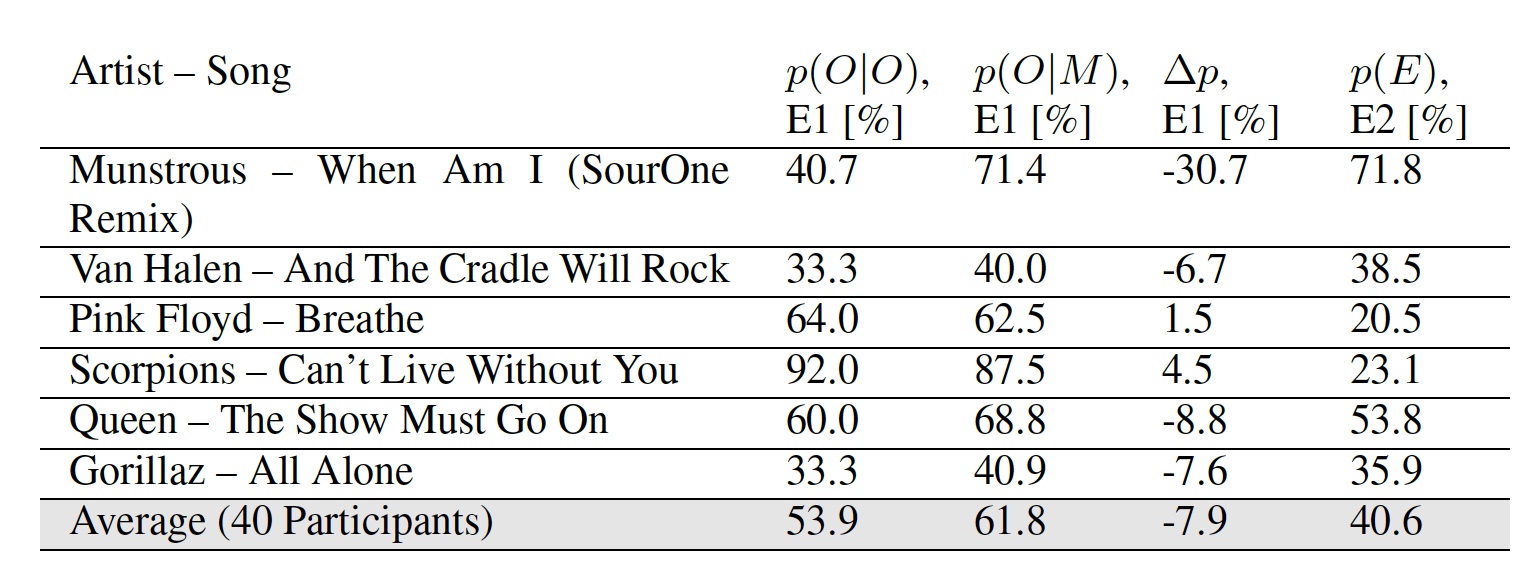 Tabelle Nr. 2: Ergebnisse der Versuche E1 und E2.
Tabelle Nr. 2: Ergebnisse der Versuche E1 und E2.Die Ergebnisse des ersten Experiments enthalten zwei Indikatoren: p ( | ) - Prozentsatz der Teilnehmer, die die ursprüngliche Melodie korrekt markiert haben, und p ( | ) - Prozentsatz der Teilnehmer, die die geänderte Version der Melodie als original markiert haben.
Es ist merkwürdig, dass einige Teilnehmer nach Ansicht der Forscher bestimmte modifizierte Melodien als origineller als das Original betrachteten. Der durchschnittliche Indikator beider Experimente legt nahe, dass der durchschnittliche Hörer den Unterschied zwischen einer regulären Melodie und der Melodie, in die die Daten eingebettet waren, nicht bemerkt.
Natürlich können Musikkenner und Musiker einige Ungenauigkeiten und verdächtige Elemente in den veränderten Melodien feststellen, aber diese Elemente sind nicht so bedeutend, dass sie Unbehagen verursachen.
Und jetzt können wir selbst am Experiment teilnehmen. Unten finden Sie zwei Optionen für dieselbe Melodie - original und modifiziert. Hörst du den Unterschied?
Die Originalversion der Melodievs.
Modifizierte Version der MelodieFür eine detailliertere Kenntnis der Nuancen der Studie empfehle ich Ihnen, den
Bericht der Forschungsgruppe zu lesen.
Unter
diesem Link können Sie auch das ZIP-Archiv der Audiodateien der in der Studie verwendeten Original- und modifizierten Melodien herunterladen.
Nachwort
In dieser Arbeit beschrieben Doktoranden der Schweizerischen Hochschule Zürich ein erstaunliches Datenübertragungssystem innerhalb der Musik. Zu diesem Zweck verwendeten sie eine Frequenzmaskierung, mit der Daten in eine vom Sprecher gespielte Melodie eingebettet werden konnten. Diese Melodie wird vom Mikrofon des Geräts wahrgenommen, das die verborgenen Daten erkennt und dekodiert, während der durchschnittliche Hörer den Unterschied nicht einmal bemerkt. In Zukunft planen die Jungs, ihr System weiterzuentwickeln und fortschrittlichere Methoden zum Einbetten von Daten in Audio zu wählen.
Wenn sich jemand etwas Ungewöhnliches einfallen lässt und vor allem arbeitet, sind wir immer glücklich. Noch mehr Freude ist jedoch, dass diese Erfindung von jungen Menschen geschaffen wurde. Die Wissenschaft hat keine Altersbeschränkungen. Und wenn junge Leute Wissenschaft für langweilig halten, dann wird sie sozusagen im falschen Winkel dargestellt. Wie wir wissen, ist die Wissenschaft eine erstaunliche Welt, die immer wieder in Erstaunen versetzt.
Freitag off-top:
Da es sich um Musik und insbesondere um Rockmusik handelt, ist hier eine wunderbare Reise durch die Weiten des Rock.
Königin, Radio Ga Ga (1984).
Vielen Dank für Ihre Aufmerksamkeit, bleiben Sie neugierig und wünschen Sie allen ein schönes Wochenende! :) :)
Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung
aufgeben oder Ihren Freunden empfehlen, einen
Rabatt von 30% für Habr-Benutzer auf ein einzigartiges Analogon von Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s von $ 20 oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
Dell R730xd 2 mal günstiger? Nur wir haben
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2,6 GHz 14C 64 GB DDR4 4 x 960 GB SSD 1 Gbit / s 100 TV von 199 US-Dollar in den Niederlanden! Dell R420 - 2x E5-2430 2,2 GHz 6C 128 GB DDR3 2x960 GB SSD 1 Gbit / s 100 TB - ab 99 US-Dollar! Lesen Sie mehr über
den Aufbau eines Infrastrukturgebäudes. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?