Jetzt kann das Vision-Framework Text real erkennen und nicht mehr wie zuvor. Wir freuen uns darauf, wann wir dies auf Dodo IS anwenden können. In der Zwischenzeit eine Übersetzung eines Artikels über das Erkennen von Karten aus dem Brettspiel Magic The Gathering und das Extrahieren von Textinformationen aus diesen.
Das Vision-Framework wurde 2017 zusammen mit iOS 11 erstmals auf der WWDC der Öffentlichkeit vorgestellt.
Vision wurde entwickelt, um Entwicklern beim Klassifizieren und Identifizieren von Objekten, horizontalen Ebenen, Barcodes, Gesichtsausdrücken und Text zu helfen.
Es gab jedoch ein Problem mit der Texterkennung: Vision konnte den Ort finden, an dem sich der Text befindet, aber die eigentliche Texterkennung fand nicht statt. Natürlich war es schön, den Begrenzungsrahmen um einzelne Textfragmente zu sehen, aber dann mussten sie herausgezogen und unabhängig voneinander erkannt werden.
Dieses Problem wurde im Vision-Update behoben, das in iOS 13 enthalten war. Jetzt bietet das Vision-Framework eine echte Texterkennung.
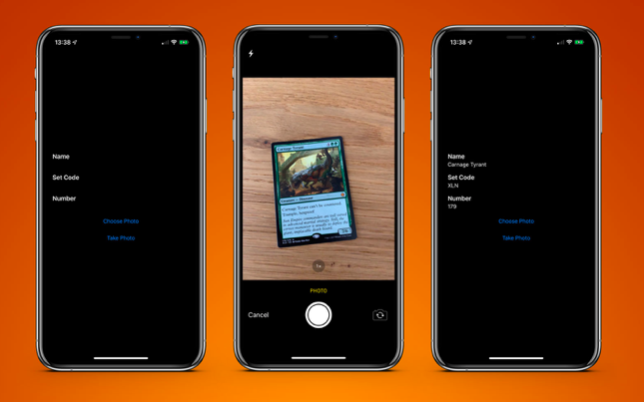
Um dies zu testen, habe ich eine sehr einfache Anwendung erstellt, die eine Karte aus dem Brettspiel Magic The Gathering erkennen und Textinformationen daraus extrahieren kann:
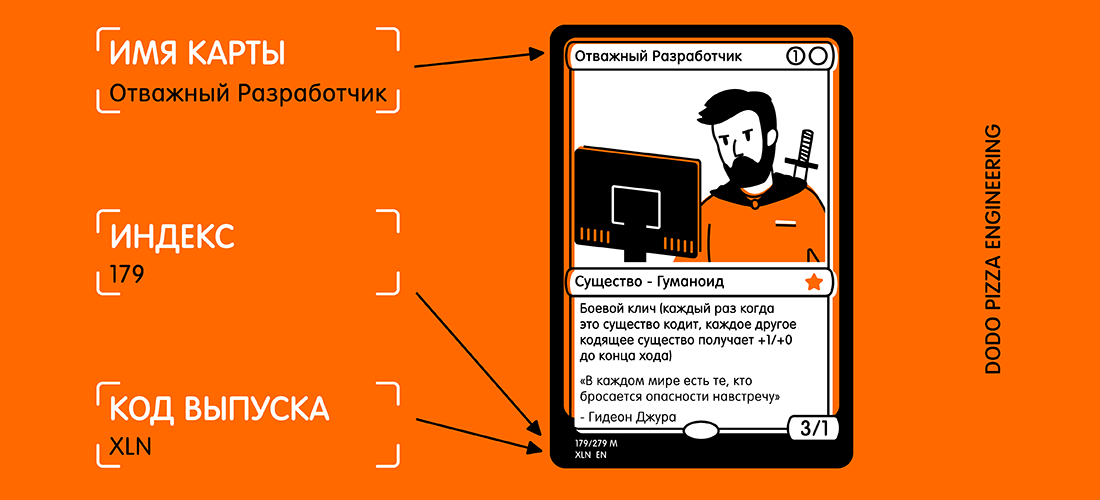
- Kartenname;
- Release-Code;
- Sammlungsnummer (auch bekannt als Postleitzahl).
Hier ist ein Beispiel einer Karte und eines ausgewählten Textes, den ich erhalten möchte.

Wenn Sie sich die Karte ansehen, denken Sie vielleicht: "Dieser Text ist ziemlich klein, und es gibt viele andere Texte auf der Karte, die stören können." Für Vision ist dies jedoch kein Problem.
Zuerst müssen wir eine
VNRecognizeTextRequest erstellen. Im Wesentlichen ist dies eine Beschreibung dessen, was wir zu erkennen hoffen, sowie eine Einstellung der Erkennungssprache und ein Genauigkeitsniveau:
let request = VNRecognizeTextRequest(completionHandler: self.handleDetectedText) request.recognitionLevel = .accurate request.recognitionLanguages = ["en_GB"]
Der Abschlussblock hat das Formular
handleDetectedText(request: VNRequest?, error: Error?) . Wir übergeben es an den
VNRecognizeTextRequest Konstruktor und legen dann die verbleibenden Eigenschaften fest.
Es stehen zwei Stufen der Erkennungsgenauigkeit zur Verfügung:
.fast und
.accurate . Da unsere Karte unten einen eher kleinen Text enthält, habe ich eine höhere Genauigkeit gewählt. Die schnellere Option ist wahrscheinlich besser für große Textmengen geeignet.
Ich habe die Erkennung auf britisches Englisch beschränkt, da alle meine Karten darin enthalten sind. Sie können mehrere Sprachen angeben, aber Sie müssen verstehen, dass das Scannen und Erkennen für jede weitere Sprache etwas länger dauern kann.
Es gibt zwei weitere erwähnenswerte Eigenschaften:
customWords : Sie können ein Array von Zeichenfolgen hinzufügen, die über dem integrierten Lexikon verwendet werden sollen. Dies ist nützlich, wenn Ihr Text ungewöhnliche Wörter enthält. Ich habe die Option für dieses Projekt nicht verwendet. Aber wenn ich die kommerzielle Magic The Gathering-Kartenerkennungsanwendung machen würde, würde ich einige der komplexesten Karten hinzufügen (zum Beispiel Fblthp, the Lost ), um Probleme zu vermeiden.minimumTextHeight : Dies ist ein Float-Wert. Es gibt die Größe relativ zur Höhe des Bildes an, bei der der Text nicht mehr erkannt werden soll. Wenn ich diesen Scanner nur erstellen würde, um den Namen der Karte zu erhalten, wäre es nützlich, alle anderen Texte zu löschen, die nicht benötigt werden. Aber ich brauche die kleinsten Textstücke, deshalb habe ich diese Eigenschaft vorerst ignoriert. Wenn Sie kleine Texte ignorieren, ist die Erkennungsgeschwindigkeit natürlich höher.
Nachdem wir unsere Anfrage erhalten haben, müssen wir sie zusammen mit dem Bild an den Request-Handler weitergeben:
let requests = [textDetectionRequest] let imageRequestHandler = VNImageRequestHandler(cgImage: cgImage, orientation: .right, options: [:]) DispatchQueue.global(qos: .userInitiated).async { do { try imageRequestHandler.perform(requests) } catch let error { print("Error: \(error)") } }
Ich verwende das Bild direkt von der Kamera und konvertiere es von
UIImage in
CGImage . Dies wird im
VNImageRequestHandler zusammen mit dem Orientierungsflag verwendet, damit der Handler besser versteht, welchen Text er erkennen soll.
Im Rahmen dieser Demo verwende ich das Telefon nur im Hochformat. Also füge ich natürlich die Orientierung
.right . Also Padaji!
Es stellt sich heraus, dass die Ausrichtung der Kamera auf Ihrem Gerät vollständig von der Drehung des Geräts getrennt ist und immer nach links betrachtet wird (wie 2009 standardmäßig, um Fotos aufzunehmen, muss das Telefon im Querformat gehalten werden). Natürlich haben sich die Zeiten geändert und wir nehmen Fotos und Videos im Hochformat auf, aber die Kamera ist immer noch nach links ausgerichtet.
Sobald unser Handler konfiguriert ist, gehen wir mit der Priorität
.userInitiated in den Stream und versuchen, unsere Anforderungen zu erfüllen. Möglicherweise stellen Sie fest, dass dies eine Reihe von Abfragen ist. Dies geschieht, weil Sie versuchen können, mehrere Daten in einem Durchgang zu extrahieren (d. H. Gesichter und Text aus demselben Bild zu identifizieren). Wenn keine Fehler vorliegen, wird der mit unserer Anfrage erstellte Rückruf aufgerufen, nachdem der Text erkannt wurde:
func handleDetectedText(request: VNRequest?, error: Error?) { if let error = error { print("ERROR: \(error)") return } guard let results = request?.results, results.count > 0 else { print("No text found") return } for result in results { if let observation = result as? VNRecognizedTextObservation { for text in observation.topCandidates(1) { print(text.string) print(text.confidence) print(observation.boundingBox) print("\n") } } } }
Unser Handler gibt unsere Abfrage zurück, die jetzt die Eigenschaft results hat. Jedes Ergebnis ist eine
VNRecognizedTextObservation , die für uns mehrere Optionen für das Ergebnis bietet (im Folgenden - die Kandidaten).
Sie können bis zu 10 Kandidaten für jede Einheit des erkannten Textes erhalten, die in absteigender Reihenfolge des Vertrauens sortiert sind. Dies kann nützlich sein, wenn Sie eine bestimmte Terminologie haben, die der Parser beim ersten Versuch falsch erkennt. Bestimmt aber später richtig, auch wenn er weniger von der Richtigkeit des Ergebnisses überzeugt ist.
In diesem Beispiel benötigen wir nur das erste Ergebnis, also durchlaufen wir
observation.topCandidates(1) und extrahieren sowohl Text als auch Vertrauen. Während der Kandidat selbst einen anderen Text und ein anderes Vertrauen hat, bleibt die
.boundingBox dieselbe.
.boundingBox verwendet ein normalisiertes Koordinatensystem mit dem Ursprung in der unteren linken Ecke. Wenn es also in Zukunft in UIKit verwendet werden soll, muss es zur Vereinfachung konvertiert werden.
Das ist fast alles was Sie brauchen. Wenn ich ein
Foto der Karte durchlaufe, erhalte ich auf dem iPhone XS Max in weniger als 0,5 Sekunden das folgende Ergebnis:
Carnage Tyrant 1.0 (0.2654155572255453, 0.6955686092376709, 0.18710780143737793, 0.019915008544921786) Creature 1.0 (0.26317582130432127, 0.423814058303833, 0.09479101498921716, 0.013565015792846635) Dinosaur 1.0 (0.3883238156636556, 0.42648010253906254, 0.10021591186523438, 0.014479541778564364) Carnage Tyrant can't be countered. 1.0 (0.26538230578104655, 0.3742666244506836, 0.4300231456756592, 0.024643898010253906) Trample, hexproof 0.5 (0.2610074838002523, 0.34864263534545903, 0.23053167661031088, 0.022259855270385653) Sun Empire commanders are well versed 1.0 (0.2619712670644124, 0.31746063232421873, 0.45549616813659666, 0.022649812698364302) in advanced martial strategy. Still, the 1.0 (0.2623249689737956, 0.29798884391784664, 0.4314465204874674, 0.021180248260498136) correct maneuver is usually to deploy the 1.0 (0.2620727062225342, 0.2772137641906738, 0.4592740217844645, 0.02083740234375009) giant, implacable death lizard. 1.0 (0.2610833962758382, 0.252408218383789, 0.3502468903859457, 0.023736238479614258) 7/6 0.5 (0.6693102518717448, 0.23347826004028316, 0.04697717030843107, 0.018937730789184593) 179/279 M 1.0 (0.24829587936401368, 0.21893787384033203, 0.08339192072550453, 0.011646795272827193) XLN: EN N YEONG-HAO HAN 0.5 (0.246867307027181, 0.20903720855712893, 0.19095951716105145, 0.012227916717529319) TN & 0 2017 Wizards of the Coast 1.0 (0.5428387324015299, 0.21133480072021482, 0.19361832936604817, 0.011657810211181618)
Das ist unglaublich! Jedes Textstück wurde erkannt, in einen eigenen Begrenzungsrahmen gelegt und als Ergebnis mit einer Konfidenzbewertung von 1,0 zurückgegeben.
Auch ein sehr kleines Copyright ist meist richtig. All dies wurde auf einem 3024 x 4032-Bild mit einem Gewicht von 3,1 MB durchgeführt. Der Vorgang wäre noch schneller, wenn ich das Bild zuerst verkleinern würde. Es ist auch erwähnenswert, dass dieser Prozess bei den neuen A12-Bionic-Chips, die über eine spezielle neuronale Engine verfügen, viel schneller ist.
Wenn der Text erkannt wird, müssen Sie als letztes die benötigten Informationen herausholen. Ich werde hier nicht den gesamten Code einfügen, aber die Schlüssellogik besteht darin, über jede
.boundingBox zu
.boundingBox um die
.boundingBox bestimmen, sodass ich den Text in der unteren linken Ecke und in der oberen linken Ecke auswählen und alles weiter rechts ignorieren kann.
Das Endergebnis ist eine Scan-Karten-Anwendung, die das Ergebnis in weniger als einer Sekunde an mich zurücksendet.
PS Tatsächlich brauche ich nur einen Versionscode und eine Sammlungsnummer (es ist ein Index). Anschließend können sie in der Scryfall-API verwendet werden, um alle möglichen Informationen zu dieser Karte abzurufen, einschließlich der Spielregeln und der Kosten.
Eine Beispielanwendung ist auf
GitHub verfügbar.