
Ab einem bestimmten Stadium der Reife der Informationssicherheit beginnen viele Unternehmen darüber nachzudenken, wie sie Informationen über Cyber-Bedrohungen erhalten und verwenden können, die für sie relevant sind. Abhängig von den Branchenspezifikationen der Organisation können verschiedene Arten von Bedrohungen Interesse wecken. Der Ansatz zur Verwendung solcher Informationen wurde von Lockheed Martin in der Material
Intelligence Driven Defense entwickelt .
Glücklicherweise haben Informationssicherheitsdienste viele Quellen, um sie zu erhalten, und sogar eine separate Klasse von Lösungen - die Threat Intelligence Platform (TIP), mit der Sie die Prozesse ihres Empfangs, ihrer Generierung und Integration in Sicherheitstools verwalten können.
Als Zentrum für die Überwachung und Reaktion auf Vorfälle im Bereich der Informationssicherheit ist es für uns äußerst wichtig, dass die Informationen über die Cyber-Bedrohungen, die wir erhalten und generieren, relevant, anwendbar und vor allem überschaubar sind. Denn die Sicherheit von Organisationen, die uns den Schutz ihrer Infrastruktur anvertraut haben, hängt davon ab.
Wir haben uns entschlossen, unsere Vision von TI bei Jet CSIRT zu teilen und über den Versuch zu sprechen, verschiedene potenziell nützliche Ansätze für das Management von Cyber-Bedrohungsinformationen anzupassen.
Auf dem Gebiet der Cybersicherheit arbeitet wenig am Prinzip des Set'n'Pget. Die Firewall blockiert keine Pakete, bis die Filter konfiguriert sind, IPS findet keine Anzeichen von böswilliger Aktivität im Datenverkehr, bis Signaturen darauf heruntergeladen werden, und SIEM beginnt, Korrelationsregeln unabhängig zu schreiben und Fehlalarme zu ermitteln. Threat Intelligence ist keine Ausnahme.
Die Komplexität der Implementierung einer Lösung, die das Threat Intelligence-Konzept wirklich widerspiegelt, liegt in ihrer Definition.
Threat Intelligence ist ein Prozess der Erforschung und Analyse
bestimmter Informationsquellen, um
Informationen über aktuelle Cyber-Bedrohungen zu erhalten und zu sammeln, um Maßnahmen zur Verbesserung der Cybersicherheit und zur Sensibilisierung einer
bestimmten Informationssicherheitsgemeinschaft für Informationssicherheit durchzuführen.
Bestimmte Quellen können sein:
- Offene Informationsquellen. All dies kann mit Google, Yandex, Bing und spezielleren Tools wie Shodan, Censys, nmap gefunden werden. Der Prozess der Analyse dieser Quellen wird als Open Source Intelligence (OSINT) bezeichnet. Es ist zu beachten, dass die über OSINT erhaltenen Informationen aus offenen (nicht klassifizierten) Quellen stammen. Wenn die Quelle bezahlt wird, wird sie möglicherweise nicht geheim, was bedeutet, dass die Analyse einer solchen Quelle ebenfalls OSINT ist.
- Medien. Alles, was in den Medien und auf den sozialen Plattformen Sosial Media Intelligence (SOCMINT) zu finden ist. Diese Art der Datenerfassung ist im Wesentlichen ein wesentlicher Bestandteil von OSINT.
- Geschlossene Veranstaltungsorte und Foren, in denen Details zu bevorstehenden Cyberkriminalität (Deepweb, Darknet) besprochen werden. Meistens erhalten Sie in den Schattenbereichen Informationen zu DDoS-Angriffen oder zum Erstellen einer neuen Malware, die Hacker dort verkaufen möchten.
- Menschen mit Zugang zu Informationen. „Kollegen“ und Personen, die Social-Engineering-Methoden erliegen, sind ebenfalls Quellen, die Informationen austauschen können.
Es gibt ernstere Methoden, die nur spezialisierten Diensten zur Verfügung stehen. In diesem Fall können die Daten entweder von Agenten stammen, die in einer Cyberkriminalitätsumgebung verdeckt arbeiten, oder von Personen, die an Cyberkriminalität beteiligt sind und an der Untersuchung mitarbeiten. Mit einem Wort, all dies wird HUMan Intelligence (HUMINT) genannt. Natürlich üben wir HUMINT bei Jet CSIRT nicht.
Es ist unmöglich, all diese Prozesse in eine „Box“ zu packen, die autonom funktioniert. Wenn es um die TI-Lösung geht, besteht ihr Hauptversprechen für den Verbraucher höchstwahrscheinlich in den
Informationen über Cyber-Bedrohungen und deren Verwaltung, auf die die
Informationssicherheitsgemeinschaft in der einen oder anderen Form zugreifen kann.
Informationen zu Cyber-Bedrohungen
Im Jahr 2015 veröffentlichte MWR Infosecurity zusammen mit CERT und dem National Infrastructure Protection Centre von Großbritannien eine
Informationsbroschüre , in der vier Kategorien von Informationen hervorgehoben wurden, die sich aus dem TI-Prozess ergeben. Diese Klassifizierung wird jetzt allgemein angewendet:
- Betrieb Informationen über bevorstehende und laufende Cyber-Angriffe, die in der Regel von speziellen Diensten als Ergebnis des HUMINT-Prozesses oder durch Abhören von Kommunikationskanälen von Angreifern erhalten werden.
- Strategisch. Informationen zur Risikobewertung für ein Unternehmen, das Opfer eines Cyberangriffs werden soll. Sie enthalten keine technischen Informationen und dürfen in keiner Weise für Schutzausrüstung verwendet werden.
- Taktisch. Informationen zu den Techniken, Taktiken, Verfahren (TTP) und Tools, die Cyberkriminelle im Rahmen einer böswilligen Kampagne verwenden.
Ein typisches Beispiel: Kürzlich eröffnetes LockerGoga- Werkzeug : cmd.exe.
- Technik : Es wird ein Crypto-Locker gestartet, der alle Dateien auf dem Computer des Opfers (einschließlich Windows-Kerneldateien) mithilfe des AES-Algorithmus im Blockverschlüsselungsmodus (CTR) mit einer Schlüssellänge von 128 Bit verschlüsselt. Der Dateischlüssel und der Initialisierungsvektor (IV) werden unter Verwendung des RSA-1024-Algorithmus unter Verwendung der MGF1-Maskenerzeugungsfunktion (SHA-1) verschlüsselt. Um die kryptografische Stärke dieser Funktion zu erhöhen, wird wiederum das OAEP-Füllschema verwendet. Die verschlüsselten Schlüssel der Datei und IV werden dann im Header der verschlüsselten Datei selbst gespeichert.
- Vorgehensweise : Außerdem startet die Malware mehrere parallele untergeordnete Prozesse, verschlüsselt nur alle 80.000 Bytes jeder Datei und überspringt die nächsten 80.000 Bytes, um die Verschlüsselung zu beschleunigen.
- Taktik : Dann ist ein Lösegeld in Bitcoins erforderlich, damit der Schlüssel die Dateien wieder entschlüsselt.
Lesen Sie
hier mehr.
Solche Informationen sind das Ergebnis einer gründlichen Untersuchung einer böswilligen Kampagne, die ziemlich lange dauern kann. Die Ergebnisse dieser Studien sind Newsletter und Berichte von kommerziellen Unternehmen wie Cisco Talos, FireEye, Symantec, Group-IB, Kaspersky GREAT, Regierungsorganisationen und Aufsichtsbehörden (FinCERT, NCCCI, US-CERT, FS-ISAC) sowie unabhängigen Forschern.
Taktische Informationen können und sollten für Sicherheitsausrüstung und beim Aufbau einer Netzwerkarchitektur verwendet werden.
- Technisch Informationen zu den Anzeichen und Essenzen böswilliger Aktivitäten oder zu deren Identifizierung.
Bei der Analyse von Malware wurde beispielsweise festgestellt, dass sie sich als PDF-Datei mit den folgenden Parametern verbreitet:
- benannt price_december.pdf ,
- Starten des Prozesses pureevil.exe ,
- mit einem MD5-Hash von 81a284a2b84dde3230ff339415b0112a ,
- Das versucht, Verbindungen mit dem C & C-Server unter 123.45.67.89 auf TCP-Port 1337 herzustellen .
In diesem Beispiel sind die Entitäten die Datei- und Prozessnamen, der Hashwert, die Serveradresse und die Portnummer. Zeichen sind die Interaktion dieser Entitäten zwischen sich und den Infrastrukturkomponenten: Starten des Prozesses, ausgehende Netzwerkinteraktion mit dem Server, Ändern von Registrierungsschlüsseln usw.
Diese Informationen stehen in engem Zusammenhang mit dem Konzept des Kompromissindikators (IoC). Technisch gesehen sagt die Entität nichts aus, solange sie nicht in der Infrastruktur gefunden wird. Wenn Sie jedoch beispielsweise im Netzwerk feststellen, dass versucht wurde, den Host unter
123.45.67.89:1337 oder mit dem Start des Prozesses
pureevil.exe und sogar mit der MD5-Summe
81a284a2b84dde3230ff339415b0112a mit dem C & C-Server zu
verbinden , ist dies bereits ein Indikator für einen Kompromiss.
Das heißt, der Indikator für einen Kompromiss ist eine Kombination aus bestimmten Entitäten, Anzeichen böswilliger Aktivitäten und Kontextinformationen, die eine Antwort von Informationssicherheitsdiensten erfordern.
Gleichzeitig ist es im Bereich der Informationssicherheit üblich, Indikatoren für Kompromisse nur Entitäten aufzurufen, die von jemandem in böswilliger Aktivität bemerkt wurden (IP-Adressen, Domänennamen, Hash-Summen, URLs, Dateinamen, Registrierungsschlüssel usw.).
Die Erkennung eines Kompromissindikators signalisiert nur, dass diese Tatsache berücksichtigt und analysiert werden sollte, um weitere Maßnahmen zu bestimmen. Es wird grundsätzlich nicht empfohlen, den Indikator auf dem SZI sofort zu blockieren, ohne alle Umstände zu klären. Aber wir werden weiter darüber sprechen.
Kompromissindikatoren sind auch bequem unterteilt in:
- Atomic. Sie enthalten nur eine Funktion, die nicht weiter unterteilt werden kann, zum Beispiel:
- IP-Adresse des C & C-Servers - 123.45.67.89
- Die Hash-Menge beträgt 81a284a2b84dde3230ff339415b0112a
- Verbund Sie enthalten zwei oder mehr Entitäten, die bei böswilligen Aktivitäten auftreten, zum Beispiel:
- Sockel - 123.45.67.89:5900
- Die Datei price_december.pdf erzeugt den Prozess pureevil.exe mit einem Hash von 81a284a2b84dde3230ff339415b0112a
Offensichtlich weist die Erkennung eines zusammengesetzten Indikators eher auf einen Kompromiss des Systems hin.
Die technischen Informationen können auch verschiedene Entitäten zum Erkennen und Blockieren von Kompromissindikatoren enthalten, z. B. Yara-Regeln, Korrelationsregeln für SIEM, verschiedene Signaturen zum Erkennen von Angriffen und Malware. Somit können technische Informationen eindeutig auf Schutzausrüstung angewendet werden.
Probleme der effizienten Nutzung technischer TI-Informationen
Am schnellsten können TI-Dienstleister genau die technischen Informationen über Cyber-Bedrohungen erhalten, und wie sie angewendet werden, ist eine Frage für den Verbraucher. Hier liegen die meisten Probleme.
Beispielsweise können Kompromissindikatoren in mehreren Phasen der Reaktion auf einen IS-Vorfall angewendet werden:
- in der Vorbereitungsphase (Vorbereitung) proaktive Blockierung des Indikators im SIS (natürlich nach der falsch positiven Ausnahme);
- in der Erkennungsphase Verfolgung der Funktionsweise der Regeln zur Identifizierung des Indikators in Echtzeit durch Überwachungstools (SIEM, SIM, LM);
- in der Phase der Untersuchung des Vorfalls unter Verwendung des Indikators bei nachträglichen Kontrollen;
- im Stadium einer eingehenderen Analyse der betroffenen Assets, beispielsweise bei der Analyse des Quellcodes einer böswilligen Probe.
Je mehr manuelle Arbeit in der einen oder anderen Phase erforderlich ist, desto mehr Analysen (die das Wesentliche des Indikators mit Kontextinformationen bereichern) werden von Anbietern von Kompromissindikatoren benötigt. In diesem Fall handelt es sich um externe Kontextinformationen, dh um das, was andere bereits über diesen Indikator wissen.
In der Regel werden Kompromissindikatoren in Form von sogenannten
Bedrohungs-Feeds oder
Feeds geliefert. Dies ist eine so strukturierte Liste von Bedrohungsdaten in verschiedenen Formaten.
Das Folgende ist beispielsweise ein böswilliger Hash-Feed im JSON-Format:

Dies ist ein Beispiel für einen guten kontextreichen Feed:
- enthält einen Link zur Bedrohungsanalyse;
- Name, Art und Kategorie der Bedrohung;
- Zeitstempel der Veröffentlichung.
All dies ermöglicht es Ihnen, die Kompromissindikatoren aus diesem Feed beim Hochladen auf Informationsschutz- und Überwachungstools zu verwalten und die Zeit für die Analyse von Vorfällen zu reduzieren, die daran gearbeitet haben.
Es gibt jedoch auch andere Qualitäts-Feeds (normalerweise Open Source). Das Folgende ist beispielsweise ein Beispiel für die Adressen von vermeintlichen C & C-Servern von einer Open Source:

Wie Sie sehen, fehlen hier Kontextinformationen vollständig. Jede dieser IP-Adressen kann einen legitimen Dienst hosten, von denen einige Yandex- oder Google-Crawler sein können, die Websites indizieren. Über diese Liste können wir nichts sagen.
Das Fehlen oder die Unzulänglichkeit des Kontexts in Bedrohungs-Feeds ist eines der Hauptprobleme für Verbraucher technischer Informationen. Ohne Kontext ist die Entität aus dem Feed nicht anwendbar und in der Tat kein Indikator für einen Kompromiss. Mit anderen Worten, das Blockieren einer IP-Adresse in SZI sowie das Hochladen dieses Feeds in Überwachungstools führt wahrscheinlich zu einer großen Anzahl von Fehlalarmen (False Positive - FP).
Wenn wir die Verwendung von Kompromissindikatoren unter dem Gesichtspunkt der Erkennung von Überwachungswerkzeugen in Betracht ziehen, ist dieser Prozess vereinfacht eine Folge:
- Indikatorintegration in Überwachungsinstrumente;
- Auslösen der Indikatorerkennungsregel;
- IS Service Response Analyse.
Aufgrund des Vorhandenseins einer Humanressource in dieser Reihenfolge sind wir daran interessiert, nur die Fälle zu analysieren, in denen Indikatoren identifiziert werden, die tatsächlich auf eine Bedrohung für das Unternehmen hinweisen, und die Anzahl der FPs zu verringern.
Grundsätzlich werden Fehlalarme ausgelöst, wenn die Essenz beliebter Ressourcen (Google, Microsoft, Yandex, Adobe usw.) als potenziell bösartig erkannt wird.
Ein einfaches Beispiel: Es wird Malware untersucht, die den Host erreicht hat. Es wird festgestellt, dass der Internetzugriff durch Abfragen von
update.googleapis.com überprüft wird . Das Asset
update.googleapis.com wird im Bedrohungsfeed als Indikator für einen Kompromiss aufgeführt und ruft FP auf. Ebenso kann die Hash-Summe einer legitimen Bibliothek oder Datei, die von Malware verwendet wird, öffentliche DNS-Adressen, Adressen verschiedener Crawler und Spider, Ressourcen zum Überprüfen gesperrter CRL-Zertifikate (Certificate Revocation List) und URL-Abkürzungen (bit.ly, goo) in den Feed gelangen. gl usw.).
Das Testen dieser Art von Reaktion, die nicht in einem externen Kontext angereichert ist, kann für den Analysten ziemlich viel Zeit in Anspruch nehmen, während der ein realer Vorfall übersehen werden kann.
Übrigens gibt es Indikator-Feeds, die FP auslösen können. Ein solches Beispiel ist die
Ressource für die
Fehlwarnliste .
Priorisierung von Kompromissindikatoren
Ein weiteres Problem ist die Priorisierung von Antworten. Relativ gesehen, welche Art von SLA werden wir haben, wenn wir einen bestimmten Indikator für einen Kompromiss erkennen. In der Tat priorisieren Anbieter von Bedrohungs-Feeds die darin enthaltenen Entitäten nicht. Um den Verbrauchern zu helfen, können sie ein gewisses Maß an Vertrauen in die Schädlichkeit eines Unternehmens schaffen, wie dies in Feeds von Kaspersky Lab der Fall ist:

Die Priorisierung der Ereignisse zur Identifizierung von Indikatoren ist jedoch Aufgabe des Verbrauchers.
Um dieses Problem bei Jet CSIRT anzugehen, haben wir den von Ryan Kazanciyan auf der COUNTERMEASURE 2016 skizzierten
Ansatz angepasst. Im Wesentlichen werden alle Kompromissindikatoren, die in der Infrastruktur zu finden sind, unter dem Gesichtspunkt der Zugehörigkeit zu Systemdomänen und Datendomänen berücksichtigt .
Datendomänen sind in 3 Kategorien unterteilt:
- Echtzeitaktivität auf der Quelle (was sie derzeit im Speicher speichert; erkannt durch Analysieren von Informationssicherheitsereignissen in Echtzeit):
- Prozesse starten, Registrierungsschlüssel ändern, Dateien erstellen;
- Netzwerkaktivität, aktive Verbindungen;
- andere Ereignisse, die gerade generiert wurden.
Wenn ein Indikator dieser Kategorie erkannt wird, ist die Antwortzeit der IS-Dienste minimal .
- Historische Aktivität (was bereits geschehen ist; bei nachträglichen Kontrollen aufgedeckt):
- historische Protokolle;
- Telemetrie;
- ausgelöste Warnungen.
Wird ein Indikator dieser Kategorie erkannt, ist die Reaktionszeit der IS-Dienste zulässig .
- Daten in Ruhe (was bereits war, bevor wir die Quelle mit der Überwachung verbunden haben; dies wird im Rahmen der nachträglichen Überprüfung von nicht verwendeten Quellen offengelegt):
- Dateien, die schon lange in der Quelle gespeichert sind;
- Registrierungsschlüssel;
- andere nicht verwendete Objekte.
Wenn ein Indikator dieser Kategorie erkannt wird, ist die Reaktionszeit der IS-Dienste durch die Dauer der vollständigen Untersuchung des Vorfalls begrenzt .
Normalerweise werden detaillierte Berichte und Newsletter auf der Grundlage solcher Untersuchungen mit einer Aufschlüsselung der Aktionen von Angreifern erstellt, aber die Relevanz solcher Daten ist relativ gering.
Das heißt
, Datendomänen sind der Status der analysierten Daten, in dem ein Kompromissindikator erkannt wurde.
Systemdomänen sind die Zugehörigkeit der Quelle des Kompromissindikators zu einem der Infrastruktursubsysteme:
- Arbeitsstationen. Quellen, die direkt vom Benutzer für die tägliche Arbeit verwendet werden: Workstations, Laptops, Tablets, Smartphones, Terminals (VoIP, VKS, IM), Anwendungsprogramme (CRM, ERP usw.).
- Server. Dies bezieht sich auf andere Geräte, die die Infrastruktur bedienen, d. H. Geräte für den Betrieb des IT-Komplexes: SZI (FW, IDS / IPS, AV, EDR, DLP), Netzwerkgeräte, Datei- / Web- / Proxyserver, Speichersysteme, ACS, Umgebungskontrolle. Umwelt usw.

Wenn Sie diese Informationen mit der Zusammensetzung der Zeichen eines Kompromissindikators
(Atom, Komposit) kombinieren, können Sie abhängig von der akzeptablen Reaktionszeit die Priorität des Vorfalls formulieren, wenn er erkannt wird:
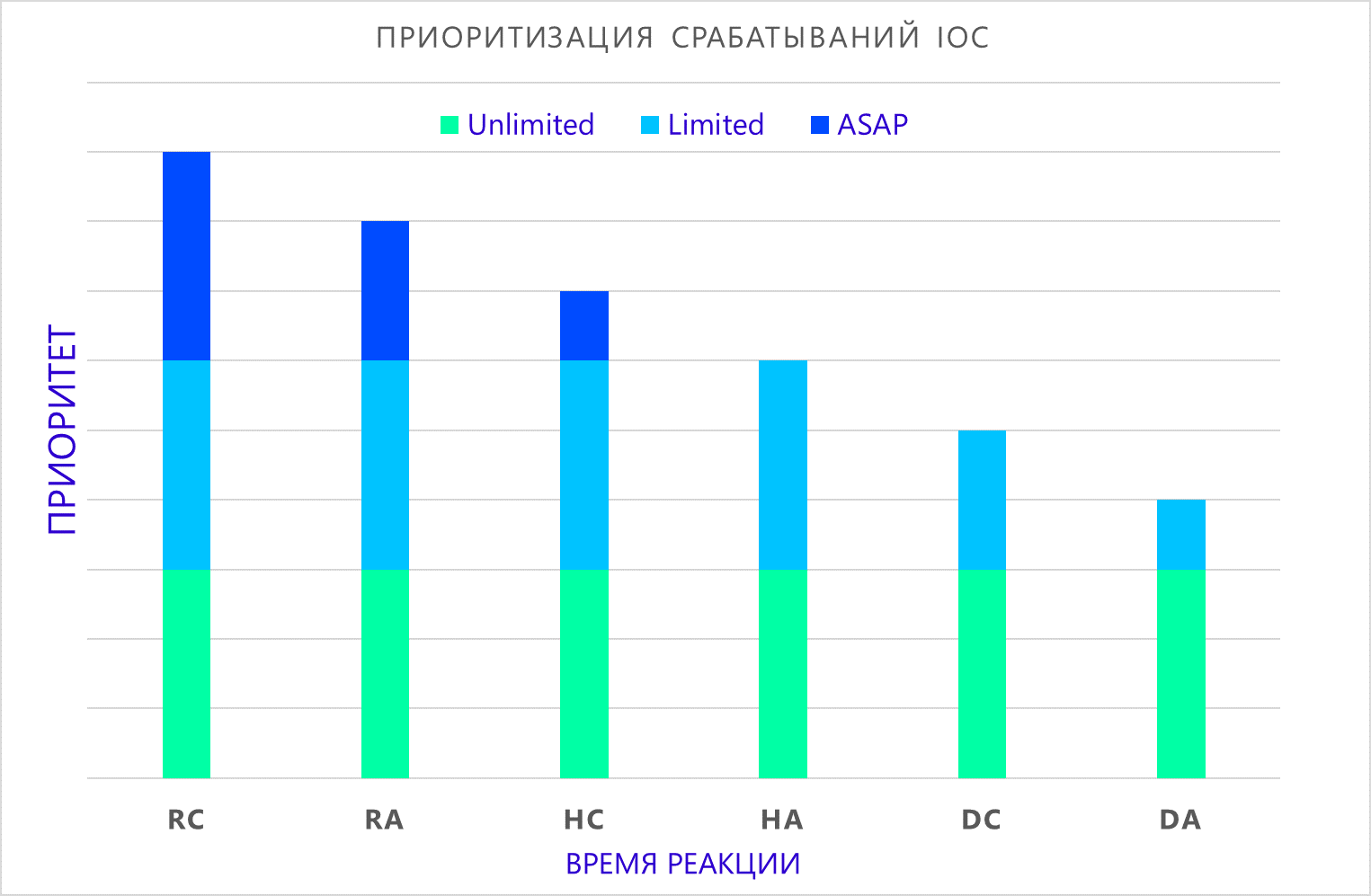
- So schnell wie möglich Die Erkennung eines Indikators erfordert eine sofortige Reaktion des Reaktionsteams.
- Begrenzt Die Erkennung des Indikators erfordert eine zusätzliche Analyse, um die Umstände des Vorfalls zu klären und weitere Maßnahmen zu beschließen.
- Unbegrenzt Die Erkennung des Indikators erfordert eine gründliche Untersuchung und Erstellung eines Berichts über die Aktivitäten von Angreifern. Typischerweise werden solche Befunde im Rahmen der Forensik untersucht, die Jahre dauern kann.
Wo:
- RC - zusammengesetzte Echtzeitindikatorerkennung;
- RA - Erkennung eines Atomindikators in Echtzeit;
- HC - Erkennung eines zusammengesetzten Indikators im Rahmen einer retrospektiven Überprüfung;
- HA - Nachweis eines Atomindikators im Rahmen einer retrospektiven Verifikation;
- DC - Erkennung eines zusammengesetzten Indikators in langen unbenutzten Quellen;
- DA - Nachweis eines Atomindikators in langen ungenutzten Quellen.
Ich muss sagen, dass die Priorität nicht die Wichtigkeit der Erkennung eines Indikators beeinträchtigt, sondern vielmehr die ungefähre Zeit angibt, die wir benötigen, um einen möglichen Kompromiss der Infrastruktur zu verhindern.
Es ist auch fair zu bemerken, dass ein solcher Ansatz nicht isoliert von der beobachteten Infrastruktur verwendet werden kann, wir werden darauf zurückkommen.
Überwachung der Lebensdauer von Kompromissindikatoren
Es gibt einige böswillige Entitäten, die den Indikator für Kompromisse für immer hinterlassen. Es wird nicht empfohlen, solche Informationen auch nach längerer Zeit zu löschen. Dies wird häufig bei retrospektiven Audits
(NA / HA) und bei der Suche nach langen, nicht verwendeten Quellen
(DC / DA) relevant.
Einige Überwachungszentren und Anbieter von Kompromissindikatoren halten es für unnötig, die Lebensdauer aller Indikatoren im Allgemeinen zu kontrollieren. In der Praxis wird dieser Ansatz jedoch unwirksam. In der Tat werden solche Kompromissindikatoren wie beispielsweise Hashes von schädlichen Dateien, von Malware generierte Registrierungsschlüssel und URLs, über die ein Knoten infiziert wird, niemals zu legitimen Einheiten, d. H. ihre Gültigkeit ist nicht beschränkt.Beispiel: SHA-256-Analyse der Summe einer RAT- Ungezieferdatei mit einem gekapselten SOAP-Protokoll für den Datenaustausch mit einem C & C-Server. Die Analyse zeigt, dass die Datei im Jahr 2015 erstellt wurde. Kürzlich haben wir es auf einem der Dateiserver unserer Kunden gefunden.
In der Tat werden solche Kompromissindikatoren wie beispielsweise Hashes von schädlichen Dateien, von Malware generierte Registrierungsschlüssel und URLs, über die ein Knoten infiziert wird, niemals zu legitimen Einheiten, d. H. ihre Gültigkeit ist nicht beschränkt.Beispiel: SHA-256-Analyse der Summe einer RAT- Ungezieferdatei mit einem gekapselten SOAP-Protokoll für den Datenaustausch mit einem C & C-Server. Die Analyse zeigt, dass die Datei im Jahr 2015 erstellt wurde. Kürzlich haben wir es auf einem der Dateiserver unserer Kunden gefunden.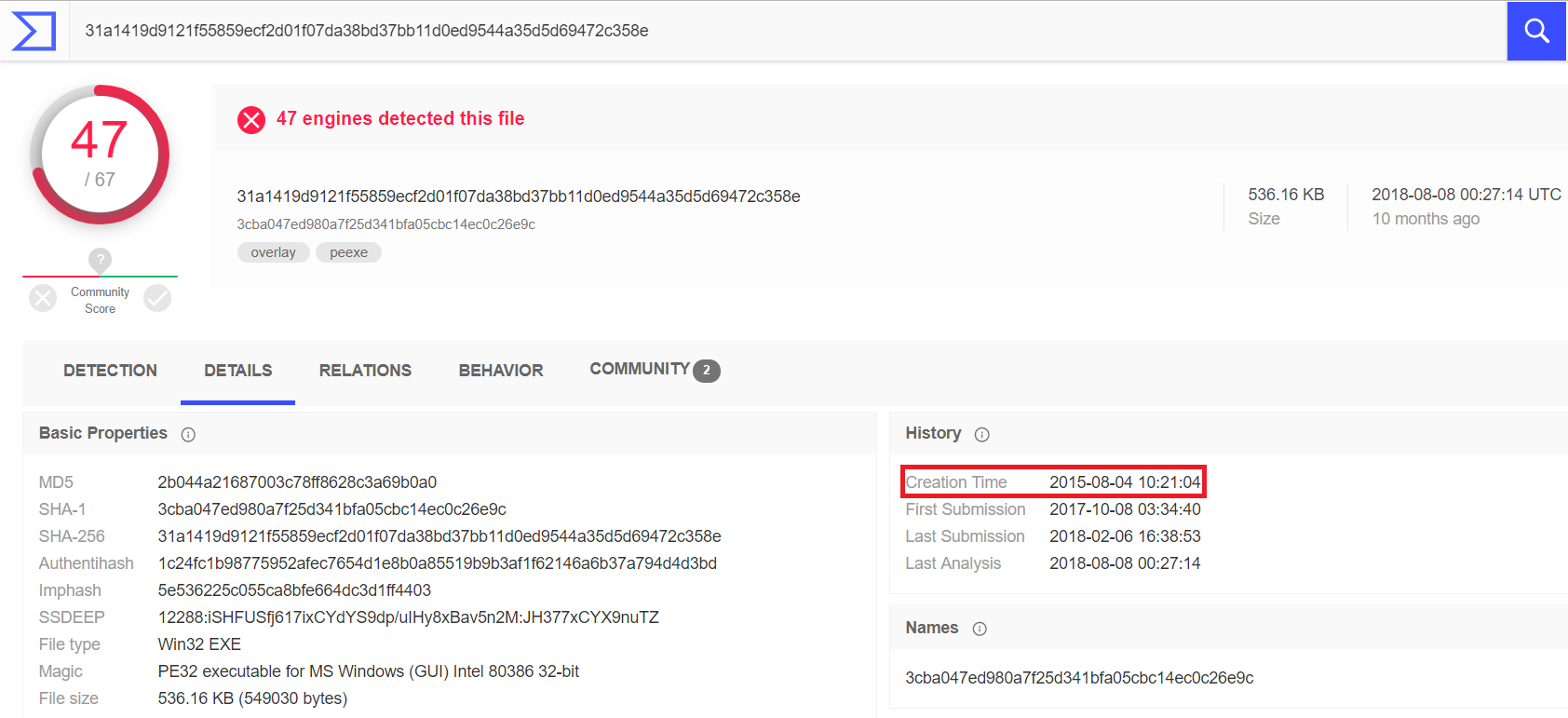 Ein völlig anderes Bild ergibt sich jedoch aus der Art der Entitäten, die für eine Weile für eine böswillige Kampagne erstellt oder „ausgeliehen“ wurden. Das heißt, sie sind Endpunkte, die von Eindringlingen kontrolliert werden.Solche Entitäten können wieder legitim werden, nachdem ihre Eigentümer die gefährdeten Knoten gelöscht haben oder wenn Angreifer die nächste Infrastruktur nicht mehr nutzen.Unter Berücksichtigung dieser Faktoren ist es möglich, eine ungefähre Tabelle von Kompromissindikatoren in Bezug auf Datendomänen, den Zeitraum ihrer Relevanz und die Notwendigkeit der Kontrolle ihres Lebenszyklus zu erstellen:
Ein völlig anderes Bild ergibt sich jedoch aus der Art der Entitäten, die für eine Weile für eine böswillige Kampagne erstellt oder „ausgeliehen“ wurden. Das heißt, sie sind Endpunkte, die von Eindringlingen kontrolliert werden.Solche Entitäten können wieder legitim werden, nachdem ihre Eigentümer die gefährdeten Knoten gelöscht haben oder wenn Angreifer die nächste Infrastruktur nicht mehr nutzen.Unter Berücksichtigung dieser Faktoren ist es möglich, eine ungefähre Tabelle von Kompromissindikatoren in Bezug auf Datendomänen, den Zeitraum ihrer Relevanz und die Notwendigkeit der Kontrolle ihres Lebenszyklus zu erstellen: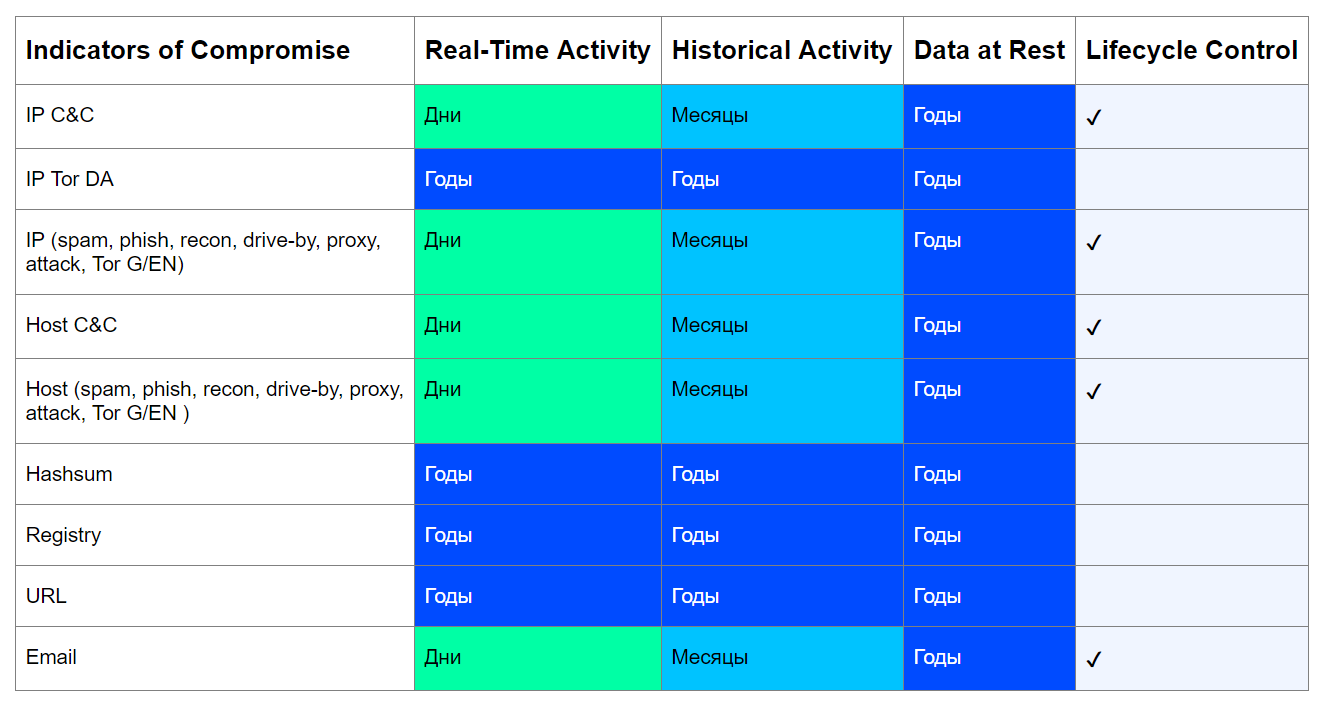 Der Zweck dieser Tabelle besteht darin, drei Fragen zu beantworten:
Der Zweck dieser Tabelle besteht darin, drei Fragen zu beantworten:- Kann dieser Indikator im Laufe der Zeit legitim werden?
- Was ist die Mindestrelevanzdauer eines Indikators in Abhängigkeit vom Status der analysierten Daten?
- Ist es notwendig, die Lebensdauer dieses Indikators zu kontrollieren?
Betrachten Sie diesen Ansatz am Beispiel eines IP C & C-Servers. Heutzutage ziehen es Angreifer vor, eine verteilte Infrastruktur aufzubauen und häufig Adressen zu ändern, um unbemerkt zu bleiben und mögliche Blockierungen durch den Anbieter zu vermeiden. Gleichzeitig wird C & C häufig auf gehackten Knoten bereitgestellt, wie beispielsweise im Fall von Emotet . Die Botnets werden jedoch liquidiert, die Bösewichte werden gefangen, daher kann ein Indikator wie die IP-Adresse des C & C-Servers sicherlich zu einer legitimen Einheit werden, was bedeutet, dass seine Lebensdauer kontrolliert werden kann.Wenn wir Anrufe beim IP C & C-Server in Echtzeit (RA / RC) finden, wird der für uns relevante Zeitraum in Tagen berechnet. Schließlich ist es unwahrscheinlich, dass diese Adresse am Tag nach der Entdeckung C & C nicht mehr hostet.Der Nachweis eines solchen Indikators bei retrospektiven Kontrollen (HA / HC), die normalerweise längere Intervalle (alle paar Wochen / Monate) aufweisen, zeigt auch einen Mindestrelevanzzeitraum an, der dem entsprechenden Intervall entspricht. Gleichzeitig ist C & C selbst möglicherweise nicht mehr aktiv. Wenn wir jedoch feststellen, dass unsere Infrastruktur in Umlauf ist, ist der Indikator für uns relevant.Die gleiche Logik gilt für andere Arten von Indikatoren. Ausnahmen sind Hash-Beträge, Registrierungsschlüssel, Directory Authority (DA) Tor-Netzwerkknoten und URLs.Mit Hashes und Registrierungswerten ist alles einfach - sie können nicht aus der Natur entfernt werden, daher macht es keinen Sinn, ihre Lebensdauer zu kontrollieren. Aber böswillige URLs können entfernt werden. Natürlich werden sie nicht legitim, aber sie sind inaktiv. Sie sind jedoch auch einzigartig und wurden speziell für eine böswillige Kampagne erstellt, sodass sie nicht legitimiert werden können.Die IP-Adressen der DA-Knoten des Tor-Netzwerks sind bekannt und unverändert. Ihre Lebensdauer ist nur durch die Lebensdauer des Tor-Netzwerks selbst begrenzt. Daher sind solche Indikatoren immer relevant.Wie Sie sehen können, ist für die meisten Arten von Indikatoren aus der Tabelle eine Kontrolle ihrer Lebensdauer erforderlich.Wir bei Jet CSIRT befürworten diesen Ansatz aus folgenden Gründen.- , - , - , , , .
, Microsoft 99 , APT35. - Microsoft .
IP- , -. , IP- «», , . - , .
, , , . - .
, . 1 MS Office, -, . , , , .
Aus diesem Grund halten wir es jetzt für wichtig, Prozesse anzupassen und Ansätze zur Kontrolle der Lebensdauer von Indikatoren zu entwickeln, die in die Schutzmittel integriert sind.Ein solcher Ansatz ist in den abnehmenden Kompromissindikatoren des Luxemburger Computer Emergency Response Center (CIRCL) beschrieben, dessen Mitarbeiter eine Plattform für den Informationsaustausch über MISP- Bedrohungen geschaffen haben . In MISP ist geplant, Ideen aus diesem Material anzuwenden. Zu diesem Zweck haben die Projekt-Repositories bereits die entsprechende Niederlassung eröffnet , was erneut die Relevanz dieses Problems für die Community für Informationssicherheit belegt.Bei diesem Ansatz wird davon ausgegangen, dass die Lebensdauer einiger Indikatoren nicht homogen ist und sich wie folgt ändern kann:- Angreifer nutzen ihre Infrastruktur nicht mehr für Cyber-Angriffe.
- Er erfährt mehr und mehr von den Spezialisten für Informationssicherheit über den Cyberangriff und setzt Indikatoren in den Block des SZI, wodurch Angreifer gezwungen werden, die verwendeten Elemente zu ändern.
Somit kann die Lebensdauer solcher Indikatoren in Form einer bestimmten Funktion beschrieben werden, die die Austrittsrate des Ablaufdatums jedes Indikators über die Zeit charakterisiert.CIRCL-Kollegen erstellen ihr Modell unter den in MISP verwendeten Bedingungen. Die allgemeine Idee des Modells kann jedoch auch außerhalb ihres Produkts verwendet werden:- Dem Kompromissindikator (a) wird eine bestimmte Grundbewertung zugewiesen ( ), die von 0 bis 100 reicht;
Im CIRCL-Material wird dies durch die Zuverlässigkeit / das Vertrauen in den Indikatoranbieter und die damit verbundenen Taxonomien berücksichtigt. Gleichzeitig kann sich bei wiederholter Erkennung des Indikators die grundlegende Bewertung ändern - je nach den Algorithmen des Anbieters erhöhen oder verringern.- Die Zeit wird eingegeben , bei dem seine Gesamtpunktzahl = 0 sein sollte;
- Das Konzept der Indikator-Ablaufrate (Decay_rate) wird vorgestellt. , das die Abnahmerate der Gesamtindikatorbewertung über die Zeit charakterisiert;
- Zeitstempel eingegeben und , die jeweils die aktuelle Zeit und die Zeit charakterisiert, zu der der Indikator zuletzt gesehen wurde.
Unter allen oben genannten Bedingungen geben Kollegen von CIRCL die folgende Formel zur Berechnung der Gesamtpunktzahl an (1):
WoParameter
vorgeschlagen, τ a als zu betrachten ,
Wo- Zeitpunkt der ersten Erkennung des Indikators;- Zeitpunkt der letzten Erkennung des Indikators;- die maximale Zeit zwischen zwei Erfassungen des Indikators. Die Idee ist, dass, wenn die Punktzahl = 0 ist, der entsprechende Indikator zurückgezogen werden kann. Nach unseren Daten implementieren einige Anbieter von Bedrohungs-Feeds andere Methoden, um die Relevanz zu kontrollieren und Kompromissindikatoren zu filtern, die auf vorbeugender Ebene verwendet werden. Die meisten dieser Techniken sind jedoch recht einfach. Wir haben versucht, den Algorithmus aus dem CIRCL-Material auf Indikatoren anzuwenden, die in der Erkennungsphase erkannt und während des Reaktionsprozesses und der Aktivität nach einem Vorfall als Blockierungsregeln auf das SIS angewendet wurden. Offensichtlich kann dieser Ansatz nur auf die Arten von Indikatoren angewendet werden, für die er bekannt ist.
Das CIRCL-Material gibt ein Beispiel für die sogenannte Kulanzzeit - eine feste Korrekturzeit, die der Anbieter dem Eigentümer der Ressource, der bei verdächtigen Aktivitäten festgestellt wurde, vor dem Trennen der Ressource angibt. Aber für die meisten Arten von Indikatoren ist noch unbekannt.Leider können wir den Zeitpunkt, zu dem ein bestimmtes Unternehmen legitim wird, nicht genau vorhersagen. Wir haben jedoch fast immer (vom Lieferanten des Indikators oder von der Analyse offener Quellen) Informationen darüber, wann dieses Unternehmen zum ersten und letzten Mal entdeckt wurde, sowie eine Art grundlegende Bewertung. Um herauszufinden, wann es möglich sein wird, den Indikator gemäß dem CIRCL-Material abzuschreiben, trennt uns nur eine Variable - zerfallsrate. Es reicht jedoch nicht aus, sie nur für alle Indikatoren und vor allem für alle Infrastrukturen konstant zu halten.Daher haben wir versucht, jeden Indikatortyp, für den eine Lebenszyklusüberwachung möglich ist, mit seiner Ablaufrate (zerfallsrate), der Art der beobachteten Infrastruktur und dem Reifegrad der Informationssicherheit zu verknüpfen.Indem wir eine Bestandsaufnahme der spezifischen geschützten Infrastruktur durchführen und das Alter der verwendeten Software und Ausrüstung ermitteln, ermitteln wir die Zerfallsrate für jede Art von Kompromissindikator. Ein ungefähres Ergebnis solcher Arbeiten kann in Form einer Tabelle dargestellt werden: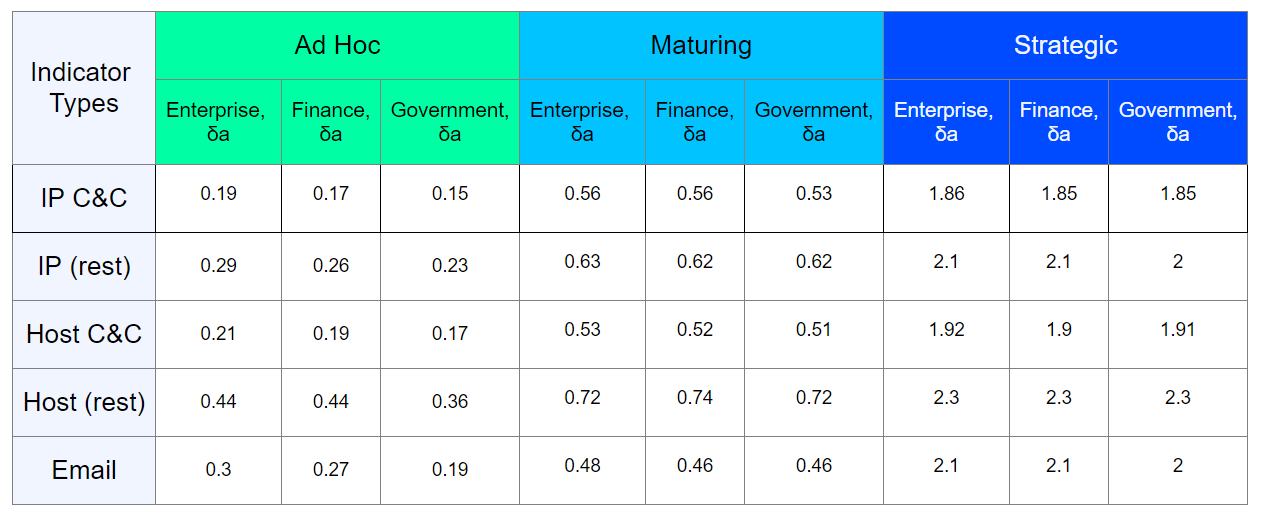 Ich betone noch einmal, dass das Ergebnis in der Tabelle ungefähr ist, in Wirklichkeit sollte die Bewertung für eine bestimmte Infrastruktur individuell durchgeführt werden.Mit dem Aufkommen der Ablaufdaten jedes Indikators können wir den ungefähren Zeitpunkt bestimmen, zu dem sie abgeschrieben werden können. Es ist auch anzumerken, dass die Berechnung der Abschreibzeit nur durchgeführt werden sollte, wenn die Tendenz zu einer Abnahme der Basisbewertung des Indikators besteht.Betrachten Sie beispielsweise einen Indikator mit einer Basisbewertung von 80, Zeit = 120 und unterschiedliche Abklingrate (
Ich betone noch einmal, dass das Ergebnis in der Tabelle ungefähr ist, in Wirklichkeit sollte die Bewertung für eine bestimmte Infrastruktur individuell durchgeführt werden.Mit dem Aufkommen der Ablaufdaten jedes Indikators können wir den ungefähren Zeitpunkt bestimmen, zu dem sie abgeschrieben werden können. Es ist auch anzumerken, dass die Berechnung der Abschreibzeit nur durchgeführt werden sollte, wenn die Tendenz zu einer Abnahme der Basisbewertung des Indikators besteht.Betrachten Sie beispielsweise einen Indikator mit einer Basisbewertung von 80, Zeit = 120 und unterschiedliche Abklingrate ( )
 Wie aus den Diagrammen ersichtlich ist, können wir bei der Bestimmung der ungefähren Kritikalitätsgrenze der Bewertung (in unserem Fall - 20, mit einer anfänglichen Bewertung von 80) den Zeitpunkt für die Überprüfung dieses Indikators auf Relevanz festlegen. Je mehr Zerfallsrate, desto schneller kommt diese Zeit. Zum Beispiel könnte man mit Decay_rate = 3 und einem Bewertungslimit = 20 diesen Indikator für ungefähr 50 Tage seines Betriebs im SZI überprüfen.Der beschriebene Ansatz ist ziemlich schwierig zu implementieren, aber sein Reiz ist, dass wir Tests durchführen können, ohne die etablierten Prozesse der Informationssicherheit und die Infrastruktur der Kunden zu beeinträchtigen. Jetzt führen wir den Algorithmus zur Überwachung der Lebensdauer einer bestimmten Stichprobe von Indikatoren aus, die hypothetisch unter die Stilllegung fallen können. Tatsächlich bleiben diese Indikatoren jedoch beim SZI in Betrieb. Relativ gesehen nehmen wir eine Stichprobe von Indikatoren, die wir für sie berücksichtigen und, nachdem eine Tendenz zur Abnahme der Basisschätzung festgestellt wurde, markieren Sie sie als „abgeschrieben“, wenn die Prüfung ihre Irrelevanz bestätigt.Es ist noch zu früh, um über die Wirksamkeit dieses Ansatzes zu sprechen, aber anhand der Testergebnisse können wir feststellen, ob es sich lohnt, ihn „in die Produktion“ zu übersetzen.Eine solche Technik kann möglicherweise dazu beitragen, nicht nur die Indikatoren zu steuern, die aufgrund der Reaktion auf den Vorfall im SIS betrieben werden. Die erfolgreiche Anpassung dieses Ansatzes durch Anbieter von Cyberthreat-Informationen ermöglicht es ihnen, Bedrohungs-Feeds so zu profilieren, dass sie Kompromissindikatoren mit einer bestimmten Lebensdauer für bestimmte Kunden und Infrastrukturen enthalten.
Wie aus den Diagrammen ersichtlich ist, können wir bei der Bestimmung der ungefähren Kritikalitätsgrenze der Bewertung (in unserem Fall - 20, mit einer anfänglichen Bewertung von 80) den Zeitpunkt für die Überprüfung dieses Indikators auf Relevanz festlegen. Je mehr Zerfallsrate, desto schneller kommt diese Zeit. Zum Beispiel könnte man mit Decay_rate = 3 und einem Bewertungslimit = 20 diesen Indikator für ungefähr 50 Tage seines Betriebs im SZI überprüfen.Der beschriebene Ansatz ist ziemlich schwierig zu implementieren, aber sein Reiz ist, dass wir Tests durchführen können, ohne die etablierten Prozesse der Informationssicherheit und die Infrastruktur der Kunden zu beeinträchtigen. Jetzt führen wir den Algorithmus zur Überwachung der Lebensdauer einer bestimmten Stichprobe von Indikatoren aus, die hypothetisch unter die Stilllegung fallen können. Tatsächlich bleiben diese Indikatoren jedoch beim SZI in Betrieb. Relativ gesehen nehmen wir eine Stichprobe von Indikatoren, die wir für sie berücksichtigen und, nachdem eine Tendenz zur Abnahme der Basisschätzung festgestellt wurde, markieren Sie sie als „abgeschrieben“, wenn die Prüfung ihre Irrelevanz bestätigt.Es ist noch zu früh, um über die Wirksamkeit dieses Ansatzes zu sprechen, aber anhand der Testergebnisse können wir feststellen, ob es sich lohnt, ihn „in die Produktion“ zu übersetzen.Eine solche Technik kann möglicherweise dazu beitragen, nicht nur die Indikatoren zu steuern, die aufgrund der Reaktion auf den Vorfall im SIS betrieben werden. Die erfolgreiche Anpassung dieses Ansatzes durch Anbieter von Cyberthreat-Informationen ermöglicht es ihnen, Bedrohungs-Feeds so zu profilieren, dass sie Kompromissindikatoren mit einer bestimmten Lebensdauer für bestimmte Kunden und Infrastrukturen enthalten.Fazit
Treat Intelligence ist natürlich ein notwendiges und nützliches Informationssicherheitskonzept, das die Sicherheit der Unternehmensinfrastruktur erheblich verbessern kann. Um eine effektive Nutzung von TI zu erreichen, müssen Sie verstehen, wie wir die verschiedenen Informationen verwenden können, die durch diesen Prozess erhalten werden.Wenn wir über die technischen Informationen von Threat Intelligence sprechen, wie z. B. Bedrohungs-Feeds und Kompromissindikatoren, müssen wir uns daran erinnern, dass die Methode ihrer Verwendung nicht auf einer blinden schwarzen Liste basieren sollte. Ein einfacher Algorithmus zum Erkennen und anschließenden Blockieren einer Bedrohung weist tatsächlich viele „Fallstricke“ auf. Um technische Informationen effektiv zu nutzen, ist es daher erforderlich, ihre Qualität korrekt zu bewerten, die Priorität der Erkennungen zu bestimmen und ihre Lebensdauer zu steuern, um die Belastung des SPI zu verringern.Verlassen Sie sich jedoch ausschließlich auf das technische Wissen von Threat Intelligence. Es ist viel wichtiger, taktische Informationen an Verteidigungsprozesse anzupassen. Schließlich ist es für Angreifer viel schwieriger, Taktiken, Techniken und Werkzeuge zu ändern, als einen anderen Teil der Kompromissindikatoren zu verfolgen, der nach einem Hackerangriff entdeckt wurde. Aber darüber werden wir in unseren nächsten Artikeln sprechen.Autor: Alexander Akhremchik, Experte im Jet Infrastructure Jet Monitoring- und Reaktionszentrum von Jet Infosystems, Jet CSIRT