Neuronale Netze - dies ist ein Thema, das großes Interesse und den Wunsch weckt, es zu verstehen. Aber leider eignet es sich nicht für alle. Wenn Sie Bände obskurer Literatur sehen, verlieren Sie den Wunsch zu studieren, möchten aber trotzdem auf dem Laufenden bleiben, was gerade passiert.
Am Ende schien es mir, dass es keinen besseren Weg gibt, es herauszufinden, als einfach ein eigenes kleines Projekt zu erstellen.
Sie können den lyrischen Hintergrund lesen, indem Sie den Text erweitern, oder Sie können diesen überspringen und direkt zur
Beschreibung des neuronalen Netzwerks gehen.Was ist der Sinn Ihres Projekts?Vorteile:
- Sie verstehen besser, wie Neuronen angeordnet sind
- Sie verstehen besser, wie Sie mit vorhandenen Bibliotheken arbeiten
- Parallel dazu etwas Neues lernen
- Tickle dein Ego und erschaffe etwas Eigenes
Nachteile:
- Sie erstellen ein Fahrrad, das wahrscheinlich schlechter ist als das vorhandene
- Niemand kümmert sich um Ihr Projekt.
Die Wahl der Sprache.Zum Zeitpunkt der Auswahl der Sprache kannte ich C ++ mehr oder weniger und war mit den Grundlagen von Python vertraut. Es ist einfacher, mit Neuronen in Python zu arbeiten, aber C ++ wusste es besser und es gibt keine einfachere Parallelisierung von Berechnungen als OpenMP.
Aus diesem
Grund habe ich mich für C ++ entschieden, und die API für Python erstellt, um sich nicht darum zu
kümmern , einen
Swig , der unter Windows und Linux funktioniert. (
Ein Beispiel für das Erstellen einer Python-Bibliothek aus C ++ - Code)
OpenMP- und GPU-Beschleunigung.Derzeit ist OpenMP Version 2.0 in Visual Studio installiert, in dem nur die CPU-Beschleunigung erfolgt. Ab Version 3.0 unterstützt OpenMP jedoch auch die GPU-Beschleunigung, während die Syntax der Anweisungen nicht kompliziert ist. Es bleibt nur zu warten, bis OpenMP 3.0 von allen Compilern unterstützt wird. In der Zwischenzeit der Einfachheit halber nur die CPU.
Mein erster Rechen.Bei der Berechnung des Werts eines Neurons gibt es folgenden Punkt: Bevor wir die Aktivierungsfunktion berechnen, müssen wir die Multiplikation der Gewichte zu den Eingabedaten hinzufügen. Wie man das an der Universität lernt: Bevor ein großer Vektor kleiner Zahlen summiert wird, muss er in aufsteigender Reihenfolge sortiert werden. Also. In neuronalen Netzen gibt dies, abgesehen davon, dass das Programm N-mal verlangsamt wird, nichts. Dies wurde mir jedoch erst klar, als ich mein Netzwerk bereits auf MNIST getestet hatte.
Ein Projekt auf GitHub setzen.Ich bin nicht der erste, der meine Kreation auf GitHub veröffentlicht. In den meisten Fällen sehen Sie jedoch über den Link nur eine Reihe von Codes mit der Aufschrift in README.md
"Dies ist mein neuronales Netzwerk, beobachten und studieren .
" Um besser zu sein als andere, beschrieb er
README.md mehr oder weniger und füllte das
Wiki aus . Die Nachricht ist einfach -
füllen Sie das Wiki aus. Eine interessante Beobachtung: Wenn der Titel im Wiki auf GitHub in Russisch geschrieben ist, funktioniert der
Anker zu diesem Titel nicht.
LizenzWenn Sie Ihr kleines Projekt erstellen, ist eine Lizenz wieder eine Möglichkeit, Ihr Ego zu kitzeln. Hier ist ein interessanter
Artikel darüber, wofür eine Lizenz gedacht ist. Ich habe mich für
APACHE 2.0 entschieden .
Beschreibung des Netzwerks.
Eigenschaften
Der Hauptvorteil meiner Bibliothek ist die Erstellung eines Netzwerks mit einer Codezeile.
Es ist leicht zu erkennen, dass in linearen Schichten die Anzahl der Neuronen in einer Schicht gleich der Anzahl der Eingabeparameter in der nächsten Schicht ist. Eine weitere offensichtliche Aussage: Die Anzahl der Neuronen in der letzten Schicht entspricht der Anzahl der Ausgabewerte des Netzwerks.
Erstellen wir ein Netzwerk, das drei Parameter am Eingang empfängt und drei Schichten mit 5, 4 und 2 Neuronen aufweist.
import foxnn nn = foxnn.neural_network([3, 5, 4, 2])
Wenn Sie sich das Bild ansehen, sehen Sie nur: zuerst 3 Eingabeparameter, dann eine Schicht mit 5 Neuronen, dann eine Schicht mit 4 Neuronen und schließlich die letzte Schicht mit 2 Neuronen.
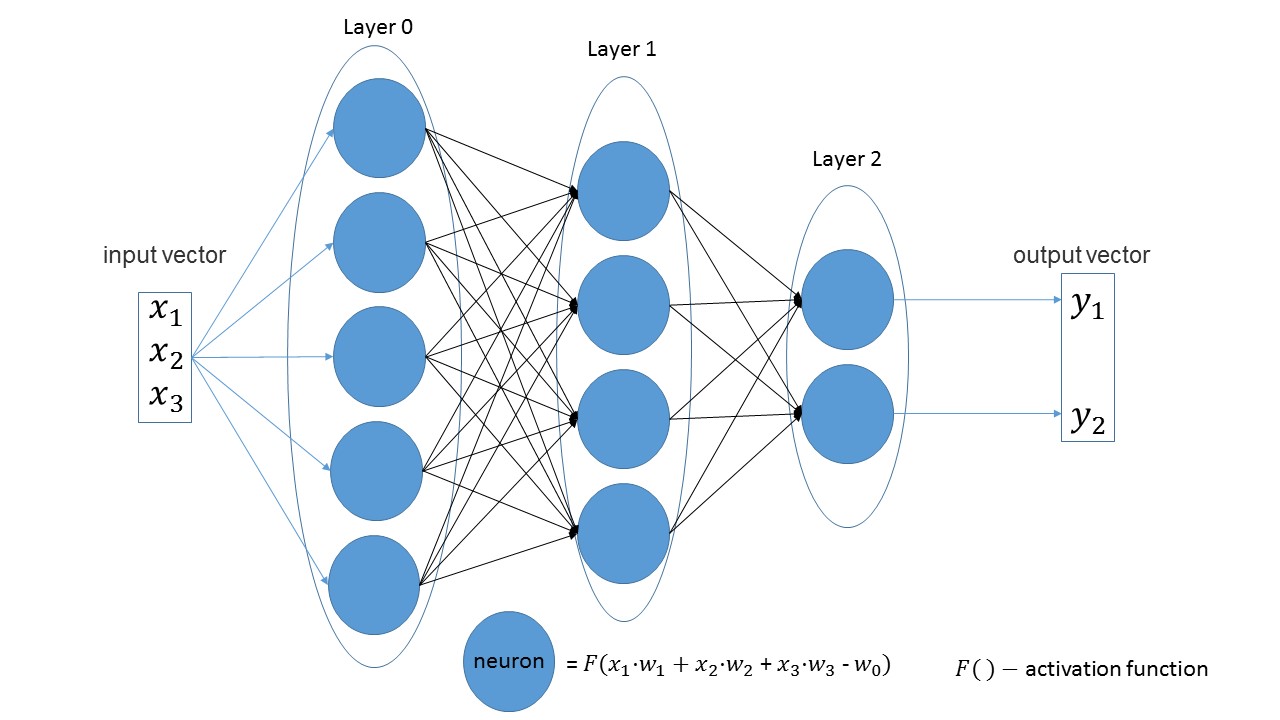
Standardmäßig sind alle Aktivierungsfunktionen Sigmoid (ich mag sie mehr).
Falls gewünscht, kann auf jeder Ebene eine andere Funktion geändert werden.
Die beliebtesten Aktivierungsfunktionen sind verfügbar. nn.get_layer(0).set_activation_function("gaussian")
Einfach zu erstellendes Trainingsset. Der erste Vektor sind die Eingabedaten, der zweite Vektor sind die Zieldaten.
data = foxnn.train_data() data.add_data([1, 2, 3], [1, 0])
Netzwerktraining:
nn.train(data_for_train=data, speed=0.01, max_iteration=100, size_train_batch=98)
Optimierung aktivieren:
nn.settings.set_mode("Adam")
Und eine Methode, um nur den Netzwerkwert zu erhalten:
nn.get_out([0, 1, 0.1])
Ein bisschen über den Namen der Methode.Get übersetzt übersetzt, wie man es bekommt , und out bedeutet Ausgabe . Ich wollte den Namen " gib den Ausgabewert " bekommen und bekam ihn. Erst später bemerkte ich, dass es sich herausstellte, herauszukommen . Aber es macht mehr Spaß und ich habe beschlossen zu gehen.
Testen
Es ist bereits eine ungeschriebene Tradition geworden, jedes auf
MNIST basierende Netzwerk zu
testen . Und ich war keine Ausnahme. Alle Codes mit Kommentaren finden Sie
hier .
Erstellt ein Trainingsbeispiel: from mnist import MNIST import foxnn mndata = MNIST('C:download/') mndata.gz = True imagesTrain, labelsTrain = mndata.load_training() def get_data(images, labels): train_data = foxnn.train_data() for im, lb in zip(images, labels): data_y = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Erstellen Sie ein Netzwerk: drei Ebenen, 784 Parameter für die Eingabe und 10 für die Ausgabe: nn = foxnn.neural_network([784, 512, 512, 10]) nn.settings.n_threads = 7
Wir trainieren: nn.train(data_for_train=train_data, speed=0.001, max_iteration=10000, size_train_batch=98)
Was ist passiert:
In ca. 10 Minuten (nur CPU-Beschleunigung) kann eine Genauigkeit von 75% erreicht werden. Mit der Adam-Optimierung kann in 5 Minuten eine Genauigkeit von 88% erreicht werden. Am Ende gelang es mir, eine Genauigkeit von 97% zu erreichen.
Die Hauptnachteile (es gibt bereits Pläne für eine Überarbeitung):- In Python wurden noch keine Fehler gemacht, d. H. In Python wird der Fehler nicht abgefangen und das Programm wird einfach mit einem Fehler beendet.
- Während des Trainings wird in Iterationen und nicht in Epochen angezeigt, wie es in anderen Netzwerken üblich ist.
- Keine GPU-Beschleunigung
- Es gibt noch keine anderen Arten von Schichten.
- Wir müssen das Projekt auf PyPi hochladen.
Für einen kleinen Abschluss des Projekts fehlte dieser Artikel. Wenn mindestens zehn Leute interessiert sind und spielen, wird es bereits einen Sieg geben. Willkommen in meinem
Github .
PS: Wenn Sie etwas Eigenes erstellen müssen, um es herauszufinden, haben Sie keine Angst und erstellen Sie.