Foto aus der Veröffentlichung genommenEinführung
Eine der dringendsten Aufgaben der digitalen Signalverarbeitung ist die Reinigung des Signals von Rauschen. Jedes praktische Signal enthält nicht nur nützliche Informationen, sondern auch Spuren einiger Nebeneffekte von Interferenzen oder Rauschen. Zusätzlich haben während der Schwingungsdiagnose Signale von Schwingungssensoren ein instationäres Frequenzspektrum, was die Filteraufgabe erschwert.
Es gibt viele verschiedene Möglichkeiten, um hochfrequentes Rauschen aus einem Signal zu entfernen. Beispielsweise enthält die Scipy-Bibliothek Filter, die auf verschiedenen Filtermethoden basieren: Kalman; Glätten des Signals durch Mitteln entlang der Zeitachse und anderer.
Der Vorteil des DWT-Verfahrens (Discrete Wavelet Transform) ist jedoch die Vielzahl der Wavelet-Formen. Sie können ein Wavelet auswählen, das eine für die erwarteten Phänomene charakteristische Form aufweist. Sie können beispielsweise ein Signal in einem bestimmten Frequenzbereich auswählen, dessen Form für das Auftreten eines Defekts verantwortlich ist.
Der Zweck dieser Veröffentlichung ist die Analyse der Methoden zum Filtern der Signale von Schwingungssensoren unter Verwendung der DWT-Signalumwandlung, des Kalman-Filters und der Methode des gleitenden Durchschnitts.
Quelldaten zur Analyse
In der Veröffentlichung wird der Betrieb von Filtern basierend auf verschiedenen Filtermethoden anhand
eines NASA-Datensatzes analysiert. Auf der Versuchsplattform PRONOSTIA erhaltene Daten:

Das Kit enthält Daten zu Vibrationssensorsignalen für den Verschleiß verschiedener Lagertypen. Der Zweck der Ordner mit den Signaldateien ist in der
Tabelle angegeben :
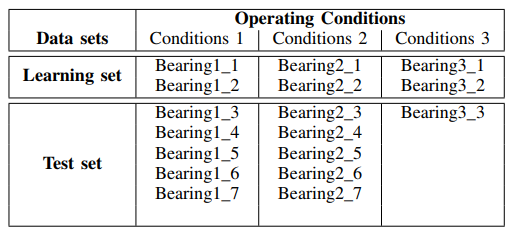
Die Überwachung des Lagerzustands erfolgt durch die Signale von Schwingungssensoren (horizontale und vertikale Beschleunigungsmesser), Kraft und Temperatur.

Empfangene Signale für drei verschiedene Lasten:
- Erste Arbeitsbedingungen: 1800 U / min und 4000 N;
- Zweite Arbeitsbedingungen: 1650 U / min und 4200 N;
- Dritte Betriebsbedingungen: 1500 U / min und 5000 N.
Für diese Bedingungen
erstellen wir unter Verwendung einer kontinuierlichen Wavelet-Signalumwandlung die
Spektroleistungsskalogramme für die Daten aus dem
Testsatz - eine Datei (für einen Lagertyp) aus den Ordnern: ['Test_set / Bearing1_3 / acc_00001.csv', 'Test_set / Bearing2_3 / acc_00001. csv ',' Test_set / Bearing3_3 / acc_00001.csv '] (siehe Tabelle 1).
Skalogrammlisteimport scaleogram as scg import pandas as pd from pylab import * import pywt filename_n = ['Test_set/Bearing1_3/acc_00001.csv', 'Test_set/Bearing2_3/acc_00001.csv', 'Test_set/Bearing3_3/acc_00001.csv'] for filename in filename_n: df = pd.read_csv(filename, header=None) signal = df[4].values wavelet = 'cmor1-0.5' ax = scg.cws(signal, scales=arange(1, 40), wavelet=wavelet, figsize=(8, 4), cmap="jet", cbar=None, ylabel=' ', xlabel=" ", yscale="log", title='- %s \n( )'%filename) show()


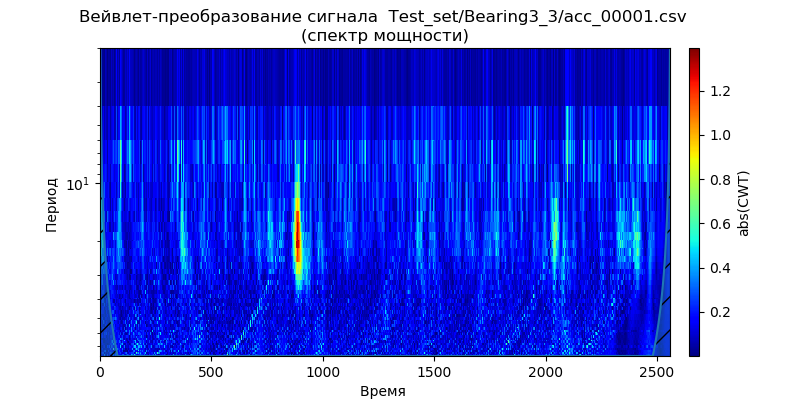
Aus den gegebenen Skalogrammen folgt, dass die Momente der Erhöhung der Leistung des Spektrums früher auftreten und eine Periodizität für die Betriebsbedingungen zeigen: 1650 U / min und 4200 N, was auf eine beschleunigte Verschlechterung der Lager in diesem Frequenzband für die verringerte Kraft hinweist. Wir werden dieses Signal ('Test_set / Bearing2_3 / acc_00001.csv') verwenden, um Rauschunterdrückungsmethoden zu analysieren.
Signaldekonstruktion mit DWT
In der
Veröffentlichung haben wir gesehen, wie eine Filterbank auf dem DWT implementiert ist, die ein Signal in seine Frequenzteilbänder zerlegen kann. Die Approximationskoeffizienten (cA) repräsentieren den niederfrequenten Teil des Signals (Mittelungsfilter). Detailkoeffizienten (cD) repräsentieren den Hochfrequenzanteil des Signals. Als nächstes werden wir untersuchen, wie DWT verwendet werden kann, um ein Signal in seine Frequenzteilbänder zu zerlegen und das ursprüngliche Signal wiederherzustellen.
Es gibt zwei Möglichkeiten, um das Problem der Signaldekonstruktion mit PyWavelets-Tools zu lösen:
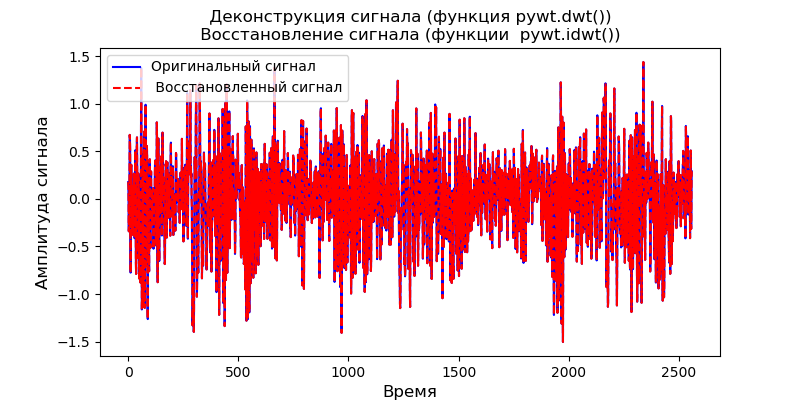
Der erste Weg besteht darin, pywt.dwt () auf das Signal anzuwenden, um die Approximations- und Detailkoeffizienten (cA1, cD1) zu extrahieren. Um das Signal wiederherzustellen, verwenden wir dann pywt.idwt ():
Auflistung import pywt from scipy import * import pandas as pd from pylab import * filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) signal = df[4].values (cA1, cD1) = pywt .dwt (signal, 'db2', 'smooth') r_signal = pywt.idwt (cA1, cD1, 'db2', 'smooth') fig, ax =subplots(figsize=(8,4)) ax.plot(signal, 'b',label=' ') ax.plot(r_signal, 'r', label=' ', linestyle='--') ax.legend(loc='upper left') ax.set_ylabel(' ', fontsize=12) ax.set_xlabel('', fontsize=12) ax.set_title(' ( pywt.dwt()) \n ( pywt.idwt()) ') show()
Die zweite Möglichkeit, die Funktion pywt.wavedec () auf das Signal anzuwenden, besteht darin, alle Approximations- und Detailkoeffizienten auf ein bestimmtes Niveau zurückzusetzen. Diese Funktion nimmt das Eingangssignal und den Pegel als Eingang und gibt einen Satz von Approximationskoeffizienten (n-ten Pegel) und n Sätze von Detailkoeffizienten (von 1 bis n-ten Pegel) zurück. Wenden Sie für die Dekonstruktion pywt.waverec () an:
Auflistung import pywt import pandas as pd from pylab import * filename = 'Test_set/Bearing3_3/acc_00026.csv' df = pd.read_csv(filename, header=None) signal = df[4].values coeffs = pywt.wavedec(signal, 'db2', level=8) r_signal = pywt.waverec(coeffs, 'db2') fig, ax = plt.subplots(figsize=(8,4)) ax.plot(signal, 'b',label=' ') ax.plot(r_signal, 'r ',label= ' ', linestyle='--') ax.legend(loc='upper left') ax.set_ylabel(' ', fontsize=12) ax.set_xlabel('', fontsize=12) ax.set_title(' - level.\n ( pywt.wavedec()) ') show()

Die zweite Möglichkeit, das Signal zu dekonstruieren und wiederherzustellen, ist bequemer. Sie können sofort den gewünschten Dekonstruktionsgrad einstellen.
Entfernen von hochfrequentem Rauschen durch Eliminieren einiger Detailkoeffizienten während der Signaldekonstruktion
Wir werden das Signal wiederherstellen, indem wir einige der Detailkoeffizienten löschen. Da die Detailkoeffizienten den hochfrequenten Teil des Signals darstellen, filtern wir diesen Teil des Frequenzspektrums einfach. Wenn das Signal hochfrequentes Rauschen enthält, können Sie es auf diese Weise filtern.
In der PyWavelets-Bibliothek kann dies mit der Schwellenwertverarbeitungsfunktion pywt.threshol () erfolgen:
pywt.threshold (Daten, Wert, Modus = 'weich', Ersatz = 0) ¶
Daten: array_like
Numerische Daten.Wert: Skalar
Schwellenwert.Modus: {'weich', 'hart', 'garrote', 'größer', 'kleiner'}
Definiert den Typ des Schwellenwerts, der auf die Eingabe angewendet wird. Der Standardwert ist "weich".Ersatz: float, optional
Substitutionswert (Standard: 0).Ausgabe: Array
Schwellenwertarray.Die Anwendung der Schwellenwertverarbeitungsfunktion für einen bestimmten Schwellenwert wird am besten anhand des folgenden Beispiels betrachtet:
>>>> from scipy import* >>> import pywt >>> data =linspace(1, 4, 7) >>> data array([1. , 1.5, 2. , 2.5, 3. , 3.5, 4. ]) >>> pywt.threshold(data, 2, 'soft') array([0. , 0. , 0. , 0.5, 1. , 1.5, 2. ]) >>> pywt.threshold(data, 2, 'hard') array([0. , 0. , 2. , 2.5, 3. , 3.5, 4. ]) >>> pywt.threshold(data, 2, 'garrote') array([0. , 0. , 0., 0.9,1.66666667, 2.35714286, 3.])
Wir zeichnen den Schwellenwertfunktionsgraphen anhand der folgenden Auflistung:
Auflistung from scipy import* from pylab import* import pywt s = linspace(-4, 4, 1000) s_soft = pywt.threshold(s, value=0.5, mode='soft') s_hard = pywt.threshold(s, value=0.5, mode='hard') s_garrote = pywt.threshold(s, value=0.5, mode='garrote') figsize=(10, 4) plot(s, s_soft) plot(s, s_hard) plot(s, s_garrote) legend(['soft (0.5)', 'hard (0.5)', 'non-neg. garrote (0.5)']) xlabel(' ') ylabel(' ') show()
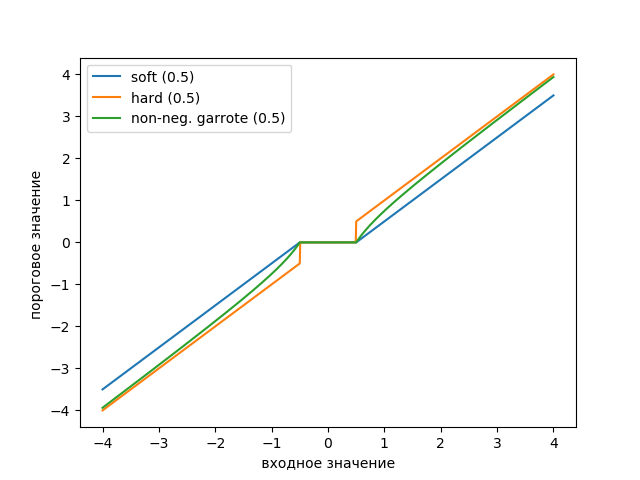
Die Grafik zeigt, dass die nicht negative Garott-Schwelle zwischen der weichen und der harten Schwelle liegt. Es sind zwei Schwellenwerte erforderlich, die die Breite des Übergangsbereichs definieren.
Der Einfluss der Schwellenwertfunktion auf die Filtereigenschaften
Wie aus der obigen Grafik hervorgeht, sind für uns nur zwei Schwellenwertfunktionen "weich" und "Garrote" geeignet. Um ihren Einfluss auf die Filtereigenschaften zu untersuchen, schreiben wir die Liste auf:
Auflistung import pandas as pd from pylab import * import pywt filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) signal = df[4].values v='bior4.4' thres=['soft' ,'garrote'] for w in thres: def lowpassfilter(signal, thresh, wavelet=v): thresh = thresh*nanmax(signal) coeff = pywt.wavedec(signal, wavelet, level=8,mode="per" ) coeff[1:] = (pywt.threshold(i, value=thresh, mode=w ) for i in coeff[1:]) reconstructed_signal = pywt.waverec(coeff, wavelet, mode="per" ) return reconstructed_signal fig, ax = subplots(figsize=(8,4)) ax.plot(signal, color="b", alpha=0.5, label=' ') rec = lowpassfilter(signal, 0.4) ax.plot(rec, 'r', label='DWT ', linewidth=2) ax.legend() ax.set_title(' :%s\n :%s'%(v,w), fontsize=12) ax.set_ylabel(' ', fontsize=12) ax.set_xlabel('', fontsize=12) show()

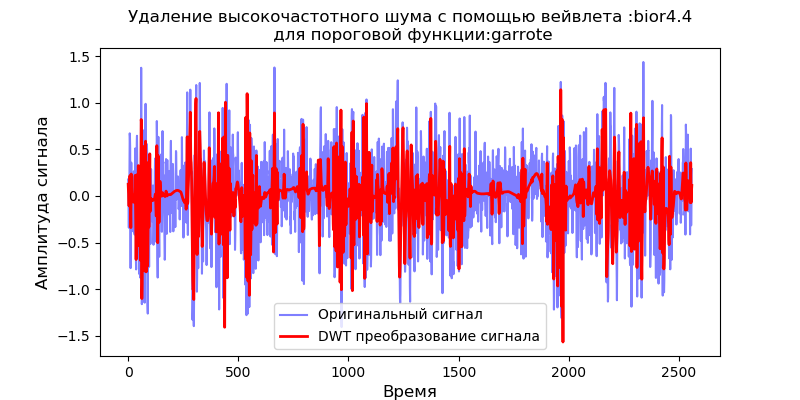
Wie aus den Diagrammen hervorgeht, bietet die Soft-Funktion eine bessere Glättung als die Garrote-Funktion, daher werden wir die Soft-Funktion in Zukunft verwenden.
Der Einfluss der Detailschwelle auf die Filtereigenschaften
Für den betrachteten Filtertyp ist der Schwellenwert für die Änderung der Detailkoeffizienten ein wichtiges Merkmal. Daher untersuchen wir seine Wirkung anhand der folgenden Auflistung:
Auflistung import pandas as pd from pylab import * import pywt filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) signal = df[4].values v='bior4.4' thres=[0.1,0.4,0.6] for w in thres: def lowpassfilter(signal, thresh, wavelet=v): thresh = thresh*nanmax(signal) coeff = pywt.wavedec(signal, wavelet, level=8,mode="per" ) coeff[1:] = (pywt.threshold(i, value=thresh, mode='soft' ) for i in coeff[1:]) reconstructed_signal = pywt.waverec(coeff, wavelet, mode="per" ) return reconstructed_signal fig, ax = subplots(figsize=(8,4)) ax.plot(signal, color="b", alpha=0.5, label=' ') rec = lowpassfilter(signal,w) ax.plot(rec, 'r', label='DWT ', linewidth=2) ax.legend() ax.set_title(' :%s\n %s'%(v,w), fontsize=12) ax.set_ylabel(' ', fontsize=12) ax.set_xlabel('', fontsize=12) show()



Wie aus den erhaltenen Diagrammen hervorgeht, beeinflusst der Detaillierungsgradschwellenwert den Maßstab der gesiebten Teile. Mit einer Erhöhung des Schwellenwerts subtrahiert das Wavelet das Rauschen eines immer höheren Pegels, bis eine übermäßige Vergrößerung der Detailskala auftritt und die Transformation beginnt, die Form des ursprünglichen Signals zu verzerren. Für unser Signal sollte der Schwellenwert nicht höher als 0,63 sein.
Die Wirkung von Wavelet auf die Filtereigenschaften
Die PyWavelets-Bibliothek verfügt über eine ausreichende Anzahl von Wavelets für die DWT-Konvertierung, die wie folgt abgerufen werden können:
>>> import pywt >>> print(pywt.wavelist(kind= 'discrete')) ['bior1.1', 'bior1.3', 'bior1.5', 'bior2.2', 'bior2.4', 'bior2.6', 'bior2.8', 'bior3.1', 'bior3.3', 'bior3.5', 'bior3.7', 'bior3.9', 'bior4.4', 'bior5.5', 'bior6.8', 'coif1', 'coif2', 'coif3', 'coif4', 'coif5', 'coif6', 'coif7', 'coif8', 'coif9', 'coif10', 'coif11', 'coif12', 'coif13', 'coif14', 'coif15', 'coif16', 'coif17', 'db1', 'db2', 'db3', 'db4', 'db5', 'db6', 'db7', 'db8', 'db9', 'db10', 'db11', 'db12', 'db13', 'db14', 'db15', 'db16', 'db17', 'db18', 'db19', 'db20', 'db21', 'db22', 'db23', 'db24', 'db25', 'db26', 'db27', 'db28', 'db29', 'db30', 'db31', 'db32', 'db33', 'db34', 'db35', 'db36', 'db37', 'db38', 'dmey', 'haar', 'rbio1.1', 'rbio1.3', 'rbio1.5', 'rbio2.2', 'rbio2.4', 'rbio2.6', 'rbio2.8', 'rbio3.1', 'rbio3.3', 'rbio3.5', 'rbio3.7', 'rbio3.9', 'rbio4.4', 'rbio5.5', 'rbio6.8', 'sym2', 'sym3', 'sym4', 'sym5', 'sym6', 'sym7', 'sym8', 'sym9', 'sym10', 'sym11', 'sym12', 'sym13', 'sym14', 'sym15', 'sym16', 'sym17', 'sym18', 'sym19', 'sym20']
Der Einfluss des Wavelets auf die Filtercharakteristik hängt von seiner primitiven Funktion ab. Um diese Abhängigkeit zu demonstrieren, wählen wir zwei Wavelets aus der Dobeshi-Familie aus - db1 und db38 - und betrachten diese Familien:
Auflistung import pywt from pylab import* db_wavelets = ['db1', 'db38'] fig, axarr = subplots(ncols=2, nrows=5, figsize=(14,8)) fig.suptitle(' : db1,db38', fontsize=14) for col_no, waveletname in enumerate(db_wavelets): wavelet = pywt.Wavelet(waveletname) no_moments = wavelet.vanishing_moments_psi family_name = wavelet.family_name for row_no, level in enumerate(range(1,6)): wavelet_function, scaling_function, x_values = wavelet.wavefun(level = level) axarr[row_no, col_no].set_title("{} : {}. : {}. :: {} ".format( waveletname, level, no_moments, len(x_values)), loc='left') axarr[row_no, col_no].plot(x_values, wavelet_function, 'b--') axarr[row_no, col_no].set_yticks([]) axarr[row_no, col_no].set_yticklabels([]) tight_layout() subplots_adjust(top=0.9) show()
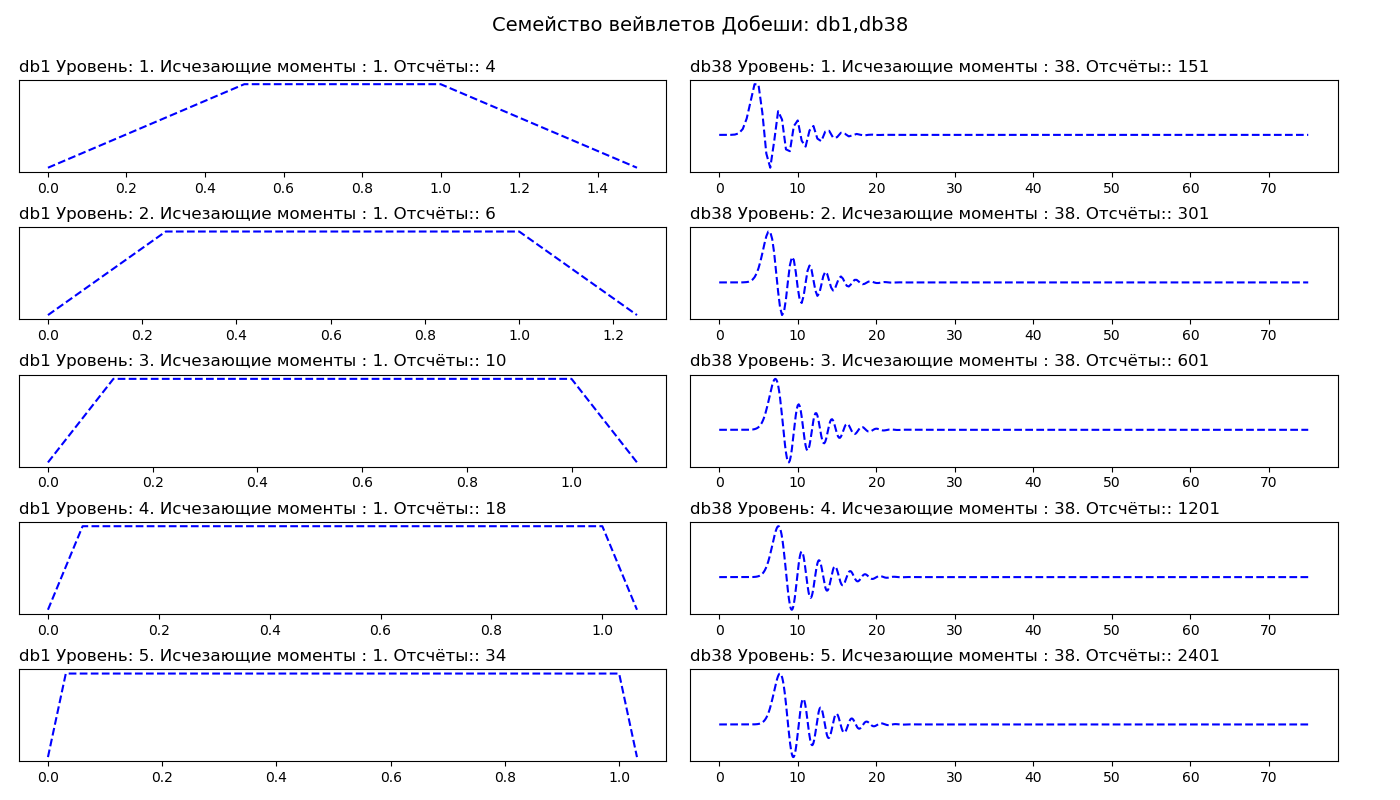
In der ersten Spalte sehen wir Daubeshi-Wavelets erster Ordnung (db1), in der zweiten Spalte achtunddreißigster Ordnung (db38). Somit hat db1 einen Moment des Aussterbens und db38 hat 38 Momente des Aussterbens. Die Anzahl der Momente des Verschwindens hängt mit der Reihenfolge der Approximation und der Glätte des Wavelets zusammen. Wenn ein Wavelet P Verschwindungspunkte hat, kann es Polynome vom Grad P - 1 approximieren.
Glattere Wavelets erzeugen eine glattere Signalannäherung, und umgekehrt - „kurze“ Wavelets verfolgen die Spitzen der angenäherten Funktion besser. Bei der Auswahl eines Wavelets können wir auch den Zersetzungsgrad angeben. Standardmäßig wählt PyWavelets den maximal möglichen Zerlegungspegel für das Eingangssignal aus. Der maximale Zerlegungspegel hängt von der Länge des Eingangssignals und des Wavelets ab:
Auflistung import pandas as pd import pywt filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) data = df[4].values w=['db1', 'db38'] for v in w: n_level=pywt.dwt_max_level(len(data),v) print(' %s : %s ' %(v,n_level))
Für db1 Wavelet maximales Zerlegungsniveau: 11
Für db38 Wavelet maximales Zerlegungsniveau: 5
Für die erhaltenen Werte der maximalen Wavelet-Zerlegungspegel betrachten wir den Betrieb des Filters, um hochfrequentes Rauschen zu entfernen:
Auflistung import pandas as pd import scaleogram as scg from pylab import * import pywt filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) signal = df[4].values discrete_wavelets =[('db38', 5),('db1',11)] for v in discrete_wavelets: def lowpassfilter(signal, thresh = 0.63, wavelet=v[0]): thresh = thresh*nanmax(signal) coeff = pywt.wavedec(signal, wavelet, mode="per" ) coeff[1:] = (pywt.threshold(i, value=thresh, mode='soft' ) for i in coeff[1:]) reconstructed_signal = pywt.waverec(coeff, wavelet, mode="per" ) return reconstructed_signal wavelet = pywt.DiscreteContinuousWavelet(v[0]) phi, psi, x = wavelet.wavefun(level=v[1]) fig, ax = subplots(figsize=(8,4)) ax.set_title(" : %s,level=%s"%(v[0],v[1]), fontsize=12) ax.plot(x,phi,linewidth=2) fig, ax = subplots(figsize=(8,4)) ax.plot(signal, color="b", alpha=0.5, label=' ') rec = lowpassfilter(signal, 0.4) ax.plot(rec, 'r', label='DWT ', linewidth=2) ax.legend() ax.set_title(' \n :%s,level=%s'%(v[0],v[1]),fontsize=12) ax.set_ylabel(' ', fontsize=12) ax.set_xlabel('', fontsize=12) wavelet = 'cmor1-0.5' ax = ax = scg.cws(rec, scales=arange(1,128), wavelet=wavelet,figsize=(8, 4), cmap="jet", ylabel=' ', xlabel=" ", yscale="log", title='CWT \n( DWT )') show()

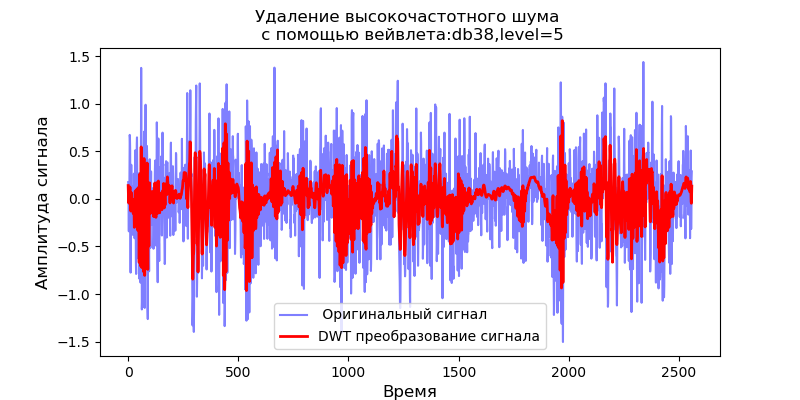
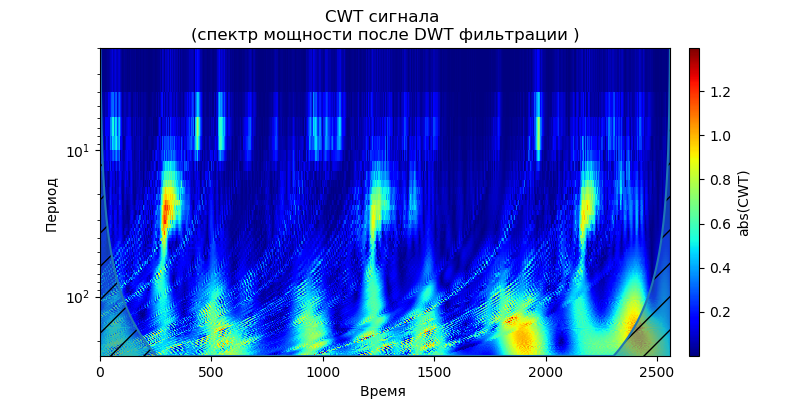

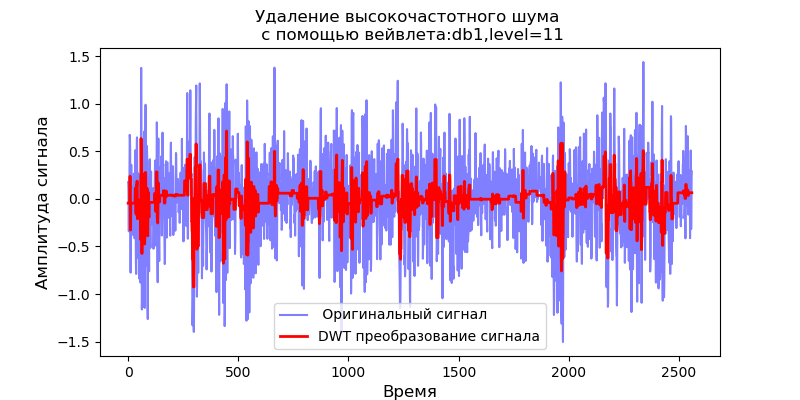

Aus den zitierten Wellenformen der Signale am Filterausgang folgt, dass für das db38-Wavelet auf die Spitzenleistung des Spektrums lokalisierte Bereiche folgen, für das db1-Wavelet verschwinden diese Bereiche. Es ist anzumerken, dass beispielsweise das db38-Wavelet ein Signal mit einem Polynom vom Grad 37 approximieren kann. Dies erweitert die Klassifizierung von Signalen, um beispielsweise Fehlfunktionen von Geräten anhand der Signale von Vibrationssensoren zu identifizieren.
Da das Signal nach dem Filter mit dem Daubechies-Wavelet eine Zeitreihe unter Verwendung von Approximations- und Zerlegungskoeffizienten als Eigenschaften der Reihe bildet, kann man den Grad der Nähe solcher Reihen bestimmen, was ihre Suche und Klassifizierung stark vereinfachtKalman-Filter zur Entfernung von hochfrequentem Rauschen
Das Kalman-Filter wird häufig zum Filtern von Rauschen in verschiedenen dynamischen Systemen verwendet. Betrachten Sie ein dynamisches System mit einem Zustandsvektor x.
wobei F die Übergangsmatrix ist
w (Q) ist ein zufälliger Prozess (Rauschen) mit einer mathematischen Erwartung von Null und einer Kovarianzmatrix Q.
Wir werden zu jedem Zeitpunkt Zustandsübergänge des Systems mit einem bekannten Messfehler beobachten. Das Entfernen von Rauschen mit der Kalman-Methode besteht aus zwei Schritten: Extrapolation und Korrektur.
Stellen Sie die Systemparameter ein:
Q-Matrix der Rauschkovarianz (Prozessrauschkovarianz).
H ist die Beobachtungsmatrix (Messung).
R - Kovarianz des Beobachtungsrauschens (Messrauschkovarianz).
P = Q ist der Anfangswert der Kovarianzmatrix für den Zustandsvektor.
z (t) ist der beobachtete Zustand des Systems.
x = z (0) ist der Anfangswert der Bewertung des Zustands des Systems.
Für jede Beobachtung z berechnen wir den gefilterten Zustand x
und dazu führen wir die folgenden schritte aus.
• Schritt 1: Extrapolation
1. Extrapolation (Vorhersage) des Zustands des Systems
2. Berechnen Sie die Kovarianzmatrix für den extrapolierten Zustandsvektor
• Schritt 2: Korrektur
1. Berechnen Sie den Fehlervektor, die Abweichung der Beobachtung vom erwarteten Zustand
2. Berechnen Sie die Kovarianzmatrix für den Abweichungsvektor (Fehlervektor)
3. Berechnen Sie die Kalman-Gewinne
4. Korrektur der Zustandsvektorschätzung
5. Wir korrigieren die Kovarianzmatrix zur Schätzung des Systemzustandsvektors
Auflistung für die Implementierung des Algorithmus from scipy import* from pylab import* import pandas as pd def kalman_filter( z, F = eye(2), # (transitionMatrix) Q = eye(2)*3e-3, # (processNoiseCov) H = eye(2), # (measurement) R = eye(2)*3e-1 # (measurementNoiseCov) ): n = z.shape[0]
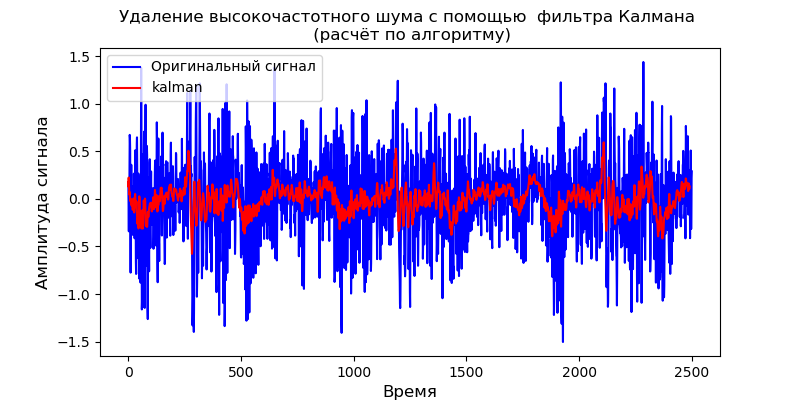
Für das angegebene dynamische Modell können Sie die pyKalman-Bibliothek verwenden:
Auflistung from pykalman import KalmanFilter import pandas as pd from pylab import * import scaleogram as scg filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) signal = df[4].values measurements =signal kf = KalmanFilter(transition_matrices=[1] ,



Das Kalman-Filter entfernt hochfrequentes Rauschen, erlaubt jedoch keine Änderung der Form des Ausgangssignals.
Methode des gleitenden Durchschnitts
Bei der Bestimmung der Hauptrichtung von Änderungen in einer stark oszillierenden Sequenz tritt das Problem auf, sie unter Verwendung der Methode des gleitenden Durchschnitts zu glätten. Dies können die Messwerte des Kraftstoffstandsensors im Auto oder, wie in unserem Fall, die Daten von Hochfrequenzsensoren bezüglich des beschleunigten Abbaus von Lagern sein. Das Problem kann als Wiederherstellung einer Sequenz r betrachtet werden, der Rauschen überlagert wurde.
Kurzer einfacher gleitender Durchschnitt - SMA (Simple Moving Average). Berechnung des aktuellen Filterwerts
Wir mitteln nur die vorherigen n Elemente der Sequenz, sodass der Filter mit dem Element der Sequenz n arbeitet.
Auflistung <source lang="python">from scipy import * import pandas as pd from pylab import * import pywt import scaleogram as scg def get_ave_values(xvalues, yvalues, n = 6): signal_length = len(xvalues) if signal_length % n == 0: padding_length = 0 else: padding_length = n - signal_length//n % n xarr = array(xvalues) yarr = array(yvalues) xarr.resize(signal_length//n, n) yarr.resize(signal_length//n, n) xarr_reshaped = xarr.reshape((-1,n)) yarr_reshaped = yarr.reshape((-1,n)) x_ave = xarr_reshaped[:,0] y_ave = nanmean(yarr_reshaped, axis=1) return x_ave, y_ave def plot_signal_plus_average(time, signal, average_over = 5): fig, ax = subplots(figsize=(8, 4)) time_ave, signal_ave = get_ave_values(time, signal, average_over) ax.plot(time_ave, signal_ave,"b", label = ' (n={})'.format(5)) ax.set_xlim([time[0], time[-1]]) ax.set_ylabel(' ', fontsize=12) ax.set_title(' SMA', fontsize=14) ax.set_xlabel('', fontsize=12) ax.legend() return signal_ave filename = 'Test_set/Bearing2_3/acc_00001.csv' df = pd.read_csv(filename, header=None) df_nino = df[4].values N = df_nino.shape[0] time = arange(0, N) signal = df_nino signal_ave=plot_signal_plus_average(time, signal) wavelet = 'cmor1-0.5' ax = ax = scg.cws(signal, scales=arange(1,40), wavelet=wavelet, figsize=(8, 4),cmap="jet", ylabel=' ', xlabel=" ", yscale="log", title='CWT %s \n( )'%filename) ax = ax = scg.cws(signal_ave, scales=arange(1,40), wavelet=wavelet, figsize=(8, 4), cmap="jet", ylabel=' ', xlabel=" ", yscale="log", title='CWT %s \n( )'%filename) show()

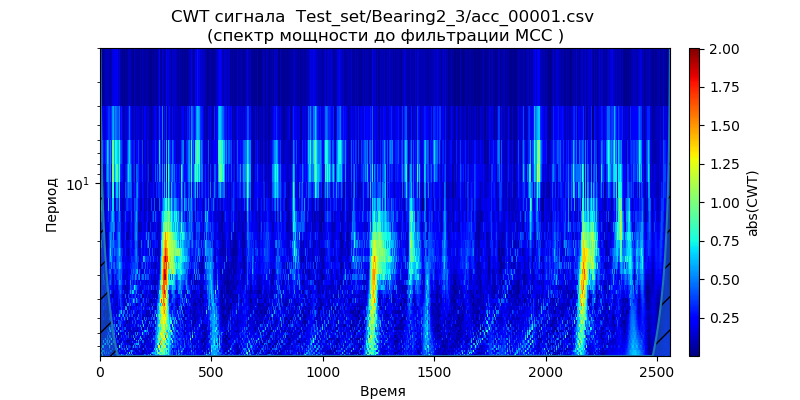

Wie aus dem Skalogramm folgt, reinigt das SMA-Verfahren das Signal schlecht von hochfrequentem Rauschen und
wie oben erwähnt wird zum Glätten verwendet.
Schlussfolgerungen:
- Unter Verwendung des Skalogrammmoduls wurden CWT-Wavelet-Skalogramme von drei Testvibrationssensorsignalen für verschiedene Testbedingungen für Lager des gleichen Typs erhalten. Gemäß den Skalogrammdaten wurde ein Signal mit deutlich zum Ausdruck gebrachten Anzeichen einer späten Verschlechterung ausgewählt. Dieses Signal wurde verwendet, um die Funktionsweise von Filtern in allen angegebenen Beispielen zu demonstrieren.
- Die Methoden der PyWavelets-Bibliothek zur DWT-Dekonstruktion und Wiederherstellung des Schwingungssensorsignals unter Verwendung der Module pywt.dwt (), pywt.idwt () und des Moduls pywt.wavedec () für einen bestimmten Wavelet-Pegel werden berücksichtigt.
- Die Beispiele veranschaulichen die Anwendungsmerkmale des Moduls pywt.threshol () zum Filtern von DWT-Detailkoeffizienten, die für den hochfrequenten Teil des Spektrums unter Verwendung von Schwellenwertfunktionen für einen bestimmten Schwellenwert verantwortlich sind.
- Die Auswirkungen des antiderivativen DWT-Wavelets auf die Form eines vom Rauschen befreiten Signals werden berücksichtigt.
- Man erhält ein Kalman-Filtermodell für ein dynamisches Medium, das Modell wird am Testsignal des Schwingungssensors getestet. Das Rauschunterdrückungsdiagramm ist das gleiche wie das, das mit dem pyKalman-Modul erhalten wurde. Die Art des Diagramms stimmt mit dem Skalogramm überein.
- .