Vor einiger Zeit wurden wir in einer Diskussion über eine der Versionen von SObjectizer gefragt: "Ist es möglich, ein DSL zur Beschreibung einer Datenverarbeitungspipeline zu erstellen?" Mit anderen Worten, ist es möglich, so etwas zu schreiben:
A | B | C | D
und erhalten Sie eine funktionierende Pipeline, in der Nachrichten von A nach B und dann nach C und dann nach D geleitet werden. Mit der Kontrolle erhält B genau den Typ, den A zurückgibt. Und C empfängt genau den Typ, den B zurückgibt. Und so weiter.
Es war eine interessante Aufgabe mit einer überraschend einfachen Lösung. So kann beispielsweise die Erstellung einer Pipeline aussehen:
auto pipeline = make_pipeline(env, stage(A) | stage(B) | stage(C) | stage(D));
Oder in einem komplexeren Fall (der unten diskutiert wird):
auto pipeline = make_pipeline( sobj.environment(), stage(validation) | stage(conversion) | broadcast( stage(archiving), stage(distribution), stage(range_checking) | stage(alarm_detector{}) | broadcast( stage(alarm_initiator), stage( []( const alarm_detected & v ) { alarm_distribution( cerr, v ); } ) ) ) );
In diesem Artikel werden wir über die Implementierung eines solchen Pipeline-DSL sprechen. Wir werden hauptsächlich Teile im Zusammenhang mit stage() , broadcast() und operator|() -Funktionen mit mehreren Beispielen für die Verwendung von C ++ - Vorlagen diskutieren. Ich hoffe, es wird auch für Leser interessant sein, die nichts über SObjectizer wissen (wenn Sie noch nie von SObjectizer gehört haben, finden Sie hier eine Übersicht über dieses Tool).
Ein paar Worte zur verwendeten Demo
Das in diesem Artikel verwendete Beispiel wurde von meiner alten (und eher vergessenen) Erfahrung im SCADA-Bereich beeinflusst.
Die Idee der Demo ist der Umgang mit Daten, die von einem Sensor gelesen werden. Die Daten werden von einem Sensor mit einer gewissen Zeitspanne erfasst, dann müssen diese Daten validiert (falsche Daten sollten ignoriert werden) und in einige tatsächliche Werte umgewandelt werden. Beispielsweise können die von einem Sensor gelesenen Rohdaten zwei 8-Bit-Ganzzahlwerte sein, und diese Werte sollten in eine Gleitkommazahl umgewandelt werden.
Dann sollten die gültigen und konvertierten Werte archiviert, irgendwo verteilt (z. B. auf verschiedenen Knoten zur Visualisierung) und auf "Alarme" überprüft werden (wenn Werte außerhalb sicherer Bereiche liegen, sollte dies speziell behandelt werden). Diese Operationen sind unabhängig und können parallel ausgeführt werden.
Operationen, die sich auf den erkannten Alarm beziehen, können auch parallel ausgeführt werden: Ein "Alarm" sollte ausgelöst werden (damit der Teil von SCADA auf dem aktuellen Knoten darauf reagieren kann) und die Informationen über den "Alarm" sollten an anderer Stelle verteilt werden (z. B.) : in einer historischen Datenbank gespeichert und / oder auf dem Display des SCADA-Bedieners visualisiert).
Diese Logik kann in Textform folgendermaßen ausgedrückt werden:
optional(valid_raw_data) = validate(raw_data); if valid_raw_data is not empty then { converted_value = convert(valid_raw_data); do_async archive(converted_value); do_async distribute(converted_value); do_async { optional(suspicious_value) = check_range(converted_value); if suspicious_value is not empty then { optional(alarm) = detect_alarm(suspicious_value); if alarm is not empty then { do_async initiate_alarm(alarm); do_async distribute_alarm(alam); } } } }
Oder in grafischer Form:

Es ist ein ziemlich künstliches Beispiel, aber es hat einige interessante Dinge, die ich zeigen möchte. Das erste ist das Vorhandensein paralleler Stufen in einer Pipeline (Operation broadcast() existiert nur deswegen). Das zweite ist das Vorhandensein eines Staates in einigen Stadien. Zum Beispiel ist alarm_detector eine Stateful-Phase.
Pipeline-Funktionen
Eine Pipeline wird aus getrennten Stufen aufgebaut. Jede Stufe ist eine Funktion oder ein Funktor des folgenden Formats:
opt<Out> func(const In &);
oder
void func(const In &);
Stufen, die void können nur als letzte Stufe einer Pipeline verwendet werden.
Stufen sind zu einer Kette verbunden. Jede nächste Stufe erhält ein Objekt, das von der vorherigen Stufe zurückgegeben wurde. Wenn die vorherige Stufe den leeren Wert opt<Out> zurückgibt, wird die nächste Stufe nicht aufgerufen.
Es gibt eine spezielle broadcast . Es besteht aus mehreren Pipelines. Eine broadcast empfängt ein Objekt aus der vorherigen Stufe und sendet es an jede Tochterpipeline.
Aus Sicht der Pipeline sieht die broadcast Phase wie eine Funktion des folgenden Formats aus:
void func(const In &);
Da es keinen Rückgabewert von der broadcast Stufe gibt, kann eine broadcast Stufe nur die letzte Stufe in einer Pipeline sein.
Warum gibt die Pipeline-Stufe einen optionalen Wert zurück?
Dies liegt daran, dass einige eingehende Werte gelöscht werden müssen. Beispielsweise gibt die validate nichts zurück, wenn ein Rohwert falsch ist und es keinen Sinn macht, damit umzugehen.
Ein weiteres Beispiel: Die Stufe alarm_detector gibt nichts zurück, wenn der aktuelle verdächtige Wert keinen neuen Alarmfall erzeugt.
Implementierungsdetails
Beginnen wir mit Datentypen und Funktionen, die sich auf die Anwendungslogik beziehen. In dem diskutierten Beispiel werden die folgenden Datentypen verwendet, um Informationen von einer Stufe zur anderen zu übergeben:
Eine Instanz von raw_value geht in die erste Phase unserer Pipeline. Dieser raw_value enthält Informationen, die von einem Sensor in Form eines raw_measure Objekts raw_measure . Dann wird raw_value in valid_raw_value . Dann valid_raw_value sensor_value mit dem Wert eines tatsächlichen Sensors in Form von calulated_measure in calulated_measure . Wenn eine Instanz von sensor_value einen verdächtigen Wert enthält, wird eine Instanz von suspicious_value erzeugt. Und dieser suspicious_value kann später in eine alarm_detected Instanz umgewandelt werden.
Oder in grafischer Form:

Jetzt können wir einen Blick auf die Implementierung unserer Pipeline-Phasen werfen:
Überspringen stage_result_t make_result make_empty wie stage_result_t , make_result und make_empty , wir werden es im nächsten Abschnitt besprechen.
Ich hoffe, dass der Code dieser Stufen eher trivial ist. Der einzige Teil, der einer zusätzlichen Erläuterung bedarf, ist die Implementierung der Stufe alarm_detector .
In diesem Beispiel wird ein Alarm nur ausgelöst, wenn im Zeitfenster von 25 ms mindestens zwei suspicious_values Werte vorhanden sind. Wir müssen uns also die Zeit der vorherigen suspicious_value Instanz im Stadium alarm_detector . alarm_detector liegt daran, dass alarm_detector als Stateful Functor mit einem Funktionsaufrufoperator alarm_detector ist.
Stufen geben den Typ von SObjectizer anstelle von std :: optional zurück
Ich habe vorhin gesagt, dass die Stufe einen optionalen Wert zurückgeben könnte. Aber std::optional wird im Code nicht verwendet, der unterschiedliche Typ stage_result_t kann in der Implementierung von Stufen gesehen werden.
Dies liegt daran, dass einige der spezifischen Funktionen von SObjectizer hier eine Rolle spielen. Die zurückgegebenen Werte werden als Nachrichten zwischen den Agenten von SObjectizer (auch als Akteure bezeichnet) verteilt. Jede Nachricht in SObjectizer wird als dynamisch zugewiesenes Objekt gesendet. Wir haben hier also eine Art "Optimierung": Anstatt std::optional und dann ein neues Nachrichtenobjekt zuzuweisen, weisen wir einfach ein Nachrichtenobjekt zu und geben einen intelligenten Zeiger darauf zurück.
Tatsächlich ist stage_result_t nur ein typedef für SObjectizers shared_ptr-Analog:
template< typename M > using stage_result_t = message_holder_t< M >;
Und make_result und make_empty sind nur make_result make_empty stage_result_t mit oder ohne tatsächlichen Wert:
template< typename M, typename... Args > stage_result_t< M > make_result( Args &&... args ) { return stage_result_t< M >::make(forward< Args >(args)...); } template< typename M > stage_result_t< M > make_empty() { return stage_result_t< M >(); }
Der Einfachheit halber kann man mit Sicherheit sagen, dass die validation folgendermaßen ausgedrückt werden könnte:
std::shared_ptr< valid_raw_value > validation( const raw_value & v ) { if( 0x7 >= v.m_data.m_high_bits ) return std::make_shared< valid_raw_value >( v.m_data ); else return std::shared_ptr< valid_raw_value >{}; }
Aufgrund der Besonderheiten von SObjectizer können wir std::shared_ptr jedoch nicht verwenden und müssen so_5::message_holder_t Typ so_5::message_holder_t befassen. Und wir verstecken das spezifisch hinter den stage_result_t , make_result und make_empty .
Stage_handler_t und Stage_builder_t Trennung
Ein wichtiger Punkt bei der Pipeline-Implementierung ist die Trennung von Stage-Handler- und Stage-Builder- Konzepten. Dies geschieht der Einfachheit halber. Das Vorhandensein dieser Konzepte ermöglichte mir zwei Schritte in der Pipeline-Definition.
Im ersten Schritt beschreibt ein Benutzer Pipeline-Phasen. Als Ergebnis erhalte ich eine Instanz von stage_t , die alle Pipeline-Stufen enthält.
Im zweiten Schritt wird eine Reihe von zugrunde liegenden SObjectizer-Agenten erstellt. Diese Agenten empfangen Nachrichten mit Ergebnissen der vorherigen Phasen und rufen die tatsächlichen Phasenhandler auf . Anschließend senden sie die Ergebnisse an die nächsten Phasen.
Um diese Gruppe von Agenten zu erstellen, muss jede Stufe einen Bühnenbauer haben . Stage Builder kann als Factory betrachtet werden, die den Agenten eines zugrunde liegenden SObjectizers erstellt.
Wir haben also die folgende Beziehung: Jede Pipeline-Stufe erzeugt zwei Objekte: Stage-Handler mit stufenbezogener Logik und Stage-Builder , der den Agenten eines zugrunde liegenden SObjectizers erstellt, um den Stage-Handler zum richtigen Zeitpunkt aufzurufen:

Der Stage Handler wird folgendermaßen dargestellt:
template< typename In, typename Out > class stage_handler_t { public : using traits = handler_traits_t< In, Out >; using func_type = function< typename traits::output(const typename traits::input &) >; stage_handler_t( func_type handler ) : m_handler( move(handler) ) {} template< typename Callable > stage_handler_t( Callable handler ) : m_handler( handler ) {} typename traits::output operator()( const typename traits::input & a ) const { return m_handler( a ); } private : func_type m_handler; };
Wobei handler_traits_t folgendermaßen definiert werden:
Der Stage Builder wird nur durch std::function :
using stage_builder_t = function< mbox_t(coop_t &, mbox_t) >;
Hilfstypen lambda_traits_t und callable_traits_t
Da Stufen durch freie Funktionen oder Funktoren dargestellt werden können (z. B. Instanzen der Klasse alarm_detector oder von anonymen Compilern generierte Klassen, die Lambdas darstellen), benötigen wir einige Helfer, um die Argumente und den Rückgabewert der Stufe zu erkennen. Zu diesem Zweck habe ich den folgenden Code verwendet:
Ich hoffe, dass dieser Code für Leser mit guten C ++ - Kenntnissen durchaus verständlich ist. Wenn nicht, können Sie mich gerne in den Kommentaren fragen. Gerne erkläre ich Ihnen die Logik hinter lambda_traits_t und lambda_traits_t im Detail.
Stage () -, Broadcast () - und Operator | () -Funktionen
Jetzt können wir uns die wichtigsten Funktionen zum Aufbau von Pipelines ansehen. stage_t die Definition einer Vorlagenklasse stage_t :
template< typename In, typename Out > struct stage_t { stage_builder_t m_builder; };
Es ist eine sehr einfache Struktur, die nur stage_bulder_t Instanz stage_bulder_t . Vorlagenparameter werden in stage_t nicht verwendet. Warum sind sie hier also vorhanden?
Sie sind für die Überprüfung der Typkompatibilität zwischen Pipeline-Stufen zur Kompilierungszeit erforderlich. Wir werden das bald sehen.
Schauen wir uns die einfachste Pipeline-Funktion an, die stage() :
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( Callable handler ) { stage_builder_t builder{ [h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent< a_stage_point_t<In, Out> >( std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
Es erhält einen tatsächlichen Stage-Handler als einzelnen Parameter. Es kann ein Zeiger auf eine Funktion oder eine Lambda-Funktion oder einen Funktor sein. Die Arten der Eingabe und Ausgabe der Bühne werden aufgrund der "Vorlagenmagie" hinter der Vorlage callable_traits_t automatisch abgeleitet.
Eine Instanz des Stage Builders wird im Inneren erstellt und diese Instanz wird als Ergebnis der Funktion stage() in einem neuen stage_t Objekt zurückgegeben. Ein tatsächlicher Stage-Handler wird vom Stage-Builder Lambda erfasst und dann für die Erstellung eines zugrunde liegenden SObjectizer-Agenten verwendet (darüber werden wir im nächsten Abschnitt sprechen).
Die nächste zu überprüfende Funktion ist der operator|() , der zwei Stufen miteinander verkettet und eine neue Stufe zurückgibt:
template< typename In, typename Out1, typename Out2 > stage_t< In, Out2 > operator|( stage_t< In, Out1 > && prev, stage_t< Out1, Out2 > && next ) { return { stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } } }; }
Der einfachste Weg, die Logik des operator|() zu erklären, besteht darin, ein Bild zu zeichnen. Nehmen wir an, wir haben den Ausdruck:
stage(A) | stage(B) | stage(C) | stage(B)
Dieser Ausdruck wird folgendermaßen transformiert:

Dort können wir auch sehen, wie die Typprüfung zur Kompilierungszeit funktioniert: Die Definition des operator|() erfordert, dass der Ausgabetyp der ersten Stufe die Eingabe der zweiten Stufe ist. Ist dies nicht der Fall, wird der Code nicht kompiliert.
Und jetzt können wir uns die komplexeste Funktion zum Aufbau von Pipelines ansehen, die broadcast() . Die Funktion selbst ist ziemlich einfach:
template< typename In, typename Out, typename... Rest > stage_t< In, void > broadcast( stage_t< In, Out > && first, Rest &&... stages ) { stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)] ( coop_t & coop, mbox_t ) -> mbox_t { vector< mbox_t > mboxes; mboxes.reserve( broadcasts.size() ); for( const auto & b : broadcasts ) mboxes.emplace_back( b( coop, mbox_t{} ) ); return broadcast_mbox_t::make( coop.environment(), std::move(mboxes) ); } }; return { std::move(builder) }; }
Der Hauptunterschied zwischen einer gewöhnlichen Bühne und einer Rundfunkbühne besteht darin, dass die Rundfunkbühne einen Vektor von Nebenbühnenbauern enthalten muss . Also müssen wir diesen Vektor erstellen und ihn an den Hauptbühnenbauer der Rundfunkbühne übergeben. Aus diesem Grund können wir einen Aufruf von collect_sink_builders in der Capture-Liste eines Lambdas in der Funktion collect_sink_builders broadcast() :
stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)]
Wenn wir uns collect_sink_builder ansehen, collect_sink_builder wir den folgenden Code:
Die Typprüfung zur Kompilierungszeit funktioniert auch hier: Ein Aufruf von move_sink_builder_to explizit durch den Typ 'In' parametrisiert. collect_sink_builders(stage_t<In1, Out1>, stage_t<In2, Out2>, ...) bedeutet, dass ein Aufruf in der Form collect_sink_builders(stage_t<In1, Out1>, stage_t<In2, Out2>, ...) zu einem Kompilierungsfehler führt, da der Compiler einen Aufruf von move_sink_builder_to<In1>(receiver, stage_t<In2, Out2>, ...) .
Ich kann auch feststellen, dass wir, da die Anzahl der Nebenpipelines für broadcast() zur Kompilierungszeit bekannt ist, std::array anstelle von std::vector und einige Speicherzuordnungen vermeiden können. Der Einfachheit halber wird hier jedoch std::vector verwendet.
Beziehung zwischen Stufen und Agenten / mboxen von SObjectizer
Die Idee hinter der Implementierung der Pipeline ist die Erstellung eines separaten Agenten für jede Pipeline-Phase. Ein Agent empfängt eine eingehende Nachricht, leitet sie an den entsprechenden Stage-Handler weiter , analysiert das Ergebnis und sendet das Ergebnis als eingehende Nachricht an die nächste Stufe, wenn das Ergebnis nicht leer ist. Dies kann durch das folgende Sequenzdiagramm veranschaulicht werden:

Einige SObjectizer-bezogene Dinge müssen zumindest kurz besprochen werden. Wenn Sie kein Interesse an solchen Details haben, können Sie die folgenden Abschnitte überspringen und direkt zum Abschluss gehen.
Coop ist eine Gruppe von Agenten, die zusammenarbeiten
Agenten werden nicht einzeln, sondern in Gruppen mit dem Namen coops in SObjectizer eingeführt. Ein Coop ist eine Gruppe von Agenten, die zusammenarbeiten sollten, und es macht keinen Sinn, die Arbeit fortzusetzen, wenn einer der Agenten der Gruppe fehlt.
Die Einführung von Agenten in SObjectizer sieht also so aus, als würde eine Coop-Instanz erstellt, diese Instanz mit den entsprechenden Agenten gefüllt und dann die Coop in SObjectizer registriert.
Aus diesem Grund ist das erste Argument für einen Bühnenbauer ein Verweis auf einen neuen Coop. Dieser Coop wird in der Funktion make_pipeline() erstellt ( make_pipeline() unten), dann von Stage Buildern make_pipeline() und dann registriert (erneut in der Funktion make_pipeline() ).
Meldungsfelder
SObjectizer implementiert mehrere Parallelitätsmodelle. Das Actor Model ist nur einer von ihnen. Aus diesem Grund kann sich SObjectizer erheblich von anderen Akteur-Frameworks unterscheiden. Einer der Unterschiede ist das Adressierungsschema für Nachrichten.
Nachrichten in SObjectizer richten sich nicht an Akteure, sondern an Nachrichtenfelder (mboxes). Schauspieler müssen Nachrichten von einer mbox abonnieren. Wenn ein Akteur einen bestimmten Nachrichtentyp von einer mbox abonniert, erhält er Nachrichten dieses Typs:
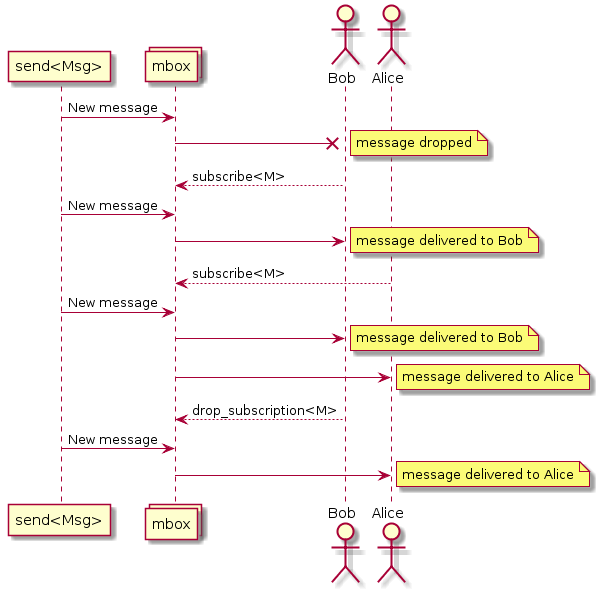
Diese Tatsache ist entscheidend, da Nachrichten von einer Stufe zur anderen gesendet werden müssen. Dies bedeutet, dass jede Stufe ihre mbox haben sollte und dass mbox für die vorherige Stufe bekannt sein sollte.
Jeder Schauspieler (auch bekannt als Agent) in SObjectizer hat die direkte mbox . Diese mbox ist nur dem Eigentümeragenten zugeordnet und kann von keinem anderen Agenten verwendet werden. Die direkten mboxen von Agenten, die für Stufen erstellt wurden, werden für die Stufeninteraktion verwendet.
Die spezifische Funktion dieses SObjectizers bestimmt einige Details der Pipeline-Implementierung.
Das erste ist die Tatsache, dass Stage Builder den folgenden Prototyp hat:
mbox_t builder(coop_t &, mbox_t);
Dies bedeutet, dass der Stage Builder eine mbox der nächsten Stufe empfängt und einen neuen Agenten erstellen sollte, der die Ergebnisse der Stufe an diese mbox sendet. Eine mbox des neuen Agenten sollte vom Stage Builder zurückgegeben werden . Diese mbox wird für die Erstellung eines Agenten für die vorherige Stufe verwendet.
Das zweite ist die Tatsache, dass Agenten für Stufen in Reservereihenfolge erstellt werden. Es bedeutet, dass wenn wir eine Pipeline haben:
stage(A) | stage(B) | stage(C)
Zuerst wird ein Agent für Stufe C erstellt, dann wird seine mbox für die Erstellung eines Agenten für Stufe B verwendet, und dann wird die mbox des Agenten der Stufe B für die Erstellung eines Agenten für Stufe A verwendet.
Beachten Sie auch, dass der operator|() keine Agenten erstellt:
stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } }
Der operator|() erstellt einen Builder, der nur andere Builder aufruft, aber keine zusätzlichen Agenten einführt. Also für den Fall:
stage(A) | stage(B)
Es werden nur zwei Agenten erstellt (für A-Stufe und B-Stufe), die dann im vom operator|() erstellten Stage Builder miteinander verknüpft werden.
Es gibt keinen Agenten für broadcast() Implementierung von broadcast()
Eine naheliegende Möglichkeit, eine Broadcast-Phase zu implementieren, besteht darin, einen speziellen Agenten zu erstellen, der eine eingehende Nachricht empfängt und diese Nachricht dann erneut an eine Liste von Ziel-Mboxes sendet. Dieser Weg wurde bei der ersten Implementierung der beschriebenen Pipeline DSL verwendet.
Aber unser Begleitprojekt, so5extra , hat jetzt eine spezielle Variante von mbox: Broadcasting one. Diese mbox macht genau das, was hier erforderlich ist: Sie nimmt eine neue Nachricht auf und sendet sie an eine Reihe von Ziel-mboxen.
Aus diesem Grund muss kein separater Broadcast-Agent erstellt werden. Wir können einfach die Broadcast-Mbox von so5extra verwenden:
Implementierung von Stage-Agent
Jetzt können wir uns die Implementierung von Stage Agent ansehen:
Es ist ziemlich trivial, wenn Sie die Grundlagen des SObjectizers verstehen. Wenn nicht, wird es ziemlich schwierig sein, es in wenigen Worten zu erklären (also zögern Sie nicht, Fragen in den Kommentaren zu stellen).
Die Hauptimplementierung des Agenten a_stage_point_t erstellt ein Abonnement für eine Nachricht vom Typ In. Wenn eine Nachricht dieses Typs eintrifft, wird der Stage-Handler aufgerufen. Wenn der Stage-Handler ein tatsächliches Ergebnis zurückgibt, wird das Ergebnis an die nächste Stufe gesendet (falls diese Stufe vorhanden ist).
Es gibt auch eine Version von a_stage_point_t für den Fall, dass die entsprechende Stufe die Endstufe ist und es nicht die nächste Stufe geben kann.
Die Implementierung von a_stage_point_t kann etwas kompliziert aussehen, aber glauben Sie mir, es ist einer der einfachsten Agenten, die ich geschrieben habe.
Funktion make_pipeline ()
Es ist Zeit, die letzte Pipeline-Funktion zu diskutieren, die make_pipeline() :
template< typename In, typename Out, typename... Args > mbox_t make_pipeline(
Hier gibt es weder Magie noch Überraschungen. Wir müssen nur einen neuen Coop für die zugrunde liegenden Agenten der Pipeline erstellen, diesen Coop mit Agenten füllen, indem wir einen Stage Builder der obersten Ebene aufrufen, und diesen Coop dann in SObjectizer registrieren. Das alles.
Das Ergebnis von make_pipeline() ist die mbox der am weitesten links stehenden (ersten) Stufe der Pipeline. Diese mbox sollte zum Senden von Nachrichten an die Pipeline verwendet werden.
Die Simulation und Experimente damit
Jetzt haben wir Datentypen und Funktionen für unsere Anwendungslogik und die Tools zum Verketten dieser Funktionen zu einer Datenverarbeitungspipeline. Lassen Sie es uns tun und ein Ergebnis sehen:
int main() {
Wenn wir dieses Beispiel ausführen, sehen wir die folgende Ausgabe:
archiving (0,0) distributing (0,0) archiving (0,5) distributing (0,5) archiving (0,10) distributing (0,10) archiving (0,15) distributing (0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,30) distributing (0,30) ... archiving (0,105) distributing (0,105) archiving (0,110) distributing (0,110) === alarm (0) === alarm_distribution (0) archiving (0,115) distributing (0,115) archiving (0,120) distributing (0,120) === alarm (0) === alarm_distribution (0)
Es funktioniert.
Aber es scheint, dass Phasen unserer Pipeline nacheinander ablaufen, nicht wahr?
Ja, das ist es. Dies liegt daran, dass alle Pipeline-Agenten an den Dispatcher des Standard-SObjectizers gebunden sind. Und dieser Dispatcher verwendet nur einen Arbeitsthread, um die Nachrichtenverarbeitung aller Agenten zu bedienen.
Dies kann jedoch leicht geändert werden. make_pipeline() einfach ein zusätzliches Argument an den make_pipeline() von make_pipeline() :
Dadurch wird ein neuer Thread-Pool erstellt und alle Pipeline-Agenten an diesen Pool gebunden. Jeder Agent wird vom Pool unabhängig von anderen Agenten bedient.
Wenn wir das modifizierte Beispiel ausführen, können wir so etwas sehen:
archiving (0,0) distributing (0,0) distributing (0,5) archiving (0,5) archiving (0,10) distributing (0,10) distributing (archiving (0,15) 0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,distributing (030) ,30) ... archiving (0,distributing (0,105) 105) archiving (0,alarm_distribution (0) distributing (0,=== alarm (0) === 110) 110) archiving (distributing (0,0,115) 115) archiving (distributing (=== alarm (0) === 0alarm_distribution (0) 0,120) ,120)
Wir können also sehen, dass verschiedene Phasen der Pipeline parallel arbeiten.
Aber ist es möglich, weiter zu gehen und Stufen an verschiedene Disponenten zu binden?
Ja, es ist möglich, aber wir müssen eine weitere Überladung für die Funktion stage() implementieren:
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( disp_binder_shptr_t disp_binder, Callable handler ) { stage_builder_t builder{ [binder = std::move(disp_binder), h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent_with_binder< a_stage_point_t<In, Out> >( std::move(binder), std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
This version of stage() accepts not only a stage handler but also a dispatcher binder. Dispatcher binder is a way to bind an agent to the particular dispatcher. So to assign a stage to a specific working context we can create an appropriate dispatcher and then pass the binder to that dispatcher to stage() function. Let's do that:
In that case stages archiving , distribution , alarm_initiator and alarm_distribution will work on own worker threads. All other stages will work on the same single worker thread.
The conclusion
This was an interesting experiment and I was surprised how easy SObjectizer could be used in something like reactive programming or data-flow programming.
However, I don't think that pipeline DSL can be practically meaningful. It's too simple and, maybe not flexible enough. But, I hope, it can be a base for more interesting experiments for those why need to deal with different workflows and data-processing pipelines. At least as a base for some ideas in that area. C++ language a rather good here and some (not so complicated) template magic can help to catch various errors at compile-time.
In conclusion, I want to say that we see SObjectizer not as a specialized tool for solving a particular problem, but as a basic set of tools to be used in solutions for different problems. And, more importantly, that basic set can be extended for your needs. Just take a look at SObjectizer , try it, and share your feedback. Maybe you missed something in SObjectizer? Perhaps you don't like something? Tell us , and we can try to help you.
If you want to help further development of SObjectizer, please share a reference to it or to this article somewhere you want (Reddit, HackerNews, LinkedIn, Facebook, Twitter, ...). The more attention and the more feedback, the more new features will be incorporated into SObjectizer.
And many thanks for reading this ;)
PS. The source code for that example can be found in that repository .