Jeder, der mit Redux arbeitet, wird früher oder später auf das Problem asynchroner Aktionen stoßen. Eine moderne Anwendung kann jedoch nicht ohne sie entwickelt werden. Dies sind http-Anfragen an das Backend und alle Arten von Timern / Verzögerungen. Die Redux-Ersteller selbst sprechen eindeutig - standardmäßig wird nur der synchrone Datenfluss unterstützt, alle asynchronen Aktionen müssen in der Middleware platziert werden.
Dies ist natürlich zu ausführlich und unpraktisch, sodass es schwierig ist, einen Entwickler zu finden, der nur die "native" Middleware verwendet. Bibliotheken und Frameworks wie Thunk, Saga und dergleichen helfen immer.
Für die meisten Aufgaben reichen sie aus. Was aber, wenn eine etwas komplexere Logik erforderlich ist, als eine Anfrage zu senden oder einen Timer zu erstellen? Hier ist ein kleines Beispiel:
async dispatch => { setTimeout(() => { try { await Promise .all([fetchOne, fetchTwo]) .then(([respOne, respTwo]) => { dispatch({ type: 'SUCCESS', respOne, respTwo }); }); } catch (error) { dispatch({ type: 'FAILED', error }); } }, 2000); }
Es ist schmerzhaft, sich solchen Code anzusehen, aber es ist einfach unmöglich, ihn zu pflegen und zu erweitern. Was tun, wenn eine komplexere Fehlerbehandlung erforderlich ist? Was ist, wenn Sie eine Wiederholungsanfrage benötigen? Und wenn ich diese Funktion wiederverwenden möchte?
Mein Name ist Dmitry Samokhvalov, und in diesem Beitrag werde ich Ihnen erklären, was das Konzept von Observable ist und wie es in Verbindung mit Redux in die Praxis umgesetzt werden kann, und all dies mit den Fähigkeiten von Redux-Saga vergleichen.
Nehmen Sie in solchen Fällen in der Regel die Redux-Saga. OK, wir schreiben die Sagen neu:
try { yield call(delay, 2000); const [respOne, respTwo] = yield [ call(fetchOne), call(fetchTwo) ]; yield put({ type: 'SUCCESS', respOne, respTwo }); } catch (error) { yield put({ type: 'FAILED', error }); }
Es ist spürbar besser geworden - der Code ist fast linear, sieht besser aus und liest sich besser. Das Erweitern und Wiederverwenden ist jedoch immer noch schwierig, da die Saga genauso wichtig ist wie der Thunk.
Es gibt einen anderen Ansatz. Dies ist genau der Ansatz und nicht nur eine andere Bibliothek zum Schreiben von asynchronem Code. Es heißt Rx (es handelt sich auch um Observables, Reactive Streams usw.). Wir werden es verwenden und das Beispiel auf Observable neu schreiben:
action$ .delay(2000) .switchMap(() => Observable.merge(fetchOne, fetchTwo) .map(([respOne, respTwo]) => ({ type: 'SUCCESS', respOne, respTwo })) .catch(error => ({ type: 'FAILED', error }))
Der Code wurde nicht nur flach und nahm an Volumen ab, auch das Prinzip der Beschreibung asynchroner Aktionen hat sich geändert. Jetzt arbeiten wir nicht direkt mit Abfragen, sondern führen Operationen an speziellen Objekten aus, die als Observable bezeichnet werden.
Es ist zweckmäßig, Observable als eine Funktion darzustellen, die einen Strom (eine Folge) von Werten ergibt. Observable hat drei Hauptzustände - next ("Geben Sie den nächsten Wert"), error ("ein Fehler ist aufgetreten") und complete ("die Werte sind vorbei, es gibt nichts mehr zu geben"). In dieser Hinsicht ist es ein bisschen wie Promise, unterscheidet sich jedoch darin, dass es möglich ist, über diese Werte zu iterieren (und dies ist eine der beobachtbaren Supermächte). Sie können alles in Observable einschließen - Timeouts, http-Anforderungen, DOM-Ereignisse, nur js-Objekte.
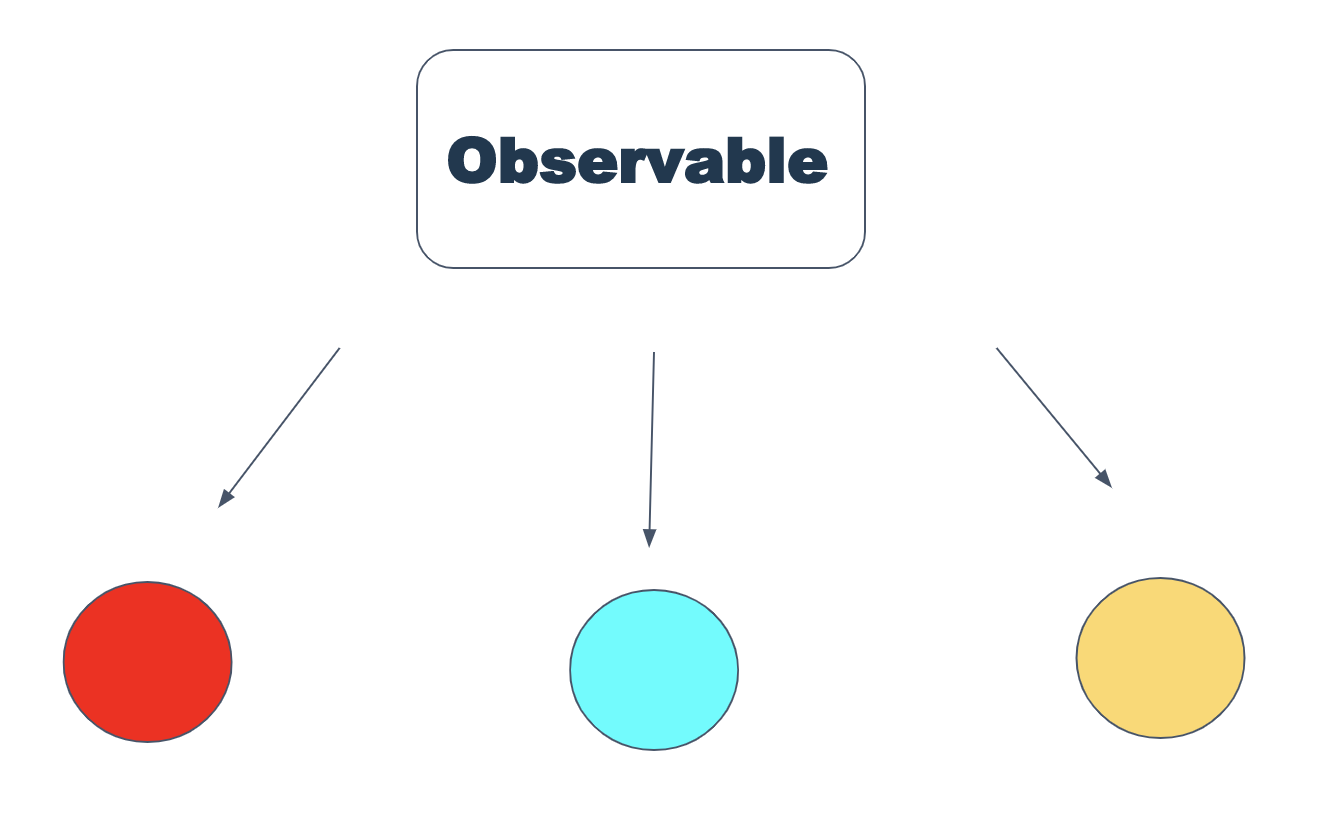
Die zweite beobachtbare Supermacht sind Betreiber. Ein Operator ist eine Funktion, die eine Observable akzeptiert und zurückgibt, jedoch eine Aktion für den Wertestrom ausführt. Die nächste Analogie ist Map und Filter aus Javascript (solche Operatoren sind übrigens in Rx).
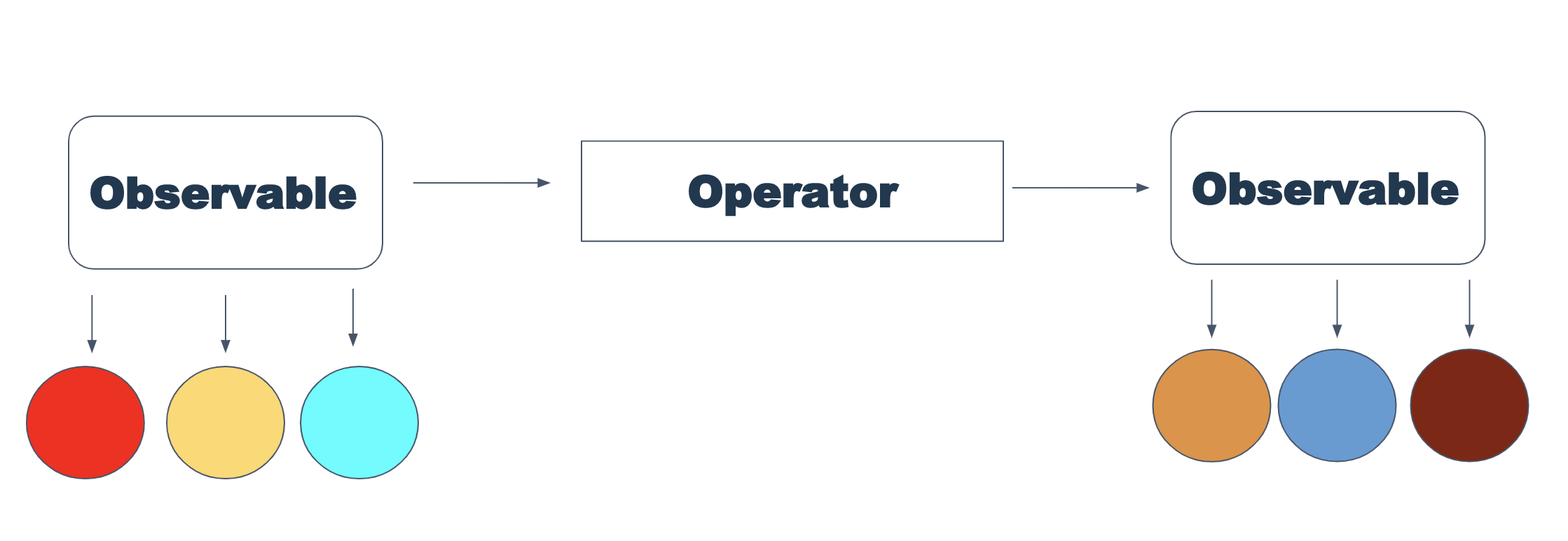
Am nützlichsten für mich persönlich waren die Operatoren zip, forkJoin und flatMap. Anhand ihres Beispiels ist es am einfachsten, die Arbeit der Bediener zu erklären.
Der Zip-Operator funktioniert sehr einfach - er benötigt einige Observable (nicht mehr als 9) und gibt in einem Array die von ihnen ausgegebenen Werte zurück.
const first = fromEvent("mousedown"); const second = fromEvent("mouseup"); zip(first, second) .subscribe(e => console.log(`${e[0].x} ${e[1].x}`));
Im Allgemeinen kann die Arbeit von zip durch das Schema dargestellt werden:
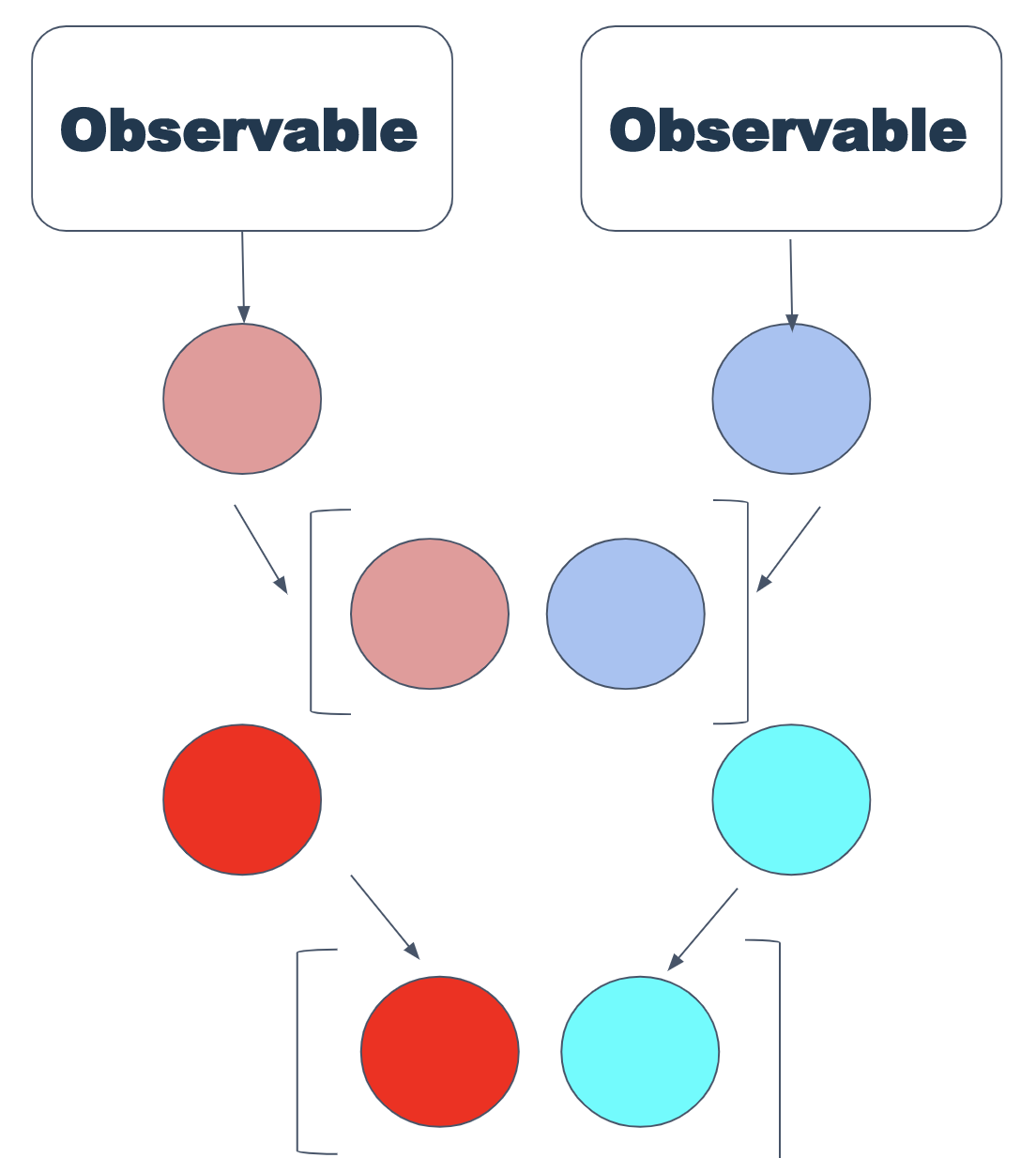
Zip wird verwendet, wenn Sie mehrere Observable haben und konsistent Werte von ihnen empfangen müssen (trotz der Tatsache, dass sie in unterschiedlichen Intervallen synchron oder nicht synchron ausgegeben werden können). Dies ist sehr nützlich, wenn Sie mit DOM-Ereignissen arbeiten.
Die forkJoin-Anweisung ähnelt zip mit einer Ausnahme: Sie gibt nur die neuesten Werte von jedem Observable zurück.
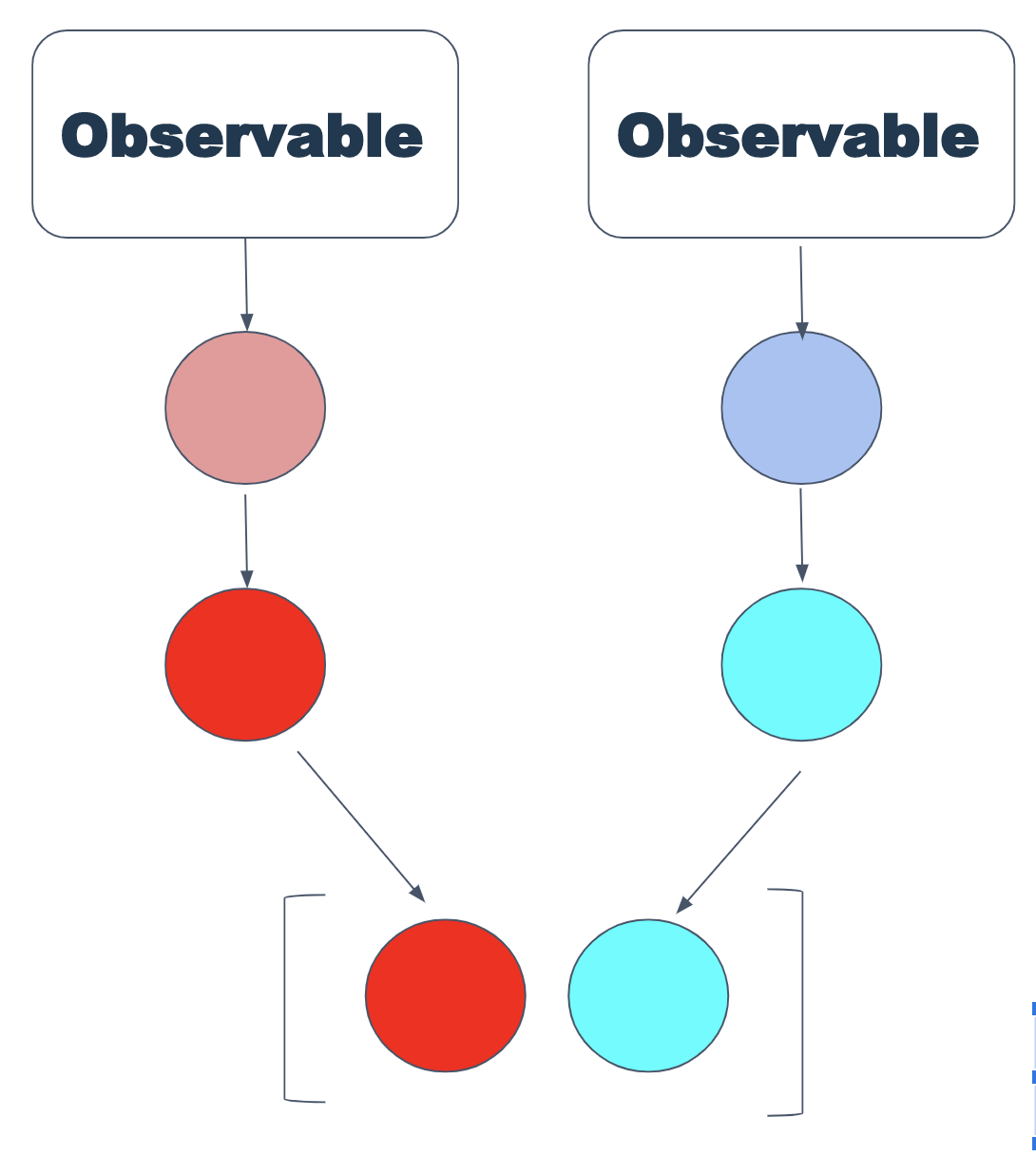
Dementsprechend ist es sinnvoll, es zu verwenden, wenn nur endliche Werte aus dem Stream benötigt werden.
Etwas komplizierter ist der flatMap-Operator. Es nimmt ein Observable als Eingabe und gibt ein neues Observable zurück und ordnet die Werte daraus dem neuen Observable zu, wobei entweder eine Auswahlfunktion oder ein anderes Observable verwendet wird. Es klingt verwirrend, aber das Diagramm ist ziemlich einfach:
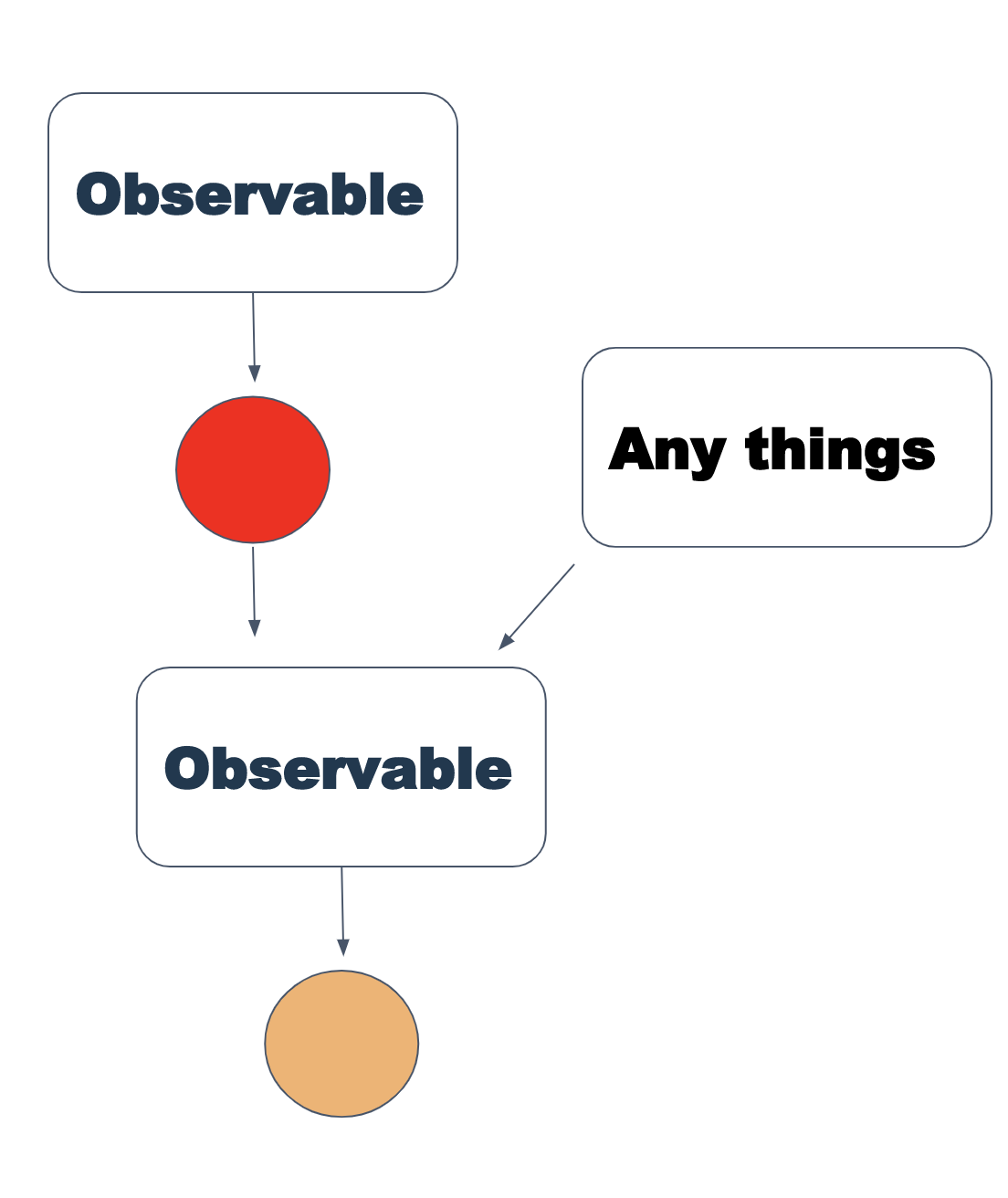
Noch klarer im Code:
const observable = of("Hello"); const promise = value => new Promise(resolve => resolve(`${value} World`); observable .flatMap(value => promise(value)) .subscribe(result => console.log(result));
In den meisten Fällen wird flatMap zusammen mit switchMap und concatMap in Backend-Anforderungen verwendet.
Wie kann ich Rx in Redux verwenden? Dafür gibt es eine wunderbare Redux-beobachtbare Bibliothek. Die Architektur sieht folgendermaßen aus:

Alle Observable-Operatoren und Aktionen auf ihnen werden in Form einer speziellen Middleware namens Epic ausgeführt. Jedes Epos nimmt eine Aktion als Eingabe, verpackt sie in ein Observable und sollte eine Aktion zurückgeben, auch als Observable. Sie können keine reguläre Aktion zurückgeben, dies erzeugt eine Endlosschleife. Lassen Sie uns ein kleines Epos schreiben, das eine Anfrage an api stellt.
const fetchEpic = action$ => action$ .ofType('FETCH_INFO') .map(() => ({ type: 'FETCH_START' })) .flatMap(() => Observable .from(apiRequest) .map(data => ({ type: 'FETCH_SUCCESS', data })) .catch(error => ({ type: 'FETCH_ERROR', error })) )
Es ist unmöglich, auf den Vergleich von Redux-Observable und Redux-Saga zu verzichten. Vielen scheint es, dass sie in Funktionalität und Fähigkeiten nahe beieinander liegen, aber dies ist überhaupt nicht der Fall. Sagas sind ein absolut zwingendes Werkzeug, im Wesentlichen eine Reihe von Methoden zum Arbeiten mit Nebenwirkungen. Observable ist eine grundlegend andere Art, asynchronen Code zu schreiben, wenn Sie möchten, eine andere Philosophie.
Ich habe mehrere Beispiele geschrieben, um die Möglichkeiten und den Ansatz zur Lösung von Problemen zu veranschaulichen.
Angenommen, wir müssen einen Timer implementieren, der durch Aktion stoppt. So sieht es in den Sagen aus:
while(true) { const timer = yield race({ stopped: take('STOP'), tick: call(wait, 1000) }) if (!timer.stopped) { yield put(actions.tick()) } else { break } }
Verwenden Sie jetzt Rx:
interval(1000) .takeUntil(action$.ofType('STOP'))
Angenommen, es gibt eine Aufgabe zum Implementieren einer Anforderung mit Stornierung in Sagen:
function* fetchSaga() { yield call(fetchUser); } while (yield take('FETCH')) { const fetchSaga = yield fork(fetchSaga); yield take('FETCH_CANCEL'); yield cancel(fetchSaga); }
Bei Rx ist alles einfacher:
switchMap(() => fetchUser()) .takeUntil(action$.ofType('FETCH_CANCEL'))
Endlich mein Favorit. Implementieren Sie eine API-Anfrage. Stellen Sie im Fehlerfall nicht mehr als 5 wiederholte Anfragen mit einer Verzögerung von 2 Sekunden. Folgendes haben wir in den Sagen:
for (let i = 0; i < 5; i++) { try { const apiResponse = yield call(apiRequest); return apiResponse; } catch (err) { if(i < 4) { yield delay(2000); } } } throw new Error(); }
Was passiert auf Rx:
.retryWhen(errors => errors .delay(1000) .take(5))
Wenn Sie die Vor- und Nachteile der Saga zusammenfassen, erhalten Sie das folgende Bild:

Sagas sind leicht zu erlernen und sehr beliebt, sodass Sie in der Community Rezepte für fast alle Gelegenheiten finden können. Leider verhindert der imperative Stil die Verwendung der Sagen wirklich flexibel.
Rx hat eine ganz andere Situation:

Es scheint, dass Rx ein magischer Hammer und eine Silberkugel ist. Dies ist leider nicht so. Der Schwellenwert für die Eingabe von Rx ist viel höher, daher ist es schwieriger, eine neue Person in ein Projekt einzuführen, das Rx aktiv nutzt.
Darüber hinaus ist es bei der Arbeit mit Observable besonders wichtig, vorsichtig zu sein und immer gut zu verstehen, was passiert. Andernfalls können Sie auf nicht offensichtliche Fehler oder undefiniertes Verhalten stoßen.
action$ .ofType('DELETE') .switchMap(() => Observable .fromPromise(deleteRequest) .map(() => ({ type: 'DELETE_SUCCESS'})))
Nachdem ich ein Epos geschrieben hatte, das einen ziemlich einfachen Job machte - mit jeder Aktion vom Typ 'DELETE' wurde eine API-Methode aufgerufen, die das Element entfernte. Beim Testen traten jedoch Probleme auf. Der Tester beschwerte sich über seltsames Verhalten - manchmal passierte nichts, wenn Sie auf die Schaltfläche Löschen klickten. Es stellte sich heraus, dass der switchMap-Operator die Ausführung von jeweils nur einem Observable unterstützt, eine Art Schutz gegen Race-Bedingungen.
Infolgedessen gebe ich einige Empfehlungen, denen ich folge, und fordere alle, die mit Rx arbeiten, auf, zu folgen:
- Seien Sie aufmerksam.
- Überprüfen Sie die Dokumentation.
- Checken Sie den Sandkasten ein.
- Schreiben Sie Tests.
- Schieße keine Spatzen aus der Kanone.