In der bibliografischen Datenbank des Web of Science hat der Leitfaden
„R: eine Sprache und Umgebung für statistische Berechnungen“ kürzlich * andere Quellen umgangen, die im Abschnitt „Referenzen“ der von dieser Datenbank indizierten Veröffentlichungen erwähnt wurden. Leider ist der Zugriff darauf begrenzt und es ist schwierig, einen Link anzugeben (für jede Sitzung wird ein Link generiert), aber eine Reihe von Benutzern ** können meine Beobachtungen reproduzieren. Unter dem Schnitt wird beschrieben, wie und mit welchen Vorbehalten es sich lohnt, die Überschrift der Nachrichten zu verstehen.

Die Abbildung zeigt eine Liste der am häufigsten zitierten Quellen in von WoS indizierten Veröffentlichungen, die selbst nicht von WoS in der Hauptsammlung (Core Collection) indiziert werden, sondern nur in der Datenbank mit bibliografischen Referenzen.
Abgesehen von der Tatsache, dass drei indexierte Veröffentlichungen (alle in der Biologie) dem R-Handbuch noch voraus sind, ist dies in vielerlei Hinsicht eine eher begrenzte Aufzeichnung mit einer Reihe von Annahmen. Erstens betrifft es nur WoS. In der Scopus-Datenbank, die häufig zusammen mit WoS erwähnt wird, überholt die Nomenklatur „Diagnostisches und statistisches Handbuch für psychische Störungen“ immer noch (gemessen an der Wachstumsrate, nicht lange) das Handbuch zu R. Zweitens: Natürlich ist mir bewusst, dass dies ein absoluter Rekord ist, ohne Normalisierung nach Wissensgebiet, Erscheinungsjahr usw. Drittens verwende ich wahrscheinlich nicht die ehrlichste Berechnung, nämlich ich fasse Zitate aller Versionen des Handbuchs (sowie andere solche bibliografischen Verweise - alle Versionen von DSM, alle Bände von numerischen Rezepten usw.) zusammen, während in der üblichen Berechnung ohne Von jeder Zusammenfassung befindet sich das Handbuch nur an 40. Stelle (im Folgenden in 51, 61 usw.). Die Stelle befindet sich ebenfalls dort, ist jedoch auf ein anderes Jahr datiert, auf eine andere Version des Handbuchs, den Artikel a vor dem Doppelpunkt in Großbuchstaben usw. .).
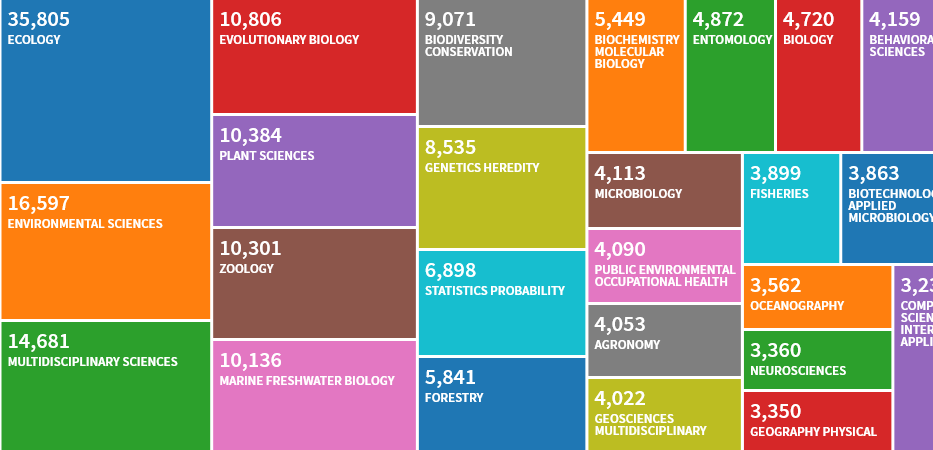 TOP 25 WoS-Kategorien im Handbuch zitiert. Ähnlich ist die Situation bei Scopus.
TOP 25 WoS-Kategorien im Handbuch zitiert. Ähnlich ist die Situation bei Scopus.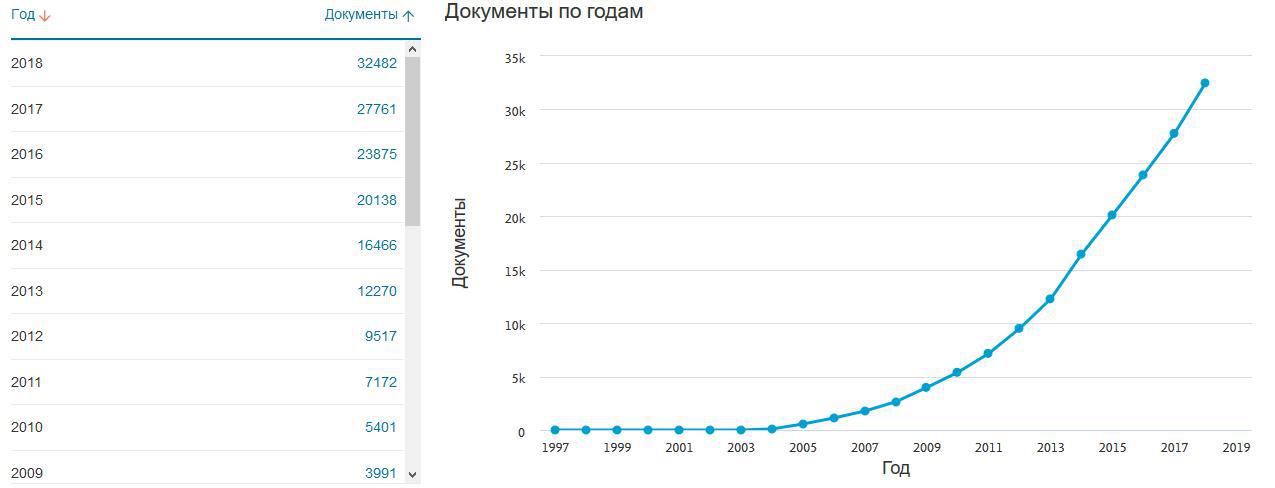 Eine Erhöhung der Anzahl der Zitate des Handbuchs in Scopus mit ähnlichen Werten für WoS.
Eine Erhöhung der Anzahl der Zitate des Handbuchs in Scopus mit ähnlichen Werten für WoS.Es ist auch zu bedenken, dass die Autoren einer wissenschaftlichen Publikation nicht in jedem Fall definitiv ein Werkzeug verwenden (im weiteren Sinne, ob Hardware oder Software oder ein Theorem oder ein logisches Argument usw.) ein Link dazu, also das Thema einer separaten Studie, wie sehr eine so häufige Erwähnung des Handbuchs seine häufige Verwendung beim Schreiben wissenschaftlicher Arbeiten widerspiegelt (es ist bekannt, dass R in der Wissenschaft populär ist, die Frage ist anders, je nach den Zahlen gibt es vielleicht eine andere nicht-akademische Quelle, de tatsächlich verwendet oft, aber nicht im Literaturverzeichnis erwähnt).
Laut
dieser Überprüfung wird SPSS beispielsweise de facto beim Durchsuchen der Google Scholar-Datenbank und gemäß den Daten für 2018 eineinhalb Mal häufiger zum Schreiben akademischer Arbeiten verwendet. Der Autor erklärt dies durch die Komplexität der Beherrschung von R. Ich möchte jedoch eine vergleichende Analyse auf verschiedenen Grundlagen, da die Auswahl der indexierten Veröffentlichungen und dementsprechend die Zitierindikatoren unterschiedlich sind.
Warum ist R für Wissenschaftler so wichtig? Andy Wills
schreibt im Linux Journal über R im Lichte der Idee von Open Science und im Zusammenhang mit der Relevanz der Krise der Reproduzierbarkeit in der Psychologie. Der Psychologe und Datenwissenschaftler
Evgeny Tomilov , an den ich mich wandte, begründete die Bedeutung von R für die Wissenschaft in der Antwort:
Mit R können Sie reproduzierbare Forschungsprotokolle erstellen, einschließlich Daten und deren Verarbeitung. Unter Bedingungen vollständiger Fälschungen und der dringenden Notwendigkeit, die Reproduzierbarkeit und Glaubwürdigkeit wissenschaftlicher Arbeiten zu erhöhen, ist die Verwendung dieses Tools zumindest nützlich und zumindest ethisch.
Z.Y. Interessant ist auch, dass es in Google Scholar
ein R-Core-Team-Profil gibt , das den Profilen einzelner Forscher ähnelt, mit einem guten Hirsch-Index von 50 (dafür müssen mehr als 50 Veröffentlichungen vorhanden sein, während die Veröffentlichung von 50 in einer Reihe, wenn sie nach der Anzahl der Zitate geordnet wird, eine Nummer haben sollte Zitate gleich 50).
* Aufgrund der Besonderheiten bei der Berechnung und Detaillierung der Daten ist es schwierig, ein genaues Datum anzugeben. Dies ist höchstwahrscheinlich in den letzten Monaten geschehen.
** nämlich die Eigentümer des Bibliotheksausweises der Russischen Nationalbibliothek RSL und des Gorki-Bibliotheks- und Studentenausweises der St. Petersburg State University sowie mehrerer anderer Universitäten.
So reproduzieren Sie KDPV:
Im Abschnitt "Suche nach Referenzbibliographie" können Sie die Abfrage 1000-2999 in die Suche nach Jahr eingeben und eine Stichprobe von 264 Millionen Ergebnissen aus 268 erhalten (die übrigen haben wahrscheinlich nicht das Jahr angegeben, aber es ist unwahrscheinlich, dass sie für nachfolgende Manipulationen wesentlich sind). . Rang nach Anzahl der Zitate. Exportieren Sie als Nächstes die Ergebnisse und filtern Sie diejenigen heraus, die eine Quellenspalte, aber keine Titelspalte haben (im Fall eines Zeitschriftenartikels wird im ersten Fall der Name der Zeitschrift und im zweiten Fall der Titel der Veröffentlichung und dann der Inhalt angegeben Beide Spalten sind gleich, und nur bei nicht indizierten Quellen ist die Spalte "Überschrift" leer. Sie können manuell oder über ein Skript die Ergebnisse der Zusammenfassung von Zitaten für jeden einzelnen Datensatz abrufen (dh Daten zu exportierten bibliografischen Referenzen kombinieren, die in unterschiedlichen Schreibweisen zitiert sind und unterschiedliche Ausgaben, einzelne Seiten usw. angeben).