Wenn Ihre Veröffentlichungen blitzschnell, automatisiert und zuverlässig sind, können Sie diesen Artikel möglicherweise nicht lesen.
Zuvor war unser Release-Prozess manuell, langsam und fehlerhaft.
Wir haben den Sprint nach dem Sprint nicht bestanden, weil wir keine Zeit hatten, die Funktionen für den nächsten Sprint-Test zu erstellen und auszulegen. Wir haben unsere Veröffentlichungen gehasst. Oft dauerten sie drei bis vier Tage.
In diesem Artikel beschreiben wir die Stop the Line-Praxis, mit deren Hilfe wir uns auf die Behebung von Layoutproblemen konzentrieren konnten. In nur drei Monaten konnten wir die Bereitstellungsrate um das Zehnfache erhöhen. Heute ist unsere Bereitstellung vollständig automatisiert und die Freigabe des Monolithen dauert nur 4 bis 5 Stunden.
Stoppen Sie die Linie. Vom Team erfundene Praxis
Ich erinnere mich, wie wir auf Stop the Line gekommen sind. In einer allgemeinen Retrospektive diskutierten wir lange Veröffentlichungen, die uns daran hinderten, Sprintziele zu erreichen. Einer unserer Entwickler schlug vor:
- [Sergey] Begrenzen wir das Release-Volumen. Dies hilft uns, Fehler zu testen, zu beheben und schneller bereitzustellen.
- [Dima] Können wir eine Beschränkung der laufenden Arbeiten einführen (WIP-Grenze)? Sobald wir beispielsweise 10 Aufgaben erledigt haben, stoppen wir die Entwicklung.
- [Entwickler] Die Aufgaben können jedoch unterschiedlich groß sein. Dies wird das Problem großer Releases nicht lösen.
- [I] Lassen Sie uns eine Einschränkung einführen, die auf der Dauer der Veröffentlichung und nicht auf der Anzahl der Aufgaben basiert. Wir werden die Entwicklung einstellen, wenn die Veröffentlichung zu lange dauert.
Wir haben beschlossen, dass wir, wenn die Veröffentlichung länger als 48 Stunden dauert, das blinkende Licht einschalten und die Arbeit aller Teams an den Geschäftsmerkmalen des Monolithen einstellen. Alle Teams, die an dem Monolithen arbeiten, sollten die Entwicklung einstellen und sich darauf konzentrieren, die aktuelle Version im Verkauf voranzutreiben oder die Gründe zu beseitigen, die die Verzögerung der Veröffentlichung verursacht haben. Wenn die Veröffentlichung nicht funktioniert, macht es keinen Sinn, neue Funktionen zu erstellen, da diese noch in Kürze verfügbar sein werden. Derzeit ist es verboten, neuen Code zu schreiben, auch in separaten Zweigen.
Wir haben auch "Stop the Line Board" auf einem einfachen Flipchart eingeführt. Darauf schreiben wir Aufgaben, die entweder dazu beitragen, die aktuelle Version voranzutreiben oder die Gründe für ihre Verzögerung zu vermeiden.
Natürlich ist Stop The Line keine einfache Entscheidung, aber diese Vorgehensweise ist ein wichtiger Schritt in Richtung kontinuierlicher Lieferung und echter DevOps.
Geschichte von Dodo IS (Technische Präambel)Dodo IS wurde hauptsächlich auf dem .NET-Framework mit einer Benutzeroberfläche für React / Redux geschrieben, auf jQuery platziert und mit Angular durchsetzt. Es gibt immer noch Apps für iOS und Android auf Swift und Kotlin.
Die Dodo IS-Architektur ist eine Mischung aus einem vererbten Monolithen und etwa 20 Mikrodiensten. Wir entwickeln neue Geschäftsfunktionen in separaten Microservices, die entweder bei jedem Commit (kontinuierliche Bereitstellung) oder auf Anfrage, wenn das Unternehmen dies benötigt, mindestens alle fünf Minuten (kontinuierliche Bereitstellung) bereitgestellt werden.
Wir haben jedoch immer noch einen großen Teil unserer Geschäftslogik in einer monolithischen Architektur implementiert. Der Monolith ist am schwierigsten einzusetzen. Es braucht Zeit, um das gesamte System zusammenzubauen (das Build-Artefakt wiegt etwa 1 GB), Unit- und Integrationstests durchzuführen und vor jeder Version eine manuelle Regression durchzuführen. Die Veröffentlichung selbst ist ebenfalls langsam. Jedes Land hat seine eigene Kopie des Monolithen, daher müssen wir 12 Kopien für 12 Länder bereitstellen.
Continuous Integration (CI) ist eine Methode, mit der Entwickler den Code ständig funktionsfähig halten, das Produkt in kleinen Schritten erweitern und mindestens täglich mit Unterstützung des CI-Builds mit vielen Autotests in einen Zweig integrieren können.
Wenn mehrere Teams an demselben Produkt arbeiten und CI üben, wächst die Anzahl der Änderungen in der allgemeinen Branche schnell. Je mehr Änderungen Sie sammeln, desto mehr enthält diese Änderung versteckte Fehler und potenzielle Probleme. Aus diesem Grund bevorzugen Teams die häufige Bereitstellung von Änderungen, was dazu führt, dass Continuous Delivery (CD) der nächste logische Schritt nach CI ist.
Mit der CD-Übung können Sie jederzeit Code in prod bereitstellen. Diese Vorgehensweise basiert auf einer Bereitstellungspipeline - einer Reihe von automatischen oder manuellen Schritten, mit denen das Inkrement eines Produkts auf dem Weg zu einem Produkt überprüft wird.
Unsere Bereitstellungspipeline sieht folgendermaßen aus:
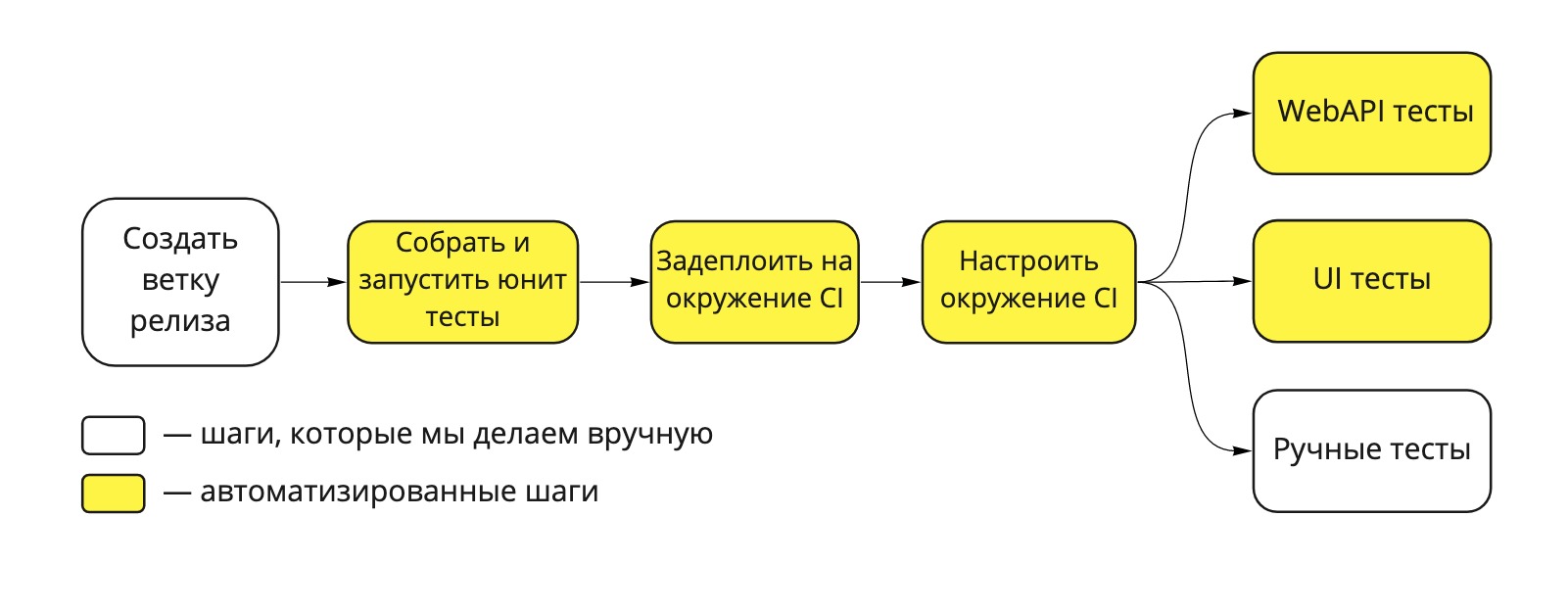
Abb. 1. Dodo IS-Bereitstellungspipeline
Lassen Sie uns schnell loslassen: vom Problem zum angepassten Stop the Line-Training
Der Schmerz langsamer Freisetzungen. Warum sind sie so lang? Analyse
Extreme Programming (XP) hat eine goldene Regel: Wenn etwas weh tut, tun Sie es so oft wie möglich. Unsere Veröffentlichungen waren schon immer ein Schmerz. Wir haben mehrere Tage damit verbracht, die Testumgebung bereitzustellen, die Datenbank wiederherzustellen, die Tests auszuführen (normalerweise mehrmals), herauszufinden, warum sie gefallen sind, Fehler zu beheben und schließlich freizugeben.
Der Sprint dauert 2 Wochen und die Veröffentlichung dauert drei Tage. Um es vor Sprint Review am Freitag veröffentlichen zu können, sollten Sie die Veröffentlichung am Montag auf gute Weise starten. Das heißt, wir arbeiten an dem Ziel, nur 50% der Zeit zu sprinten. Und wenn wir jeden Tag veröffentlichen könnten, würde die produktive Arbeitszeit auf 80-90% steigen.
Unsere durchschnittliche Veröffentlichung dauerte normalerweise zwei bis drei Tage. Zunächst arbeiteten sechs Teams in der allgemeinen Entwicklungsabteilung am Code (und mit dem Wachstum des Unternehmens stieg die Anzahl der Teams auf neun). Kurz vor der Veröffentlichung haben wir den Release-Zweig gebrunst. Während dieser Zweig getestet und zurückgebildet wird, entwickeln sich die Teams im allgemeinen Entwicklungszweig weiter. Bevor der Release-Zweig den Verkauf erreicht, werden die Teams ziemlich viel Code schreiben.
Je mehr Änderungen am Inkrement vorgenommen werden, desto wahrscheinlicher ist es, dass sich die von verschiedenen Teams vorgenommenen Änderungen gegenseitig beeinflussen. Dies bedeutet, dass das Inkrement genauer getestet werden muss und desto länger dauert es, es freizugeben. Dies ist ein sich selbst verstärkender Zyklus (siehe Abb. 2). Je mehr Änderungen in der Version ("Pferd" -Freigabe) vorgenommen werden, desto länger ist die Regressionszeit. Je länger die Regressionszeit ist, desto mehr Zeit zwischen den Veröffentlichungen und desto mehr Änderungen nimmt das Team vor der nächsten Veröffentlichung vor. Wir nannten es "Pferde gebären Pferde". Das folgende CLD-Diagramm (Kausalschleifendiagramm) veranschaulicht diese Beziehung:
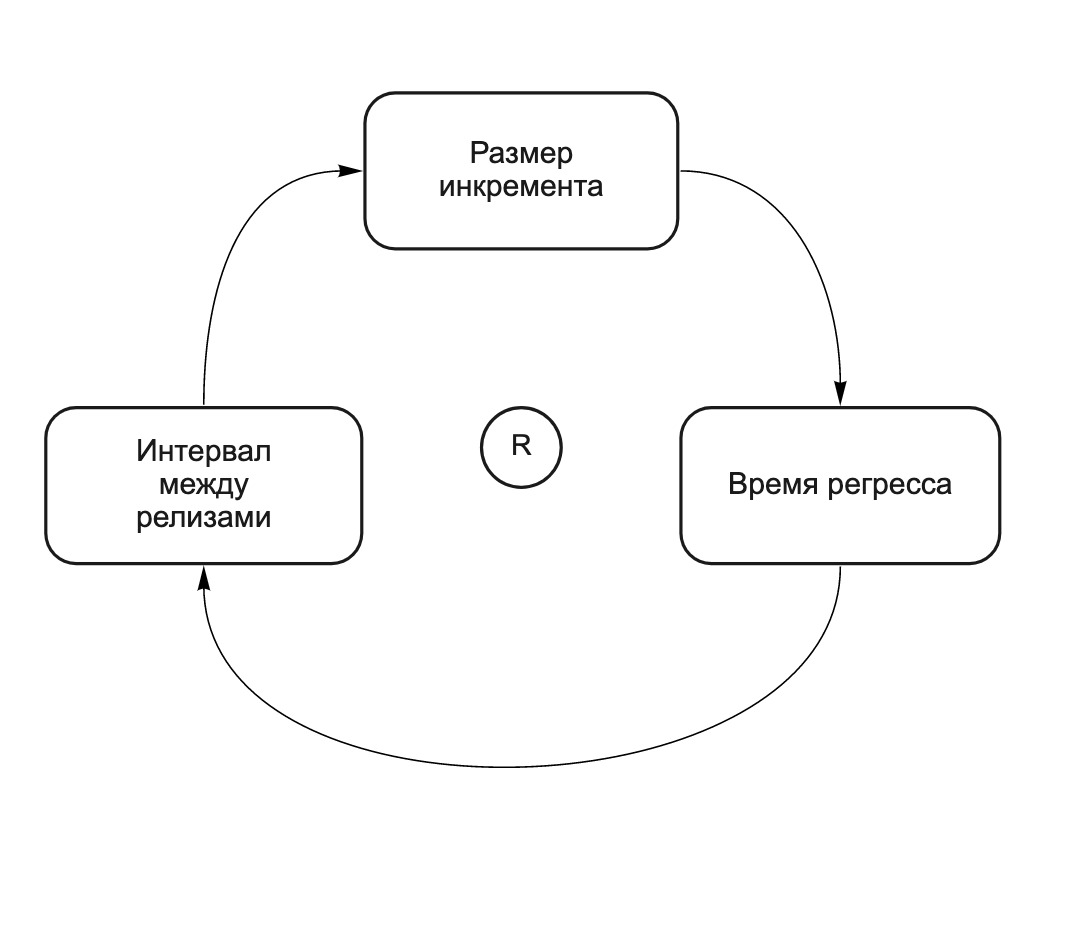
Abb. 2. CLD-Diagramm: Lange Releases führen zu noch längeren Releases
Regressionsautomatisierung mit QS-Befehl
Die Schritte, aus denen eine Veröffentlichung besteht- Umgebungseinstellung. Wir stellen die Verkaufsbasis (675 GB) wieder her, verschlüsseln persönliche Daten und bereinigen die RabbitMQ-Warteschlangen. Die Datenverschlüsselung ist sehr zeitaufwändig und dauert etwa 1 Stunde.
- Führen Sie automatische Tests durch. Einige UI-Tests sind instabil, daher müssen wir sie mehrmals ausführen, bis sie bestanden sind. Das Reparieren von Blinktests erfordert viel Aufmerksamkeit und Disziplin.
- Manuelle Abnahmetests. Einige Teams ziehen es vor, die endgültige Annahme vorzunehmen, bevor der Code an den Hersteller geht. Dies kann mehrere Stunden dauern. Wenn sie Fehler finden, geben wir den Teams zwei Stunden Zeit, um sie zu beheben. Andernfalls müssen sie ihre Änderungen zurücksetzen.
- Auf Produkt bereitstellen. Da wir für jedes Land separate Kopien von Dodo IS haben, dauert der Bereitstellungsprozess einige Zeit. Nachdem die Bereitstellung im ersten Land abgeschlossen ist, überprüfen wir die Protokolle einige Zeit, suchen nach Fehlern und setzen die Bereitstellung in anderen Ländern fort. Der gesamte Vorgang dauert normalerweise etwa zwei Stunden, manchmal kann er jedoch auch länger dauern, insbesondere wenn Sie die Version zurücksetzen müssen.
Zuerst haben wir beschlossen, manuelle Regressionstests loszuwerden, aber der Weg dorthin war lang und schwierig. Vor zwei Jahren dauerte die manuelle Regression von Dodo IS eine ganze Woche. Dann hatten wir ein ganzes Team von manuellen Testern, die Woche für Woche die gleichen Funktionen in 10 Ländern testeten. Sie werden solche Arbeit nicht beneiden.
Im Juni 2017 haben wir das QA-Team gebildet. Das Hauptziel des Teams war es, die Regression der wichtigsten Geschäftsabläufe zu automatisieren: Auftragseingang und Herstellung von Produkten. Sobald wir genug Tests hatten, um uns zu vertrauen, haben wir die manuellen Tests vollständig aufgegeben. Dies geschah jedoch erst 1,5 Jahre nach Beginn der Regressionsautomatisierung. Danach haben wir das QA-Team aufgelöst und das QA-Team hat sich den Entwicklungsteams angeschlossen.
UI-Tests weisen jedoch erhebliche Nachteile auf. Da sie von den tatsächlichen Daten in der Datenbank abhängen, müssen diese Daten konfiguriert werden. Ein Test kann Daten für einen anderen Test beschädigen. Der Test kann nicht nur fehlschlagen, weil eine Logik fehlerhaft ist, sondern auch aufgrund eines langsamen Netzwerks oder veralteter Daten im Cache. Wir mussten uns viel Mühe geben, um blinkende Tests loszuwerden und sie zuverlässig und reproduzierbar zu machen.
Ein Schritt, um die Leitung zu stoppen. #IReleaseEveryDay Initiative
Wir haben eine gleichgesinnte Community #IReleaseEveryDay erstellt und uns Gedanken darüber gemacht, wie die Bereitstellungspipeline beschleunigt werden kann. Die ersten Aktionen waren wie folgt:
- Wir haben die Anzahl der UI-Tests erheblich reduziert, indem wir wiederholte und unnötige Tests verworfen haben. Dies reduzierte die Testzeit um einige zehn Minuten;
- Aufgrund der vorläufigen Wiederherstellung der Datenbank und der Datenverschlüsselung haben wir die Zeit zum Einrichten der Umgebung erheblich verkürzt. Zum Beispiel erstellen wir jetzt nachts eine Sicherungskopie der Datenbank und sobald die Veröffentlichung beginnt, wechseln wir die Testumgebung in wenigen Sekunden zur Sicherungsdatenbank.
Dank der oben genannten Lösungen konnten wir die durchschnittliche Veröffentlichungszeit reduzieren, sie war jedoch immer noch ärgerlich lang. Es ist Zeit für Systemänderungen.
Was ist, wenn ...
Wir haben die Regel eingeführt, dass wir, wenn die Veröffentlichung länger als 48 Stunden dauert, das blinkende Licht einschalten und die Arbeit aller Teams an den Geschäftsfunktionen des Monolithen stoppen. Alle Teams, die an dem Monolithen arbeiten, sollten die Entwicklung einstellen und sich darauf konzentrieren, die aktuelle Version auf den Verkauf zu übertragen oder die Gründe zu beseitigen, die die Veröffentlichung verzögert haben.
Wenn die Veröffentlichung nicht funktioniert, macht es keinen Sinn, neue Funktionen zu erstellen, da diese noch in Kürze verfügbar sein werden. Derzeit ist es verboten, neuen Code zu schreiben, auch in separaten Zweigen. Dieses Prinzip wird in Martin Fowlers Artikel "Continuous Delivery" beschrieben: "Bei Problemen mit dem Layout sollte Ihr Team der Lösung dieser Probleme Vorrang vor der Arbeit an neuen Funktionen einräumen."
Entourage Blinker
Während Stop the Line schaltet sich im Büro ein orangefarbener Blinker ein. Jeder, der in den dritten Stock kommt, wo die Entwickler von Dodo IS arbeiten, sieht dieses visuelle Signal. Wir beschlossen, unsere Entwickler nicht mit dem Klang einer Sirene verrückt zu machen und ließen nur ein nerviges blinkendes Licht zurück. So konzipiert. Wie können wir uns wohl fühlen, wenn eine Veröffentlichung in Schwierigkeiten ist?

Abb. 3. Blinker Stoppt die Leitung
Teamwiderstand und kleine Sabotage
Anfangs mochte Stop the Line alle Teams, weil es Spaß gemacht hat. Alle waren als Kinder glücklich und legten Fotos unserer Notlichter aus. Aber wenn es 3-4 Tage hintereinander brennt, wird es nicht lustig. Eines Tages verstieß eines der Teams gegen die Regeln und lud den Code während Stop the Line in den Entwicklungszweig hoch, um sein Sprintziel zu speichern. Es ist am einfachsten, eine Regel zu brechen, wenn Sie dadurch nicht mehr arbeiten können. Dies ist eine schnelle und schmutzige Methode, um eine Geschäftsfunktion auszuführen und ein Systemproblem zu ignorieren.
Als Scrum Master konnte ich Verstöße gegen die Regeln nicht ertragen, daher habe ich dieses Problem in einer allgemeinen Retrospektive angesprochen. Wir hatten ein schwieriges Gespräch. Die meisten Teams waren sich einig, dass die Regeln für alle gelten. Wir waren uns einig, dass jedes Team die Regeln einhalten muss, auch wenn es nicht mit ihnen übereinstimmt. Und gleichzeitig darüber, wie Sie die Regeln ändern können, ohne auf die nächste Retrospektive zu warten.
Was hat nicht wie vorgesehen geklappt?
Anfangs konzentrierten sich die Entwickler nicht auf die Lösung von Systemproblemen mit Deployment Pipelint. Wenn die Freigabe stecken blieb, zogen sie es vor, Microservices zu entwickeln, die nicht der Stop the Line-Regel unterliegen, anstatt die Ursachen für die Verzögerung zu beseitigen. Microservices sind gut, aber die Probleme des Monolithen werden sich nicht von selbst lösen. Um diese Probleme zu lösen, haben wir den Stop The Line-Rückstand eingeführt.
Einige Lösungen waren schnelle Lösungen, die Probleme versteckten, anstatt sie zu lösen. Zum Beispiel wurden viele Tests repariert, indem Timeouts erhöht oder Retrays hinzugefügt wurden. Einer dieser Tests dauerte 21 Minuten. Der Test suchte nach dem zuletzt erstellten Mitarbeiter in einer Tabelle ohne Index. Anstatt die Logik der Anforderung zu korrigieren, fügte der Programmierer 3 Wiederholungsversuche hinzu. Infolgedessen wurde der langsame Test noch langsamer. Als Stop The Line ein Besitzerteam vorstellte, das sich auf Testprobleme konzentrierte, gelang es ihnen in den nächsten drei Sprints, unsere Tests 2-3 Mal zu beschleunigen.
Wie hat sich das Verhalten der Teams nach dem Üben von Stop the Line verhalten?
Bisher hatte nur ein Team Probleme mit einer Version - eine, die die Version unterstützte. Die Teams versuchten, diese unangenehme Pflicht so schnell wie möglich loszuwerden, anstatt in langfristige Verbesserungen zu investieren. Wenn die Tests in der Testumgebung beispielsweise gesunken sind, können sie lokal neu gestartet werden. Wenn die Tests erfolgreich sind, setzen Sie die Freigabe fort. Mit der Einführung von Stop The Line haben die Teams nun Zeit, die Tests zu stabilisieren. Wir haben den Testvorbereitungscode neu geschrieben, einige UI-Tests durch API-Tests ersetzt und unnötige Zeitüberschreitungen beseitigt. Jetzt bestehen fast alle Tests schnell und in jeder Umgebung.
Bisher haben sich Teams nicht systematisch mit technischen Schulden befasst. Wir haben jetzt einen Rückstand an technischen Verbesserungen, die wir während Stop the Line analysieren. Zum Beispiel haben wir Tests auf .Net Core neu geschrieben, sodass wir sie in Docker ausführen konnten. Durch Ausführen von Tests in Docker konnten wir das Selenium Grid verwenden, um Tests zu parallelisieren und ihre Ausführungszeit weiter zu verkürzen.
Zuvor waren Teams beim Testen auf ein QS-Team und bei der Bereitstellung auf ein Infrastruktur-Team angewiesen. Jetzt gibt es niemanden, auf den man sich verlassen kann, außer sich selbst. Die Teams selbst testen und veröffentlichen den Code in der Produktion. Dies sind echte, keine gefälschten DevOps.
Die Entwicklung der Stop the Line-Methode
In einer allgemeinen Sprint-Retrospektive überprüfen wir Experimente. In den nächsten Rückblicken haben wir viele Änderungen an den Stop the Line-Regeln vorgenommen, zum Beispiel:
- Kanal freigeben. Alle Informationen zur aktuellen Version befinden sich in einem separaten Slack-Kanal. Der Kanal hat alle Teams, deren Änderungen in der Veröffentlichung enthalten sind. Auf diesem Kanal bittet der Auslöser um Hilfe.
- Magazin veröffentlichen. Die für die Freigabe verantwortliche Person protokolliert ihre Aktionen. Dies hilft, die Gründe für die Verzögerung der Veröffentlichung zu finden und Muster zu entdecken.
- Die Regel von fünf Minuten. Innerhalb von fünf Minuten nach der Ankündigung von Stop the Line versammeln sich Teamvertreter um das Notlicht.
- Rückstand Stoppen Sie die Leitung. An der Wand befindet sich ein Flipchart mit dem Backlog von Stop The Line - eine Liste von Aufgaben, die Teams ausführen können, während die Linie stoppt.
- Berücksichtigen Sie nicht den letzten Freitag des Sprints. Es ist unfair, zwei Veröffentlichungen zu vergleichen, zum Beispiel eine, die am Montag begann, und eine andere, die am Freitag begann. Das erste Team kann zwei volle Tage damit verbringen, die Veröffentlichung zu unterstützen, und während der zweiten Veröffentlichung wird es am Freitag (Sprint Review, Team Retrospective, General Retrospective) und am kommenden Montag (General und Team Sprint Planning) viele Veranstaltungen geben, sodass das Freitagsteam weniger Zeit hat Release-Unterstützung. Die Veröffentlichung am Freitag wird mit größerer Wahrscheinlichkeit als am Montag gestoppt. Aus diesem Grund haben wir beschlossen, den letzten Freitag des Sprints von der Gleichung auszuschließen.
- Beseitigung der technischen Schulden. Nach ein paar Monaten beschlossen die Teams, während des Stopps an technischen Schulden zu arbeiten und nicht nur die Bereitstellungspipeline zu beschleunigen.
- Besitzer Stop the Line. Einer der Entwickler meldete sich freiwillig als Eigentümer von Stop The Line. Er ist tief in die Gründe für die Verzögerung der Veröffentlichungen vertieft und verwaltet den Stop the Line-Rückstand. Wenn die Linie stoppt, kann der Eigentümer jedes Team anziehen, um an den Elementen des Stop the Line-Rückstands zu arbeiten.
- Post mortem. Der Besitzer von Stop the Line hält nach jedem Stopp eine Obduktion.
Kosten für Verluste
Aufgrund von Stop the Line haben wir einige Sprintziele nicht erreicht. Unternehmensvertreter waren mit unseren Fortschritten nicht allzu zufrieden und stellten beim Sprint Review viele Fragen. Nach dem Prinzip der Transparenz haben wir darüber gesprochen, was Stop the Line ist und warum Sie auf ein paar weitere Sprints warten sollten. Bei jedem Sprint Review haben wir Teams und Stakeholdern gezeigt, wie viel Geld wir durch Stop the Line verloren haben. Die Kosten werden als Gesamtgehalt der Entwicklungsteams während der Ausfallzeit berechnet.
• 2. November 106 000 p.
• Dezember - 503 504 p.
• Januar - 1 219 767 p.
• 2. Februar 002 278 p.
• März - 0 p.
• April - 0 p.
• Mai - 361 138 S.
Diese Transparenz erzeugt einen gesunden Druck und motiviert die Teams, Probleme mit der Bereitstellungspipeline sofort zu lösen. Wenn wir uns diese Zahlen ansehen, verstehen unsere Teams, dass nichts umsonst ist, und jeder Stop the Line bringt uns einen hübschen Cent.
Ergebnisse
Tatsächlich wandelt Stop the Line einen selbstverstärkenden Zyklus (Abb. 2) in zwei Ausgleichszyklen (Abb. 4) um. Stop the Line hilft uns, uns auf die Verbesserung der Bereitstellungspipeline zu konzentrieren, wenn sie zu langsam wird. In nur 4 Sprints haben wir:
- 12 stabile Releases fallen gelassen
- Reduzierte Bauzeit um 30%
- Stabilisierte UI- und API-Tests. Jetzt geben sie alle Umgebungen und sogar lokal weiter.
- Befreien Sie sich von blinkenden Tests
- Ich habe angefangen, unseren Tests zu vertrauen.
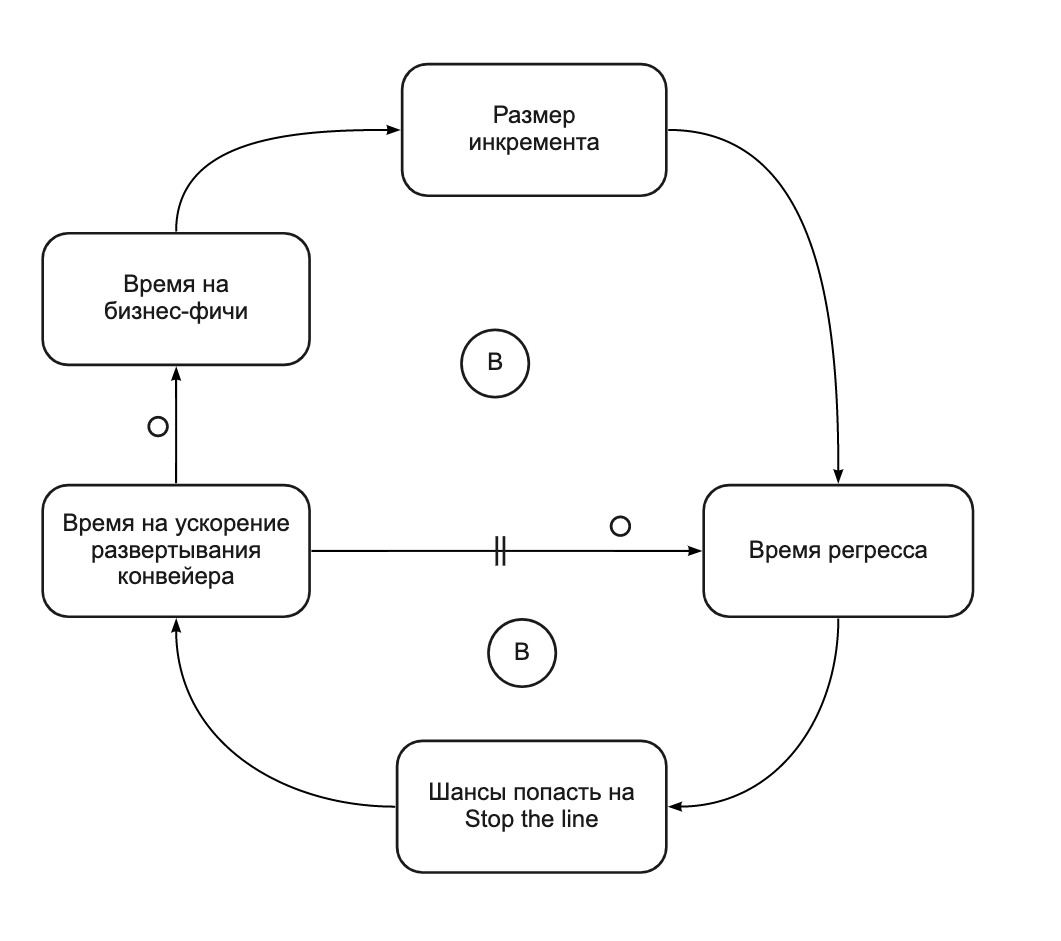
Abb. 4. CLD-Diagramm: Stoppen Sie die Freigabezeit für die Linienbilanzen
Schlussfolgerungen von Scrum Masters
Stop The Line ist ein Paradebeispiel für eine leistungsstarke Lösung, die von den Entwicklungsteams selbst erfunden wurde. Scrum Master kann nicht einfach eine brillante neue Praxis für die Teams übernehmen. Das Training wird nur funktionieren, wenn die Teams selbst darauf gekommen sind. Dies erfordert günstige Bedingungen: eine Atmosphäre des Vertrauens und eine Kultur des Experimentierens.
Natürlich sind Vertrauen und Unterstützung durch das Unternehmen erforderlich, was nur mit vollständiger Transparenz möglich ist. Feedback, wie eine regelmäßige, allgemeine Retrospektive mit allen Teamvertretern, hilft dabei, neue Praktiken zu erfinden, umzusetzen und zu modifizieren.
Im Laufe der Zeit sollte sich die Praxis von Stop the Line von selbst töten. Je öfter wir die Leitung anhalten, je mehr wir in die Bereitstellungspipeline investieren, desto stabiler und schneller wird die Veröffentlichung, desto weniger Grund zum Anhalten. Am Ende wird die Linie niemals anhalten, es sei denn, wir beschließen, den Schwellenwert beispielsweise von 48 auf 24 Stunden zu senken. Dank dieser Vorgehensweise haben wir das Freigabeverfahren jedoch erheblich verbessert. Die Teams sammelten nicht nur Erfahrung in der Entwicklung, sondern auch in der schnellen Wertschöpfung für Produkte. Dies sind echte DevOps.
Was weiter? Ich weiß nicht. Vielleicht werden wir diese Praxis bald aufgeben. Die Teams werden entscheiden. Es ist jedoch offensichtlich, dass wir uns weiterhin in Richtung Continuous Delivery und DevOps bewegen werden. Eines Tages wird mein Traum, mehrmals am Tag einen Monolithen freizugeben, wahr.