
Stellen Sie sich vor, Sie haben mit einem Freund darüber gestritten, was vorher passiert ist - ein
Huhn oder ein Ei, zum Beispiel
eine Steuererhöhung oder Neuigkeiten zu diesem Thema oder ein wichtiges Ereignis, das eine Wolke von Neuigkeiten über ein neues Lied, beispielsweise Kirkorov, völlig übertönt. Es wäre zweckmäßig, zu berechnen, wie viele Nachrichten zu jedem Thema zu einem bestimmten Zeitpunkt vorliegen, und diese dann zu visualisieren. Genau darum geht es in dem Projekt „Runet News Radar“. Im Rahmen des Schnitts werden wir Ihnen sagen, was maschinelles Lernen damit zu tun hat und wie jeder Freiwillige daran teilnehmen kann.
Kurzanleitung
Maschinelles Lernen für das soziale Wohl (ML4SG) ist eine Initiative innerhalb der ODS-Community, die darauf abzielt, wie der Name schon sagt, die Voraussetzungen für Projekte zu schaffen, die maschinelles Lernen nutzen, um der Gesellschaft einen gewissen Nutzen zu bringen. Die Schaffung von Bedingungen bezieht sich hier hauptsächlich auf organisatorische Ressourcen. Es sieht ungefähr so aus: Jemand formuliert die Idee des Projekts und ermutigt Freiwillige, während sich jemand einfach dem Projekt anschließt, um eine Idee, Erfahrung oder andere Interessen zu haben. Alles beruht auf Begeisterung, meistens in der Freizeit von der Hauptarbeit. Runet News Radar, oder wie wir es kurz im News Team nennen, ist eines der Projekte innerhalb der ML4SG.
Haftungsausschluss
In einigen Abbildungen in diesem Artikel werden einige politische Ereignisse oder Personen erwähnt. Überlassen wir uns selbst die Meinung dazu. Habr ist nicht für Politik.
Was machen wir
Kurz gesagt, über Motivation
Jetzt ist das Projekt als Werkzeug zur Analyse der Medien als Ganzes positioniert. Wenn es eine Hypothese darüber gibt, wie sich die Aufmerksamkeit in den Nachrichten auf verschiedene Themen, Ereignisse, Personen usw. entwickelt hat, können wir auf der Grundlage bestimmter Zahlen sprechen, nicht auf der Grundlage von Spekulationen.
Die ursprüngliche Idee war folgende: Wir nehmen alle gefundenen Nachrichtendaten, wenden thematische Modelle an, legen die Ergebnisse rechtzeitig an und zeichnen das Ergebnis.
Was ist thematische Modellierung?Definition von machinelearning.ru:
Ein Themenmodell ist eine Sammlung von Textdokumenten, die bestimmt, zu welchen Themen jedes Sammlungsdokument gehört. Der Algorithmus zum Erstellen eines thematischen Modells empfängt am Eingang eine Sammlung von Textdokumenten. Die Ausgabe für jedes Dokument ist ein numerischer Vektor, der aus Schätzungen des Grads der Zugehörigkeit dieses Dokuments zu jedem der Themen besteht. Die Dimension dieses Vektors, die der Anzahl der Themen entspricht, kann entweder am Eingang festgelegt oder vom Modell automatisch bestimmt werden.
Weitere Details
hier .
Es ist klar, dass dies die Nachrichten selbst erfordert, und wir laden sie herunter. Und da wir ein großes Nachrichtenkorps haben werden, können Sie viele weitere interessante Dinge tun, die nicht auf Themen beschränkt sind. Unter Berücksichtigung der tatsächlichen Bedingungen, über die wir sprechen werden, nämlich dass eine Menge Freiwilliger und kein gut funktionierendes Team bezahlter Spezialisten das Projekt umsetzen werden, lösen wir das Problem zunächst noch fast unverändert.

Jetzt sind wir zu diesem Format der Visualisierung gekommen, es wird Kammlinienplot genannt. Auf der Folie sind diese Themen übrigens ein Bildschirm aus einer alten internen Demo. Das heißt, hier haben wir Zeit auf der Abszissenachse, die Dicke des Streifens ist proportional dazu, wie stark das Thema in diesem Moment unter anderen Nachrichten vertreten ist. In diesem Fall Aggregation nach Monat.
Im Grundplan haben wir die Wahl zwischen einer Nachrichtenquelle und der Wahl, wie ein Diagramm angezeigt werden soll. Sie können auch zusätzliche Daten auswählen, die nicht aus den Nachrichten stammen, z. B. wie sich der Ölpreis oder ein anderer Indikator zu diesem Zeitpunkt im selben Zeitraum verhalten hat. Die Auswahl einer Überschrift und einer Reihe von Themen. Darüber hinaus gibt es viel mehr Ideen, aber dazu später mehr.
Ähnliche Projekte
Es gibt viele verschiedene andere Projekte, die sich mit der Visualisierung von Nachrichten befassen. Ich mag
diese beiden . Der erste vergleicht, wie die gleichen Nachrichten in verschiedenen Quellen präsentiert werden und gleichzeitig eine sehr gute Form der Präsentation und Interaktivität. Der zweite hat einfach eine sehr gute Einstellung zur Informativität zur Einfachheit. Es wird verglichen, wie viel über die verschiedenen Todesursachen in den Nachrichten gesagt wird, wie oft welche Todesursachen in Suchanfragen erwähnt werden und wie statistisch. Nun, in den Schlussfolgerungen darüber, wie der Terrorismus katastrophal überschätzt wird und wie Herzkrankheiten und Krebs unterschätzt werden.
Wie machen wir das?
Das Projekt ist ziemlich einfach. Zuerst laden wir die Daten herunter, dann verarbeiten wir sie, lernen maschinell und zeichnen Diagramme. Dann machen wir eine Website und jeder schaut zu. Alles ist klar (na ja, natürlich).

Datenerfassung
Zu Beginn hatten wir 20 Jahre lang einen Ru-Tape-Datensatz. Grundsätzlich haben wir alle Experimente damit gemacht. Jetzt haben wir mehrere weitere Quellen gesammelt und sammeln weiterhin alles, was wir erreichen. Es gibt viele detaillierte Materialien zum Thema Schaben und Spinnen, daher werden wir hier nicht im Detail auf dieses Thema eingehen.
Nlp
Ich war am meisten besorgt über den NLP-Teil, weil es schwierig ist, die Anforderungen für das Ergebnis des Themas zu formalisieren. Darüber hinaus gibt es viele Nebenaufgaben. Jetzt haben wir eine Menge Experimente mit verschiedenen Werkzeugen für die thematische Modellierung durchgeführt, bevor wir die Vorverarbeitung losgeworden sind, viele Benchmarks und Vergleiche durchgeführt haben. Im Moment erwies sich bigARTM als unangefochtener Themenführer in Bezug auf Ressourcen und Qualität. Dies ist unsere Arbeitsoption, bis jemand etwas Besseres zeigt.
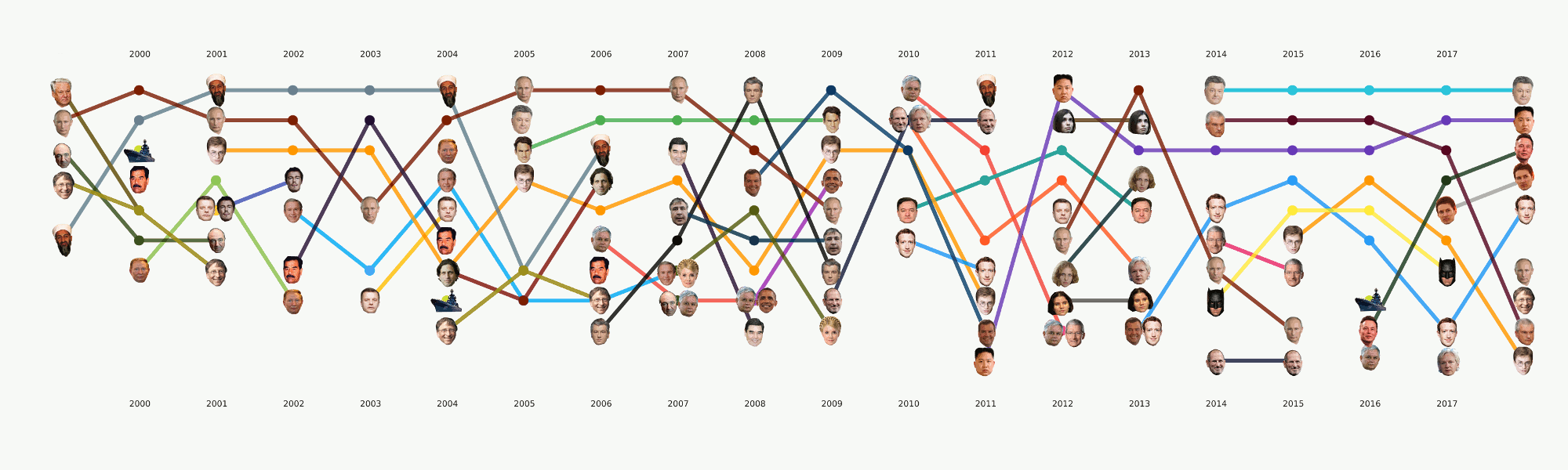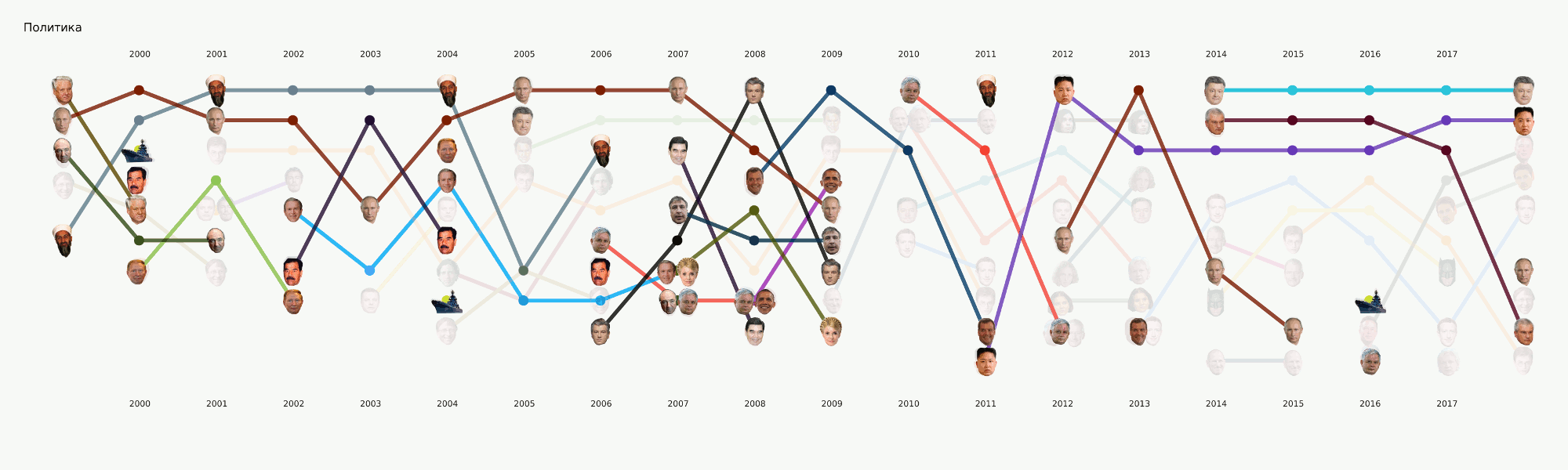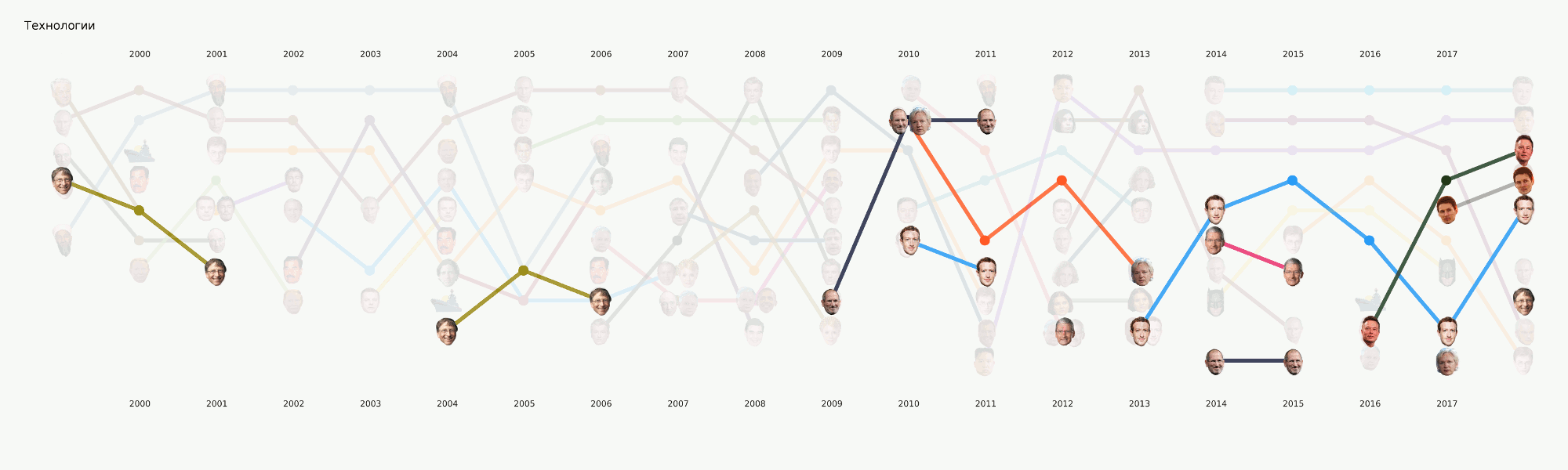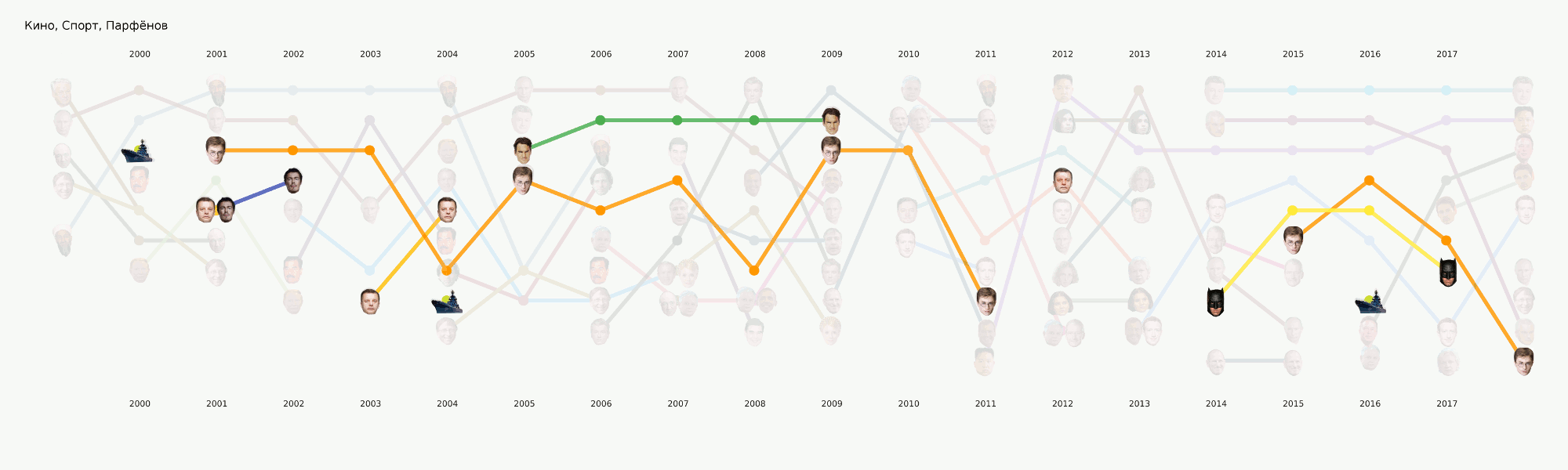
Im Allgemeinen konzentriert sich das gesamte maschinelle Lernen hauptsächlich auf diesen Abschnitt. Neben der ursprünglich festgelegten Hauptaufgabe des Themas gibt es viele andere, die ebenfalls interessante Schlussfolgerungen ziehen. Zum Beispiel NER. Wir haben bereits alle Namen aus den Daten herausgezogen, Wörterbücher zusammengestellt und gezählt, die wir oft erwähnen. Es stellte sich zum Beispiel heraus, dass über Poroschenko in Lente.ru die ganze Zeit viermal mehr geschrieben wurde als über Putin. Es wurde für mich interessant, dass Assange synchron mit Magnitsky geht, und das alles genau nachdem Bush gegangen ist. Aber Batman ist beliebter als Medwedew.
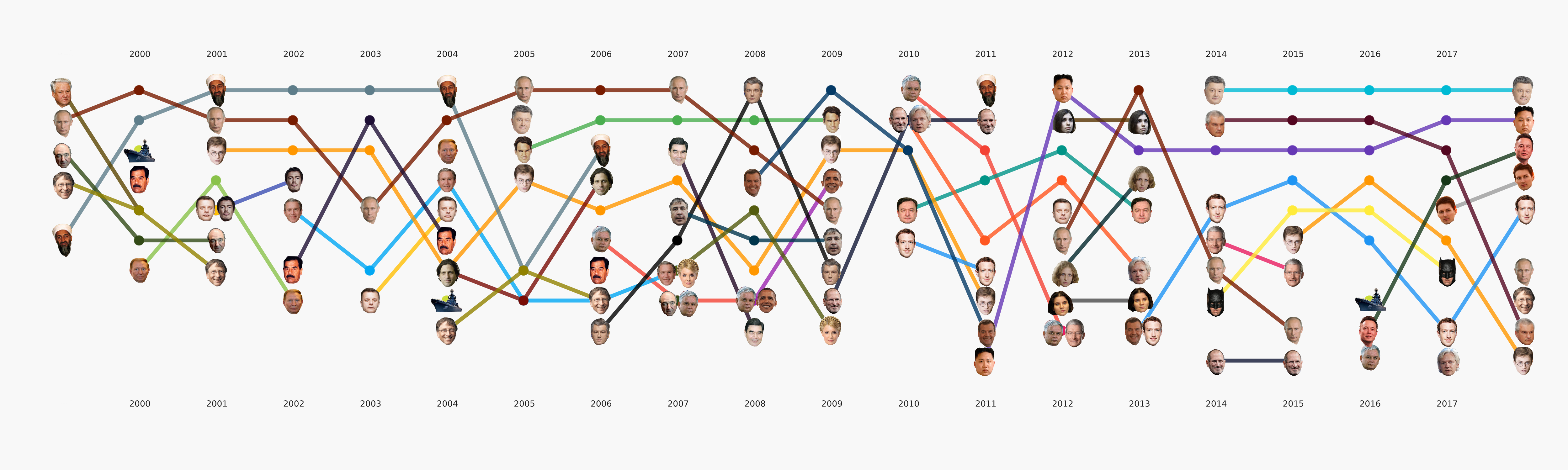

Animation in Kategorien unterteiltDies ist eine Art Teaser für unsere kommenden Artikel, in denen wir ausführlicher darüber sprechen werden, wie dieses Bild entstanden ist und welche Schlussfolgerungen daraus gezogen werden können.
Obwohl sich diese Phase noch im Prozess befindet, haben wir eine große Anzahl von Experimenten durchgeführt und viele Werkzeuge und Ansätze verglichen. Dabei ein umfangreiches Tutorial zu verschiedenen NLP-Aufgaben mit Codebeispielen und Benchmarks der beliebtesten und ungewöhnlichsten Tools.
Visualisierung
Diese Phase schien nicht allzu kompliziert zu sein, aber aus irgendeinem Grund war fast niemand bereit, sich damit zu befassen. Die Visualisierungsanforderungen gehen etwas weiter als der übliche EDA-Ansatz in datasense. Das Zeichnen eines Diagramms für sich selbst oder ein anderes Rechenzentrum ist viel einfacher als das Zeichnen eines Diagramms für die breite Öffentlichkeit. Wir waren sehr lange mit Formaten und Werkzeugen beschäftigt und sind jetzt zu einigen Ansätzen gekommen, die am vernünftigsten erscheinen, aber es liegt noch viel Arbeit vor uns, da es praktisch keine vorgefertigten Werkzeuge für unsere Aufgaben gibt. Zum Beispiel wurde das Diagramm mit den obigen Flächen in zwei Schritten erstellt - die Hauptelemente wurden im Code generiert, und dann folgte eine lange Phase des manuellen Neuzeichnens, sodass zumindest etwas gelesen wurde. In Bezug auf eine detaillierte Analyse dieser Visualisierung in einem separaten Artikel spiegelt sie in gewissem Maße die Geschichte Russlands in den letzten 20 Jahren wider.
Das Team
Es ist bedingt möglich, die Teilnehmer in zwei Gruppen einzuteilen: Anfänger und Profis. Für Anfänger ist die Motivation einfach: Legen Sie in ein Sparschwein ein Projekt, um es den Arbeitgebern zu zeigen, oder sammeln Sie einfach Erfahrungen, um etwas zu lernen. Und ich wurde bereits darüber informiert, dass die verschiedenen Dinge, die wir im Rahmen des Projekts getan haben, für die Arbeit der Teilnehmer nützlich waren, schätzten die Behörden. Profis kommen entweder wegen des eigentlichen Ziels des Projekts, weil sie daran interessiert sind, sich der Idee anzuschließen, oder weil sie einige ihrer Ideen in den Nachrichten ausprobieren möchten.
Tatsächlich gibt es eine andere Gruppe von Teilnehmern - dies sind die schwer fassbaren Ninjas, die dazu passen und nichts tun oder einfach anfangen und dann verschwinden. Aber wie ich bereits erklärt habe, arbeitet niemand für Geld im Projekt, so dass die Desorganisation der Humanressourcen unvermeidlich ist. Eine Beobachtung von der Seite der Neugier ist ebenfalls möglich.

Derzeit gibt es formell ungefähr 80 Personen, von denen ungefähr 10-20 aktiv sind und 2-4 Personen fast ständig aktiv sind. In diesem Format können Sie den Mangel an Erfahrung im Laufe der Zeit ausgleichen. Viele Leute schreiben, dass es kein Wissen darüber gibt, wie es geht, es besteht die Angst, aufgrund von Unfähigkeit zu scheitern, aber in der Tat ist es wichtig, es einfach zu tun und keinen Moment zu warten. Weil ml4sg eine sehr coole Aktivität ist. Sie können nützlich sein und gleichzeitig Gewinn in Form von Erfahrung und Portfolio erzielen. Während Risiko nur Zeit ist, hat der Manager natürlich auch einen guten Ruf, aber die wichtigste Ressource hier ist Zeit, die sich letztendlich auszahlt.
Weitere Pläne
Jetzt versuche ich es als Forschungswerkzeug zu positionieren. Wir planen, eine "explorative" Suche hinzuzufügen, die das Thema der Anfrage auswerten und Statistiken zu den Nachrichten dieses Themas sowie Diagramme verschiedener Nicht-Nachrichten-Daten bereitstellen kann, die jedoch für das Thema des Projekts relevant sind. Dann können alle möglichen Hypothesen darüber getestet werden, wie sich die Medien verhalten, wie Ereignisse und andere willkürliche soziale oder wirtschaftliche Indikatoren zusammenhängen. Ein solches Werkzeug, um die Medien als Ganzes zu erforschen.
Wer braucht ein Projekt
- Wir haben nur sehr wenige Leute, die an der Visualisierung beteiligt sind. Wir gehen über die üblichen Tools von Rechenzentren wie matplotlib oder plotly hinaus und brauchen daher Menschen, die die Visualisierung von Daten wirklich lieben und tief in sie hineinpumpen möchten.
- Wir brauchen Leute, die etwas in der Webentwicklung verstehen.
- Wir brauchen Leute, die uns sagen, wonach wir suchen sollen. Tatsächlich sollten es unsere Kunden sein, die daran interessiert sind, eine Studie durchzuführen und einigen Dingen auf den Grund zu gehen, wie sich die russischsprachigen Medien in letzter Zeit verändert haben.
- Wir brauchen immer Spezialisten für NLP, ich denke, hier besteht kein Grund zur Erklärung. Und es gibt etwas zu tun für diejenigen, die lernen wollen, und für erfahrene Leute, da es in diesem Bereich viele so interessante Probleme gibt.
- Und natürlich müssen wir ein anständiges Projekt erstellen, damit nicht alles auf Klebeband funktioniert. Wenn Sie also in der Architektur von Projekten herumfummeln, können Sie eine Reihe von Experimenten in einer Pipeline zusammenfassen und sind bereit, Ihre Erfahrungen zu teilen. Wenn Sie unterwegs lernen möchten, sind Sie auch herzlich willkommen.