
Mein Name ist Eduard Tyantov, ich leite das Computer Vision-Team bei Mail.ru Group. In den letzten Jahren unseres Bestehens hat unser Team Dutzende von Computer-Vision-Problemen gelöst. Heute werde ich Ihnen erläutern, mit welchen Methoden wir erfolgreich Modelle für maschinelles Lernen erstellen, die für eine Vielzahl von Aufgaben geeignet sind. Ich werde Tricks vorstellen, die das Modell in allen Phasen beschleunigen können: Festlegen einer Aufgabe, Vorbereiten von Daten, Schulung und Bereitstellung in der Produktion.
Computer Vision bei Mail.ru
Was ist Computer Vision in Mail.ru und welche Projekte wir durchführen? Wir bieten Lösungen für unsere Produkte wie Mail, Mail.ru Cloud (eine Anwendung zum Speichern von Fotos und Videos), Vision (B2B-Lösungen basierend auf Computer Vision) und andere. Ich werde einige Beispiele geben.
Die Cloud (dies ist unser erster und Hauptkunde) enthält 60 Milliarden Fotos. Wir entwickeln verschiedene Funktionen, die auf maschinellem Lernen basieren, für ihre intelligente Verarbeitung, z. B. Gesichtserkennung und Besichtigung (dazu
gibt es einen separaten Beitrag ). Alle Benutzerfotos werden durch Erkennungsmodelle geführt, mit denen Sie eine Suche und Gruppierung nach Personen, Tags, besuchten Städten und Ländern usw. organisieren können.
Für Mail haben wir OCR - Erkennung von Text aus einem Bild durchgeführt. Heute erzähle ich Ihnen etwas mehr über ihn.
Bei B2B-Produkten erkennen und zählen wir Personen in Warteschlangen. Zum Beispiel gibt es eine Warteschlange für den Skilift, und Sie müssen berechnen, wie viele Personen sich darin befinden. Um die Technologie und das Spiel zu testen, haben wir zunächst einen Prototyp im Speisesaal des Büros installiert. Es gibt mehrere Kassen und dementsprechend mehrere Warteschlangen, und wir berechnen anhand des Modells anhand mehrerer Kameras (eine für jede Warteschlange), wie viele Personen sich in den Warteschlangen befinden und wie viele ungefähr Minuten in jeder Warteschlange verbleiben. Auf diese Weise können wir die Linien im Esszimmer besser ausbalancieren.

Erklärung des Problems
Beginnen wir mit dem kritischen Teil jeder Aufgabe - ihrer Formulierung. Fast jede ML-Entwicklung dauert mindestens einen Monat (dies ist bestenfalls, wenn Sie wissen, was zu tun ist) und in den meisten Fällen mehrere Monate. Wenn die Aufgabe falsch oder ungenau ist, besteht am Ende der Arbeit eine große Chance, vom Produktmanager etwas im Geiste zu hören: „Alles ist falsch. Das ist nicht gut Ich wollte etwas anderes. " Um dies zu verhindern, müssen Sie einige Schritte ausführen. Was ist das Besondere an ML-basierten Produkten? Im Gegensatz zur Aufgabe der Entwicklung einer Site kann die Aufgabe des maschinellen Lernens nicht allein mit Text formalisiert werden. Darüber hinaus scheint es einer unvorbereiteten Person in der Regel, dass alles bereits offensichtlich ist und es einfach erforderlich ist, alles „schön“ zu machen. Aber welche kleinen Details gibt es, der Task-Manager weiß vielleicht nicht einmal, hat noch nie darüber nachgedacht und wird nicht nachdenken, bis er das Endprodukt sieht und sagt: "Was haben Sie getan?"
Die Probleme
Lassen Sie uns anhand eines Beispiels verstehen, welche Probleme auftreten können. Angenommen, Sie haben eine Gesichtserkennungsaufgabe. Sie erhalten es, freuen sich und rufen Ihre Mutter an: "Hurra, eine interessante Aufgabe!" Aber ist es möglich, direkt zusammenzubrechen und damit zu beginnen? Wenn Sie dies tun, können Sie am Ende Überraschungen erwarten:
- Es gibt verschiedene Nationalitäten. Zum Beispiel gab es keine Asiaten oder sonst jemanden im Datensatz. Ihr Modell weiß dementsprechend überhaupt nicht, wie es sie erkennt, und das Produkt benötigt es. Oder umgekehrt, Sie haben zusätzliche drei Monate für die Überarbeitung aufgewendet, und das Produkt wird nur Kaukasier haben, und dies war nicht erforderlich.
- Es gibt Kinder. Für kinderlose Väter wie mich sind alle Kinder auf einem Gesicht. Ich bin absolut einverstanden mit dem Modell, wenn sie alle Kinder zu einem Cluster schickt - es ist wirklich unklar, wie sich die Mehrheit der Kinder unterscheidet! ;) Aber Menschen mit Kindern haben eine ganz andere Meinung. Normalerweise sind sie auch Ihre Führer. Oder es gibt immer noch lustige Erkennungsfehler, wenn der Kopf des Kindes erfolgreich mit dem Ellbogen oder dem Kopf eines kahlen Mannes verglichen wird (wahre Geschichte).
- Was mit gemalten Zeichen zu tun ist, ist im Allgemeinen unklar. Muss ich sie erkennen oder nicht?
Solche Aspekte der Aufgabe sind zu Beginn sehr wichtig zu identifizieren. Daher müssen Sie von Anfang an „an den Daten“ arbeiten und mit dem Manager kommunizieren. Mündliche Erklärungen können nicht akzeptiert werden. Es ist notwendig, die Daten zu betrachten. Es ist wünschenswert, aus der gleichen Verteilung, auf der das Modell arbeiten wird.
Im Idealfall wird im Verlauf dieser Diskussion ein Testdatensatz abgerufen, auf dem Sie das Modell endgültig ausführen und prüfen können, ob es wie vom Manager gewünscht funktioniert. Es ist ratsam, dem Manager selbst einen Teil des Testdatensatzes zu geben, damit Sie keinen Zugriff darauf haben. Da Sie dieses Testset problemlos neu trainieren können, sind Sie ein ML-Entwickler!
Das Setzen einer Aufgabe in ML ist eine ständige Arbeit zwischen einem Produktmanager und einem Spezialisten in ML. Selbst wenn Sie die Aufgabe zunächst gut eingestellt haben, treten im Laufe der Entwicklung des Modells immer mehr neue Probleme auf, neue Funktionen, die Sie über Ihre Daten lernen. All dies muss ständig mit dem Manager besprochen werden. Gute Manager senden ihren ML-Teams immer, dass sie Verantwortung übernehmen und dem Manager bei der Festlegung von Aufgaben helfen müssen.
Warum so? Maschinelles Lernen ist ein ziemlich neuer Bereich. Manager haben (oder haben wenig) Erfahrung mit der Verwaltung solcher Aufgaben. Wie oft lernen Menschen, neue Probleme zu lösen? Auf die Fehler. Wenn Sie nicht möchten, dass Ihr Lieblingsprojekt zum Fehler wird, müssen Sie sich engagieren und Verantwortung übernehmen, dem Produktmanager beibringen, die Aufgabe richtig einzustellen, Checklisten und Richtlinien zu entwickeln. das alles hilft sehr. Jedes Mal, wenn ich mich abziehe (oder jemand von meinen Kollegen mich abzieht), wenn eine neue interessante Aufgabe eintrifft, rennen wir los, um sie zu erledigen. Alles, was ich dir gerade gesagt habe, vergesse ich selbst. Daher ist es wichtig, eine Checkliste zu haben, um sich selbst zu überprüfen.
Daten
Daten sind in ML sehr wichtig. Für mehr Lernen ist es umso besser, je mehr Daten Sie Modelle füttern. Das blaue Diagramm zeigt, dass sich Deep-Learning-Modelle normalerweise erheblich verbessern, wenn Daten hinzugefügt werden.
Und die "alten" (klassischen) Algorithmen können sich irgendwann nicht mehr verbessern.
Normalerweise sind in ML Datensätze verschmutzt. Sie wurden von Menschen markiert, die immer lügen. Assessoren sind oft unaufmerksam und machen viele Fehler. Wir verwenden diese Technik: Wir nehmen die Daten, die wir haben, trainieren das Modell darauf und löschen dann mit Hilfe dieses Modells die Daten und wiederholen den Zyklus erneut.
Schauen wir uns das Beispiel derselben Gesichtserkennung genauer an. Angenommen, wir haben VKontakte-Benutzeravatare heruntergeladen. Zum Beispiel haben wir ein Benutzerprofil mit 4 Avataren. Wir erkennen Gesichter auf allen 4 Bildern und durchlaufen das Gesichtserkennungsmodell. So erhalten wir Einbettungen von Personen, mit deren Hilfe sie ähnliche Personen in Gruppen (Cluster) „kleben“ können. Als nächstes wählen wir den größten Cluster aus, vorausgesetzt, die Avatare des Benutzers enthalten hauptsächlich sein Gesicht. Dementsprechend können wir alle anderen Gesichter (die Rauschen sind) auf diese Weise reinigen. Danach können wir den Zyklus erneut wiederholen: Trainieren Sie das Modell für die bereinigten Daten und verwenden Sie es zum Bereinigen der Daten. Sie können mehrmals wiederholen.
Fast immer verwenden wir für ein solches Clustering CLink-Algorithmen. Dies ist ein hierarchischer Clustering-Algorithmus, bei dem es sehr praktisch ist, einen Schwellenwert für das „Kleben“ ähnlicher Objekte festzulegen (genau dies ist für die Reinigung erforderlich). CLink erzeugt sphärische Cluster. Dies ist wichtig, da wir häufig den metrischen Raum dieser Einbettungen lernen. Der Algorithmus hat eine Komplexität von O (n
2 ), die im Prinzip ca.
Manchmal ist es so schwierig, Daten abzurufen oder zu markieren, dass nichts mehr zu tun ist, sobald Sie mit der Generierung beginnen. Mit dem generativen Ansatz können Sie eine große Datenmenge erzeugen. Dafür müssen Sie aber etwas programmieren. Das einfachste Beispiel ist OCR, Texterkennung auf Bildern. Das Markup des Textes für diese Aufgabe ist extrem teuer und laut: Sie müssen jede Zeile und jedes Wort hervorheben, den Text signieren und so weiter. Assessoren (Markup-Personen) nehmen extrem lange hundert Seiten Text in Anspruch, und für die Schulung wird viel mehr benötigt. Natürlich können Sie den Text irgendwie generieren und irgendwie „verschieben“, damit das Modell daraus lernt.
Wir haben selbst festgestellt, dass das beste und bequemste Toolkit für diese Aufgabe eine Kombination aus PIL, OpenCV und Numpy ist. Sie haben alles für die Arbeit mit Text. Sie können das Bild auf irgendeine Weise mit Text komplizieren, damit das Netzwerk nicht für einfache Beispiele umschult.

Manchmal brauchen wir Objekte aus der realen Welt. Zum Beispiel Waren in den Regalen. Eines dieser Bilder wird automatisch generiert. Denkst du links oder rechts?

Tatsächlich werden beide generiert. Wenn Sie sich die kleinen Details nicht ansehen, werden Sie keine Unterschiede zur Realität bemerken. Wir machen das mit Blender (analog zu 3dmax).
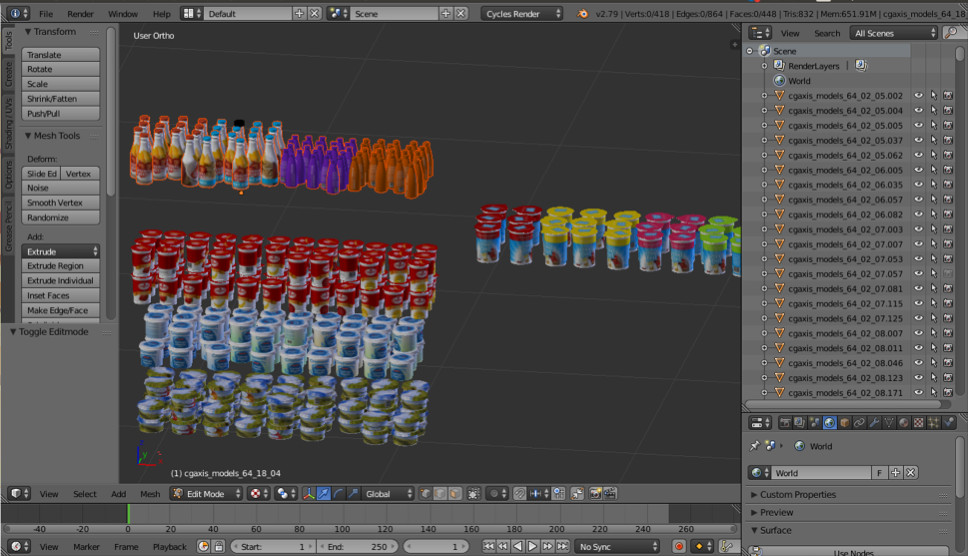
Der wichtigste Vorteil ist, dass es Open Source ist. Es verfügt über eine hervorragende Python-API, mit der Sie Objekte direkt im Code platzieren, den Prozess konfigurieren und randomisieren und schließlich ein vielfältiges Dataset erhalten können.
Zum Rendern wird Raytracing verwendet. Dies ist ein ziemlich kostspieliger Vorgang, der jedoch zu einem Ergebnis mit ausgezeichneter Qualität führt. Die wichtigste Frage: Woher bekommen Sie Modelle für Objekte? In der Regel müssen sie gekauft werden. Aber wenn Sie ein armer Schüler sind und mit etwas experimentieren möchten, gibt es immer Ströme. Es ist klar, dass Sie für die Produktion gerenderte Modelle bei jemandem kaufen oder bestellen müssen.
Das ist alles über die Daten. Fahren wir mit dem Lernen fort.
Metrisches Lernen
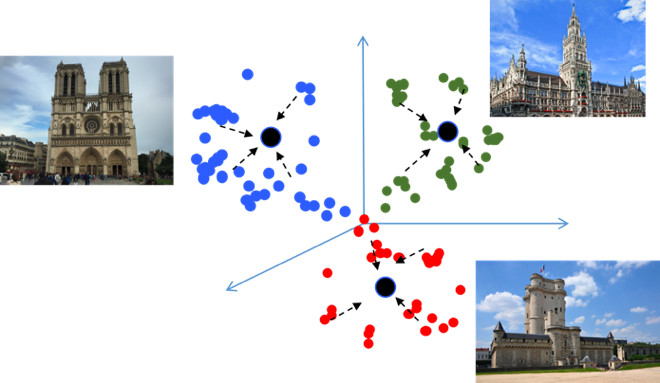
Das Ziel des metrischen Lernens besteht darin, das Netzwerk so zu trainieren, dass es ähnliche Objekte in ähnliche Regionen im eingebetteten metrischen Raum übersetzt. Ich werde noch einmal ein Beispiel mit den Sehenswürdigkeiten geben, was insofern ungewöhnlich ist, als es im Wesentlichen eine Klassifizierungsaufgabe ist, aber für Zehntausende von Klassen. Es scheint, warum hier metrisches Lernen, das in der Regel für Aufgaben wie die Gesichtserkennung geeignet ist? Versuchen wir es herauszufinden.
Wenn Sie beim Trainieren eines Klassifizierungsproblems, z. B. Softmax, Standardverluste verwenden, sind die Klassen im metrischen Raum gut voneinander getrennt, aber im Einbettungsraum können die Punkte verschiedener Klassen nahe beieinander liegen ...

Dies führt zu potenziellen Fehlern bei der Verallgemeinerung Ein geringfügiger Unterschied in den Quelldaten kann das Klassifizierungsergebnis ändern. Wir möchten wirklich, dass die Punkte kompakter sind. Hierzu werden verschiedene metrische Lerntechniken eingesetzt. Zum Beispiel Center Loss, dessen Idee extrem einfach ist: Wir ziehen einfach Punkte zum Lernzentrum jeder Klasse zusammen, die schließlich kompakter werden.
Center Loss wird in Python buchstäblich in 10 Zeilen programmiert, funktioniert sehr schnell und vor allem verbessert es die Qualität der Klassifizierung, weil Kompaktheit führt zu einer besseren Verallgemeinerungsfähigkeit.
Angular Softmax
Wir haben viele verschiedene metrische Lernmethoden ausprobiert und sind zu dem Schluss gekommen, dass Angular Softmax die besten Ergebnisse liefert. In der Forschungsgemeinschaft gilt er auch als Stand der Technik.
Schauen wir uns ein Beispiel für die Gesichtserkennung an. Hier haben wir zwei Leute. Wenn Sie den Standard-Softmax verwenden, wird eine Teilungsebene zwischen ihnen gezeichnet - basierend auf zwei Gewichtsvektoren. Wenn wir die Norm 1 einbetten, liegen die Punkte auf dem Kreis, d.h. auf der Kugel im n-dimensionalen Fall (Bild rechts).
Dann können Sie sehen, dass der Winkel zwischen ihnen bereits für die Trennung der Klassen verantwortlich ist und optimiert werden kann. Aber nur das ist nicht genug. Wenn wir nur den Winkel optimieren, ändert sich die Aufgabe tatsächlich nicht, weil wir haben es einfach anders formuliert. Ich erinnere mich, dass unser Ziel darin besteht, Cluster kompakter zu machen.
In gewisser Weise ist es notwendig, einen größeren Winkel zwischen den Klassen zu fordern, um die Aufgabe des neuronalen Netzwerks zu erschweren. Zum Beispiel so, dass sie denkt, dass der Winkel zwischen den Punkten einer Klasse größer ist als in der Realität, so dass sie versucht, sie immer mehr zu komprimieren. Dies wird erreicht, indem der Parameter m eingeführt wird, der die Differenz in den Kosinus der Winkel steuert.
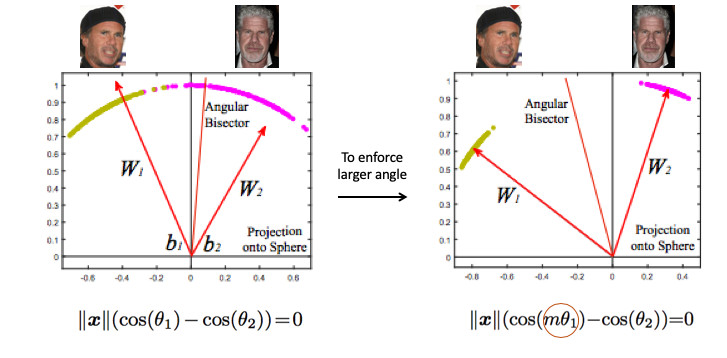
Es gibt verschiedene Optionen für Angular Softmax. Sie alle spielen mit der Tatsache, dass sie mit diesem Winkel multiplizieren oder addieren oder multiplizieren und addieren. State-of-the-Art - ArcFace.
Tatsächlich ist dieser recht einfach in die Pipeline-Klassifizierung zu integrieren.
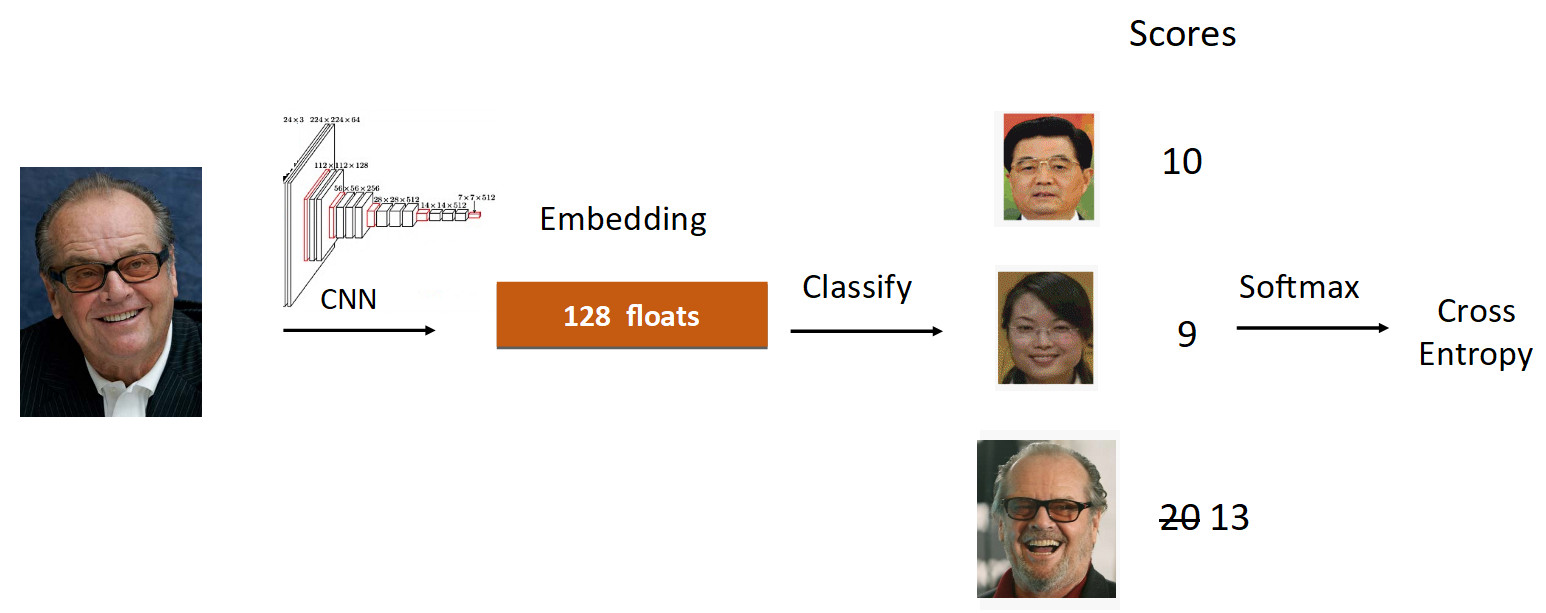
Schauen wir uns das Beispiel von Jack Nicholson an. Wir führen sein Foto im Lernprozess durch das Raster. Wir werden eingebettet, durchlaufen die lineare Ebene zur Klassifizierung und erhalten am Ausgang Punktzahlen, die den Grad der Zugehörigkeit zur Klasse widerspiegeln. In diesem Fall hat Nicholsons Foto eine Geschwindigkeit von 20, die größte. Gemäß der Formel von ArcFace reduzieren wir die Geschwindigkeit von 20 auf 13 (nur für die Groundtruth-Klasse), was die Aufgabe für das neuronale Netzwerk kompliziert. Dann machen wir alles wie gewohnt: Softmax + Cross Entropy.
Insgesamt wird die übliche lineare Ebene durch die ArcFace-Ebene ersetzt, die nicht in 10, sondern in 20 Zeilen geschrieben ist, aber hervorragende Ergebnisse und ein Minimum an Overhead für die Implementierung bietet. Daher ist ArcFace für die meisten Aufgaben besser als die meisten anderen Methoden. Es lässt sich perfekt in Klassifizierungsaufgaben integrieren und verbessert die Qualität.
Lernen übertragen
Das zweite, worüber ich sprechen wollte, ist das Transferlernen - Verwenden eines vorab geschulten Netzwerks für eine ähnliche Aufgabe zur Umschulung für eine neue Aufgabe. Somit wird Wissen von einer Aufgabe zur anderen übertragen.
Wir haben nach Bildern gesucht. Das Wesentliche der Aufgabe besteht darin, semantisch ähnliche aus der Datenbank im Bild (Abfrage) zu erstellen.

Es ist logisch, ein Netzwerk zu verwenden, das bereits eine große Anzahl von Bildern untersucht hat - in ImageNet- oder OpenImages-Datensätzen, in denen sich Millionen von Bildern befinden, und unsere Daten zu trainieren.
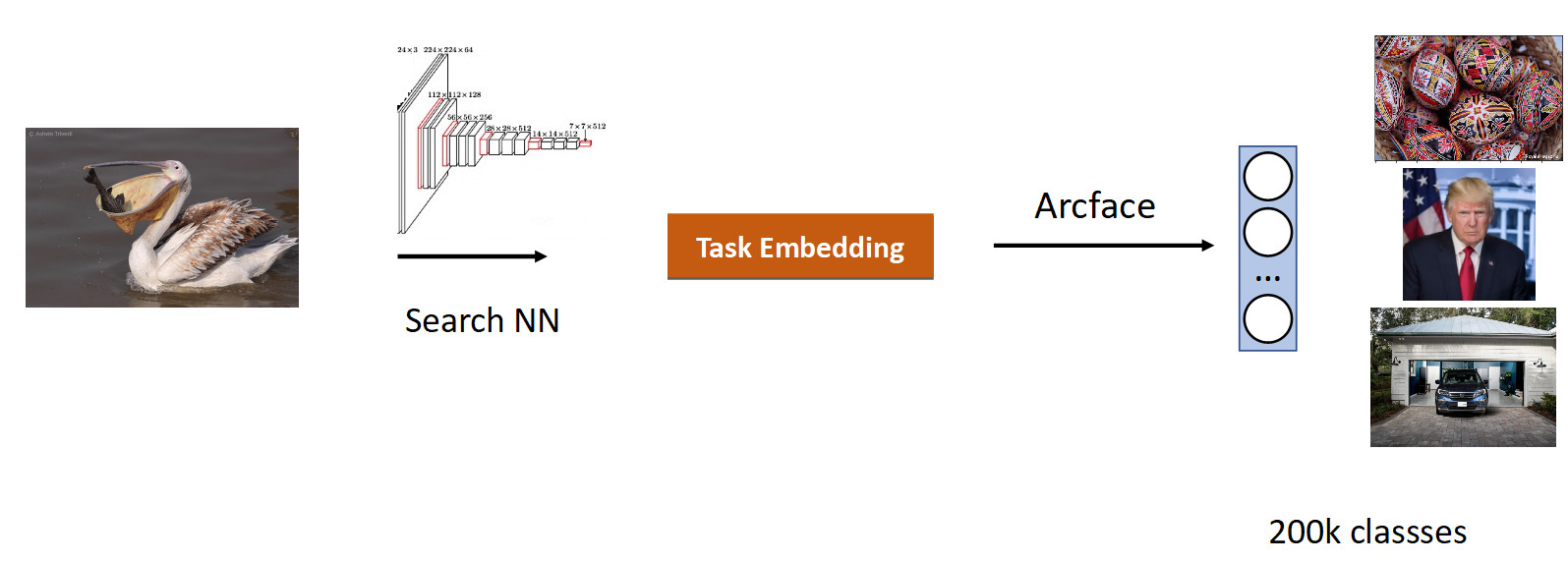
Wir haben Daten für diese Aufgabe basierend auf der Ähnlichkeit von Bildern und Benutzerklicks gesammelt und 200.000 Klassen erhalten. Nach dem Training mit ArFace haben wir das folgende Ergebnis erhalten.

Im obigen Bild sehen wir, dass für den angeforderten Pelikan auch Spatzen in das Problem geraten sind. Das heißt, Einbettung stellte sich semantisch als wahr heraus - es ist ein Vogel, aber rassentreu. Das nervigste ist, dass das ursprüngliche Modell, mit dem wir umgeschult haben, diese Klassen kannte und sie perfekt unterschied. Hier sehen wir den Effekt, der allen neuronalen Netzen gemeinsam ist und als katastrophales Vergessen bezeichnet wird. Das heißt, während der Umschulung vergisst das Netzwerk die vorherige Aufgabe, manchmal sogar vollständig. Genau dies verhindert bei dieser Aufgabe eine bessere Qualität.
Wissensdestillation
Dies wird mit einer Technik behandelt, die als Wissensdestillation bezeichnet wird, wenn ein Netzwerk ein anderes lehrt und „sein Wissen darauf überträgt“. Wie es aussieht (vollständige Trainingspipeline im Bild unten).
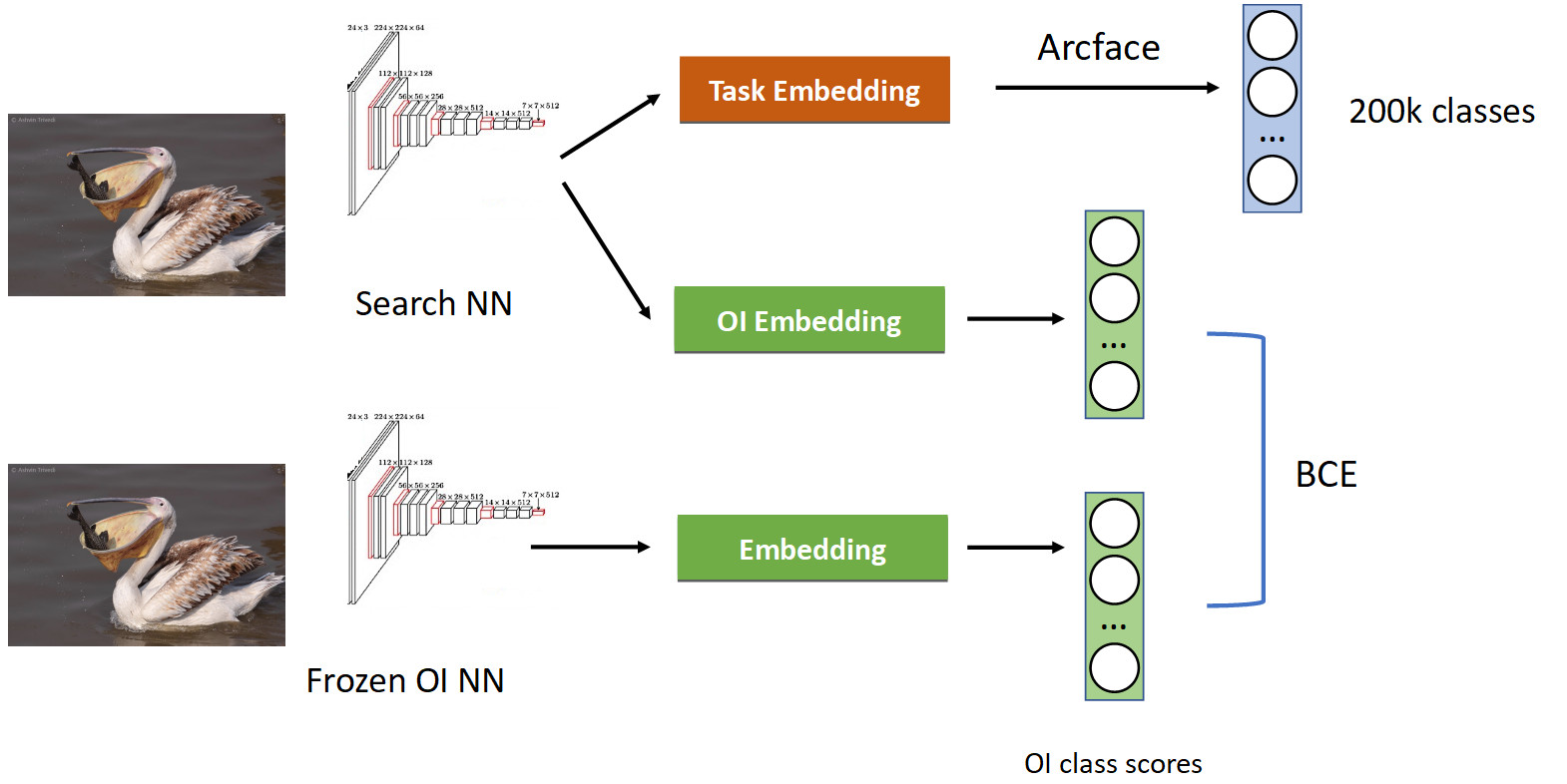
Wir haben bereits eine vertraute Klassifizierungspipeline mit Arcface. Denken Sie daran, dass wir ein Netzwerk haben, mit dem wir vorgeben. Wir haben es eingefroren und einfach seine Einbettungen in alle Fotos berechnet, auf denen wir unser Netzwerk lernen, und die Klassen von OpenImages schnell erhalten: Pelikane, Spatzen, Autos, Menschen usw. ... Wir rühren uns vom ursprünglich trainierten neuronalen Netzwerk und lernen eine weitere Einbettung für Klassen OpenImages, das ähnliche Ergebnisse liefert. Mit BCE sorgen wir dafür, dass das Netzwerk eine ähnliche Verteilung dieser Scores erzeugt. So lernen wir einerseits eine neue Aufgabe (oben im Bild), aber wir lassen das Netzwerk auch seine Wurzeln nicht vergessen (unten) - erinnern Sie sich an die Klassen, die es früher kannte. Wenn Sie die Steigungen in einem bedingten Verhältnis von 50/50 richtig ausgleichen, bleiben alle Pelikane oben und werfen alle Spatzen von dort weg.

Als wir dies angewendet haben, haben wir einen vollen Prozentsatz im mAP erhalten. Das ist ziemlich viel.
Wenn Ihr Netzwerk also die vorherige Aufgabe vergisst, behandeln Sie die Wissensdestillation - dies funktioniert einwandfrei.
Zusätzliche Köpfe
Die Grundidee ist sehr einfach. Wieder am Beispiel der Gesichtserkennung. Wir haben eine Reihe von Personen im Datensatz. Aber auch in Datensätzen gibt es oft andere Merkmale des Gesichts. Zum Beispiel, wie alt, welche Augenfarbe usw. All dies kann als eine weitere hinzugefügt werden. Signal: Bringen Sie den einzelnen Köpfen bei, diese Daten vorherzusagen. Somit empfängt unser Netzwerk ein vielfältigeres Signal, weshalb es möglicherweise besser ist, die Hauptaufgabe zu lernen.
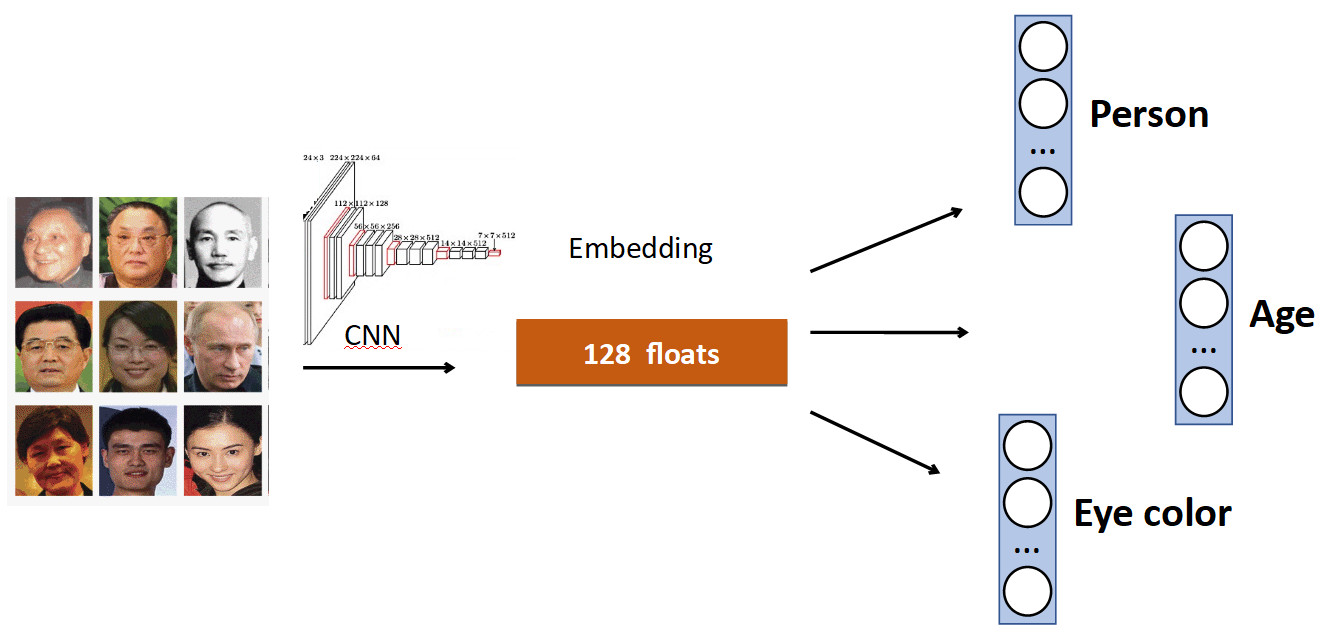
Ein weiteres Beispiel: Warteschlangenerkennung.

Oft gibt es in Datensätzen mit Personen zusätzlich zum Körper eine separate Markierung der Position des Kopfes, die natürlich verwendet werden kann. Daher haben wir dem Netzwerk die Vorhersage des Begrenzungsrahmens der Person und die Vorhersage des Begrenzungsrahmens des Kopfes hinzugefügt und eine Erhöhung der Genauigkeit (mAP) um 0,5% erzielt, was anständig ist. Und vor allem - leistungsfrei, weil Bei der Produktion wird der zusätzliche Kopf „getrennt“.

OCR
Ein komplexerer und interessanterer Fall ist die oben bereits erwähnte OCR. Die Standard-Pipeline ist so.
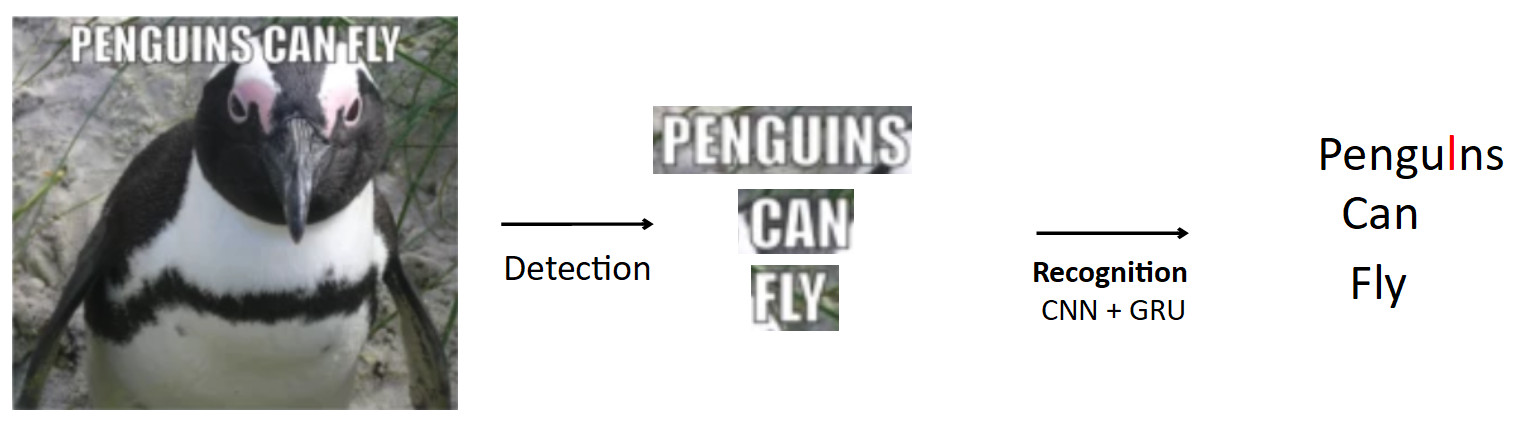
Lassen Sie es ein Plakat mit einem Pinguin geben, der Text ist darauf geschrieben. Mit dem Erkennungsmodell markieren wir diesen Text. Außerdem geben wir diesen Text an die Eingabe des Erkennungsmodells weiter, das den erkannten Text erzeugt. Nehmen wir an, unser Netzwerk ist falsch und anstelle von "i" im Wort "Pinguine" wird "l" vorhergesagt. Dies ist tatsächlich ein sehr häufiges Problem bei OCR, wenn das Netzwerk ähnliche Zeichen verwechselt. Die Frage ist, wie man das vermeidet - Pengulns in Pinguine übersetzen? Wenn eine Person dieses Beispiel betrachtet, ist es für sie offensichtlich, dass dies ein Fehler ist, weil Er kennt die Struktur der Sprache. Daher sollte das Wissen über die Verteilung von Zeichen und Wörtern in der Sprache in das Modell eingebettet werden.
Wir haben dafür ein Ding namens BPE (Byte-Pair-Codierung) verwendet. Dies ist ein Komprimierungsalgorithmus, der in den 90er Jahren allgemein nicht für maschinelles Lernen erfunden wurde, aber jetzt sehr beliebt ist und beim Tiefenlernen verwendet wird. Die Bedeutung des Algorithmus besteht darin, dass häufig vorkommende Teilsequenzen im Text durch neue Zeichen ersetzt werden. Angenommen, wir haben die Zeichenfolge "aaabdaaabac" und möchten eine BPE dafür erhalten. Wir finden, dass das Zeichenpaar "aa" das häufigste in unserem Wort ist. Wir ersetzen es durch ein neues Zeichen "Z", wir erhalten die Zeichenfolge "ZabdZabac". Wir wiederholen die Iteration: Wir sehen, dass ab die häufigste Teilsequenz ist, ersetzen sie durch "Y", wir erhalten die Zeichenfolge "ZYdZYac". Jetzt ist "ZY" die häufigste Folge, wir ersetzen sie durch "X", wir bekommen "XdXac". Daher codieren wir einige statistische Abhängigkeiten bei der Verteilung des Textes. Wenn wir auf ein Wort stoßen, in dem es sehr „seltsame“ (für das Lehrkorps seltene) Folgen gibt, dann ist dieses Wort verdächtig.
aaabdaaabac
ZabdZabac Z=aa
ZY d ZY ac Y=ab
X d X ac X=ZYWie alles zur Anerkennung passt.
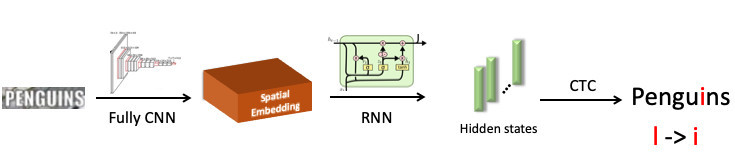
Wir haben das Wort „Pinguin“ hervorgehoben und an das neuronale Faltungsnetzwerk gesendet, das eine räumliche Einbettung erzeugt (ein Vektor fester Länge, zum Beispiel 512). Dieser Vektor codiert räumliche Symbolinformationen. Als nächstes verwenden wir ein Wiederholungsnetzwerk (UPD: Tatsächlich verwenden wir bereits das Transformer-Modell), das einige versteckte Zustände (grüne Balken) ausgibt, in denen jeweils die Wahrscheinlichkeitsverteilung zusammengenäht ist - wobei das Symbol je nach Modell an einer bestimmten Position dargestellt wird. Dann wickeln wir mit CTC-Loss diese Zustände ab und erhalten unsere Vorhersage für das ganze Wort, jedoch mit einem Fehler: L anstelle von i.
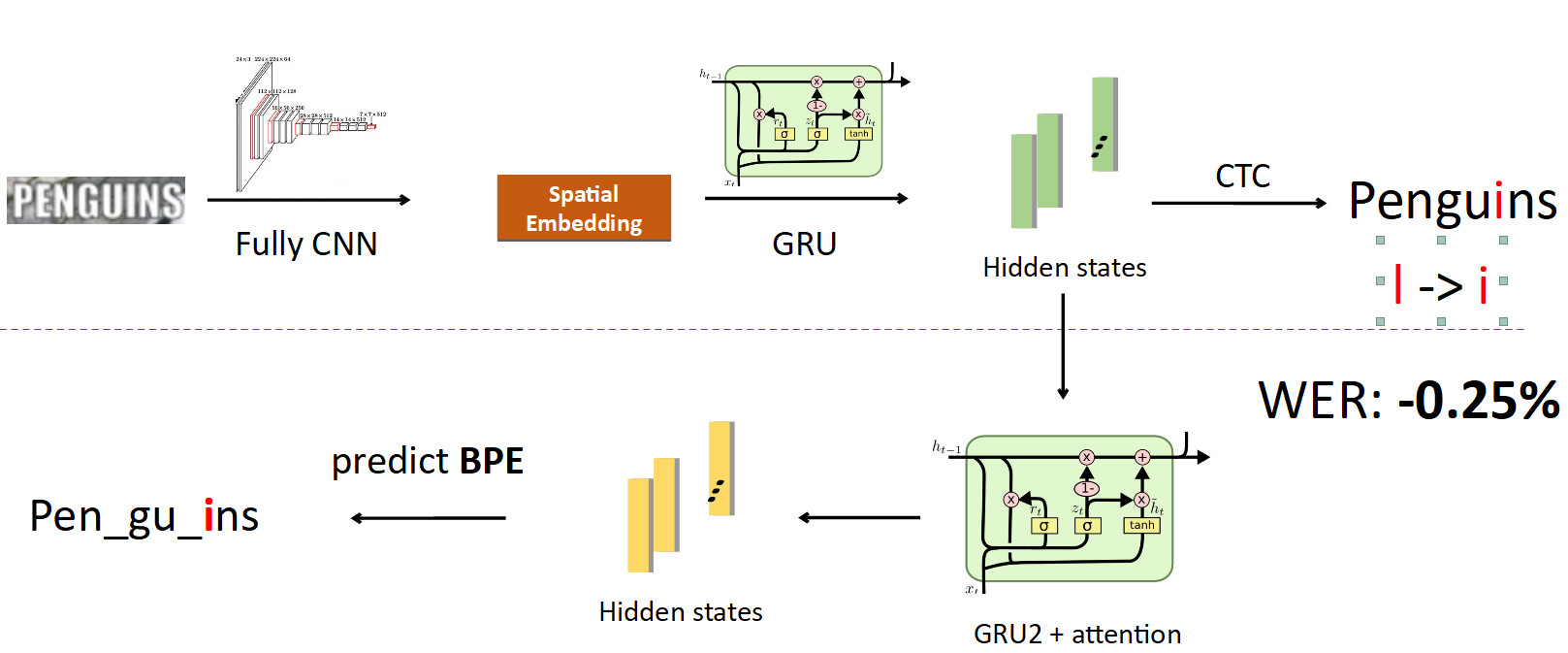
Jetzt BPE in die Pipeline integrieren. Wir wollen nicht nur einzelne Zeichen zu Wörtern vorhersagen, sondern verzweigen uns auch von den Zuständen, in denen Informationen über die Zeichen zusammengenäht sind, und richten ein anderes rekursives Netzwerk darauf ein. sie sagt BPE voraus. Im Fall des oben beschriebenen Fehlers werden 3 BPEs erhalten: "peng", "ul", "ns". Dies unterscheidet sich erheblich von der richtigen Reihenfolge für das Wort Pinguine, dh Stift, Gu, Ins. Wenn Sie dies unter dem Gesichtspunkt des Modelltrainings betrachten, dann hat das Netzwerk bei einer zeichenweisen Vorhersage nur in einem von acht Buchstaben einen Fehler gemacht (12,5% Fehler). und in Bezug auf BPE war sie zu 100% falsch darin, alle 3 BPEs falsch vorherzusagen. Dies ist ein viel größeres Signal für das Netzwerk, dass ein Fehler aufgetreten ist und Sie Ihr Verhalten korrigieren müssen. Als wir dies implementierten, konnten wir Fehler dieser Art beheben und die Wortfehlerrate um 0,25% reduzieren - das ist viel. Dieser zusätzliche Kopf wird bei der Schlussfolgerung entfernt, wodurch seine Rolle im Training erfüllt wird.
FP16
Das Letzte, was ich zum Training sagen wollte, war das RP16. Historisch gesehen geschah dies, dass Netzwerke auf der GPU auf Einheitsgenauigkeit trainiert wurden, d. H. FP32. Dies ist jedoch redundant, insbesondere für Inferenzen, bei denen die halbe Genauigkeit (FP16) ohne Qualitätsverlust ausreicht. Dies ist jedoch beim Training nicht der Fall.
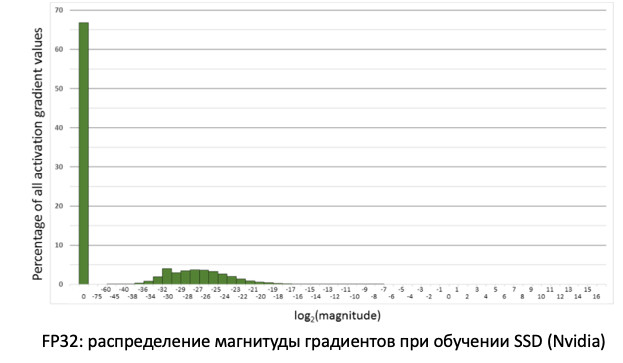
Wenn wir uns die Verteilung der Gradienten ansehen, Informationen, die unsere Gewichte bei der Verbreitung von Fehlern aktualisieren, werden wir feststellen, dass es bei Null einen großen Peak gibt. Und im Allgemeinen sind viele Werte nahe Null. Wenn wir nur alle Gewichte auf FP16 übertragen, stellt sich heraus, dass wir die linke Seite im Bereich von Null (von der roten Linie) abschneiden.
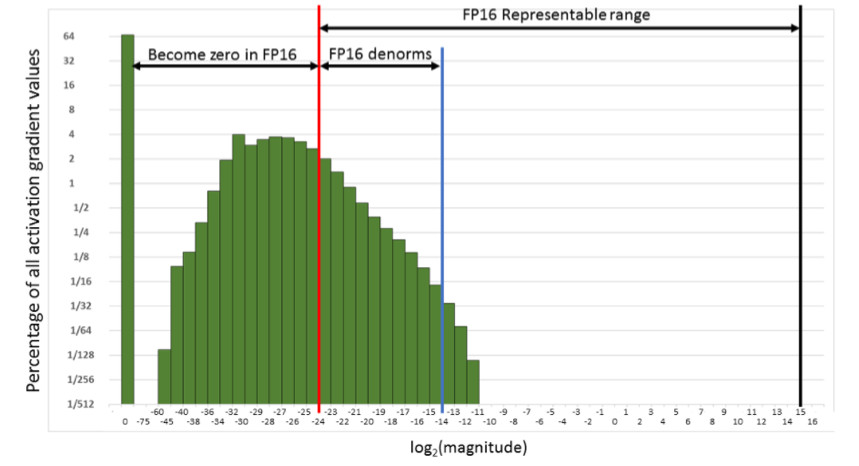
Das heißt, wir werden eine sehr große Anzahl von Verläufen zurücksetzen. Und der richtige Teil im FP16-Arbeitsbereich wird überhaupt nicht verwendet. Wenn Sie die Stirn auf FP16 trainieren, wird sich der Prozess wahrscheinlich zerstreuen (die graue Grafik in der Abbildung unten).
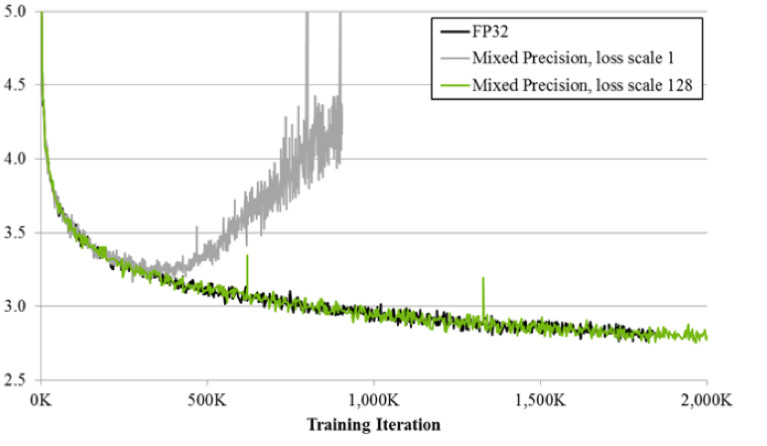
Wenn Sie mit der Technik der gemischten Präzision trainieren, ist das Ergebnis fast identisch mit dem von FP32. Gemischte Präzision implementiert zwei Tricks.
Erstens: Wir multiplizieren den Verlust einfach mit einer Konstanten, z. B. 128. Daher skalieren wir alle Gradienten und verschieben ihre Werte von Null in den Arbeitsbereich von FP16. Zweitens: Wir speichern die Master-Version des FP32-Guthabens, die nur zum Aktualisieren verwendet wird, und bei der Berechnung von Vorwärts- und Rückwärtspassnetzwerken wird nur FP16 verwendet.
Wir verwenden Pytorch, um Netzwerke zu trainieren. NVIDIA hat dafür eine spezielle Baugruppe mit dem sogenannten APEX erstellt, die die oben beschriebene Logik implementiert. Er hat zwei Modi. Die erste ist die automatische gemischte Präzision. Sehen Sie sich den folgenden Code an, um zu sehen, wie einfach die Verwendung ist.

Dem Trainingscode werden buchstäblich zwei Zeilen hinzugefügt, die den Verlust und das Initialisierungsverfahren des Modells und der Optimierer umschließen. Was macht AMP? Er hat alle Funktionen gepatcht. Was genau ist los? Zum Beispiel sieht er, dass es eine Faltungsfunktion gibt, und sie erhält einen Gewinn aus dem RP16. Dann ersetzt er es durch sein eigenes, das zuerst auf FP16 gewirkt wird, und führt dann eine Faltungsoperation durch. AMP erledigt also alle Funktionen, die im Netzwerk verwendet werden können. Für einige ist dies nicht der Fall. Es wird keine Beschleunigung geben. Für die meisten Aufgaben ist diese Methode geeignet.
Zweite Option: FP16-Optimierer für Fans mit vollständiger Kontrolle. Geeignet, wenn Sie selbst angeben möchten, welche Ebenen in FP16 und welche in FP32 enthalten sein sollen. Es gibt jedoch eine Reihe von Einschränkungen und Schwierigkeiten. Es beginnt nicht mit einem halben Tritt (zumindest mussten wir schwitzen, um es zu starten). Auch FP_optimizer funktioniert nur mit Adam und selbst dann nur mit diesem Adam, der sich in APEX befindet (ja, sie haben ihren eigenen Adam im Repository, das eine völlig andere Schnittstelle als Paytorch hat).
Wir haben einen Vergleich beim Lernen auf Tesla T4-Karten durchgeführt.
Bei Inference haben wir die erwartete Beschleunigung zweimal. Im Training sehen wir, dass das Apex-Framework mit einem relativ einfachen FP16 eine Beschleunigung von 20% bietet. Als Ergebnis erhalten wir ein Training, das doppelt so schnell ist und zweimal weniger Speicher verbraucht, und die Qualität des Trainings leidet in keiner Weise. Werbegeschenk.
Folgerung
Weil Da wir PyTorch verwenden, stellt sich dringend die Frage, wie es in der Produktion eingesetzt werden kann.
Es gibt 3 Möglichkeiten, wie es geht (und alle, die wir verwendet haben).
- ONNX -> Caffe2
- ONNX -> TensorRT
- Und in jüngerer Zeit Pytorch C ++
Schauen wir uns jeden an.
ONNX und Caffe2
ONNX erschien vor 1,5 Jahren. Dies ist ein spezielles Framework zum Konvertieren von Modellen zwischen verschiedenen Frameworks. Und Caffe2 ist ein Framework neben Pytorch, die beide auf Facebook entwickelt werden. Historisch gesehen entwickelt sich Pytorch viel schneller als Caffe2. Caffe2 bleibt in seinen Funktionen hinter Pytorch zurück, sodass nicht jedes Modell, das Sie in Pytorch trainiert haben, auf Caffe2 konvertiert werden kann. Oft muss man mit anderen Ebenen neu lernen. In Caffe2 gibt es beispielsweise keine Standardoperation wie Upsampling mit Interpolation des nächsten Nachbarn. Als Ergebnis kamen wir zu dem Schluss, dass wir für jedes Modell ein spezielles Docker-Image eingeführt haben, in dem wir die Framework-Versionen mit Nägeln nageln, um Unstimmigkeiten bei zukünftigen Updates zu vermeiden, sodass wir bei einer erneuten Aktualisierung einer der Versionen keine Zeit mit ihrer Kompatibilität verschwenden . All dies ist nicht sehr praktisch und verlängert den Bereitstellungsprozess.
Tensor rt
Es gibt auch Tensor RT, ein NVIDIA-Framework, das die Netzwerkarchitektur optimiert, um die Inferenz zu beschleunigen. Wir haben unsere Messungen durchgeführt (auf der Tesla T4-Karte).
Wenn Sie sich die Grafiken ansehen, können Sie sehen, dass der Übergang von FP32 zu FP16 auf Pytorch eine zweifache Beschleunigung und TensorRT gleichzeitig eine vierfache Beschleunigung ergibt. Ein sehr bedeutender Unterschied. Wir haben es auf Tesla T4 getestet, das Tensorkerne hat, die nur sehr gut FP16-Berechnungen verwenden, was in TensorRT offensichtlich hervorragend ist. Wenn also ein hoch geladenes Modell auf Dutzenden von Grafikkarten ausgeführt wird, gibt es alle Motivatoren, Tensor RT auszuprobieren.
Bei der Arbeit mit TensorRT treten jedoch noch mehr Schmerzen auf als bei Caffe2: Schichten werden darin noch weniger unterstützt. Leider müssen wir jedes Mal, wenn wir dieses Framework verwenden, ein wenig leiden, um das Modell zu konvertieren. Bei stark belasteten Modellen müssen Sie dies jedoch tun. ;) Ich stelle fest, dass auf Karten ohne Tensorkerne ein derart massiver Anstieg nicht beobachtet wird.
Pytorch C ++
Und der letzte ist Pytorch C ++. Vor sechs Monaten erkannten die Pytorch-Entwickler den Schmerz der
Benutzer ihres Frameworks und veröffentlichten das
TorchScript-Tutorial , mit dem Sie das Python-Modell ohne unnötige Gesten (JIT) in einem statischen Diagramm verfolgen und serialisieren können. Es wurde im Dezember 2018 veröffentlicht, wir haben sofort damit begonnen, haben sofort einige Leistungsfehler entdeckt und mehrere Monate auf die
Korrektur durch
Chintala gewartet . Aber jetzt ist es eine ziemlich stabile Technologie, und wir verwenden sie aktiv für alle Modelle. Das einzige ist der Mangel an Dokumentation, die aktiv ergänzt wird. Natürlich können Sie immer * .h-Dateien anzeigen, aber für Leute, die die Pluspunkte nicht kennen, ist es schwierig. Aber dann gibt es wirklich identische Arbeit mit Python. In C ++ wird j-Code auf einem minimalen Python-Interpreter ausgeführt, der praktisch die Identität von C ++ mit Python garantiert.
Schlussfolgerungen
- Die Erklärung des Problems ist sehr wichtig. Sie müssen mit Produktmanagern über Daten kommunizieren. Bevor Sie mit der Ausführung der Aufgabe beginnen, ist es ratsam, einen vorgefertigten Testsatz zu haben, an dem wir die endgültigen Metriken vor der Implementierungsphase messen.
- Wir bereinigen die Daten selbst mit Hilfe von Clustering. Wir erhalten das Modell für die Quelldaten, bereinigen die Daten mithilfe von CLink-Clustering und wiederholen den Vorgang bis zur Konvergenz.
- Metrisches Lernen: Auch die Klassifizierung hilft. State-of-the-Art - ArcFace, das sich leicht in den Lernprozess integrieren lässt.
- Wenn Sie das Lernen aus einem vorab trainierten Netzwerk übertragen, verwenden Sie Wissensdestillation, damit das Netzwerk die alte Aufgabe nicht vergisst.
- Es ist auch nützlich, mehrere Netzwerkköpfe zu verwenden, die unterschiedliche Signale aus den Daten verwenden, um die Hauptaufgabe zu verbessern.
- Für FP16 müssen Sie die Apex-Assemblys von NVIDIA, Pytorch, verwenden.
- Und schlussfolgernd ist es bequem, Pytorch C ++ zu verwenden.