Am 27. Mai wurde in der Haupthalle der DevOpsConf 2019-Konferenz, die im Rahmen des
RIT ++ 2019- Festivals im Rahmen der Continuous Delivery-Sektion stattfand, der Bericht „werf ist unser Tool für CI / CD in Kubernetes“ veröffentlicht. Es geht um die
Probleme und Herausforderungen, mit denen jeder bei der Bereitstellung auf Kubernetes konfrontiert ist , sowie um die Nuancen, die möglicherweise nicht sofort erkennbar sind. Wir analysieren mögliche Lösungen und zeigen, wie dies im
werf Open Source Tool implementiert wird.
Seit der Show hat unser Dienstprogramm (früher bekannt als dapp) die historische Grenze von
1000 Sternen auf GitHub überschritten - wir hoffen, dass die wachsende Community seiner Benutzer das Leben vieler DevOps-Ingenieure vereinfachen wird.

Deshalb präsentieren wir das
Video mit dem Bericht (~ 47 Minuten, viel informativer als der Artikel) und dem Hauptauszug daraus in Textform. Lass uns gehen!
Code-Lieferung in Kubernetes
Es geht nicht mehr um werf, sondern um CI / CD in Kubernetes, was bedeutet, dass unsere Software in Docker-Containern verpackt ist
(darüber habe ich im Bericht 2016 gesprochen ) , und K8s werden verwendet, um sie in der Produktion zu starten
(darüber - im Jahr 2017 ) .
Wie sieht die Lieferung von Kubernetes aus?
- Es gibt ein Git-Repository mit Code und Anweisungen zum Erstellen. Die Anwendung wird in ein Docker-Image kompiliert und in der Docker-Registrierung veröffentlicht.
- Im selben Repository finden Sie Anweisungen zum Bereitstellen und Ausführen der Anwendung. In der Bereitstellungsphase werden diese Anweisungen an Kubernetes gesendet, das das gewünschte Image von der Registrierung empfängt und startet.
- Außerdem gibt es normalerweise Tests. Einige davon können beim Veröffentlichen eines Bildes ausgeführt werden. Sie können auch (nach denselben Anweisungen) eine Kopie der Anwendung (in einem separaten K8s-Namespace oder in einem separaten Cluster) bereitstellen und dort Tests ausführen.
- Schließlich benötigen wir ein CI-System, das Ereignisse von Git (oder Schaltflächenklicks) empfängt und alle angegebenen Phasen aufruft: Erstellen, Veröffentlichen, Bereitstellen, Testen.

Hier gibt es einige wichtige Hinweise:
- Da wir über eine unveränderliche Infrastruktur verfügen, muss das Image der Anwendung, die in allen Phasen (Staging, Produktion usw.) verwendet wird, eins sein . Ich habe hier mehr darüber und mit Beispielen gesprochen.
- Da wir den IaC-Ansatz ( Infrastructure as Code) verfolgen , sollten der Anwendungscode und die Anweisungen zum Erstellen und Ausführen in einem Repository liegen . Weitere Informationen hierzu finden Sie im selben Bericht .
- Normalerweise sehen wir die Lieferkette (Lieferung) folgendermaßen : Die Anwendung wurde zusammengestellt, getestet, freigegeben (Freigabestufe) und das ist alles - die Lieferung ist erfolgt. In Wirklichkeit erhält der Benutzer jedoch das, was Sie eingeführt haben, nicht, als Sie es an die Produktion geliefert haben, sondern als er dorthin gehen konnte und diese Produktion funktionierte. Daher glaube ich, dass die Lieferkette erst in der Betriebsphase (Lauf) endet, genauer gesagt, selbst in dem Moment, in dem der Code aus der Produktion entfernt wurde (indem er durch einen neuen ersetzt wurde).
Kehren wir zu dem oben angegebenen Kubernetes-Lieferschema zurück: Es wurde nicht nur von uns erfunden, sondern buchstäblich von allen, die sich mit diesem Problem befasst haben. Im Wesentlichen heißt dieses Muster jetzt GitOps
(mehr über den Begriff und die Ideen dahinter finden Sie hier ) . Schauen wir uns die Phasen des Schemas an.
Bühne bauen
Es scheint, dass Sie 2019 über die Zusammenstellung von Docker-Images berichten können, wenn jeder weiß, wie man
docker build Dateien schreibt und
docker build Builds ausführt? Hier sind die Nuancen, auf die ich achten möchte:
- Das Gewicht des Bildes ist wichtig. Verwenden Sie daher mehrstufig , um nur die Anwendung zu belassen, die wirklich für das Bild benötigt wird.
- Die Anzahl der Ebenen sollte minimiert werden, indem die Ketten der
RUN Befehle innerhalb der Bedeutung kombiniert werden. - Dies trägt jedoch zu den Debugging- Problemen bei, da Sie beim Absturz der Assembly den erforderlichen Befehl aus der Kette finden müssen, die das Problem verursacht hat.
- Die Build-Geschwindigkeit ist wichtig, da wir Änderungen schnell einführen und das Ergebnis betrachten möchten. Zum Beispiel möchte ich die Abhängigkeiten in den Sprachbibliotheken nicht bei jedem Build der Anwendung neu zusammenstellen.
- Oft werden viele Bilder aus einem Git-Repository benötigt, die durch eine Reihe von Docker-Dateien (oder benannten Stufen in einer Datei) und ein Bash-Skript mit ihrer sequentiellen Assemblierung gelöst werden können.
Es war nur die Spitze des Eisbergs, der sich alle gegenübersehen. Es gibt aber noch andere Probleme, insbesondere:
- Oft müssen wir in der Assembly-Phase etwas bereitstellen (z. B. das Ergebnis eines Befehls wie apt in einem Verzeichnis eines Drittanbieters zwischenspeichern).
- Wir wollen Ansible, anstatt auf die Shell zu schreiben.
- Wir möchten ohne Docker erstellen (warum benötigen wir eine zusätzliche virtuelle Maschine, in der Sie alles dafür konfigurieren müssen, wenn bereits ein Kubernetes-Cluster vorhanden ist, in dem Sie Container ausführen können?).
- Parallele Assembly , die auf unterschiedliche Weise verstanden werden kann: verschiedene Befehle aus der Docker-Datei (wenn mehrstufig verwendet wird), mehrere Commits eines Repositorys, mehrere Docker-Dateien.
- Verteilte Montage : Wir wollen etwas in Hülsen sammeln, die „kurzlebig“ sind, weil Ihr Cache verschwindet, was bedeutet, dass er irgendwo separat gespeichert werden muss.
- Schließlich nannte ich den Höhepunkt der Wünsche Automagie: Es wäre ideal, in das Repository zu gehen, ein Team einzugeben und ein fertiges Bild zu erhalten, das mit dem Verständnis zusammengestellt ist, wie und was richtig zu tun ist. Ich persönlich bin mir jedoch nicht sicher, ob alle Nuancen auf diese Weise vorhergesehen werden können.
Und hier sind die Projekte:
- moby / buildkit - ein Builder der Firma Docker Inc (bereits in die aktuellen Versionen von Docker integriert), der versucht, all diese Probleme zu lösen;
- kaniko - ein Sammler von Google, mit dem Sie ohne Docker bauen können;
- Buildpacks.io - ein Versuch von CNCF, Auto- Magie zu machen, und insbesondere eine interessante Lösung mit Rebase für Ebenen;
- und eine Reihe anderer Dienstprogramme wie Buildah , Genuinetools / Img ...
... und sehen, wie viele Sterne sie auf GitHub haben. Das heißt, einerseits ist und kann
docker build etwas tun, aber in Wirklichkeit ist das
Problem nicht vollständig gelöst - dies wird durch die parallele Entwicklung alternativer Builder belegt, von denen jeder einige der Probleme löst.
Werf einbauen
Also kamen wir zu
werf (früher bekannt als dapp) - dem Open Source-Dienstprogramm von Flant, das wir seit vielen Jahren betreiben. Alles begann vor ungefähr 5 Jahren mit Bash-Skripten, die die Zusammenstellung von Dockerfiles optimieren. In den letzten 3 Jahren wurde die vollständige Entwicklung im Rahmen eines Projekts mit einem eigenen Git-Repository fortgesetzt
(zuerst in Ruby, dann in Go umgeschrieben und gleichzeitig umbenannt) . Welche Build-Probleme werden in werf behoben?

Die blau schattierten Probleme wurden bereits implementiert, die parallele Montage wurde auf demselben Host durchgeführt, und wir planen, die gelben Fragen bis Ende des Sommers zu beantworten.
Stadium der Veröffentlichung in der Registrierung (veröffentlichen)
Wir haben
docker push eingegeben ... - Was kann beim Hochladen eines Bildes in die Registrierung schwierig sein? Und dann stellt sich die Frage: "Welches Tag soll das Bild setzen?"
Dies liegt daran, dass wir
Gitflow (oder eine andere Git-Strategie) und Kubernetes haben und die Branche sich dafür einsetzt, dass das, was in Kubernetes passiert, dem folgt, was in Git gemacht wird. Git ist unsere einzige Quelle der Wahrheit.
Was ist so kompliziert?
Stellen Sie die Reproduzierbarkeit sicher : von einem Commit in Git, das von Natur aus
unveränderlich ist , bis zu einem Docker-Image, das
unverändert bleiben muss.
Für uns ist es auch wichtig
, den Ursprung zu
bestimmen , da wir verstehen möchten, aus welchem Commit die in Kubernetes gestartete Anwendung erstellt wurde (dann können wir Unterschiede und ähnliche Dinge tun).
Markierungsstrategien
Das erste ist ein einfaches
Git-Tag . Wir haben eine Registrierung mit einem Bild als
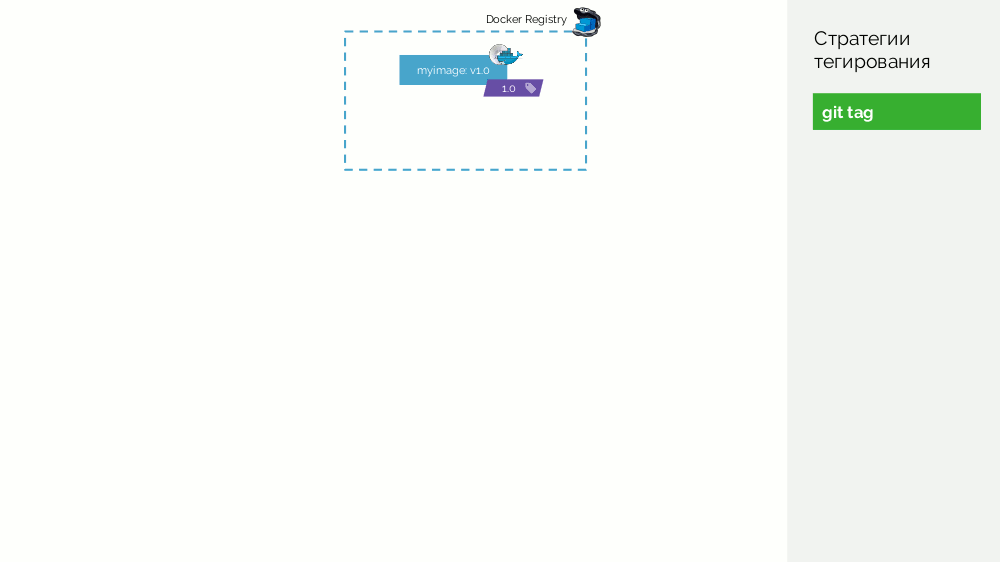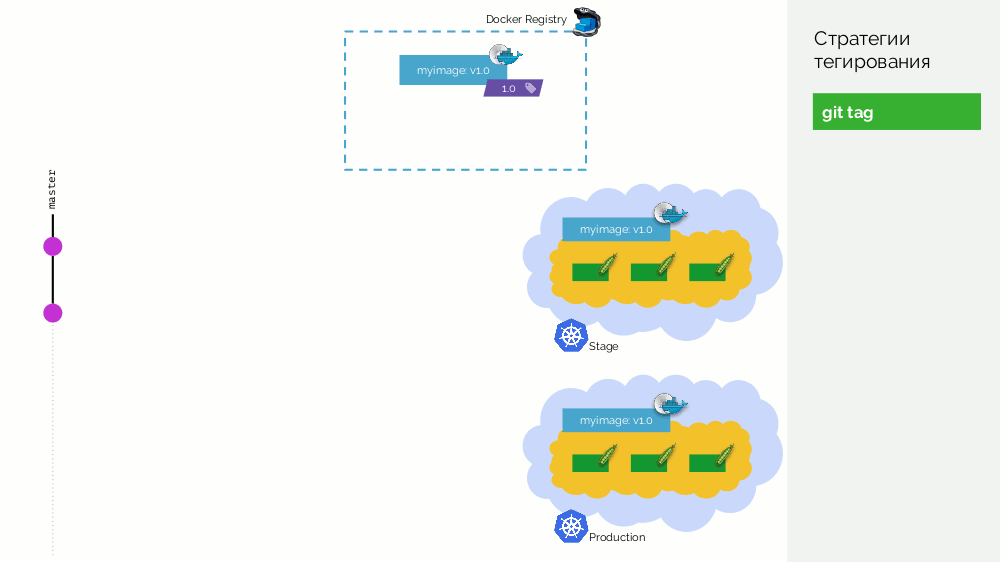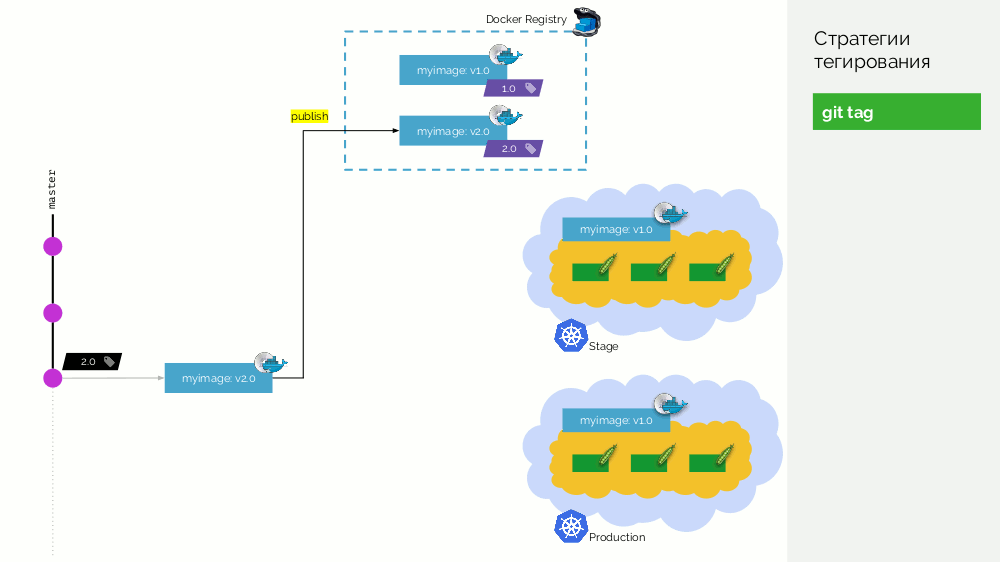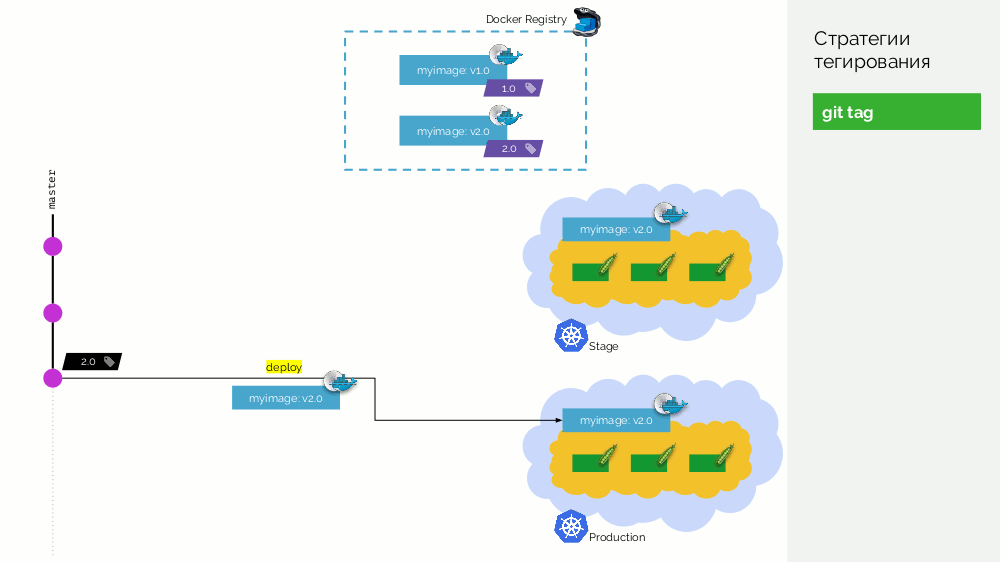
1.0 . Kubernetes hat Bühne und Produktion, wo dieses Bild gepumpt wird. In Git machen wir Commits und setzen irgendwann das Tag
2.0 . Wir sammeln es gemäß den Anweisungen aus dem Repository und legen es mit dem
2.0 Tag in der Registrierung ab. Wir rollen es auf der Bühne aus und wenn alles in Ordnung ist, dann in der Produktion.
Das Problem bei diesem Ansatz ist, dass wir das Tag zuerst festgelegt und erst dann getestet und ausgerollt haben. Warum? Erstens ist dies einfach unlogisch: Wir geben eine Softwareversion heraus, die wir noch nicht einmal getestet haben (wir können nichts anderes tun, da Sie zur Überprüfung ein Tag einfügen müssen). Zweitens ist dieser Weg nicht mit Gitflow kompatibel.
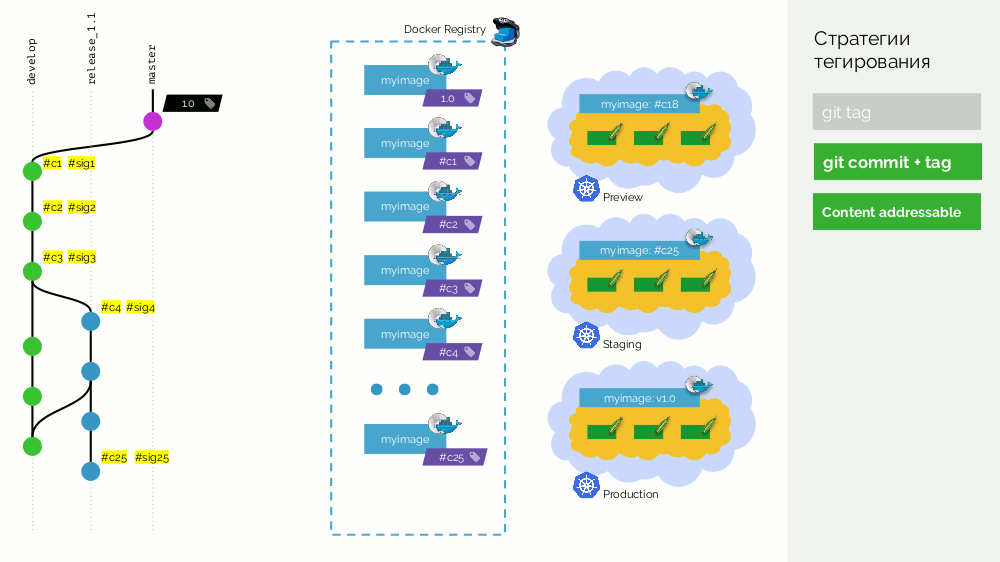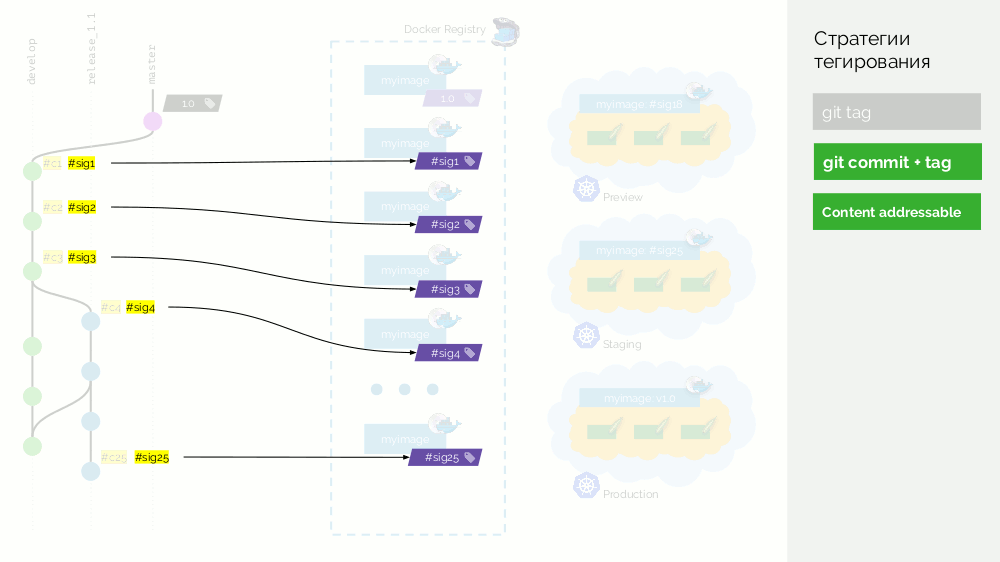
Die zweite Option ist
git commit + tag . Im Hauptzweig befindet sich ein
1.0 Tag. für ihn in der Registrierung - ein Image, das für die Produktion bereitgestellt wird. Darüber hinaus verfügt der Kubernetes-Cluster über Vorschau- und Staging-Schleifen. Weiter folgen wir Gitflow: Im Hauptzweig für die Entwicklung
develop wir neue Funktionen, aufgrund derer ein Commit mit der Kennung
#c1 . Wir sammeln es und veröffentlichen es in der Registrierung unter Verwendung dieser Kennung (
#c1 ). Wir rollen die Vorschau mit derselben Kennung aus. Wir machen dasselbe mit den Commits
#c2 und
#c3 .
Als wir feststellten, dass es genügend Funktionen gibt, beginnen wir, alles zu stabilisieren. Erstellen Sie in Git den Zweig
release_1.1 (basierend auf
#c3 von
develop ). Das Sammeln dieser Version ist nicht erforderlich, da Dies wurde im vorherigen Schritt durchgeführt. Daher können wir es einfach auf die Inszenierung ausrollen. Wir beheben Fehler in
#c4 und rollen sie ebenfalls auf Staging aus. Gleichzeitig wird derzeit eine
develop , bei der regelmäßig Änderungen gegenüber
release_1.1 werden. Irgendwann bekommen wir ein Commit und werden zum Staging Commit herausgepumpt, mit dem wir zufrieden sind (
#c25 ).
Dann führen wir eine Zusammenführung (mit schnellem Vorlauf) des Release-Zweigs (
release_1.1 ) im Master durch. Wir haben diesem Commit ein Tag mit der neuen Version (
1.1 ) hinzugefügt. Dieses Bild ist jedoch bereits in der Registrierung zusammengestellt. Um es nicht erneut zu erfassen, fügen wir dem vorhandenen Bild nur ein zweites Tag hinzu (jetzt enthält es die Tags
#c25 und
1.1 in der Registrierung). Danach rollen wir es in die Produktion aus.
Es gibt einen Nachteil, dass ein Bild (
#c25 ) beim Staging
#c25 wird und ein anderes (
1.1 ) bei der Produktion
#c25 , aber wir wissen, dass es sich "physisch" um dasselbe Bild aus der Registrierung handelt.
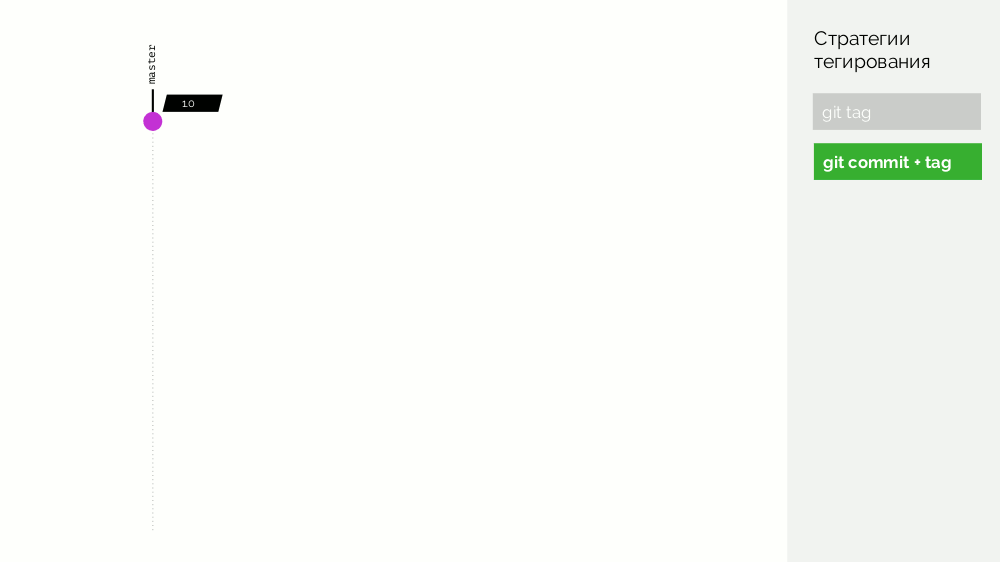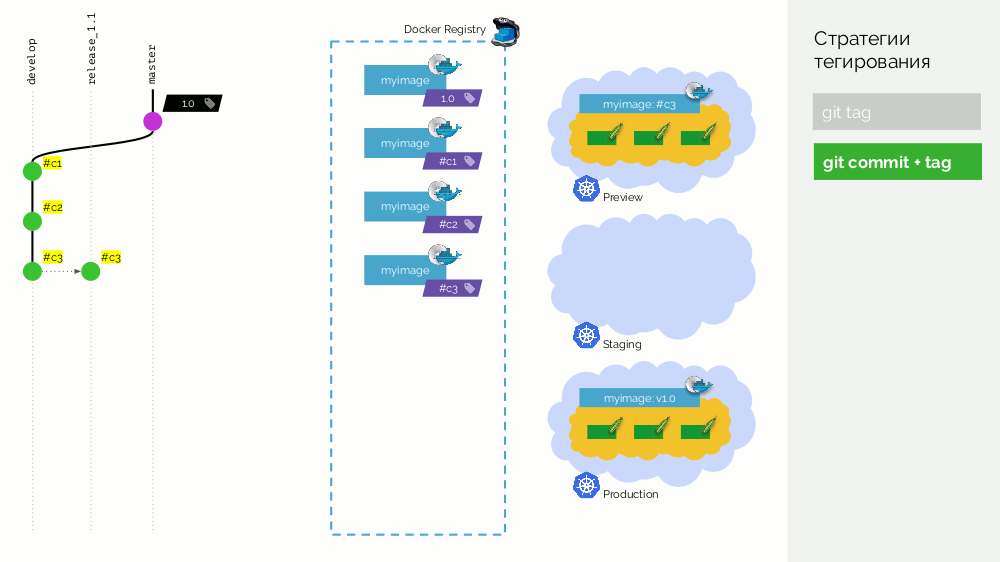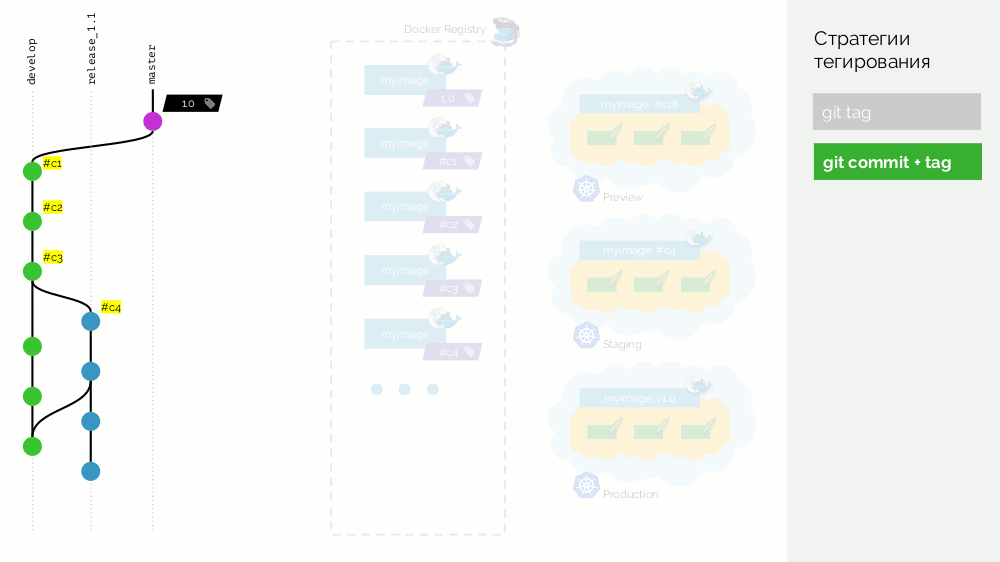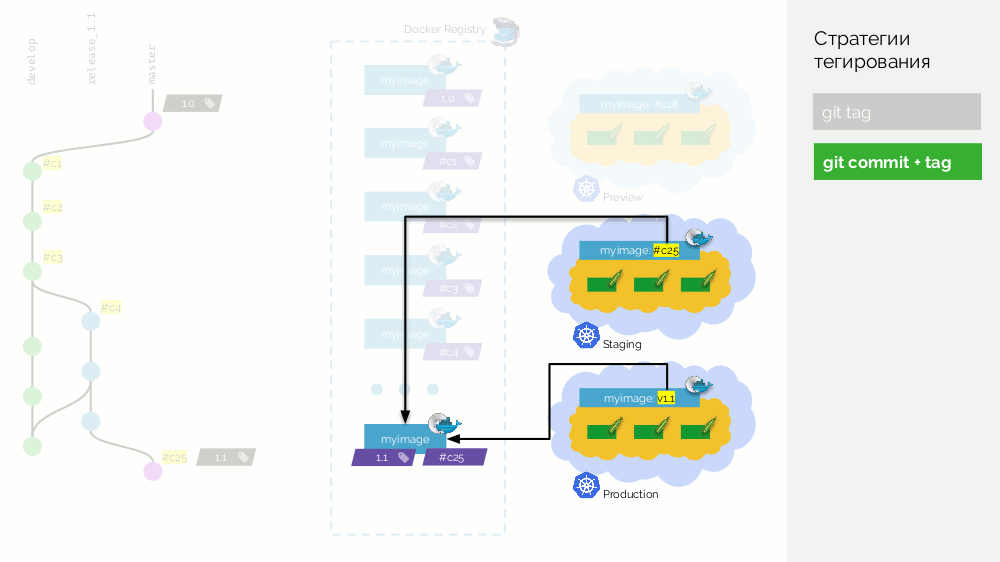
Das eigentliche Minus ist, dass es keine Unterstützung für Merge Commit'ov gibt. Sie müssen einen schnellen Vorlauf durchführen.
Sie können noch weiter gehen und den Trick machen ... Betrachten Sie ein Beispiel für eine einfache Docker-Datei:
FROM ruby:2.3 as assets RUN mkdir -p /app WORKDIR /app COPY . ./ RUN gem install bundler && bundle install RUN bundle exec rake assets:precompile CMD bundle exec puma -C config/puma.rb FROM nginx:alpine COPY --from=assets /app/public /usr/share/nginx/www/public
Wir erstellen daraus eine Datei nach diesem Prinzip, das wir nehmen:
- SHA256 aus Kennungen der verwendeten Bilder (
ruby:2.3 und nginx:alpine ), die Prüfsummen ihres Inhalts sind; - alle Teams (
RUN , CMD usw.); - SHA256 aus Dateien, die hinzugefügt wurden.
... und nehmen Sie die Prüfsumme (wieder SHA256) aus einer solchen Datei. Dies ist die
Signatur von allem, was den Inhalt eines Docker-Images definiert.
 Kehren wir
Kehren wir zum Schema zurück und verwenden
anstelle von Commits solche Signaturen , d. H. Kennzeichnen Sie Bilder mit Signaturen.
Wenn Sie beispielsweise Änderungen von der Version zum Master zusammenführen müssen, können Sie ein echtes Zusammenführungs-Commit durchführen: Es hat eine andere Kennung, aber dieselbe Signatur. Mit der gleichen Kennung werden wir das Bild auch in der Produktion ausrollen.
Der Nachteil ist, dass jetzt nicht mehr festgestellt werden kann, welche Art von Commit in die Produktion gepumpt wurde - Prüfsummen funktionieren nur in eine Richtung. Dieses Problem wird durch eine zusätzliche Ebene mit Metadaten gelöst - mehr dazu später.
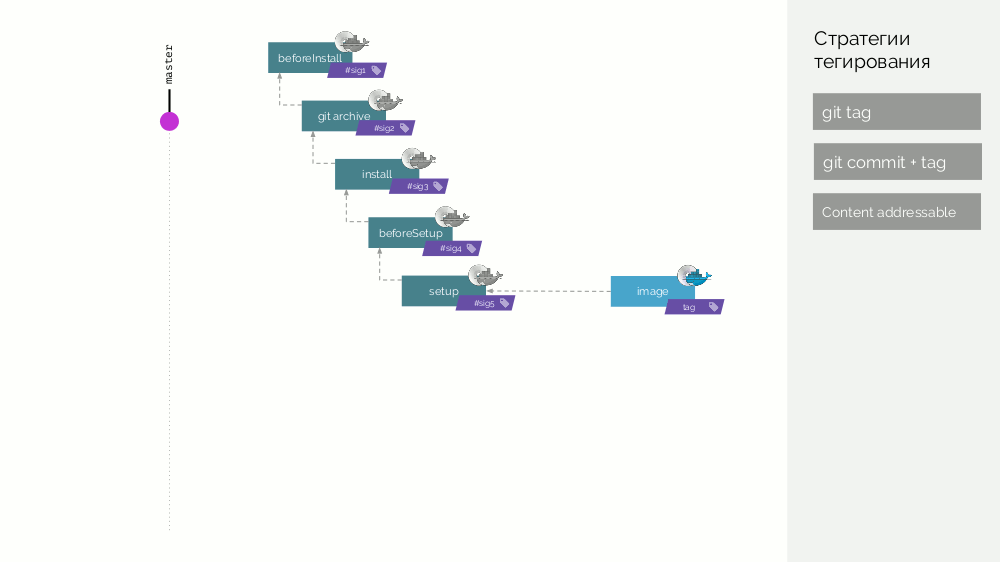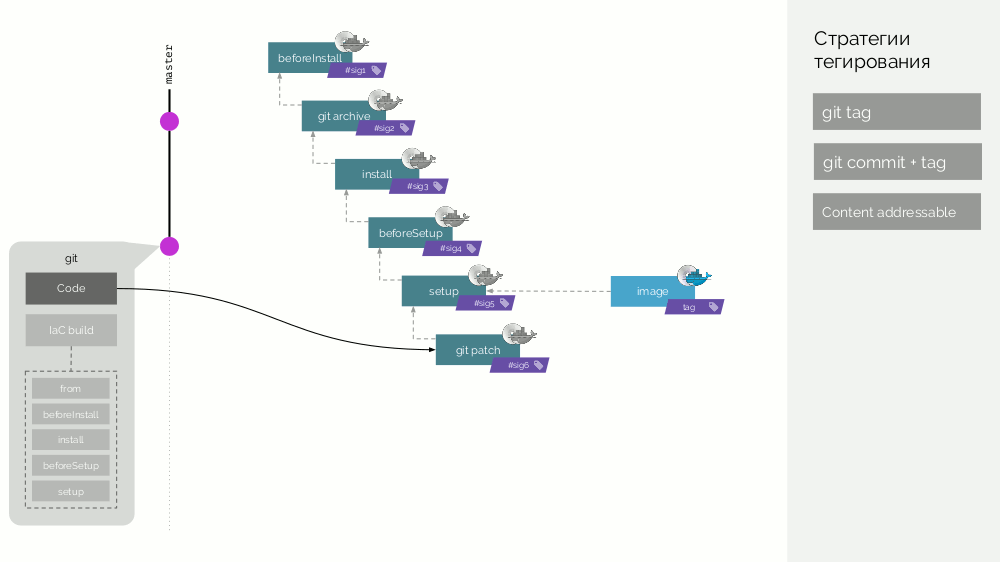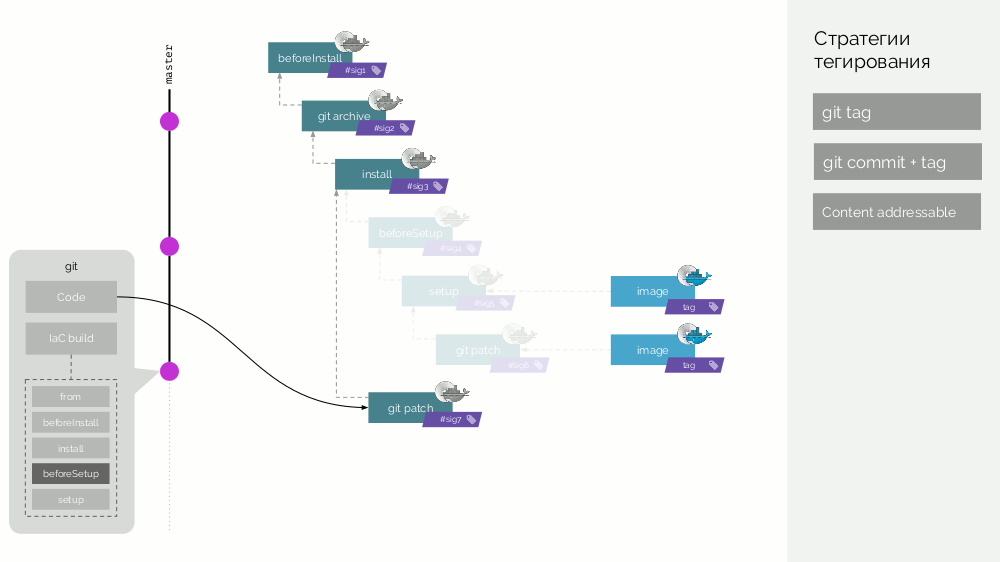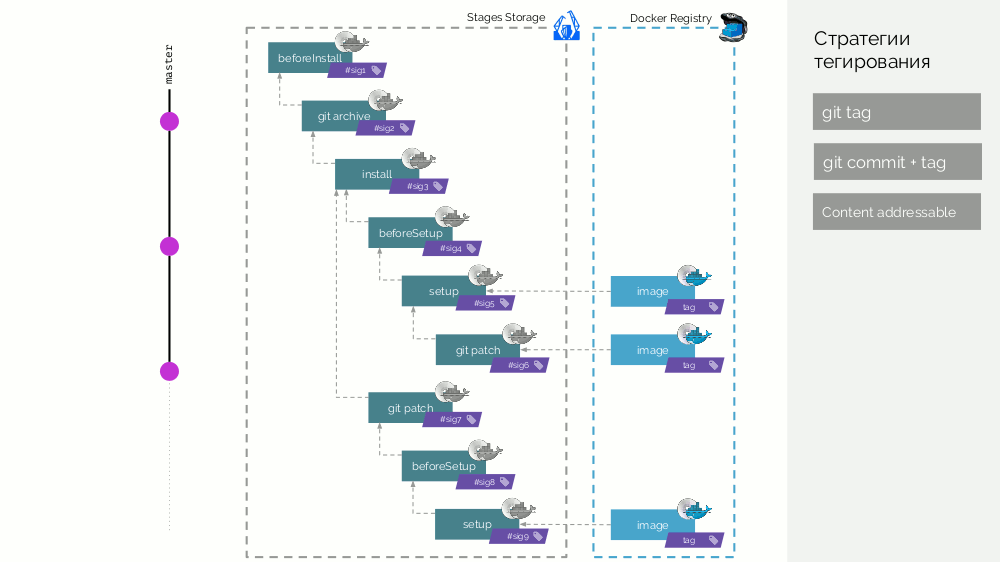
Tagging in werf
In werf sind wir noch weiter gegangen und bereiten uns darauf vor, eine verteilte Assembly mit einem Cache zu erstellen, der nicht auf demselben Computer gespeichert ist ... Wir haben also zwei Arten von Docker-Images, die wir
Stage und
Image nennen .
Das werf Git-Repository speichert spezifische Build-Anweisungen, die die verschiedenen Phasen des Builds beschreiben (
beforeInstall ,
install ,
beforeSetup ,
setup ). Wir sammeln das Bild der ersten Stufe mit einer Signatur, die als Prüfsumme der ersten Schritte definiert ist. Dann fügen wir den Quellcode hinzu, für das neue Bühnenbild betrachten wir seine Prüfsumme ... Diese Operationen werden für alle Stufen wiederholt, wodurch wir eine Reihe von Bühnenbildern erhalten. Dann machen wir das endgültige Bild-Bild, das auch Metadaten über seinen Ursprung enthält. Und wir markieren dieses Bild auf verschiedene Arten (Details später).

Lassen Sie danach ein neues Commit erscheinen, in dem nur der Anwendungscode geändert wird. Was wird passieren? Für Codeänderungen wird ein Patch erstellt und ein neues Bühnenbild erstellt. Seine Signatur wird als Prüfsumme des alten Bühnenbildes und des neuen Patches definiert. Aus diesem Bild wird ein neues endgültiges Bildbild erzeugt. Ein ähnliches Verhalten tritt bei Änderungen in anderen Phasen auf.
Bühnenbilder sind somit ein Cache, der verteilt verteilt werden kann, und bereits daraus erstellte Bildbilder werden in die Docker-Registrierung geladen.
Registry-Reinigung
Hier geht es nicht darum, Ebenen zu löschen, die nach gelöschten Tags hängen bleiben. Dies ist eine Standardfunktion der Docker-Registrierung. Dies ist eine Situation, in der sich viele Docker-Tags ansammeln und wir verstehen, dass wir einige davon nicht mehr benötigen und sie Platz beanspruchen (und / oder wir dafür bezahlen).
Was sind die Reinigungsstrategien?
- Sie können einfach nichts reinigen . Manchmal ist es wirklich einfacher, ein wenig für den zusätzlichen Platz zu bezahlen, als einen riesigen Ball mit Tags zu entwirren. Dies funktioniert aber nur bis zu einem bestimmten Punkt.
- Vollständiger Reset . Wenn Sie alle Bilder löschen und nur die relevanten im CI-System neu erstellen, kann ein Problem auftreten. Wenn der Container bei der Produktion neu gestartet wird, wird ein neues Image für ihn geladen - eines, das noch von niemandem getestet wurde. Dies tötet die Idee einer unveränderlichen Infrastruktur.
- Blaugrün . Eine Registrierung begann zu überlaufen - Bilder wurden in eine andere geladen. Das gleiche Problem wie bei der vorherigen Methode: Ab wann können Sie die Registrierung bereinigen, die übergelaufen ist?
- Mit der Zeit . Alle Bilder löschen, die älter als 1 Monat sind? Aber es wird sicher einen Dienst geben, der seit einem Monat nicht mehr aktualisiert wurde ...
- Manuell bestimmen, was bereits gelöscht werden kann.
Es gibt zwei wirklich praktikable Optionen: Nicht reinigen oder eine Kombination aus Blaugrün + manuell. Im letzteren Fall handelt es sich um Folgendes: Wenn Sie verstehen, dass es Zeit ist, die Registrierung zu bereinigen, erstellen Sie eine neue und fügen Sie beispielsweise für einen Monat alle neuen Bilder hinzu. Überprüfen Sie einen Monat später, welche Pods in Kubernetes noch die alte Registrierung verwenden, und übertragen Sie sie auch in die neue Registrierung.
Wo sind wir zu
werf gegangen ? Wir sammeln:
- Git-Kopf: alle Tags, alle Zweige - vorausgesetzt, dass alles, was in Git getestet wird, in den Bildern benötigt wird (und wenn nicht, müssen wir es im Git selbst löschen);
- alle Pods, die jetzt in Kubernetes heruntergeladen werden;
- alte ReplicaSets (etwas, das kürzlich herausgepumpt wurde) sowie wir planen, Helm-Releases zu scannen und dort die neuesten Bilder auszuwählen.
... und wir erstellen eine Whitelist aus diesem Set - eine Liste von Bildern, die wir nicht löschen werden. Wir säubern alles andere, danach finden wir die verwaisten Bühnenbilder und löschen sie auch.
Bereitstellungsphase (Bereitstellung)
Robuste Deklarativität
Der erste Punkt, auf den ich in der Bereitstellung aufmerksam machen möchte, ist die Einführung der deklarativ deklarierten aktualisierten Ressourcenkonfiguration. Das ursprüngliche YAML-Dokument, das die Kubernetes-Ressourcen beschreibt, unterscheidet sich immer stark von dem Ergebnis, das tatsächlich im Cluster funktioniert. Weil Kubernetes die Konfiguration erweitert:
- Bezeichner
- Serviceinformationen;
- viele Standardwerte;
- Abschnitt mit aktuellem Status;
- Änderungen, die im Rahmen des Zulassungs-Webhooks vorgenommen wurden;
- das Ergebnis der Arbeit verschiedener Controller (und Scheduler).
Wenn eine neue Konfiguration einer Ressource (
neu ) angezeigt wird, können wir daher nicht einfach die aktuelle "Live" -Konfiguration (
Live ) übernehmen und damit überschreiben. Dazu müssen wir
new mit der zuletzt angewendeten (
zuletzt angewendeten ) Konfiguration vergleichen und den resultierenden Patch
live übertragen .
Dieser Ansatz wird als
2-Wege-Zusammenführung bezeichnet . Es wird zum Beispiel in Helm verwendet.
Es gibt auch eine
3-Wege-Zusammenführung , die sich darin unterscheidet:
- Beim Vergleich von zuletzt angewendet und neu sehen wir uns an, was entfernt wurde.
- Beim Vergleich von Neuem und Live sehen wir, was hinzugefügt oder geändert wurde.
- Wende den zusammengefassten Patch auf live an .
Wir stellen mehr als 1000 Anwendungen mit Helm bereit, sodass wir tatsächlich mit einer 2-Wege-Zusammenführung leben. Er hat jedoch eine Reihe von Problemen, die wir mit unseren Patches gelöst haben, die Helm helfen, normal zu arbeiten.
Aktueller Rollout-Status
Nach dem nächsten Ereignis hat unser CI-System eine neue Konfiguration für Kubernetes generiert und diese mit Helm oder
kubectl apply an den Cluster
kubectl apply . Als nächstes findet die bereits beschriebene N-Wege-Zusammenführung statt, zu der die Kubernetes-API das CI-System genehmigt und dieses auf seinen Benutzer reagiert.

Es gibt jedoch ein großes Problem: Eine
erfolgreiche Anwendung bedeutet schließlich keinen erfolgreichen Rollout . Wenn Kubernetes versteht, welche Änderungen anzuwenden sind, wendet er sie an - wir wissen immer noch nicht, wie das Ergebnis aussehen wird. Das Aktualisieren und Neustarten von Pods im Frontend kann beispielsweise erfolgreich sein, nicht jedoch im Backend, und wir erhalten verschiedene Versionen der ausgeführten Anwendungsabbilder.
Um alles richtig zu machen, entsteht in diesem Schema ein zusätzlicher Link - ein spezieller Tracker, der Statusinformationen von der Kubernetes-API empfängt und zur weiteren Analyse des tatsächlichen Zustands der Dinge überträgt. Wir haben eine Open Source-Bibliothek auf Go -
kubedog erstellt (siehe Ankündigung hier ) - die dieses Problem löst und in werf integriert ist.
Das Verhalten dieses Trackers auf werf-Ebene wird mithilfe von Anmerkungen konfiguriert, die in Deployments oder StatefulSets eingefügt werden. Die Hauptanmerkung
fail-mode versteht die folgenden Bedeutungen:
IgnoreAndContinueDeployProcess - Ignorieren Sie IgnoreAndContinueDeployProcess Probleme dieser Komponente und setzen Sie die Bereitstellung fort.FailWholeDeployProcessImmediately - Ein Fehler in dieser Komponente stoppt den Bereitstellungsprozess.HopeUntilEndOfDeployProcess - Wir hoffen, dass diese Komponente bis zum Ende der Bereitstellung funktioniert.
Beispiel: Eine Kombination aus Ressourcen und Annotationswerten im Fehlermodus:

Bei der ersten Bereitstellung ist die Datenbank (MongoDB) möglicherweise noch nicht bereit. Die Bereitstellung stürzt ab. Sie können jedoch warten, bis der Start beginnt und die Bereitstellung weiterhin abgeschlossen ist.
Es gibt zwei weitere Anmerkungen für kubedog in werf:
failures-allowed-per-replica - die Anzahl der erlaubten Drops pro Replikat;show-logs-until till - Passt den Moment an, bis werf (in stdout) Protokolle aller Pods anzeigt, die ausgerollt werden. Standardmäßig ist dies PodIsReady (um Nachrichten zu ignorieren, die wir kaum benötigen, wenn Datenverkehr auf dem Pod eintrifft). Die Werte ControllerIsReady und EndOfDeploy ebenfalls EndOfDeploy .
Was wollen wir noch von der Bereitstellung?
Zusätzlich zu den beiden bereits beschriebenen Punkten möchten wir:
- Protokolle zu sehen - und nur notwendig, aber nicht alles;
- Verfolgen Sie den Fortschritt , denn wenn ein Job mehrere Minuten lang "still" hängt, ist es wichtig zu verstehen, was dort passiert.
- Führen Sie ein automatisches Rollback durch, falls ein Fehler aufgetreten ist (und daher ist es wichtig, den tatsächlichen Status der Bereitstellung zu kennen). Der Rollout muss atomar sein: Entweder geht er bis zum Ende oder alles kehrt in seinen vorherigen Zustand zurück.
Zusammenfassung
Als Unternehmen
reichen es für uns aus, alle beschriebenen Nuancen in verschiedenen Phasen der Bereitstellung (Erstellen, Veröffentlichen, Bereitstellen) zu implementieren, das CI-System und das
werf- Dienstprogramm.
Anstelle einer Schlussfolgerung:

Mit Hilfe von werf haben wir gute Fortschritte bei der Lösung einer Vielzahl von Problemen der DevOps-Ingenieure erzielt und werden uns freuen, wenn die breitere Community dieses Dienstprogramm zumindest in der Praxis ausprobiert. Gemeinsam ein gutes Ergebnis zu erzielen, wird einfacher.
Videos und Folien
Video von der Aufführung (~ 47 Minuten):
Präsentation des Berichts:
PS
Andere Kubernetes-Berichte in unserem Blog: