Hinweis perev. : Die Autorin dieses Materials ist Cindy Sridharan, eine Ingenieurin von imgix, die an der Entwicklung von APIs und insbesondere am Testen von Microservices beteiligt ist. In diesem Artikel teilt sie ihre detaillierte Vision von tatsächlichen Problemen im Bereich der verteilten Rückverfolgung, wo es ihrer Meinung nach an wirklich wirksamen Werkzeugen zur Lösung dringender Probleme mangelt. [Die Abbildung stammt aus einem anderen Material über verteilte Rückverfolgung.]
[Die Abbildung stammt aus einem anderen Material über verteilte Rückverfolgung.]Es wird angenommen, dass
verteiltes Tracing schwierig zu implementieren ist und die Rendite
bestenfalls zweifelhaft ist . Das "Problem" der Ablaufverfolgung wird aus vielen Gründen erklärt und bezieht sich häufig auf die Komplexität der Einrichtung jeder Komponente des Systems, um die entsprechenden Header zusammen mit jeder Anforderung zu übertragen. Obwohl dieses Problem auftritt, kann es nicht als unüberwindbar bezeichnet werden. Übrigens erklärt es nicht, warum Entwickler Tracing nicht wirklich mögen (auch wenn es bereits funktioniert).
Die Hauptschwierigkeit bei der verteilten Ablaufverfolgung besteht darin, keine Daten zu sammeln, die Formate für die Verteilung und Präsentation der Ergebnisse nicht zu standardisieren und nicht zu bestimmen, wann, wo und wie Stichproben erstellt werden sollen. Ich versuche überhaupt nicht, diese „Verdaulichkeitsprobleme“ als
trivial darzustellen - tatsächlich gibt es ziemlich bedeutende technische und (wenn wir uns wirklich mit Open Source-
Standards und -Protokollen befassen) politische Herausforderungen, die bewältigt werden müssen, damit diese Probleme berücksichtigt werden können gelöst.
Wenn Sie sich jedoch vorstellen, dass all diese Probleme behoben wurden, wird sich an der
Endbenutzererfahrung wahrscheinlich nichts wesentlich ändern. Die Ablaufverfolgung ist in den gängigsten Debugging-Szenarien möglicherweise immer noch nicht praktikabel - selbst nach der Bereitstellung.
So eine andere Spur
Die verteilte Ablaufverfolgung umfasst mehrere unterschiedliche Komponenten:
- Ausstattung von Anwendungen und Middleware mit Steuerelementen;
- Verteilte Kontextübertragung
- Spurensammlung;
- Speicherung von Spuren;
- ihre Extraktion und Visualisierung.
Bei vielen Gesprächen über verteiltes Tracing geht es darum, es als eine Art unäre Operation zu betrachten, deren einziger Zweck darin besteht, bei der vollständigen Diagnose des Systems zu helfen. Dies ist hauptsächlich auf die Art und Weise zurückzuführen, in der das Konzept der verteilten Verfolgung entwickelt wurde. In
einem Blog-Beitrag, der beim Öffnen der Zipkin-Quellen verfasst wurde, wurde erwähnt, dass
er [Zipkin] Twitter schneller macht . Die ersten kommerziellen Angebote für die Rückverfolgung wurden auch als
APM-Tools beworben.
Hinweis perev. : Damit der weitere Text besser verstanden wird, definieren wir gemäß der Dokumentation des OpenTracing-Projekts zwei Grundbegriffe:- Span - das Grundelement der verteilten Verfolgung. Es ist eine Beschreibung eines bestimmten Workflows (z. B. einer Datenbankabfrage) mit einem Namen, Start- und Endzeiten, Tags, Protokollen und Kontext.
- Bereiche enthalten normalerweise Links zu anderen Bereichen, sodass Sie viele Bereiche in Trace kombinieren können - eine Visualisierung der Lebensdauer einer Anforderung, wenn diese sich durch ein verteiltes System bewegt.
Trace'y enthält unglaublich wertvolle Daten, die bei folgenden Aufgaben hilfreich sein können: Testen in der Produktion, Durchführen von Disaster Recovery-Tests, Testen mit Einführung von Fehlern usw. Tatsächlich verwenden einige Unternehmen die Rückverfolgung bereits für solche Zwecke. Zunächst hat die
universelle Kontextübertragung neben der einfachen Übertragung von Bereichen auf das Speichersystem noch andere Verwendungszwecke:
- Beispielsweise verwendet Uber Trace-Ergebnisse, um zwischen Testverkehr und Produktionsverkehr zu unterscheiden.
- Facebook verwendet Trace-Daten, um den kritischen Pfad zu analysieren und den Datenverkehr während regelmäßiger Disaster Recovery-Tests zu wechseln.
- Das soziale Netzwerk verwendet auch Jupyter-Notizbücher, mit denen Entwickler beliebige Abfragen zu den Ergebnissen der Ablaufverfolgung ausführen können.
- LDFI- Anhänger (Lineage Driven Failure Injection ) verwenden verteilte Traces für Fehlertests.
Keine der oben genannten Optionen bezieht sich vollständig auf das
Debugging- Szenario, in dem der Techniker versucht, das Problem durch Betrachten der Ablaufverfolgung zu lösen.
Wenn es um das Debugging-Szenario geht, bleibt das
Traceview- Diagramm die primäre Schnittstelle (obwohl einige es auch als
"Gantt-Diagramm" oder
"Kaskadendiagramm" bezeichnen ). Mit
Traceview meine ich alle
Bereiche und zugehörigen Metadaten, die zusammen Trace bilden. Jedes Open-Source-Trace-System sowie jede kommerzielle Trace-Lösung bietet eine auf
Traceview basierende Benutzeroberfläche zum Visualisieren, Detaillieren und Filtern von Trace-Daten.
Das Problem bei allen Trace-Systemen, mit denen ich im Moment vertraut bin, ist, dass die endgültige
Visualisierung (Trace-Ansicht) die Funktionen des Trace-Generierungsprozesses fast vollständig widerspiegelt. Selbst wenn alternative Visualisierungen angeboten werden: Intensitätskarten (Heatmap), Servicetopologien,
Latenzhistogramme - am Ende kommt es immer noch auf die
Trace-Ansicht an .
In der Vergangenheit habe ich mich darüber
beschwert, dass die meisten „Innovationen“ bei der Rückverfolgbarkeit in Bezug auf UI / UX
darauf beschränkt zu sein scheinen, zusätzliche Metadaten in die Ablaufverfolgung aufzunehmen, Informationen mit
hoher Kardinalität in diese einzubetten oder die Möglichkeit zu bieten, einen Drilldown auf bestimmte Bereiche durchzuführen oder
Inter- und Intra-Trace- Abfragen ausführen. In diesem Fall bleibt die
Trace-Ansicht das
Hauptvisualisierungsmittel . Solange dieser Zustand anhält, wird die verteilte Ablaufverfolgung (bestenfalls) als Debugging-Tool den 4. Platz einnehmen, gefolgt von Metriken, Protokollen und Stapelverfolgungen, und im schlimmsten Fall wird es sich als Geld- und Zeitverschwendung herausstellen.
Problem mit Traceview
Der Zweck der
Ablaufverfolgungsansicht besteht darin, ein vollständiges Bild der Bewegung einer einzelnen Anforderung über alle Komponenten eines verteilten Systems bereitzustellen, auf das sie sich bezieht. Mit einigen fortschrittlicheren Ablaufverfolgungssystemen können Sie einen Drilldown zu einzelnen Bereichen durchführen und die Zeitaufteilung
innerhalb eines einzelnen Prozesses anzeigen (wenn Bereiche funktionale Grenzen haben).
Die Grundvoraussetzung der Microservices-Architektur ist die Idee, dass die Organisationsstruktur mit den Anforderungen des Unternehmens wächst. Befürworter von Microservices argumentieren, dass die Verteilung verschiedener Geschäftsaufgaben auf separate Services es kleinen, autonomen Entwicklungsteams ermöglicht, den gesamten Lebenszyklus solcher Services zu steuern und diese Services unabhängig zu erstellen, zu testen und bereitzustellen. Der Nachteil dieser Verteilung ist jedoch der Verlust von Informationen darüber, wie jeder Dienst mit anderen interagiert. Unter solchen Umständen sind verteilte Ablaufverfolgungsansprüche ein unverzichtbares Werkzeug zum
Debuggen komplexer Interaktionen zwischen Diensten.
Wenn Sie ein wirklich
erstaunlich komplexes verteiltes System haben , kann sich niemand das
vollständige Bild merken. Tatsächlich ist die Entwicklung eines Tools, das auf der Annahme basiert, dass es im Allgemeinen möglich ist, ein bisschen antimuster (ineffizienter und unproduktiver Ansatz). Im Idealfall erfordert das Debuggen ein Tool, mit dem Sie
Ihre Suche eingrenzen können, damit sich die Ingenieure auf eine Teilmenge der Dimensionen (Dienste / Benutzer / Hosts usw.) konzentrieren können, die für das betreffende Szenario relevant sind. Bei der Ermittlung der Fehlerursache müssen die Ingenieure nicht verstehen, was in
allen Diensten gleichzeitig passiert ist, da eine solche Anforderung der Idee einer Microservice-Architektur widersprechen würde.
Traceview ist jedoch
genau das. Ja, einige Trace-Systeme bieten komprimierte Trace-Ansichten, wenn die Anzahl der Spans im Trace so groß ist, dass sie nicht in einer einzigen Visualisierung angezeigt werden können. Aufgrund der großen Menge an Informationen, die selbst in einer derart reduzierten Visualisierung enthalten sind, sind die Ingenieure jedoch immer noch
gezwungen, diese zu „sichten“ und die Auswahl manuell auf eine Reihe von Servicequellen für Probleme zu beschränken. Leider sind Maschinen auf diesem Gebiet viel schneller als Menschen, weniger fehleranfällig und ihre Ergebnisse sind wiederholbarer.
Ein weiterer Grund, warum ich die Traceview-Methode für falsch halte, ist, dass sie nicht für das hypothetische Debuggen geeignet ist. Das Debuggen ist im Kern ein
iterativer Prozess, der mit einer Hypothese beginnt, gefolgt von der Überprüfung verschiedener Beobachtungen und Fakten, die vom System erhalten wurden, unter Verwendung verschiedener Vektoren, Schlussfolgerungen / Verallgemeinerungen und einer weiteren Bewertung der Wahrheit der Hypothese.
Die Fähigkeit
, Hypothesen
schnell und kostengünstig zu testen und das mentale Modell entsprechend zu verbessern, ist der
Eckpfeiler des Debuggens. Jedes Debugging-Tool sollte
interaktiv sein und den Suchraum einschränken oder im Falle einer falschen Ablaufverfolgung dem Benutzer ermöglichen, zurück zu gehen und sich auf einen anderen Bereich des Systems zu konzentrieren. Ein ideales Tool erledigt dies
proaktiv und macht den Benutzer sofort auf potenziell problematische Bereiche aufmerksam.
Leider kann
Traceview nicht als interaktives Schnittstellentool bezeichnet werden. Das Beste, auf das Sie bei der Verwendung hoffen können, ist, eine bestimmte Quelle erhöhter Verzögerungen zu erkennen und alle damit verbundenen Tags und Protokolle anzuzeigen. Dies hilft dem Ingenieur nicht, Verkehrsmuster wie die Besonderheiten der Verteilung von Verzögerungen zu identifizieren oder Korrelationen zwischen verschiedenen Messungen zu erkennen.
Die generische Trace-Analyse kann einige dieser Probleme umgehen. In der Tat
gibt es Beispiele für eine erfolgreiche Analyse unter Verwendung von maschinellem Lernen, um abnormale Bereiche zu identifizieren und eine Teilmenge von Tags zu identifizieren, die mit abnormalem Verhalten verbunden sein können. Trotzdem bin ich noch nicht auf überzeugende Visualisierungen von Funden gestoßen, die mithilfe von maschinellem Lernen oder Datenanalyse auf Bereiche angewendet wurden, die sich erheblich von Traceview oder DAG (direktionaler azyklischer Graph) unterscheiden würden.
Die Spannweiten sind zu niedrig
Das grundlegende Problem bei der Trace-Ansicht besteht darin, dass
Spans sowohl für die Latenzanalyse als auch für die Ursachenanalyse zu niedrige Grundelemente sind. Es ist so, als würde man einzelne Prozessorbefehle analysieren, um eine Ausnahme zu beseitigen, da man weiß, dass es viel übergeordnete Tools wie Backtrace gibt, mit denen man viel bequemer arbeiten kann.
Darüber hinaus werde ich mir erlauben, Folgendes zu behaupten: Im Idealfall benötigen wir kein
vollständiges Bild dessen, was während des Lebenszyklus der Anfrage passiert ist, was moderne Tools zur Rückverfolgung darstellen. Stattdessen ist eine Form der Abstraktion auf höherer Ebene erforderlich, die Informationen darüber enthält, was
schief gelaufen ist (ähnlich wie bei der Rückverfolgung), sowie einen gewissen Kontext. Anstatt die gesamte Spur zu beobachten, sehe ich lieber einen
Teil davon, wo etwas Interessantes oder Ungewöhnliches passiert. Derzeit wird die Suche manuell durchgeführt: Der Ingenieur erhält eine Ablaufverfolgung und analysiert unabhängig voneinander die Spannweiten auf der Suche nach etwas Interessantem. Der Ansatz, wenn Personen in der Hoffnung, verdächtige Aktivitäten zu erkennen, auf Bereiche in getrennten Spuren starren, ist überhaupt nicht skalierbar (insbesondere, wenn sie alle in verschiedenen Bereichen codierten Metadaten wie Span-ID, RPC-Methodenname und Span-Dauer erfassen müssen 'a, Protokolle, Tags usw.).
Traceview-Alternativen
Verfolgungsergebnisse sind am nützlichsten, wenn sie so visualisiert werden können, dass eine nicht triviale Vorstellung davon entsteht, was in den miteinander verbundenen Teilen des Systems geschieht. Bis dies der Fall ist, bleibt der Debugging-Prozess weitgehend
inert und hängt von der Fähigkeit des Benutzers ab, die richtigen Korrelationen zu erkennen, die richtigen Teile des Systems zu überprüfen oder Teile des Mosaiks zusammenzusetzen - im Gegensatz zu dem
Tool , mit dem der Benutzer diese Hypothesen formulieren kann.
Ich bin kein visueller Designer oder UX-Spezialist, aber im nächsten Abschnitt möchte ich einige Ideen dazu teilen, wie solche Visualisierungen aussehen könnten.
Konzentrieren Sie sich auf bestimmte Dienstleistungen
In einem Umfeld, in dem sich die Branche auf die Ideen von
SLO (Service Level Objectives) und SLI (Service Level Indicators) konzentriert , erscheint es sinnvoll, dass einzelne Teams zunächst die Relevanz ihrer Services für diese Ziele überwachen. Daraus folgt, dass eine
serviceorientierte Visualisierung für solche Teams am besten geeignet ist.
Spuren, insbesondere ohne Stichproben, sind ein Informationsspeicher für jede Komponente eines verteilten Systems. Diese Informationen können an einen kniffligen Handler weitergeleitet werden, der den Benutzern serviceorientierte Fundstücke liefert, die im Voraus erkannt werden können - noch bevor der Benutzer die Spuren betrachtet:
- Verzögerungsverteilungsdiagramme nur für stark differenzierte Anforderungen (Ausreißeranforderungen) ;
- Verzögerungsverteilungsdiagramme für Fälle, in denen SLO-Serviceziele nicht erreicht werden;
- Die "häufigsten", "interessantesten" und "seltsamsten" Tags in Abfragen, die am häufigsten wiederholt werden .
- Aufschlüsselung der Verzögerungen für Fälle, in denen Dienstabhängigkeiten die festgelegten SLO-Ziele nicht erreichen;
- Aufschlüsselung der Verzögerungen für verschiedene nachgelagerte Dienste.
Integrierte Metriken können einige dieser Fragen einfach nicht beantworten, sodass Benutzer die Bereiche sorgfältig untersuchen müssen. Infolgedessen haben wir einen äußerst feindlichen Mechanismus für den Benutzer.
In diesem Zusammenhang stellt sich die Frage: Was ist mit den komplexen Wechselwirkungen zwischen den verschiedenen Diensten, die von verschiedenen Teams gesteuert werden? Wird
Traceview nicht als das am besten geeignete Tool zur Abdeckung einer solchen Situation angesehen?
Mobile Entwickler, Eigentümer von zustandslosen Diensten, Eigentümer von verwalteten Stateful Services (wie Datenbanken) und Plattformbesitzer sind möglicherweise an einer anderen
Ansicht eines verteilten Systems interessiert.
traceview ist eine viel zu universelle Lösung für diese grundlegend unterschiedlichen Anforderungen. Selbst in einer sehr komplexen Microservice-Architektur benötigen Service-Eigentümer keine gründlichen Kenntnisse über mehr als zwei oder drei Upstream- und Downstream-Services. Im Wesentlichen müssen Benutzer in den meisten Szenarien nur Fragen zu einem
begrenzten Satz von Diensten beantworten.
Es ist, als würde man eine kleine Untergruppe von Diensten durch eine Lupe betrachten, um genau zu studieren. Auf diese Weise kann der Benutzer dringendere Fragen zur komplexen Interaktion zwischen diesen Diensten und ihren unmittelbaren Abhängigkeiten stellen. Dies ähnelt der Rückverfolgung in der Welt der Dienste, in der der Ingenieur weiß,
was falsch ist, und auch eine Vorstellung davon hat, was in den umliegenden Diensten geschieht, um zu verstehen,
warum .
Der Ansatz, den ich fördere, ist das genaue Gegenteil des Top-Down-Ansatzes basierend auf der Trace-Ansicht, wenn die Analyse mit der gesamten Trace beginnt und dann allmählich auf einzelne Bereiche abfällt. Im Gegenteil, der Bottom-up-Ansatz beginnt mit einer Analyse eines kleinen Bereichs in der Nähe der potenziellen Ursache des Vorfalls. Anschließend wird der Suchraum bei Bedarf erweitert (unter Einbeziehung anderer Teams zur Analyse eines breiteren Leistungsspektrums). Der zweite Ansatz ist besser geeignet, um anfängliche Hypothesen schnell zu testen. Nachdem Sie bestimmte Ergebnisse erhalten haben, können Sie mit einer genaueren und detaillierteren Analyse fortfahren.
Topologiegebäude
Die mit einem bestimmten Dienst verknüpften Ansichten können unglaublich nützlich sein, wenn der Benutzer weiß,
welcher Dienst oder welche Gruppe von Diensten für zunehmende Verzögerungen verantwortlich ist oder eine Fehlerquelle darstellt. In einem komplexen System ist das Identifizieren eines Eindringlings während eines Fehlers möglicherweise keine triviale Aufgabe, insbesondere wenn keine Fehlermeldungen von den Diensten empfangen wurden.
Das Erstellen einer Servicetopologie kann sehr hilfreich sein, um herauszufinden, welcher Service einen Anstieg der Fehlerrate oder eine Erhöhung der Latenz aufweist, was zu einer spürbaren Verschlechterung der Serviceleistung führt. Wenn ich über das Erstellen einer Topologie spreche, meine ich nicht
eine Dienstkarte , die jeden im System verfügbaren
Dienst anzeigt und für seine
Architekturkarten in Form eines Todessterns bekannt ist . Eine solche Darstellung ist nicht besser als eine Trace-Ansicht, die auf einem gerichteten azyklischen Graphen basiert. Stattdessen möchte ich eine
dynamisch generierte Diensttopologie sehen, die auf bestimmten Attributen wie Fehlerrate, Antwortzeit oder einem benutzerdefinierten Parameter basiert, der zur Klärung der Situation mit bestimmten verdächtigen Diensten beiträgt.
Schauen wir uns ein Beispiel an. Stellen Sie sich eine hypothetische Nachrichtenseite vor. Der
Titelseitendienst kommuniziert mit Redis über einen Empfehlungsdienst, einen Werbedienst und einen Videodienst. Der Videodienst nimmt Videos aus S3 und die Metadaten aus DynamoDB auf. Der Empfehlungsdienst empfängt Metadaten von DynamoDB, lädt Daten von Redis und MySQL herunter und schreibt Nachrichten an Kafka. Der Werbedienst empfängt Daten von MySQL und schreibt Nachrichten an Kafka.
Das Folgende ist eine schematische Darstellung dieser Topologie (viele kommerzielle Routing-Programme bauen die Topologie auf). Dies kann nützlich sein, wenn Sie die Abhängigkeiten von Diensten verstehen müssen. Während des
Debuggens ist eine solche Topologie jedoch nicht sehr nützlich, wenn ein bestimmter Dienst (z. B. ein Videodienst) eine längere Antwortzeit aufweist.
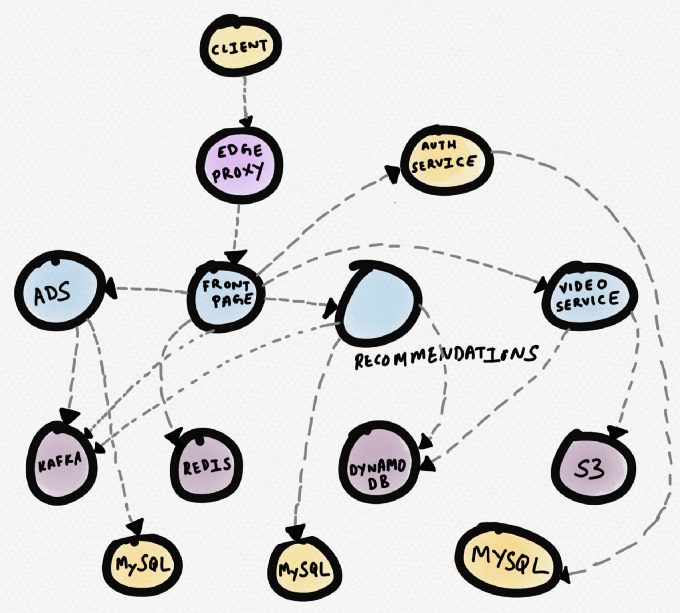 Hypothetical News Site Services Scheme
Hypothetical News Site Services SchemeDas folgende Diagramm wäre besser. Darauf
ist in der Mitte ein problematischer Dienst
(Video) abgebildet. Der Benutzer bemerkt ihn sofort. Aus dieser Visualisierung wird deutlich, dass der Videodienst aufgrund der erhöhten Antwortzeit von S3, die sich auf die Download-Geschwindigkeit eines Teils der Hauptseite auswirkt, nicht ordnungsgemäß funktioniert.
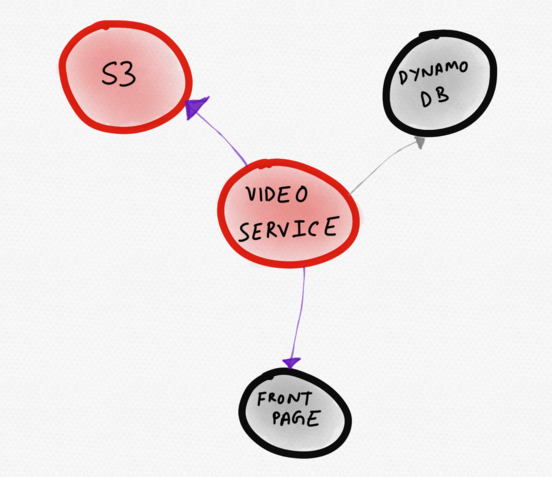 Dynamische Topologie, die nur „interessante“ Dienste anzeigt
Dynamische Topologie, die nur „interessante“ Dienste anzeigtDynamisch generierte topologische Schemata können effizienter sein als statische Service-Maps, insbesondere in flexiblen, automatisch skalierbaren Infrastrukturen. Durch die Möglichkeit, Diensttopologien zu vergleichen und gegenüberzustellen, kann der Benutzer relevantere Fragen stellen. Genauere Fragen zum System führen eher zu einem besseren Verständnis der Funktionsweise des Systems.
Vergleichsanzeige
Eine weitere nützliche Visualisierung wäre eine vergleichende Anzeige. Spuren sind derzeit nicht gut für Vergleiche nebeneinander geeignet, daher werden
Spannweiten normalerweise verglichen. Die Hauptidee dieses Artikels ist genau, dass die Spannweiten zu niedrig sind, um die wertvollsten Informationen aus den Trace-Ergebnissen zu extrahieren.
Der Vergleich zweier trace'ov erfordert keine grundlegend neuen Visualisierungen. In der Tat ist so etwas wie ein Histogramm ausreichend, das die gleichen Informationen wie die Trace-Ansicht darstellt. Überraschenderweise kann selbst diese einfache Methode viel mehr Früchte bringen als eine einfache Untersuchung von zwei Spuren getrennt. Noch leistungsfähiger wäre die Möglichkeit,
den Vergleich von Spuren
im Aggregat zu
visualisieren . Es wäre äußerst nützlich zu sehen, wie sich eine kürzlich bereitgestellte Änderung der Datenbankkonfiguration unter Einbeziehung von GC (Garbage Collection) auf die Antwortzeit eines nachgeschalteten Dienstes in wenigen Stunden auswirkt. Wenn das, was ich hier beschreibe, wie eine A / B-Analyse der Auswirkungen von Infrastrukturänderungen
in einer Vielzahl von Diensten unter Verwendung von Trace-Ergebnissen erscheint, sind Sie nicht zu weit von der Wahrheit entfernt.
Fazit
Ich bezweifle nicht die Nützlichkeit der Spur selbst. Ich bin der festen Überzeugung, dass es keinen anderen Weg gibt, so umfangreiche, zufällige und kontextbezogene Daten zu sammeln als die in der Spur enthaltenen.
Ich glaube jedoch auch, dass alle Tracing-Lösungen diese Daten äußerst ineffizient verwenden. Solange die Tools für die Ablaufverfolgung in der Ablaufverfolgungsdarstellung fixiert sind, können sie nur begrenzt wertvolle Informationen verwenden, die aus den in den Ablaufverfolgungen enthaltenen Daten extrahiert werden können. Darüber hinaus besteht die Gefahr der Weiterentwicklung einer völlig unfreundlichen und nicht intuitiven visuellen Oberfläche, die die Fähigkeit des Benutzers, Fehler in der Anwendung zu beheben, erheblich einschränkt.Das Debuggen komplexer Systeme ist selbst mit den neuesten Tools unglaublich komplex. Die Werkzeuge sollten die Entwicklern zu formulieren und zu testen Hypothesen helfen, die aktive Bereitstellung von , . , production , , , , .
, , , , , . , , , trace' span'.
( UI). , , . , . . .
PS vom Übersetzer
Lesen Sie auch in unserem Blog: