Hinweis perev. : Wir freuen uns, die Übersetzung des wunderbaren Materials des Senior Technology Evangelist von AWS - Adrian Hornsby - zu teilen. In einfachen Worten erklärt er die Bedeutung von Experimenten, mit denen die Folgen von Ausfällen in IT-Systemen gemindert werden sollen. Sie haben wahrscheinlich schon von Chaos Monkey gehört (oder sogar ähnliche Lösungen verwendet)? Heutzutage werden Ansätze zur Erstellung solcher Tools und deren Implementierung in einem breiteren Kontext im Rahmen einer Aktivität namens Chaos Engineering durchgeführt. Lesen Sie mehr darüber in diesem Artikel.
"Aber hinter all dieser Schönheit steckt Chaos und Wahnsinn." - Gerberwand
Feuerwehrleute . Diese hochqualifizierten Spezialisten riskieren jeden Tag ihr Leben und bekämpfen das Feuer. Wissen Sie, dass Sie mindestens 600 Stunden im Training verbringen müssen, bevor Sie Feuerwehrmann werden? Und das ist erst der Anfang. Berichten zufolge trainieren Feuerwehrleute bis zu 80% ihrer Arbeitszeit.
Warum?
Wenn ein Feuerwehrmann mit echtem Feuer zu kämpfen hat, braucht er eine angemessene
Intuition . Um es zu entwickeln, muss man Tag für Tag Stunde für Stunde trainieren. Übung wirkt Wunder.
„Es scheint, als ob sie die Essenz des Feuers durchdringen; solche Analoga von Dr. Phil für die Flamme. " - Waldbrände mit Computern und Intuition bekämpfen
Hinweis perev. : Phillip Calvin "Phil" McGraw ist ein amerikanischer Psychologe, Autor und Moderator der beliebten Fernsehsendung "Doctor Phil", in der der Moderator seinen Teilnehmern Lösungen für ihre Probleme anbietet.Es war einmal in Seattle
In den frühen 2000er Jahren gründete und leitete
Jesse Robbins , der eine offizielle Position bei Amazon mit dem offiziellen Namen
Master of Disaster innehatte , das GameDay-Programm. Es beruhte auf seiner Erfahrung als Feuerwehrmann. GameDay wurde entwickelt, um verschiedene Amazon-Systeme, -Software und -Personen auf potenzielle Krisensituationen zu testen, zu schulen und vorzubereiten.
Gerade als Feuerwehrleute die Intuition entwickeln, um Brände zu bekämpfen, wollte Jesse seinem Team helfen, die Intuition zu entwickeln, um großen katastrophalen Ereignissen entgegenzuwirken.
"GameDay: Resilienz durch Zerstörung schaffen" - Jesse RobbinsGameDay wurde entwickelt, um die Ausfallsicherheit der Amazon-Einzelhandels-Website zu erhöhen, indem absichtlich Fehler in unternehmenskritische Systeme eingeführt werden.
GameDay begann mit einer Reihe von Ankündigungen für das gesamte Unternehmen, dass ein Trainingsalarm geplant war - manchmal sehr umfangreich, zum Beispiel die Deaktivierung eines gesamten Rechenzentrums. Details über die geplante Abschaltung wurden minimal angegeben, und das Team hatte mehrere Monate Zeit, sich vorzubereiten. Das Hauptziel der Übung war es zu überprüfen, ob die Mitarbeiter mit der lokalen Krise fertig werden und ihre Folgen schnell beseitigen können.
Während dieser Übungen wurden spezielle Tools und Prozesse wie Überwachung, Warnungen und dringende Anrufe verwendet, um Fehler in den Verfahren zur Reaktion auf Vorfälle zu analysieren und zu identifizieren. Wie sich herausstellte, enthüllt GameDay klassische Architekturprobleme perfekt. Manchmal war es auch möglich, die sogenannten "versteckten Mängel" zu erkennen - Probleme, die sich aufgrund der Besonderheiten des Vorfalls manifestierten. Beispielsweise fielen Incident-Management-Systeme, die für den Wiederherstellungsprozess kritisch sind, aufgrund unerwarteter Nebenwirkungen aus, die durch ein vom Menschen verursachtes Problem verursacht wurden.
Mit dem Wachstum des Unternehmens erweiterte sich der theoretische Niederschlagsradius von GameDay. Am Ende hörten diese Übungen auf: Der potenzielle Schaden für das Unternehmen wurde zu groß, wenn etwas schief ging. Seitdem ist das Programm zu einer Reihe unterschiedlicher, nicht wirkungsvoller Geschäftsexperimente für die Schulung von Personal in Krisensituationen verkommen. Ich werde in diesem Artikel nicht auf die Details der Experimente eingehen, aber ich werde dies in Zukunft tun. Dieses Mal möchte ich die wichtige Idee diskutieren, die GameDay zugrunde liegt:
Resiliency Engineering , auch als
Chaos Engineering bekannt .
Affenaufstieg
Sie haben wahrscheinlich schon von Netflix gehört, dem Anbieter von Online-Videoinhalten. Netflix begann im August 2008 mit dem Umzug von seinem eigenen Rechenzentrum in die AWS Cloud. Dieser Schritt wurde durch schwerwiegende Schäden an der Datenbank verursacht, aufgrund derer sich die DVD-Lieferung um drei Tage verzögerte (ja, Netflix begann mit dem Versenden von Filmen per Post). Die Migration in die Cloud war mit der Notwendigkeit verbunden, viel höheren Streaming-Lasten standzuhalten, sowie mit dem Wunsch, die monolithische Architektur aufzugeben und auf Microservices umzusteigen, die je nach Anzahl der Benutzer und Größe des Engineering-Teams einfach zu skalieren sind. Der Benutzerteil des Streaming-Service wechselte zwischen 2010 und 2011 zunächst zu AWS, gefolgt von der Unternehmens-IT und allen anderen Strukturen. Das eigene Rechenzentrum von Netflix wurde 2016 geschlossen. Das Unternehmen misst die Zugänglichkeit als Verhältnis der Anzahl erfolgreicher Versuche, einen Film zu starten, zur Gesamtzahl und nicht als einfachen Vergleich von Betriebszeit und Ausfallzeit und versucht, vierteljährlich in jeder Region einen Wert von 0,9999 zu erreichen (häufig gelingt dies). Die globale Architektur von Netflix umfasst drei AWS-Regionen. Bei Problemen in einer der Regionen kann das Unternehmen Benutzer auf andere umleiten.
Ich wiederhole eines meiner Lieblingszitate:
„Misserfolg ist unvermeidlich; Irgendwann wird jedes System mit der Zeit abstürzen. “ - Werner Vogels
In der Tat sind Ausfälle in verteilten Systemen, insbesondere in großen Systemen, selbst in der Cloud unvermeidlich. Die AWS-Cloud und ihre Redundanzprimitive - insbesondere das
Prinzip der Mehrfachzugriffszonen, auf denen sie basiert - ermöglichen es jedoch jedem, hochzuverlässige Dienste zu entwerfen.
Mit den Prinzipien der Redundanz und der
ordnungsgemäßen Verschlechterung gelang es Netflix
, Fehler zu überstehen, ohne die Endbenutzer zu beeinträchtigen.
Netflix hat sich von Anfang an an die strengsten Architekturprinzipien gehalten. Eine der ersten Anwendungen, die sie für AWS bereitstellten, war ihr
Chaos Monkey - zur Unterstützung von zustandslosen Mikrodiensten im automatischen Maßstab. Mit anderen Worten, jede Instanz kann gestoppt und automatisch ersetzt werden, ohne dass der Status verloren geht. Chaos Monkey stellt sicher, dass niemand gegen dieses Prinzip verstößt.
Hinweis perev. : Übrigens gibt es für Kubernetes ein Analogon namens Kubusaffe , dessen Entwicklung im März dieses Jahres gestoppt zu sein scheint.Netflix hat eine weitere Regel, die die Verteilung jedes Dienstes in drei Verfügbarkeitszonen vorsieht. Es sollte weiter funktionieren, wenn nur zwei davon verfügbar sind. Um sicherzustellen, dass diese Regel eingehalten wird, deaktiviert
Chaos Gorilla Verfügbarkeitszonen. Global
Kong kann
Chaos Kong die gesamte AWS-Region deaktivieren, um zu bestätigen, dass alle Netflix-Benutzer von jeder der drei Regionen aus bedient werden können. Und sie führen diese groß angelegten Tests alle paar Wochen in der Produktion durch, um sicherzustellen, dass nichts der Aufmerksamkeit entgeht.
Schließlich entwickelte Netflix auch die gezielteren
Chaos-Test-Tools , um Probleme mit Microservices und Speicherarchitekturen zu erkennen. Weitere Informationen zu diesen Techniken finden Sie im Buch Chaos Engineering, das ich jedem empfehlen kann, der sich für dieses Thema interessiert.
„Durch regelmäßige Experimente, die regionale Ausfälle nachahmen, konnten wir verschiedene Systemfehler identifizieren und frühzeitig beseitigen.“ - Netflix-Blog
Heute sind die Prinzipien des Chaos Engineering
formalisiert ; Sie erhalten die folgende Definition:
"Chaos Engineering ist ein Ansatz, bei dem Experimente an einem Produktionssystem durchgeführt werden, um sicherzustellen, dass es verschiedenen Störungen standhält, die während des Betriebs auftreten." - Principlesofchaos.org
In einer
Rede auf der AWS re: Invent 2018 zum Thema Chaos Engineering stellte
Adrian Cockcroft , ein ehemaliger Entwickler der Netflix-Cloud-Architektur, der dem Unternehmen half, vollständig auf die Cloud-Infrastruktur umzusteigen, eine alternative Definition des Chaos Engineering vor. Meiner Meinung nach ist es genauer und etablierter:
"Chaos Engineering ist ein Experiment, mit dem die Folgen von Fehlern gemindert werden sollen."
Tatsächlich wissen wir, dass Abstürze die ganze Zeit passieren. Mit der richtigen Antwort sollten sie keine Auswirkungen auf Endbenutzer haben. Das Hauptziel des Chaos Engineering ist es, Probleme zu erkennen, die nicht richtig gelöst werden.
Voraussetzungen für die Schaffung von Chaos
Stellen Sie vor Beginn des Chaos Engineering sicher, dass Sie alle erforderlichen Arbeiten ausführen, um die Nachhaltigkeit auf allen Ebenen des Unternehmens sicherzustellen. Bei der Erstellung fehlertoleranter Systeme geht es nicht nur um Software. Es beginnt auf
Infrastrukturebene , erstreckt sich auf das
Netzwerk und die Daten , wirkt sich auf die Struktur von
Anwendungen aus und umfasst letztendlich
Menschen und Kultur . In der Vergangenheit habe ich viel über Stabilitätsmodelle und Fehler geschrieben (
hier ,
hier ,
hier und
hier ) und ich werde mich jetzt nicht darauf konzentrieren, aber ich kann nicht ohne eine kleine Erinnerung auskommen.
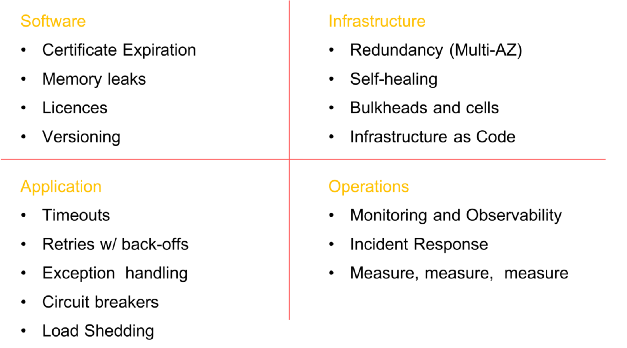 Einige obligatorische Elemente, bevor Chaos in das System eingeführt wird (die Liste ist nicht vollständig).
Einige obligatorische Elemente, bevor Chaos in das System eingeführt wird (die Liste ist nicht vollständig).Stufen der Chaos-Technik
Es ist wichtig zu verstehen, dass die Essenz der Chaos-Technik
NICHT darin besteht, die Affen loszulassen und alles hintereinander ohne Zweck zerstören zu lassen. Ziel dieser Disziplin ist es, einige Elemente des Systems in einer kontrollierten Umgebung durch gut geplante Experimente zu zerstören, um zu überprüfen, ob Ihre Anwendung turbulenten Bedingungen standhält.
Dazu müssen Sie den in der folgenden Abbildung gezeigten klar definierten, formalisierten Prozess befolgen. Damit können Sie vom Verständnis des stationären Zustands Ihres Systems zur Formulierung einer Hypothese übergehen, diese testen und schließlich die während des Experiments gewonnenen Erfahrungen analysieren und die Stabilität des Systems selbst erhöhen.
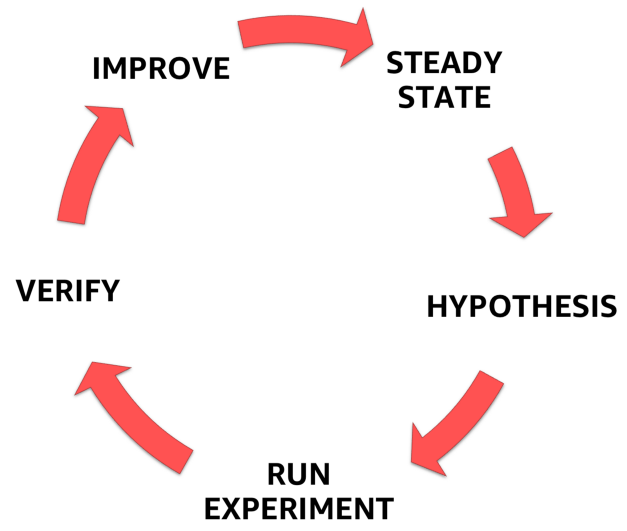 Stufen der Chaos-Technik
Stufen der Chaos-Technik1. Stabiler Zustand
Eines der wichtigsten Elemente der Chaos-Technik ist das Verständnis des Verhaltens eines Systems unter normalen Bedingungen.
Warum? Es ist ganz einfach: Nach der Einführung des künstlichen Versagens müssen Sie sicherstellen, dass das System in einen gut untersuchten stabilen Zustand zurückgekehrt ist und das Experiment sein normales Verhalten nicht mehr beeinträchtigt.
Der entscheidende Punkt hierbei ist, dass Sie sich nicht auf die internen Attribute des Systems (Prozessor, Speicher usw.) konzentrieren müssen, sondern die messbaren Ausgangssignale überwachen müssen, die die Leistung mit der Benutzererfahrung verbinden. Damit sich diese Ausgangssignale in einem stabilen Zustand befinden, muss das beobachtete Verhalten des Systems ein vorhersagbares Muster aufweisen, sich jedoch erheblich ändern, wenn eine Fehlfunktion im System auftritt.
Unter Berücksichtigung der oben von Adrian Cockcroft vorgeschlagenen
Definition der Chaos-Technik ändert sich dieser stabile Zustand, wenn ein außer Kontrolle geratener Fehler ein unerwartetes Problem verursacht und signalisiert, dass das Chaos-Experiment unterbrochen werden sollte.
Lassen Sie uns als Beispiel für stabile Bedingungen die Amazon-Erfahrung anführen. Das Unternehmen verwendet die Anzahl der Bestellungen aus gutem Grund als eine der Metriken für einen stabilen Zustand. 2007 sprach Greg Linden, der zuvor bei Amazon gearbeitet hatte, darüber, wie er im Rahmen eines Experiments mit der
A / B-Testmethode versuchte, die Ladezeit von Seiten auf der Website in Schritten von 100 ms zu verlangsamen, und stellte fest, dass sich sogar geringfügige Verzögerungen ergeben zu einem ernsthaften Umsatzrückgang. Mit einer Verlängerung der Ladezeit um 100 ms verringerte sich die Anzahl der Bestellungen (und damit der Umsatz) um 1%. Aus diesem Grund ist die Anzahl der Bestellungen ein hervorragender Kandidat für stabile Kennzahlen.
Netflix verwendet eine serverseitige Metrik, die mit dem Start der Wiedergabe verknüpft ist - die Anzahl der Klicks auf die Wiedergabetaste. Sie bemerkten eine Regelmäßigkeit im Verhalten des SPS-Indikators (Starts pro Sekunde) und seine signifikanten Schwankungen bei Systemausfällen. Die Metrik heißt "Pulse of Netflix" (
Pulse of Netflix ).
Die Anzahl der Bestellungen bei Amazon und Netflix Pulse ist ein hervorragendes Stabilitätsbarometer, da sie Benutzererfahrung und Betriebsmetriken in einem einzigen, messbaren und hoch vorhersehbaren Indikator kombinieren.
Messen, messen und erneut messen
Es versteht sich von selbst, dass Sie Änderungen in einem stabilen Zustand nicht überwachen (oder sogar erkennen) können, wenn Sie die Leistung des Systems nicht ordnungsgemäß aufzeichnen können. Achten Sie besonders darauf, alle Parameter / Indikatoren aus dem Netzwerk und der Hardware zu entfernen und mit der Anwendung und den Personen zu enden. Zeichnen Sie Diagramme dieser Messungen, auch wenn sie sich im Laufe der Zeit nicht ändern. Sie werden überrascht sein, Zusammenhänge zu entdecken, die Ihnen nicht bekannt waren.
"Machen Sie es Ingenieuren so einfach wie möglich, auf die Daten zuzugreifen, die sie zählen oder in grafische Form übersetzen können." - Ian Malpass
2. Hypothese
Nachdem wir uns mit einem stabilen Zustand befasst haben, können wir eine Hypothese formulieren.

- Was ist, wenn der Empfehlungsmechanismus stoppt?
- Was ist, wenn der Load Balancer herunterfällt?
- Was ist, wenn das Caching abfällt?
- Was ist, wenn die Verzögerung um 300 ms zunimmt?
- Was ist, wenn die Master-Basis abstürzt?
Natürlich sollte nur eine Hypothese gewählt werden, und es ist nicht notwendig, sie unnötig zu komplizieren. Fangen Sie klein an. Ich beginne gerne mit der Mitarbeiterhypothese. Haben Sie vom
Busfaktor gehört ? Der Busfaktor ist ein Risikomaß, das damit verbunden ist, dass das Wissen nicht gleichmäßig auf die Teammitglieder verteilt wird. Sie können die Mindestteilnehmerzahl berechnen, nach deren plötzlichem Verlust das Projekt aufgrund mangelnder Kenntnisse oder Erfahrungen eingestellt wird.
Viele Unternehmen haben technische Experten, deren plötzliches Verschwinden („von einem Bus angefahren“) verheerende Auswirkungen auf das Projekt und das Team haben wird. Identifizieren Sie diese Personen und führen Sie mit ihrer Teilnahme Chaos-Experimente durch: Nehmen Sie ihnen beispielsweise Computer ab und schicken Sie sie für einen Tag nach Hause. Beobachten Sie dann die (oft chaotischen) Ergebnisse.
Machen Sie das Problem allen gemeinsam!
Binden Sie das
gesamte Team in die Entwicklung einer Hypothese ein. Lassen Sie alle am Brainstorming teilnehmen: den Product Owner, den technischen Manager, die Backend- und Frontend-Entwickler, Designer, Architekten usw. Jeder, der auf die eine oder andere Weise mit dem Produkt verbunden ist.
Bitten Sie zunächst alle, ihre eigene Antwort auf die Frage "Was wäre wenn ...?" Zu schreiben. auf einem Stück Papier. Sie werden sehen, dass in den meisten Fällen jeder seine eigene Antwort hat, und Sie werden verstehen, dass ein Teil des Teams noch immer nicht über ein solches Problem nachgedacht hat.
Halten Sie an dieser Stelle an und diskutieren Sie, warum Teammitglieder das Produktverhalten im Fall von „Was wäre wenn ...?“ Anders sehen. Gehen Sie zurück zu den Spezifikationen und stellen Sie sicher, dass jeder die mögliche Entwicklung von Ereignissen richtig versteht.
Nehmen Sie zum Beispiel die erwähnte Amazon-Einzelhandels-Website. Was passiert, wenn der Shop nach Kategorie-Service auf der Hauptseite nicht mehr geladen wird?

Sollte ich einen 404-Fehler zurückgeben? Lohnt es sich, die Seite zu laden und einen leeren Platz wie im folgenden Screenshot zu lassen?

Lohnt es sich, einen Teil der Funktionalität zu opfern und beispielsweise die Seite erweitern und den Fehler verbergen zu lassen?
Und das nur auf der Seite der Benutzeroberfläche. Was soll im Backend passieren? Sollten Benachrichtigungen gesendet werden? Sollte ein ausgefallener Dienst weiterhin jedes Mal Anforderungen empfangen, wenn der Benutzer die Homepage lädt, oder sollte das Backend sie vollständig abschneiden müssen?
Und der letzte. Bitte formulieren Sie keine Hypothese, die im Voraus bekannt ist, dass sie Brennholz brechen wird! Experimentieren Sie mit Teilen des Systems, die Ihrer Meinung nach stabil sind - letztendlich ist dies der springende Punkt des Experiments.3. Entwerfen Sie ein Experiment und führen Sie es aus
- Wählen Sie eine Hypothese;
- Definieren Sie den Umfang des Experiments.
- Definieren Sie die zu messenden Indikatoren.
- Benachrichtigen Sie die Organisation.
Heutzutage fördern viele Menschen sowie die Website von
Principlesofchaos die Idee des Chaos Engineering in der Produktion. Obwohl dies das ultimative Ziel sein sollte, haben die meisten Unternehmen Angst vor diesem Ansatz, daher sollten Sie nicht damit beginnen.
Chaos Engineering ist für mich nicht nur die Zerstörung verschiedener Elemente von Produktionssystemen. Dies ist eine Reise. Eine Reise in die Welt des Wissens, die untrennbar mit Aktivitäten wie der Zerstörung von Systemen in einer kontrollierten Umgebung verbunden ist - jeder Umgebung, ob es sich um eine lokale Entwicklungsumgebung, Beta, Staging oder Prod handelt. Zerstörung durch gut konzipierte Experimente, um Vertrauen in die Fähigkeit Ihrer Anwendung zu schaffen, turbulente Bedingungen zu tolerieren. „
Vertrauen aufbauen“ ist in diesem Fall ein zentraler Punkt, da es ein Vorläufer der kulturellen Veränderungen ist, die für die erfolgreiche Implementierung von Chaos Engineering und die Praxis der Verbesserung der Zuverlässigkeit in Ihrem Unternehmen erforderlich sind.
Ehrlich gesagt, die meisten Teams werden viel lernen, indem sie Dinge auch in einer Umgebung ohne Produktion brechen. Versuchen Sie einfach,
docker stop database in Ihrer lokalen Umgebung zu
docker stop database und prüfen Sie, ob Sie dieses Problem ohne Konsequenzen lösen können. Hohe Wahrscheinlichkeit, dass nein.
Datenbankstopp - BeispielFangen Sie klein an und bauen Sie nach und nach Vertrauen in Ihr Team und Ihre Organisation auf. Sie werden erfahren, dass "realer Produktionsverkehr die einzige Möglichkeit ist, das Systemverhalten zuverlässig zu erfassen". Hören Sie zu, lächeln Sie und machen Sie langsam weiter, was Sie tun. Das Schlimmste, was Sie tun können, ist, Chaos Engineering auf die Produktion anzuwenden und kläglich zu scheitern. Danach wird dir niemand mehr vertrauen und du wirst gezwungen sein, die „Chaosaffen“ für immer zu vergessen.
Gewinnen Sie zuerst Glaubwürdigkeit. Zeigen Sie Organisationen und Kollegen, dass Sie wissen, was Sie tun. Werden Sie Feuerwehrmann und lernen Sie so viel wie möglich über die Flamme, bevor Sie mit Live-Feuer trainieren. Glaubwürdigkeit verdienen. Erinnerst
du dich an die
Geschichte der Schildkröte und des Hasen ? Das Rennen wird immer von einem langsamen und geduldigen gewonnen.
Einer der wichtigsten Punkte während des Experiments ist das Verständnis des potenziellen
Schadensradius aufgrund der von Ihnen eingeführten Fehlfunktion und deren Minimierung. Stellen Sie sich folgende Fragen:
- Wie viele Kunden sind von dem Experiment betroffen?
- Welche Funktionalität wird darunter leiden?
- Welche Orte sind betroffen?
Stellen Sie sich einen „Not-Aus-Schalter“ oder eine Möglichkeit vor, ein Experiment sofort zu beenden und so schnell wie möglich in einen stabilen Zustand zurückzukehren. Ich mache gerne Experimente mit dem sogenannten. Rollouts "Canary". Diese Technik verringert das Ausfallrisiko beim Starten neuer Versionen einer Anwendung in der Produktion, indem Änderungen schrittweise auf eine kleine Teilmenge von Benutzern übertragen und dann langsam auf die gesamte Infrastruktur und alle Benutzer verteilt werden. Ich liebe kanarische Rollouts, einfach weil sie dem Prinzip einer
festen Infrastruktur entsprechen und das Experiment selbst ziemlich einfach zu stoppen ist.
 Ein Beispiel für einen DNS-basierten kanarischen Rollout für Chaos-Experimente
Ein Beispiel für einen DNS-basierten kanarischen Rollout für Chaos-ExperimenteSeien Sie vorsichtig mit Experimenten, die den Status der Anwendung ändern (Cache oder Datenbank) oder die nicht zurückgesetzt werden können (einfach oder im Prinzip).
Es ist merkwürdig, dass Adrian Cockcroft mir sagte, dass einer der Gründe, warum Netflix NoSQL-Datenbanken verwendet, das Fehlen von Schemata für Änderungen oder Rollbacks in diesen ist, so dass es viel einfacher ist, einzelne Datensätze schrittweise mit Daten zu aktualisieren oder zu korrigieren (d. H. Sie sind mehr) freundlich zu Chaos Engineering).
4. Beobachten und lernen
Um etwas Neues zu lernen und den Fortschritt des Experiments zu überwachen, müssen Sie in der Lage sein, die Systemleistung zu verfolgen. Achten Sie, wie bereits erwähnt, auf alle Arten von Metriken und Parametern! Dann quantifizieren Sie die Ergebnisse und immer - immer! - Notieren Sie die Zeit, bis die ersten Anzeichen eines Problems auftreten. In meiner Geschichte ist es wiederholt vorgekommen, dass sich die Warnsysteme geweigert haben und die ersten das Problem den Kunden auf Twitter gemeldet haben. Glauben Sie mir, Sie werden nicht in dieser Situation sein wollen. Verwenden Sie also Chaos-Experimente, um Ihre Überwachungs- und Warnsysteme zu überprüfen.
- Zeit zu entdecken?
- Zeit für Alarm und aktive Aktion?
- Zeit zur öffentlichen Bekanntmachung?
- Zeit bis zum teilweisen Verlust der Funktionalität?
- Die Länge der Selbstheilungsphase?
- Zeit für eine vollständige oder teilweise Wiederherstellung?
- Zeit, die Krise zu beenden und in einen stabilen Zustand zurückzukehren?
Denken Sie daran, dass es keine einzige isolierte Fehlerursache gibt. Schwere Unfälle sind immer das Ergebnis mehrerer kleiner Ausfälle, die sich ansammeln und zu einer großen Krise führen.
Führen Sie für jedes Experiment eine detaillierte Postmortem-Analyse durch!Bei AWS legen wir großen Wert darauf, erkannte Fehler zu analysieren und die Ursachen zu verstehen, die dazu geführt haben, dass ähnliche Probleme in Zukunft vermieden werden. Alle Schlussfolgerungen und Ergebnisse des Experiments sind in einem Dokument namens Correction-of-Errors (COE) zusammengefasst. COE ermöglicht es uns, aus unseren Fehlern zu lernen, ob in Technologie, Prozess oder sogar Organisation fehlerhaft. Wir verwenden diesen Mechanismus, um die Hauptursachen für Ausfälle und kontinuierliche Entwicklung zu beseitigen.
Der Schlüssel zum Erfolg in diesem Prozess ist Offenheit und Transparenz in Bezug auf das, was schief gelaufen ist. Eines der wichtigsten Prinzipien beim Schreiben eines guten COE ist es, unparteiisch zu sein und zu vermeiden, bestimmte Personen zu erwähnen. Dies ist in einer Umgebung, die ein solches Verhalten nicht fördert und kein Versagen zulässt, oft schwierig. Amazon verwendet eine Sammlung von
Führungsprinzipien , um dieses Verhalten zu fördern.
Selbstkritik, ein analytischer Ansatz, die Einhaltung höchster Standards und Verantwortung sind Schlüsselkomponenten des COE-Prozesses und der operativen Exzellenz im Allgemeinen.
Der COE-Bericht besteht aus fünf Hauptabschnitten:
- Was ist passiert (chronologische Reihenfolge)?
- Was war der Einfluss auf die Kunden?
- Warum ist der Fehler aufgetreten? ( Fünf "warum?" )
- Was haben wir gelernt?
- Wie kann dies in Zukunft verhindert werden?
Es ist schwieriger, diese Fragen zu beantworten, als es auf den ersten Blick scheint, da Sie sicherstellen müssen, dass jeder unverständliche / unbekannte Moment sorgfältig untersucht wird.
Um den COE-Mechanismus in einen vollwertigen Prozess zu verwandeln, führen wir ständig Überprüfungen in Form von wöchentlichen Besprechungen mit einer obligatorischen Analyse der Betriebsmetriken durch. Darüber hinaus führen führende technische Experten wöchentliche Metrikprüfungen mit allen AWS-Mitarbeitern durch.
5. Korrigieren und verbessern!
Die wichtigste Lehre hierbei ist
zunächst, die während der Chaos-Experimente festgestellten Probleme zu beseitigen und ihnen eine höhere Priorität zuzuweisen als der Entwicklung neuer Funktionen . Binden Sie das Top-Management in diesen Prozess ein und führen Sie ihn in die Idee ein, dass die Behebung aktueller Probleme viel wichtiger ist als die Entwicklung neuer Funktionen.
Einmal half ich einem Kunden mithilfe eines Chaos-Experiments, kritische Stabilitätsprobleme zu identifizieren. Aufgrund des Drucks der Verkaufsabteilung wurde die Priorität des Fixes jedoch gesenkt, und alle Bemühungen richteten sich auf die Einführung einer neuen Sache, die für Kunden „äußerst wichtig“ ist. Zwei Wochen später zwang eine 16-stündige Ausfallzeit das Unternehmen, dieselben Probleme anzugehen, die wir während des Chaos-Experiments festgestellt hatten. Nur die Verluste waren viel höher.
Die Vorteile von Chaos Engineering
Es gibt viele Vorteile. Ich werde meiner Meinung nach zwei hervorheben, die wichtigsten:
Erstens hilft Chaos Engineering dabei, unbekannte Probleme im System zu lösen und zu beheben, bevor sie beispielsweise am Sonntag um 3 Uhr morgens zu Produktionsausfällen führen. Das heißt, es
erhöht die Crash-Beständigkeit und in der Tat die Schlafqualität .
Zweitens führen effizient durchgeführte Chaos-Experimente immer zu größeren (hauptsächlich kulturellen) Veränderungen als erwartet. Das vielleicht wichtigste davon ist die natürliche Entwicklung zu einer
" nicht beschuldigenden" Kultur , wenn die Frage "Warum hast du das getan?" wird zu "Wie können wir dies in Zukunft vermeiden?". Dadurch wird das Team glücklicher, effizienter, interessierter und erfolgreicher.
Und das ist wunderbar!Damit endet der erste Teil. Ich hoffe es hat euch gefallen. Bitte schreiben Sie Bewertungen, tauschen Sie Meinungen aus oder klatschen Sie einfach in die Hände von
Medium . Im nächsten Teil werde ich mich mit Tools und Techniken zur Einführung von Systemfehlern befassen. Bis!
Für diejenigen, die den zweiten Teil unbedingt kennenlernen möchten, biete ich meine Präsentation zum Thema Chaos Engineering am NDC in Oslo an. Darin spreche ich über viele meiner Lieblingswerkzeuge:
PS vom Übersetzer
Der zweite Teil des Artikels in englischer Sprache ist bereits erschienen und wir werden ihn auch übersetzen, wenn die Leser des Habré genügend Interesse an diesem Material haben - relevante Kommentare zum Artikel sind willkommen! AKTUALISIERT (3. September): Eine Übersetzung des zweiten Teils wird ebenfalls
veröffentlicht .
AKTUALISIERT (19. Dezember): Die
Übersetzung des dritten Teils ist verfügbar.
Lesen Sie auch in unserem Blog: