Hallo allerseits, wir haben kürzlich darüber geschrieben, wie wir gelernt haben, mit GoPractice Simulator datengesteuert zu sein! In dieser Ausgabe werden wir das Thema Datenanalyse fortsetzen und über den Aufbau des Prozesses der Arbeit mit Analysen im Plesk-Team sprechen.
Plesk ist ein komplexes Produkt mit einem 20-jährigen Hintergrund, und wir konnten die erforderlichen Statistiken nicht immer effektiv erfassen. Wir haben die Daten lange Zeit nur im Nachhinein betrachtet und Entscheidungen auf der Grundlage subjektiver Empfindungen „so wie sie sein sollten“ getroffen. In der Vergangenheit hatten wir bereits die traurigen Konsequenzen dieses Ansatzes - 2012 haben wir das Design geändert, um das Beste zu tun, erhielten jedoch eine Welle negativer Rückmeldungen, die Weigerung, auf die neueste Version des Produkts zu aktualisieren, und den Abfluss von Kunden.
Nachdem wir diese traurige Erfahrung verstanden hatten, kamen wir zu Schlussfolgerungen und beschlossen, ein datengetriebenes Unternehmen zu gründen. Auf diesem Weg erwarteten uns Schwierigkeiten anderer Art. Im großen Maßstab können sie in zwei Hauptgruppen unterteilt werden - System und Prozess. In diesem Artikel werde ich mich auf die Aufgabe konzentrieren, den Prozess der Arbeit mit Analysen aufzubauen.
Systemische Probleme, die mit den Besonderheiten des verpackten Produkts verbunden sind, verdienen einen gesonderten Artikel, daher werde ich hier nicht näher darauf eingehen, sondern nur die wichtigsten auflisten.
- Viele Veranstaltungen, hohe Nutzungsmengen. Wenn wir nach unseren Berechnungen nur über das Verfolgen von Benutzeraktionen im Panel sprechen, sind dies 60 Millionen Ereignisse pro Monat, und es ist schade, 150.000 US-Dollar für Advanced Google Analytics bereitzustellen. Eine weitere Schwierigkeit besteht darin, dass Sie für die Arbeit mit GA jede benutzerdefinierte Aktion explizit behandeln müssen. Wir wollten jedoch einen einheitlichen Mechanismus, bei dem Ereignisse oder Aktionen nicht für jede neue Funktion manuell markiert werden müssen.
- Aufgrund des Volumens und Formats der Box (die Einführung von Änderungen erfordert Zeit) kann die Analyse nicht in Echtzeit durchgeführt werden. Benutzer sitzen auf 8 verschiedenen Versionen des Produkts, von denen 4 bereits EOLed sind. Selbst bei den neuesten Versionen haben nur 60% der Benutzer in den ersten zwei Wochen nach der Veröffentlichung neue Änderungen vorgenommen.
- Komplexes Produkt. Plesk unterstützt 14 Betriebssysteme der Linux-Familie, 4 OC Windows, eine 150-Komponenten von Drittanbietern, mehrere Webserver, Mailserver, Webmail-Clients, Statistikvisualisierer, Antivirenlösungen usw. Eine große Anzahl möglicher Konfigurationen wirkt sich hauptsächlich auf die Komplexität und das Volumen der Tests aus und macht die Verwendung von A / B-Tests nahezu unmöglich.
- B2B2C-Besonderheiten. Der Entscheider ist nicht immer gleich dem „echten Benutzer des Panels“.
- DSGVO - Die Notwendigkeit, den Buchstaben des Gesetzes einzuhalten, erfordert zusätzliche Anstrengungen zur Anonymisierung der Daten und erschwert die Aufgaben der Benutzersegmentierung. Außerdem ist es uns nicht möglich, Kunden über ihre Kontaktinformationen einfach und schnell zu kontaktieren.
Wir werden detaillierter auf Prozessschmerzen eingehen. Bis vor kurzem war der Prozess des Sammelns von Analysen bei uns vollständig vom Entwicklungsprozess getrennt - wir haben uns am Ende an das Tracking und die Metriken erinnert, eine einmalige Lösung vermasselt und so weiter bis zum nächsten Feature. Darüber hinaus hat Plesk im Laufe der Jahre eine Reihe von Datenquellen angesammelt. Dies war mit den Kosten für die Aufrechterhaltung der Konsistenz, der Relevanz der Daten, der Notwendigkeit verbunden, zu berücksichtigen, woher sie stammen, unter welchen Bedingungen sie in die Datenbank gelangen und warum dieselben Metriken an verschiedenen Orten verwendet werden unterscheiden sich (zum Beispiel die Anzahl der Lizenzschlüssel und physischen Installationen). In diese Quellen wurden viele Informationen geschrieben (monatliche Kürzungen aus einer Datenbank mit 270.000 Schlüsseln und Berichten, die doppelt so häufig von 300.000 Servern eingehen), aber nur wenige Personen konnten mit diesen Daten arbeiten und fanden Zeit. Ich kam 2015 nach Plesk und meine erste Aufgabe bestand darin, heterogene Statistiken aus dem OLAP-Cube und der MongoDB-Datenbank abzurufen. 'How To' zu dieser Datenbank war eine Seite mit einem Benutzernamen und einem Passwort vom Host und einer Textdatei mit einem js-Skript aus der letzten populären Anfrage.
Eine Reihe von Quellen bedeutete eine Reihe von Tools und Diensten, die jeder Programmmanager verwenden sollte. Das Gefühl in den frühen Tagen der Arbeit war ungefähr so:

Was haben wir getan
Die Lösung lautete wie folgt: Vor ungefähr eineinhalb Jahren haben wir mit der vollständigen Überarbeitung des Datenerfassungsprozesses begonnen. Jetzt entwickeln wir Analysen auf die gleiche Weise wie das Feature selbst. In jeder Phase ist das gesamte Team (Feature-Crew) involviert, von PM und Entwicklung bis hin zum QS-Ingenieur.
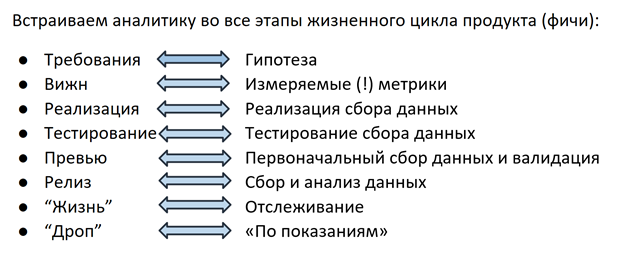
Hypothese
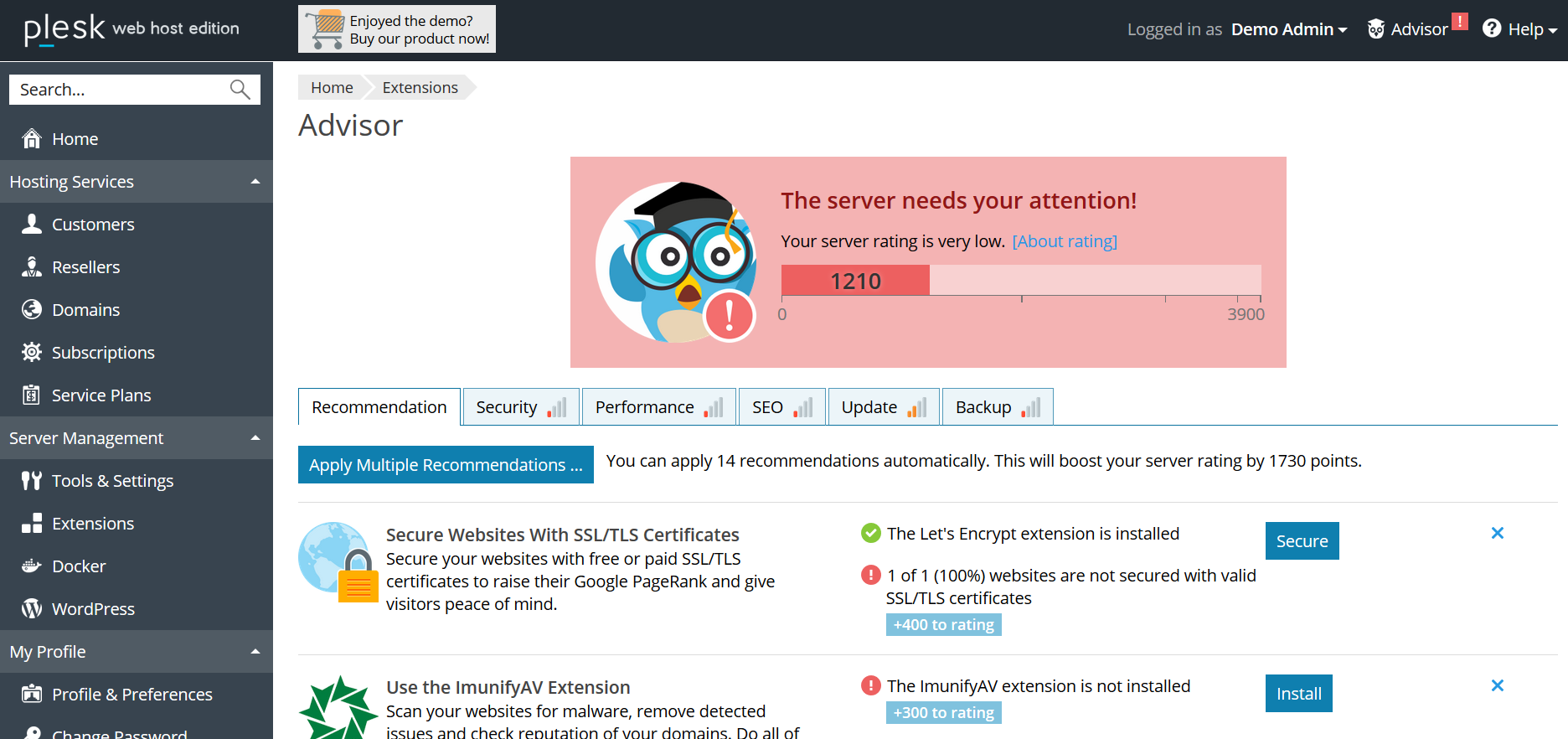
Alles beginnt in der Phase der Feature-Planung: PM formuliert eine Hypothese, auf deren Grundlage die Metrik im nächsten Schritt ausgewählt wird. Beispiel: Plesk verfügt über ein Advisor-Empfehlungssystem, mit dessen Hilfe der Benutzer den Status des Servers verbessern kann, indem er die vorgeschlagenen Schritte ausführt (SSL-Zertifikat hinzufügen, Updates aktivieren, PHP-Version aktualisieren usw.). Durch die Freigabe von Advisor gehen wir davon aus, dass der Benutzer den Empfehlungen folgt, die "Gesundheits" -Rating des Servers steigt und dank spielerischer "Erfolge" der Benutzer kontinuierlich in die Interaktion mit dem Advisor einbezogen wird.
Metrisch
Im nächsten Schritt wird für jede Hypothese eine Metrik ausgewählt: Für Advisor ist dies die Anzahl der Click-throughs in den Empfehlungen, der Prozentsatz der durch Zertifikate geschützten Websites, die Bewertung usw. Alle diese Informationen (Hypothese + Metriken) werden in das Vision - Dokument mit den Anforderungen für Funktionen eingegeben. Zu diesem Zeitpunkt sind Datenanalysten in den Prozess involviert. Ihre Aufgabe ist es, die Metrik messbar, einfach zu erfassen und eindeutig zu machen. Auch Details wie die Struktur des zukünftigen Felds in der Datenbank oder im Bericht sind wichtig. Da der für das Feature verantwortliche PM häufig auf diese Informationen zugreift, liegt es in seinem Interesse, zu bestimmen, wie dies bis zur gewünschten Struktur der Datenbankanforderung bequemer ist. Dank dieses Ansatzes ist es übrigens für alle einfacher geworden, da der Bedarf an 100.500 Quellen erheblich gesunken ist. Jetzt entscheiden Sie, in welchem Format die Daten erfasst werden und wie Sie sie bevorzugen. Durch das Festlegen der Zähllogik in einer Ansicht erhält der PM auch jederzeit die Möglichkeit, zum Dokument zurückzukehren und sich daran zu erinnern, nach welchen Kriterien die Datenbank in den Zähler gelangt / den Zähler erhöht / die Tatsache des Sendens usw. Dies löst das Problem des Verständnisses der Logik von Berichten.
Implementierung
Wenn eine Hypothese formuliert und eine Metrik ausgewählt wird, ist die Implementierung an der Reihe. Entwickler implementieren gleichzeitig das Feature selbst und den Mechanismus zum Sammeln seiner Statistiken. Wie bereits erwähnt, ist die Verwendung von vorgefertigten Lösungen wie GA aus verschiedenen Gründen für uns schwierig. Daher haben unsere Ingenieure vor zwei Jahren einen eigenen Mechanismus zur Verfolgung von Benutzeraktionen im Panel implementiert. Neben Benutzeraktionen können auch verschiedene technische Details, Konfigurationseinstellungen usw. von Interesse sein. - All dies wird an die bereits erwähnte MongoDB-Datenbank gesendet.
Testen und Vorschau
Wie bei jedem Produkt sollte der Datenerfassungsmechanismus getestet werden. In unserem Fall überprüft der QS-Techniker, ob die Empfehlungen angezeigt und geöffnet werden, die Bewertung wird überwacht und Informationen zu all diesen Ereignissen werden in der Datenbank erfasst. Häufig werden die für die Nachverfolgung und Analyse ausgewählten Anwendungsfälle zu neuen Testfällen, um die Funktionalität der Funktion selbst zu testen.
Nachdem der QS-Ingenieur alle Szenarien überprüft hatte, überprüfte der PM zusammen mit dem Entwickler die ersten Daten und stellte sicher, dass die Funktion 1) nichts kaputt machte und 2) wie erwartet funktioniert, und die Statistiken sammeln, was ihn interessiert - alles ist bereit für die Veröffentlichung in freigeben.
Feature-Leben
Wenn ein Feature in einer Version gestartet wird, beginnt der interessanteste Teil - sein „Leben“ im Produkt. Kein Werfen mehr: „Wissen Sie zufällig, in welchem Feld unserer Datenbank Informationen zum Anzeigen von Empfehlungen gespeichert sind? nein? blin ... ". Der Datenanalyst erhält keine Nachrichten in Ruhe: "Können Sie erneut zählen, wie viele Impressionen in der neuesten Version enthalten sind?" - Dazu gibt es Diagramme in Dashboards mit konfigurierten Warnungen, die Briefe senden, wenn der überwachte Wert stark gesunken / erhöht / geändert / keine Datensätze in der Datenbank gefunden wurden. Das ist aber noch nicht alles. Das Verständnis, dass der Zähler um n% gestiegen oder gefallen ist, reicht nicht immer aus, um mit Sicherheit zu sagen, dass dies eine signifikante Änderung ist und kein saisonaler Sprung oder eine Schwankung innerhalb der Fehlergrenze. Eines unserer Teammitglieder entwickelt ein Framework zur Messung der statistischen Signifikanz von metrischen Änderungen. Mit Hilfe der mathematischen Statistik berechnet er die Mindeststichprobe (Anzahl der Benutzer / Installationen / Ereignisse), die zur Beurteilung der Signifikanz von Änderungen erforderlich ist, wählt Segmente aus, zwischen denen Sie vergleichen können, und bestimmt das Konfidenzintervall, das höchstwahrscheinlich den tatsächlichen Wert der für uns interessanten Metrik enthält. Dieses Framework wurde bereits letzte Woche getestet und lieferte interessante Ergebnisse: Nachdem wir die Preise im Erweiterungskatalog im Plesk-Panel angezeigt hatten, kauften die Kunden weniger jährliche und häufiger monatliche Lizenzschlüssel für diese Produkte. Im Moment berechnen unsere Kollegen die LTV-Prognose. Danach wird klar, dass diese Änderungen langfristig für uns sind und welche Option wir in der Logik der Preisanzeige fördern sollten.
Beendigung der Unterstützung
Das Ergebnis der Lebensdauer eines Produkts oder einer Funktion ist die Beendigung des Supports für den Fall, dass dies auf mangelnde Nachfrage oder andere Gründe zurückzuführen ist (z. B. Sicherheitsaspekte bei Beendigung des Supports für ein veraltetes Betriebssystem oder eine veraltete Version von PHP). Hier hilft uns auch die Analyse: Als wir beispielsweise beschlossen, Benutzer zum Wechsel zu neuen PHP-Versionen zu ermutigen, haben wir zunächst Versionsnutzungsstatistiken unter Plesk-Benutzern gesammelt. Wir haben erfahren, dass der Prozentsatz, der PHP 7 verwendet, nur 20% der Benutzer erreicht, und festgestellt, dass die potenziellen Kosten eines erzwungenen Wechsels in Form von Millionen defekter Websites das Risiko möglicher Schwachstellen älterer Versionen überwiegen. Infolgedessen haben wir uns für mildere Einflussmaße entschieden und mit einer Benachrichtigung über die Wünschbarkeit eines Upgrades im Panel begonnen. Ein weiteres Beispiel können zahlreiche Geschichten sein, in denen die Unterstützung für Betriebssysteme eingestellt wurde. Als wir herausfanden, dass einer der größten Kunden mit Zehntausenden von Plesk-Installationen ein bestimmtes Betriebssystem verwendet, kommunizieren wir gezielt mit diesem Partner und bieten ihn an, falls ein schneller Übergang unmöglich ist Der sogenannte Lazy Drop - die Beendigung des Supports für neue Installationen und die Möglichkeit, nach dem Upgrade auf die neueste Version von Plesk weiter an vorhandenen zu arbeiten.
Fazit
Zusammenfassend möchte ich noch einmal sagen, was wir für das Wichtigste halten - jetzt ist die Arbeit mit Analytics für uns ein wesentlicher Bestandteil der Arbeit an jeder Funktion. Aber der erstellte Prozess ist nicht das Ende. Aus eigener Erfahrung waren wir davon überzeugt, dass die Datenqualitätskontrolle nicht weniger wichtig ist als der Prozess selbst. Alles macht keinen Sinn, wenn zu irgendeinem Zeitpunkt der Sammlung die Daten verloren gehen oder verzerrt werden. Um dies zu verhindern, bemühen wir uns in jeder Phase, die Vollständigkeit und Richtigkeit der Daten zu überprüfen und jeden Verarbeitungsschritt zu protokollieren.

Und der letzte. Wiegen Sie sich nicht mit Metriken, nur weil Sie können :) Geben Sie klar an, was diese Informationen für Sie sind, und fragen Sie sich, wenn sie empfangen werden, ob sie eine Schlussfolgerung enthalten, die zu Maßnahmen führt. Zu verstehen, was zu tun ist, ist genau das, wofür alles begonnen wurde :)