Wir haben uns bereits mit dem
Puffer-Cache- Gerät vertraut gemacht, einem der Hauptobjekte im gemeinsam genutzten Speicher, und festgestellt, dass Sie ein
Voraufzeichnungsprotokoll führen müssen, um einen Fehler zu beheben, wenn der Inhalt des RAM verloren geht.
Das ungelöste Problem, das wir beim letzten Mal gestoppt haben, ist, dass nicht bekannt ist, zu welchem Zeitpunkt Sie die Protokolle während der Wiederherstellung wiedergeben können. Von Anfang an zu funktionieren, wie der König von
Alice geraten hat, wird nicht funktionieren: Es ist unmöglich, alle Journaleinträge vom Serverstart an zu speichern - dies ist möglicherweise eine große Menge und dieselbe große Wiederherstellungszeit. Wir brauchen einen solchen Schritt vorwärts, von dem aus wir mit der Wiederherstellung beginnen können (und dementsprechend alle vorherigen Journaleinträge sicher löschen können). Dies ist der
Kontrollpunkt , der heute diskutiert wird.
Kontrollpunkt
Welche Eigenschaft sollte ein Kontrollpunkt haben? Wir müssen sicher sein, dass alle Journaleinträge, beginnend mit dem Prüfpunkt, auf Seiten angewendet werden, die auf die Festplatte geschrieben wurden. Wenn dies nicht der Fall wäre, könnten wir während der Wiederherstellung eine zu alte Version der Seite von der Festplatte lesen und einen Journaleintrag darauf anwenden, wodurch die Daten unwiderruflich beschädigt würden.
Wie bekomme ich einen Haltepunkt? Die einfachste Möglichkeit besteht darin, das System regelmäßig anzuhalten und alle verschmutzten Seiten des Puffers und anderer Caches auf die Festplatte zu leeren. (Beachten Sie, dass Seiten nur geschrieben, aber nicht aus dem Cache ausgeworfen werden.) Solche Punkte erfüllen die Bedingung, aber natürlich möchte niemand mit einem System arbeiten, das auf unbestimmte, aber sehr wichtige Zeit ständig einfriert.
In der Praxis ist daher alles etwas komplizierter: Ein Kontrollpunkt von einem Punkt wird zu einem Segment. Zuerst
starten wir
den Haltepunkt. Danach, ohne die Arbeit zu unterbrechen und wenn möglich, ohne Spitzenlasten zu erzeugen, werfen wir langsam schmutzige Puffer auf die Festplatte.

Wenn alle Puffer geschrieben wurden,
die zu Beginn des Prüfpunkts verschmutzt waren, wird der Prüfpunkt als
vollständig betrachtet . Jetzt (aber nicht früher) können wir den Startpunkt als den Punkt verwenden, von dem aus Sie mit der Wiederherstellung beginnen können. Und die Journaleinträge bis zu diesem Punkt brauchen wir nicht mehr.

Der Checkpoint wird von einem speziellen Hintergrund-Checkpointer-Prozess behandelt.
Die Dauer verschmutzter Puffer wird durch den Wert des Parameters
checkpoint_completion_target bestimmt. Es zeigt an, wie viel Zeit zwischen zwei benachbarten Kontrollpunkten die Aufzeichnung stattfinden wird. Der Standardwert ist 0,5 (wie in den obigen Abbildungen), dh die Aufzeichnung dauert die Hälfte der Zeit zwischen den Kontrollpunkten. Typischerweise wird der Wert für eine größere Gleichmäßigkeit auf 1,0 erhöht.
Betrachten wir genauer, was passiert, wenn ein Kontrollpunkt ausgeführt wird.
Der Prüfpunktprozess löscht zuerst die Transaktionsstatuspuffer (XACT) auf die Festplatte. Da es nur wenige davon gibt (insgesamt 128), werden sie sofort aufgezeichnet.
Dann beginnt die Hauptarbeit - das Schreiben schmutziger Seiten aus dem Puffercache. Wie bereits erwähnt, können nicht alle Seiten gleichzeitig zurückgesetzt werden, da die Größe des Puffercaches erheblich sein kann. Daher werden zunächst alle aktuell verschmutzten Seiten im Puffercache in den Headern mit einem speziellen Flag markiert.
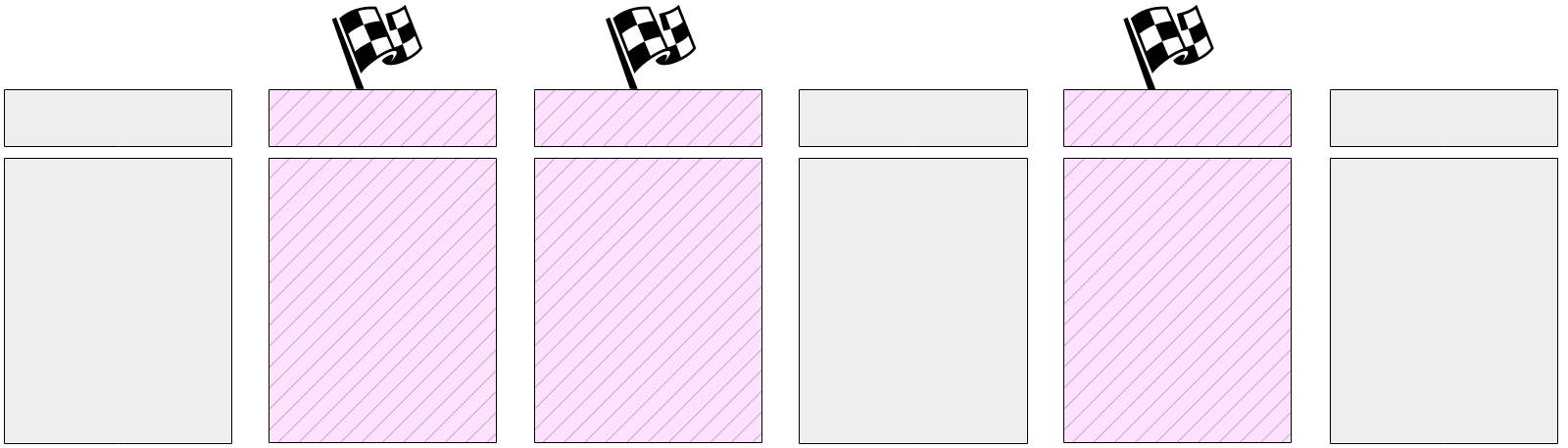
Und dann durchläuft der Checkpoint-Prozess nach und nach alle Puffer und löscht die auf der Festplatte markierten. Denken Sie daran, dass Seiten nicht aus dem Cache ausgeworfen, sondern nur auf die Festplatte geschrieben werden, sodass Sie nicht auf die Anzahl der Aufrufe des Puffers oder dessen Korrektur achten müssen.
Beschriftete Puffer können auch von Serverprozessen geschrieben werden - je nachdem, wer zuerst in den Puffer gelangt. In jedem Fall wird das zuvor gesetzte Flag bei der Aufzeichnung entfernt, sodass (zum Zweck des Prüfpunkts) der Puffer nur einmal geschrieben wird.
Während der Ausführung des Prüfpunkts ändern sich die Seiten natürlich weiterhin im Puffercache. Neue verschmutzte Puffer werden jedoch nicht markiert, und der Checkpoint-Prozess sollte sie nicht schreiben.
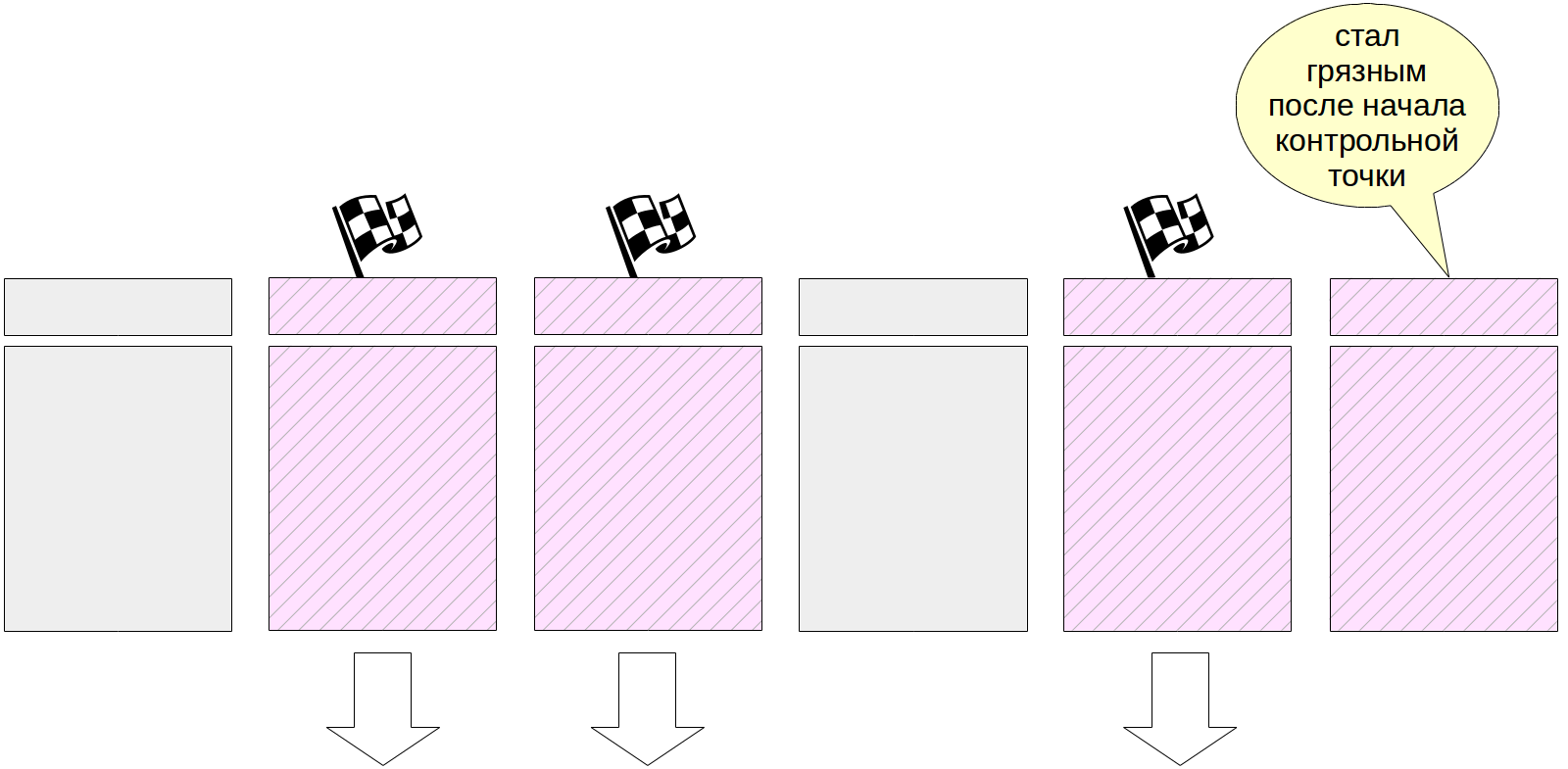
Am Ende seiner Arbeit erstellt der Prozess einen Journaleintrag für das Ende des Prüfpunkts. Dieser Datensatz enthält die LSN des Arbeitsbeginns des Kontrollpunkts. Da der Kontrollpunkt zu Beginn seiner Arbeit nichts in das Protokoll schreibt, kann dieser LSN einen beliebigen Protokolldatensatz enthalten.
Darüber hinaus aktualisiert die Datei $ PGDATA / global / pg_control die Angabe des zuletzt übergebenen Prüfpunkts. Bevor der Prüfpunkt abgeschlossen ist, zeigt pg_control auf den vorherigen Prüfpunkt.

Um die Arbeit des Prüfpunkts zu betrachten, erstellen Sie eine Tabelle. Die Seiten werden in den Puffercache verschoben und sind verschmutzt:
=> CREATE TABLE chkpt AS SELECT * FROM generate_series(1,10000) AS g(n); => CREATE EXTENSION pg_buffercache; => SELECT count(*) FROM pg_buffercache WHERE isdirty;
count ------- 78 (1 row)
Merken Sie sich die aktuelle Position im Protokoll:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 0/3514A048 (1 row)
Jetzt führen wir den Prüfpunkt manuell aus und stellen sicher, dass sich keine fehlerhaften Seiten im Cache befinden (wie gesagt, es können neue fehlerhafte Seiten angezeigt werden, aber in unserem Fall gab es keine Änderungen im Prozess der Ausführung des Prüfpunkts):
=> CHECKPOINT; => SELECT count(*) FROM pg_buffercache WHERE isdirty;
count ------- 0 (1 row)
Mal sehen, wie sich der Prüfpunkt im Protokoll widerspiegelte:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 0/3514A0E4 (1 row)
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A048 -e 0/3514A0E4
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/3514A048, prev 0/35149CEC, desc: RUNNING_XACTS nextXid 101105 latestCompletedXid 101104 oldestRunningXid 101105
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A07C, prev 0/3514A048, desc: CHECKPOINT_ONLINE redo 0/3514A048; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 101105; online
Hier sehen wir zwei Einträge. Der letzte ist eine Aufzeichnung des Passierens des Kontrollpunkts (CHECKPOINT_ONLINE). Die LSN des Starts des Prüfpunkts wird nach dem Wort "Wiederherstellen" angezeigt, und diese Position entspricht dem Journaleintrag, der der letzte am Anfang des Prüfpunkts war.
Wir finden die gleichen Informationen in der Kontrolldatei:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | egrep 'Latest.*location'
Latest checkpoint location: 0/3514A07C Latest checkpoint's REDO location: 0/3514A048
Wiederherstellung
Jetzt sind wir bereit, den im vorherigen Artikel beschriebenen Wiederherstellungsalgorithmus zu klären.
Wenn der Server beim nächsten Start abstürzt, erkennt der Startvorgang dies, indem er sich die Datei pg_control ansieht und einen anderen Status als "Herunterfahren" anzeigt. In diesem Fall wird eine automatische Wiederherstellung durchgeführt.
Zunächst liest der Wiederherstellungsprozess aus derselben pg_control die Position des Starts des Kontrollpunkts. (Um das Bild zu vervollständigen, stellen wir fest, dass, wenn die Datei backup_label vorhanden ist, der Datensatz des Kontrollpunkts daraus gelesen wird. Dies ist für die Wiederherstellung aus Sicherungen erforderlich, dies ist jedoch ein Thema für einen separaten Zyklus.)
Dann liest er das Magazin ausgehend von der gefundenen Position und wendet nacheinander Journaleinträge auf die Seiten an (falls erforderlich, wie wir es
letztes Mal besprochen
haben ).
Abschließend werden alle nicht journalisierten Tabellen mit Bildern in den Init-Dateien überschrieben.
Zu diesem Zeitpunkt wird der Startvorgang beendet und der Checkpointer-Prozess führt sofort einen Checkpoint aus, um den wiederhergestellten Status auf der Festplatte zu beheben.
Sie können einen Fehler simulieren, indem Sie den Server im Sofortmodus zwangsweise stoppen.
student$ sudo pg_ctlcluster 11 main stop -m immediate --skip-systemctl-redirect
(Der Schlüssel
--skip-systemctl-redirect wird hier benötigt, da PostgreSQL in Ubuntu aus dem Paket installiert wird. Er wird vom Befehl pg_ctlcluster gesteuert, der tatsächlich systemctl aufruft, und ruft bereits pg_ctl auf. Bei all diesen Wrappern wird der Modusname angegeben geht dabei verloren und mit dem
--skip-systemctl-redirect können Sie auf systemctl verzichten und wichtige Informationen speichern.)
Überprüfen Sie den Clusterstatus:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: in production
Beim Start erkennt PostgreSQL, dass ein Fehler aufgetreten ist und eine Wiederherstellung erforderlich ist.
student$ sudo pg_ctlcluster 11 main start
postgres$ tail -n 7 /var/log/postgresql/postgresql-11-main.log
2019-07-17 15:27:49.441 MSK [8865] LOG: database system was interrupted; last known up at 2019-07-17 15:27:48 MSK 2019-07-17 15:27:49.801 MSK [8865] LOG: database system was not properly shut down; automatic recovery in progress 2019-07-17 15:27:49.804 MSK [8865] LOG: redo starts at 0/3514A048 2019-07-17 15:27:49.804 MSK [8865] LOG: invalid record length at 0/3514A0E4: wanted 24, got 0 2019-07-17 15:27:49.804 MSK [8865] LOG: redo done at 0/3514A07C 2019-07-17 15:27:49.824 MSK [8864] LOG: database system is ready to accept connections 2019-07-17 15:27:50.409 MSK [8872] [unknown]@[unknown] LOG: incomplete startup packet
Die Notwendigkeit einer Wiederherstellung wird im Nachrichtenprotokoll vermerkt: Das
Datenbanksystem wurde nicht ordnungsgemäß heruntergefahren. automatische Wiederherstellung läuft . Anschließend werden die Journaleinträge an der unter „Wiederherstellen beginnt um“ markierten Position abgespielt und fortgesetzt, bis die nächsten Journaleinträge abgerufen werden können. Damit ist die Wiederherstellung an der Position "Wiederherstellen um" abgeschlossen, und das DBMS beginnt mit der Arbeit mit Clients (das
Datenbanksystem ist bereit, Verbindungen zu akzeptieren ).
Und was passiert beim normalen Herunterfahren des Servers? Um verschmutzte Seiten auf die Festplatte zu übertragen, trennt PostgreSQL alle Clients und führt dann den endgültigen Prüfpunkt aus.
Merken Sie sich die aktuelle Position im Protokoll:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 0/3514A14C (1 row)
Stoppen Sie nun vorsichtig den Server:
student$ sudo pg_ctlcluster 11 main stop
Überprüfen Sie den Clusterstatus:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: shut down
Und im Protokoll finden wir den einzigen Datensatz über den endgültigen Kontrollpunkt (CHECKPOINT_SHUTDOWN):
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A14C
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A14C, prev 0/3514A0E4, desc: CHECKPOINT_SHUTDOWN redo 0/3514A14C; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 0; shutdown
pg_waldump: FATAL: error in WAL record at 0/3514A14C: invalid record length at 0/3514A1B4: wanted 24, got 0
(In einer schrecklichen tödlichen Nachricht möchte pg_waldump nur sagen, dass er bis zum Ende des Magazins gelesen hat.)
Führen Sie die Instanz erneut aus.
student$ sudo pg_ctlcluster 11 main start
Hintergrundaufnahme
Wie wir herausgefunden haben, ist der Prüfpunkt einer der Prozesse, die schmutzige Seiten aus dem Puffercache auf die Festplatte schreiben. Aber nicht der einzige.
Wenn das Backend die Seite aus dem Puffer schieben muss und die Seite verschmutzt ist, muss es sie selbst auf die Festplatte schreiben. Dies ist eine schlechte Situation, die zu Erwartungen führt - es ist viel besser, wenn die Aufnahme asynchron im Hintergrund erfolgt.
Daher gibt es zusätzlich zum Checkpoint-
Prozess auch
einen Hintergrundaufzeichnungsprozess (Hintergrundschreiber, Bgwriter oder nur Schreiber). Dieser Prozess verwendet denselben Puffersuchalgorithmus wie der Preemption-Mechanismus. Grundsätzlich gibt es zwei Unterschiede.
- Es wird kein Zeiger auf das "nächste Opfer" verwendet, sondern ein eigener. Er kann dem Zeiger auf das "Opfer" voraus sein, bleibt aber nie hinter ihm zurück.
- Beim Durchlaufen von Puffern verringert sich der Trefferzähler nicht.
Es werden Puffer geschrieben, die gleichzeitig sind:
- geänderte Daten enthalten (verschmutzt),
- nicht fest (Pinanzahl = 0),
- habe null Treffer (Nutzungsanzahl = 0).
Der Hintergrundaufzeichnungsprozess läuft also sozusagen dem Verdrängen voraus und findet die Puffer, die wahrscheinlich bald überfüllt sein werden. Aus diesem Grund sollten Serviceprozesse im Idealfall feststellen, dass die von ihnen ausgewählten Puffer verwendet werden können, ohne das Schreiben anzuhalten.
Anpassung
Der Prüfpunktprozess wird normalerweise aus den folgenden Gründen konfiguriert.
Zuerst müssen Sie entscheiden, wie viele Protokolldateien wir uns leisten können (und welche Wiederherstellungszeit für uns geeignet ist). Je größer, desto besser, aber aus offensichtlichen Gründen wird dieser Wert begrenzt sein.
Als nächstes können wir berechnen, wie lange dieses Volumen unter normaler Last erzeugt wird. Wir haben bereits darüber nachgedacht, wie dies zu tun ist (wir müssen uns die Positionen im Journal merken und voneinander subtrahieren).
Diese Zeit ist unser übliches Intervall zwischen Kontrollpunkten. Wir schreiben es in den Parameter
checkpoint_timeout . Der Standardwert von 5 Minuten ist offensichtlich zu klein, normalerweise wird die Zeit beispielsweise auf eine halbe Stunde erhöht. Ich wiederhole: Je seltener Sie sich Meilensteine leisten können, desto besser - dies reduziert den Overhead.
Es ist jedoch möglich (und sogar wahrscheinlich), dass die Last manchmal höher als normal ist und zu viele Journaleinträge in der im Parameter angegebenen Zeit generiert werden. In diesem Fall möchte ich den Kontrollpunkt öfter ausführen. Dazu geben wir im Parameter
max_wal_size den Betrag an, der innerhalb desselben Kontrollpunkts gültig ist. Wenn das tatsächliche Volumen mehr erreicht wird, initiiert der Server einen außerplanmäßigen Prüfpunkt.
Daher treten die meisten Kontrollpunkte nach einem Zeitplan auf: einmal pro
checkpoint_timeout- Zeiteinheit. Bei erhöhter Last wird der Kontrollpunkt jedoch häufiger aufgerufen, wenn das Volumen
max_wal_size erreicht ist .
Es ist wichtig zu verstehen, dass der Parameter
max_wal_size überhaupt nicht die maximale Menge bestimmt, die Protokolldateien auf der Festplatte belegen können.
- Um einen Fehler zu beheben, müssen Sie die Dateien ab dem Zeitpunkt speichern, an dem der letzte Prüfpunkt übergeben wurde, sowie die Dateien, die sich während des Betriebs des aktuellen Prüfpunkts angesammelt haben. Daher kann das Gesamtvolumen grob geschätzt werden als
(1 + checkpoint_completion_target ) × max_wal_size . - Vor Version 11 hat PostgreSQL auch Dateien für den zwei Jahre alten Prüfpunkt gespeichert. Bis zu Version 10 in der obigen Formel müssen Sie also 2 anstelle von 1 festlegen.
- Der Parameter max_wal_size ist nur ein Wunsch, aber keine feste Grenze. Es kann sich herausstellen, mehr.
- Der Server ist nicht berechtigt, Protokolldateien zu löschen, die noch nicht über die Replikationssteckplätze übertragen wurden und die während der kontinuierlichen Archivierung noch nicht archiviert wurden. Wenn diese Funktionalität verwendet wird, ist eine ständige Überwachung erforderlich, da der Serverspeicher leicht überlaufen kann.
Um das Bild zu vervollständigen, können Sie nicht nur die maximale Lautstärke, sondern auch die minimale Lautstärke
einstellen : Parameter
min_wal_size . Die Bedeutung dieser Einstellung ist, dass der Server keine Dateien löscht, während sie in das Volume in
min_wal_size passen, sondern sie einfach umbenennt und erneut verwendet. Dies spart Ihnen ein wenig, indem Sie ständig Dateien erstellen und löschen.
Die Hintergrundaufzeichnung ist nach der Konfiguration des Prüfpunkts sinnvoll zu konfigurieren. Zusammen müssen diese Prozesse Zeit haben, um verschmutzte Puffer zu schreiben, bevor sie von Wartungsprozessen benötigt werden.
Der Hintergrundaufzeichnungsprozess läuft in Zyklen von höchstens
bgwriter_lru_maxpages- Seiten ab und schläft zwischen den Zyklen auf
bgwriter_delay ein .
Die Anzahl der Seiten, die in einem Arbeitszyklus aufgezeichnet werden, wird durch die durchschnittliche Anzahl der Puffer bestimmt, die von Wartungsprozessen aus dem letzten Lauf angefordert wurden (unter Verwendung eines gleitenden Durchschnitts, um die Ungleichmäßigkeiten zwischen den Läufen auszugleichen, hängt jedoch nicht von einer langen Historie ab). Die berechnete Anzahl von Puffern wird mit dem Koeffizienten
bgwriter_lru_multiplier multipliziert (in jedem Fall wird
bgwriter_lru_maxpages jedoch nicht überschritten).
Standardwerte:
bgwriter_delay = 200 ms (höchstwahrscheinlich zu viel, es
tritt in 1/5 Sekunde viel Wasser aus),
bgwriter_lru_maxpages = 100,
bgwriter_lru_multiplier = 2.0 (wir versuchen, vorzeitig auf die Nachfrage zu reagieren).
Wenn der Prozess überhaupt keine verschmutzten Puffer erkennt (dh im System passiert nichts), wird er in den Ruhezustand versetzt, woraus abgeleitet wird, dass der Serverprozess auf den Puffer zugreift. Danach wacht der Prozess auf und funktioniert wieder wie gewohnt.
Überwachung
Die Einstellungen für Kontrollpunkt und Hintergrundaufzeichnung können und sollten angepasst werden, um Feedback von der Überwachung zu erhalten.
Der Parameter
checkpoint_warning zeigt eine Warnung an, wenn Prüfpunkte, die durch Überläufe der Protokolldateigröße verursacht werden, zu häufig ausgeführt werden. Der Standardwert beträgt 30 Sekunden und muss mit dem Wert von
checkpoint_timeout in Einklang gebracht werden.
Der Parameter
log_checkpoints (standardmäßig deaktiviert) ermöglicht den Empfang von Informationen zu den ausgeführten Prüfpunkten im Servernachrichtenprotokoll. Schalten Sie es ein.
=> ALTER SYSTEM SET log_checkpoints = on; => SELECT pg_reload_conf();
Ändern Sie nun etwas in den Daten und führen Sie den Prüfpunkt aus.
=> UPDATE chkpt SET n = n + 1; => CHECKPOINT;
Im Nachrichtenprotokoll sehen wir ungefähr Folgendes:
postgres$ tail -n 2 /var/log/postgresql/postgresql-11-main.log
2019-07-17 15:27:55.248 MSK [8962] LOG: checkpoint starting: immediate force wait 2019-07-17 15:27:55.274 MSK [8962] LOG: checkpoint complete: wrote 79 buffers (0.5%); 0 WAL file(s) added, 0 removed, 0 recycled; write=0.001 s, sync=0.013 s, total=0.025 s; sync files=2, longest=0.011 s, average=0.006 s; distance=1645 kB, estimate=1645 kB
Hier können Sie sehen, wie viele Puffer geschrieben wurden, wie sich die Zusammensetzung der Protokolldateien nach dem Kontrollpunkt geändert hat, wie lange der Kontrollpunkt gedauert hat und wie weit (in Byte) die benachbarten Kontrollpunkte voneinander entfernt sind.
Die wahrscheinlich nützlichste Information ist jedoch die Statistik der Arbeit von Prüfpunkt- und Hintergrundaufzeichnungsprozessen in der Ansicht pg_stat_bgwriter. Die Ansicht ist eins für zwei, da beide Aufgaben einmal von einem Prozess ausgeführt wurden. dann wurden ihre Funktionen geteilt, und die Sicht blieb.
=> SELECT * FROM pg_stat_bgwriter \gx
-[ RECORD 1 ]---------+------------------------------ checkpoints_timed | 0 checkpoints_req | 1 checkpoint_write_time | 1 checkpoint_sync_time | 13 buffers_checkpoint | 79 buffers_clean | 0 maxwritten_clean | 0 buffers_backend | 42 buffers_backend_fsync | 0 buffers_alloc | 363 stats_reset | 2019-07-17 15:27:49.826414+03
Hier sehen wir unter anderem die Anzahl der abgeschlossenen Kontrollpunkte:
- checkpoints_timed - gemäß Zeitplan (bei Erreichen von checkpoint_timeout),
- checkpoints_req - auf Anfrage (auch bei Erreichen von max_wal_size).
Der große Wert von checkpoint_req (im Vergleich zu checkpoints_timed) zeigt an, dass Kontrollpunkte häufiger als erwartet auftreten.
Wichtige Informationen zur Anzahl der aufgezeichneten Seiten:
- buffers_checkpoint - Checkpoint-Prozess,
- buffers_backend - durch Serving von Prozessen,
- buffers_clean - Hintergrundaufzeichnungsprozess.
Auf einem gut abgestimmten System sollte der Wert von buffers_backend wesentlich kleiner sein als die Summe von buffers_checkpoint und buffers_clean.
Maxwritten_clean ist auch nützlich, um die Hintergrundaufzeichnung
einzurichten . Diese Zahl gibt an, wie oft der Hintergrundaufzeichnungsprozess aufgrund von Überschreitungen von
bgwriter_lru_maxpages nicht mehr
funktioniert .
Sie können die akkumulierten Statistiken mit dem folgenden Aufruf zurücksetzen:
=> SELECT pg_stat_reset_shared('bgwriter');
Fortsetzung folgt .