Wir möchten unser neues Tool für die Text-Tokenisierung vorstellen - YouTokenToMe. Es funktioniert 7-10 Mal schneller als andere gängige Versionen in Sprachen, die in ihrer Struktur der europäischen ähnlich sind, und 40-50 Mal - in asiatischen Sprachen. Wir sprechen über YouTokenToMe und teilen es Ihnen in Open Source auf GitHub mit. Link am Ende des Artikels!

Heutzutage besteht ein erheblicher Teil der Aufgaben für neuronale Netzwerkalgorithmen in der Textverarbeitung. Da neuronale Netze jedoch mit Zahlen arbeiten, muss der Text konvertiert werden, bevor er in das Modell übertragen wird.
Wir listen die gängigen Lösungen auf, die normalerweise dafür verwendet werden:
- Raumpause
- regelbasierte Algorithmen: spaCy, NLTK;
- Stemming, Lemmatisierung.
Jeder von ihnen hat seine eigenen Nachteile:
- Sie können die Größe des Token-Wörterbuchs nicht steuern. Die Größe der Einbettungsschicht im Modell hängt direkt davon ab.
- Informationen über die Verwandtschaft von Wörtern, die sich durch Suffixe oder Präfixe unterscheiden, werden nicht verwendet, zum Beispiel: höflich - unhöflich;
- abhängig von der Sprache.
In letzter Zeit war der Ansatz der
Byte-Paar-Codierung beliebt. Ursprünglich war dieser Algorithmus für die Textkomprimierung vorgesehen, vor einigen Jahren wurde er jedoch zum Tokenisieren von Text in der maschinellen Übersetzung verwendet. Jetzt wird es für eine Vielzahl von Aufgaben verwendet, einschließlich der in den BERT- und GPT-2-Modellen verwendeten.
Die effektivsten BPE-Implementierungen waren
SentencePiece , entwickelt von Google-Ingenieuren, und
fastBPE , erstellt von Facebook AI Research. Es ist uns jedoch gelungen zu beweisen, dass die Tokenisierung erheblich beschleunigt werden kann. Wir haben den BPE-Algorithmus optimiert, den Quellcode veröffentlicht und das fertige Paket im Pip-Repository veröffentlicht.
Im Folgenden können Sie die Ergebnisse der Messung der Geschwindigkeit unseres Algorithmus und anderer Versionen vergleichen. Als Beispiel haben wir die ersten 100 MB
des Wikipedia-Datenkorpus in Russisch, Englisch, Japanisch und Chinesisch verwendet.
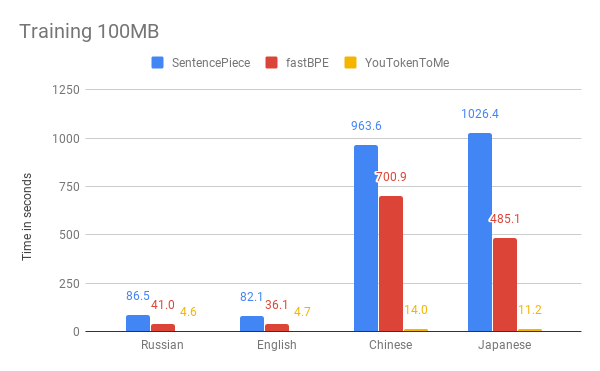

Die Grafiken zeigen, dass die Betriebszeit wesentlich von der Sprache abhängt. Dies liegt daran, dass asiatische Sprachen mehr Alphabete haben und Wörter nicht durch Leerzeichen getrennt sind. YouTokenToMe arbeitet 7-10-mal schneller in Sprachen, deren Struktur der europäischen ähnelt, und 40-50-mal in asiatischen Sprachen. Die Tokenisierung wurde mindestens zweimal und in einigen Tests mehr als zehnmal beschleunigt.
Diese Ergebnisse haben wir dank zweier Schlüsselideen erzielt:
- Der neue Algorithmus hat eine lineare Laufzeit, abhängig von der Größe des Falles für das Training. Satzteil und fastBPE zeigen ein weniger effektives asymptotisches Verhalten.
- Der neue Algorithmus kann effektiv mehrere Streams sowohl im Lernprozess als auch im Tokenisierungsprozess verwenden - dies ermöglicht es Ihnen, die Beschleunigung um ein Vielfaches zu erhöhen.
Sie können YouTokenToMe über die Benutzeroberfläche verwenden, um über die Befehlszeile und direkt über Python zu arbeiten.
Weitere Informationen finden Sie im Repository:
github.com/vkcom/YouTokenToMe