
Vor fast 9 Jahren war Cloudflare ein winziges Unternehmen, aber ich habe nicht darin gearbeitet, ich war nur ein Kunde. Einen Monat nach dem Start von Cloudflare erhielt ich eine Benachrichtigung, dass DNS auf meiner jgc.org- Website anscheinend nicht funktioniert. Cloudflare hat eine Änderung an den Protokollpuffern vorgenommen , und es gab einen defekten DNS.
Ich schrieb sofort an Matthew Prince mit der Überschrift „Wo ist mein DNS?“ Und er schickte eine lange Antwort voller technischer Details ( lesen Sie die gesamte Korrespondenz hier ), auf die ich antwortete:
Von: John Graham Cumming
Datum: 7. Oktober 2010, 9:14 Uhr
Betreff: Re: Wo ist mein DNS?
An: Matthew Prince
Cooler Bericht, danke. Ich werde auf jeden Fall anrufen, wenn es Probleme gibt. Es lohnt sich wahrscheinlich, einen Beitrag darüber zu schreiben, wenn Sie alle technischen Informationen gesammelt haben. Ich denke, die Leute werden eine offene und ehrliche Geschichte mögen. Vor allem, wenn Sie Grafiken anhängen, um zu zeigen, wie der Datenverkehr nach dem Start gewachsen ist.
Ich habe eine gute Überwachung auf der Website und erhalte eine SMS über jeden Fehler. Die Überwachung zeigt, dass der Fehler von 13:03:07 bis 14:04:12 war. Tests werden alle fünf Minuten durchgeführt.
Ich bin sicher, Sie werden es herausfinden. Sie brauchen definitiv keine eigene Person in Europa? :-)
Und er antwortete:
Von: Matthew Prince
Datum: 7. Oktober 2010, 9:57 Uhr
Betreff: Re: Wo ist mein DNS?
An: John Graham Cumming
Vielen Dank. Wir haben allen geantwortet, die geschrieben haben. Ich gehe jetzt ins Büro und wir werden etwas auf dem Blog schreiben oder einen offiziellen Beitrag in unserem Bulletin Board veröffentlichen. Ich stimme vollkommen zu, Ehrlichkeit ist unser Alles.
Jetzt ist Cloudflare ein wirklich großes Unternehmen, ich arbeite darin und jetzt muss ich offen über unseren Fehler, seine Folgen und unser Handeln schreiben.
2. Juli Veranstaltungen
Am 2. Juli haben wir eine neue Regel in verwalteten Regeln für WAF bereitgestellt, aufgrund derer die Prozessorressourcen auf jedem Prozessorkern, der HTTP / HTTPS-Verkehr im Cloudflare-Netzwerk auf der ganzen Welt verarbeitet, aufgebraucht sind. Wir verbessern ständig die verwalteten Regeln für WAF als Reaktion auf neue Schwachstellen und Bedrohungen. Im Mai haben wir beispielsweise eine Regel hinzugefügt , um uns vor einer schwerwiegenden Sicherheitsanfälligkeit in SharePoint zu schützen. Der springende Punkt unserer WAF ist die Fähigkeit, Regeln schnell und global bereitzustellen.
Leider enthielt das Update vom letzten Donnerstag einen regulären Ausdruck, der für das Zurückverfolgen zu vieler Prozessorressourcen aufgewendet wurde, die für HTTP / HTTPS zugewiesen wurden. Dies betraf unsere Kernfunktionen für Proxy, CDN und WAF. Die Grafik zeigt, dass die Prozessorressourcen für die Bereitstellung von HTTP / HTTPS-Verkehr auf Servern in unserem Netzwerk fast 100% erreichen.
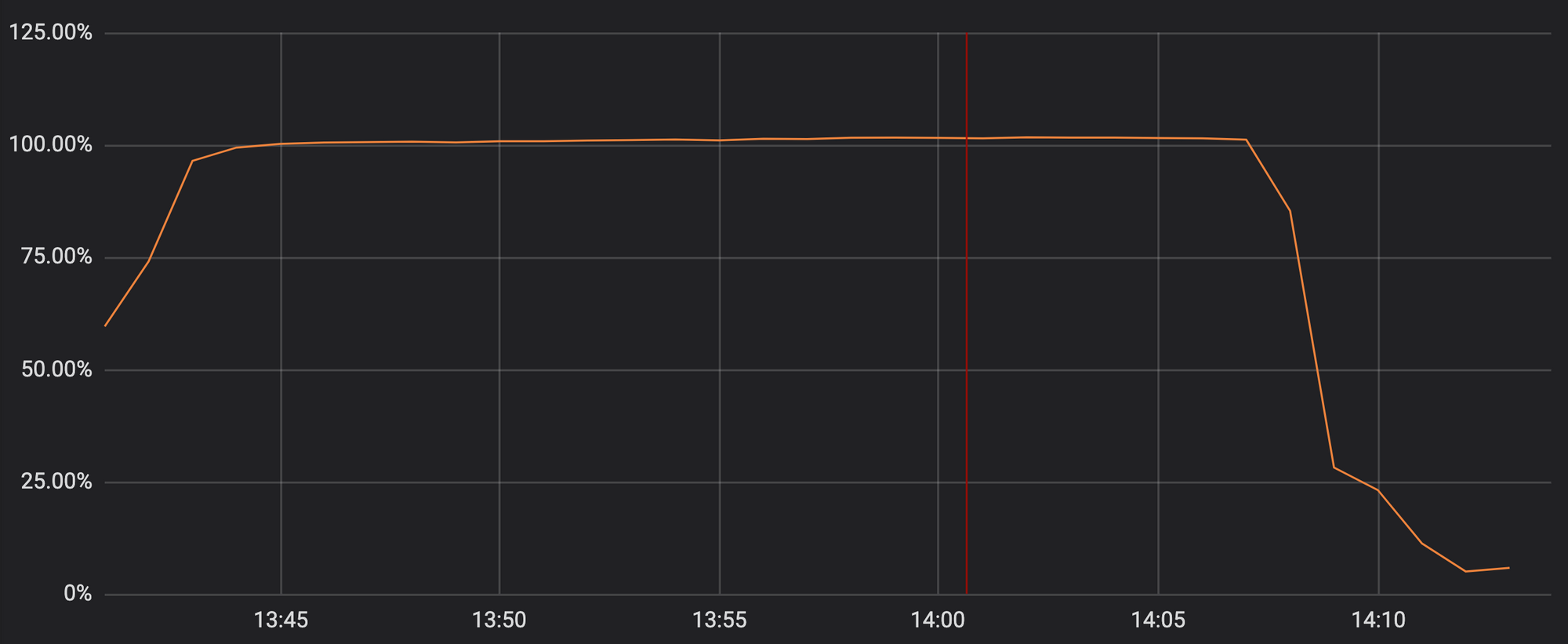
Verwenden von Prozessorressourcen an einem der Anwesenheitspunkte während eines Vorfalls
Infolgedessen stießen unsere Kunden (und die Kunden unserer Kunden) auf eine Seite mit einem 502-Fehler in den Cloudflare-Domänen. 502 Fehler wurden von Cloudflare-Front-End-Webservern generiert, die noch freie Kernel hatten, aber nicht mit Prozessen kommunizieren konnten, die HTTP / HTTPS-Verkehr verarbeiten.
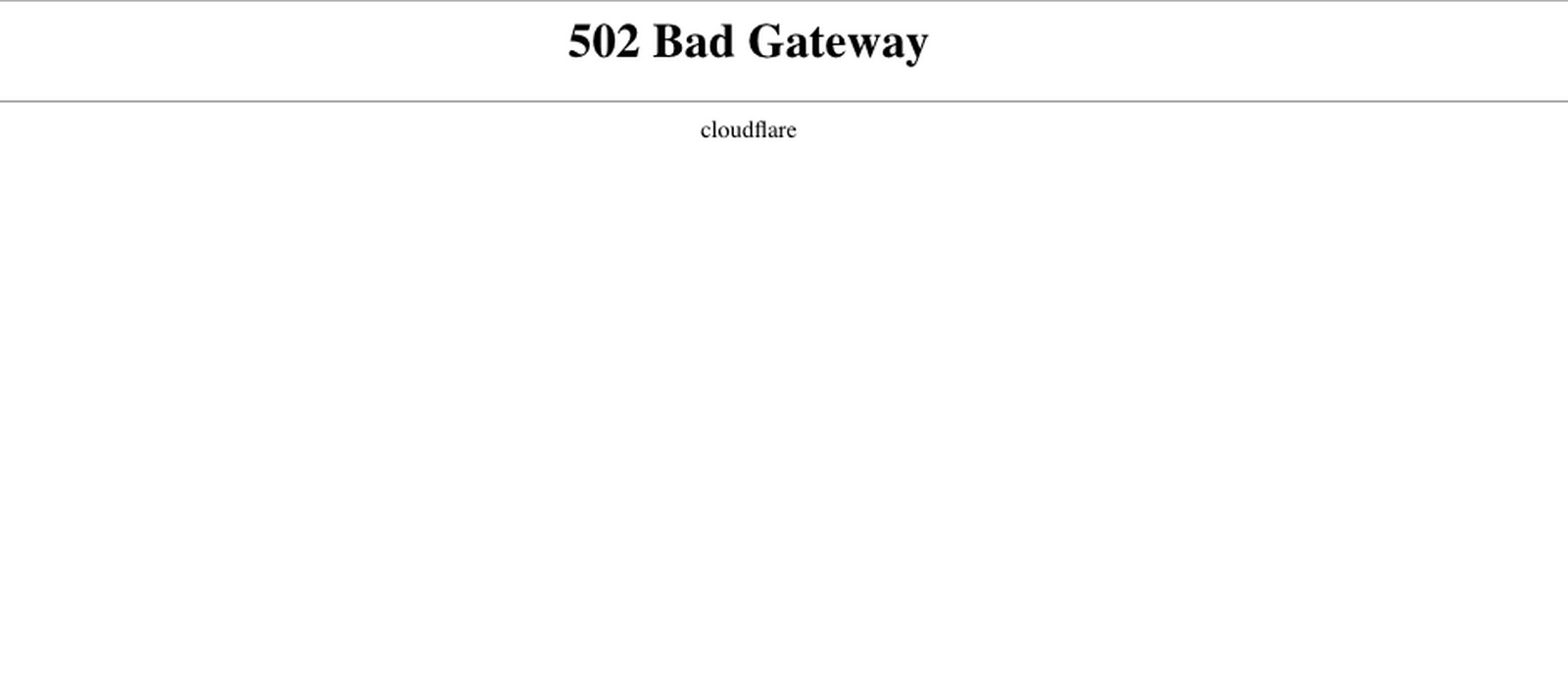
Wir wissen, wie viele Unannehmlichkeiten dies unseren Kunden verursacht hat. Wir schämen uns schrecklich. Und dieses Versagen hat uns daran gehindert, den Vorfall effektiv zu behandeln.
Wenn Sie einer dieser Kunden waren, hat es Sie wahrscheinlich erschreckt, verärgert und verärgert. Darüber hinaus haben wir seit 6 Jahren keine globalen Ausfälle mehr . Der hohe CPU-Verbrauch war auf eine WAF-Regel mit einem schlecht formulierten regulären Ausdruck zurückzuführen, die zu übermäßigem Backtracking führte. Hier ist der schuldige Ausdruck: (?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*)))
Obwohl es an sich interessant ist (und ich werde Ihnen weiter unten mehr darüber erzählen), wurde der Cloudflare-Dienst für 27 Minuten unterbrochen, nicht nur wegen unpassender regulärer Ausdrücke. Wir haben eine Weile gebraucht, um die Abfolge der Ereignisse zu beschreiben, die zum Ausfall geführt haben, sodass wir nicht schnell reagiert haben. Am Ende des Beitrags werde ich das Backtracking in regulären Ausdrücken beschreiben und Ihnen sagen, was Sie dagegen tun sollen.
Was ist passiert
Beginnen wir in der richtigen Reihenfolge. Alle Zeiten werden hier in UTC angezeigt.
Um 13:42 Uhr nahm ein Techniker des Firewall-Teams eine kleine Änderung an den Regeln für die Erkennung von XSS mithilfe eines automatischen Prozesses vor. Dementsprechend wurde ein Ticket für eine Änderungsanforderung erstellt. Wir verwalten diese Tickets über Jira (Screenshot unten).
Nach 3 Minuten wurde die erste PagerDuty-Seite angezeigt, auf der ein Problem mit WAF gemeldet wurde. Es war ein synthetischer Test, der die Funktionalität von WAF (wir haben Hunderte davon) außerhalb von Cloudflare überprüft, um den normalen Betrieb zu überwachen. Dann gab es sofort Seiten mit Benachrichtigungen über Fehler anderer End-to-End-Tests von Cloudflare-Diensten, globale Verkehrsprobleme, weit verbreitete 502-Fehler und eine Reihe von Berichten von unseren Points of Presence (PoP) in Städten auf der ganzen Welt, die auf einen Mangel an Prozessorressourcen hinwiesen.


Ich erhielt mehrere solcher Benachrichtigungen, fiel von der Besprechung ab und ging bereits zum Tisch, als der Leiter unserer Abteilung für Lösungsentwicklung sagte, dass wir 80% des Datenverkehrs verloren haben. Ich lief zu unseren SRE-Ingenieuren, die bereits an dem Problem arbeiteten. Zuerst dachten wir, es sei eine Art unbekannter Angriff.

Cloudflare SRE-Ingenieure sind auf der ganzen Welt verstreut und überwachen die Situation rund um die Uhr. In der Regel werden Sie durch solche Warnungen über bestimmte lokale Probleme mit begrenztem Umfang informiert, in internen Dashboards überwacht und mehrmals täglich behoben. Solche Seiten und Benachrichtigungen wiesen jedoch auf etwas wirklich Ernstes hin, und die SRE-Ingenieure kündigten sofort den Schweregrad P0 an und wandten sich an die Management- und Systemingenieure.
Unsere Londoner Ingenieure hörten gerade einen Vortrag in der Haupthalle. Der Vortrag musste unterbrochen werden, alle versammelten sich in einem großen Konferenzraum und weitere Experten wurden eingeladen. Dies war kein häufiges Problem, das SRE selbst herausfinden konnte. Es war dringend notwendig, die richtigen Spezialisten zusammenzubringen.
Um 14:00 Uhr stellten wir fest, dass es ein Problem mit WAF gab und es keinen Angriff gab. Die Leistungsabteilung rief Prozessordaten ab, und es wurde offensichtlich, dass WAF schuld war. Ein anderer Mitarbeiter bestätigte diese Theorie mit aller Kraft. Jemand anderes sah in den Protokollen, dass das Problem mit WAF. Um 14:02 Uhr kam das gesamte Team zu mir, als vorgeschlagen wurde, Global Kill zu verwenden - einen in Cloudflare integrierten Mechanismus, der eine Komponente auf der ganzen Welt deaktiviert.
Wie wir für WAF weltweit getötet haben, ist eine andere Geschichte. So einfach ist das nicht. Wir verwenden unsere eigenen Produkte, und da unser Access- Service nicht funktioniert hat, konnten wir uns nicht authentifizieren und das interne Kontrollfeld nicht betreten (als alles repariert wurde, haben wir erfahren, dass einige Mitglieder des Teams den Zugriff aufgrund einer Sicherheitsfunktion verloren haben, die Anmeldeinformationen deaktiviert, wenn Verwenden Sie das interne Bedienfeld nicht für längere Zeit.
Und wir konnten nicht zu unseren internen Diensten wie Jira oder dem Build-System gelangen. Wir brauchten eine Problemumgehung, die wir selten verwendeten (dies müsste auch ausgearbeitet werden). Schließlich konnte ein Ingenieur um 14:07 Uhr die WAF abhacken, und um 14:09 Uhr normalisierten sich das Verkehrsaufkommen und der Prozessor überall wieder. Der Rest der Abwehrmechanismen von Cloudflare funktionierte wie erwartet.
Dann machten wir uns daran, WAF wiederherzustellen. Die Situation war ungewöhnlich, daher führten wir negative Tests (bei denen wir uns fragten, ob das Problem wirklich diese Änderung war) und positive Tests (um sicherzustellen, dass der Rollback funktionierte) in einer Stadt mit separatem Verkehr durch und transferierten bezahlte Kunden von dort.
Um 14.52 Uhr waren wir überzeugt, dass wir den Grund verstanden und eine Korrektur vorgenommen hatten, und schalteten die WAF wieder ein.
Wie Cloudflare funktioniert
Cloudflare verfügt über ein Team von Ingenieuren, die verwaltete Regeln für WAF verwalten. Sie versuchen, die Erkennungsrate zu erhöhen, die Anzahl der Fehlalarme zu verringern und schnell auf neue Bedrohungen zu reagieren, sobald sie auftreten. In den letzten 60 Tagen wurden 476 Änderungsanforderungen für von WAF verwaltete Regeln verarbeitet (durchschnittlich eine alle 3 Stunden).
Diese spezielle Änderung musste im Simulationsmodus bereitgestellt werden, in dem der reale Clientverkehr die Regel durchläuft, aber nichts blockiert wird. Wir verwenden diesen Modus, um die Wirksamkeit der Regeln zu überprüfen und den Anteil falsch positiver und falsch negativer Ergebnisse zu messen. Aber auch im Simulationsmodus müssen die Regeln tatsächlich ausgeführt werden. In diesem Fall enthielt die Regel einen regulären Ausdruck, der zu viele Prozessorressourcen verbrauchte.
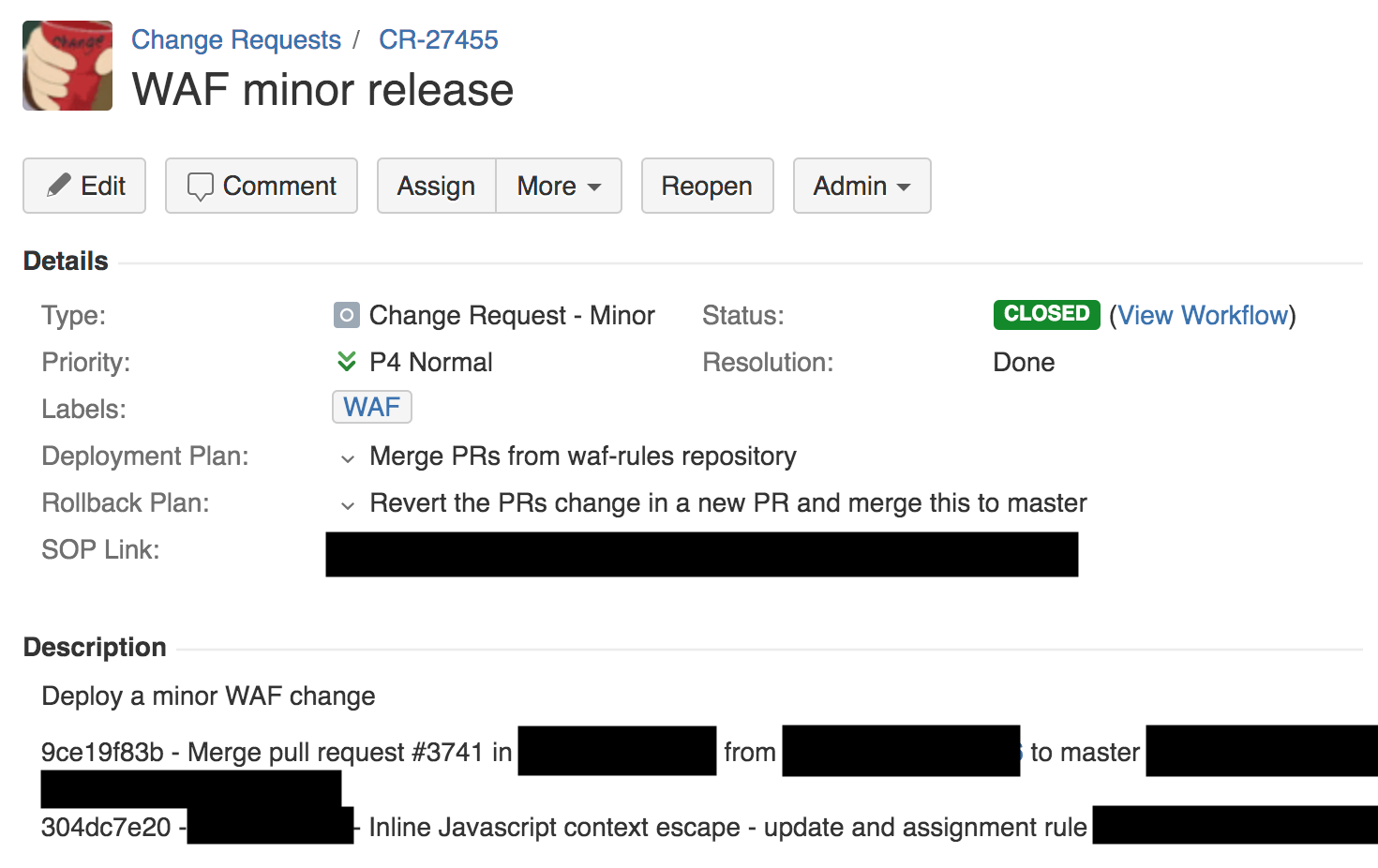
Wie Sie der obigen Änderungsanforderung entnehmen können, verfügen wir über einen Bereitstellungsplan, einen Rollback-Plan und einen Link zur internen Standardarbeitsanweisung (SOP) für diese Art der Bereitstellung. Mit SOP zum Ändern der Regel können Sie sie global veröffentlichen. Tatsächlich ist in Cloudflare alles völlig anders angeordnet, und SOP erfordert, dass die Software zum Testen und für den internen Gebrauch zuerst an einen internen Point of Presence (PoP) (den unsere Mitarbeiter verwenden), dann an eine kleine Anzahl von Clients an einem isolierten Ort, dann an eine große Anzahl von Clients und nur dann gesendet wird für die ganze Welt.
So sieht es aus. Wir verwenden Git im internen System über BitBucket. Die Änderungsingenieure senden den von ihnen erstellten Code an TeamCity, und wenn der Build erfolgreich ist, werden Prüfer zugewiesen. Wenn die Poolanforderung genehmigt wird, wird der Code gesammelt und eine Reihe von Tests (erneut) durchgeführt.
Wenn die Montage und die Tests erfolgreich sind, wird in Jira eine Änderungsanforderung erstellt, und die Änderung muss vom entsprechenden Vorgesetzten oder leitenden Spezialisten genehmigt werden. Nach der Genehmigung wird es in der sogenannten „PoP-Menagerie“ eingesetzt: HUND, SCHWEIN und Kanarienvogel (Hund, Mumps und Kanarienvogel).
DOG PoP ist Cloudflare PoP (wie jede andere unserer Städte), das nur von Cloudflare-Mitarbeitern verwendet wird. Mit PoP für den internen Gebrauch können Sie Probleme erkennen, noch bevor die Lösung Kundenverkehr empfängt. Nützliche Sache.
Wenn der DOG-Test erfolgreich ist, geht der Code zum PIG-Stadium (Meerschweinchen) über. Dies ist Cloudflare PoP, bei dem ein kleiner Teil des freien Clientverkehrs durch den neuen Code fließt.
Wenn alles in Ordnung ist, geht der Code an Canary. Wir haben drei kanarische PoPs in verschiedenen Teilen der Welt. Der Datenverkehr von bezahlten und kostenlosen Kunden durchläuft den neuen Code in ihnen, und dies ist die letzte Fehlerprüfung.

Release-Prozess für Cloudflare-Software
Wenn der Code in Canary in Ordnung ist, geben wir ihn frei. Das Durchlaufen aller Phasen - DOG, PIG, Canary, die ganze Welt - dauert je nach Codeänderung mehrere Stunden oder Tage. Aufgrund der Vielfalt des Cloudflare-Netzwerks und der Kunden testen wir den Code vor einer globalen Veröffentlichung für alle Kunden gründlich. WAF folgt diesem Prozess jedoch nicht speziell, da auf Bedrohungen schnell reagiert werden muss.
Bedrohungen WAF
In den letzten Jahren gab es bei herkömmlichen Anwendungen erheblich mehr Bedrohungen. Dies ist auf die höhere Verfügbarkeit von Softwaretest-Tools zurückzuführen. Zum Beispiel haben wir kürzlich über Fuzzing geschrieben .
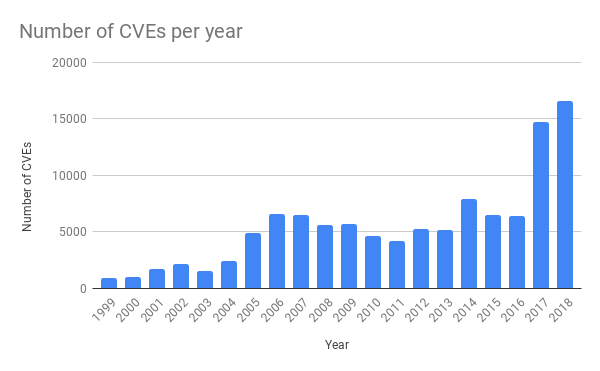
Quelle: https://cvedetails.com/
Sehr oft wird eine Bestätigung des Konzepts erstellt und sofort auf Github veröffentlicht, damit die Teams, die die Anwendung warten, sie schnell testen und sicherstellen können, dass sie angemessen geschützt ist. Daher muss Cloudflare in der Lage sein, so schnell wie möglich auf neue Angriffe zu reagieren, damit Kunden die Möglichkeit haben, ihre Software zu reparieren.
Ein gutes Beispiel für die schnelle Reaktion von Cloudflare ist die Bereitstellung des SharePoint-Schwachstellenschutzes im Mai ( siehe hier ). Fast unmittelbar nach der Veröffentlichung der Anzeigen haben wir eine Vielzahl von Versuchen festgestellt, die Sicherheitsanfälligkeit in den SharePoint-Installationen unserer Kunden auszunutzen. Unsere Mitarbeiter überwachen ständig neue Bedrohungen und schreiben Regeln, um unsere Kunden zu schützen.
Die Regel, die das Problem am Donnerstag verursachte, war der Schutz vor Cross-Site-Scripting (XSS). In den letzten Jahren gab es auch viele weitere derartige Angriffe.
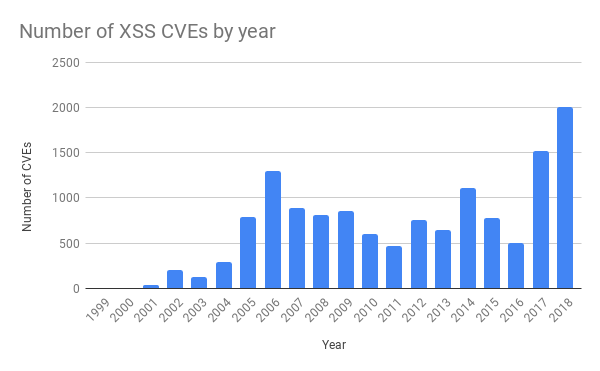
Quelle: https://cvedetails.com/
Das Standardverfahren zum Ändern einer verwalteten Regel für WAF erfordert kontinuierliche Integrationstests (CI) vor der globalen Bereitstellung. Letzten Donnerstag haben wir es geschafft und die Regeln erweitert. Um 13:31 Uhr schickte ein Ingenieur eine genehmigte Poolanfrage mit einer Änderung.
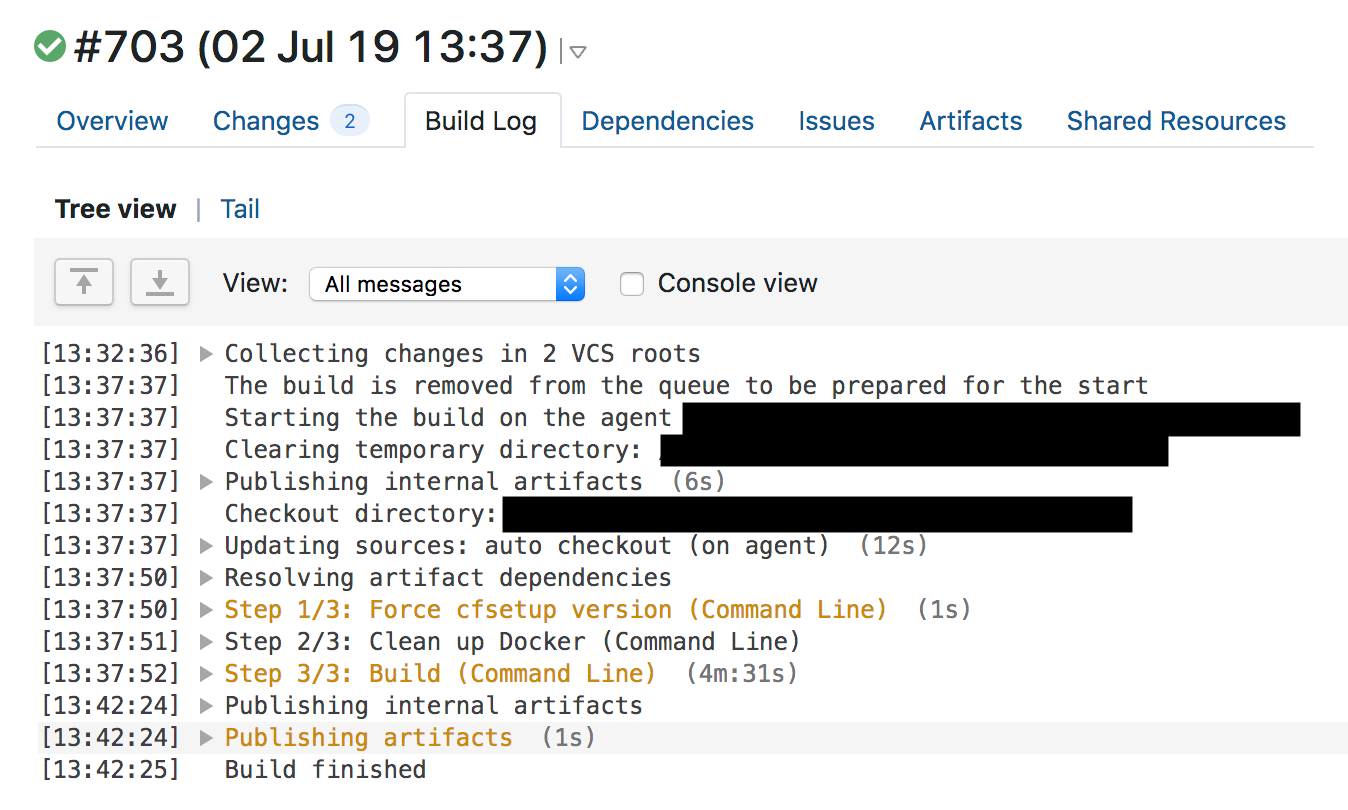
Um 13:37 Uhr sammelte TeamCity die Regeln, führte die Tests durch und gab den Startschuss. Die WAF-Testsuite testet die WAF-Kernfunktionalität und besteht aus einer Vielzahl von Komponententests für einzelne Funktionen. Nach Unit-Tests haben wir die Regeln für WAF mit einer großen Anzahl von HTTP-Anfragen überprüft. HTTP-Anforderungen prüfen, welche Anforderungen von WAF blockiert werden sollen (um den Angriff abzufangen) und welche übersprungen werden können (um nicht alles zu blockieren und Fehlalarme zu vermeiden). Wir haben jedoch keine Tests für die übermäßige Verwendung von Prozessorressourcen durchgeführt. Die Untersuchung der Protokolle früherer WAF-Assemblys zeigt, dass sich die Testausführungszeit mit der Regel nicht erhöht hat und es schwierig war zu vermuten, dass nicht genügend Ressourcen vorhanden waren.
Die Tests wurden bestanden und TeamCity begann um 13:42 Uhr, die Änderung automatisch bereitzustellen.
Quecksilber
WAF-Regeln befassen sich mit der dringenden Beseitigung von Bedrohungen. Daher stellen wir sie mithilfe der verteilten Schlüssel-Wert-Paare Quicksilver bereit, mit denen Änderungen innerhalb von Sekunden global verteilt werden. Alle unsere Kunden verwenden diese Technologie, wenn sie die Konfiguration im Dashboard oder über die API ändern. Dank dieser Reaktion reagieren wir blitzschnell auf Änderungen.
Wir haben ein wenig über Quecksilber gesprochen. Früher haben wir Kyoto Tycoon als global verteiltes Repository für Schlüssel-Wert-Paare verwendet, aber es gab Betriebsprobleme, und wir haben unser Repository in mehr als 180 Städten repliziert. Mit Quicksilver senden wir jetzt Änderungen an der Clientkonfiguration, aktualisieren WAF-Regeln und verteilen JavaScript-Code, der von Clients in Cloudflare Workers geschrieben wurde.
Es dauert nur wenige Sekunden, bis eine Konfiguration weltweit funktioniert, vom Drücken einer Taste auf einem Dashboard über das Aufrufen einer API bis hin zum Vornehmen von Konfigurationsänderungen. Kunden lieben diese Geschwindigkeitseinstellung. Und Workers bietet ihnen eine fast sofortige globale Softwarebereitstellung. Im Durchschnitt verteilt Quicksilver etwa 350 Änderungen pro Sekunde.
Und Quecksilber ist sehr schnell. Im Durchschnitt haben wir das 99. Perzentil von 2,29 Sekunden erreicht, um Änderungen auf jeden Computer auf der ganzen Welt zu übertragen. Normalerweise ist die Geschwindigkeit gut. Wenn Sie eine Funktion aktivieren oder den Cache leeren, geschieht dies schließlich fast sofort und überall. Das Senden von Code über Cloudflare Workers erfolgt mit derselben Geschwindigkeit. Cloudflare verspricht seinen Kunden schnelle Updates zum richtigen Zeitpunkt.
Aber in diesem Fall hat uns die Geschwindigkeit einen Streich gespielt, und die Regeln haben sich innerhalb von Sekunden überall geändert. Sie haben wahrscheinlich bemerkt, dass der WAF-Code Lua verwendet. Cloudflare verwendet Lua in großem Umfang in der Produktionsumgebung, und wir haben die Details von Lua bereits in WAF besprochen . Lua WAF verwendet PCRE intern und wendet das Back-Tracking für den Abgleich an. Es gibt keine Abwehrmechanismen gegen außer Kontrolle geratene Ausdrücke. Im Folgenden werde ich mehr darüber und darüber sprechen, was wir damit machen.

Bevor die Regeln bereitgestellt wurden, verlief alles reibungslos: Die Poolanforderung wurde erstellt und genehmigt, die CI / CD-Pipeline hat den Code kompiliert und getestet, die Änderungsanforderung wurde gemäß der SOP gesendet, die die Bereitstellung und das Rollback regelt, und die Bereitstellung wurde abgeschlossen.

CloudFare WAF-Bereitstellungsprozess
Was ist schief gelaufen?
Wie ich bereits sagte, stellen wir jede Woche Dutzende neuer WAF-Regeln bereit, und wir haben viele Schutzsysteme gegen die negativen Folgen einer solchen Bereitstellung. Und wenn etwas schief geht, ist es normalerweise eine Kombination mehrerer Umstände. Wenn Sie nur einen Grund finden, ist dies natürlich beruhigend, aber nicht immer wahr. Hier sind die Gründe, die zusammen zum Ausfall unseres HTTP / HTTPS-Dienstes geführt haben.
- Der Ingenieur schrieb einen regulären Ausdruck, der zu übermäßigem Backtracking führen könnte.
- Ein Tool, das eine übermäßige Verwendung der vom regulären Ausdruck verwendeten Prozessorressourcen verhindern konnte, wurde einige Wochen zuvor fälschlicherweise während des WAF-Refactorings entfernt. Das Refactoring war erforderlich, damit WAF weniger Ressourcen verbrauchte.
- Die Regex-Engine hatte keine Garantie für Komplexität.
- Die Testsuite konnte keinen übermäßigen CPU-Verbrauch feststellen.
- Das SOP-Verfahren ermöglicht die globale Bereitstellung nicht dringender Regeländerungen ohne einen mehrstufigen Prozess.
- Der Rollback-Plan erforderte zweimal eine vollständige WAF-Montage, was lange dauerte.
- Der erste globale Verkehrsalarm war zu spät.
- Wir haben die Aktualisierung der Statusseite verzögert.
- Wir hatten aufgrund eines Absturzes Probleme beim Zugriff auf Systeme, und die Problemumgehung wurde nicht gut genug ausgearbeitet.
- SRE-Ingenieure haben den Zugriff auf einige Systeme verloren, weil ihre Anmeldeinformationen aus Sicherheitsgründen abgelaufen sind.
- Unsere Kunden hatten keinen Zugriff auf das Cloudflare-Dashboard oder die API, da sie die Cloudflare-Region durchlaufen haben.
Was hat sich seit letztem Donnerstag geändert?
Erstens haben wir alle Arbeiten an Releases für WAF vollständig eingestellt und gehen wie folgt vor:
- Wiedereinführung des Schutzes vor übermäßigen Prozessorressourcen, die wir entfernt haben. (Fertig)
- Überprüfen Sie alle 3868-Regeln in den verwalteten Regeln manuell, damit WAF andere potenzielle Fälle von übermäßigem Backtracking findet und behebt. (Überprüfung abgeschlossen)
- Wir enthalten Leistungsprofile für alle Regeln in der Testsuite. (Voraussichtlich: 19. Juli)
- Wir wechseln zur re2- oder Rust- Regex- Engine - beide bieten Garantien zur Laufzeit. (Voraussichtlich: 31. Juli)
- Wir schreiben SOP neu, um die Regeln wie andere Software in Cloudflare schrittweise bereitzustellen, haben aber gleichzeitig die Möglichkeit, eine globale Notfallbereitstellung durchzuführen, wenn die Angriffe bereits begonnen haben.
- Wir entwickeln die Möglichkeit eines dringenden Rückzugs des Cloudflare-Dashboards und der API aus der Cloudflare-Region.
- Wir automatisieren die Aktualisierung der Cloudflare-Statusseite .
Auf lange Sicht geben wir Lua WAF auf, das ich vor einigen Jahren geschrieben habe. Wir migrieren WAF auf das neue Firewall-System . So wird WAF schneller und erhält ein zusätzliches Schutzniveau.
Fazit
Dieser Fehler verursachte Probleme für uns und unsere Kunden. Wir haben schnell reagiert, um die Situation zu korrigieren, und jetzt arbeiten wir an Fehlern in den Prozessen, die den Fehler verursacht haben, und wir graben noch tiefer, um uns durch die Umstellung auf eine neue Technologie vor potenziellen Problemen mit regulären Ausdrücken in der Zukunft zu schützen.
Wir schämen uns sehr für diesen Fehler und entschuldigen uns bei unseren Kunden. Wir hoffen, dass diese Änderungen sicherstellen, dass dies nicht erneut geschieht.
Anwendung. Backtracking für reguläre Ausdrücke
Um zu verstehen, wie der Ausdruck:
(?:(?:\"|'|\]|\}|\\|\d (?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\- |\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*)))
Wenn Sie alle Prozessorressourcen verbraucht haben, müssen Sie ein wenig über die Funktionsweise der Standard-Regex-Engine wissen. Das Problem hier ist das Muster .*(?:.*=.*) . (?: und die entsprechende ) ist keine aufregende Gruppe (dh der Ausdruck in Klammern wird als ein Ausdruck gruppiert).
Im Zusammenhang mit einem übermäßigen Verbrauch von Prozessorressourcen kann dieses Muster als .*.*=.* Bezeichnet werden. Als solches sieht das Muster unnötig komplex aus. Noch wichtiger ist jedoch, dass in der realen Welt solche Ausdrücke (ähnlich wie komplexe Ausdrücke in den WAF-Regeln), die die Engine auffordern, einem Fragment gefolgt von einem anderen Fragment zu entsprechen, zu einem katastrophalen Backtracking führen können. Und hier ist warum.
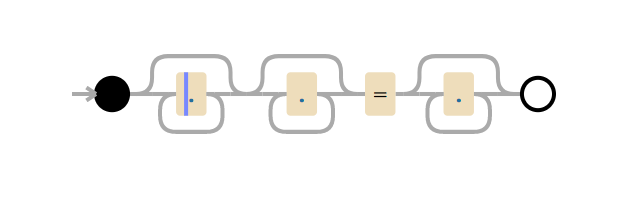
Im regulären Ausdruck . bedeutet, dass Sie mit einem Zeichen übereinstimmen müssen. .* - Null oder mehr Zeichen "gierig" abgleichen, dh maximal ein Zeichen erfassen, also .*.*=.* bedeutet, dass Sie mit null oder mehr Zeichen übereinstimmen und dann mit null oder mehr Zeichen übereinstimmen Literalzeichen =, entspricht null oder mehr Zeichen.
Nehmen Sie die Testlinie x=x . Es entspricht dem Ausdruck .*.*=.*. .*.* .*.*=.*. .*.* bis zum Gleichheitszeichen entspricht dem ersten x (eine der Gruppen .* entspricht x und das zweite bis null Zeichen). .* after = entspricht dem letzten x .
Für einen solchen Vergleich sind 23 Schritte erforderlich. Die erste Gruppe .* .*.*=.* Handelt "gierig" und entspricht der gesamten Zeile x=x . Der Motor fährt zur nächsten Gruppe .* . Wir haben keine übereinstimmenden Zeichen mehr, also die zweite Gruppe .* Entspricht null Zeichen (dies ist zulässig). Dann geht der Motor zum = -Zeichen. Es gibt keine weiteren Zeichen (die erste Gruppe .* Verwendet den gesamten Ausdruck x=x ), es findet keine Übereinstimmung statt.
Und hier kehrt die Engine für reguläre Ausdrücke zum Anfang zurück. Er geht zur ersten Gruppe .* Und vergleicht sie x= (anstelle von x=x ) und übernimmt dann die zweite Gruppe .* . Die zweite Gruppe .* Wird dem zweiten x , und wir haben wieder keine Zeichen mehr. Und wenn der Motor = v .*.*=.* Erreicht, passiert wieder nichts. Und er macht wieder einen Backtrack.
Diesmal die Gruppe .* immer noch mit x= überein, aber mit der zweiten Gruppe .* nicht mehr x , sondern null Zeichen. Die Engine versucht, das Literalsymbol = im Muster zu finden .*.*=.* , Wird jedoch nicht beendet (schließlich hat die erste Gruppe es bereits belegt .* ). Und er macht wieder einen Backtrack.
Diesmal die erste Gruppe .* Nimmt nur das erste x. Aber die zweite Gruppe .* "Gierig" erfasst =x . Schon erraten, was passieren wird? Die Engine versucht, mit literal = übereinzustimmen, schlägt fehl und führt das nächste Backtracking durch.
.* x . .* = . , = , .* . . !
.* x , .* — , = = . .* x .
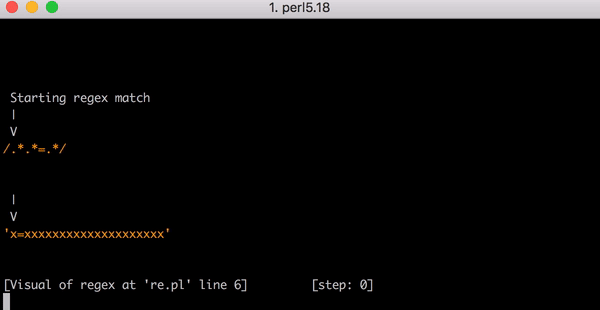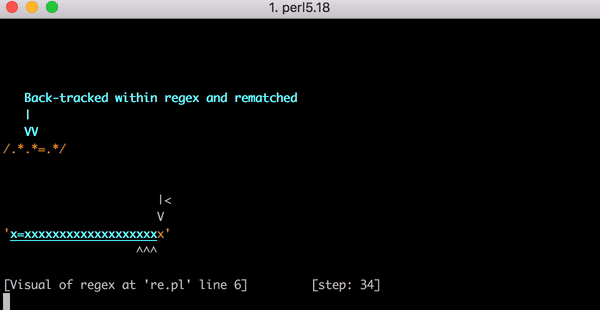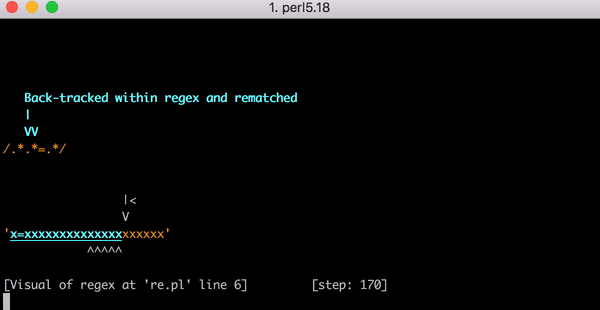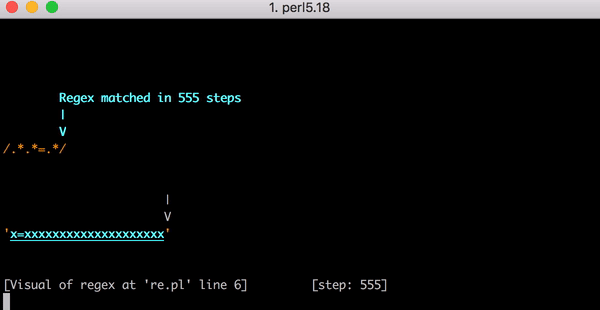
23 x=x . Perl Regexp::Debugger , , .
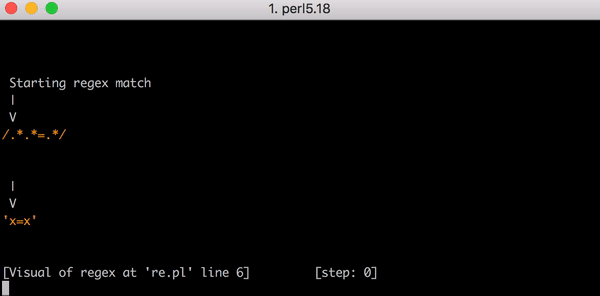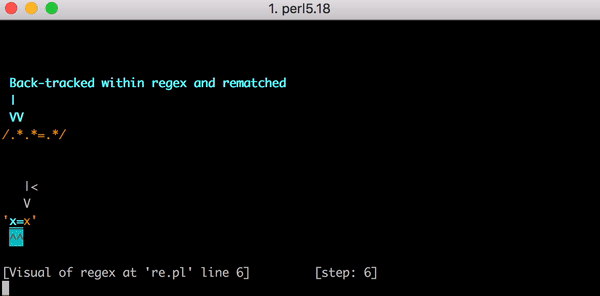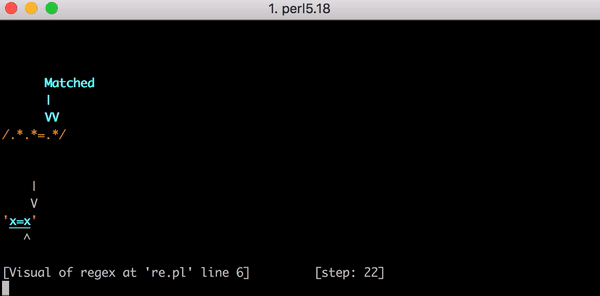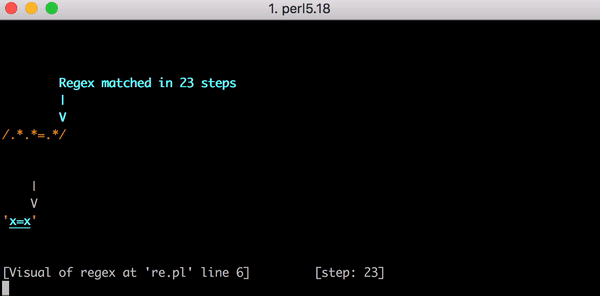
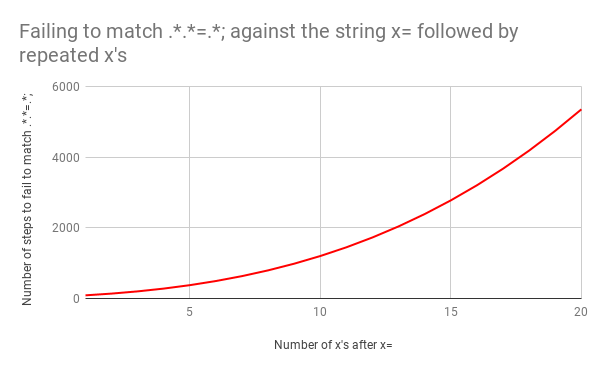
, x=x x=xx ? 33 . x=xxx ? 45. . x=x x=xxxxxxxxxxxxxxxxxxxx (20 x = ). 20 x = , 555 ! ( , x= 20 x , 4067 , , ).
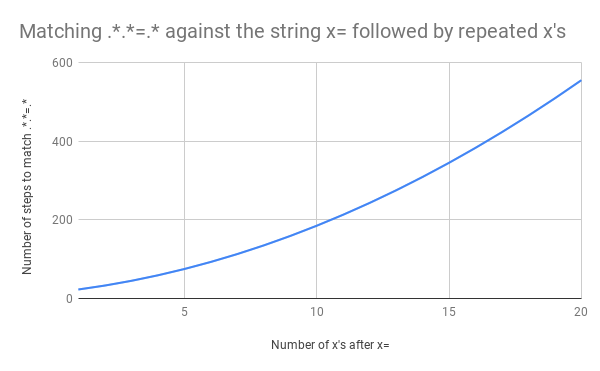
x=xxxxxxxxxxxxxxxxxxxx :
, . , . , .*.*=.* ; ( ). , , foo=bar; .
. x=x 90 , 23. . x= 20 x , 5353 . . Y .
, 5353 x=xxxxxxxxxxxxxxxxxxxx .*.*=.*;
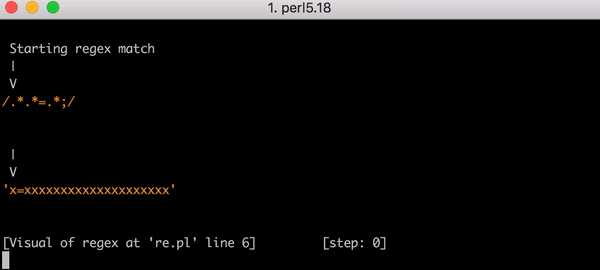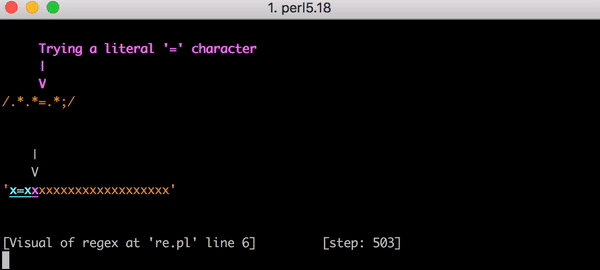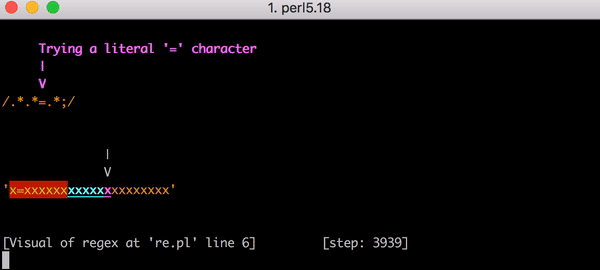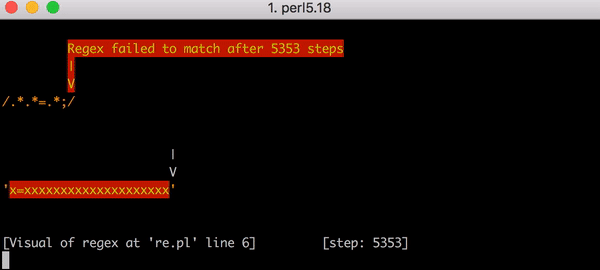
«», «» , . .*?.*?=.*? , x=x 11 ( 23). x=xxxxxxxxxxxxxxxxxxxx . , ? .* , .
«» . .*.*=.*; .*?.*?=.*?; , . x=x 555 , x= 20 x — 5353.
, ( ) — . .
1968 , Programming Techniques: Regular expression search algorithm (« : »). , , , .

(Ken Thompson)
Bell Telephone Laboratories, Inc., -, -
. IBM 7094 . , . , .
, .
. . — .
. , . , .
, IBM 7094.
. — , . «·» . . . 2 , .
, ALGOL-60, IBM 7094. , .
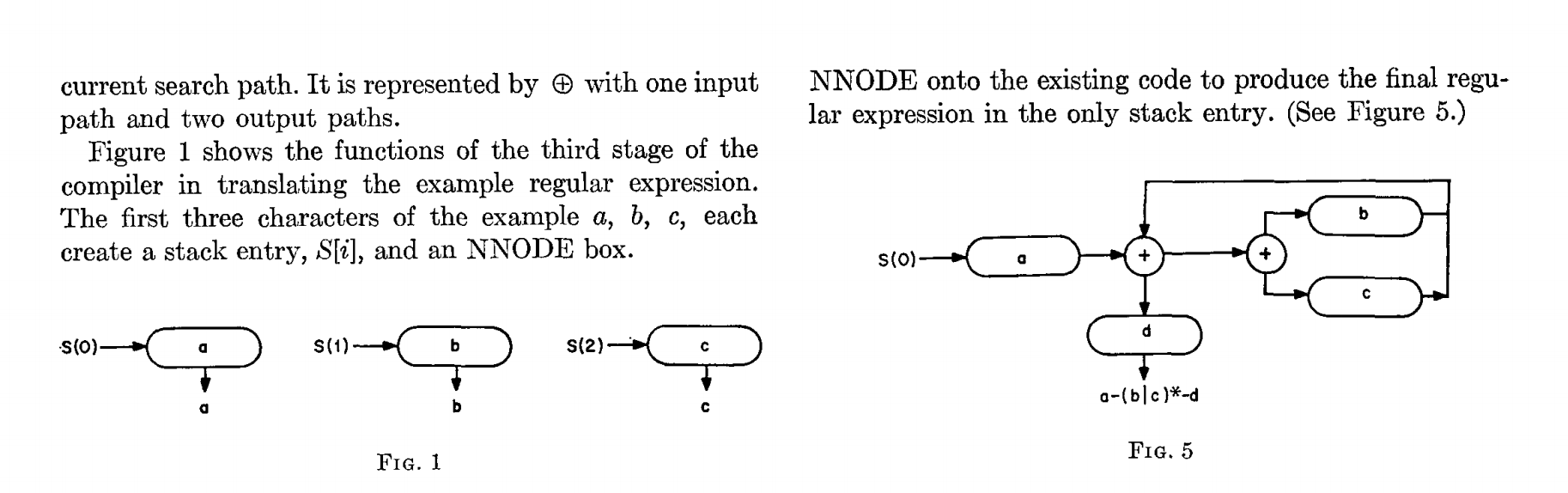
. ⊕ .
1 . — a, b, c, S[i] NNODE.
NNODE , (. . 5)
.*.*=.* , , .
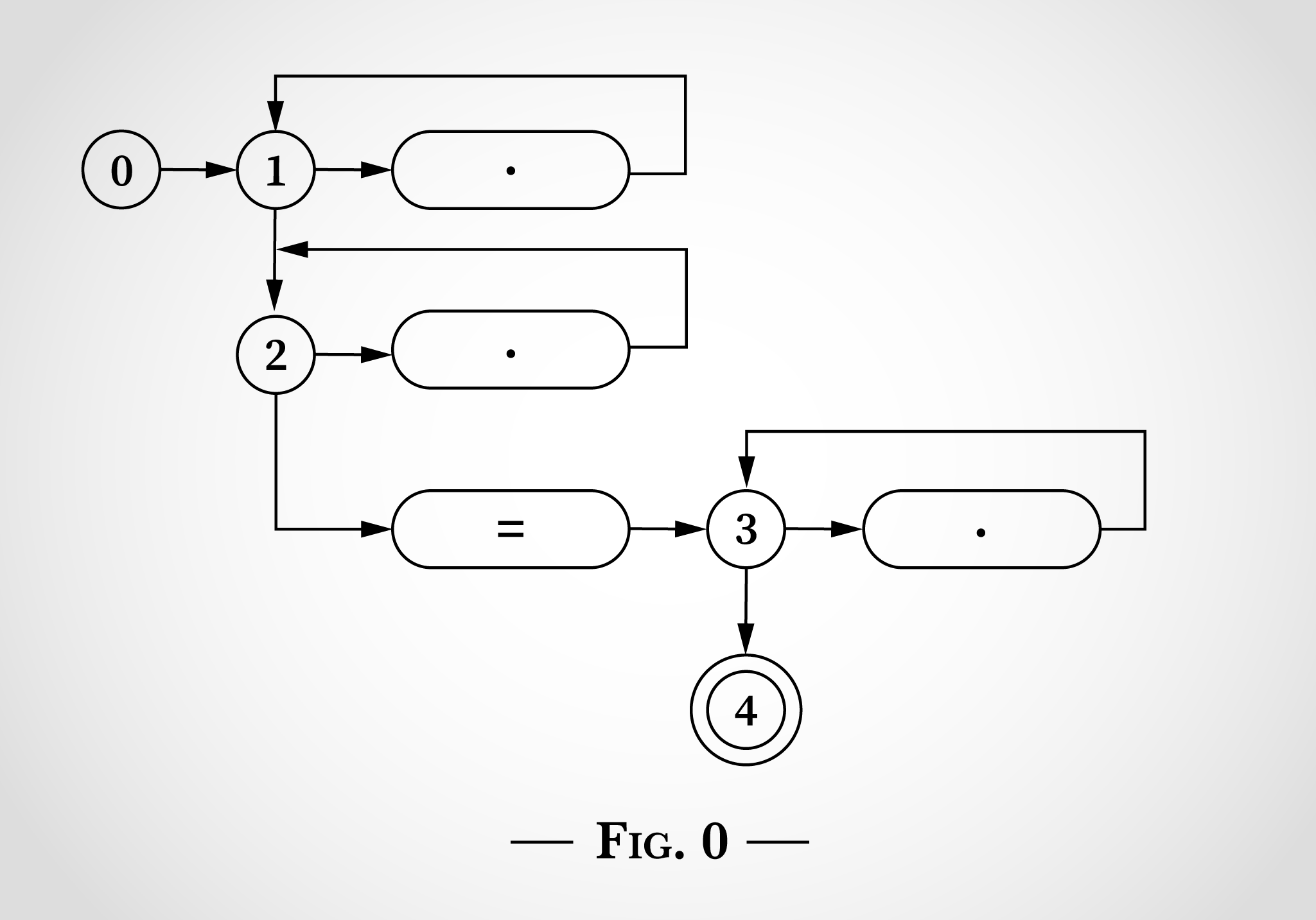
. 0 , 0, 3 , 1, 2 3. .* . 3 . = = . 4 . , .
, .*.*=.* , x=x . 0, . 1.
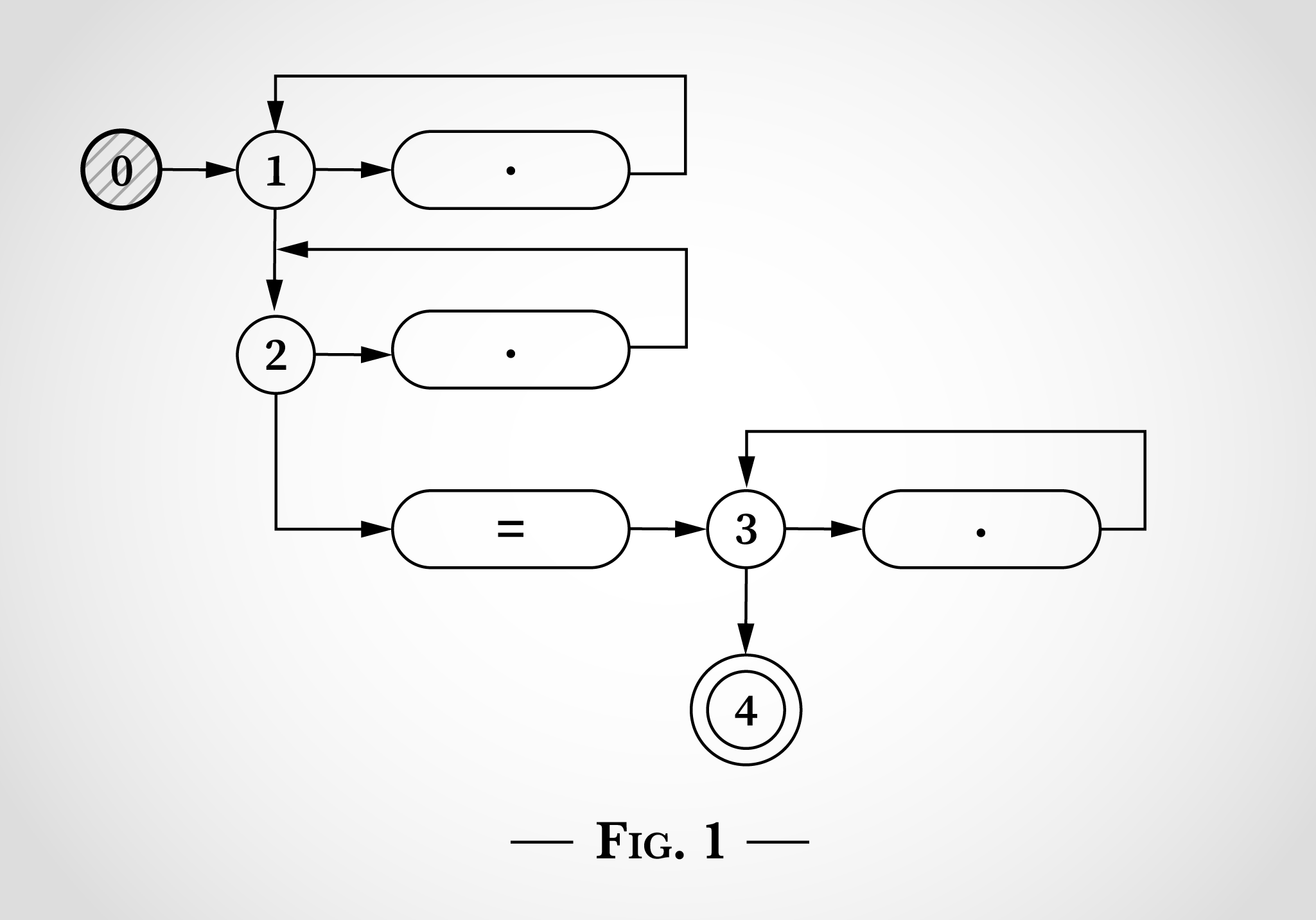
, . .
, (1 2), . 2.
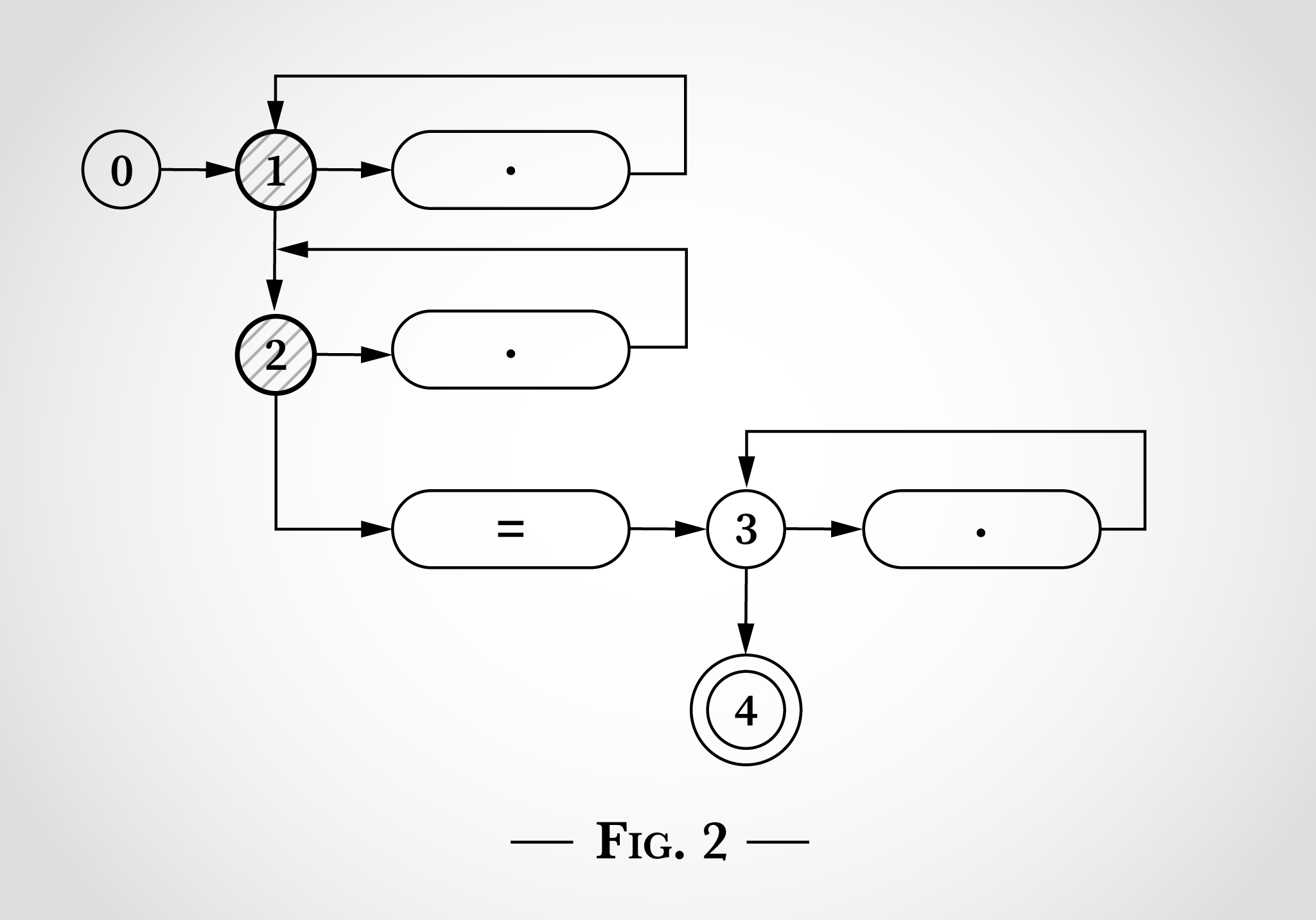
. 2 , , x x=x . x , 1 1. x , 2 2.
x x=x - 1 2. 3 4, = .
= x=x . x , 1 1 2 2, = 2 3 ( 4). . 3.
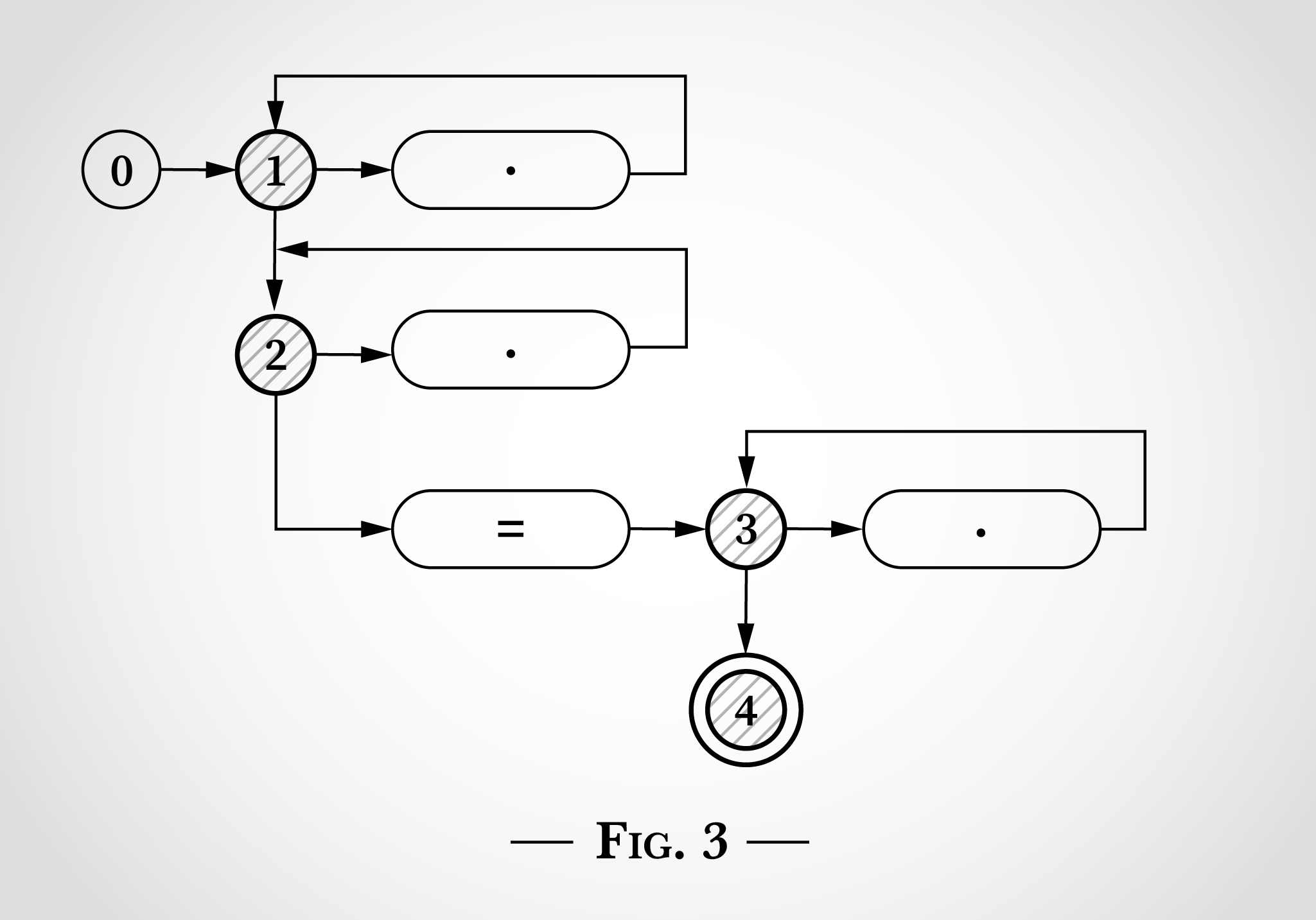
x x=x . 1 2 1 2. 3 x 3.
x=x , 4, . , . .
, 4 ( x= ) , , x .
.