 Hinweis perev. : Dailymotion ist einer der weltweit größten Video-Hosting-Dienste und daher ein bemerkenswerter Kubernetes-Benutzer. In diesem Artikel teilt der Systemarchitekt David Donchez die Ergebnisse der Erstellung einer Produktionsplattform für das Unternehmen auf der Basis von K8s, die mit einer Cloud-Installation in GKE begann und als Hybridlösung endete, die es ermöglichte, eine bessere Reaktionszeit zu erzielen und Infrastrukturkosten zu sparen.
Hinweis perev. : Dailymotion ist einer der weltweit größten Video-Hosting-Dienste und daher ein bemerkenswerter Kubernetes-Benutzer. In diesem Artikel teilt der Systemarchitekt David Donchez die Ergebnisse der Erstellung einer Produktionsplattform für das Unternehmen auf der Basis von K8s, die mit einer Cloud-Installation in GKE begann und als Hybridlösung endete, die es ermöglichte, eine bessere Reaktionszeit zu erzielen und Infrastrukturkosten zu sparen.Als wir uns vor drei Jahren für die Neuerstellung der zentralen
Dailymotion- API entschieden haben, wollten wir eine effizientere Methode zum Hosten von Anwendungen und zur Vereinfachung
der Entwicklungs- und Produktionsprozesse entwickeln . Zu diesem Zweck haben wir uns für die Container-Orchestrierungsplattform entschieden und uns natürlich für Kubernetes entschieden.
Warum lohnt es sich, eine eigene Kubernetes-basierte Plattform zu erstellen?
API auf Produktionsebene so schnell wie möglich mit Google Cloud
Sommer 2016
Vor drei Jahren, unmittelbar nachdem
Vivendi Dailymotion gekauft hatte, konzentrierten sich unsere Entwicklungsteams auf ein globales Ziel: ein völlig neues Dailymotion-Produkt zu entwickeln.
Basierend auf der Analyse von Containern, Orchestrierungslösungen und unseren bisherigen Erfahrungen haben wir sichergestellt, dass Kubernetes die richtige Wahl ist. Einige Entwickler hatten bereits eine Vorstellung von den Grundkonzepten und wussten, wie man sie verwendet, was ein großer Vorteil für die Transformation der Infrastruktur war.
Unter dem Gesichtspunkt der Infrastruktur war ein leistungsstarkes und flexibles System erforderlich, um neue Arten von Cloud-nativen Anwendungen zu hosten. Wir haben uns zu Beginn unserer Reise entschieden, in der Cloud zu bleiben, um ruhig die zuverlässigste lokale Plattform aufzubauen. Sie beschlossen, ihre Anwendungen mithilfe der Google Kubernetes Engine bereitzustellen, obwohl sie wussten, dass wir früher oder später in unsere eigenen Rechenzentren wechseln und eine Hybridstrategie anwenden würden.
Warum GKE wählen?
Wir haben diese Wahl hauptsächlich aus technischen Gründen getroffen. Darüber hinaus war es notwendig, schnell die Infrastruktur bereitzustellen, die den Anforderungen des Unternehmens entspricht. Wir hatten einige Anwendungsanforderungen, wie z. B. geografische Verteilung, Skalierbarkeit und Fehlertoleranz.
 GKE-Cluster in Dailymotion
GKE-Cluster in DailymotionDa Dailymotion eine weltweit verfügbare Videoplattform ist, wollten wir die Servicequalität wirklich verbessern, indem wir die
Latenz reduzieren. Bisher war
unsere API nur in Paris verfügbar, was nicht optimal war. Ich wollte Anwendungen nicht nur in Europa, sondern auch in Asien und den USA hosten können.
Diese Empfindlichkeit gegenüber Verzögerungen bedeutete, dass wir ernsthaft an der Netzwerkarchitektur der Plattform arbeiten mussten. Während die meisten Cloud-Dienste sie zwangen, in jeder Region ein eigenes Netzwerk zu erstellen und diese dann über ein VPN oder einen bestimmten verwalteten Dienst zu verbinden, ermöglichte Google Cloud die Erstellung eines vollständig routbaren einheitlichen Netzwerks, das alle Regionen von Google abdeckt. Dies ist ein großes Plus in Bezug auf Betrieb und Systemeffizienz.
Darüber hinaus leisten Netzwerkdienste und Load Balancer aus Google Cloud hervorragende Arbeit. Sie ermöglichen es Ihnen einfach, beliebige öffentliche IP-Adressen aus jeder Region zu verwenden, und das wunderbare BGP-Protokoll kümmert sich um den Rest (d. H. Leitet Benutzer zum nächsten Cluster um). Im Falle eines Ausfalls wird der Verkehr natürlich ohne menschliches Eingreifen automatisch in eine andere Region geleitet.
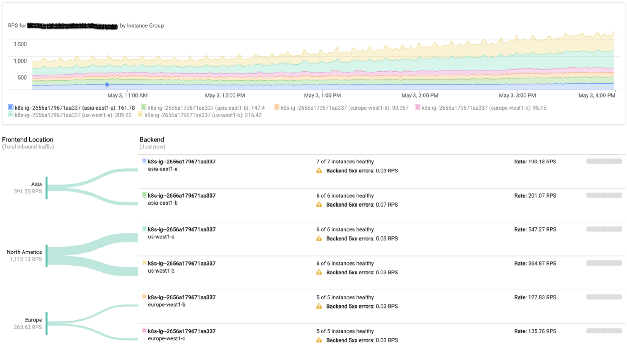 Google Load Balancing Monitoring
Google Load Balancing MonitoringUnsere Plattform verwendet auch aktiv Grafikprozessoren. Google Cloud macht es äußerst effizient, sie direkt in Kubernetes-Clustern zu verwenden.
Zu dieser Zeit konzentrierte sich das Infrastruktur-Team hauptsächlich auf den alten Stack, der auf physischen Servern bereitgestellt wurde. Aus diesem Grund hat die Verwendung eines verwalteten Dienstes (einschließlich der Kubernetes-Hauptkomponenten) unsere Anforderungen erfüllt und es uns ermöglicht, Teams in der Arbeit mit lokalen Clustern zu schulen.
Infolgedessen konnten wir bereits 6 Monate nach Arbeitsbeginn Produktionsdatenverkehr in der Google Cloud-Infrastruktur akzeptieren.
Trotz einer Reihe von Vorteilen ist die Zusammenarbeit mit einem Cloud-Anbieter mit bestimmten Kosten verbunden, die sich je nach Auslastung erhöhen können. Aus diesem Grund haben wir jeden verwendeten Managed Service sorgfältig analysiert, um ihn in Zukunft vor Ort implementieren zu können. Tatsächlich begann die Einführung lokaler Cluster Ende 2016 und gleichzeitig wurde eine hybride Strategie eingeleitet.
Starten der Dailymotion Local Container Orchestration Platform
Herbst 2016
Unter Bedingungen, unter denen der gesamte Stapel für die Produktion bereit war und die Arbeit an der API
fortgesetzt wurde , war Zeit, sich auf regionale Cluster zu konzentrieren.
Zu dieser Zeit sahen sich die Nutzer jeden Monat mehr als 3 Milliarden Videos an. Natürlich betreiben wir seit Jahren ein eigenes verzweigtes Content Delivery Network. Wir wollten diesen Umstand nutzen und Kubernetes-Cluster in vorhandenen Rechenzentren bereitstellen.
Die Dailymotion-Infrastruktur umfasste mehr als 2,5 Tausend Server in sechs Rechenzentren. Alle werden mit Saltstack konfiguriert. Wir haben begonnen, alle notwendigen Rezepte zum Erstellen von Master- und Worker-Knoten sowie eines etcd-Clusters vorzubereiten.

Netzwerkteil
Unser Netzwerk ist vollständig routingfähig. Jeder Server gibt seine IP im Netzwerk mit Exabgp bekannt. Wir haben mehrere Netzwerk-Plug-Ins verglichen und
Calico war das einzige, das alle Anforderungen erfüllte (aufgrund des auf L3-Ebene verwendeten Ansatzes). Es passt perfekt in das bestehende Netzwerkinfrastrukturmodell.
Da ich zunächst alle verfügbaren Infrastrukturelemente nutzen wollte, musste ich mich mit unserem eigenen Netzwerkdienstprogramm (das auf allen Servern verwendet wird) befassen: Verwenden Sie es, um IP-Adressbereiche in einem Netzwerk mit Kubernetes-Knoten anzukündigen. Wir haben Calico erlaubt, Pods IP-Adressen zuzuweisen, haben sie jedoch nicht verwendet und verwenden sie immer noch nicht für BGP-Sitzungen auf Netzwerkgeräten. Tatsächlich wird das Routing von Exabgp übernommen, das die von Calico verwendeten Subnetze ankündigt. Auf diese Weise können wir jeden Pod vom internen Netzwerk (und insbesondere von Load Balancern) aus erreichen.
Wie wir den eingehenden Verkehr verwalten
Um eingehende Anforderungen an den gewünschten Dienst umzuleiten, wurde aufgrund der Integration in Kubernetes Ingress-Ressourcen die Verwendung von Ingress Controller beschlossen.
Vor drei Jahren war der Nginx-Ingress-Controller der ausgereifteste Controller: Nginx wird seit langem verwendet und ist für seine Stabilität und Leistung bekannt.
In unserem System haben wir beschlossen, die Controller auf dedizierten 10-Gigabit-Blade-Servern zu platzieren. Jeder Controller war mit dem Endpunkt des Kube-Apiservers des entsprechenden Clusters verbunden. Exabgp wurde auch auf diesen Servern verwendet, um öffentliche oder private IP-Adressen anzukündigen. Die Topologie unseres Netzwerks ermöglicht es uns, BGP von diesen Controllern zu verwenden, um den gesamten Datenverkehr direkt zu Pods zu leiten, ohne einen Dienst wie NodePort zu verwenden. Dieser Ansatz hilft, horizontalen Verkehr zwischen Knoten zu vermeiden und die Effizienz zu verbessern.
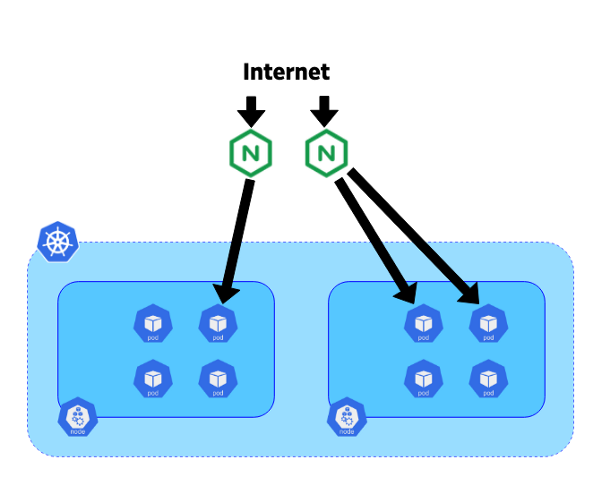 Die Bewegung des Verkehrs vom Internet zu Pods
Die Bewegung des Verkehrs vom Internet zu PodsNachdem Sie unsere Hybridplattform herausgefunden haben, können Sie sich mit dem Prozess der Verkehrsmigration befassen.
Migrieren des Datenverkehrs von Google Cloud zur Dailymotion-Infrastruktur
Herbst 2018
Nach fast zwei Jahren des Erstellens, Testens und Konfigurierens haben wir endlich einen vollständigen Kubernetes-Stack erhalten, der bereit ist, einen Teil des Datenverkehrs zu empfangen.

Die derzeitige Routing-Strategie ist recht einfach, erfüllt jedoch die Anforderungen. Zusätzlich zur öffentlichen IP-Adresse (in Google Cloud und Dailymotion) wird AWS Route 53 verwendet, um Richtlinien festzulegen und Benutzer auf den Cluster unserer Wahl umzuleiten.
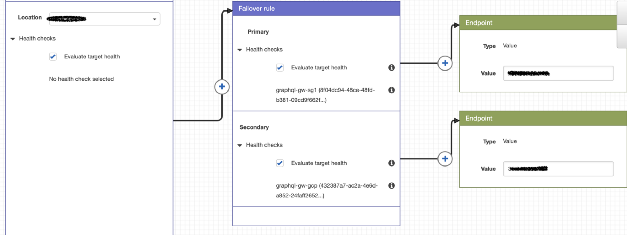 Beispiel für eine Routing-Richtlinie mit Route 53
Beispiel für eine Routing-Richtlinie mit Route 53Mit Google Cloud ist dies einfach, da wir für alle Cluster eine einzige IP-Adresse verwenden und der Nutzer zum nächsten GKE-Cluster umgeleitet wird. Die Technologie ist für unsere Cluster unterschiedlich, da ihre IPs unterschiedlich sind.
Während der Migration haben wir versucht, regionale Anfragen an die jeweiligen Cluster umzuleiten und die Vorteile dieses Ansatzes zu bewerten.
Da unsere GKE-Cluster so konfiguriert sind, dass sie mithilfe benutzerdefinierter Metriken automatisch skaliert werden, erhöhen / verringern sie die Leistung je nach eingehendem Datenverkehr.
Im normalen Modus wird der gesamte regionale Verkehr an den lokalen Cluster weitergeleitet, und GKE dient bei Problemen als Reserve (Integritätsprüfungen werden über die Route 53 durchgeführt).
...
In Zukunft möchten wir Routing-Richtlinien vollständig automatisieren, um eine autonome Hybridstrategie zu erhalten, die die Benutzerzugänglichkeit ständig verbessert. Was die Pluspunkte betrifft: Die Kosten für die Cloud wurden erheblich reduziert, und sogar die API-Antwortzeit wurde reduziert. Wir vertrauen der resultierenden Cloud-Plattform und sind bereit, bei Bedarf mehr Datenverkehr darauf umzuleiten.
PS vom Übersetzer
Sie könnten auch an einer anderen kürzlich erschienenen Dailymotion-Veröffentlichung über Kubernetes interessiert sein. Es ist für die Bereitstellung von Helm-Anwendungen in vielen Kubernetes-Clustern vorgesehen und
wurde vor etwa einem Monat veröffentlicht.
Lesen Sie auch in unserem Blog: