
Die Lösung des Problems der Bilderkennung (OCR) ist mit verschiedenen Schwierigkeiten verbunden. Dieses Bild kann aufgrund des nicht standardmäßigen Farbschemas oder aufgrund von Verzerrungen nicht erkannt werden. Dass der Kunde alle Bilder ohne Einschränkungen erkennen möchte, und das ist bei weitem nicht immer möglich. Die Probleme sind unterschiedlich und es ist nicht immer möglich, sie sofort zu lösen. In diesem Beitrag geben wir einige nützliche Tipps, die auf der Erfahrung bei der Lösung realer Situationen mit Kunden basieren.
Aber zuerst ein bisschen Geschichte. Seit der Veröffentlichung des Artikels darüber,
wie wir den Filterdienst umgeschrieben haben, ist viel Zeit vergangen. Darin haben wir ein wenig über Filterung und Nachrichtenverarbeitung gesprochen, darüber, wie unser Filterdienst insgesamt aufgebaut ist. Dieses Mal werden wir versuchen, die Frage zu beantworten: "Wie verarbeiten wir Bilder, wie interagieren Dienste und was passiert mit dem System unter Last?" Wenn wir einen Artikel über einen Filterdienst bearbeiten, werden wir jetzt nur einen Zweig der Dienstinteraktion betrachten - dies ist die Interaktion zwischen einem Filterdienst und OCR.
Was ist eine OCR?
Bevor wir über die Interaktion von Diensten und die Probleme bei der Verwendung von OCR sprechen, versuchen wir zu verstehen, was OCR ist. Nehmen Sie die
komplizierte Definition aus Wikipedia.
Optische Zeichenerkennung (OCR) - die mechanische oder elektronische Übersetzung von handgeschriebenen, maschinengeschriebenen oder getippten Textbildern in Textdaten, die zur Darstellung von Zeichen in einem Computer (z. B. in einem Texteditor) verwendet werden.
Einfach ausgedrückt, sie machten ein Foto, schickten es zur Anerkennung, dann die
Magie außerhalb von Hogwarts und erhielten den Text.

Sie können die OCR-Definition auch von der ABBYY-Website übernehmen, die einfacher aussieht.
Die optische Zeichenerkennung (OCR) ist eine Technologie, mit der Sie verschiedene Arten von Dokumenten wie gescannte Dokumente, PDF-Dateien oder Fotos von einer Digitalkamera in durchsuchbare bearbeitbare Formate konvertieren können.
Und warum brauchen wir (Bilderkennung)?
Wir können die Bilderkennung sogar auf unserem Heim-PC verwenden, um digitale Bilder in bearbeitbare Textdaten umzuwandeln. Die vor uns liegende Aufgabe ist jedoch viel umfassender (schließlich ein DLP-System): Wir müssen den Informationsfluss in der Organisation steuern.
DLP-Systeme sind seit langem auf dem Markt und gehören nun zum bekannten Arsenal von Informationssicherheitssystemen für Unternehmen (Informationsschutz-Tools). DLP steht vor der Aufgabe, die Bewegung grafischer Informationen (gescannte Dokumente, Screenshots, Fotos) zu steuern. Und nicht nur die Bewegung von Grafikdateien steuern, sondern vor allem deren Inhalt analysieren. Das System sollte in der Lage sein, genau zu verstehen, auf welche Informationen es gestoßen ist, sie mit Beispielen geschützter Informationen zu vergleichen und dem Benutzer die Möglichkeit zu geben, weiter nach diesen Informationen zu suchen. Die Verwendung anderer Analysewerkzeuge wie der Vergleich mit digitalen Fingerabdrücken, die Berechnung von Hashs, die Analyse nach Dateiformat, Größe und Struktur sind ebenfalls wertvolle Informationsquellen, ermöglichen jedoch keine Beantwortung der Frage: „Welcher Text wird in diesem Bild übertragen?“ In der Zwischenzeit ist der Text immer noch der häufigste Träger strukturierter Informationen, auch in Grafikdateien.
Traditionell wird die OCR-Technologie verwendet, um grafische Informationen zu erkennen (was wir bereits festgestellt haben). Tatsächlich ist OCR im Allgemeinen die einzige Klasse von Technologien, die die Möglichkeit bieten, Textinformationen aus Bildern zu extrahieren. Daher geht es nicht so sehr um den traditionellen Ansatz, sondern vielmehr um die mangelnde Auswahl.
Wie viele Bilder werden pro DLP-System verarbeitet?
Kannst du nicht ohne OCR auskommen? Gibt es wirklich so viele Bilder in DLP, dass Sie OCR anwenden müssen? Die Antwort auf diese Frage lautet "Ja!". Pro Tag können über eine Million Bilder in das System gelangen, und alle diese Bilder können Text enthalten.
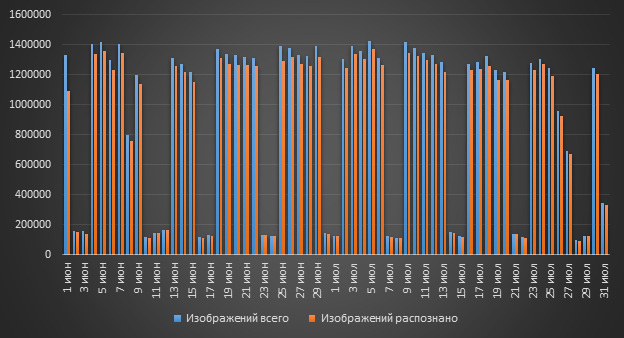
OCR als Teil des Rostelecom-Solar DLP-Systems wird von Öl- und Gasunternehmen sowie Regierungsbehörden verwendet. Alle Kunden verwenden OCR, um sensible Daten in gescannten Dokumenten zu erkennen. Was kann in einem solchen „Zeitplan“ enthalten sein? Ja, irgendetwas. Dies können Scans verschiedener interner Dokumente sein, die beispielsweise PD enthalten. Oder Informationen aus der Kategorie Geschäftsgeheimnisse, Spanplatten (für den offiziellen Gebrauch), Abschlüsse usw.
Wie erkennt OCR Bilder?
Der Vorgang ist wie folgt: DLP fängt eine Nachricht ab, die ein Bild enthält (Dokumentenscan, Foto usw.), stellt fest, dass sich das Bild tatsächlich in der Nachricht befindet, extrahiert es und sendet es zur Erkennung an OCR. Am Ausgang empfängt der DLP Informationen über den Inhalt des Bildes (und die Nachricht als Ganzes) in Form des extrahierten TEXT / PLAIN.
Wenn wir über die Interaktion von Diensten direkt in unserem Solar Dozor-System sprechen, sendet der Filterdienst Bilder (falls vorhanden) von der Nachricht an den OCR-Dienst (Image Text Extraction). Letzterer sendet nach Abschluss der Erkennung den empfangenen Text an mailfilter. Es stellt sich heraus, wie Bilder und Text zu jonglieren.

Betrachten wir den Erkennungsmechanismus am Beispiel der OCR-Technologien ABBYY, die wir in unserem eigenen DLP verwenden.
Möglicherweise ist das Hauptproblem für OCR beim Erkennen von Text die Schreibweise eines Zeichens. Wenn wir einen Buchstaben des Alphabets nehmen (zum Beispiel Russisch oder Englisch), finden wir für jeden Buchstaben mehrere Rechtschreiboptionen. OCR-Engines lösen dieses Problem auf verschiedene Weise:
- Ein Zeichen anhand eines Musters finden. Verwenden Sie beispielsweise eine Vielzahl von Rechtschreibschriften.
- Identifizierung von Zeichen zum Schreiben eines Zeichens.
Wenn Sie ein ziemlich grobes Beispiel für die Arbeit geben, zerlegt OCR den Text in Zeichen, die zuvor im Bild identifiziert wurden, und legt sie vorgefertigten Vorlagen auf. Dann wird geprüft, ob das Symbol wie eine Schreibweise einer Vorlage aussieht oder nicht. Wenn ein Zeichen identifiziert wird, wird es in der verwendeten Codierung in den Zeichencode konvertiert. Als Ergebnis dieses Prozesses werden Symbole zu Wörtern und Sätze zum endgültigen Text hinzugefügt.
Es gibt viele verschiedene Artikel über die Arbeit von OCR. Weitere Informationen zur Arbeit von OCR finden Sie beispielsweise hier
https://sysblok.ru/knowhow/iz-pikselej-v-bukvy-kak-rabotaet-raspoznavanie-teksta/Wie bereite ich OCR als Ganzes auf die Anerkennung vor?
Wir haben bereits herausgefunden, dass über eine Million Bilder in DLP gelangen können. Aber sind uns alle Bilder dieser Million nützlich?
Die Antwort auf die Frage ist mehr als offensichtlich - natürlich nicht. Aber warum werden uns nicht alle Bilder nützlich sein? Die Antwort auf diese Frage ist auch ziemlich transparent: Viele Bilder von Unterschriften in Nachrichten „laufen“ in der Post. Wahrscheinlich enthalten 90% der Nachrichten (wenn nicht mehr) das Firmenlogo.
Solche Bilder sind zu klein für die Erkennung, da sie möglicherweise überhaupt keinen Text enthalten. Hier können wir empfehlen (und sogar dringend empfehlen), Einschränkungen für die Größe erkannter Bilder festzulegen. In diesem Fall müssen die Einschränkungen sowohl an der unteren als auch an der oberen Grenze festgelegt werden. Die Wahrscheinlichkeit, schwere Dateien zur Verarbeitung zu senden, ist geringer als bei Bildern mit einer Signatur, aber immer noch recht hoch.Es ist erwähnenswert, dass digitale Bilder oft unterschiedliche Mängel aufweisen. Es ist unwahrscheinlich, dass DLP immer Dokumentenscans in guter Auflösung erhält. Im Gegenteil, Scans sind immer nicht in bester Qualität und mit vielen Fehlern.
Beispielsweise kann bei einem Digitalfoto die Perspektive verzerrt sein, sich als hervorgehoben oder invertiert herausstellen und die Scanlinien können gekrümmt sein. Eine solche Verzerrung kann die Erkennung erschweren. Daher können OCR-Engines Bilder vorverarbeiten, um sie für die Erkennung vorzubereiten. Beispielsweise kann ein Bild verdreht, in Schwarzweiß konvertiert, Farben invertiert und Linienversätze korrigiert werden.
All dies kann in den OCR-Einstellungen eingestellt werden. Infolgedessen können diese Tools dazu beitragen, die Texterkennung in Bildern zu verbessern.Als Ergebnis kamen wir zu den Grundprinzipien der Vorbereitung der OCR auf die Anerkennung:
- Bestimmen Sie die Größe der Bilder, die wir erkennen werden, sowohl in Pixel als auch in MB.
- Aktivieren Sie die Bildvorverarbeitung.
Um die Effizienz der OCR zu erhöhen, können Sie erkannte Daten auch zwischenspeichern, um nicht mehrmals dieselben Bilder zur Erkennung zu senden.
Worauf Sie bei der Vorbereitung der OCR noch achten sollten, werden im Folgenden anhand von Beispielen für den Einsatz dieser Technologie in der Kampfpraxis beschrieben.
Welche Herausforderungen sind möglich, wenn OCR in DLP unter hoher Last verwendet wird?
1. Zu große Grenzen für die Größe erkannter BilderBeginnen wir mit dem, was wir bereits erwähnt haben - mit Grenzen.
Aufgrund unserer Praxis setzen Kunden der Größe erkannter Bilddateien häufig zu große Grenzen. Ja, damit OCR gut funktioniert, müssen Sie die Bildgröße begrenzen. Kunden sind jedoch bestrebt, alles zu kontrollieren, da sie der Ansicht sind, dass selbst bei einem Bild mit 100 x 100 Pixel und einer Größe von 5 KB wertvolle Daten verloren gehen können. Im Allgemeinen sind natürlich auch 100 x 100 Pixel und 5 KB Einschränkungen, aber diese Schwellenwerte sind zu niedrig.
Das andere Extrem ist der Wunsch, schwere Dateien mit mehreren hundert MB zu erkennen. Es ist klar, dass solche Bilder aufgrund von Einschränkungen bei der Größe der gesendeten Nachrichten nicht durch Unternehmenspost crawlen. Aber hier auf anderen Abhörkanälen (zum Beispiel vom Unternehmensnetzwerkball) versuchen gewichtige Dateien beharrlich zu erkennen. Wenn der Kunde eine große Anzahl hochauflösender Bilder hinzufügen möchte, müssen Sie über die entsprechenden Serverkapazitäten verfügen. Infolgedessen wird bei solch breiten minimalen und maximalen Schwellenwerten für die Größe erkannter Dateien eine hohe Prozessorlast auf den Servern erzeugt, was den Betrieb aller Subsysteme verlangsamt.
Was kann hier empfohlen werden? Analysieren Sie zunächst, welcher vom Unternehmen verwendete „Zeitplan“ vertrauliche Daten enthält, und schätzen Sie dann die angemessenen minimalen und maximalen Einschränkungen für die Größe der überwachten Bilder. Wir empfehlen Kunden normalerweise, die untere Grenze der Bildauflösung von 200 Pixel, idealerweise von 400 Pixel (entlang der X- und Y-Achse), und Dateigrößen von mindestens 20 KB, besser größer, festzulegen. Es macht auch keinen Sinn, schwere Bilder an OCR zu senden - sie überlasten einfach Ihre Server und nicht die Tatsache, dass sie erkannt werden.2. Filtern von Warteschlangen und Zeitüberschreitungen bei der AnforderungsverarbeitungEine übermäßige Belastung der Server, die aus den oben genannten Gründen auftritt, führt entlang der Kette zu einer Verlängerung der Zeit für die Bilderkennung und Abfrageverarbeitung im Allgemeinen. Infolgedessen beginnt die Nachrichtenwarteschlange zum Filtern im DLP-System zuzunehmen. Darüber hinaus können Grafikdateien, die im Prinzip nicht erkannt werden können (schwere Dateien, schlechte Qualität usw.), im OCR-Modul eintreffen, was zu Zeitüberschreitungen bei der Bildverarbeitung führt. Wenn viele nicht erkannte Dateien vorhanden sind und das System hohe Erkennungszeitüberschreitungen aufweist, wartet der Filterdienst, bis diese Zeitüberschreitung auftritt, und fährt erst dann mit der Verarbeitung der nächsten Anforderung fort. Der gesamte Verarbeitungsprozess kann ernsthaft behindert werden.
Was können wir raten? Wenn es eine Warteschlange für die Verarbeitung von Grafiken gibt, müssen Sie die OCR-Einstellungen im DLP-System überprüfen und versuchen, die Ursache für das Bremsen zu finden. Dies kann beispielsweise aufgrund von Problemen bei der Interprozesskommunikation auf dem Server selbst auftreten. Im Allgemeinen verdienen diese Probleme eine gesonderte Diskussion. Einige Details zu allgemeinen Problemen finden Sie im Artikel „Einführung in die Interprozesskommunikation unter Linux“ .Ein wichtiger Punkt beim Einrichten von OCR ist außerdem das Festlegen angemessener Zeitüberschreitungen für die Bilderkennung. Im Allgemeinen reichen 90 Sekunden aus, um das Bild genau zu erkennen. Wenn in 90 Sekunden kein Text aus dem Bild extrahiert wurde, kann davon ausgegangen werden, dass OCR das Bild im Prinzip nicht erkennt. Zu diesem Zeitpunkt können OCR-Konfigurationsprobleme auch auftreten, wenn sie hohe Erkennungszeitlimits festlegen und dadurch versuchen, das nicht erkannte zu erkennen.Was könnte sonst eine Zeitüberschreitung verursachen? Hier kommen wir auf das Problem der Systemkonfiguration zurück. Der Filterdienst arbeitet wie der OCR-Dienst mit Threads, die Nachrichten und Bilder verarbeiten. Das System ist möglicherweise hinsichtlich der Anzahl der Filterdienst-Handler und der Anzahl der OCR-Handler nicht richtig konfiguriert. Ein Filterdienst verfügt beispielsweise über viele Thread-Handler, während OCR nur über einen verfügt. In einer solchen Situation hat OCR an einigen Stellen möglicherweise einfach keine Zeit, alle Erkennungsanforderungen zu verarbeiten, und daher werden Bildverarbeitungszeitüberschreitungen angezeigt.
Dieses Verhalten des Systems lässt auf Gedanken zu Designproblemen und Fehlern in der Architektur schließen, ist es aber nicht. Die Architektur unseres DLP bietet die Flexibilität, das System zu konfigurieren und an die Bedürfnisse der Kunden anzupassen. Zum Beispiel können wir einfach eine OCR so konfigurieren, dass sie mit zwei Filterdiensten arbeitet, ohne die Leistung zu beeinträchtigen.
3. Nicht erkannte BilderWenn ein Bild, das die OCR nicht erkennen kann, zur Analyse in das DLP-System gelangt, gibt es mehrere Lösungen für das Problem.
Aus welchen Gründen werden Bilder möglicherweise nicht erkannt? Zum Beispiel durch Folgendes:
1. Nicht standardmäßiges Farbschema des Bildes.
2. Bild mit niedriger Auflösung.
3. Falsche Ausrichtung des Bildes und des darin enthaltenen Textes im Raum.
4. Linienversatz und Verzerrung der Proportionen des Textes im Bild usw.
Hier ein Beispiel: Einer der Kunden hat während des Überwachungsprozesses festgestellt, dass OCR keine PDF-Dokumente erkennt, die in einem nicht standardmäßigen Farbschema ausgeführt wurden. Das heißt, das Bild wurde im normalen Modus aus dem PDF-Dokument extrahiert, aber bei der Verarbeitung des OCR-Moduls verstand er das Farbschema des Bildes nicht und erzeugte am Ausgang das „Malewitsch-Quadrat“. In unserer Benutzeroberfläche sah das Bild ungefähr so aus:
 OCR-Engines verfügen über verschiedene Funktionen zur automatischen Bildkorrektur, die die Chancen auf eine erfolgreiche Erkennung des darin enthaltenen Textes erheblich erhöhen. In der Praxis funktionieren diese magischen Werkzeuge jedoch nicht immer. In diesem speziellen Fall haben wir das OCR-Modul für den Kunden so angepasst, dass er dieses nicht standardmäßige Farbschema erkennt.
OCR-Engines verfügen über verschiedene Funktionen zur automatischen Bildkorrektur, die die Chancen auf eine erfolgreiche Erkennung des darin enthaltenen Textes erheblich erhöhen. In der Praxis funktionieren diese magischen Werkzeuge jedoch nicht immer. In diesem speziellen Fall haben wir das OCR-Modul für den Kunden so angepasst, dass er dieses nicht standardmäßige Farbschema erkennt.5. Inkonsistenz eines der Dokumentparameter mit den angegebenen erkannten Größen
Bilder.
In der Systemkonfiguration sind beispielsweise die Größenbeschränkungen für erkannte Bilder auf 200 x 1000 Pixel festgelegt, und eine Datei mit einer Größe von 500 x 1500 Pixel wird in OCR empfangen (Obergrenze überschritten).
In diesem Fall müssen Sie die OCR-Einstellungen korrigieren, um solche Bilder zu erkennen.Dies ist möglicherweise eines der beliebtesten Szenarien für die Systemrekonfiguration, nachdem uns mitgeteilt wurde, dass OCR nicht funktioniert.
Warum sind OCR nicht auf Agenten?
OCR in DLP-Systemen wird in zwei Versionen implementiert - auf Agenten und auf Servern. Wir befürworten den zweiten Ansatz, da die Bilderkennung direkt auf der Workstation eine hohe Belastung des Prozessors verursacht und dementsprechend die Arbeit anderer Anwendungen verlangsamt. OCR selbst ist selbst für Server eine sehr unersättliche Technologie, und ihre Anwendung erfordert eine ordnungsgemäße Planung der Prozessorkapazitäten und eine Leistungsüberwachung.
Viele inländische Unternehmen, insbesondere im öffentlichen Sektor, besitzen jedoch noch eine ziemlich alte PC-Flotte. Was passiert in diesem Fall? Benutzer beschweren sich bei der IT-Abteilung über das „Bremsen“ des PCs, und IT-Spezialisten stellen schließlich fest, dass die Ursache für das Bremsen das OCR-Modul des DLP-Systems ist. Dies ärgert sie und Benutzer, die Arbeitsaufgaben nicht schnell lösen können. Am Ende summiert sich dies zu Kopfschmerzen für einen Sicherheitsbeamten, der viele andere Aufgaben hat.
Die Verwendung von OCR auf Agenten ist nur gerechtfertigt, wenn das DLP-System "isoliert" arbeitet. In diesem Fall sollte die Bilderkennung genau zu dem Zeitpunkt erfolgen, zu dem der Benutzer Aktionen mit dieser Grafikdatei auf seiner Workstation ausführt. Das heißt, das DLP-System sollte sofort über das Schicksal des Dokuments entscheiden, das dieses Bild enthält - es darf gesendet / kopiert oder verboten werden. In der Praxis verwenden jedoch nur wenige Kunden das DLP-System im aktiven Blockierungsmodus, und dies gilt nicht nur für unser eigenes DLP. Hier funktioniert das Prinzip: "Alles, was für Überprüfungen auf dem Server herausgenommen werden kann, muss auf dem Server ausgeführt werden."
Insgesamt
OCR-Technologien bieten Grafikerkennungsfunktionen. Darüber hinaus geben wir immer allgemeine Empfehlungen für die Systemkonfiguration. In einem bestimmten Projekt kann es jedoch erforderlich sein, das OCR-Modul neu zu konfigurieren, um den spezifischen Anforderungen des Kunden sowohl in der Pilot- und Implementierungsphase der Lösung als auch in der Phase seines industriellen Betriebs gerecht zu werden. Dies ist nicht nur normal - es ist der einzig richtige Weg, um greifbare Ergebnisse zu erzielen, die OCR-Arbeit im Unternehmen so effizient wie möglich zu gestalten und den Verlust vertraulicher Informationen durch grafische Bilder zu minimieren.
Nikita Igonkin, führender Servicetechniker bei Rostelecom Solar