Hallo allerseits! Im Juni fand in Nowosibirsk eine Konferenz zur Entwicklung hochgeladener Anwendungen HighLoad ++ Siberia 2019 statt. In den Artikeln zu Habré haben wir bereits erwähnt, dass wir bei Plesk eine Retrospektive von Konferenzen und Berichten durchführen, an denen wir teilnehmen, um das gewonnene Wissen nicht zu verlieren und es anschließend anzuwenden. Wir werden Ihnen mitteilen, welche Berichte wir für uns selbst notiert haben, und Ihnen auch ein nachträgliches Rezept mitteilen. Die Organisatoren veröffentlichen das Video nach und nach hier:
Youtube-Kanal . Ein Teil dessen, was wir beschreiben, ist bereits zu sehen.
Berichtsübersicht
Victor Eremchenko (Miro)Dies ist ein Übersichtsbericht über die erfolgreiche Migration von Redis -> PostgreSQL -> Pgbouncer + PostgreSQL -> Patroni Consul + Pgbouncer + PostgreSQL. Der Autor gibt Schemata an, typische Fallstricke offensichtlicher Lösungen, spricht über alternative Lösungen und warum sie nicht passen. Aus dem Interessanten:
- Die Ingenieure von Miro haben ihre Lösung zusammengestellt, um nicht für Amazon RDS zu bezahlen, und diese Lösung passt bisher zu ihnen.
- Likbez über Verbindungsmanager für PostgreSQL.
- Beschreibt den Vorgang des Aktualisierens von Clusterknoten, ohne die Anwendung zu stoppen.
- Zeigt einen Trick zum schnellen Aktualisieren von PostgreSQL.
Es ist nützlich zu sehen, wer PostgreSQL verwendet oder verwenden wird und mit zunehmender Datenmenge.
Wassili Bogonatow (Yandex)Als Einführungsredner machte er einen kurzen Vergleich einiger Funktionen von Kafka und RabbitMQ. Kurz gesagt: Kafka - eine einfache Warteschlange, ein komplexer Empfänger; RabbitMQ ist eine komplexe Warteschlange, ein einfacher Empfänger. Der Autor sprach auch über die Arten von Garantien für die Zustellung einer Nachricht aus der Warteschlange. Wichtiger Hinweis: Keine Warteschlange kann die Zustellung einer Nachricht genau einmal ohne Unterstützung von Absender und Empfänger sicherstellen.
Der Bericht ist YandexMQ gewidmet. YandexMQ (YMQ) ist eine API, die mit der Amazon SQS-Warteschlange kompatibel ist. Die Grundlage von YandexMQ ist die Yandex-Datenbank (YDB). Vasily zeigte den Vorteil von YandexMQ, wie man strenge Konsistenz und Zuverlässigkeit erreicht, und gab einen Überblick über die Architektur von YMQ. YMQ implementiert das Muster "Konkurrierende Verbraucher" - eine Nachricht an einen Verbraucher. YMQ-Chip: Wenn der Verbraucher nach einer Nachricht fragt, wird diese in der Warteschlange versteckt, damit sie von niemand anderem verarbeitet wird. Wenn während der Verarbeitung Probleme auftreten, wird die Nachricht nach VisibilityTimeout wieder in der Warteschlange angezeigt. Der Sprecher behauptet, dass Apache Kafka ein Datenverlustproblem hat, wenn der Prozess plötzlich beendet wird. Yandex MessageQueue ist dagegen resistent.

Der Bericht wird jedem empfohlen, der die grundlegenden Funktionen der Warteschlangen verstehen möchte.
Ivan Muratov (Erste Überwachungsfirma)Bericht über das Speichern und Verarbeiten von Daten in der PostgreSQL-Zeitreihe.
Mit TimescaleDB können Sie aufgrund einer ausgeklügelten Partitionierung große Volumes speichern, und PipelineDB bietet die Arbeit mit Streams direkt in PostgreSQL (sowie die Integration in Warteschlangen).
TimescaleDB:
- Es hat eine sehr stabile Aufzeichnungsgeschwindigkeit mit einer Zunahme des Volumens der Datenbank unter hoher Last und mit einer Zunahme der Anzahl von Partitionen, gemessen in Tausenden.
- Ermöglicht die Verwendung von Standard-PostgreSQL-Funktionen wie SQL, Replikation, Sicherung, Wiederherstellung usw.
- Eine gute Reihe von Integrationen wird beispielsweise mit Prometheus, Telegraf, Grafana, Zabbix, Kubernetes angekündigt.
- Es gibt eine kostenlose Open Source-Version.
Die Hauptidee: TimescaleDB wird hauptsächlich zum Speichern von Daten benötigt.
PipelineDB:
- Ermöglicht die kontinuierliche Verarbeitung eingehender Daten mithilfe von SQL und das Hinzufügen des Ergebnisses zu einer Tabelle.
- Hat eine SQL-Schnittstelle.
- Unter den Bedingungen werden gespeicherte Prozeduren ausgeführt.
- Integrationen mit Apache Kafka und Amazon Kinesis sind möglich.
- Es gibt eine kostenlose Open Source-Version.
- Die PipelineDB-Entwicklung ist in Version 1.0 eingefroren, und jetzt werden nur Fehlerbehebungen veröffentlicht.
Die Hauptidee: PipelineDB wird hauptsächlich für die Datenverarbeitung benötigt.
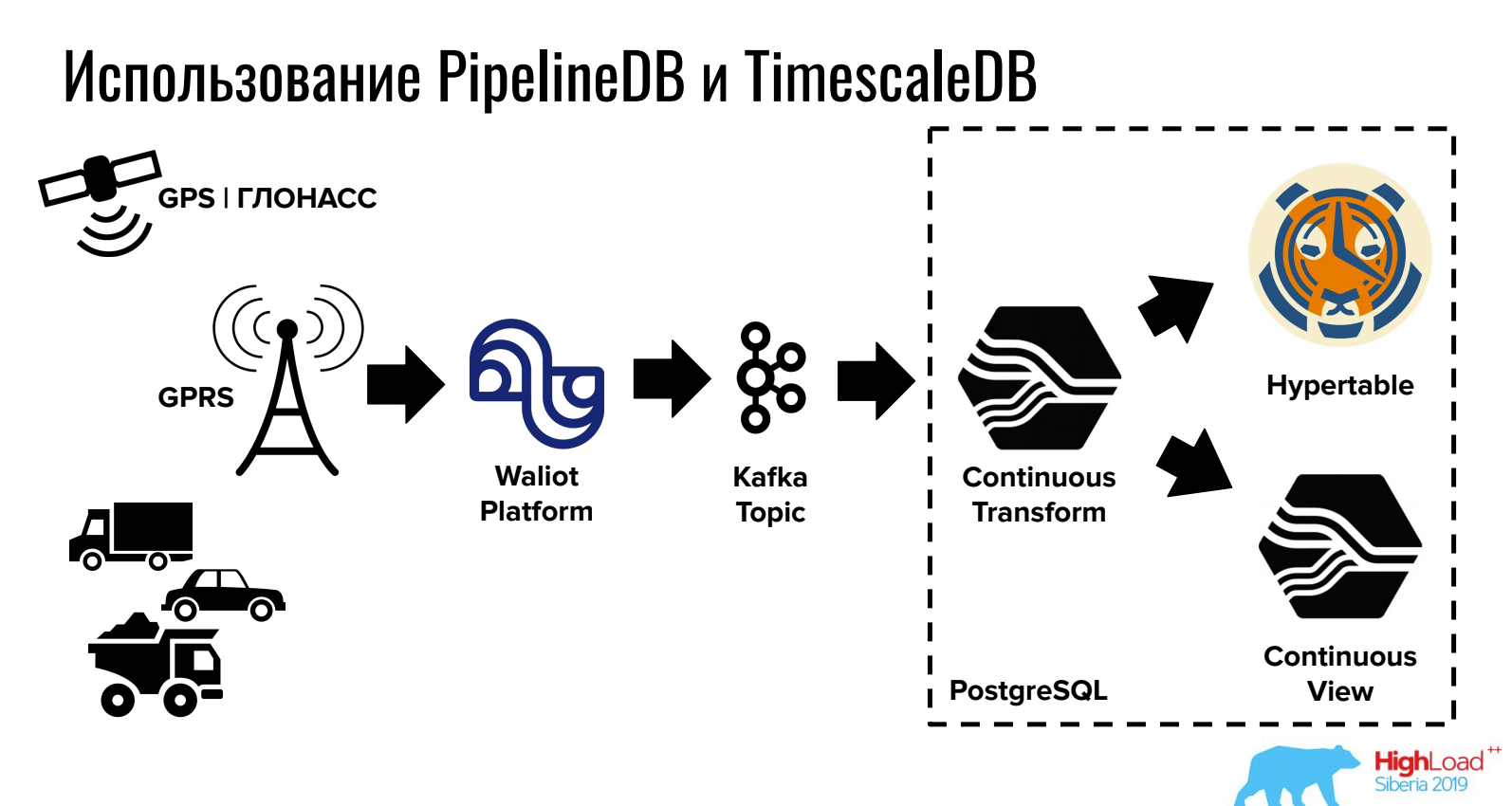
Für Aufgaben, bei denen gleichzeitig ein relationales DBMS, NoSQL und Zeitreihen benötigt werden, kann diese Option sehr praktisch sein.
Pavel Luzanov (Postgres Professional)Ein guter Übersichtsbericht über PostgreSQL, Tabellenvererbung und Tips & Tricks-Leistung von PostgreSQL 10, 11, 12+. Partitionierung durch Vererbung, Scherben. Es ist nützlich, alle zu sehen, die PostgreSQL verwenden und es etwas schneller machen möchten.
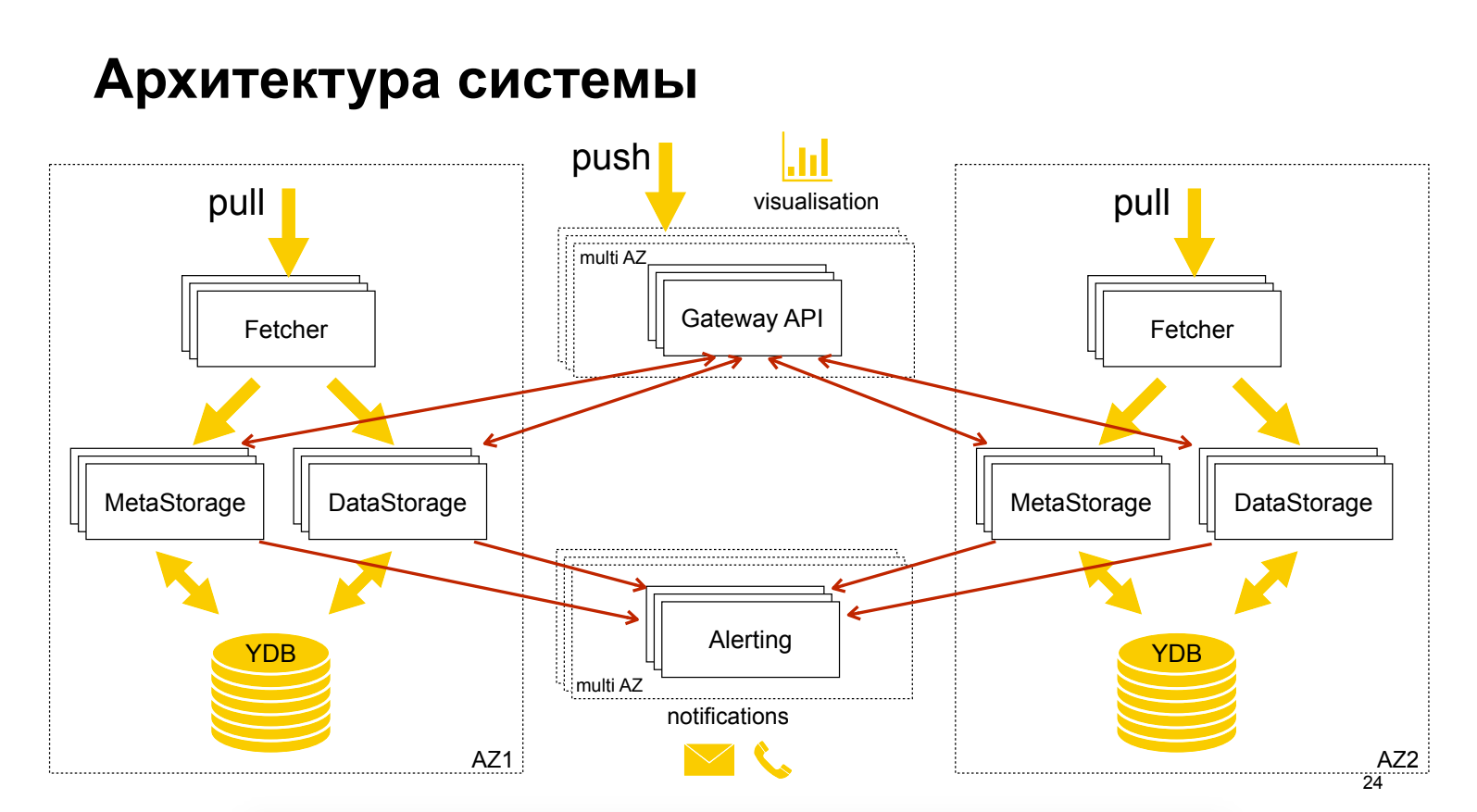
Sergey Polovko (Yandex)Informationen zum Cloud-Produkt Yandex Monitoring, das sich noch in der Vorschau befindet, sind kostenlos. Ein bisschen über Architektur. Es wird eine interessante Technik gezeigt - die Trennung von Metadaten von Daten, die eine unabhängige Skalierung und Optimierung ermöglicht. Grafana wird als GUI verwendet, während sich die Warnungen nicht in Grafana befinden.
 Andrey Salnikov (Datenreiher)
Andrey Salnikov (Datenreiher)Erfahrung in der kommerziellen Systemadministration vieler PostgreSQL-Server. Hier erfahren Sie, welche Serverparameter automatisch überwacht werden und wie Aufgaben priorisiert werden.
Data Egret verwendet allgemeine Erfahrungen im Wiki mit Rezepten und Checklisten - dies ist die Grundlage für zukünftige Artikel und Berichte. Sie verwenden eine Vorfalldatenbank mit einer Beschreibung der Probleme und Lösungen - dies spart erheblich Ressourcen. Eine Reihe von Dienstprogrammen für die Arbeit mit PostgreSQL veröffentlicht, Links zu diesen bereitstellen.
 Evgeny Sokolov (Yandex.Market)
Evgeny Sokolov (Yandex.Market)Bericht über die Architektur einer komplexen, leicht zugänglichen, verteilten Yandex.Market-Anwendung sowie über die Prozesse und Tools für deren Entwicklung, Test, Aktualisierung und Überwachung. Aus dem Interessanten:
- „Stop-Crane“ ist die Lösung für die schnelle Anwendung und das Zurücksetzen der Konfiguration und hilft beim Testen neuer Funktionen.
- Bei Problemen wird der Datenverkehr vom Balancer vom aktuellen Rechenzentrum zu einem anderen Rechenzentrum umgeleitet.
- Zur Überwachung werden Graphit und Grafana verwendet.
- Auf einem anderen Technologie-Stack gibt es eine doppelte Basisüberwachung.
- Für Entwickler wird ein Schattencluster verwendet, der einen Teil des Benutzerverkehrs dupliziert. Benutzer sehen die Antworten des Schattenclusters nicht.
- Während des A / B-Tests wird eine automatische Qualitätsberechnung durchgeführt.
 Anton Alekseev (2GIS)
Anton Alekseev (2GIS)Berichten Sie, was ClickHouse kann und wie man es in Verbindung mit Grafana kocht. Das Hauptinteresse:
- Wenn die Geschwindigkeit nicht ausreicht, sollten Sie die Abtastung verwenden (es wird argumentiert, dass die Genauigkeit der Daten nach der Abtastung ausreichend ist). Sampling in ClickHouse - Teilweise Sampling von Daten mit Aggregation unter Beibehaltung des Verhältnisses verschiedener Werte im Tabellenschlüssel ermöglicht es Ihnen, die Aggregation zeitweise zu beschleunigen und gleichzeitig ein Ergebnis zu erzielen, das dem Real sehr nahe kommt.
- Mit ClickHouse können Vorfälle schnell untersucht werden (ein interessantes Beispiel im Bericht).
- ClickHouse verfügt auch über eine MaterializedView, um das Abrufen zu beschleunigen.
- Die ClickHouse-HTTP-Schnittstelle zum Abfragen und Laden von Daten wird beschrieben.
Abschließend möchte ich darauf hinweisen, dass uns auch der Bericht
„Videoanrufe: von Millionen pro Tag bis 100 Teilnehmer an einer Konferenz“ (
Alexander Tobol / Odnoklassniki), der gemäß den Abstimmungsergebnissen in die Liste der besten Berichte der Konferenz aufgenommen wurde, sehr gut gefallen hat. Dies ist ein großartiger Überblick darüber, wie Videokonferenzen für eine Gruppe von Teilnehmern funktionieren. Der Bericht zeichnet sich durch eine verständliche systemische Darstellung aus. Wenn Sie plötzlich Videoanrufe tätigen müssen, können Sie den Bericht anzeigen, um schnell einen Einblick in den Themenbereich zu erhalten.
Plesk Conference Flashback Structure
Und jetzt zum Nachtisch darüber, wie wir eine Retrospektive innerhalb des Unternehmens schreiben. Zunächst versuchen wir, in der ersten Woche nach der Teilnahme an der Konferenz Retro zu schreiben, während unsere Erinnerungen noch frisch sind. Übrigens kann das retrospektive Material dann, wie Sie sich vorstellen können, als Grundlage für den Artikel dienen;)
Der Zweck des Schreibens einer Retrospektive besteht nicht nur darin, Wissen zu konsolidieren, sondern es auch mit denen zu teilen, die nicht an der Konferenz teilgenommen haben, sondern sich über die neuesten Trends und interessanten Lösungen auf dem Laufenden halten möchten. Eine vorgefertigte Liste verkürzt die Zeit für die Suche nach interessanten Berichten. Wir schreiben die Lektionen auf, die wir für uns selbst gelernt haben, markieren bestimmte Personen mit einem Hinweis, warum Sie den Bericht sehen und über die Ideen und Entscheidungen anderer nachdenken müssen. Die schriftlichen Lektionen helfen, sich zu konzentrieren und nicht zu verlieren, was wir tun wollten. Wenn wir uns die Aufnahmen in 3-6 Monaten ansehen, werden wir verstehen, wenn wir etwas Wichtiges vergessen haben.
Wir speichern die Dokumentation im Unternehmen in Confluence. Für Konferenzen haben wir einen separaten Seitenbaum, ein Stück Holz:
Wie aus dem Screenshot hervorgeht, legen wir die Materialien zur Erleichterung der Navigation nach Jahr an.
Auf der einer bestimmten Konferenz gewidmeten Seite speichern wir die folgenden Abschnitte: Übersicht mit Links zur Veranstaltungswebsite, Zeitplan, Videos und Präsentationen, Teilnehmerliste (persönlich und in Sendungen), allgemeiner Eindruck (Gesamteindruck) und detaillierte Übersicht (detaillierte Übersicht) ) Übrigens generieren wir eine Retro-Seite aus einer Vorlage, in der die gesamte Struktur bereits vorhanden ist. Wir stellen auch den Inhalt der Überschriften zusammen, damit Sie die Liste der Berichte sehr schnell anzeigen und mit dem gewünschten fortfahren können.
Der Abschnitt Gesamteindruck gibt einen kurzen Überblick über die Konferenz und gibt die Eindrücke der Teilnehmer. Wenn die Teilnehmer in den letzten Jahren an der Konferenz teilgenommen haben, können sie ihre Niveaus vergleichen und allgemein die Nützlichkeit der Teilnahme an der Veranstaltung verstehen.
Der Abschnitt Detaillierte Übersicht enthält eine Tabelle:

Ein Beispiel für das Füllen einer Tabelle:

Wir würden uns über die Berichte freuen, die Ihnen auf der Highload Siberia 2019 gefallen haben, sowie über Ihre Erfahrungen bei der Durchführung von Retrospektiven.