
Die Übersetzung des Artikels wurde für Studenten des Kurses "MS SQL Server Developer" vorbereitet.
Relationale Datenbanken sind bis heute eine der am häufigsten verwendeten Datenbanken. Daher sind für die meisten Beiträge SQL-Kenntnisse erforderlich. In diesem Artikel werde ich Ihnen mit SQL-Fragen aus Interviews die am häufigsten gestellten Fragen zu SQL (Structured Query Language - Strukturierte Abfragesprache) vorstellen. Dieser Artikel ist eine ideale Anleitung zum Erkunden aller Konzepte in Bezug auf SQL, Oracle, MS SQL Server und die MySQL-Datenbank.
Unser SQL-Fragenartikel ist eine universelle Ressource, mit der Sie die Vorbereitung auf ein Interview beschleunigen können. Es besteht aus 65 der häufigsten Fragen , die ein Interviewer während eines Interviews stellen kann. Es beginnt normalerweise mit grundlegenden SQL-Fragen und geht dann zu komplexeren Fragen über, die auf der Diskussion und Ihren Antworten basieren. Diese SQL-Interviewfragen helfen Ihnen dabei, Ihren Nutzen auf verschiedenen Ebenen des Verständnisses zu maximieren.
Fangen wir an!
Interview SQL Fragen
Frage 1. Was ist der Unterschied zwischen DELETE und TRUNCATE?
Frage 2. Was sind die Teilmengen von SQL?
- DDL (Data Definition Language) - Ermöglicht die Ausführung verschiedener Vorgänge mit der Datenbank, z. B. CREATE (Erstellen), ALTER (Ändern) und DROP (Löschen von Objekten).
- DML (Data Manipulation Language) - Ermöglicht den Zugriff auf und die Bearbeitung von Daten, z. B. das Einfügen, Aktualisieren, Löschen und Abrufen von Daten aus einer Datenbank.
- DCL (Data Control Language) - Ermöglicht die Steuerung des Zugriffs auf die Datenbank. Ein Beispiel ist GRANT (Grant Rights), REVOKE (Widerrufsrechte).
Frage 3. Was ist mit DBMS gemeint? Welche Arten von DBMS gibt es?
Datenbank ist eine strukturierte Datenerfassung. Database Management System (DBMS) - Software, die mit dem Benutzer, den Anwendungen und der Datenbank selbst interagiert, um Daten zu sammeln und zu analysieren. Das DBMS ermöglicht dem Benutzer die Interaktion mit der Datenbank. Die in der Datenbank gespeicherten Daten können geändert, abgerufen und gelöscht werden. Sie können von einem beliebigen Typ sein, z. B. Zeichenfolgen, Zahlen, Bilder usw.
Es gibt zwei Arten von DBMS:
- Relationales Datenbankverwaltungssystem: Daten werden in Beziehungen (Tabellen) gespeichert. Ein Beispiel ist MySQL.
- Nicht relationales Datenbankverwaltungssystem: Es gibt kein Konzept für Beziehungen, Tupel und Attribute. Ein Beispiel ist Mongo.
Frage 4. Was ist mit Tabelle und Feld in SQL gemeint?
Eine Tabelle ist ein organisierter Datensatz in Form von Zeilen und Spalten. Ein Feld ist eine Spalte in einer Tabelle. Zum Beispiel:
Tabelle: Student_Information
Feld: Stu_Id, Stu_Name, Stu_Marks
Frage 5. Was sind Joins in SQL?
Der JOIN-Operator wird verwendet, um Zeilen aus zwei oder mehr Tabellen basierend auf einer zwischen ihnen verbundenen Spalte zu verknüpfen. Es wird verwendet, um zwei Tabellen zu verbinden oder Daten von dort abzurufen. In SQL gibt es 4 Verbindungstypen:
- Inner Join
- Right Join
- Links beitreten
- Vollständige Teilnahme
Frage 6. Was ist der Unterschied zwischen den Datentypen CHAR und VARCHAR in SQL?
Sowohl Char als auch Varchar dienen als Zeichendatentypen, aber varchar wird für Zeichenfolgen variabler Länge verwendet, während Char für Zeichenfolgen fester Länge verwendet wird. Beispielsweise kann char (10) nur 10 Zeichen und keine Zeichenfolge beliebiger Länge speichern, während varchar (10) eine Zeichenfolge beliebiger Länge bis 10 speichern kann, d. H. B. 6, 8 oder 2.
Frage 7. Was ist ein Primärschlüssel?

- Ein Primärschlüssel ist eine Spalte oder ein Satz von Spalten, die jede Zeile in einer Tabelle eindeutig identifizieren.
- Identifiziert eine Zeile in einer Tabelle eindeutig
- Nullwerte nicht erlaubt
_Beispiel: In der Student Stu-Tabelle lautet der Primärschlüssel.
Frage 8. Was sind Einschränkungen?
Einschränkungen werden verwendet, um Einschränkungen für den Datentyp einer Tabelle anzuzeigen. Sie können beim Erstellen oder Ändern einer Tabelle angegeben werden. Beispiel Einschränkungen:
- NICHT NULL
- PRÜFEN
- STANDARD
- EINZIGARTIG
- Primärschlüssel
- AUSLÄNDISCHER SCHLÜSSEL
Frage 9. Was ist der Unterschied zwischen SQL und MySQL?
SQL ist die standardmäßige strukturierte Abfragesprache, die auf der englischen Sprache basiert, während MySQL ein Datenbankverwaltungssystem ist. SQL ist eine relationale Datenbanksprache, die für den Zugriff auf und die Verwaltung von Daten verwendet wird. MySQL ist ein relationales DBMS (Datenbankverwaltungssystem) sowie SQL Server, Informix usw.
Frage 10. Was ist ein eindeutiger Schlüssel?
- Identifiziert eine Zeile in einer Tabelle eindeutig.
- In einer Tabelle sind viele eindeutige Schlüssel zulässig.
- NULL-Werte sind zulässig ( Übersetzungshinweis: abhängig vom DBMS; in SQL Server kann NULL nur einmal in einem Feld mit UNIQUE KEY hinzugefügt werden ).
Frage 11. Was ist ein Fremdschlüssel?
- Ein Fremdschlüssel behält die referenzielle Integrität bei, indem er eine Verknüpfung zwischen Daten in zwei Tabellen bereitstellt.
- Der Fremdschlüssel in der untergeordneten Tabelle bezieht sich auf den Primärschlüssel in der übergeordneten Tabelle.
- Eine Fremdschlüsseleinschränkung verhindert Aktionen, die die Beziehungen zwischen der untergeordneten und der übergeordneten Tabelle unterbrechen.
Frage 12. Was versteht man unter Datenintegrität?
Die Datenintegrität bestimmt die Genauigkeit sowie die Konsistenz der in der Datenbank gespeicherten Daten. Außerdem werden Integritätsbeschränkungen definiert, um Geschäftsregeln für Daten durchzusetzen, wenn diese in eine Anwendung oder Datenbank eingegeben werden.
Frage 13. Was ist der Unterschied zwischen gruppierten und nicht gruppierten Indizes in SQL?
- Unterschiede zwischen geclusterten und nicht geclusterten Indizes in SQL:
Ein Clustered-Index wird verwendet, um Daten einfach und schnell aus einer Datenbank abzurufen, während das Lesen aus einem Nicht-Clustered-Index relativ langsamer ist. - Ein Clustered-Index ändert die Art und Weise, wie Datensätze in der Datenbank gespeichert werden. Er sortiert die Zeilen nach einer Spalte, die als Clustered-Index festgelegt ist, während er in einem Nicht-Clustered-Index die Speichermethode nicht ändert, sondern ein separates Objekt in der Tabelle erstellt, das bei der Suche auf die ursprünglichen Tabellenzeilen verweist.
- Eine Tabelle kann nur einen Clustered-Index haben, während sie viele Nonclustered-Indizes haben kann.
Frage 14. Schreiben Sie eine SQL-Abfrage, um das aktuelle Datum anzuzeigen.
SQL verfügt über eine integrierte GetDate () - Funktion, mit deren Hilfe der aktuelle Zeitstempel / das aktuelle Datum zurückgegeben werden kann.
Frage 15. Listen Sie die Verbindungstypen auf
Es gibt verschiedene Arten von Verknüpfungen, mit denen Daten zwischen Tabellen extrahiert werden. Grundsätzlich werden sie in vier Typen unterteilt, nämlich:
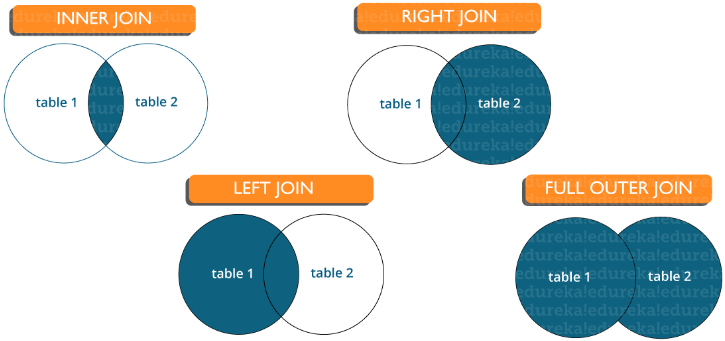
Innerer Join : In MySQL der häufigste Typ. Es wird verwendet, um alle Zeilen aus mehreren Tabellen zurückzugeben, für die die Verknüpfungsbedingung erfüllt ist.
Linker Join : In MySQL werden alle Zeilen aus der linken (ersten) Tabelle und nur übereinstimmende Zeilen aus der rechten (zweiten) Tabelle zurückgegeben, für die die Join-Bedingung erfüllt ist.
Right Join : In MySQL werden alle Zeilen aus der rechten (zweiten) Tabelle und nur übereinstimmende Zeilen aus der linken (ersten) Tabelle zurückgegeben, für die die Join-Bedingung erfüllt ist.
Vollständiger Join : Gibt alle Datensätze zurück, für die in einer der Tabellen eine Übereinstimmung vorliegt. Daher werden alle Zeilen aus der linken Tabelle und alle Zeilen aus der rechten Tabelle zurückgegeben.
Frage 16. Was meinst du mit Denormalisierung?
Die Denormalisierung ist eine Technik, mit der von höheren zu niedrigeren Normalformen konvertiert wird. Es hilft Datenbankentwicklern, die Leistung der gesamten Infrastruktur zu verbessern, indem Redundanz in die Tabelle eingeführt wird. Angesichts der häufigen Datenbankabfragen, bei denen Daten aus verschiedenen Tabellen in einer Tabelle zusammengefasst werden, werden der Tabelle redundante Daten hinzugefügt.
Frage 17. Was sind Entitäten und Beziehungen?
Entitäten: eine Person, ein Ort oder ein Objekt in der realen Welt, deren Daten in einer Datenbank gespeichert werden können. Tabellen speichern Daten, die einen Entitätstyp darstellen. Beispielsweise verfügt eine Bankdatenbank über eine Kundentabelle zum Speichern von Kundeninformationen. In der Kundentabelle werden diese Informationen als eine Reihe von Attributen (Spalten in der Tabelle) für jeden Kunden gespeichert.
Beziehungen: Beziehungen oder Beziehungen zwischen Entitäten, die irgendwie miteinander verwandt sind. Beispielsweise wird der Name eines Kunden mit einer Kundenkontonummer und Kontaktinformationen verknüpft, die sich möglicherweise in derselben Tabelle befinden. Es kann auch Beziehungen zwischen einzelnen Tabellen geben (z. B. Kunde zu Konten).
Frage 18. Was ist ein Index?
Indizes beziehen sich auf eine Leistungsoptimierungsmethode, mit der Datensätze schneller aus einer Tabelle abgerufen werden können. Der Index erstellt eine separate Struktur für das indizierte Feld und ermöglicht daher einen schnelleren Datenabruf.
Frage 19. Beschreiben Sie die verschiedenen Arten von Indizes.
Es gibt drei Arten von Indizes:
- Eindeutiger Index: Dieser Index verhindert, dass das Feld doppelte Werte aufweist, wenn die Spalte eindeutig indiziert ist. Wenn ein Primärschlüssel definiert ist, kann automatisch ein eindeutiger Index angewendet werden.
- Clustered Index: Dieser Index ändert die physische Reihenfolge der Tabelle und sucht anhand von Schlüsselwerten. Jede Tabelle kann nur einen Clustered-Index haben.
- Nicht gruppierter Index: Ändert nicht die physische Reihenfolge der Tabelle und behält die logische Reihenfolge der Daten bei. Jede Tabelle kann viele nicht gruppierte Indizes haben.
Frage 20. Was ist Normalisierung und welche Vorteile hat sie?
Bei der Normalisierung werden Daten organisiert, um Doppelarbeit und Redundanz zu vermeiden. Einige der Vorteile:
- Beste Datenbankorganisation
- Weitere Tabellen mit kleinen Zeilen
- Effektiver Datenzugriff
- Mehr Flexibilität bei Abfragen
- Schnelle Informationssuche
- Einfachere Implementierung der Datensicherheit
- Ermöglicht eine einfache Änderung
- Reduzieren Sie redundante und doppelte Daten
- Kompaktere Datenbank
- Gewährleistet die Datenkonsistenz nach Änderungen
Frage 21. Was ist der Unterschied zwischen DROP und TRUNCATE?
Der Befehl DROP löscht die Tabelle selbst, und Sie können keine Rollback-Befehle ausführen, während der Befehl TRUNCATE alle Zeilen aus der Tabelle löscht ( Anmerkung Übersetzung: In SQL Server funktioniert Rollback normalerweise und rollt DROP zurück ).
Frage 22. Erklären Sie die verschiedenen Arten der Normalisierung.
Es gibt viele aufeinanderfolgende Normalisierungsstufen. Dies sind die sogenannten Normalformen. Jede nachfolgende Normalform enthält die vorherige. Die ersten drei Normalformen reichen normalerweise aus.
- Erste Normalform (1NF) - keine doppelten Gruppen in Zeilen
- Die zweite Normalform (2NF) - jeder Nichtschlüssel (unterstützende) Spaltenwert hängt vom gesamten Primärschlüssel ab
- Dritte Normalform (3NF) - Jeder Nichtschlüsselwert hängt nur vom Primärschlüssel ab und nicht von einem anderen Nichtschlüsselwert der Spalte
Frage 23. Was ist die ACID-Eigenschaft in der Datenbank?
ACID bedeutet Atomizität, Konsistenz, Isolation, Haltbarkeit. Es wird verwendet, um eine zuverlässige Verarbeitung von Datentransaktionen in einem Datenbanksystem bereitzustellen.
Atomizität. Stellt sicher, dass die Transaktion vollständig abgeschlossen ist oder fehlschlägt, wobei die Transaktion eine einzelne logische Datenoperation darstellt. Dies bedeutet, dass wenn ein Teil einer Transaktion fehlschlägt, die gesamte Transaktion fehlschlägt und der Status der Datenbank unverändert bleibt.
Kohärenz. Stellt sicher, dass die Daten allen Validierungsregeln entsprechen müssen. Einfach ausgedrückt können Sie sagen, dass Ihre Transaktion Ihre Datenbank niemals in einem ungültigen Zustand belässt.
Isolierung. Der Hauptzweck der Isolierung besteht darin, den Mechanismus paralleler Datenänderungen zu steuern.
Langlebigkeit. Dauerhaftigkeit bedeutet, dass bei Bestätigung der Transaktion (COMMIT) die innerhalb der Transaktion aufgetretenen Änderungen beibehalten werden, unabhängig davon, was ihnen im Weg steht (z. B. Stromausfall, Ausfall oder Fehler jeglicher Art).
Frage 24. Was meinst du mit einem "Trigger" in SQL?
Ein Trigger in SQL ist eine spezielle Art von gespeicherter Prozedur, die bei oder nach Datenänderungen automatisch ausgeführt wird. Auf diese Weise können Sie ein Codepaket ausführen, wenn eine Einfügung, Aktualisierung oder eine andere Abfrage für eine bestimmte Tabelle ausgeführt wird.
Frage 25. Welche Anweisungen sind in SQL verfügbar?
In SQL stehen drei Arten von Anweisungen zur Verfügung:
- Arithmetische Operatoren
- Logische Operatoren
- Vergleichsoperatoren
Frage 26. Stimmen NULL-Werte mit Null oder Leerzeichen überein?
NULL ist überhaupt nicht Null oder Leerzeichen. Ein NULL-Wert stellt einen Wert dar, der nicht verfügbar, unbekannt, zugewiesen oder nicht anwendbar ist, während Null eine Zahl und Leerzeichen ein Zeichen ist.
Frage 27. Was ist der Unterschied zwischen einem Cross-Join und einem natürlichen Join?
Ein Cross-Join erstellt ein Cross- oder kartesisches Produkt aus zwei Tabellen, während ein natürlicher Join auf allen Spalten basiert, die in beiden Tabellen denselben Namen und denselben Datentyp haben.
Frage 28. Was ist eine Unterabfrage in SQL?
Eine Unterabfrage ist eine Abfrage in einer anderen Abfrage, die eine Abfrage zum Abrufen von Daten oder Informationen aus einer Datenbank definiert. In einer Unterabfrage wird die äußere Abfrage als Hauptabfrage bezeichnet, während die innere Abfrage als Unterabfrage bezeichnet wird. Unterabfragen werden immer zuerst ausgeführt, und das Ergebnis der Unterabfrage wird an die Hauptabfrage übergeben. Es kann in SELECT, UPDATE oder einer anderen Abfrage verschachtelt sein. Eine Unterabfrage kann auch einen beliebigen Vergleichsoperator verwenden, z. B.>, <oder =.
Frage 29. Welche Arten von Unterabfragen gibt es?
Es gibt zwei Arten von Unterabfragen: korrelierte und nicht korrelierte.
- Korrelierte Unterabfrage: Dies ist eine Abfrage, die Daten aus einer Tabelle mit einem Link zu einer externen Abfrage auswählt. Es wird nicht als unabhängige Abfrage betrachtet, da es auf eine andere Tabelle oder Spalte in der Tabelle verweist.
- Nicht korrelierte Unterabfrage: Diese Abfrage ist eine unabhängige Abfrage, bei der die Ausgabe der Unterabfrage in die Hauptabfrage eingesetzt wird.
Frage 30. Wie können Sie die Anzahl der Datensätze in der Tabelle ermitteln?
Um die Anzahl der Datensätze in einer Tabelle zu zählen, können Sie die folgenden Befehle verwenden:
SELECT * FROM table1
SELECT COUNT(*) FROM table1
SELECT rows FROM sysindexes WHERE id = OBJECT_ID(table1) AND indid < 2
Wir werden im nächsten Teil weitere 35 Fragen mit Antworten veröffentlichen ... Folgen Sie den Nachrichten!