
Wir veröffentlichen weiterhin Analysen der Aufgaben, die bei der letzten Meisterschaft vorgeschlagen wurden. Als nächstes folgen Aufgaben aus der Qualifikationsrunde für Spezialisten für maschinelles Lernen. Dies ist der dritte von vier Tracks (Backend, Frontend, ML, Analytics). Die Teilnehmer mussten ein Modell für die Korrektur von Tippfehlern in Texten erstellen, eine Strategie für das Spielen an Spielautomaten vorschlagen, ein System von Empfehlungen für Inhalte in Erinnerung rufen und mehrere weitere Programme erstellen.
A. Tippfehler
Zustand
(Epigraph) (aus einem Forum)
- Wer hat diesen Unsinn komponiert?
- Astrophysiker. Sie sind auch Menschen.
- Sie haben 10 Fehler im Wort "Journalisten" gemacht.
Viele Benutzer machen Tippfehler, einige aufgrund von Tastenanschlägen und andere aufgrund ihres Analphabetismus. Wir möchten prüfen, ob der Benutzer tatsächlich an ein anderes Wort als das von ihm eingegebene denken kann.
Nehmen wir formeller an, dass das folgende Fehlermodell auftritt: Der Benutzer beginnt mit einem Wort, das er schreiben möchte, und macht anschließend eine Reihe von Fehlern. Jeder Fehler ist eine Ersetzung eines Teilstrings des Wortes durch einen anderen Teilstring. Ein Fehler entspricht dem Ersetzen nur an einer Position (dh wenn der Benutzer einen einzelnen Fehler durch die Regel "abc" → "cba" machen möchte, kann er aus der Zeichenfolge "abcabc" entweder "cbaabc" oder "abccba" erhalten). Nach jedem Fehler wird der Vorgang wiederholt. Dieselbe Regel könnte mehrmals in verschiedenen Schritten verwendet werden (im obigen Beispiel könnte beispielsweise "cbacba" in zwei Schritten erhalten werden).
Es ist erforderlich, die Mindestanzahl von Fehlern zu bestimmen, die ein Benutzer machen kann, wenn er ein bestimmtes Wort im Auge hat und ein anderes schreibt.
E / A-Formate und BeispielEingabeformat
Die erste Zeile enthält das Wort, das der Benutzer nach unserer Annahme im Sinn hatte (es besteht aus Buchstaben des lateinischen Alphabets in Kleinbuchstaben, die Länge überschreitet 20 nicht).
Die zweite Zeile enthält das Wort, das er tatsächlich geschrieben hat (es besteht auch aus Buchstaben des lateinischen Alphabets in Kleinbuchstaben, die Länge überschreitet 20 nicht).
Die dritte Zeile enthält eine einzelne Zahl N (N <50) - die Anzahl der Ersetzungen, die verschiedene Fehler beschreiben.
Die nächsten N Zeilen enthalten mögliche Ersetzungen im Format & lt "korrekte" Buchstabenfolge & gt <Leerzeichen> <"fehlerhafte" Buchstabenfolge>. Sequenzen dürfen nicht länger als 6 Zeichen sein.
Ausgabeformat
Es ist erforderlich, eine Zahl zu drucken - die Mindestanzahl von Fehlern, die der Benutzer machen kann. Wenn diese Zahl 4 überschreitet oder es unmöglich ist, aus einem Wort ein anderes zu erhalten, drucken Sie -1.
Beispiel
Lösung
Versuchen wir, aus der richtigen Schreibweise alle möglichen Wörter mit nicht mehr als 4 Fehlern zu generieren. Im schlimmsten Fall kann O ((L﹒N)
4 ) vorliegen. In den Grenzen des Problems ist dies eine ziemlich große Zahl, daher müssen Sie herausfinden, wie Sie die Komplexität reduzieren können. Stattdessen können Sie den Meet-in-the-Middle-Algorithmus verwenden: Generieren Sie Wörter mit nicht mehr als 2 Fehlern sowie Wörter, aus denen Sie ein vom Benutzer geschriebenes Wort mit nicht mehr als 2 Fehlern erhalten können. Beachten Sie, dass die Größe jedes dieser Sätze 10
6 nicht überschreitet. Wenn die Anzahl der vom Benutzer gemachten Fehler 4 nicht überschreitet, überschneiden sich diese Sätze. Ebenso können wir überprüfen, ob die Anzahl der Fehler 3, 2 und 1 nicht überschreitet.
struct FromTo { std::string from; std::string to; }; std::pair<size_t, std::string> applyRule(const std::string& word, const FromTo &fromTo, int pos) { while(true) { int from = word.find(fromTo.from, pos); if (from == std::string::npos) { return {std::string::npos, {}}; } int to = from + fromTo.from.size(); auto cpy = word; for (int i = from; i < to; i++) { cpy[i] = fromTo.to[i - from]; } return {from, std::move(cpy)}; } } void inverseRules(std::vector<FromTo> &rules) { for (auto& rule: rules) { std::swap(rule.from, rule.to); } } int solve(std::string& wordOrig, std::string& wordMissprinted, std::vector<FromTo>& replaces) { std::unordered_map<std::string, int> mapping; std::unordered_map<int, std::string> mappingInverse; mapping.emplace(wordOrig, 0); mappingInverse.emplace(0, wordOrig); mapping.emplace(wordMissprinted, 1); mappingInverse.emplace(1, wordMissprinted); std::unordered_map<int, std::unordered_set<int>> edges; auto buildGraph = [&edges, &mapping, &mappingInverse](int startId, const std::vector<FromTo>& replaces, bool dir) { std::unordered_set<int> mappingLayer0; mappingLayer0 = {startId}; for (int i = 0; i < 2; i++) { std::unordered_set<int> mappingLayer1; for (const auto& v: mappingLayer0) { auto& word = mappingInverse.at(v); for (auto& fromTo: replaces) { size_t from = 0; while (true) { auto [tmp, wordCpy] = applyRule(word, fromTo, from); if (tmp == std::string::npos) { break; } from = tmp + 1; { int w = mapping.size(); mapping.emplace(wordCpy, w); w = mapping.at(wordCpy); mappingInverse.emplace(w, std::move(wordCpy)); if (dir) { edges[v].emplace(w); } else { edges[w].emplace(v); } mappingLayer1.emplace(w); } } } } mappingLayer0 = std::move(mappingLayer1); } }; buildGraph(0, replaces, true); inverseRules(replaces); buildGraph(1, replaces, false); { std::queue<std::pair<int, int>> q; q.emplace(0, 0); std::vector<bool> mask(mapping.size(), false); int level{0}; while (q.size()) { auto [w, level] = q.front(); q.pop(); if (mask[w]) { continue; } mask[w] = true; if (mappingInverse.at(w) == wordMissprinted) { return level; } for (auto& v: edges[w]) { q.emplace(v, level + 1); } } } return -1; }
B. Vielarmiger Bandit
Zustand
Dies ist eine interaktive Aufgabe.
Sie selbst wissen nicht, wie es passiert ist, aber Sie befanden sich in einer Halle mit Spielautomaten mit einer ganzen Tüte Token. Leider lehnen sie es an der Abendkasse ab, Token zurückzunehmen, und Sie haben beschlossen, Ihr Glück zu versuchen. Es gibt viele Spielautomaten in der Halle, die Sie spielen können. Für ein Spiel mit einem Spielautomaten verwenden Sie einen Token. Im Falle eines Gewinns gibt Ihnen die Maschine einen Dollar, im Falle eines Verlustes - nichts. Jede Maschine hat eine feste Gewinnwahrscheinlichkeit (die Sie nicht kennen), die jedoch für verschiedene Maschinen unterschiedlich ist. Nachdem Sie die Website des Herstellers dieser Maschinen studiert haben, haben Sie festgestellt, dass die Gewinnwahrscheinlichkeit für jede Maschine in der Herstellungsphase zufällig aus der
Beta-Verteilung mit bestimmten Parametern ausgewählt wird.
Sie möchten Ihre erwarteten Gewinne maximieren.
E / A-Formate und BeispielEingabeformat
Eine Ausführung kann aus mehreren Tests bestehen.
Jeder Test beginnt mit der Tatsache, dass Ihr Programm in der Zeile zwei durch ein Leerzeichen getrennte Ganzzahlen enthält: Die Anzahl N ist die Anzahl der Token in Ihrer Tasche und M ist die Anzahl der Maschinen in der Halle (N ≤ 10
4 , M ≤ min (N, 100)). ) Die nächste Zeile enthält zwei reelle Zahlen α und β (1 ≤ α, β ≤ 10) - die Parameter der Beta-Verteilung der Gewinnwahrscheinlichkeit.
Das Kommunikationsprotokoll mit dem Prüfsystem lautet wie folgt: Sie stellen genau N Anforderungen. Drucken Sie für jede Anforderung in einer separaten Zeile die Nummer der Maschine aus, die Sie spielen möchten (von 1 bis einschließlich M). Als Antwort wird in einer separaten Zeile entweder "0" oder "1" angezeigt, was jeweils einen Verlust und einen Gewinn in einem Spiel mit dem angeforderten Spielautomaten bedeutet.
Nach dem letzten Test gibt es anstelle der Zahlen N und M zwei Nullen.
Ausgabeformat
Die Aufgabe gilt als erledigt, wenn Ihre Entscheidung nicht viel schlimmer ist als die Entscheidung der Jury. Wenn Ihre Entscheidung erheblich schlechter ist als die Entscheidung der Jury, erhalten Sie das Urteil „falsche Antwort“.
Es ist garantiert, dass die Wahrscheinlichkeit, das Urteil „falsche Antwort“ zu erhalten,
10-6 nicht überschreitet, wenn Ihre Entscheidung nicht schlechter ist als die Entscheidung der Jury.
Anmerkungen
Interaktionsbeispiel:
____________________ stdin stdout ____________________ ____________________ 5 2 2 2 2 1 1 0 1 1 2 1 2 1
Lösung
Dieses Problem ist bekannt und kann auf verschiedene Arten gelöst werden. Die Hauptentscheidung der Jury setzte die
Thompson-Stichprobenstrategie um. Da jedoch die Anzahl der Schritte zu Beginn des Programms bekannt war, gibt es optimalere Strategien (z. B. UCB1). Darüber hinaus könnte man sogar mit der Epsilon-Greedy-Strategie auskommen: Mit einer bestimmten Wahrscheinlichkeit ε eine zufällige Maschine spielen und mit einer Wahrscheinlichkeit (1 - ε) eine Maschine mit der besten Siegesstatistik spielen.
class SolverFromStdIn(object): def __init__(self): self.regrets = [0.] self.total_win = [0.] self.moves = [] class ThompsonSampling(SolverFromStdIn): def __init__(self, bandits_total, init_a=1, init_b=1): """ init_a (int): initial value of a in Beta(a, b). init_b (int): initial value of b in Beta(a, b). """ SolverFromStdIn.__init__(self) self.n = bandits_total self.alpha = init_a self.beta = init_b self._as = [init_a] * self.n
C. Ausrichtung der Sätze
Zustand
Eine der wichtigsten Aufgaben für das Training eines guten maschinellen Übersetzungsmodells ist ein guter Fall von parallelen Sätzen. In der Regel sind parallele Angebote die Quelle für parallele Angebote. Es stellt sich heraus, dass Sie häufig nur ihre Länge kennen müssen, um ein bestimmtes Korpus paralleler Sätze zu bilden. Insbesondere stellen Sie möglicherweise fest, dass der Satz in der Ausgangssprache umso länger übersetzt wird, je länger er ist. Einige Schwierigkeiten liegen in der Tatsache, dass sich während der Übersetzung die Anzahl der Sätze im Text ändern kann: Manchmal können zwei benachbarte Sätze in der Übersetzung zu einem kombiniert werden oder umgekehrt - ein Satz kann in zwei Sätze geteilt werden. In einigen seltenen Fällen können Sätze in einer Übersetzung vollständig weggelassen werden, oder eine Übersetzung kann in einer Übersetzung erscheinen, die nicht im Original enthalten war.
Nehmen wir formeller an, dass das folgende generative Modell für parallele Gehäuse wahr ist. Bei jedem Schritt führen wir einen der folgenden Schritte aus:
1. Stoppen SieMit der Wahrscheinlichkeit p
h endet
die Erzeugung der Rümpfe.
2. [1-0] Angebote überspringenMit der Wahrscheinlichkeit p
d schreiben
wir dem Originaltext einen Satz zu. Wir schreiben der Übersetzung nichts zu. Die Länge des Satzes in der Originalsprache L ≥ 1 wird aus der diskreten Verteilung ausgewählt:
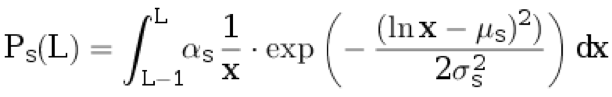
.
Hier sind
μs ,
σs die Verteilungsparameter und
αs der so gewählte Normalisierungskoeffizient

.
3. [0-1] Vorschlag einfügenMit der Wahrscheinlichkeit p
i weisen
wir der Übersetzung einen Satz zu. Wir schreiben dem Original nichts zu. Die Länge eines Satzes in einer Übersetzungssprache L ≥ 1 wird aus einer diskreten Verteilung ausgewählt:

.
Hier sind
μ t ,
σ t die Verteilungsparameter und
α t der so gewählte Normalisierungskoeffizient

.
4. ÜbersetzungMit der Wahrscheinlichkeit (1 - p
d - p
i - p
h ) nehmen wir die Länge des Satzes in der Originalsprache L
s ≥ 1 aus der Verteilung p
s (mit Aufrundung). Als nächstes erzeugen wir die Länge des Satzes in der Übersetzungssprache L
t ≥ 1 aus der bedingten diskreten Verteilung:
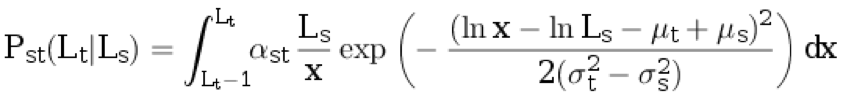
.
Hier ist
α st der Normalisierungskoeffizient, und die verbleibenden Parameter sind in den vorhergehenden Absätzen beschrieben.
Weiter ist ein weiterer Schritt:
1. [2-1] Mit der Wahrscheinlichkeit p
split s teilt sich
der erzeugte Satz in der Originalsprache in zwei nicht leere auf, so dass sich die Gesamtzahl der Wörter
um genau eins erhöht . Die Wahrscheinlichkeit, dass ein Satz der Länge L
s in Teile der Länge L
1 und L
2 zerfällt (dh L
1 + L
2 = L
s + 1), ist proportional zu P
s (L
1 ) ⋅ P
s (L
2 ).
2. [1-2] Mit der Wahrscheinlichkeit p
split t teilt sich
der erzeugte Satz in der Zielsprache in zwei nicht leere Sätze auf, so dass sich die Gesamtzahl der Wörter um genau eins erhöht. Die Wahrscheinlichkeit, dass ein Satz der Länge L
t in Teile der Länge L1 und L2 zerfällt (dh L
1 + L
2 = L
t + 1), ist proportional zu P
t (L
1 ) ⋅ P
t (L
2 ).
3. 3. [1-1] Mit einer Wahrscheinlichkeit von (1 - p
split s - p
split t ) zerfällt keiner der generierten Sätze.
E / A-Formate, Beispiele und HinweiseEingabeformat
Die erste Zeile der Datei enthält die Verteilungsparameter: p
h , p
d , p
i , p
split s , p
split t , μ
s , σ
s , μ
t , σ
t . 0,1 ≤ σ
s <σ
t ≤ 3. 0 ≤ μ
s , μ
t ≤ 5.
Die nächste Zeile enthält die Zahlen N
s und N
t - die Anzahl der Sätze im Fall in der Originalsprache bzw. in der Zielsprache (1 ≤ N
s , N
t ≤ 1000).
Die nächste Zeile enthält N
s Ganzzahlen - die Länge der Sätze in der Originalsprache. Die nächste Zeile enthält N
t Ganzzahlen - die Länge der Sätze in der Zielsprache.
Die nächste Zeile enthält zwei Zahlen: j und k (1 ≤ j ≤ N
s , 1 ≤ k ≤ N
t ).
Ausgabeformat
Es ist erforderlich, die Wahrscheinlichkeit abzuleiten, dass Sätze mit den Indizes j bzw. k in den Texten parallel sind (dh, dass sie in einem Schritt des Algorithmus erzeugt werden und keiner von ihnen das Ergebnis des Zerfalls ist).
Ihre Antwort wird akzeptiert, wenn der absolute Fehler 10
–4 nicht überschreitet.
Beispiel 1
Beispiel 2
Beispiel 3
Anmerkungen
Im ersten Beispiel kann die anfängliche Folge von Zahlen auf drei Arten erhalten werden:
• Fügen Sie zuerst mit der Wahrscheinlichkeit p
d einen Satz zum Originaltext hinzu, dann mit der Wahrscheinlichkeit p
i einen Satz zur Übersetzung und beenden Sie dann mit der Wahrscheinlichkeit p
h die Generierung.
Die Wahrscheinlichkeit dieses Ereignisses ist P
1 = p
d * P
s (4) * p
i * P
t (20) * p
h .
• Fügen Sie zuerst mit der Wahrscheinlichkeit p
d einen Satz zum Originaltext hinzu, dann mit der Wahrscheinlichkeit p
i einen Satz zur Übersetzung und beenden Sie dann mit der Wahrscheinlichkeit p
h die Generierung.
Die Wahrscheinlichkeit dieses Ereignisses ist gleich P
2 = p
i * P
t (20) * p
d * P
s (4) * p
h .
• Mit der Wahrscheinlichkeit (1 - p
h - p
d - p
i ) zwei Sätze erzeugen, dann mit der Wahrscheinlichkeit (1 - p
split s - p
split t ) alles so lassen, wie es ist (dh das Original oder die Übersetzung nicht in zwei Sätze teilen ) und beenden Sie danach mit der Wahrscheinlichkeit p
h die Erzeugung.
Die Wahrscheinlichkeit dieses Ereignisses ist

.
Als Ergebnis wird die Antwort berechnet als

.
Lösung
Die Aufgabe ist ein Sonderfall der Ausrichtung mit Hidden-Markov-Modellen (HMM-Ausrichtung). Die Hauptidee ist, dass Sie die Wahrscheinlichkeit berechnen können, mit diesem Modell und
dem Vorwärtsalgorithmus ein bestimmtes Dokumentpaar zu generieren: In diesem Fall ist der Status ein Paar von Dokumentpräfixen. Dementsprechend kann die erforderliche Wahrscheinlichkeit der Ausrichtung eines bestimmten Paares paralleler Sätze durch den
Vorwärts-Rückwärts- Algorithmus berechnet werden.
Code #include <iostream> #include <iomanip> #include <cmath> #include <vector> double p_h, p_d, p_i, p_tr, p_ss, p_st, mu_s, sigma_s, mu_t, sigma_t; double lognorm_cdf(double x, double mu, double sigma) { if (x < 1e-9) return 0.0; double res = std::log(x) - mu; res /= std::sqrt(2.0) * sigma; res = 0.5 * (1 + std::erf(res)); return res; } double length_probability(int l, double mu, double sigma) { return lognorm_cdf(l, mu, sigma) - lognorm_cdf(l - 1, mu, sigma); } double translation_probability(int ls, int lt) { double res = length_probability(ls, mu_s, sigma_s); double mu = mu_t - mu_s + std::log(ls); double sigma = std::sqrt(sigma_t * sigma_t - sigma_s * sigma_s); res *= length_probability(lt, mu, sigma); return res; } double split_probability(int l1, int l2, double mu, double sigma) { int l_sum = l1 + l2; double total_prob = 0.0; for (int i = 1; i < l_sum; ++i) { total_prob += length_probability(i, mu, sigma) * length_probability(l_sum - i, mu, sigma); } return length_probability(l1, mu, sigma) * length_probability(l2, mu, sigma) / total_prob; } double log_prob10(int ls) { return std::log(p_d * length_probability(ls, mu_s, sigma_s)); } double log_prob01(int lt) { return std::log(p_i * length_probability(lt, mu_t, sigma_t)); } double log_prob11(int ls, int lt) { return std::log(p_tr * (1 - p_ss - p_st) * translation_probability(ls, lt)); } double log_prob21(int ls1, int ls2, int lt) { return std::log(p_tr * p_ss * split_probability(ls1, ls2, mu_s, sigma_s) * translation_probability(ls1 + ls2 - 1, lt)); } double log_prob12(int ls, int lt1, int lt2) { return std::log(p_tr * p_st * split_probability(lt1, lt2, mu_t, sigma_t) * translation_probability(ls, lt1 + lt2 - 1)); } double logsum(double v1, double v2) { double res = std::max(v1, v2); v1 -= res; v2 -= res; v1 = std::min(v1, v2); if (v1 < -30) { return res; } return res + std::log(std::exp(v1) + 1.0); } double loginc(double* to, double from) { *to = logsum(*to, from); } constexpr double INF = 1e25; int main(void) { using std::cin; using std::cout; cin >> p_h >> p_d >> p_i >> p_ss >> p_st >> mu_s >> sigma_s >> mu_t >> sigma_t; p_tr = 1.0 - p_h - p_d - p_i; int Ns, Nt; cin >> Ns >> Nt; using std::vector; vector<int> ls(Ns), lt(Nt); for (int i = 0; i < Ns; ++i) cin >> ls[i]; for (int i = 0; i < Nt; ++i) cin >> lt[i]; vector< vector< double> > fwd(Ns + 1, vector<double>(Nt + 1, -INF)), bwd = fwd; fwd[0][0] = 0; bwd[Ns][Nt] = 0; for (int i = 0; i <= Ns; ++i) { for (int j = 0; j <= Nt; ++j) { if (i >= 1) { loginc(&fwd[i][j], fwd[i - 1][j] + log_prob10(ls[i - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j] + log_prob10(ls[Ns - i])); } if (j >= 1) { loginc(&fwd[i][j], fwd[i][j - 1] + log_prob01(lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i][Nt - j + 1] + log_prob01(lt[Nt - j])); } if (i >= 1 && j >= 1) { loginc(&fwd[i][j], fwd[i - 1][j - 1] + log_prob11(ls[i - 1], lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j + 1] + log_prob11(ls[Ns - i], lt[Nt - j])); } if (i >= 2 && j >= 1) { loginc(&fwd[i][j], fwd[i - 2][j - 1] + log_prob21(ls[i - 1], ls[i - 2], lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 2][Nt - j + 1] + log_prob21(ls[Ns - i], ls[Ns - i + 1], lt[Nt - j])); } if (i >= 1 && j >= 2) { loginc(&fwd[i][j], fwd[i - 1][j - 2] + log_prob12(ls[i - 1], lt[j - 1], lt[j - 2])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j + 2] + log_prob12(ls[Ns - i], lt[Nt - j], lt[Nt - j + 1])); } } } int j, k; cin >> j >> k; double rlog = fwd[j - 1][k - 1] + bwd[j][k] + log_prob11(ls[j - 1], lt[k - 1]) - bwd[0][0]; cout << std::fixed << std::setprecision(12) << std::exp(rlog) << std::endl; }
D. Band mit Empfehlungen
Zustand
Betrachten Sie einen Feed mit Empfehlungen für heterogene Inhalte. Es mischt Objekte verschiedener Typen (Bilder, Videos, Nachrichten usw.). Diese Objekte sind normalerweise nach Relevanz für den Benutzer geordnet: Je relevanter (interessanter) das Objekt für den Benutzer ist, desto näher am Anfang der Empfehlungsliste. Bei einer solchen Reihenfolge treten jedoch häufig Situationen auf, in denen mehrere Objekte desselben Typs in der Liste der Empfehlungen aufgeführt sind. Dies verschlechtert die externe Vielfalt unserer Empfehlungen erheblich und daher gefällt es den Benutzern nicht. Es ist erforderlich, einen Algorithmus zu implementieren, der gemäß der Liste der Empfehlungen eine neue Liste erstellt, die frei von diesem Problem ist und am relevantesten ist.
Eine erste Liste von Empfehlungen sei a = [a
0 , a
1 , ..., a
n - 1 ] mit der Länge n> 0. Ein Objekt mit der Nummer i hat den Typ mit der Nummer b
i ∈ {0, ..., m - 1}. Zusätzlich hat ein Objekt unter der Nummer i die Relevanz r (a
i ) = 2
−i . Betrachten Sie die Liste, die aus der ersten Liste erhalten wird, indem Sie eine Teilmenge von Objekten auswählen und neu anordnen: x = [a
i 0 , a
i 1 , ..., a
i k - 1 ] mit der Länge k (0 ≤ k ≤ n). Eine Liste wird als zulässig bezeichnet, wenn keine zwei aufeinanderfolgenden Objekte in ihrem Typ übereinstimmen, d. H. B
i j ≠ b
i j + 1 für alle j = 0, ..., k - 2. Die Relevanz der Liste wird durch die Formel berechnet
. Sie müssen die Liste der maximalen Relevanz unter allen gültigen finden.
E / A-Formate und BeispieleEingabeformat
In der ersten Zeile werden die Zahlen n und m mit einem Leerzeichen geschrieben (1 ≤ n ≤ 100000, 1 ≤ m ≤ n). Die nächsten n Zeilen enthalten die Zahlen b
i für i = 0, ..., n - 1 (0 ≤ b
i ≤ m - 1).
Ausgabeformat
Notieren Sie mit einem Leerzeichen die Anzahl der Objekte in der endgültigen Liste: i
0 , i
1 , ..., i
k - 1 .
Beispiel 1
Beispiel 2
Beispiel 3
Lösung
Mit einfachen mathematischen Berechnungen kann gezeigt werden, dass das Problem durch einen „gierigen“ Ansatz gelöst werden kann, dh in der optimalen Liste von Empfehlungen hat jeder Punkt das relevanteste Objekt von allen, die am selben Anfang der Liste gültig sind. Die Implementierung dieses Ansatzes ist einfach: Wir nehmen Objekte in einer Reihe und fügen sie, wenn möglich, der Antwort hinzu. Wenn ein ungültiges Objekt gefunden wird (dessen Typ mit dem Typ des vorherigen übereinstimmt), legen wir es in einer separaten Warteschlange beiseite, aus der wir es so schnell wie möglich in die Antwort einfügen. Beachten Sie, dass zu jedem Zeitpunkt alle Objekte in dieser Warteschlange einen übereinstimmenden Typ haben. Am Ende verbleiben möglicherweise mehrere Objekte in der Warteschlange. Sie werden nicht in die Antwort aufgenommen.
std::vector<int> blend(int n, int m, const std::vector<int>& types) { std::vector<int> result; std::queue<int> repeated; for (int i = 0; i < n; ++i) { if (result.empty() || types[result.back()] != types[i]) { result.push_back(i); if (!repeated.empty() && types[repeated.front()] != types[result.back()]) { result.push_back(repeated.front()); repeated.pop(); } } else { repeated.push(i); } } return result; }
D. Clusterisierung von Zeichenfolgen
Es gibt ein endliches Alphabet A = {a
1 , a
2 , ..., a
K - 1 , a
K = S}, a
i ∈ {a, b, ..., z}, S ist das Ende der Zeile.
Betrachten Sie die folgende Methode zum Generieren von zufälligen Zeichenfolgen über dem Alphabet A:
1. Das erste Zeichen x
1 ist eine Zufallsvariable mit der Verteilung P (x
1 = a
i ) = q
i (es ist bekannt, dass q
K = 0 ist).
2. Jedes nächste Zeichen wird basierend auf dem vorherigen gemäß der bedingten Verteilung P (x
i = a
j || x
i - 1 = a
l ) = p
jl erzeugt .
3. Wenn x
i = S ist, stoppt die Erzeugung und das Ergebnis ist x
1 x
2 ... x
i - 1 .
Der Satz von Linien, die aus einer Mischung von zwei beschriebenen Modellen mit unterschiedlichen Parametern erzeugt werden, ist angegeben. Für jede Zeile muss der Index der Kette angegeben werden, aus der sie generiert wurde.
E / A-Formate, Beispiel und NotizenEingabeformat
Die erste Zeile enthält zwei Zahlen 1000 ≤ N ≤ 2000 und 3 ≤ K ≤ 27 - die Anzahl der Zeilen bzw. die Größe des Alphabets.
Die zweite Zeile enthält eine Zeile, die aus K - 1 verschiedenen Kleinbuchstaben des lateinischen Alphabets besteht und die ersten K - 1 Elemente des Alphabets angibt.
Jede der folgenden N Zeilen wird gemäß dem in der Bedingung beschriebenen Algorithmus erzeugt.
Ausgabeformat
In n Zeilen enthält die i-te Zeile die Clusternummer (0/1) für die Sequenz in der i + 1-ten Zeile der Eingabedatei. Die Übereinstimmung mit der wahren Antwort sollte mindestens 80% betragen.
Beispiel
Anmerkungen
Hinweis zum Test aus der Bedingung: Darin werden die ersten 50 Zeilen aus der Verteilung generiert
P (x
i = a | x
i - 1 = a) = 0,5, P (x
i = S | x
i - 1 = a) = 0,5, P (x
1 = a) = 1; zweite 50 - aus der Verteilung
P (x
i = b | x
i - 1 = b) = 0,5, P (x
i = S | x
i - 1 = b) = 0,5, P (x
1 = b) = 1.
Lösung
Das Problem wird mithilfe des
EM-Algorithmus gelöst: Es wird angenommen, dass die dargestellte Probe aus einer Mischung von zwei Markov-Ketten generiert wird, deren Parameter während der Iterationen wiederhergestellt werden. Eine Einschränkung von 80% der richtigen Antworten wird vorgenommen, damit die Richtigkeit der Lösung nicht durch Beispiele beeinträchtigt wird, die in beiden Ketten eine hohe Wahrscheinlichkeit haben. Diese Beispiele können daher bei ordnungsgemäßer Wiederherstellung einer Kette zugewiesen werden, die hinsichtlich der generierten Antwort falsch ist.
import random import math EPS = 1e-9 def empty_row(size): return [0] * size def empty_matrix(rows, cols): return [empty_row(cols) for _ in range(rows)] def normalized_row(row): row_sum = sum(row) + EPS return [x / row_sum for x in row] def normalized_matrix(mtx): return [normalized_row(r) for r in mtx] def restore_params(alphabet, string_samples): n_tokens = len(alphabet) n_samples = len(string_samples) samples = [tuple([alphabet.index(token) for token in s] + [n_tokens - 1, n_tokens - 1]) for s in string_samples] probs = [random.random() for _ in range(n_samples)] for _ in range(200): old_probs = [x for x in probs]
.