Wie Sie wissen, spielen Indizes im DBMS eine wichtige Rolle und ermöglichen eine schnelle Suche nach den erforderlichen Datensätzen. Daher ist es so wichtig, sie rechtzeitig zu warten. Es wurde viel Material über Analyse und Optimierung geschrieben, auch im Internet. Beispielsweise wurde in
dieser Veröffentlichung eine aktuelle Überprüfung dieses Themas vorgenommen.
Hierfür gibt es viele kostenpflichtige und kostenlose Lösungen. Beispielsweise gibt es eine schlüsselfertige
Lösung, die auf einer adaptiven Indexoptimierungsmethode basiert.
Betrachten Sie als Nächstes das kostenlose Dienstprogramm
SQLIndexManager , das von
AlanDenton erstellt wurde .
Der wichtigste technische Unterschied zwischen SQLIndexManager und einer Reihe anderer Analoga wird
hier und
hier vom Autor selbst gemacht.
Im selben Artikel werfen wir einen Blick auf das Projekt und die Möglichkeiten der Verwendung dieser Softwarelösung.
Besprechen Sie dieses Dienstprogramm
hier .
Im Laufe der Zeit wurden die meisten Kommentare und Fehler behoben.
Kommen wir nun zum Dienstprogramm SQLIndexManager.
Die Anwendung ist in C # .NET Framework 4.5 in Visual Studio 2017 geschrieben und verwendet DevExpress für Formulare:
und sieht so aus:
Alle Anfragen werden in folgenden Dateien generiert:
- Index
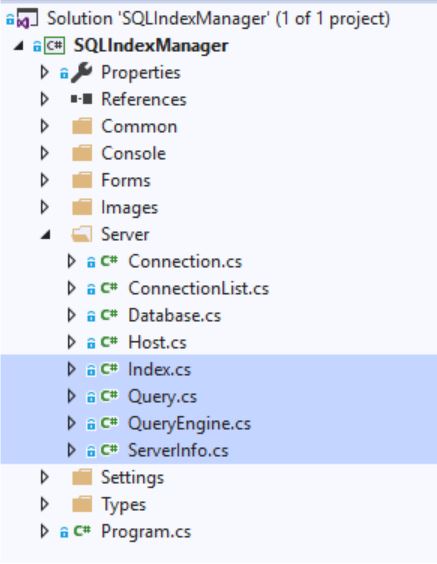
- Abfrage
- Queryengine
- ServerInfo
Wenn Sie eine Verbindung zur Datenbank herstellen und Anforderungen an das DBMS senden, wird die Anwendung wie folgt signiert:
ApplicationName=”SQLIndexManager”
Wenn die Anwendung gestartet wird, wird ein modales Fenster geöffnet, in dem Sie eine Verbindung hinzufügen können:
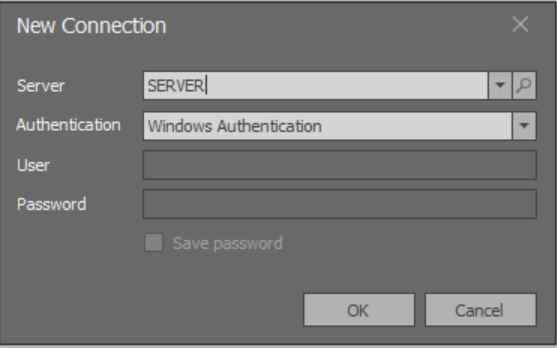
Hier funktioniert das Laden der vollständigen Liste aller über lokale Netzwerke verfügbaren Instanzen von MS SQL Server noch nicht.
Sie können eine Verbindung auch über die Schaltfläche ganz links im Hauptmenü hinzufügen:
Als Nächstes werden die folgenden DBMS-Abfragen gestartet:
Abrufen von DBMS-Informationen SELECT ProductLevel = SERVERPROPERTY('ProductLevel') , Edition = SERVERPROPERTY('Edition') , ServerVersion = SERVERPROPERTY('ProductVersion') , IsSysAdmin = CAST(IS_SRVROLEMEMBER('sysadmin') AS BIT)
Abrufen einer Liste der verfügbaren Datenbanken mit ihren kurzen Eigenschaften SELECT DatabaseName = t.[name] , d.DataSize , DataUsedSize = CAST(NULL AS BIGINT) , d.LogSize , LogUsedSize = CAST(NULL AS BIGINT) , RecoveryModel = t.recovery_model_desc , LogReuseWait = t.log_reuse_wait_desc FROM sys.databases t WITH(NOLOCK) LEFT JOIN ( SELECT [database_id] , DataSize = SUM(CASE WHEN [type] = 0 THEN CAST(size AS BIGINT) END) , LogSize = SUM(CASE WHEN [type] = 1 THEN CAST(size AS BIGINT) END) FROM sys.master_files WITH(NOLOCK) GROUP BY [database_id] ) d ON d.[database_id] = t.[database_id] WHERE t.[state] = 0 AND t.[database_id] != 2 AND ISNULL(HAS_DBACCESS(t.[name]), 1) = 1
Nach dem Ausführen der obigen Skripts wird ein Fenster mit kurzen Informationen zu den Datenbanken der ausgewählten Instanz von MS SQL Server angezeigt:
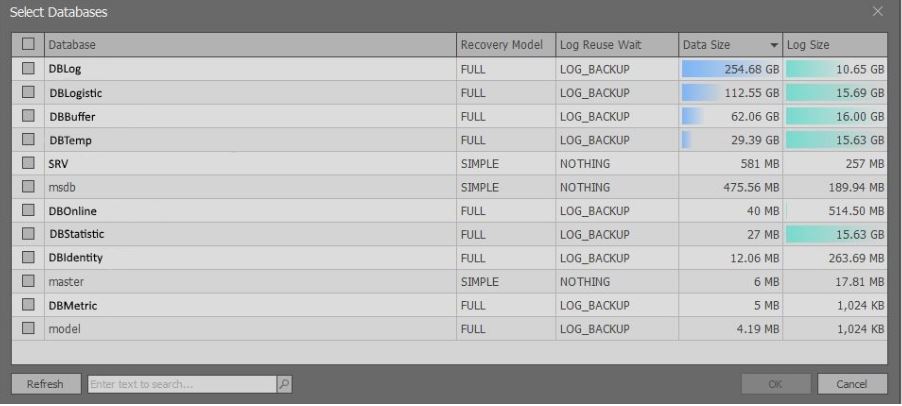
Es ist erwähnenswert, dass erweiterte Informationen basierend auf Rechten angezeigt werden. Wenn
sysadmin vorhanden ist, können Sie Daten aus der
Ansicht sys.master_files auswählen. Wenn es keine solchen Rechte gibt, werden weniger Daten zurückgegeben, um die Anforderung nicht zu verlangsamen.
Hier müssen Sie die gewünschte Datenbank auswählen und auf die Schaltfläche „OK“ klicken.
Als Nächstes wird für jede ausgewählte Datenbank das folgende Skript ausgeführt, um den Status von Indizes zu analysieren:
Indexstatusanalyse declare @Fragmentation float=15; declare @MinIndexSize bigint=768; declare @MaxIndexSize bigint=1048576; declare @PreDescribeSize bigint=32768; SET NOCOUNT ON SET ARITHABORT ON SET NUMERIC_ROUNDABORT OFF IF OBJECT_ID('tempdb.dbo.#AllocationUnits') IS NOT NULL DROP TABLE
Wie Sie den Abfragen selbst entnehmen können, werden häufig temporäre Tabellen verwendet. Dies geschieht so, dass keine Neukompilierung erfolgt. Bei einem großen Schema kann der Plan beim Einfügen von Daten parallel generiert werden, da das Einfügen mit Tabellenvariablen nur in einem Stream möglich ist.
Nach dem Ausführen des obigen Skripts wird ein Fenster mit der Indextabelle angezeigt:

Hier können Sie auch andere detaillierte Informationen anzeigen, z.
- Datenbank
- Anzahl der Abschnitte
- Datum und Uhrzeit des letzten Anrufs
- Komprimierung
- Dateigruppe
usw.
Die Spalten selbst können angepasst werden:
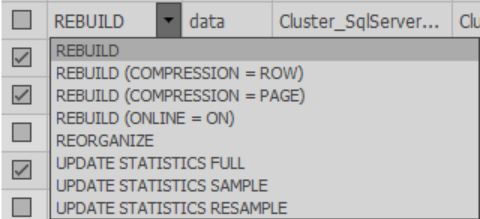
In den Zellen der Spalte Fix können Sie auswählen, welche Aktion während der Optimierung ausgeführt werden soll. Wenn der Scanvorgang abgeschlossen ist, wird die Standardaktion basierend auf den ausgewählten Einstellungen ausgewählt:
Sie müssen die gewünschten Indizes für die Verarbeitung auswählen.
Über das Hauptmenü können Sie das Skript speichern (dieselbe Schaltfläche startet den Indexoptimierungsprozess selbst):
Speichern Sie die Tabelle in verschiedenen Formaten (mit derselben Schaltfläche können Sie detaillierte Einstellungen für die Analyse und Optimierung von Indizes öffnen):

Informationen können auch aktualisiert werden, indem Sie auf die dritte Schaltfläche links im Hauptmenü neben der Lupe klicken.
Über eine Schaltfläche mit einer Lupe können Sie die gewünschte Datenbank zur Berücksichtigung auswählen.
Derzeit gibt es kein vollständiges Hilfesystem. Drücken Sie daher das "?" Es wird einfach ein modales Fenster angezeigt, das grundlegende Informationen zum Softwareprodukt enthält:
Zusätzlich zu all dem hat das Hauptmenü eine Suchleiste:

Beim Starten des Indexoptimierungsprozesses:

Außerdem sehen Sie unten im Fenster das Protokoll der durchgeführten Aktionen:
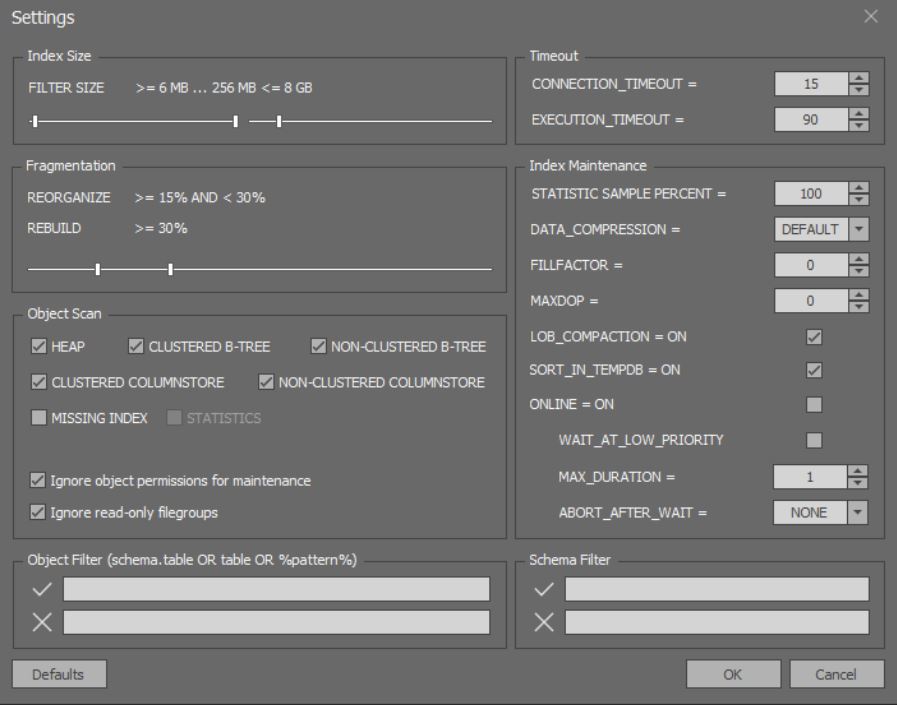
Im Fenster zur detaillierten Analyse und Optimierung von Indizes können Sie subtilere Optionen konfigurieren:
 Vorschläge für die Anwendung:
Vorschläge für die Anwendung:- ermöglichen es, Statistiken nicht nur für Indizes, sondern auch auf unterschiedliche Weise (vollständig oder teilweise zu aktualisieren) selektiv zu aktualisieren
- Ermöglichen Sie nicht nur die Auswahl der Datenbank, sondern auch verschiedener Server (dies ist sehr praktisch, wenn viele Instanzen von MS SQL Server vorhanden sind).
- Für eine größere Flexibilität bei der Verwendung wird vorgeschlagen, Befehle in Bibliotheken zu verpacken und in PowerShell-Befehle auszugeben, wie dies beispielsweise hier getan wird: dbatools.io/commands
- Ermöglichen das Speichern und Ändern persönlicher Einstellungen sowohl für die gesamte Anwendung als auch bei Bedarf für jede Instanz von MS SQL Server und jede Datenbank
- Aus den Abschnitten 2 und 4 folgt der Wunsch, Gruppen in Datenbanken und Gruppen in Instanzen von MS SQL Server zu erstellen, für die die Einstellungen identisch sind
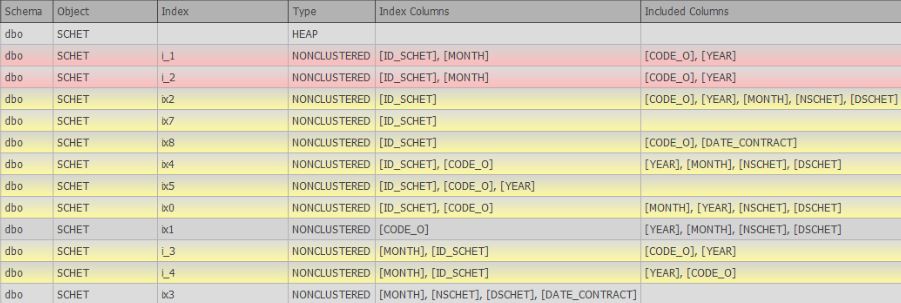
- Suche nach doppelten Indizes (vollständig und unvollständig, die sich entweder geringfügig oder nur in den enthaltenen Spalten unterscheiden)
- Da SQLIndexManager nur für MS SQL Server DBMS verwendet wird, müssen Sie dies im Namen wie folgt widerspiegeln: SQLIndexManager für MS SQL Server
- Entfernen Sie alle Teile der Anwendung von der GUI in separate Module und schreiben Sie sie in .NET Core 2.1
Zum Zeitpunkt des Schreibens wird Artikel 6 der Wünsche aktiv weiterentwickelt und es gibt bereits Unterstützung in Form einer Suche nach vollständigen und ähnlichen Duplikaten:
Quellen