Der Artikel enthält Code zum Generieren regelmäßiger Berichte zum Status von EMC VNX- Speicherlaufwerken mit alternativen Ansätzen und Erstellungsverlauf.
Ich habe versucht, Code mit den detailliertesten Kommentaren und einer Datei zu schreiben. Ersetzen Sie nur Ihre Passwörter. Das Format der Quelldaten wird ebenfalls angegeben, daher bin ich froh, wenn jemand versucht, sie zu Hause anzuwenden.
Hintergrund
Sie können überspringen, wenn es nicht interessant ist, woher die "Beine" wachsen.
Wir haben ein Rechenzentrum. Es gibt keine sehr frischen Speichersysteme. Es gibt viele Speichersysteme, auch Festplattenfehler. Mehrmals pro Woche gehen Leute zum Rechenzentrum und wechseln die Laufwerke im Speichersystem. Die Entscheidung zum Ersetzen von Festplatten wird nach einem Alarm vom System " Empfohlener Festplattenwechsel " getroffen.
Nichts Außergewöhnliches.

Vor kurzem begannen sich einzelne LUNs, die auf diesen Speichersystemen gesammelt und der virtuellen Umgebung präsentiert wurden, ernsthaft zu verschlechtern. Nach einem Gespräch mit dem technischen Support des Anbieters wurde klar, dass die Festplatten nicht nur gewechselt werden sollten, wenn die obige Alarmmeldung angezeigt wird, sondern auch, wenn eine große Anzahl anderer Meldungen angezeigt wird, dass das System keine kritischen Fehler berücksichtigt.
Die SNMP-Überwachung durch diese Speichersysteme wird nicht unterstützt. Sie müssen entweder teure proprietäre Software (wir haben sie nicht) oder das NaviSECCli- Konsolendienstprogramm verwenden, das mit jedem Controller (es gibt zwei davon) jedes Speichersystems verbunden werden muss. Dies war jedoch nicht sehr wünschenswert.
Es wurde beschlossen, die Erfassung von Protokollen zu automatisieren und nach Fehlern zu suchen. Die Entscheidung, die Festplatten auszutauschen, sollte den verantwortlichen Ingenieuren auf der Grundlage der Ergebnisse der Analyse des Berichts überlassen werden.
Erste Schritte
Zunächst schrieb einer meiner Kollegen PowerShell- Code, der Folgendes tat:
- Nahm eine Eingabetabelle, die die IP-Adressen der Speichercontroller enthielt;
- Der Zyklus ging zu den IP-Adressen der Controller A und dann zu den IP-Adressen der Controller B.
- Dabei wurden sie zusätzlich nach Seriennummern der Festplatten befragt.
- verarbeitete alle Zeilen der Protokolle und filterte nach dem Inhalt der gesuchten Nachrichten;
- ein PowerShell- Objekt erstellt und in seinen Eigenschaften die erforderlichen Daten aus den oben erhaltenen Zeilen analysiert;
- Alle resultierenden Objekte wurden in einer Tabelle zusammengeführt, die in Form von CSV ausgegeben wurde.
Der Code ist unten. Machen Sie sofort eine Reservierung, dass er arbeitet, aber wir haben eine alternative Lösung eingeführt.
PowerShell-Quellecd 'd:\Navisphere CLI\' $csv = "D:\VNX-IP.csv" $Filter1 = "name1" $Filter2 = "name2" $Filter3 = "name3" $Data = import-csv $csv -Delimiter ';' | Where {$_.cl -EQ $Filter1 -Or $_.cl -EQ $Filter2 -Or $_.cl -EQ $Filter3} | Sort-Object -Property @{Expression={$_.cl}; Ascending=$true}, @{Expression={$_.Name} ;Ascending=$true} #$Filter1 = "nameOfcl" #$Data = import-csv $csv -Delimiter ';' | Where {$_.Name -EQ $Filter1} $Data | select Name,IP,cl $yStart = (Get-Date).AddDays(-30).ToString('yyyy') $yEnd = (Get-Date).ToString('yyyy') $mStart = (Get-Date).AddDays(-30).ToString('MM') $mEnd = (Get-Date).ToString('MM') $dStart = (Get-Date).AddDays(-30).ToString('dd') $dEnd = (Get-Date).ToString('dd') #$start = (Get-Date).AddDays(-3).ToString('MM\/dd\/yy') #$end = (Get-Date).ToString('MM\/dd\/yy') $i = 1 $table = ForEach ($row in $Data) { Write-Host $row.Name -ForegroundColor "Yellow" Write-Host "SP A" Write-Host (Get-Date).ToString('HH:mm:ss') $txt = .\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getlog -date $mStart/$dStart/$yStart $mEnd/$dEnd/$yEnd | Select-String -Pattern "\(820\)","\(803\)","\(801\)","\(920\)","\(901\)" ForEach ($n in $txt) { $x = $n -Split(' ') $disk = $x[3] + "_" + $x[5] + "_" + $x[7].Split("(")[0] $sn = (.\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getdisk $disk -serial)[1] | %{$_ -replace "Serial Number: ",""} | %{$_ -replace "State: ",""} | %{$_ -replace " ",""} New-Object PSObject -Property @{ i = $i cl = $row.cl Storage = $row.Name SP = "A" Date = $x[0] Time = $x[1] Disk = $disk Error = (($n -Split('\['))[0] -Split('\)'))[1].Trim() eCode = (($n -Split('\('))[1] -Split('\)'))[0] SN = $sn } $i = $i + 1 } Write-Host "SP B" Write-Host (Get-Date).ToString('HH:mm:ss') $txt = .\NaviSECCli.exe -scope 0 -h $row.newB -user myusername -password mypassword getlog -date $mStart/$dStart/$yStart $mEnd/$dEnd/$yEnd | Select-String -Pattern "\(820\)","\(803\)","\(801\)","\(920\)","\(901\)" ForEach ($n in $txt) { $x = $n -Split(' ') $disk = $x[3] + "_" + $x[5] + "_" + $x[7].Split("(")[0] $sn = (.\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getdisk $disk -serial)[1] | %{$_ -replace "Serial Number: ",""} | %{$_ -replace "State: ",""} | %{$_ -replace " ",""} New-Object PSObject -Property @{ i = $i cl = $row.cl Storage = $row.Name SP = "B" Date = $x[0] Time = $x[1] Disk = $disk Error = (($n -Split('\['))[0] -Split('\)'))[1].Trim() eCode = (($n -Split('\('))[1] -Split('\)'))[0] SN = $sn } $i = $i + 1 } Write-Host " " } $table | select i,cl,Storage,SP,Date,Time,Disk,Error,eCode,SN | Export-Csv -Path 'd:\VNX-Errors.csv' -NoTypeInformation -UseCulture -Encoding UTF8
Alles war in Ordnung, alles, was übrig blieb, war, einen „Glanz“ in Form eines automatischen Versands eines Briefes an interessierte Kollegen und einer minimalen Formatierung der resultierenden CSV hinzuzufügen. Aber (!) All diese Probleme haben sehr lange geklappt. Daten für einen Monat wurden zum Beispiel ungefähr 45 Minuten gesammelt, was nicht sehr geeignet war, da ich zusätzlich zu regelmäßigen Berichten eine Analyse für das laufende Jahr durchführen wollte, und dies wäre eine sehr lange Zeit. Aber "ablehnen - Angebot." Sie fingen an zu denken.

Natürlich müssen Sie den Code optimieren und paralleles Rechnen aktivieren. In PowerShell konnten wir nicht mehr als 5 Threads gleichzeitig mithilfe des Workflows erfolgreich ausführen , und wir haben noch keine alternativen Methoden "geraucht". Daher wurde beschlossen, die Skriptlogik auf R zu verschieben. Das NaviSECCli- Dienstprogramm, das unter R ausgeführt werden kann , führt eine Übersicht über die Speicherung im Quellcode durch, sodass die Lösung durchaus geeignet ist.
Es wird gesagt - ein paar Tage - fertig!
Wir haben beschlossen, dass ich am Ausgang einen täglichen Newsletter erhalten möchte, der die Gesamtzahl der Fehler im Text des Briefes, einen Zeitplan für die Anzahl der Unfälle (damit das Management etwas zu zeigen hat) und einen Anhang in Form einer XLSX-Tabelle enthält. Wir haben festgestellt, dass ich in der Tabelle 3 Registerkarten haben möchte:
- Unfalldaten für 3 Tage nach Festplatte und Unfalltyp
- Ein ähnlicher Tab, aber für 30 Tage
- Rohdaten (wenn jemand sie selbst in Excel ausführen möchte)
Skriptalgorithmus
1. Laden Sie die verfügbaren Daten auf den Controllern von csv herunter.
2. Parallele Berechnung eines Zyklus für alle Steuerungen mit Suche nach Aufzeichnungen der erforderlichen Alarmmeldungen durchführen;
3. Kombinieren Sie die Ergebnisse in einem Datenrahmen.
4. Datenverarbeitung und -konvertierung durchführen;
5. xlsx-Dokument generieren;
6. Wir bilden den Zeitplan, den wir in PNG speichern.
7. einen Brief mit den gesammelten Daten bilden;
8. Senden Sie einen Brief.
Lassen Sie uns die Punkte des Algorithmus durchgehen
1. Laden Sie die verfügbaren Daten auf den Controllern von csv herunter
Quelltabellenformat mit VNX-Parametern Um Notfallinformationen zu erfassen, müssen Sie mithilfe einer speziellen EMV- Software - NaviCLI - mit bestimmten Schlüsseln eine Reihe von Verbindungen zu beiden Controllern ( Spalten newA und newB ) herstellen.
Der Einfachheit halber formatieren wir die resultierende Tabelle nach dem Laden neu, sodass sich die IP-Adressen beider Controller in derselben Spalte befinden, sodass Sie einen Zyklus in der gesamten Liste und nicht zwei aufeinanderfolgende Zyklen durchführen können. Wir machen das mit der Gather- Funktion. Die Probleme beim Arbeiten mit "vertikalen" oder "horizontalen" Datenformaten sind in der offiziellen Dokumentation der Tidyverse- Bibliothek sehr gut beschrieben. Sie können es hier lesen.
Wir lesen die Daten mit der Funktion read_csv2 und bestimmen die Spaltentypen manuell über den zusätzlichen Parameter col_types . Dies ist eine gute Praxis beschleunigt das Laden erheblich. In unserem Fall ist das nicht so wichtig, weil Die ursprüngliche CSV enthält weniger als 100 Zeilen, aber wir gewöhnen uns daran, richtig zu schreiben.
Bei der Ausgabe erhalten wir diesen Datenrahmen (die neuen Spalten sind cntName und cntIP ):
2-3. Wir durchlaufen parallele Berechnungen eines Zyklus für alle Steuerungen mit einer Suche nach Aufzeichnungen der erforderlichen Alarmmeldungen. Kombinieren Sie die Ergebnisse in einem Datenrahmen
Weiter ist das interessanteste. Paralleles Rechnen .
In R gibt es mehrere (eher sogar viele) Optionen für paralleles Rechnen. Der Link aus den Bibliotheken foreach und doParallel hat mir besser gefallen . Sie können über sie und andere parallele Rechenoptionen in R hier lesen.
Kurz gesagt, wir machen nur 3 Schritte :
Schritt 1 Registrieren Sie Kernel reiner Smaragd CPU für das parallele Rechnen über registerDoParallel (in unserem Fall ermitteln wir zunächst die Anzahl der Kerne im Fall)
Registrieren Sie die CPU-Kerne numCores <- detectCores() registerDoParallel(numCores)
Schritt 2 Wir starten den Zyklus über foreach (vergessen Sie nicht, den Operator % dopar% anzugeben, damit der Zyklus parallel abläuft, und geben Sie über den Parameter .combine an, wie das Ergebnis erfasst wird). In unserem Fall .combine = rbind , weil wir am Ausgang jeder Schleife einen Datenrahmen haben.
Code zum Abrufen der Fehlertabelle Schritt 3 Wir löschen den erstellten Parallelitätscluster mit stopImplicitCluster ()
Ein wenig mehr Details zum Abrufen einer lesbaren Tabelle aus rohem Fehlertext
In Textform lauten die Fehler wie folgt:
head(errors_raw) [1] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841d1080 10006 " [2] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841e1a00 10006 " [3] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 8420b600 10006 " [4] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 84206900 10006 " [5] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841fc900 10006 " [6] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841fc000 10006
Hier haben wir Werte, die durch ein Leerzeichen getrennt sind, das auf den ersten Blick auch in csv normal eingefügt wird. Aber es ist nicht so einfach. Die Komplexität des Parsens hier ist folgende:
- Datum und Uhrzeit sind ebenfalls durch ein Leerzeichen (das kleinste Übel) getrennt.
- der Fehlertext besteht aus "Wörtern", d.h. auch durch ein Leerzeichen getrennt;
- Aus irgendeinem Grund ist zwischen der Datenträgernummer und dem Fehlercode (in Klammern) kein Leerzeichen.
Im Allgemeinen ein Paradies für einen Liebhaber regulärer Ausdrücke :)

Ich werde mich nicht mit dem Parsen befassen, da es Geschmackssache ist, aber ich werde klarstellen, dass der Fehlertext auseinandergerissen werden musste, da sich die Werte zwischen der schließenden Klammer der Fehlernummer und der öffnenden eckigen Klammer eines anderen Werts befinden. In einer Schleife ist dies die Fehlervariable .
Es ist auch ein interessanter Punkt, dass wir zur Vereinfachung der Bildung des endgültigen Datenrahmens , um die IP-Adressen der Controller zu durchlaufen, die Sequenz nicht durch die Spalte mit den IP-Adressen der Controller (d. H. I = VNX_ip $ cntIP ), sondern durch die Zeilennummer (d. H. i = 1: nrow (VNX_ip) ). Auf diese Weise können wir die Clusternummer und den Speichernamen über die Aufrufe VNX_ip $ cl [i] bzw. VNX_ip $ Name [i] hinzufügen , wenn wir einen Datenrahmen mit bereits analysierten Fehlern erstellen. Ohne dies müssten Verknüpfungen hergestellt werden, die langsamer und schlechter im Code gelesen würden.
Am Ende erhalten wir einen Datenrahmen (um ehrlich zu sein, dann tibble , aber der Unterschied geht über den Rahmen des Artikels hinaus), der alle Daten enthält, die wir benötigen. Das heißt, Auf welchem Speichersystem, auf welcher Festplatte, wann welcher Fehler aufgetreten ist.
Das Klügste ist, dass der gesamte Zyklus der parallelen Abfrage aller Speichersysteme nicht 30 Minuten, sondern 30 Sekunden dauert .
Gott sei Dank, dass dies nicht der Fall ist, wenn 30 Sekunden zu schnell sind.

Es sollte klargestellt werden, dass der PowerShell- Code auch die Seriennummern der Festplatten aller Speichersysteme in einem Zyklus erfasst hat. Zum Zeitpunkt des Umschreibens des Codes auf R waren diese Daten redundant. Der Laufzeitvergleich ist also nicht ganz ehrlich, aber dennoch beeindruckend.
Die Datenkonvertierung für xlsx-Dokumente wurde auf das Filtern der Quelltabelle in den letzten 3 Tagen sowie im letzten Monat und das Konvertieren der Spalten mit den Fehlernamen in das "horizontale" Format reduziert, sodass sich jeder Fehlertyp in einer separaten Spalte befand. Hierfür wurde eine separate Funktion geschrieben (um die gleichen Schritte nicht zweimal zu duplizieren)
Quellfilterfunktion myErrorStats <- function(data, period, orderColname = quo(Soft_Media_Error)) { data %>% filter(Date > period) %>% group_by(cl, Storage, Disk, Error) %>% summarise(count = n()) %>% spread(Error, count, fill = 0) %>% arrange(desc(!!orderColname)) }
Um die Fehlertypen in einer separaten Spalte anzuzeigen, wurde die Spread- Funktion mit der zusätzlichen Schlüsselfüllung = 0 angewendet, mit der die fehlenden Werte mit 0 gefüllt wurden. Ohne diesen Schlüssel hätte die entsprechende Spalte NA- Werte, wenn an einem Tag kein Fehler aufgetreten wäre.
Außerdem wollte ich in der Funktion die Möglichkeit behalten, den Spaltennamen zum Sortieren als Variable zu übergeben, habe aber gleichzeitig Standardwerte für diese Variable. Hierzu wird die eigentümliche Syntax dplyr verwendet , über die Sie hier mehr lesen können.
In unserem Fall setzen wir beim Definieren der Parameter einer Funktion einen von ihnen auf den Standardwert und zitieren ihn ( orderColname = quo (Soft_Media_Error) ) und setzen dann beim Aufruf Zeichen davor !! zu arrangieren bekommen (desc (!! orderColname)) .
Das Erscheinungsbild der Tabelle mit Fehlern für den Monat Ich habe die Bildung des xlsx-Dokuments in dem Artikel über Berichte über den Status der VM analysiert, daher werde ich nicht näher darauf eingehen. Der gesamte Code ist am Ende des Artikels angegeben.

Hier sind wichtige Funktionen, die die Lesbarkeit des Berichts verbessern:
- Signierte Registerkarten (standardmäßig ist die interessanteste geöffnet);
- Hervorgehobene Spaltennamen
- Automatische Formatierung aller Spalten, sodass der gesamte Text lesbar ist, ohne dass die Spalten erweitert werden müssen.
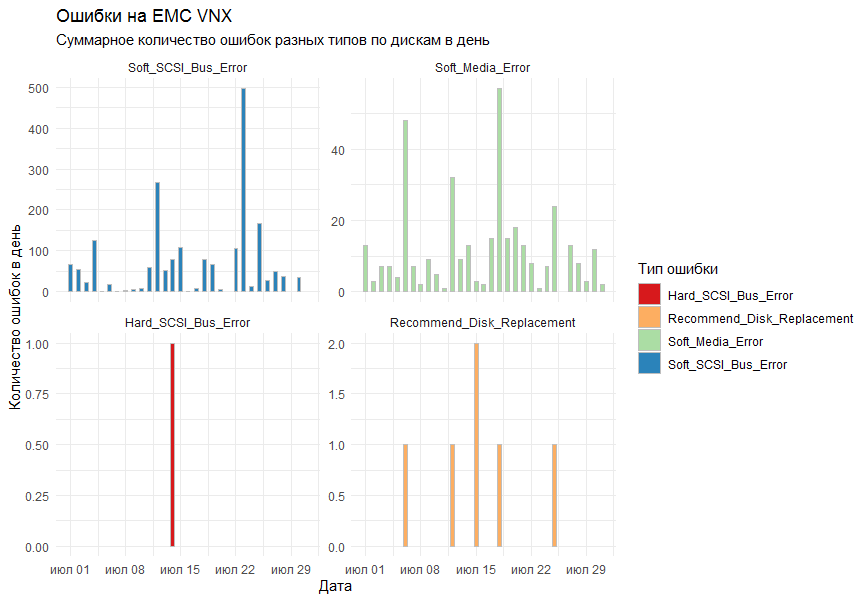
In der Grafik wollte ich die Gesamtzahl der Fehler pro Tag für alle Speichersysteme nach Typ ermitteln. Als Zeichenwerkzeug wurde beschlossen, die Standardbibliothek ggplot2 zu verwenden.
Die erste Version des Diagramms zeigte alle Fehler in einem Diagramm und sah folgendermaßen aus:

Kollegen sagten, dass es sich als unlesbar herausstellte.
Was würden sie verstehen? !!!!
Die Anmerkungen wurden berücksichtigt und die Funktion facet_grid wurde zu den Standardspalten ( geom_bar ) hinzugefügt , um das Ergebnis nach Fehlertyp in separate Diagramme zu unterteilen.
Das Endergebnis war für alle geeignet.

Datenaufbereitung, grafische Darstellung, Speichern in Datei Von den interessanten in der Bildung des Zeitplans.
Ich wollte, dass die Charts in einer bestimmten Reihenfolge sind. Dazu musste der Parameter zum Bilden von Zeilen in facet_grid als Faktor bzw. vielmehr als geordneter Faktor übertragen werden . Faktor ist ein solches gerissenes Datenformat in R, das eine Menge von Werten ist (in unserem Fall Zeichenfolgen, d. H. Zeichen ), und die Menge dieser Werte ist streng definiert (als Faktorebenen bezeichnet), und selbst diese Ebenen werden sortiert. Es klingt kompliziert, aber alles passt zusammen, wenn Sie sagen, dass die Namen der Monate ein gutes Beispiel für einen geordneten Faktor sind. Das heißt, Wir wissen, welche Namen Monate haben können, und wir wissen auch (nun, ich hoffe), dass zuerst Januar, dann Februar, dann März usw. kommen. Nach dem gleichen Prinzip schaffen wir einen Faktor.
Die Bildung und das Senden von Briefen sowie die Bildung von Aufgaben in Windows Scheduller wurden ebenfalls in dem Artikel über Berichte über den Status der VM berücksichtigt. Wir fügen einfach ein paar Variablen in den Text ein und formatieren ihn mehr oder weniger klar. Vergessen Sie nicht den Anhang.
Die endgültige Form des Briefes Schlussfolgerungen
R erwies sich erneut als universelles Werkzeug zur Ausführung alltäglicher Aufgaben und zur Visualisierung ihrer Ergebnisse. Und wenn Parallel Computing aktiviert ist, wird dieses Tool auch schnell.
Die Praxis hat auch gezeigt, dass PowerShell Protokolle nur sehr langsam analysiert und in ein lesbares Format übersetzt.
Vielen Dank an alle, die bis zum Ende so viele Briefe gelesen haben.
Vollständiger Anwendungscode
Vollständiger R-Anwendungscode - : EMC VNX 5300
- : NaviCLI-Win-32-x86-en_US-7.31.25.1.29-1
- , : 4*2 CPU, 8 Gb RAM
R > sessionInfo() R version 3.5.3 (2019-03-11) Platform: x86_64-w64-mingw32/x64 (64-bit) Running under: Windows Server 2012 R2 x64 (build 9600) Matrix products: default locale: [1] LC_COLLATE=Russian_Russia.1251 LC_CTYPE=Russian_Russia.1251 LC_MONETARY=Russian_Russia.1251 [4] LC_NUMERIC=C LC_TIME=Russian_Russia.1251 attached base packages: [1] parallel stats graphics grDevices utils datasets methods base other attached packages: [1] taskscheduleR_1.4 pander_0.6.3 doParallel_1.0.14 iterators_1.0.10 foreach_1.4.4 mailR_0.4.1 [7] xlsx_0.6.1 stringi_1.4.3 zoo_1.8-6 lubridate_1.7.4 wesanderson_0.3.6 forcats_0.4.0 [13] stringr_1.4.0 dplyr_0.8.3 purrr_0.3.2 readr_1.3.1 tidyr_0.8.3 tibble_2.1.3 [19] ggplot2_3.2.0 tidyverse_1.2.1 loaded via a namespace (and not attached): [1] tidyselect_0.2.5 reshape2_1.4.3 rJava_0.9-11 haven_2.1.1 lattice_0.20-38 colorspace_1.4-1 [7] vctrs_0.2.0 generics_0.0.2 utf8_1.1.4 rlang_0.4.0 R.oo_1.22.0 pillar_1.4.2 [13] glue_1.3.1 withr_2.1.2 R.utils_2.9.0 RColorBrewer_1.1-2 modelr_0.1.4 readxl_1.3.1 [19] plyr_1.8.4 munsell_0.5.0 gtable_0.3.0 cellranger_1.1.0 rvest_0.3.4 R.methodsS3_1.7.1 [25] codetools_0.2-16 labeling_0.3 fansi_0.4.0 xlsxjars_0.6.1 broom_0.5.2 Rcpp_1.0.1 [31] scales_1.0.0 backports_1.1.4 jsonlite_1.6 digest_0.6.20 hms_0.5.0 grid_3.5.3 [37] cli_1.1.0 tools_3.5.3 magrittr_1.5 lazyeval_0.2.2 crayon_1.3.4 pkgconfig_2.0.2 [43] zeallot_0.1.0 data.table_1.12.2 xml2_1.2.0 assertthat_0.2.1 httr_1.4.0 rstudioapi_0.10 [49] R6_2.4.0 nlme_3.1-137 compiler_3.5.3