Kurzer Artikel zum Business Process Mining im Kontext des wachsenden Interesses am Konzept des "Digital Twin". Aufgrund des periodischen Auftretens dieses Themas halte ich es für angebracht, Lösungsansätze auszutauschen.
Erklärung des Problems
Die Situation ist sehr einfach.
- Es gibt Firma X (Y, Z, ...).
- Das Unternehmen verfügt über Geschäftsprozesse, die durch verschiedene IT-Systeme automatisiert werden.
- Es gibt Geschäftsanalysten, die BPMN-Diagramme für diese Prozesse erstellt haben. Genauer gesagt, ihre eigene "bpmn-Idee", wie diese Prozesse hätten aussehen sollen.
- Geschäftsanwender möchten eine Art Repräsentation (KPI) dieser Prozesse haben.
Wie komme ich zur Wahrheit und zähle diese Metriken?
Es ist eine Fortsetzung früherer Veröffentlichungen .
Grundlegende Postulate:
- Es gibt ein temporäres Ereignisprotokoll (verschiedene Protokolle von IT-Systemen, cdr \ xdr, nur Aufzeichnungen von Ereignissen in der Datenbank) mit unterschiedlichen Reinheits-, Vollständigkeits- und Konsistenzgraden.
- IT-Systeme fungieren als Zustandsmaschine und „gehen“ zwischen verschiedenen Zuständen gemäß den Aktionen der Benutzer und der von den Programmierern in ihnen festgelegten Geschäftslogik.
- Die Benutzerinteraktion erfolgt in Transaktionsform.
Korrekturen der physischen Welt:
- Die Anzahl der am IT-System vorgenommenen Änderungen ist so hoch, dass die BPMN-Diagramme von Geschäftsanalysten fast nichts mit der Realität zu tun haben.
- Daten können sehr unstrukturiert sein (z. B. Anwendungsprotokolle).
- "Transactional" ist ein logisches Konzept. Die Ereignisdatensätze selbst enthalten nur Attribute, die diesem Status inhärent sind, und es gibt keine End-to-End-Transaktionskennung.
- Die Anzahl der Datensätze pro Tag beträgt Zehntausende, Hunderttausende von Millionen Stück .
Set-Count-Lösung
Um solche Probleme zu lösen, ist es notwendig:
- Rekonstruieren Sie Transaktionen
- Rekonstruieren Sie reale Geschäftsprozesse
- Berechnungen machen;
- Generieren Sie Ergebnisse in einem für Menschen lesbaren Format.
Sie können nach Anbieterlösungen suchen und Millionen bezahlen. Aber wir haben R. in unseren Händen. Es ermöglicht uns perfekt, dieses Problem zu lösen. Kurze Überlegungen unten.
Alles scheint einfach zu sein und R hat einen guten konsistenten Satz von bupaR- Paketen. Aber eine Fliege in der Salbe ist vorhanden und vergiftet alles. Dieser Satz in einer akzeptablen Zeit kann nur eine kleine Anzahl von Ereignissen (Hunderttausende - mehrere Millionen) bewältigen.
Für große Mengen müssen andere Ansätze verwendet werden.
Geschwindigkeit hinzufügen!
Emulieren Sie einen Eingabedatensatz
Um Ideen zu demonstrieren, ist es notwendig, eine Art Testdatensatz zu bilden. Nehmen wir ein Beispiel einer Bundesgeschäftskette als physikalische Quelle für ein mathematisches Modell. Glücklicherweise ist dies für alle verständlich. Obwohl mit dem gleichen Erfolg können es Geldautomaten, Call Center, öffentliche Verkehrsmittel, Wasserversorgung usw. sein.
- Es gibt Geschäfte in verschiedenen Größen (klein, mittel und groß).
- In Geschäften gibt es Kassen (pos Terminals).
- Geschäftsnummern können alphanumerisch sein, Terminalnummern können digital sein.
- Käufer gehen in Geschäfte und kaufen etwas ein, während sie mit einer Karte bezahlen.
- Die Interaktion des Pos-Terminals mit der Karte und der Bank wird durch eine Reihe von Zuständen und die Regeln für den Übergang zwischen ihnen beschrieben.
- Transaktionen sind erfolgreich, erfolglos, zurückgestellt und unvollständig (die Bank ist beispielsweise nicht verfügbar).
- Transaktionen haben Zeitüberschreitungen.
Nehmen Sie die folgenden Geschäftsvorgangsmuster:
"INIT-REQUEST-RESPONSE-SUCCESS" "INIT-REQUEST-RESPONSE-ERROR" "INIT-REQUEST-RESPONSE-DEFFERED" "INIT-REQUEST" "INIT"
Um den Ansatz zu demonstrieren, werden wir eine kleine Stichprobe erstellen, die jedoch bei Milliarden von Datensätzen einwandfrei funktioniert (für ein solches Volumen ohne Superdeep-Optimierung wird die charakteristische Zeit in nur Hunderten von Sekunden auf einem einzelnen Server mit sehr mittelmäßiger Leistung gemessen ).
Direkte Spoiler für große Mengen:
tidyverse bedeutet vielerorts, dass tidyverse keine Antwort erhalten können.- Die Optimierung selbst von Mikroschritten ist nützlich und kann einen wesentlichen Beitrag leisten.
Beispielsimulationscode library(tidyverse) library(datapasta) library(tictoc) library(data.table) library(stringi) library(anytime) library(rTRNG) data.table::setDTthreads(0) # data.table data.table::getDTthreads() # set.seed(46572) RcppParallel::setThreadOptions(numThreads = parallel::detectCores() - 1) # -- -, # 5 -, 2 -- bo_pattern <- tibble::tribble( # , , ~pattern, ~prob, ~mean_duration, "INIT-REQUEST-RESPONSE-SUCCESS", 0.7, 5, "INIT-REQUEST-RESPONSE-ERROR", 0.15, 5, "INIT-REQUEST-RESPONSE-DEFFERED", 0.07, 8, "INIT-REQUEST", 0.05, 2, "INIT", 0.03, 0.5 ) # + checkmate::assertTRUE(sum(bo_pattern$prob) == 1) df <- bo_pattern %>% separate_rows(pattern) %>% # mutate(coeff = sum(prob)) %>% group_by(pattern) %>% # summarise(event_prob = sum(prob/coeff)*100) %>% ungroup() checkmate::assertTRUE(sum(df$event_prob) == 100) # 3 : (4 ), (12 ), (30 ) df1 <- tribble( ~type, ~n_pos, ~n_store, "small", 4, 10, "medium", 12, 5, "large", 30, 2 ) %>% # mutate(store = map2(row_number(), n_store, ~sample(x = .x * 1000 + 1:.y, size = .y, replace = FALSE))) %>% unnest(store) %>% # mutate(pos = map(n_pos, ~sample(x = .x, size = .x, replace = FALSE))) %>% unnest(pos) %>% mutate(pattern = sample(bo_pattern$pattern, n(), replace = TRUE, prob = bo_pattern$prob)) tic("Generate transactions") # , # , df2 <- df1 %>% # select(-matches("duration")) %>% left_join(bo_pattern, by = "pattern") %>% # sample_frac(size = 200, replace = TRUE) %>% mutate(duration = rnorm(n(), mean = mean_duration, sd = mean_duration * .25)) %>% select(-prob, -mean_duration) %>% # , > # 30 filter(duration > 0.5 & duration < 30) %>% # POS mutate(session_id = row_number()) %>% # , separate_rows(pattern) %>% rename(event = pattern) toc() tic("Generate time markers, data.table way") samples_tbl <- data.table::as.data.table(df2) %>% # setkey(session_id, duration, physical = FALSE) %>% # # 1- , , 5 # .[, ticks := base::sort(runif(.N, 5, 5 + duration)), by = .(session_id, duration)] %>% # match.arg base::order!! # # 0 1 # # .[, tshift := runif(.N, 0, 1)] %>% # trng ( ) # , .[, trand := runif_trng(.N, 0, 1, parallelGrain = 100L) * duration] %>% # , # .[, ticks := sort(tshift), by = .(session_id)] %>% # , session_id, , .[, t_idx := session_id + trand / max(trand)/10] %>% # # session_id . .[, tshift := (sort(t_idx) - session_id) * 10 * max(trand)] %>% # , POS (60 ) .[event == "INIT", tshift := tshift + runif_trng(.N, 0, 60, parallelGrain = 100L)] %>% # .[, `:=`(duration = NULL, trand = NULL, t_idx = NULL, n_store = NULL, n_pos = NULL, timestamp = as.numeric(anytime("2019-03-11 08:00:00 MSK")))] %>% # , 01.03.2019 .[, timestamp := timestamp + cumsum(tshift), by = .(store, pos)] %>% # .[timestamp <= as.numeric(anytime("2019-04-11 23:00:00 MSK")), ] %>% # .[, timestamp := anytime(timestamp, tz = "Europe/Moscow")] %>% as_tibble() %>% select(store, pos, event, timestamp, session_id) toc()
Für die Reinheit des Experiments belassen wir nur die signifikanten Parameter und mischen alles. Im wirklichen Leben ist es immer noch notwendig, einen Teil der Fragmente zufällig wegzuwerfen (möglicherweise in getrennten Zeitblöcken), wodurch Verluste beim Empfangen von Daten emuliert werden.
# log_tbl <- samples_tbl %>% select(store, pos, state = event, timestamp_msk = timestamp) %>% sample_n(n()) # log_tbl %>% mutate(timegroup = lubridate::ceiling_date(timestamp_msk, unit = "10 mins")) %>% ggplot(aes(timegroup)) + # geom_bar(width = 0.7*600) + geom_bar(colour = "white", size = 1.3) + theme_bw()
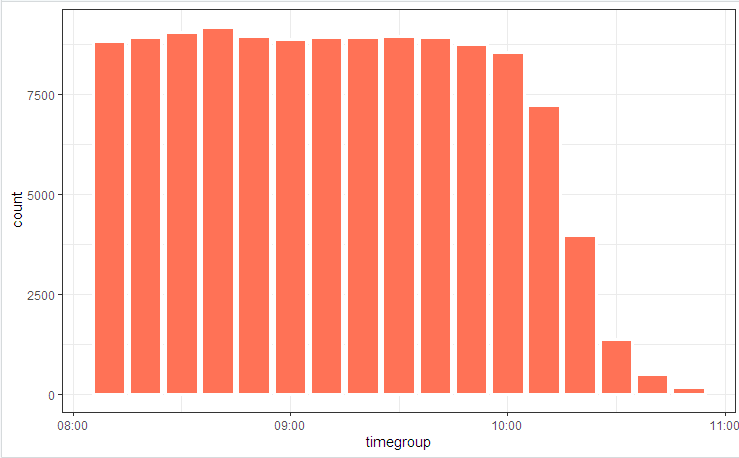
Wir veranschaulichen das Prozessdiagramm mit einem Bild

und staatliche Verteilung

Geringe Schwankungen sind darauf zurückzuführen, dass die Tabelle am Anfang berücksichtigt wird (sie ist im Code enthalten) und bupaR::process_map am Ende funktioniert hat, als einige der zufällig generierten Daten, die nicht den integralen Einschränkungen entsprachen, durch Filtern von Elementen abgeschnitten wurden.
Transaktionsrekonstruktion
Das erste, was normalerweise angeboten wird, wenn Sie Zeitreihen sammeln / zerlegen / vergleichen müssen, sind Gruppierungen und Vergleichszyklen. In Demos mit 100 Einträgen funktioniert diese Wanderung, Millionen von Listen jedoch nicht. Um diese Aufgabe zu bewältigen, müssen Sie die Zeitverlustpunkte (interne Schleifen, Zwischenspeicherzuordnungen und Kopieren) lokalisieren und versuchen, sie auf ein Minimum zu reduzieren.
Infolgedessen kann dieses Problem auf zehn Zeilen reduziert werden.
Transaktionsrekonstruktionscode clean_dt <- as.data.table(log_tbl) %>% # INIT .[, start := (state == "INIT")] %>% # session_id , # .[, event_date := lubridate::as_date(timestamp_msk)] %>% .[, date_str := format(.BY[[1]], "%y%m%d"), by = event_date] %>% # # timestamp_msk setorder(store, pos, timestamp_msk) %>% # -- .[, session_id := paste(date_str, store, pos, cumsum(start), sep = "_")] %>% # ( 30 ) # .[, time_shift := timestamp_msk - shift(timestamp_msk), by = .(store, pos)] %>% # , INIT .[, time_locf := cummax(as.numeric(timestamp_msk) * as.numeric(start)), by = .(store, pos)] %>% .[, time_shift := as.numeric(timestamp_msk) - time_locf] %>% # , 30 .[, lost_chain := time_shift > 30] %>% # .[, time_shift := as.numeric(!start) * as.numeric(timestamp_msk - shift(timestamp_msk, fill = 0))] %>% # INIT # .[, time_accu := cumsum(time_shift)] %>% .[, date_str := NULL] # # tidyverse , dt <- as.data.table(clean_dt) %>% # !!! .[lost_chain != TRUE] %>% # 1- .[order(timestamp_msk, store, pos)] %>% .[, bp_pattern := stri_join(state, collapse = "-"), by = session_id] # as_tibble(dt) %>% distinct(session_id, bp_pattern) %>% count(session_id, sort = TRUE)
In wenigen Sekunden haben wir ein rekonstruiertes Bild der Geschäftsprozesse.
Und (wer hätte das gedacht !!!) tatsächlich stellt sich heraus, dass die in IT-Systemen automatisierten Geschäftsprozesse etwas anders (oder gar nicht) funktionieren, da Geschäftsanalysten alle überzeugt haben. Die Wunder und Argumente der „Prozessverantwortlichen“ werden das Studium des endgültigen Bildes begleiten.
Tricks aktiv anwenden
Wenn die Rechengeschwindigkeit eine wichtige Größe wird, reicht das Schreiben eines Arbeitscodes nicht aus. Es ist notwendig, auf alle Ebenen zu achten. Es gibt auch eine Reihe von algorithmischen Tricks, die die Ausführungszeit erheblich verkürzen können.
Insbesondere können wir in dieser Aufgabe Folgendes erwähnen:
- Für die Hauptverarbeitung nur
data.table (Geschwindigkeit, Bearbeitung von Links), + Berücksichtigung der internen Abfrageoptimierung. POSIXct kann Millisekunden enthalten (obwohl es nicht normal angezeigt wird, sondern mithilfe von options(digits.secs=X) korrigiert werden kann). Wir verstecken sie dort. Es ist einfacher zu vergleichen und zu sortieren.- Vermeiden Sie physisches Sortieren innerhalb von Gruppen! Eine einzige physische Sortierung des gesamten Vektors gewährleistet die Sortierung der Daten in Gruppen.
- Vermeiden Sie das Rechnen innerhalb von Gruppen. Wir versuchen, alles Mögliche für die Quelldaten zu tun (wir wenden die Vektorisierung an, reduzieren die Rechnungen für Funktionsaufrufe).
- Wir verwenden ein Transaktions-Timeout, um Zeitlücken zu schließen.
- Die locf-Methoden (Last Observation Carried Forward) sind langsam. Verwenden Sie
cumsum , cummax , um Eigenschaften auf einer Zeitachse zu cummax . - Zeitaufwändige Vorgänge wie POSIX -> Zeichenfolgenkonvertierung, regelmäßige Suche usw. Wir tun es nicht Element für Element, sondern auf Windungen. Die Gemeinkosten für die interne Indizierung und Gruppierung des konvertierten Feldes sind unvergleichlich geringer.
- Wir verwenden aktiv Multithreading (einschließlich Intra-Packet).
- Vernachlässigen Sie nicht die Mikrooptimierung. Zum Beispiel ist
stri_c um ein Vielfaches schneller als paste0 .
# 1 log <- getLog(fileName) bench::mark( paste0 = paste0(log$value, collapse = "\n"), stringi = stri_c(log$value, collapse = "\n") ) # # A tibble: 2 x 13 # expression min median `itr/sec` mem_alloc `gc/sec` n_itr n_gc total_time # <bch:expr> <bch:> <bch:> <dbl> <bch:byt> <dbl> <int> <dbl> <bch:tm> # 1 paste0 58ms 59.1ms 16.9 496KB 0 9 0 533ms # 2 stringi 16.9ms 17.5ms 57.1 0B 0 29 0 508ms
Vorheriger Beitrag - Swiss Json Verarbeitungsmesser .