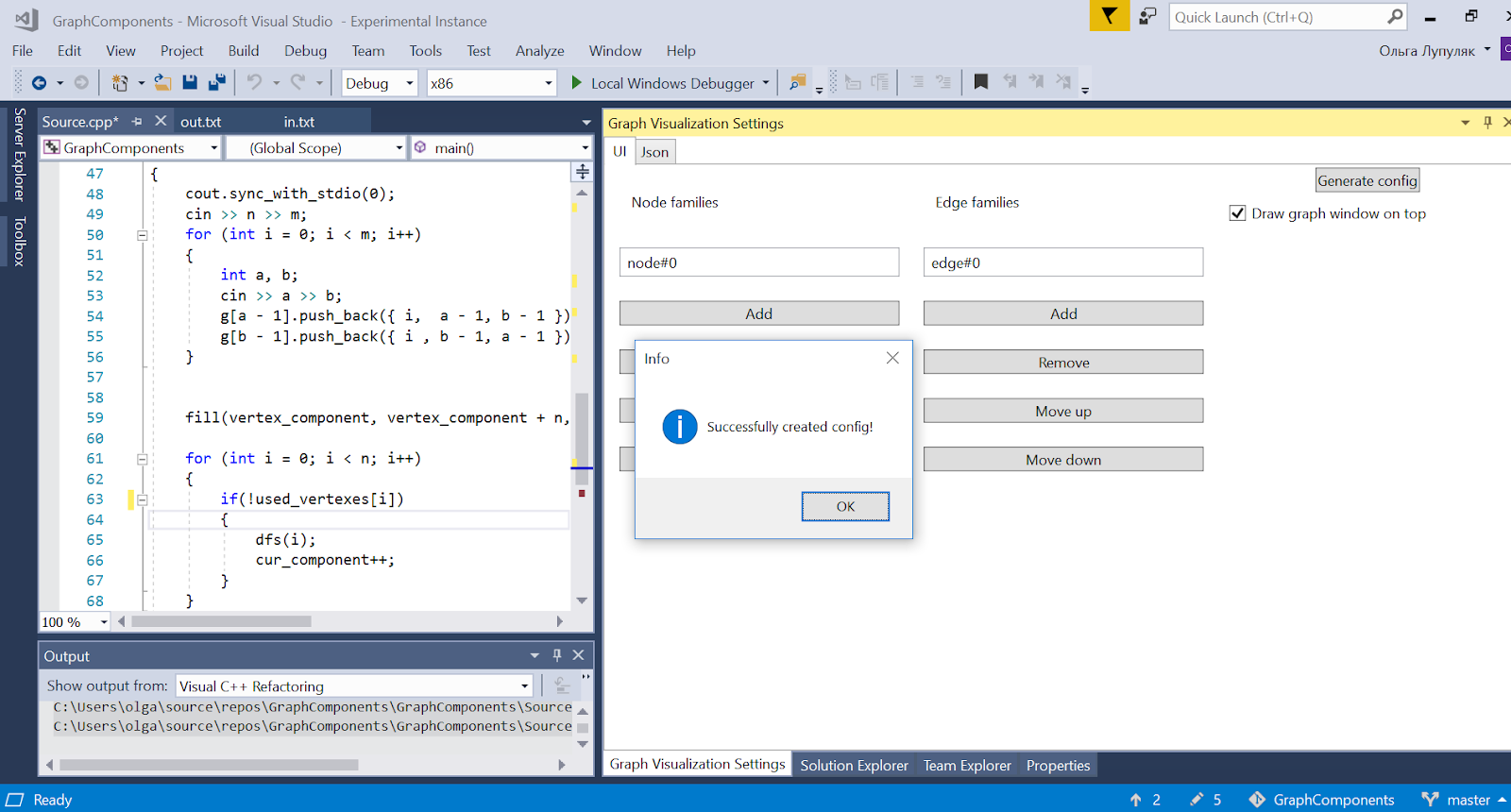
Stellen Sie sich eine typische Situation im ersten Jahr vor: Sie haben
über den Dinits-Algorithmus gelesen, ihn implementiert, aber er hat nicht funktioniert, und Sie wissen nicht warum. Die Standardlösung besteht darin, das Debuggen schrittweise zu starten und jedes Mal den aktuellen Status des Diagramms auf ein Blatt Papier zu zeichnen. Dies ist jedoch äußerst unpraktisch. Ich habe versucht, die Situation im Rahmen eines Semesterprojekts zum Thema Software Engineering zu korrigieren, und in einem Beitrag werde ich Ihnen erzählen, wie ich zu einem Plug-In für Visual Studio gekommen bin. Sie können es
hier herunterladen, den Quellcode und die Dokumentation finden Sie
hier . Hier ist ein Screenshot des Diagramms, das für den Dinits-Algorithmus erhalten wurde.
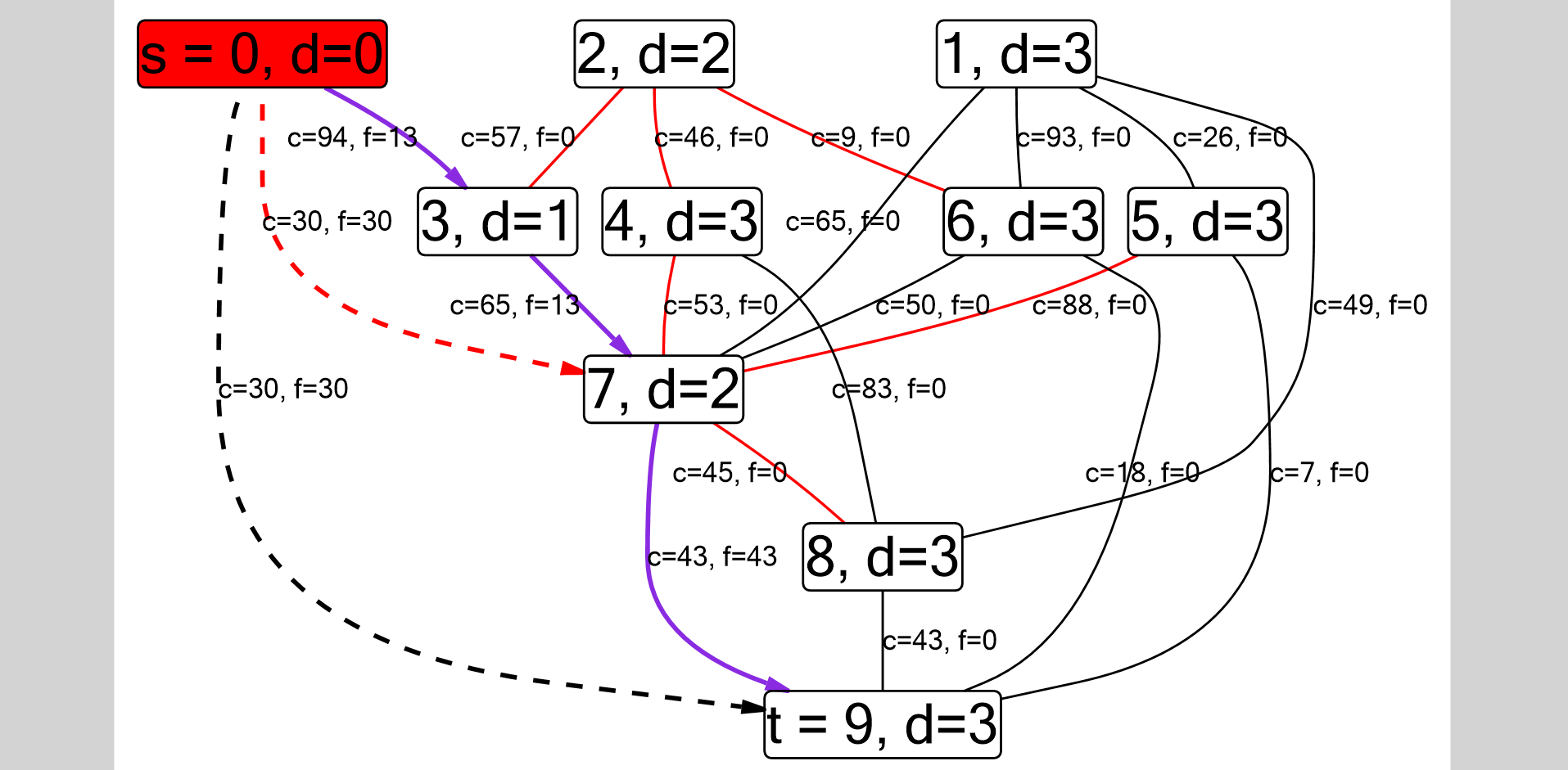
Über mich
Mein Name ist Olga, ich habe das dritte Jahr der Richtung „Angewandte Mathematik und Informatik“ an der HSE in St. Petersburg mit einem Abschluss in Software Engineering abgeschlossen. Vor dem Eintritt in die Universität war ich nicht in die Programmierung involviert.
Forschung: Anforderungen
An unserer Fakultät Praxis Semester Forschungsarbeit. Normalerweise geschieht dies so: Zu Beginn des Semesters findet eine Präsentation der Forschungsarbeiten statt - Vertreter verschiedener Unternehmen bieten alle Arten von Projekten an. Dann wählen die Schüler ihre Lieblingsprojekte aus, die Betreuer wählen ihre Lieblingsschüler aus und so weiter. Am Ende findet jeder Schüler ein Projekt für sich.
Es gibt aber noch einen anderen Weg: Sie können unabhängig voneinander einen Supervisor und ein Projekt finden und dann den Kurator davon überzeugen, dass dieses Projekt wirklich eine vollwertige F & E sein kann. Beweisen Sie dazu Folgendes:
- Du wirst etwas Neues machen. Natürlich kann das Projekt Analoga haben, aber Ihre Option sollte einige Vorteile gegenüber ihnen haben.
- Die Aufgabe sollte ziemlich schwierig sein, dh die Arbeit dort sollte für ein Semester und nicht für einen Tag sein. Gleichzeitig ist es notwendig, dass das Projekt wirklich in einem Semester durchgeführt wurde.
- Ihr Projekt sollte für die Welt nützlich sein. Das heißt, wenn Sie gefragt werden, warum dies notwendig ist, sollten Sie nicht antworten: "Nun, ich muss irgendeine Art von Forschung betreiben."
Ich habe den zweiten Weg gewählt. Das erste, was ich tun musste, nachdem ich mit dem Betreuer einverstanden war, war, das Thema des Projekts zu finden. Die Liste der Ideen enthielt: Code Style Checker für Lua, einen Debugger, mit dem Sie Ausdrücke in Teilen berechnen können, und ein Tool für Olympiaden / Programmiertraining, mit dem Sie visualisieren können, was im Code passiert. Das heißt, ein Visualisierer für beliebige Datenstrukturen in Kombination mit einem Debugger. Beispielsweise schreibt eine Person einen
kartesischen Baum , und dabei werden Scheitelpunkte, Kanten, der aktuelle Scheitelpunkt usw. gezeichnet. Am Ende habe ich mich entschlossen, über diese Option nachzudenken.
Projektarbeitsplan
Meine Arbeit an dem Projekt bestand aus folgenden Phasen:
- Das Studium des Themenbereichs war erforderlich, um zu verstehen, ob dieses Problem bereits gelöst war (dann müsste das Projektthema geändert werden), welche Analoga sie haben, welche Vor- und Nachteile sie bei meiner Arbeit berücksichtigen könnten.
- Definieren der spezifischen Funktionalität , über die das erstellte Tool verfügt. Das Thema des Projekts wurde ziemlich abstrakt formuliert, und dies war notwendig, um sicherzustellen, dass die Aufgabe ziemlich kompliziert ist, aber gleichzeitig in einem Semester abgeschlossen werden kann.
- Das Erstellen einer Prototyp-Benutzeroberfläche war erforderlich, um zu demonstrieren, wie das erstellte Tool verwendet werden kann. Es fügte noch mehr Spezifität hinzu als eine Reihe von Merkmalen, die durch Wörter beschrieben werden.
- Auswahl der Abhängigkeiten - Sie müssen verstehen, wie alles aus Sicht des Entwicklers angeordnet wird, und sich für die Tools entscheiden, die beim Schreiben von Code verwendet werden.
- Erstellen eines Prototyps (Proof-of-Concept) , dh eines minimalen Beispiels, in dem die meisten fest codiert wären. In diesem Beispiel musste ich mich mit allen Tools befassen, die ich verwenden wollte, und auch lernen, wie man alle dabei auftretenden Schwierigkeiten löst, sodass die endgültige Version bereits „sauber“ geschrieben war.
- Arbeiten Sie am Inhaltsteil , dh an der Entwicklung und Implementierung der Logik des Tools.
- Projektschutz ist erforderlich, um schnell über die geleistete Arbeit zu sprechen und die Möglichkeit zu geben, sie allen zu bewerten, auch Personen, die sich nicht mit dem Thema beschäftigen. Es ist eine Ausbildung vor dem Abschluss. Gleichzeitig garantiert ein gut gemachtes Projekt nicht, dass sich der Bericht als gut herausstellt, da andere Fähigkeiten erforderlich sind, beispielsweise die Fähigkeit, mit der Öffentlichkeit zu sprechen.
Ich habe immer mit meinem Vorgesetzten geplant. Wir haben uns auch immer alle Ideen ausgedacht und diskutiert, die auf dem Weg entstanden sind. Außerdem gab mir der Supervisor Ratschläge zum Code und half beim Zeitmanagement. Über alle technischen Probleme (unverständliche Fehler usw.) habe ich auch immer berichtet, aber meistens habe ich es geschafft, sie selbst zu lösen.
Fachforschung
Für den Anfang hätte unsere Führung davon überzeugt sein müssen, dass dieses Thema meine Forschungsarbeit verdient. Und um mit dem ersten Punkt zu beginnen: der Suche nach Analoga.
Wie sich herausstellte, gibt es viele Analoga. Die meisten von ihnen wurden jedoch zur Visualisierung des Gedächtnisses entwickelt. Das heißt, sie hätten bei der Visualisierung des kartesischen Baums großartige Arbeit geleistet, aber sie können nicht verstehen, dass der
Heap auf dem Array nicht als Array, sondern als Baum gezeichnet werden sollte. Dazu gehörten
gdbgui , ein
Data Display Debugger , ein Plug-In für Eclipse
jGRASP und ein Plug-In für Visual Studio
Data Structures Visualizer . Letzteres wurde auch für die Probleme der Olympiadenprogrammierung erstellt, konnte jedoch nur Datenstrukturen auf Zeigern visualisieren.
Es gab noch ein paar weitere Tools:
Algojammer für Python (und wir wollten Pluspunkte als beliebteste Sprache unter Olympiadniki) und das 1994 entwickelte
Lens- Tool. Letzteres hat nach der Beschreibung fast das getan, was es brauchte, aber leider wurde es unter Sun OS 4.1.3 (einem Betriebssystem von 1992) erstellt. Trotz der Verfügbarkeit von Quellcodes wurde beschlossen, keine Zeit mit dieser zweifelhaften Archäologie zu verschwenden.
Nach einigen Recherchen stellte sich heraus, dass Tula, die genau das tun würde, was wir wollten, und gleichzeitig an modernen Maschinen arbeitet, noch nicht in der Natur liegt.
Funktionsdefinition
Der zweite Schritt bestand darin zu beweisen, dass diese Aufgabe ziemlich kompliziert, aber machbar ist. Dazu musste etwas Spezifischeres vorgeschlagen werden als „Ich möchte ein schönes Bild, und dass daraus sofort alles klar wird“.
In diesem Projekt haben wir uns darauf konzentriert, nur Diagramme zu visualisieren: Es gibt viele Algorithmen für Diagramme, die auf unterschiedliche Weise implementiert werden können, und selbst wenn sie eingegrenzt werden, bleibt die Aufgabe nicht trivial.
Es ist auch mehr oder weniger offensichtlich, dass das Tool irgendwie in den Debugger integriert werden muss. Wir müssen in der Lage sein, die Werte von Variablen und Ausdrücken anzuzeigen und aus diesen Werten ein fertiges Bild zu zeichnen.
Danach musste eine bestimmte Sprache entwickelt werden, mit der wir ein Diagramm erstellen können, das dem aktuellen Status des Programms entspricht. Zusätzlich zum Diagramm selbst musste die Möglichkeit bereitgestellt werden, die Farbe der Scheitelpunkte und Kanten zu ändern, ihnen beliebige Beschriftungen hinzuzufügen und andere Eigenschaften zu ändern. Dementsprechend war die erste Idee:
- Bestimmen Sie, welche Eckpunkte wir haben, zum Beispiel Zahlen von 0 bis n.
- Bestimmen Sie das Vorhandensein einer Kante zwischen den Scheitelpunkten mithilfe der Booleschen Bedingung. In diesem Fall sind die Kanten von unterschiedlichem Typ, und jeder Typ hat seine eigenen Eigenschaften.
- Außerdem können wir Scheitelpunkteigenschaften wie Farbe definieren, auch unter Verwendung der Booleschen Bedingung.
- Gehen Sie mit dem Debugger die Schritte durch: Alle Ausdrücke werden berechnet, alle Bedingungen überprüft und abhängig davon ein Diagramm gezeichnet.
Prototyping der Benutzeroberfläche
Ich habe den Prototyp der Benutzeroberfläche in
NinjaMock gezeichnet . Dies war erforderlich, um besser zu verstehen, wie die Benutzeroberfläche aus Sicht des Benutzers aussehen wird und welche Aktionen er ausführen muss. Wenn es Probleme mit dem Prototyp gäbe, würden wir verstehen, dass es einige logische Inkonsistenzen gibt, und diese Idee sollte verworfen werden. Aus Gründen der Wiedergabetreue habe ich einige Algorithmen verwendet. Das Bild unten zeigt Beispiele, wie ich mir die
DFS- Visualisierungseinstellungen und
den Floyd-Algorithmus vorgestellt habe .
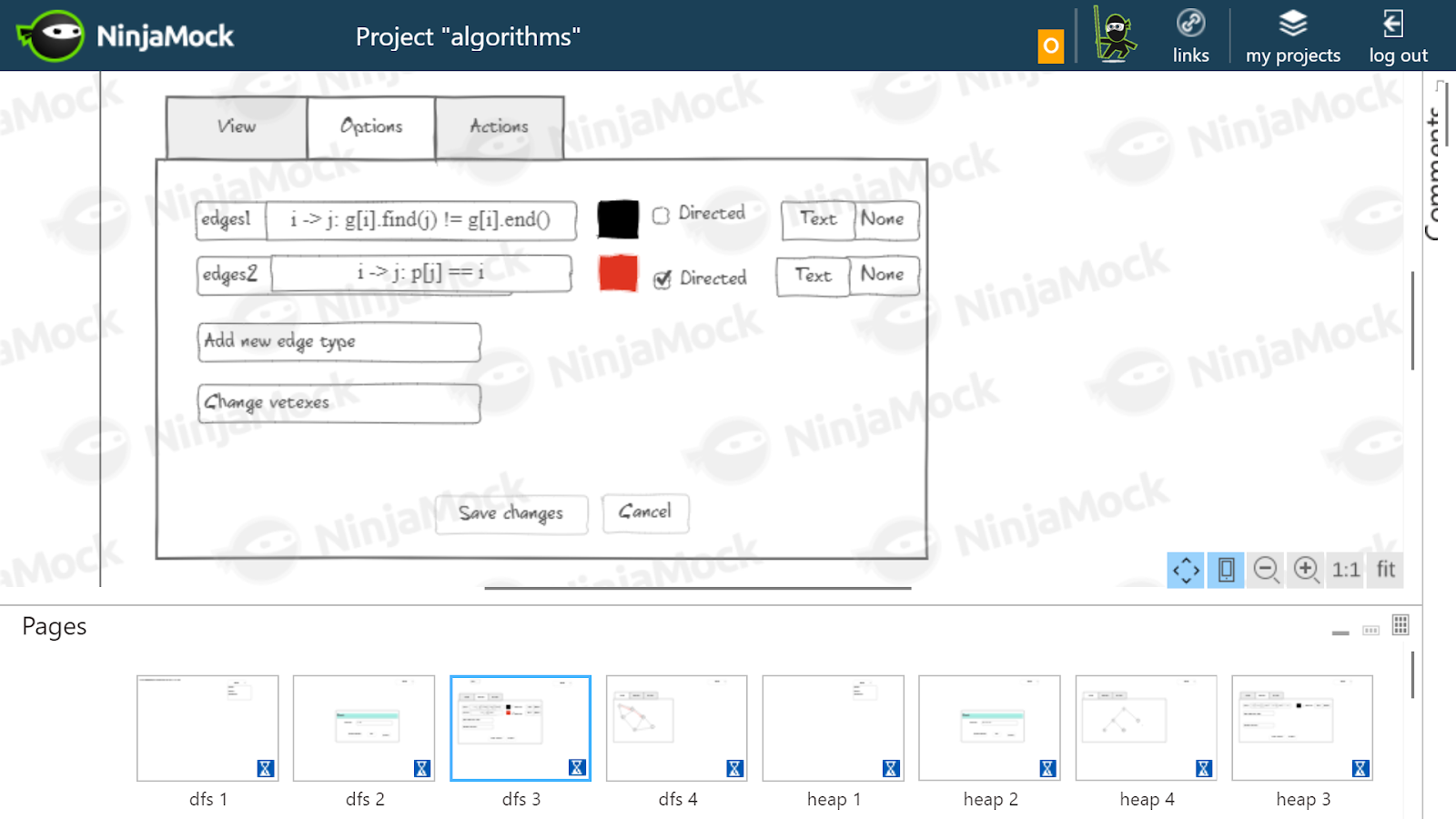 Wie ich mir Einstellungen für DFS vorgestellt habe. Der Graph wird als Adjazenzliste gespeichert, daher wird die Kante zwischen den Eckpunkten i und j durch die Bedingung
Wie ich mir Einstellungen für DFS vorgestellt habe. Der Graph wird als Adjazenzliste gespeichert, daher wird die Kante zwischen den Eckpunkten i und j durch die Bedingung g[i].find() != g[i].end() (um die Kanten nicht zu duplizieren, muss i <= j überprüft werden i <= j ). Der DFS-Pfad wird separat angezeigt: p[j] == i . Diese Kanten werden ausgerichtet.
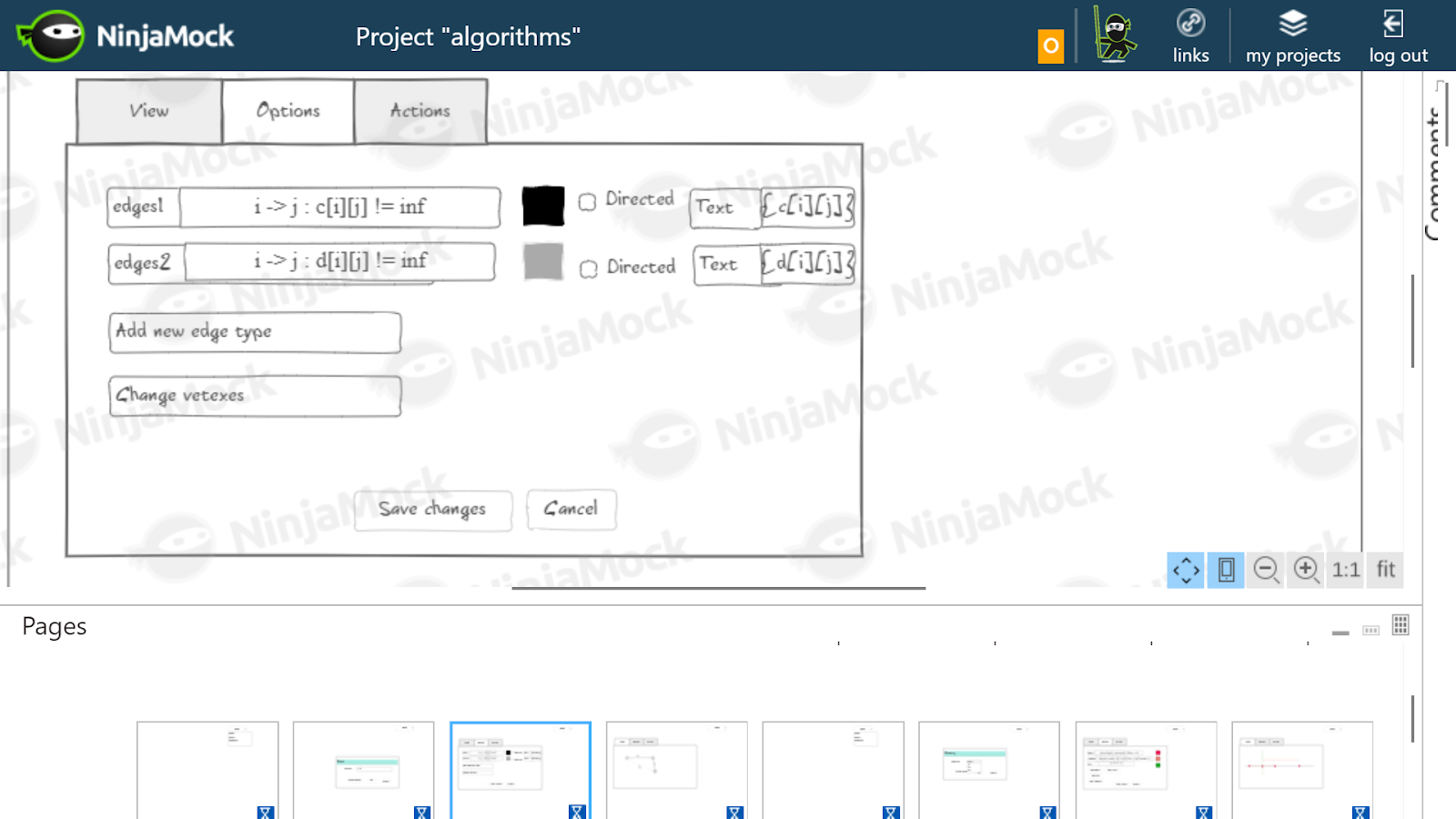
Ich nahm an, dass es für Floyds Algorithmus notwendig wäre, die in Array c gespeicherten realen Kanten schwarz und Grau zu zeichnen - die kürzesten in dieser Phase gefundenen Pfade, die in Array d gespeichert sind. Für jede Kante und jeden kürzesten Weg wird das Gewicht geschrieben.Abhängigkeitsauswahl
Für den nächsten Schritt musste man verstehen, wie man das alles macht. Zunächst war die Integration mit einem Debugger erforderlich. Das erste, was mir einfällt, wenn das Wort "Debugger" gdb ist, aber dann müsste man die gesamte grafische Oberfläche von Grund auf neu erstellen, was für einen Studenten in einem Semester wirklich schwierig ist. Die zweite offensichtliche Idee ist, ein Plugin für eine vorhandene Entwicklungsumgebung zu erstellen. Als Optionen habe ich QTCreator, CLion und Visual Studio in Betracht gezogen.
Die CLion-Option wurde fast sofort verworfen, da zum einen der Quellcode geschlossen ist und zum anderen die Dokumentation sehr schlecht ist (und niemand zusätzliche Schwierigkeiten benötigt). QTCreator ist im Gegensatz zu Visual Studio plattformübergreifend und Open Source. Daher haben wir uns zunächst entschlossen, darauf einzugehen.
Es stellte sich jedoch heraus, dass QTCreator für die Erweiterung mit Plugins schlecht geeignet ist. Der erste Schritt beim Erstellen eines Plugins für QTCreator besteht darin, aus dem Quellcode zu erstellen. Ich habe anderthalb Wochen gebraucht. Am Ende habe ich zwei Fehlerberichte (
hier und
da ) zum Montageprozess gesendet. Ja, so viel Aufwand wurde in die Erstellung von QTCreator gesteckt, um festzustellen, dass der Debugger in QTCreator keine öffentliche API hat. Ich kehrte zu einer anderen Option zurück, nämlich Visual Studio.
Und dies stellte sich als die richtige Entscheidung heraus: Visual Studio verfügt nicht nur über eine großartige API, sondern auch über eine hervorragende Dokumentation. Die Ausdrucksauswertung
_debugger.GetExpression(...).Value durch Aufrufen von
_debugger.GetExpression(...).Value vereinfacht. Visual Studio bietet auch die Möglichkeit, die Frames zu durchlaufen und den Ausdruck im Kontext eines beliebigen Frames auszuwerten. Ändern Sie dazu die Eigenschaft
CurrentStackFrame in die gewünschte. Sie können auch Aktualisierungen des Debugger-Wettbewerbs verfolgen, um das Bild beim Ändern neu zu zeichnen.
Natürlich sollte ich mich nicht mit der Visualisierung von Graphen von Grund auf beschäftigen - dafür gibt es viele spezielle Bibliotheken. Der bekannteste von ihnen ist
Graphviz , und wir hatten vor, es zuerst zu verwenden. Für ein Plug-In für Visual Studio wäre es jedoch logischer, die Bibliothek für C # zu verwenden, da ich darauf schreiben wollte. Ich habe ein wenig gegoogelt und die
MSAGL- Bibliothek gefunden: Sie hatte alle erforderlichen Funktionen und eine einfache und intuitive Benutzeroberfläche.
Proof-of-Concept
Mit einem Mechanismus zur Berechnung beliebiger Ausdrücke einerseits und einer Bibliothek zur Visualisierung von Graphen andererseits musste nun ein Prototyp erstellt werden. Der erste Prototyp wurde für DFS erstellt, dann wurden der Dinits-
Algorithmus ,
der Kuhn-Algorithmus , die
Suche nach doppelt verbundenen Komponenten , der kartesische Baum und das
SNM als Beispiele genommen. Ich habe meine alten Implementierungen dieser Algorithmen vom ersten bis zum zweiten Jahr übernommen, ein neues Plug-In erstellt und ein Diagramm erstellt, das dieser Aufgabe entspricht (alle Variablennamen wurden fest codiert). Hier ist ein Beispiel eines Diagramms, das ich für den Kuhn-Algorithmus erhalten habe:
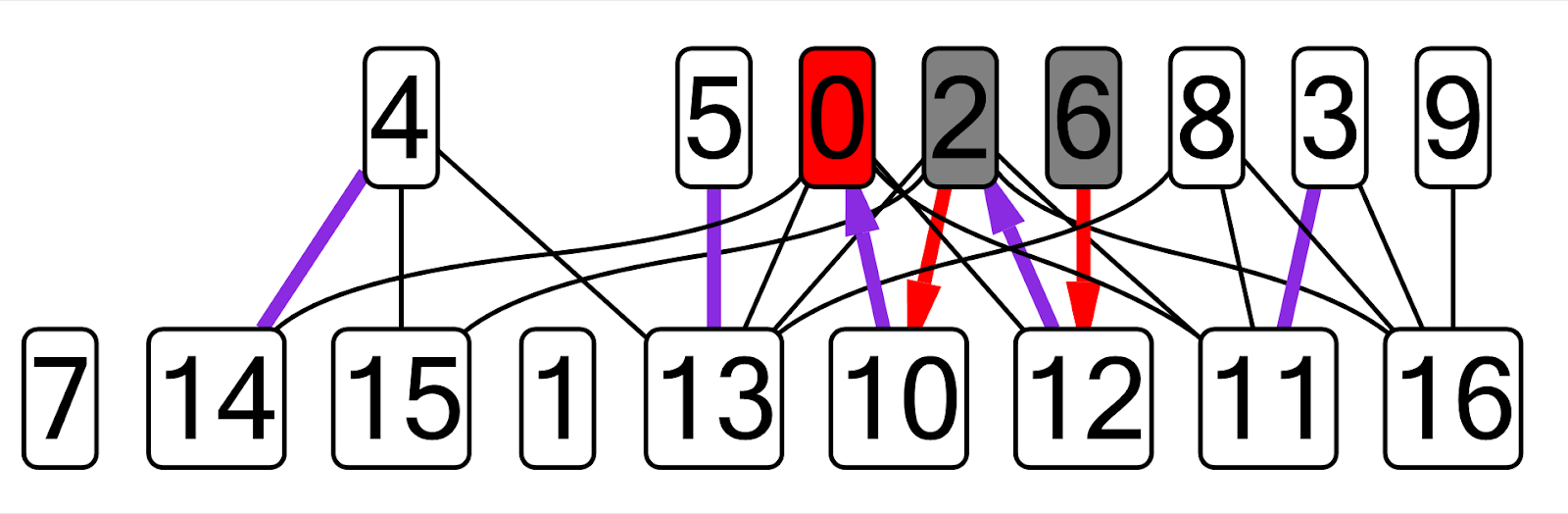 In diesem Diagramm werden die aktuellen Übereinstimmungskanten in lila angezeigt, der aktuelle dfs-Scheitelpunkt in rot, die besuchten Scheitelpunkte in grau und die Kanten einer alternierenden Kette, die nicht aus der Übereinstimmung stammen, in rot.
In diesem Diagramm werden die aktuellen Übereinstimmungskanten in lila angezeigt, der aktuelle dfs-Scheitelpunkt in rot, die besuchten Scheitelpunkte in grau und die Kanten einer alternierenden Kette, die nicht aus der Übereinstimmung stammen, in rot.Ich hielt es für zulässig, den Algorithmuscode geringfügig zu ändern, um die Visualisierung zu vereinfachen. Im Fall des kartesischen Baums stellte sich beispielsweise heraus, dass es einfacher ist, alle erstellten Knoten zu einem Vektor hinzuzufügen, als den Baum im Plugin zu umgehen.
Eine unangenehme Entdeckung war, dass der Debugger in Visual Studio das Aufrufen von Methoden und Funktionen aus der STL nicht unterstützt. Dies bedeutete, dass es nicht möglich war, das Vorhandensein eines Elements im Container mit
std::find zu überprüfen, wie ursprünglich angenommen. Dieses Problem kann entweder durch Erstellen einer benutzerdefinierten Funktion oder durch Duplizieren der Eigenschaft "Das Element ist im Container enthalten" in einem Booleschen Array gelöst werden.
In meinen Test-Plugins ist Folgendes passiert (wenn das Diagramm als Adjazenzliste gespeichert wurde):
- Zuerst kommt die
for Schleife von 0 nach _debugger.GetExpression("n").Value , der alle Scheitelpunkte zum Diagramm hinzufügt, jeder mit seiner eigenen Nummer.
- Dann gibt es zwei verschachtelte
for _debugger.GetExpression($"g[{i}].size()").Value , die erste für i - von 0 bis n , die zweite für j - von 0 bis _debugger.GetExpression($"g[{i}].size()").Value und die Kante {i, _debugger.GetExpression($"g[{i}][{j}]").Value} .
- Bei Bedarf wurden den Beschriftungen der Scheitelpunkte und Kanten einige zusätzliche Informationen hinzugefügt. Zum Beispiel der Wert des Arrays
d , der für den Abstand zum ausgewählten Scheitelpunkt verantwortlich ist.
- Wenn der Algorithmus auf dfs basierte, durchlief eine Schleife alle Frames und alle Scheitelpunkte im Stapel (
stackFrame.FunctionName.Equals("dfs") && stackFrame.Arguments.Item(1) == v ) wurden grau hervorgehoben.
- Dann wurden für jedes
i von 0 bis n , das die Anzahl der Scheitelpunkte bezeichnet, einige Bedingungen überprüft, und wenn sie erfüllt waren, änderten sich einige Eigenschaften am Scheitelpunkt, meistens die Farbe.
Zu dieser Zeit schrieb ich den Code "nach Bedarf", ohne zu versuchen, ein allgemeines Schema für alle Algorithmen zu entwickeln oder den Code zumindest irgendwie schön zu schreiben. Die Erstellung jedes neuen Plugins begann mit dem Kopieren und Einfügen des vorherigen Plugins.
Diagrammkonfiguration
Nach der Untersuchung musste ein allgemeines Schema erstellt werden, das auf alle Algorithmen angewendet werden konnte. Als erstes wurden die Indizes für die Eckpunkte und Kanten eingeführt. Jeder Index hat einen eindeutigen Namen und Bereichsenden, die mit
_debugger.GetExpression berechnet werden. Verwenden Sie den von __ umgebenen Namen (d. H. __x__), um auf den Wert des Index zuzugreifen. Ausdrücke mit Stellen zum Ersetzen von Indexwerten sowie der Name der aktuellen Funktion (__CURRENT_FUNCTION__) und die Werte ihrer Argumente (__ARG1__, __ARG2__, ...) werden als Vorlagen bezeichnet.
Indizes werden für jeden Scheitelpunkt oder jede Kante ersetzt und danach im Debugger berechnet. Die Vorlagen wurden verwendet, um einige Indexwerte herauszufiltern (wenn der Graph als Adjazenzmatrix
c gespeichert ist, sind die Indizes a und b von 0 bis n, und die Vorlage für die Validierung ist
c[__a__][__b__] ). Die Grenzen des Indexbereichs sind ebenfalls Vorlagen, da sie möglicherweise frühere Indizes enthalten.
Ein Diagramm kann verschiedene Arten von Scheitelpunkten und Kanten haben. Beispielsweise kann bei der Suche nach der maximalen Übereinstimmung in einem zweigeteilten Diagramm jeder Bruch separat indiziert werden. Daher wurde das Konzept einer Familie für Eckpunkte und Kanten eingeführt. Für jede Familie werden die Indizierung und alle Eigenschaften unabhängig voneinander bestimmt. In diesem Fall können Kanten Scheitelpunkte aus verschiedenen Familien verbinden.
Sie können einer Scheitelpunkt- oder Kantenfamilie bestimmte Eigenschaften zuweisen, die selektiv auf Elemente in der Familie angewendet werden. Die Eigenschaft wird angewendet, wenn die Bedingung erfüllt ist. Die Bedingung besteht aus einer Vorlage, die als
true oder
false ausgewertet wird, und einem regulären Ausdruck für den Funktionsnamen. Die Bedingung wird entweder nur für den aktuellen Glasrahmen oder für alle Glasrahmen geprüft (und gilt dann als erfüllt, wenn sie für mindestens einen erfüllt ist).
Die Eigenschaften sind sehr unterschiedlich. Für Scheitelpunkte: Beschriftung, Füllfarbe, Rahmenfarbe, Rahmenbreite, Form, Rahmenstil (z. B. gepunktete Linie). Für Kanten: Beschriftung, Farbe, Breite, Stil, Ausrichtung (Sie können zwei Pfeile angeben - von Anfang bis Ende oder umgekehrt; in diesem Fall können zwei Pfeile gleichzeitig vorhanden sein).
Es ist wichtig, dass jedes Mal, wenn das Diagramm von Grund auf neu gezeichnet wird, der vorherige Status in keiner Weise berücksichtigt wird. Dies kann ein Problem sein, wenn sich der Graph während des Algorithmus dynamisch ändert - die Eckpunkte und Kanten können ihre Position dramatisch ändern, und dann ist es schwierig zu verstehen, was passiert.
Eine detaillierte Beschreibung der Grafikkonfiguration finden Sie
hier .
Benutzeroberfläche
Mit der Schnittstelle habe ich beschlossen, nicht viel zu stören. Das Hauptfenster mit den Einstellungen (
ToolWindow ) enthält einen Textbereich für die in JSON serialisierte
Konfiguration sowie eine Liste der Scheitelpunkt- und
Kantenfamilien . Jede Familie hat ein eigenes Fenster mit Einstellungen, und jede Eigenschaft in der Familie hat ein weiteres Fenster (es werden drei Verschachtelungsebenen erhalten). Das Diagramm selbst wird in einem separaten Fenster gezeichnet. Es hat nicht funktioniert, es in ToolWindow einzufügen, daher habe ich einen
Fehlerbericht an die MSAGL-Entwickler gesendet, aber sie haben geantwortet, dass dies nicht der Zielanwendungsfall ist.
Ein weiterer Fehlerbericht wurde an Visual Studio gesendet, da TextBoxen manchmal in den zusätzlichen Einstellungsfenstern hängen blieben.
Plugin
Um das Diagramm zu konfigurieren, verfügt das Plugin über eine Benutzeroberfläche und die Möglichkeit, die Konfiguration in JSON (de) zu serialisieren. Das allgemeine Wechselwirkungsschema aller Komponenten lautet wie folgt:
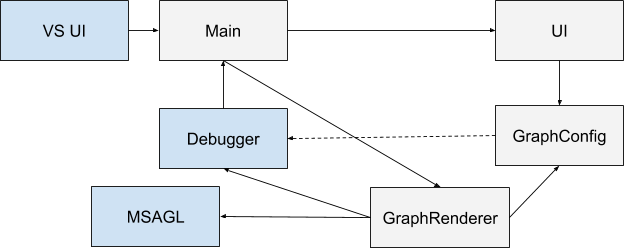
Blau zeigt die ursprünglich vorhandenen Komponenten, grau - die ich erstellt habe. Beim Start von Visual Studio wird die Erweiterung initialisiert (hier wird die Hauptkomponente als Hauptkomponente bezeichnet). Der Benutzer hat die Möglichkeit, die Konfiguration über die Schnittstelle festzulegen. Jedes Mal, wenn der Debugger-Kontext geändert wird, wird die Hauptkomponente benachrichtigt. Wenn die Konfiguration definiert und das zu debuggende Programm ausgeführt wird, wird GraphRenderer gestartet. Er erhält eine Konfigurationseingabe und erstellt mit Hilfe eines Debuggers ein Diagramm darauf, das dann in einem speziellen Fenster angezeigt wird.
Beispiele
Als Ergebnis habe ich ein Tool erstellt, mit dem Sie Diagrammalgorithmen visualisieren können und das kleine Änderungen im Code erfordert. Es wurde an acht verschiedenen Aufgaben getestet. Hier sind einige resultierende Bilder:
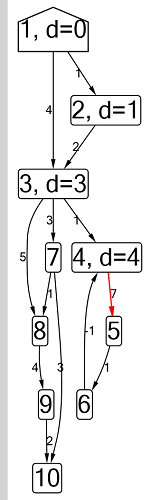 Ford-Bellman-Algorithmus : Der Scheitelpunkt, zu dem wir die kürzesten Wege zählen, wird durch ein Haus angezeigt. Der aktuell kürzeste Abstand für die Scheitelpunkte ist d. Rot gibt die Kante an, entlang der die Relaxation verläuft.
Ford-Bellman-Algorithmus : Der Scheitelpunkt, zu dem wir die kürzesten Wege zählen, wird durch ein Haus angezeigt. Der aktuell kürzeste Abstand für die Scheitelpunkte ist d. Rot gibt die Kante an, entlang der die Relaxation verläuft.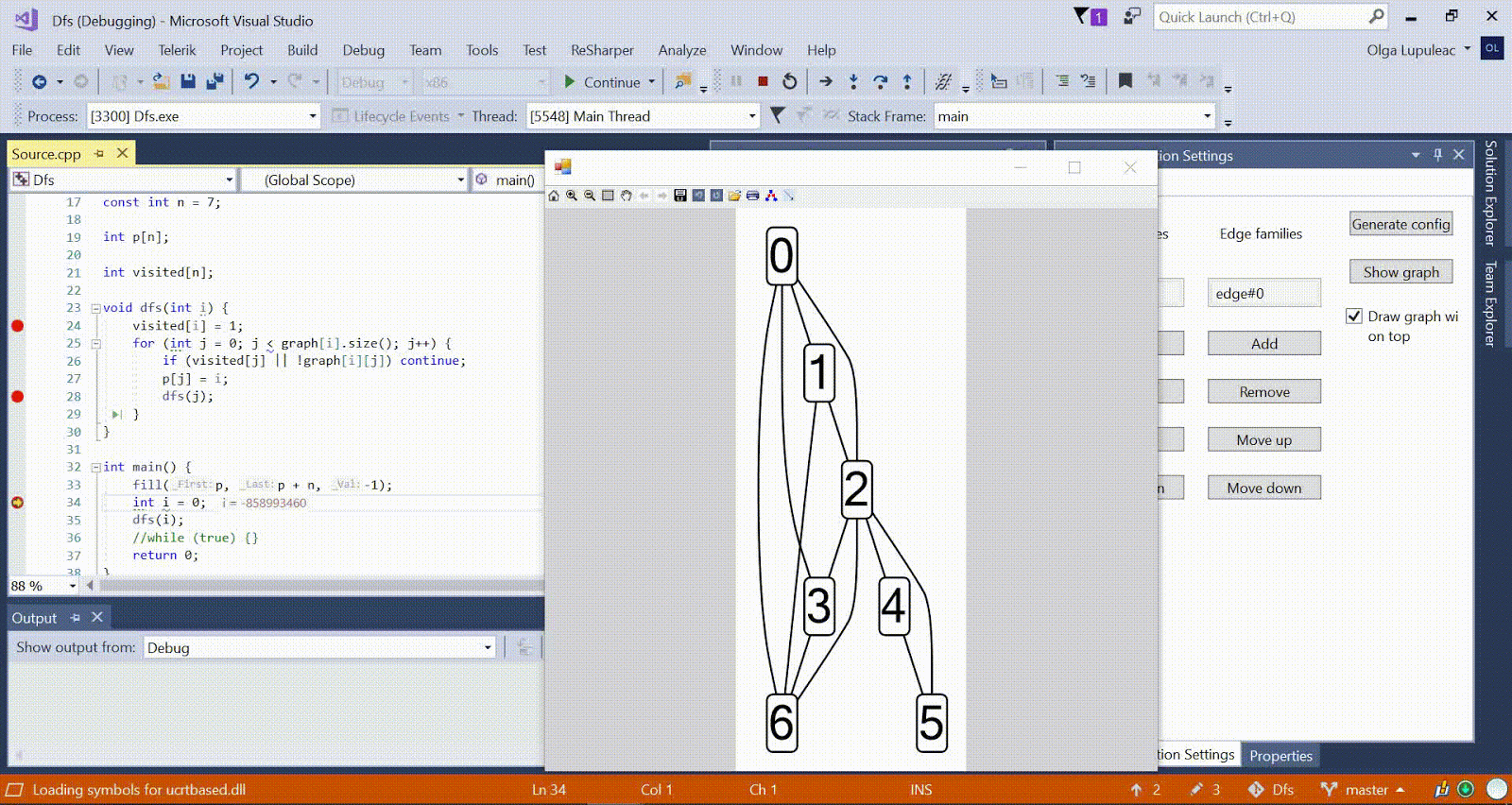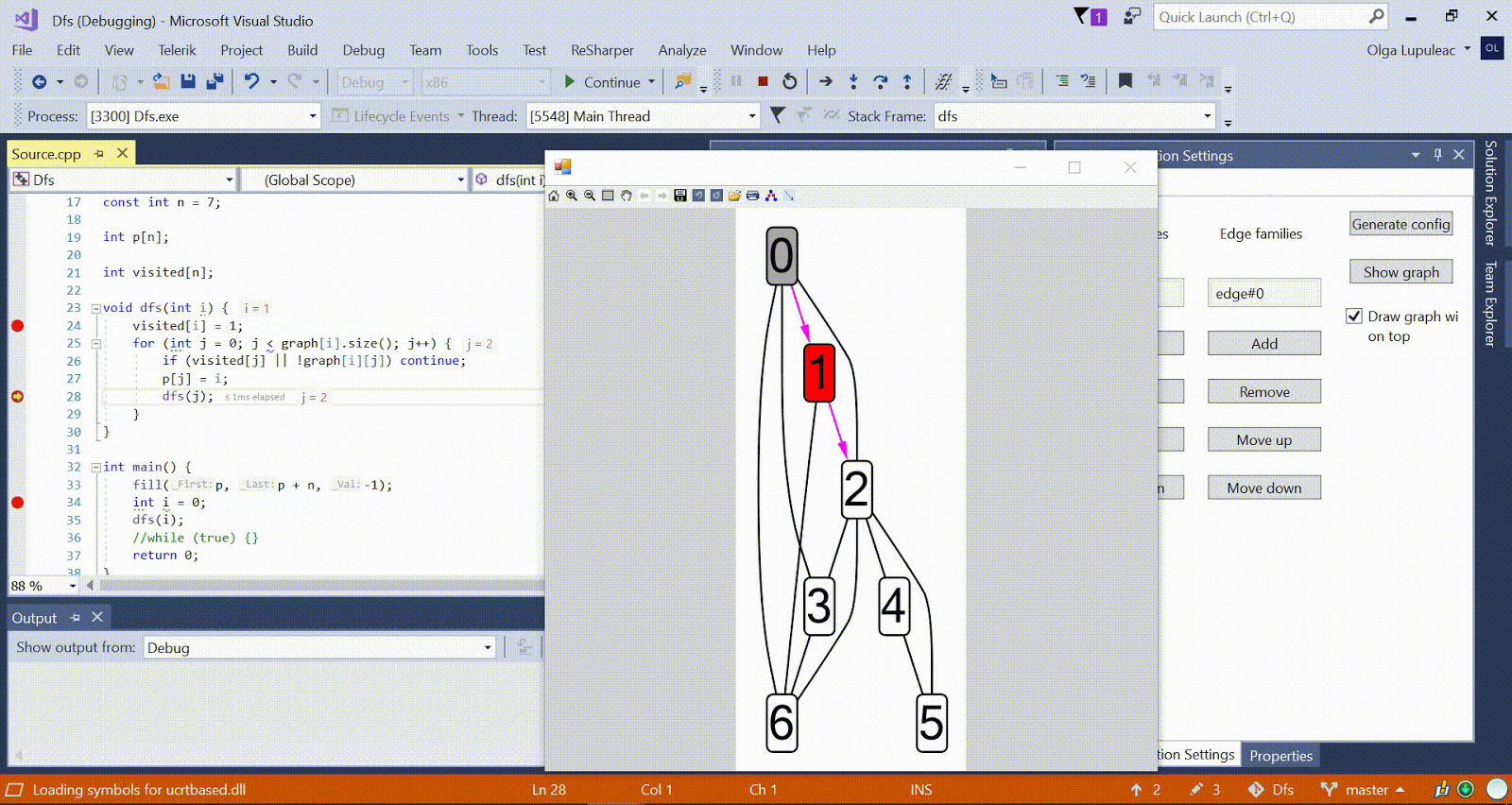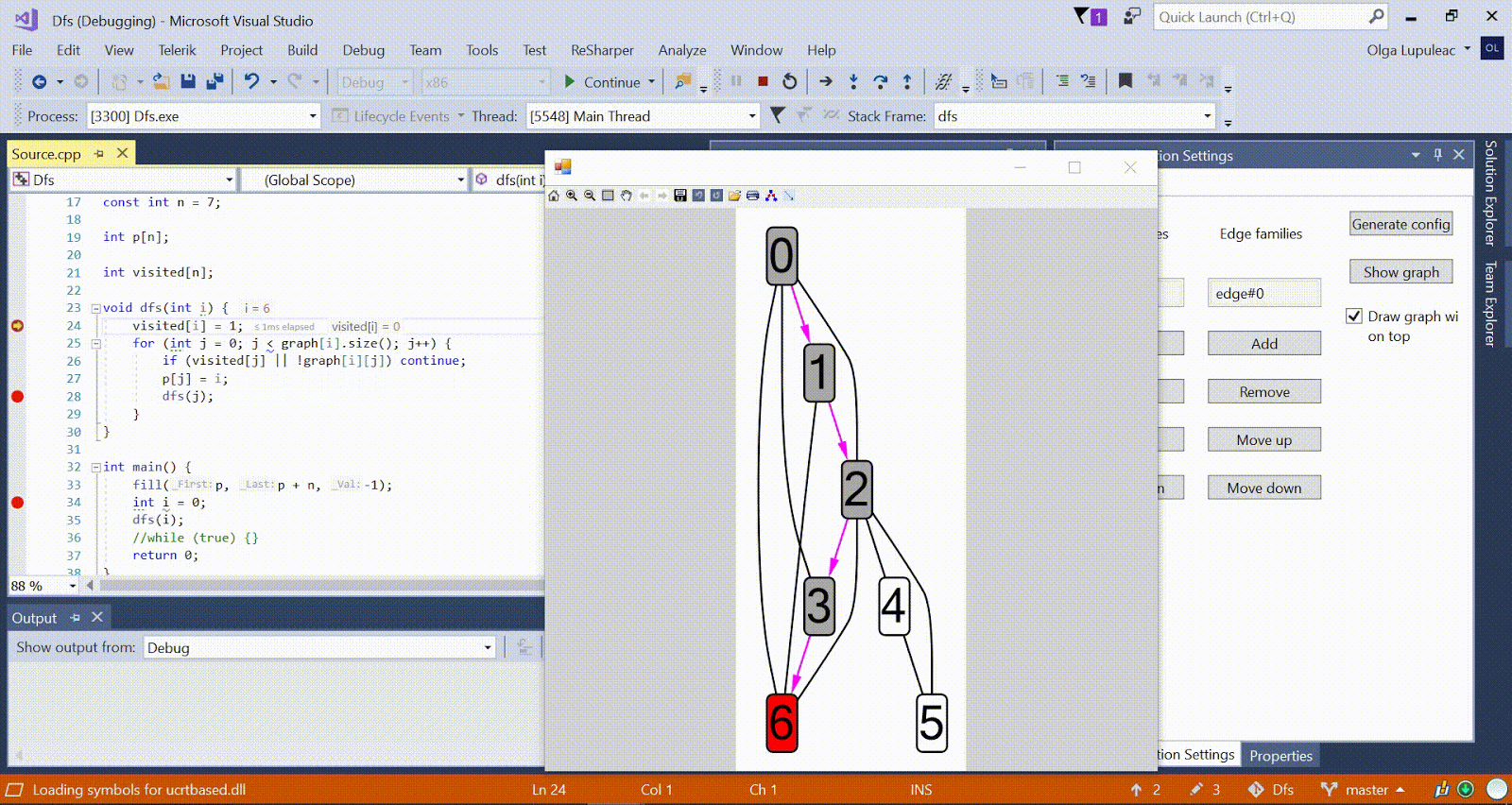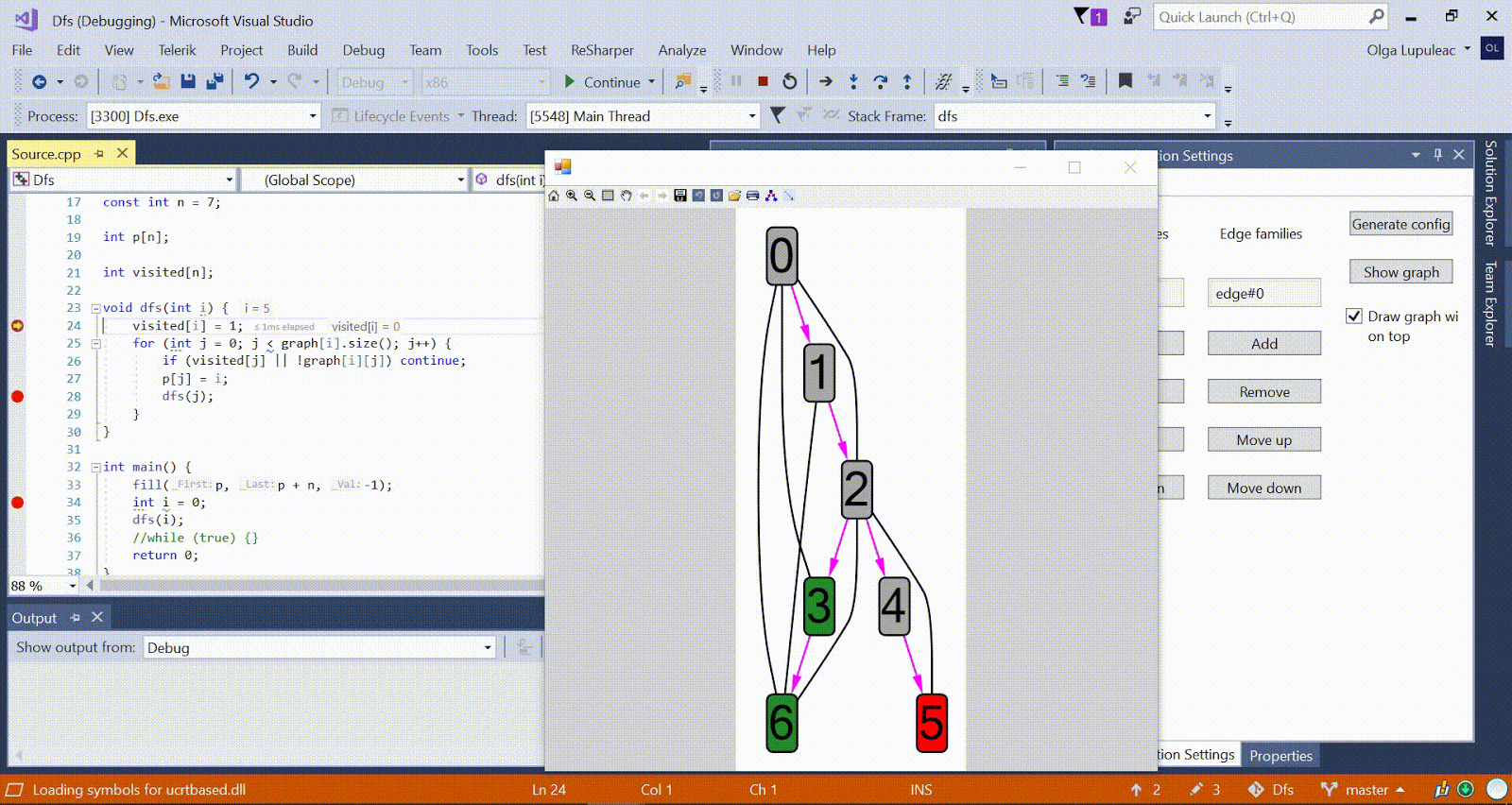 Animation mit DFS - Der aktuelle Scheitelpunkt wird rot angezeigt, die Scheitelpunkte im Stapel sind grau und die anderen besuchten Scheitelpunkte sind grün. Himbeerrippen geben die Richtung des Bypasses an.
Animation mit DFS - Der aktuelle Scheitelpunkt wird rot angezeigt, die Scheitelpunkte im Stapel sind grau und die anderen besuchten Scheitelpunkte sind grün. Himbeerrippen geben die Richtung des Bypasses an.Weitere Beispielalgorithmen finden Sie
hier.NIR-Schutz
Um die Forschungsarbeit zu schützen, müssen die Studierenden innerhalb von sieben Minuten ein Semester lang über ihre Arbeit berichten. Unabhängig davon, ob das Thema im Rahmen der Präsentation der Forschungsarbeit vorgeschlagen wurde oder der Student es selbst gefunden hat, müssen Sie in der Lage sein zu antworten, um zu begründen, warum das Thema des Projekts unter die zu Beginn beschriebenen Anforderungen fällt. In der Regel ist ein Bericht wie folgt aufgebaut: Zuerst gibt es Motivation, dann eine Überprüfung der Analoga, es wird gesagt, warum sie nicht zu uns passen, dann werden Ziele und Vorgaben formuliert, und dann wird jede der Aufgaben beschrieben, wie sie gelöst wurden. Am Ende gibt es eine Folie mit den Ergebnissen, die erneut besagt, dass das Ziel erreicht wurde und alle Aufgaben gelöst sind.
Da ich mich bereits in der Anfangsphase für die Motivation und Überprüfung von Analoga entschieden hatte, musste ich nur alle Informationen zusammen sammeln und auf sieben Minuten komprimieren. Am Ende gelang es mir, die Verteidigung verlief reibungslos, ich erhielt die maximale Punktzahl für die Forschung.
Referenzen