In großen Cloud-Systemen ist das Problem des automatischen Ausgleichs oder des Ausgleichs der Belastung der Computerressourcen besonders akut. Tionics hat sich ebenfalls um dieses Problem gekümmert (Entwickler und Betreiber von Cloud-Diensten, wir sind Teil der Rostelecom-Unternehmensgruppe).
Und da unsere Hauptentwicklungsplattform Openstack ist und wir, wie alle Menschen, faul sind, wurde beschlossen, eine Art fertiges Modul aufzunehmen, das bereits Teil der Plattform ist. Unsere Wahl fiel auf Watcher, das wir für unsere Bedürfnisse verwendeten.

Lassen Sie uns zunächst Begriffe und Definitionen behandeln.
Begriffe und Definitionen
Ein Ziel ist ein vom Menschen lesbares, beobachtbares und messbares Endergebnis, das erreicht werden muss. Um jedes Ziel zu erreichen, gibt es eine oder mehrere Strategien. Eine Strategie ist eine Implementierung eines Algorithmus, der eine Lösung für einen bestimmten Zweck finden kann.
Eine Aktion ist eine elementare Aufgabe, die den aktuellen Status einer verwalteten Zielressource eines OpenStack-Clusters ändert, z. B.: Migrieren einer virtuellen Maschine (Migration), Ändern des Energiezustands eines Knotens (change_node_power_state), Ändern des Status eines Nova-Dienstes (change_nova_service_state), Ändern einer Version (Größe ändern) , Registrierung von NOP-Nachrichten (nop), Fehlen von Aktionen während einer bestimmten Zeitspanne - Pause (Ruhezustand), Datenträgerübertragung (volume_migrate).
Aktionsplan (Aktionsplan) - Ein bestimmter Strom von Aktionen, die in einer bestimmten Reihenfolge ausgeführt werden, um ein bestimmtes Ziel zu erreichen. Der Aktionsplan enthält auch die geschätzte globale Leistung mit einer Reihe von Leistungsindikatoren. Der Aktionsplan wird von Watcher während eines erfolgreichen Audits erstellt, wodurch die verwendete Strategie eine Lösung zur Erreichung des Ziels findet. Ein Aktionsplan besteht aus einer Liste aufeinanderfolgender Aktionen.
Audit ist eine Anforderung zur Clusteroptimierung. Die Optimierung wird durchgeführt, um ein Ziel in einem bestimmten Cluster zu erreichen. Für jedes erfolgreiche Audit generiert Watcher einen Aktionsplan.
Der Überwachungsbereich ist eine Reihe von Ressourcen, innerhalb derer eine Prüfung durchgeführt wird (Verfügbarkeitszone (n), Knotenaggregatoren, einzelne Rechenknoten oder Speicherknoten usw.). In jeder Vorlage ist ein Überwachungsbereich definiert. Wenn der Überwachungsbereich nicht angegeben ist, wird der gesamte Cluster überwacht.
Überwachungsvorlage - Eine gespeicherte Reihe von Einstellungen zum Starten einer Prüfung. Vorlagen werden benötigt, um Audits mit denselben Einstellungen mehrmals auszuführen. Die Vorlage muss unbedingt den Zweck des Audits enthalten. Wenn keine Strategien angegeben sind, wird die am besten geeignete der vorhandenen Strategien ausgewählt.
Ein Cluster besteht aus einer Reihe physischer Maschinen, die Computer-, Speicher- und Netzwerkressourcen bereitstellen und von demselben OpenStack-Steuerknoten verwaltet werden.
Das Cluster Data Model (CDM) ist eine logische Darstellung des aktuellen Status und der Topologie von Cluster-verwalteten Ressourcen.
Effizienzindikator (Wirksamkeitsindikator) - Ein Indikator, der angibt, wie die mit dieser Strategie erstellte Lösung implementiert wird. Leistungsindikatoren sind spezifisch für ein bestimmtes Ziel und werden üblicherweise verwendet, um die globale Wirksamkeit eines endgültigen Aktionsplans zu berechnen.
Die Wirksamkeitsspezifikation besteht aus einer Reihe spezifischer Merkmale, die mit jedem Ziel verbunden sind und verschiedene Leistungsindikatoren definieren, die die Strategie, die das Erreichen des entsprechenden Ziels sicherstellt, in ihrer Entscheidung enthalten sollte. In der Tat wird jede von der Strategie vorgeschlagene Lösung vor der Berechnung ihrer globalen Wirksamkeit auf Übereinstimmung mit der Spezifikation überprüft.
Eine „Scoring Engine“ ist eine ausführbare Datei, die genau definierte Eingaben und Definitionen enthält und eine rein mathematische Aufgabe ausführt. Somit hängt die Berechnung nicht von der Umgebung ab, in der sie durchgeführt wird - sie liefert überall das gleiche Ergebnis.
Watcher Planner ist Teil der Watcher-Entscheidungs-Engine. Dieses Modul akzeptiert die von der Strategie generierten Aktionen und erstellt einen Workflowplan, der definiert, wie diese verschiedenen Aktionen rechtzeitig geplant werden und welche Voraussetzungen für jede Aktion erforderlich sind.
Beobachterziele und -strategien
Dummy-Ziel - ein Reserveziel, das zu Testzwecken verwendet wird.
Verwandte Strategien: Dummy-Strategie, Dummy-Strategie mit Beispiel-Scoring-Engines und Dummy-Strategie mit Größenänderung. Die Dummy-Strategie ist eine Dummy-Strategie, die für Integrationstests über Tempest verwendet wird. Diese Strategie bietet keine nützliche Optimierung, sondern dient ausschließlich der Verwendung von Tempest-Tests.
Dummy-Strategie mit Beispiel-Scoring-Engines - Die Strategie ähnelt der vorherigen und unterscheidet sich nur in der Verwendung des Beispiels „Evaluierungs-Engine“, das Berechnungen mit Methoden des maschinellen Lernens durchführt.
Dummy-Strategie mit Größenänderung - Die Strategie ähnelt der vorherigen, unterscheidet sich jedoch nur in der Verwendung der Änderung des Geschmacks (Migration und Größenänderung).
Wird in der Produktion nicht verwendet.
Energie sparen - Energieverbrauch minimieren. Strategie für dieses Ziel Die Energiesparstrategie in Verbindung mit der VM Workload Consolidation Strategy (Server Consolidation) kann DPM-Funktionen (Dynamic Power Management) ausführen, die Energie sparen, indem Workloads auch in Zeiten geringer Ressourcenlast dynamisch konsolidiert werden: Virtuelle Maschinen werden auf weniger Knoten übertragen und unnötige Knoten werden getrennt. Nach der Konsolidierung bietet die Strategie die Entscheidung, die Knoten gemäß den angegebenen Parametern ein- und auszuschalten: "min_free_hosts_num" - die Anzahl der freien eingeschlossenen Knoten, die auf das Laden warten, und "free_used_percent" - der Prozentsatz der freien eingeschlossenen Knoten zur Anzahl der von Maschinen belegten Knoten. Damit die Strategie
funktioniert, muss
Ironic aktiviert und konfiguriert sein, damit die Knoten ein- und ausgeschaltet werden können.Strategieoptionen
Es müssen mindestens zwei Knoten in der Cloud vorhanden sein. Die verwendete Methode ändert den Energiezustand des Knotens (change_node_power_state).
Die Strategie erfordert keine Erfassung von Metriken.Serverkonsolidierung - Minimieren Sie die Anzahl der Rechenknoten (Konsolidierung). Es gibt zwei Strategien: Grundlegende Offline-Serverkonsolidierung und VM Workload-Konsolidierungsstrategie.
Die grundlegende Offline-Serverkonsolidierungsstrategie minimiert die Gesamtzahl der verwendeten Server und die Anzahl der Migrationen.
Die Grundstrategie erfordert die folgenden Metriken:
Strategieparameter: Migrationsversuche - Die Anzahl der Kombinationen für die Suche nach potenziellen Kandidaten für das Herunterfahren (Standard, 0, keine Einschränkungen), Zeitraum - Zeitintervall in Sekunden, um eine statische Aggregation aus der metrischen Datenquelle zu erhalten (standardmäßig 700).
Verwendete Methoden: Migration, Änderung des Nova-Service-Status (change_nova_service_state).
Die VM Workload Consolidation Strategy basiert auf dem heuristischen First-Fit-Algorithmus, der sich auf die gemessene CPU-Auslastung konzentriert und versucht, Knoten mit zu hoher oder zu geringer Auslastung unter Berücksichtigung von Einschränkungen der Ressourcenkapazität zu minimieren. Diese Strategie bietet eine Lösung, die zu einer effizienteren Nutzung der Clusterressourcen in den folgenden vier Schritten führt:
- Entladephase - Verarbeitung überlasteter Ressourcen;
- Konsolidierungsphase - Verarbeitung nicht ausgelasteter Ressourcen;
- Lösungsoptimierung - Reduzierung der Anzahl der Migrationen;
- Nicht verwendete Rechenknoten deaktivieren.
Die Strategie erfordert die folgenden Metriken:
Die folgenden Metriken sind optional, verbessern jedoch die Strategiegenauigkeit, falls verfügbar:
Strategieparameter: Zeitraum - Zeitintervall in Sekunden, um eine statische Aggregation aus der metrischen Datenquelle zu erhalten (standardmäßig 3600).
Verwendet die gleichen Methoden wie die vorherige Strategie. Weitere Details
hier .
Workload Balancing - Ausgleich der Arbeitslast zwischen Rechenknoten. Das Ziel hat drei Strategien: Migrationsstrategie für das Workload-Gleichgewicht, Stabilisierung des Workloads, Strategie für das Gleichgewicht der Speicherkapazität.
Die Workload Balance-Migrationsstrategie startet Migrationen virtueller Maschinen basierend auf der Arbeitslast virtueller Hostmaschinen. Die Entscheidung zur Übertragung wird immer dann getroffen, wenn der Prozentsatz der CPU- oder RAM-Auslastung des Knotens den angegebenen Schwellenwert überschreitet. In diesem Fall sollte die verschobene virtuelle Maschine den Knoten näher an die durchschnittliche Arbeitslast aller Knoten bringen.
Anforderungen
- Verwendung von physischen Prozessoren;
- Mindestens zwei physische Rechenknoten;
- Die installierte und konfigurierte Ceilometer-Komponente ist die Ceilometer-Agent-Berechnung, die auf jedem Rechenknoten und der Ceilometer-API ausgeführt wird, und erfasst die folgenden Metriken:
Strategieoptionen:
Die verwendete Methode ist die Migration.
Workload-Stabilisierung - eine Strategie zur Stabilisierung der Workload mithilfe von Live-Migration. Die Strategie basiert auf dem Standardabweichungsalgorithmus und ermittelt, ob im Cluster eine Überlastung vorliegt, und löst darauf eine Maschinenmigration aus, um den Cluster zu stabilisieren.
Anforderungen
- Verwendung von physischen Prozessoren;
- Mindestens zwei physische Rechenknoten;
- Die installierte und konfigurierte Ceilometer-Komponente ist die Ceilometer-Agent-Berechnung, die auf jedem Rechenknoten und der Ceilometer-API ausgeführt wird, und erfasst die folgenden Metriken:
Storage Capacity Balance Strategy (eine Strategie, die seit Queens implementiert wurde) - Die Strategie überträgt Festplatten abhängig von der Auslastung der Cinder-Pools. Die Übertragungsentscheidung wird immer dann getroffen, wenn die Poolauslastung den angegebenen Schwellenwert überschreitet. Eine Roaming-Festplatte sollte den Pool näher an die durchschnittliche Auslastung aller Cinder-Pools bringen.
Anforderungen und Einschränkungen
- Mindestens zwei Cinder-Pools;
- Möglichkeit zum Migrieren von Festplatten.
- Cluster-Datenmodellkollektor.
Strategieoptionen:
Die verwendete Methode ist die Festplattenmigration (volume_migrate).
Lauter Nachbar - Identifizieren und migrieren Sie einen „lauten Nachbarn“ - eine virtuelle Maschine mit niedriger Priorität, die die Leistung einer virtuellen Maschine mit hoher Priorität aus IPC-Sicht beeinträchtigt und den Cache der letzten Ebene überbeansprucht. Eigene Strategie: Noisy Neighbor (der verwendete Strategieparameter ist cache_threshold (Standardwert ist 35), die Migration beginnt, wenn die Leistung auf den angegebenen Wert abfällt. Damit die Strategie funktioniert, die enthaltenen
LLC-Metriken (Last Level Cache), der neueste Intel-Server mit CMT-Unterstützung und auch Sammlung der folgenden Metriken:
Clusterdatenmodell (Standard): Nova Cluster Data Model Collector. Die angewandte Methode ist die Migration.
Die Arbeit für diesen Zweck über Dashboard ist in Queens nicht vollständig implementiert.
Thermische Optimierung - Temperaturbedingungen optimieren. Die Auslasstemperatur (Abluft) ist eines der wichtigsten thermischen Telemetriesysteme zur Messung des Zustands der Wärme- / Arbeitslast des Servers. Zu diesem Zweck gibt es eine Strategie - die auf der Auslasstemperatur basierende Strategie, mit der Entscheidungen über die Übertragung von Workloads an Knoten mit günstigen Temperaturbedingungen (niedrigste Temperatur am Ausgang) getroffen werden, wenn die Temperatur am Ausgang der ursprünglichen Hosts einen benutzerdefinierten Schwellenwert erreicht.
Damit die Strategie funktioniert, benötigen Sie einen Server mit installiertem und konfiguriertem Intel Power Node Manager
3.0 oder höher sowie die Sammlung der folgenden Metriken:
Strategieoptionen:
Die verwendete Methode ist die Migration.
Luftstromoptimierung - Optimieren Sie den Lüftungsmodus. Eigene Strategie - Einheitlicher Luftstrom durch Live-Migration. Die Strategie startet die Migration der virtuellen Maschine immer dann, wenn der Luftstrom vom Serverlüfter den angegebenen Schwellenwert überschreitet.
Um zu arbeiten, erfordert die Strategie:
- Hardware: Rechenknoten <mit NodeManager 3.0-Unterstützung;
- Mindestens zwei Rechenknoten;
- Die auf jedem Rechenknoten installierten und konfigurierten Ceilometer-Agent-Compute- und Ceilometer-API-Komponenten können erfolgreich Metriken wie Luftstrom, Systemleistung und Einlasstemperatur melden:
Damit die Strategie funktioniert, benötigen Sie einen Server mit Intel Power Node Manager 3.0 oder höher, der installiert und konfiguriert ist.
Einschränkungen: Das Konzept ist nicht für die Produktion vorgesehen.
Es wird vorgeschlagen, diesen Algorithmus für kontinuierliche Audits zu verwenden, da nur eine virtuelle Maschine pro Iteration migriert werden soll.
Live-Migrationen sind möglich.
Strategieoptionen:
Die verwendete Methode ist die Migration.
Hardware-Wartung - Hardware-Wartung. Eine mit diesem Ziel verbundene Strategie ist die Zonenmigration. Die Strategie ist ein Tool für eine effiziente automatische und minimale Migration von virtuellen Maschinen und Festplatten im Falle einer Hardwarewartung. Die Strategie erstellt einen Aktionsplan in Übereinstimmung mit den Gewichten: Eine Reihe von Aktionen mit mehr Gewicht wird vor den anderen geplant. Es gibt zwei Konfigurationsoptionen: Aktionsgewichte (Aktionsgewichte) und Parallelisierung.
Einschränkungen: Es ist erforderlich, die Gewichtung der Aktionen und die Parallelisierung anzupassen.
Strategieoptionen:
Elemente eines Arrays von Rechenknoten:
Elemente eines Arrays von Speicherknoten:
Elemente von Prioritätsobjekten:
Verwendete Methoden - Migration von virtuellen Maschinen, Migration von Festplatten.
Nicht klassifiziert ist ein unterstützendes Ziel, das zur Entwicklung einer Strategie verwendet wird. Es enthält keine Spezifikationen und kann verwendet werden, wenn die Strategie noch nicht mit einem vorhandenen Ziel verbunden ist. Dieses Ziel kann auch als Übergangsphase genutzt werden. Eine verwandte Strategie ist Actuator.
Erstellen Sie ein neues Ziel
Die Watcher Decision Engine verfügt über eine Plug-In-Schnittstelle für externe Ziele, über die Sie ein externes Ziel integrieren können, das mithilfe der Strategie erreicht werden kann.
Bevor Sie ein neues Ziel erstellen, sollten Sie sicherstellen, dass keines der vorhandenen Ziele Ihren Anforderungen entspricht.
Erstellen Sie ein neues Plugin
Um ein neues Ziel zu erstellen, müssen Sie: die
Zielklasse erweitern, die Klassenmethode
get_name () implementieren, um eine eindeutige Kennung für das neue Ziel zurückzugeben, das Sie erstellen möchten. Diese eindeutige Kennung muss mit dem Namen des Einstiegspunkts übereinstimmen, den Sie später deklarieren.
Als Nächstes müssen Sie die Klassenmethode
get_display_name () implementieren, um den übersetzten Anzeigenamen des Ziels zurückzugeben, das Sie erstellen möchten (verwenden Sie die Variable nicht, um die übersetzte Zeichenfolge zurückzugeben, damit sie vom Übersetzungstool automatisch erfasst werden kann.).
Implementieren Sie die Klassenmethode
get_translatable_display_name () , um den Übersetzungsschlüssel (eigentlich den englischen Anzeigenamen) Ihres neuen Ziels zurückzugeben. Der Rückgabewert muss mit der in get_display_name () übersetzten Zeichenfolge übereinstimmen.
Implementieren
Sie die Methode
get_efficacy_specification () , um die Leistungsspezifikation für Ihren Zweck zurückzugeben. Die Methode get_efficacy_specification () gibt die von Watcher bereitgestellte Instanz Unclassified () zurück. Diese Leistungsspezifikation ist nützlich bei der Entwicklung Ihres Ziels, da sie der leeren Spezifikation entspricht.
→
Weitere Details hierArchitecture Watcher (mehr Infos
hier ).
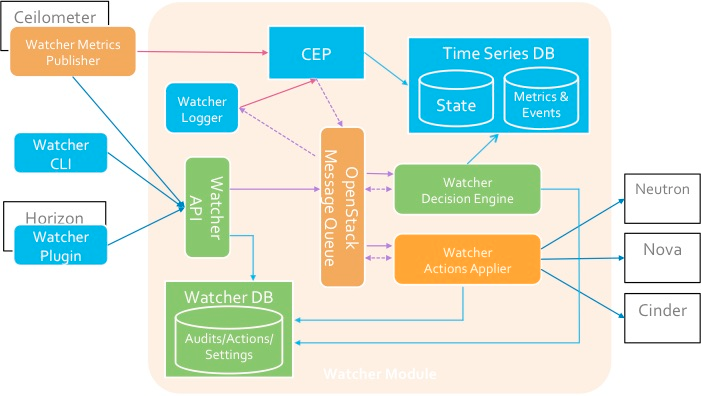
Komponenten
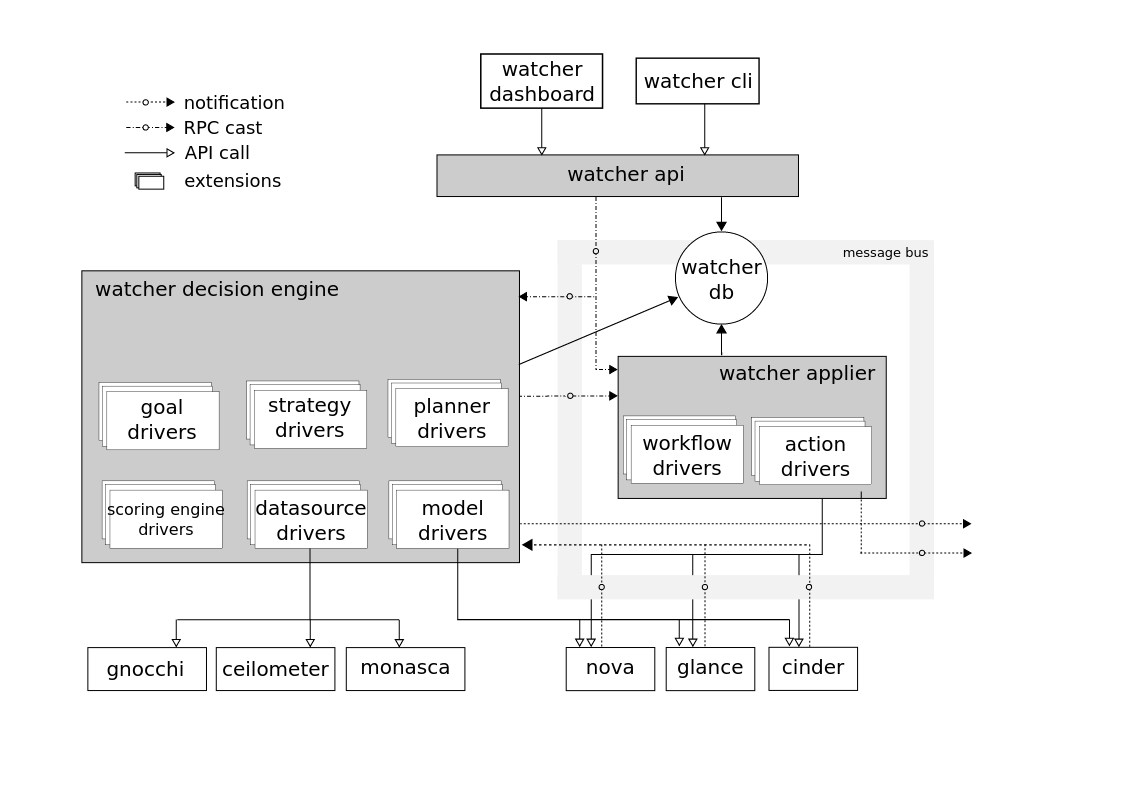 Watcher-API
Watcher-API - Eine Komponente, die die von Watcher bereitgestellte REST-API implementiert. Interaktionsmechanismen: CLI, Horizon-Plugin, Python SDK.
Watcher DB - Watcher-Datenbank.
Watcher Applier - eine Komponente, die die Implementierung des von der Watcher Decision Engine erstellten Aktionsplans implementiert.
Die Watcher Decision Engine ist eine Komponente, die für die Berechnung einer Reihe potenzieller Optimierungsmaßnahmen zur Erreichung eines Prüfungsziels verantwortlich ist. Wenn keine Strategie angegeben ist, wählt die Komponente unabhängig die am besten geeignete aus.Watcher Metrics Publisher ist eine Komponente, die einige Metriken oder Ereignisse sammelt, berechnet und am CEP-Endpunkt veröffentlicht. Funktionsfunktionen können auch vom Ceilometer-Verlag bereitgestellt werden.CEP-Engine (Complex Event Processing)- Engine für die komplexe Ereignisverarbeitung. Aus Leistungsgründen können mehrere Instanzen der CEP-Engine gleichzeitig ausgeführt werden, von denen jede einen bestimmten Typ von Metrik / Ereignis behandelt. Im Watcher-System startet CEP zwei Arten von Aktionen: - Schreiben Sie die entsprechenden Ereignisse / Metriken in die Zeitreihendatenbank. - relevante Ereignisse an die Watcher Decision Engine-Komponente senden, wenn dieses Ereignis das Ergebnis der aktuellen Optimierungsstrategie beeinflussen kann, da der Openstack-Cluster kein statisches System ist.Das Zusammenspiel der Komponenten erfolgt nach dem AMQP-Protokoll.→ Watcher konfigurierenSchema der Interaktion mit Watcher

Watcher-Testergebnisse
- Optimization — Action plans 500 ( Queens, ), , , .
- Action details , ( Queens, ).
- Dummy () , .
- Unclassified , .
- Workload Balancing ( Storage Capacity balance) , . .
- Workload Balancing ( Workload Balance Migration Strategy) , .
- Workload Balancing ( Workload Stabilization Strategy) .
- Noisy Neighbor , .
- Hardware maintenance , ( , ).
- nova.conf ( default compute_monitors = cpu.virt_driver) .
- Server Consolidation ( Basic) .
- Server Consolidation ( VM workload consolidation) . . , , .
- Watcher ( — Optimization, - ):
[watcher_strategies.basic]
datasource = ceilometer, gnocchi - Saving Energy . , - Ironic, baremetal service.
- Thermal Optimization . , Server Consolidation ( VM workload consolidation) ( )
- Audits für die Luftstromoptimierung schlagen fehl.
Die folgenden Audit-Abschlussfehler treten ebenfalls auf. Traceback in Decision-Engine.log-Protokollen (Clusterstatus ist nicht definiert).→ Diskussion des Fehlers hierFazit
Das Ergebnis unserer zweimonatigen Forschung war die eindeutige Schlussfolgerung, dass wir eng an der Fertigstellung der Tools für die Openstack-Plattform arbeiten müssen, um ein vollwertiges, funktionierendes Lastausgleichssystem zu erhalten.Watcher hat sich als seriöses und sich schnell entwickelndes Produkt mit enormem Potenzial erwiesen, für dessen volle Nutzung eine Menge ernsthafter Arbeit erforderlich sein wird.Aber mehr dazu in den nächsten Artikeln des Zyklus.