Das Sammeln, Speichern, Konvertieren und Präsentieren von Daten sind die Hauptherausforderungen für Dateningenieure. Die Business Intelligence Badoo-Abteilung empfängt und verarbeitet täglich mehr als 20 Milliarden Ereignisse, die von Benutzergeräten oder 2 TB eingehender Daten gesendet werden.
Das Studium und die Interpretation all dieser Daten ist nicht immer eine triviale Aufgabe, manchmal wird es notwendig, über die Fähigkeiten vorgefertigter Datenbanken hinauszugehen. Und wenn Sie den Mut haben und sich für etwas Neues entschieden haben, sollten Sie sich zunächst mit den Funktionsprinzipien bestehender Lösungen vertraut machen.
Mit einem Wort, neugierige und aufgeschlossene Entwickler, dieser Artikel wird angesprochen. Darin finden Sie eine Beschreibung des traditionellen Modells der Abfrageausführung in relationalen Datenbanken am Beispiel der Demosprache PigletQL.
Inhalt
Hintergrund
Unsere Gruppe von Ingenieuren beschäftigt sich mit Backends und Schnittstellen und bietet Möglichkeiten zur Analyse und Recherche von Daten innerhalb des Unternehmens (wir expandieren übrigens). Unsere Standardtools sind eine verteilte Datenbank mit Dutzenden von Servern (Exasol) und ein Hadoop-Cluster für Hunderte von Computern (Hive und Presto).
Die meisten Abfragen an diese Datenbanken sind analytisch, dh sie betreffen Hunderttausende bis Milliarden von Datensätzen. Ihre Ausführung dauert Minuten, zehn Minuten oder sogar Stunden, abhängig von der verwendeten Lösung und der Komplexität der Anforderung. Bei manueller Arbeit des Benutzer-Analysten wird diese Zeit als akzeptabel angesehen, ist jedoch nicht für die interaktive Recherche über die Benutzeroberfläche geeignet.
Im Laufe der Zeit haben wir die gängigen analytischen Abfragen und Abfragen hervorgehoben, die in Bezug auf SQL schwer darzulegen sind, und kleine spezialisierte Datenbanken für sie entwickelt. Sie speichern eine Teilmenge von Daten in einem Format, das für einfache Komprimierungsalgorithmen (z. B. Streamvbyte) geeignet ist. Auf diese Weise können Sie Daten mehrere Tage lang auf einem einzelnen Computer speichern und Abfragen in Sekunden ausführen.
Die ersten Abfragesprachen für diese Daten und ihre Interpreter wurden ahnungslos implementiert, wir mussten sie ständig weiterentwickeln, und jedes Mal dauerte es unannehmbar lange.
Abfragesprachen waren nicht flexibel genug, obwohl es keine offensichtlichen Gründe gab, ihre Fähigkeiten einzuschränken. Infolgedessen haben wir uns an die Erfahrung der Entwickler von SQL-Interpreten gewandt, dank derer wir die aufgetretenen Probleme teilweise lösen konnten.
Im Folgenden werde ich über das häufigste Modell zur Ausführung von Abfragen in relationalen Datenbanken sprechen - Volcano. Der Quellcode des Interpreters des primitiven SQL-Dialekts PigletQL ist dem Artikel beigefügt , sodass sich alle Interessierten leicht mit den Details im Repository vertraut machen können.
SQL-Interpreter-Struktur
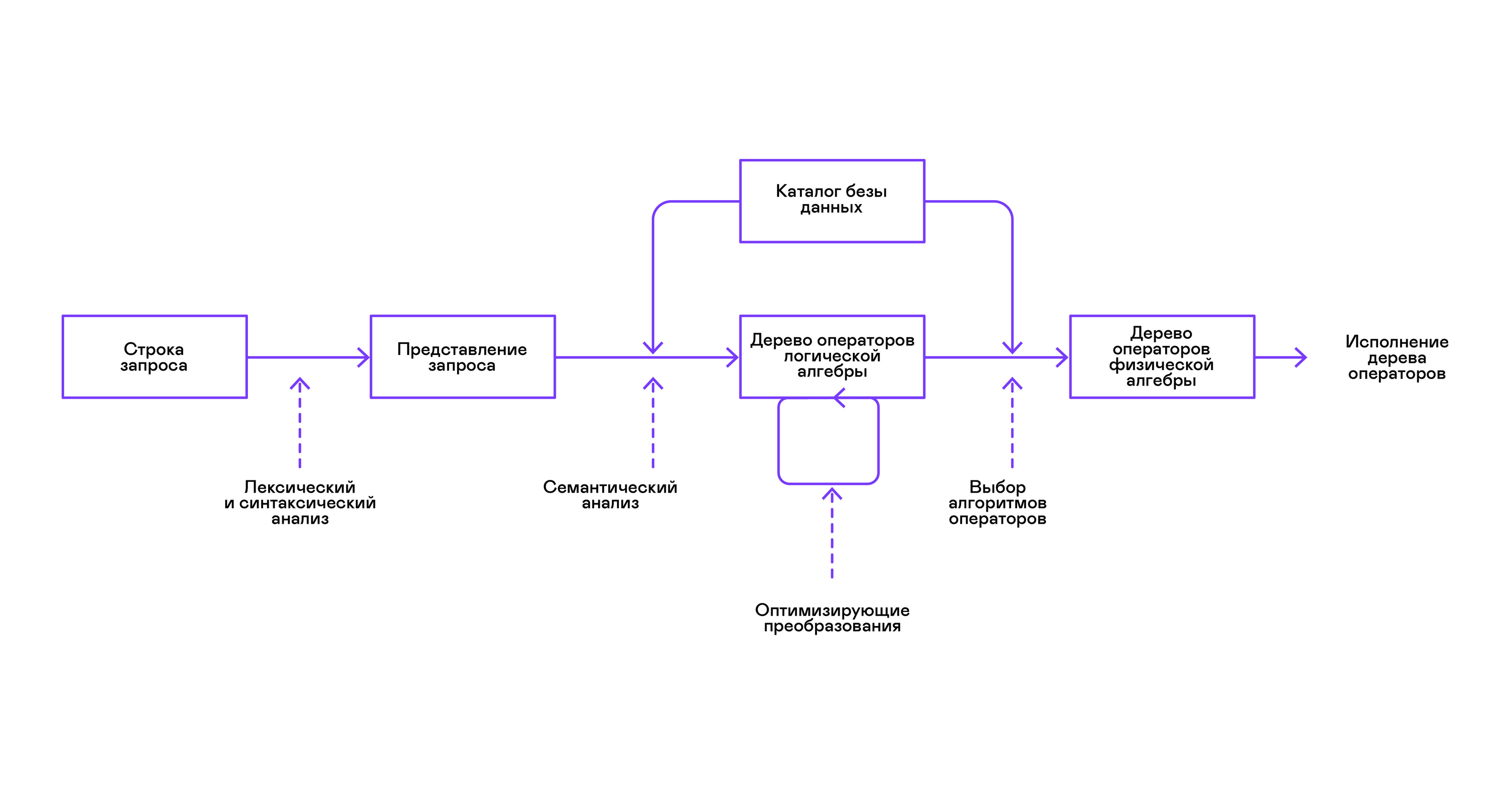
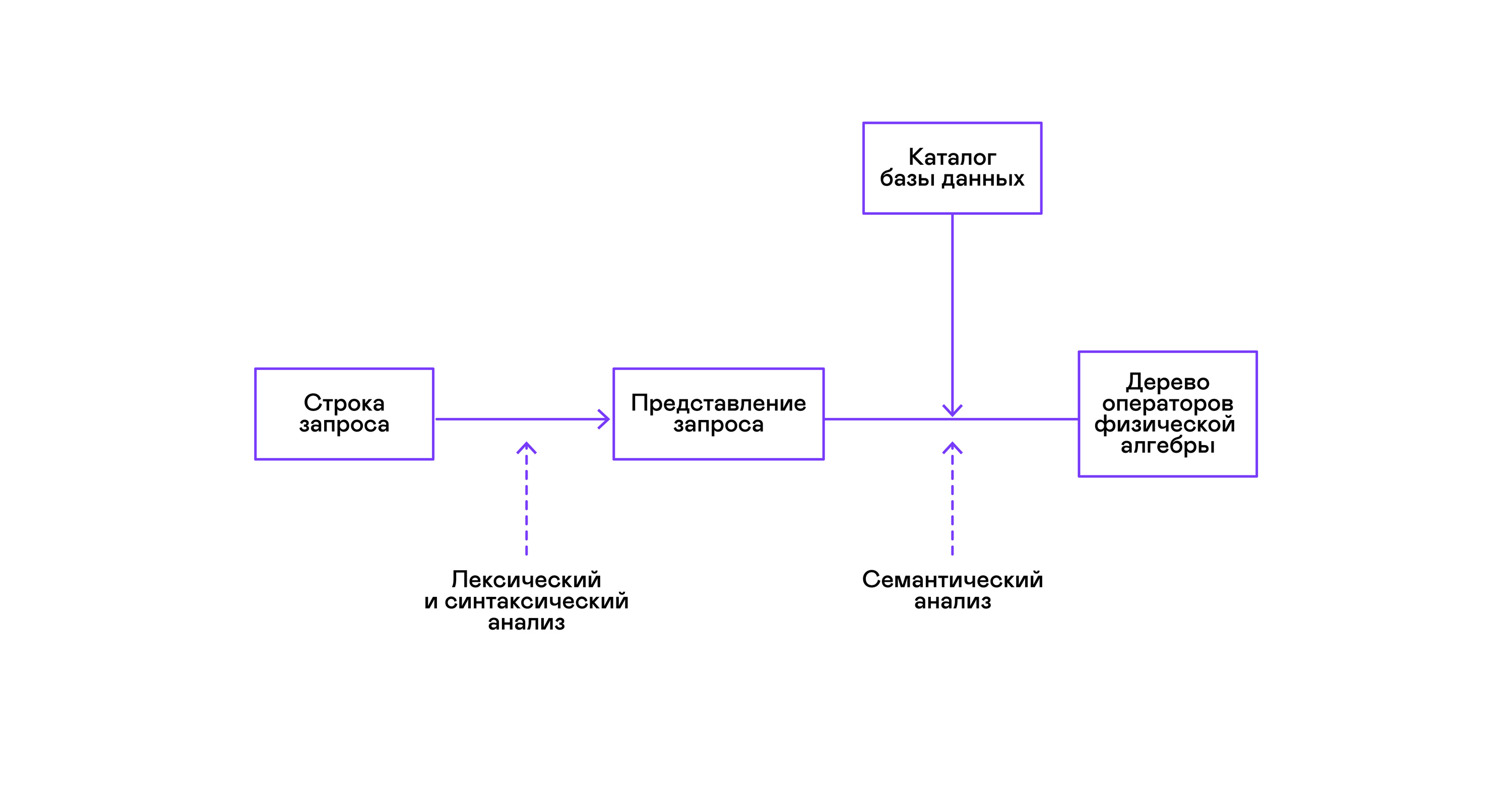
Die meisten gängigen Datenbanken bieten eine Schnittstelle zu Daten in Form einer deklarativen SQL-Abfragesprache. Eine Abfrage in Form einer Zeichenfolge wird vom Parser in eine Beschreibung der Abfrage konvertiert, ähnlich einem abstrakten Syntaxbaum. Es ist bereits in dieser Phase möglich, einfache Abfragen auszuführen. Zur Optimierung von Transformationen und der anschließenden Ausführung ist diese Darstellung jedoch unpraktisch. In den mir zu diesem Zweck bekannten Datenbanken werden Zwischendarstellungen eingeführt.
Die relationale Algebra wurde zum Modell für Zwischendarstellungen. Dies ist eine Sprache, in der die an den Daten durchgeführten Transformationen ( Operatoren ) explizit beschrieben werden: Auswählen einer Teilmenge der Daten gemäß einem Prädikat, Kombinieren von Daten aus verschiedenen Quellen usw. Darüber hinaus ist die relationale Algebra eine Algebra im mathematischen Sinne, dh eine große Anzahl von Äquivalenten Transformationen. Daher ist es zweckmäßig, Transformationen über eine Abfrage in Form eines Baums relationaler Algebraoperatoren zu optimieren.
Es gibt wichtige Unterschiede zwischen internen Darstellungen in Datenbanken und der ursprünglichen relationalen Algebra. Daher ist es korrekter, sie als logische Algebra zu bezeichnen .
Die Überprüfung der Gültigkeit einer Abfrage wird normalerweise beim Kompilieren der anfänglichen Darstellung der Abfrage in logische Algebraoperatoren durchgeführt und entspricht der Stufe der semantischen Analyse in herkömmlichen Compilern. Die Rolle der Symboltabelle in Datenbanken spielt das Datenbankverzeichnis , in dem Informationen zum Datenbankschema und zu den Metadaten gespeichert werden: Tabellen, Tabellenspalten, Indizes, Benutzerrechte usw.
Im Vergleich zu Allzweckdolmetschern weisen Datenbankdolmetscher eine weitere Besonderheit auf: Unterschiede im Datenvolumen und Metainformationen zu den Daten, an die Abfragen gestellt werden sollen. In Tabellen oder Beziehungen in Bezug auf die relationale Algebra kann es eine unterschiedliche Datenmenge geben, auf einigen Spalten (Beziehungsattributen) können Indizes erstellt werden usw. Das heißt, abhängig vom Datenbankschema und der Datenmenge in den Tabellen muss die Abfrage von verschiedenen Algorithmen ausgeführt werden und verwenden Sie sie in einer anderen Reihenfolge.
Um dieses Problem zu lösen, wird eine andere Zwischendarstellung eingeführt - die physikalische Algebra . Abhängig von der Verfügbarkeit von Indizes für die Spalten, der Datenmenge in den Tabellen und der Struktur des Baums der logischen Algebra werden verschiedene Formen des Baums der physikalischen Algebra angeboten, aus denen die beste Option ausgewählt wird. Dieser Baum wird der Datenbank als Abfrageplan angezeigt. In herkömmlichen Compilern entspricht diese Stufe bedingt den Stufen der Registerzuweisung, Planung und Befehlsauswahl.
Der letzte Schritt in der Arbeit des Interpreten ist direkt die Ausführung des Baums von Operatoren der physikalischen Algebra.
Vulkanmodell und Abfrageausführung
Physikalische Algebra-Bauminterpreter wurden immer in geschlossenen kommerziellen Datenbanken verwendet, aber die akademische Literatur bezieht sich normalerweise auf den experimentellen Optimierer Volcano, der Anfang der 90er Jahre entwickelt wurde.
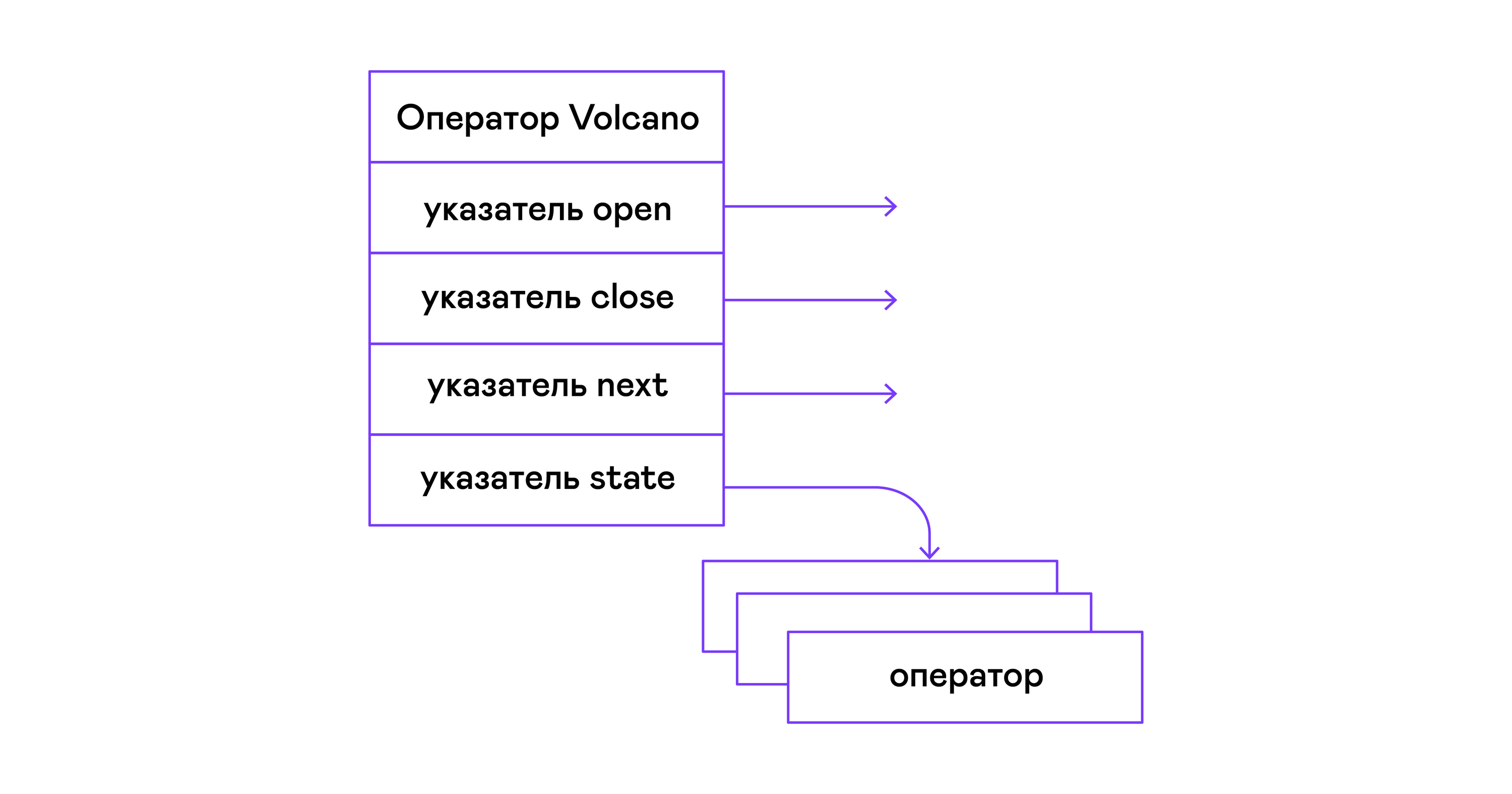
Im Volcano-Modell verwandelt sich jeder Operator eines Baums der physischen Algebra in eine Struktur mit drei Funktionen: Öffnen, Weiter, Schließen. Zusätzlich zu den Funktionen enthält der Bediener einen Betriebszustand - Zustand. Die Funktion open initiiert den Status der Anweisung, die nächste Funktion gibt entweder das nächste Tupel (englisches Tupel) zurück oder NULL. Wenn keine Tupel mehr vorhanden sind, beendet die Funktion close die Anweisung:
Operatoren können verschachtelt werden, um einen Baum von Operatoren der physikalischen Algebra zu bilden. Jeder Operator iteriert somit über die Tupel einer Beziehung, die entweder auf einem realen Medium vorhanden ist, oder über eine virtuelle Beziehung, die durch Aufzählen der Tupel verschachtelter Operatoren gebildet wird:
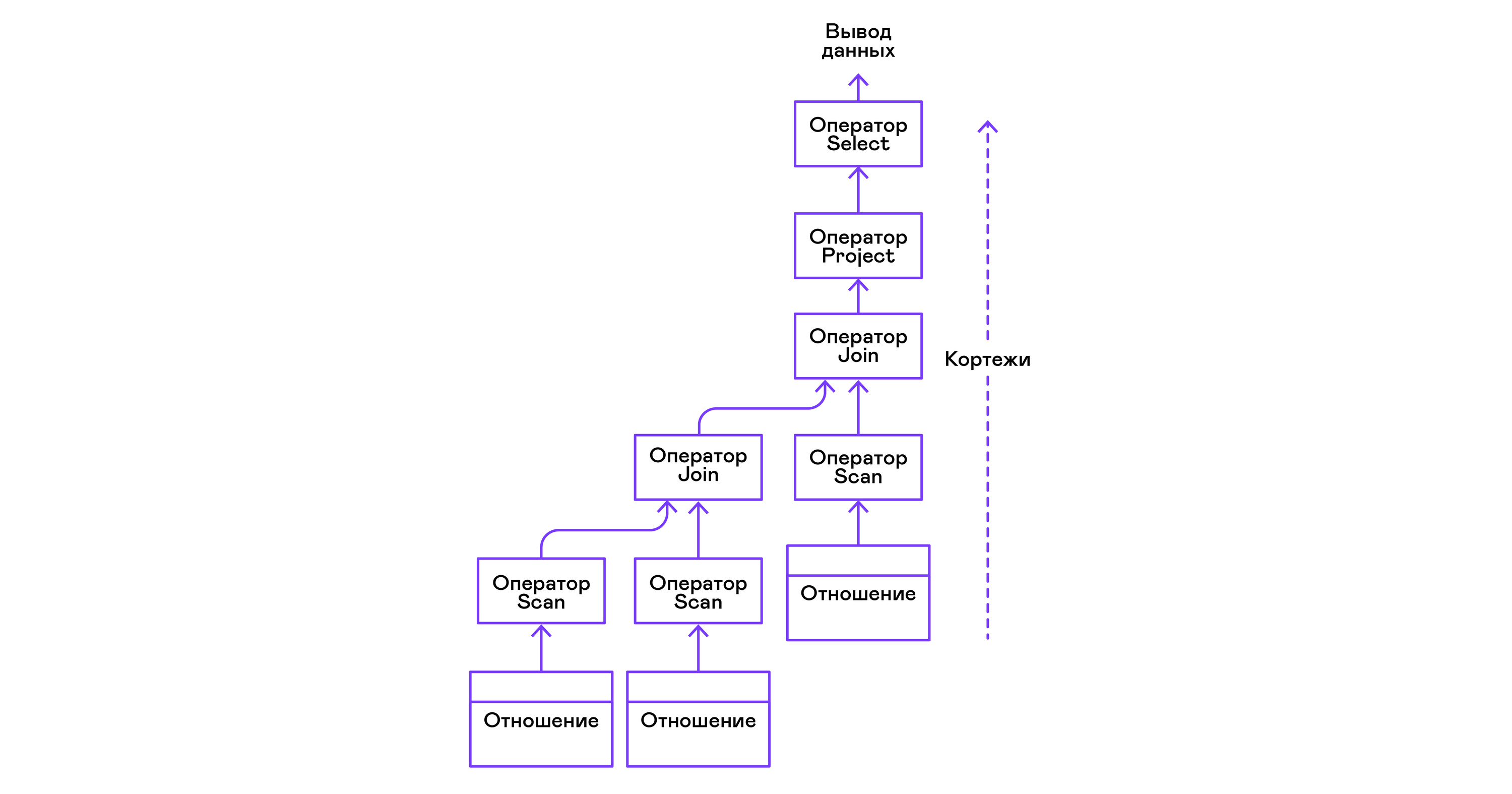
In Bezug auf moderne Hochsprachen ist der Baum solcher Operatoren eine Kaskade von Iteratoren.
Sogar industrielle Abfragedolmetscher in relationalem DBMS werden vom Volcano-Modell abgestoßen. Deshalb habe ich es als Grundlage für den PigletQL-Interpreter verwendet.
PigletQL
Um das Modell zu demonstrieren, habe ich den Interpreter der eingeschränkten Abfragesprache PigletQL entwickelt . Es ist in C geschrieben, unterstützt die Erstellung von Tabellen im SQL-Stil, ist jedoch auf einen einzigen Typ beschränkt - 32-Bit-Ganzzahlen. Alle Tabellen sind im Speicher. Das System arbeitet in einem einzelnen Thread und verfügt nicht über einen Transaktionsmechanismus.
In PigletQL gibt es keinen Optimierer, und SELECT-Abfragen werden direkt in den Operatorbaum der physischen Algebra kompiliert. Die verbleibenden Abfragen (CREATE TABLE und INSERT) funktionieren direkt in den primären internen Ansichten.
Beispiel für eine Benutzersitzung in PigletQL:
> ./pigletql > CREATE TABLE tab1 (col1,col2,col3); > INSERT INTO tab1 VALUES (1,2,3); > INSERT INTO tab1 VALUES (4,5,6); > SELECT col1,col2,col3 FROM tab1; col1 col2 col3 1 2 3 4 5 6 rows: 2 > SELECT col1 FROM tab1 ORDER BY col1 DESC; col1 4 1 rows: 2
Lexikalisch und Parser
PigletQL ist eine sehr einfache Sprache, deren Implementierung in den Phasen der lexikalischen Analyse und der Parsing-Analyse nicht erforderlich war.
Der lexikalische Analysator wird von Hand geschrieben. Aus der Abfragezeichenfolge wird ein Analysatorobjekt ( scanner_t ) erstellt, das nacheinander Token ausgibt :
scanner_t *scanner_create(const char *string); void scanner_destroy(scanner_t *scanner); token_t scanner_next(scanner_t *scanner);
Das Parsen erfolgt mit der rekursiven Abstiegsmethode. Zunächst wird das Objekt parser_t erstellt , das nach Erhalt des lexikalischen Analysators (scanner_t) das Objekt query_t mit Informationen zur Anforderung füllt:
query_t *query_create(void); void query_destroy(query_t *query); parser_t *parser_create(void); void parser_destroy(parser_t *parser); bool parser_parse(parser_t *parser, scanner_t *scanner, query_t *query);
Das Ergebnis der Analyse in query_t ist eine der drei von PigletQL unterstützten Abfragetypen:
typedef enum query_tag { QUERY_SELECT, QUERY_CREATE_TABLE, QUERY_INSERT, } query_tag; typedef struct query_t { query_tag tag; union { query_select_t select; query_create_table_t create_table; query_insert_t insert; } as; } query_t;
Die komplexeste Art von Abfrage in PigletQL ist SELECT. Es entspricht der Datenstruktur query_select_t :
typedef struct query_select_t { attr_name_t attr_names[MAX_ATTR_NUM]; uint16_t attr_num; rel_name_t rel_names[MAX_REL_NUM]; uint16_t rel_num; query_predicate_t predicates[MAX_PRED_NUM]; uint16_t pred_num; bool has_order; attr_name_t order_by_attr; sort_order_t order_type; } query_select_t;
Die Struktur enthält eine Beschreibung der Abfrage (ein vom Benutzer angefordertes Array von Attributen), eine Liste von Datenquellen - Beziehungen, ein Array von Prädikaten, die Tupel filtern, und Informationen zu dem Attribut, das zum Sortieren der Ergebnisse verwendet wird.
Semantischer Analysator
Die semantische Analysephase in regulärem SQL umfasst die Überprüfung des Vorhandenseins der aufgelisteten Tabellen, Spalten in den Tabellen und die Typprüfung in Abfrageausdrücken. Für Prüfungen in Bezug auf Tabellen und Spalten wird das Datenbankverzeichnis verwendet, in dem alle Informationen zur Datenstruktur gespeichert sind.
In PigletQL gibt es keine komplexen Ausdrücke. Daher wird die Abfrageprüfung auf die Überprüfung der Katalogmetadaten von Tabellen und Spalten reduziert. SELECT-Abfragen werden beispielsweise von der Funktion validate_select validiert . Ich werde es in Kurzform bringen:
static bool validate_select(catalogue_t *cat, const query_select_t *query) { for (size_t rel_i = 0; rel_i < query->rel_num; rel_i++) { if (catalogue_get_relation(cat, query->rel_names[rel_i])) continue; fprintf(stderr, "Error: relation '%s' does not exist\n", query->rel_names[rel_i]); return false; } if (!rel_names_unique(query->rel_names, query->rel_num)) return false; if (!attr_names_unique(query->attr_names, query->attr_num)) return false; return true; }
Wenn die Anforderung gültig ist, besteht der nächste Schritt darin, den Analysebaum in einen Operatorbaum zu kompilieren.
Kompilieren von Abfragen in eine Zwischenansicht
In vollwertigen SQL-Interpreten gibt es normalerweise zwei Zwischendarstellungen: logische und physikalische Algebra.
Ein einfacher PigletQL-Interpreter führt CREATE TABLE- und INSERT-Abfragen direkt aus seinen Analysebäumen aus, dh den Strukturen query_create_table_t und query_insert_t . Komplexere SELECT-Abfragen werden zu einer einzigen Zwischendarstellung kompiliert, die vom Interpreter ausgeführt wird.
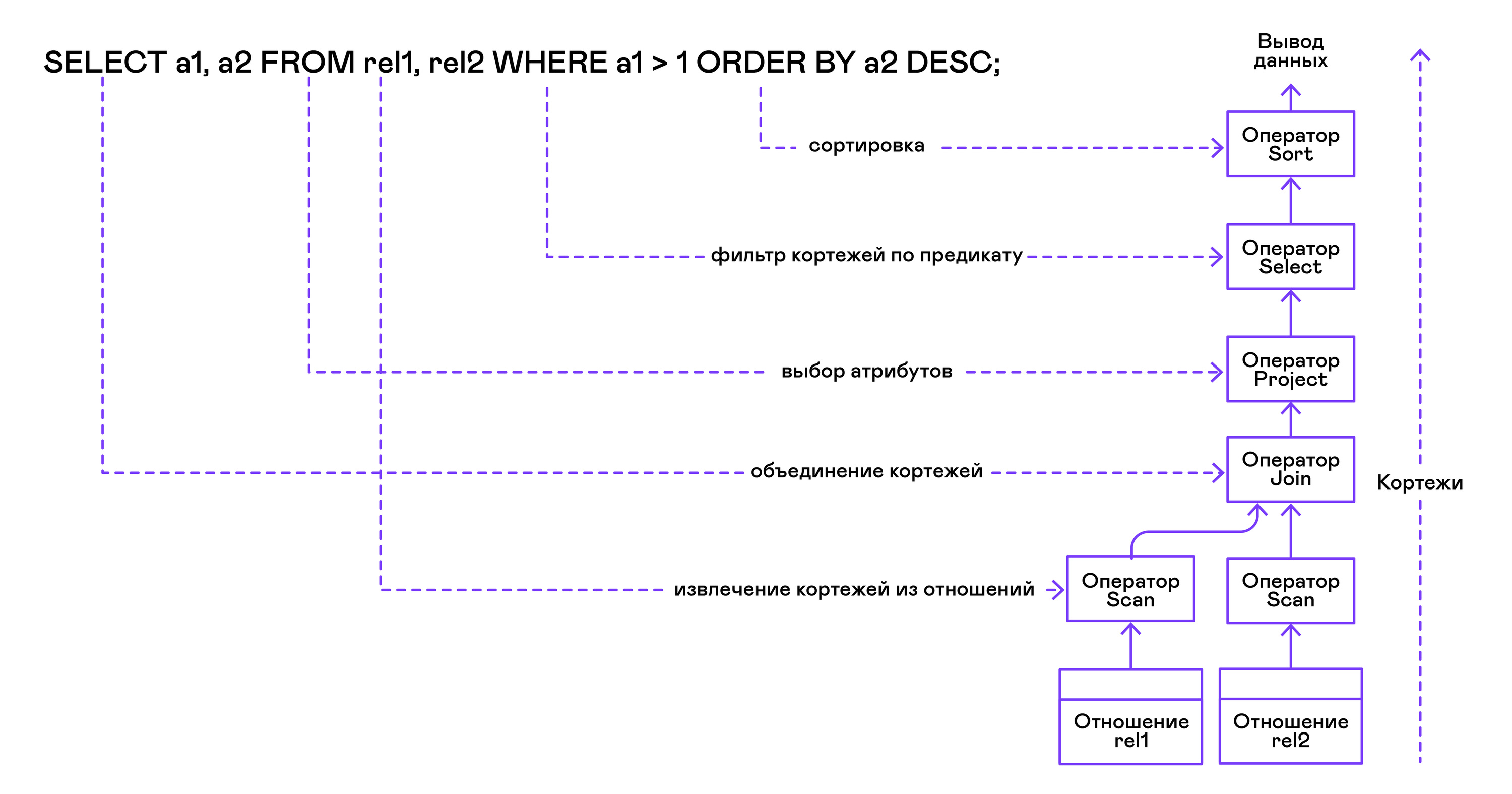
Der Operatorbaum wird in der folgenden Reihenfolge von den Blättern bis zur Wurzel erstellt:
Aus dem rechten Teil der Abfrage ("... VON Beziehung1, Beziehung2, ...") werden die Namen der gewünschten Beziehungen erhalten, für die jeweils eine Scan-Anweisung erstellt wird.
Durch Extrahieren von Tupeln aus Relationen werden Scanoperatoren über den Verknüpfungsoperator zu einem linksseitigen Binärbaum kombiniert.
Vom Benutzer angeforderte Attribute ("SELECT attr1, attr2, ...") werden von der Projektanweisung ausgewählt.
Wenn Prädikate angegeben werden ("... WO a = 1 UND b> 10 ..."), wird die select-Anweisung zum obigen Baum hinzugefügt.
Wenn die Methode zum Sortieren des Ergebnisses angegeben ist ("... ORDER BY attr1 DESC"), wird der Sortieroperator oben im Baum hinzugefügt.
Kompilierung in PigletQL- Code :
operator_t *compile_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = NULL; { size_t rel_i = 0; relation_t *rel = catalogue_get_relation(cat, query->rel_names[rel_i]); root_op = scan_op_create(rel); rel_i += 1; for (; rel_i < query->rel_num; rel_i++) { rel = catalogue_get_relation(cat, query->rel_names[rel_i]); operator_t *scan_op = scan_op_create(rel); root_op = join_op_create(root_op, scan_op); } } root_op = proj_op_create(root_op, query->attr_names, query->attr_num); if (query->pred_num > 0) { operator_t *select_op = select_op_create(root_op); for (size_t pred_i = 0; pred_i < query->pred_num; pred_i++) { query_predicate_t predicate = query->predicates[pred_i]; } root_op = select_op; } if (query->has_order) root_op = sort_op_create(root_op, query->order_by_attr, query->order_type); return root_op; }
Nachdem der Baum gebildet wurde, werden normalerweise optimierende Transformationen durchgeführt, aber PigletQL geht sofort zum Stadium der Ausführung der Zwischendarstellung über.
Durchführung einer Zwischenpräsentation
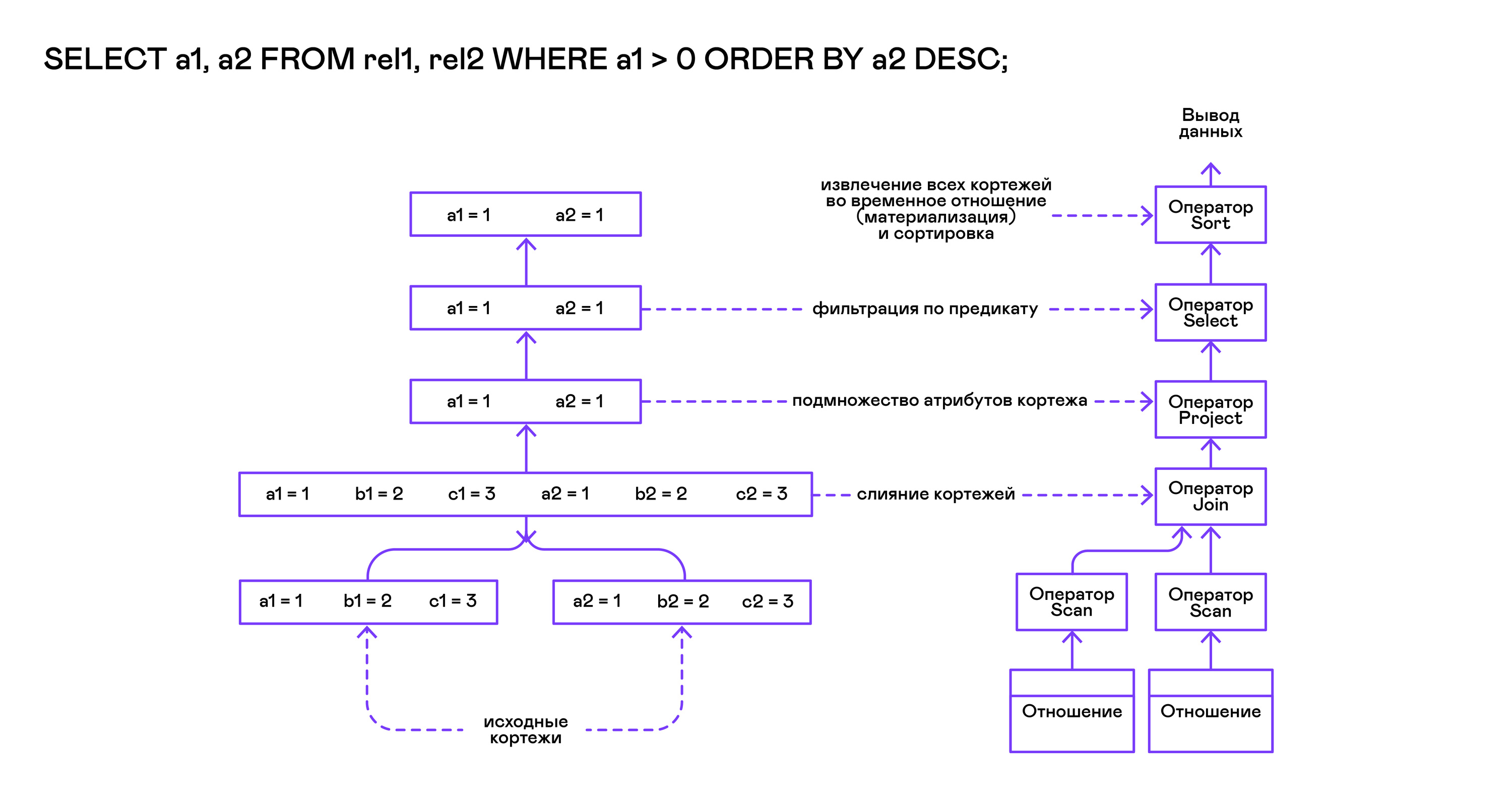
Das Volcano-Modell impliziert eine Schnittstelle für die Arbeit mit Bedienern über drei gemeinsame Öffnungs- / Weiter- / Schließvorgänge. Im Wesentlichen ist jede Volcano-Anweisung ein Iterator, aus dem Tupel einzeln „gezogen“ werden. Daher wird dieser Ausführungsansatz auch als Pull-Modell bezeichnet.
Jeder dieser Iteratoren kann selbst dieselben Funktionen verschachtelter Iteratoren aufrufen, temporäre Tabellen mit Zwischenergebnissen erstellen und eingehende Tupel konvertieren.
Ausführen von SELECT-Abfragen in PigletQL:
bool eval_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = compile_select(cat, query); { root_op->open(root_op->state); size_t tuples_received = 0; tuple_t *tuple = NULL; while((tuple = root_op->next(root_op->state))) { if (tuples_received == 0) dump_tuple_header(tuple); dump_tuple(tuple); tuples_received++; } printf("rows: %zu\n", tuples_received); root_op->close(root_op->state); } root_op->destroy(root_op); return true; }
Die Anforderung wird zuerst von der Funktion compile_select kompiliert, die den Stamm des Operatorbaums zurückgibt. Danach werden dieselben Funktionen zum Öffnen / Weiter / Schließen für den Stammoperator aufgerufen. Jeder Aufruf von next gibt entweder das nächste Tupel oder NULL zurück. Im letzteren Fall bedeutet dies, dass alle Tupel extrahiert wurden und die Funktion zum Schließen des Iterators aufgerufen werden sollte.
Die resultierenden Tupel werden neu berechnet und von der Tabelle an den Standardausgabestream ausgegeben.
Betreiber
Das Interessanteste an PigletQL ist der Operatorbaum. Ich werde das Gerät einiger von ihnen zeigen.
Die Operatoren haben eine gemeinsame Schnittstelle und bestehen aus Zeigern auf die Open / Next / Close-Funktion und einer zusätzlichen Destroy Destroy-Funktion, die die Ressourcen des gesamten Operatorbaums auf einmal freigibt:
typedef void (*op_open)(void *state); typedef tuple_t *(*op_next)(void *state); typedef void (*op_close)(void *state); typedef void (*op_destroy)(operator_t *op); struct operator_t { op_open open; op_next next; op_close close; op_destroy destroy; void *state; } ;
Zusätzlich zu Funktionen kann der Operator einen beliebigen internen Zustand (Zustandszeiger) enthalten.
Im Folgenden werde ich das Gerät von zwei interessanten Operatoren analysieren: den einfachsten Scan und das Erstellen einer Zwischenrelationssortierung.
Scan-Anweisung
Die Anweisung, die eine Abfrage startet, ist scan. Er geht einfach alle Tupel der Beziehung durch. Der interne Status des Scans ist ein Zeiger auf die Beziehung, aus der Tupel abgerufen werden, der Index des nächsten Tupels in der Beziehung und eine Verknüpfungsstruktur zum aktuellen Tupel, die an den Benutzer übergeben wird:
typedef struct scan_op_state_t { const relation_t *relation; uint32_t next_tuple_i; tuple_t current_tuple; } scan_op_state_t;
Um den Status einer Scan-Anweisung zu erstellen, benötigen Sie eine Quellbeziehung. alles andere (Zeiger auf die entsprechenden Funktionen) ist bereits bekannt:
operator_t *scan_op_create(const relation_t *relation) { operator_t *op = calloc(1, sizeof(*op)); assert(op); *op = (operator_t) { .open = scan_op_open, .next = scan_op_next, .close = scan_op_close, .destroy = scan_op_destroy, }; scan_op_state_t *state = calloc(1, sizeof(*state)); assert(state); *state = (scan_op_state_t) { .relation = relation, .next_tuple_i = 0, .current_tuple.tag = TUPLE_SOURCE, .current_tuple.as.source.tuple_i = 0, .current_tuple.as.source.relation = relation, }; op->state = state; return op; }
Öffnungs- / Schließvorgänge bei Scan-Reset-Links zurück zum ersten Element der Beziehung:
void scan_op_open(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; } void scan_op_close(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; }
Der nächste Aufruf gibt entweder das nächste Tupel zurück oder NULL, wenn die Beziehung keine Tupel mehr enthält:
tuple_t *scan_op_next(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; if (op_state->next_tuple_i >= op_state->relation->tuple_num) return NULL; tuple_source_t *source_tuple = &op_state->current_tuple.as.source; source_tuple->tuple_i = op_state->next_tuple_i; op_state->next_tuple_i++; return &op_state->current_tuple; }
Sortieranweisung
Die sort-Anweisung erzeugt Tupel in der vom Benutzer angegebenen Reihenfolge. Erstellen Sie dazu eine temporäre Beziehung zu Tupeln, die von verschachtelten Operatoren abgerufen wurden, und sortieren Sie sie.
Der interne Status des Bedieners:
typedef struct sort_op_state_t { operator_t *source; attr_name_t sort_attr_name; sort_order_t sort_order; relation_t *tmp_relation; operator_t *tmp_relation_scan_op; } sort_op_state_t;
Die Sortierung erfolgt nach den in der Anforderung angegebenen Attributen (sort_attr_name und sort_order) über das Zeitverhältnis (tmp_relation). All dies geschieht, wenn die offene Funktion aufgerufen wird:
void sort_op_open(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; operator_t *source = op_state->source; source->open(source->state); tuple_t *tuple = NULL; while((tuple = source->next(source->state))) { if (!op_state->tmp_relation) { op_state->tmp_relation = relation_create_for_tuple(tuple); assert(op_state->tmp_relation); op_state->tmp_relation_scan_op = scan_op_create(op_state->tmp_relation); } relation_append_tuple(op_state->tmp_relation, tuple); } source->close(source->state); relation_order_by(op_state->tmp_relation, op_state->sort_attr_name, op_state->sort_order); op_state->tmp_relation_scan_op->open(op_state->tmp_relation_scan_op->state); }
Die Aufzählung der Elemente der temporären Beziehung erfolgt durch den temporären Operator tmp_relation_scan_op:
tuple_t *sort_op_next(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; return op_state->tmp_relation_scan_op->next(op_state->tmp_relation_scan_op->state);; }
Die temporäre Beziehung wird in der Funktion zum Schließen freigegeben:
void sort_op_close(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; if (op_state->tmp_relation) { op_state->tmp_relation_scan_op->close(op_state->tmp_relation_scan_op->state); scan_op_destroy(op_state->tmp_relation_scan_op); relation_destroy(op_state->tmp_relation); op_state->tmp_relation = NULL; } }
Hier können Sie deutlich sehen, warum das Sortieren von Spalten in Spalten ohne Indizes viel Zeit in Anspruch nehmen kann.
Arbeitsbeispiele
Ich werde einige Beispiele für PigletQL-Abfragen und die entsprechenden Bäume der physikalischen Algebra geben.
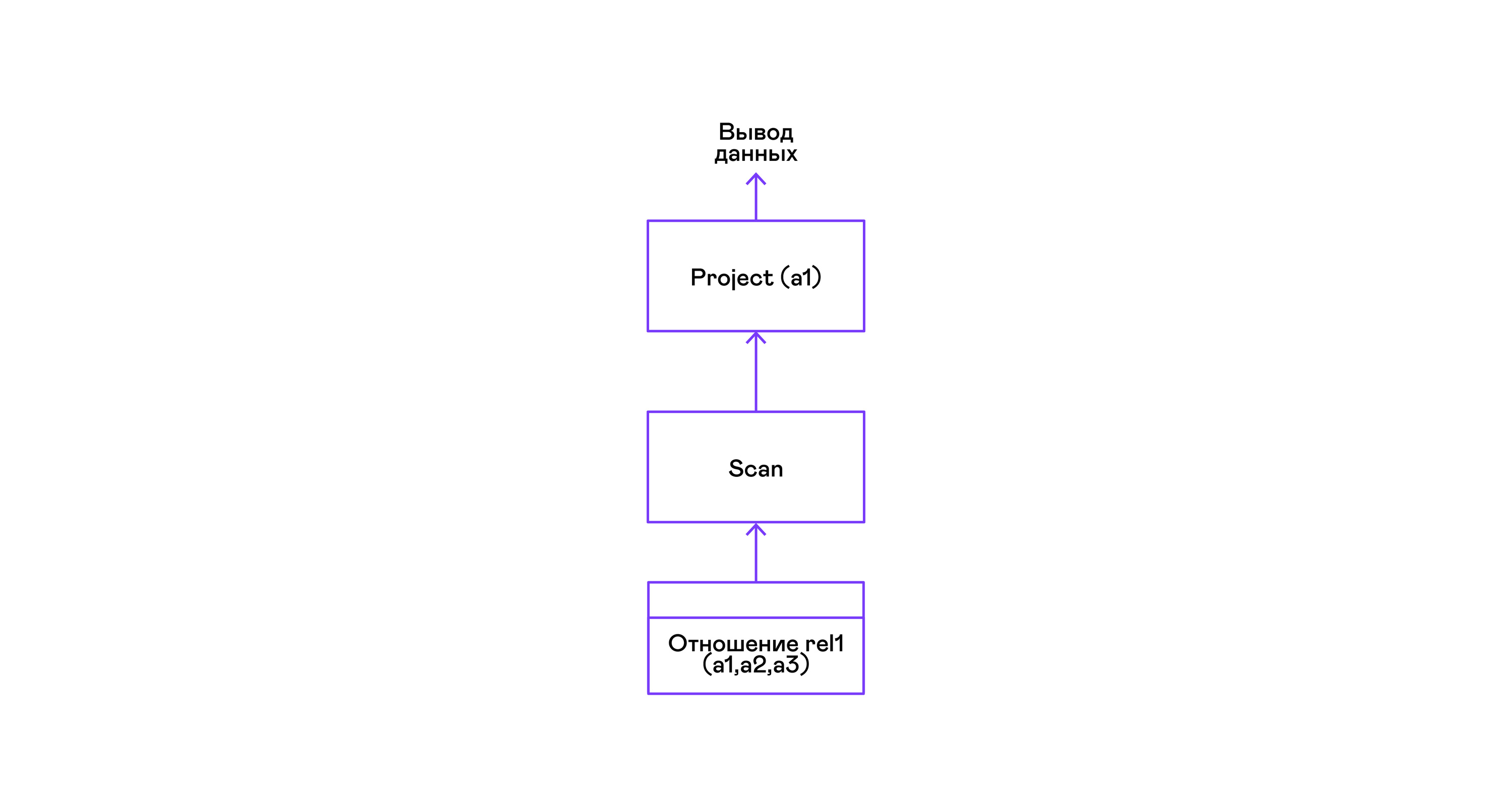
Das einfachste Beispiel, bei dem alle Tupel aus einer Beziehung ausgewählt werden:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1; a1 1 4 rows: 2 >
Für die einfachste Abfrage werden nur Tupel aus der Scan-Beziehung abgerufen und das einzige Projektattribut aus den Tupeln ausgewählt:
Tupel mit einem Prädikat auswählen:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 where a1 > 3; a1 4 rows: 1 >
Prädikate werden durch die select-Anweisung ausgedrückt:
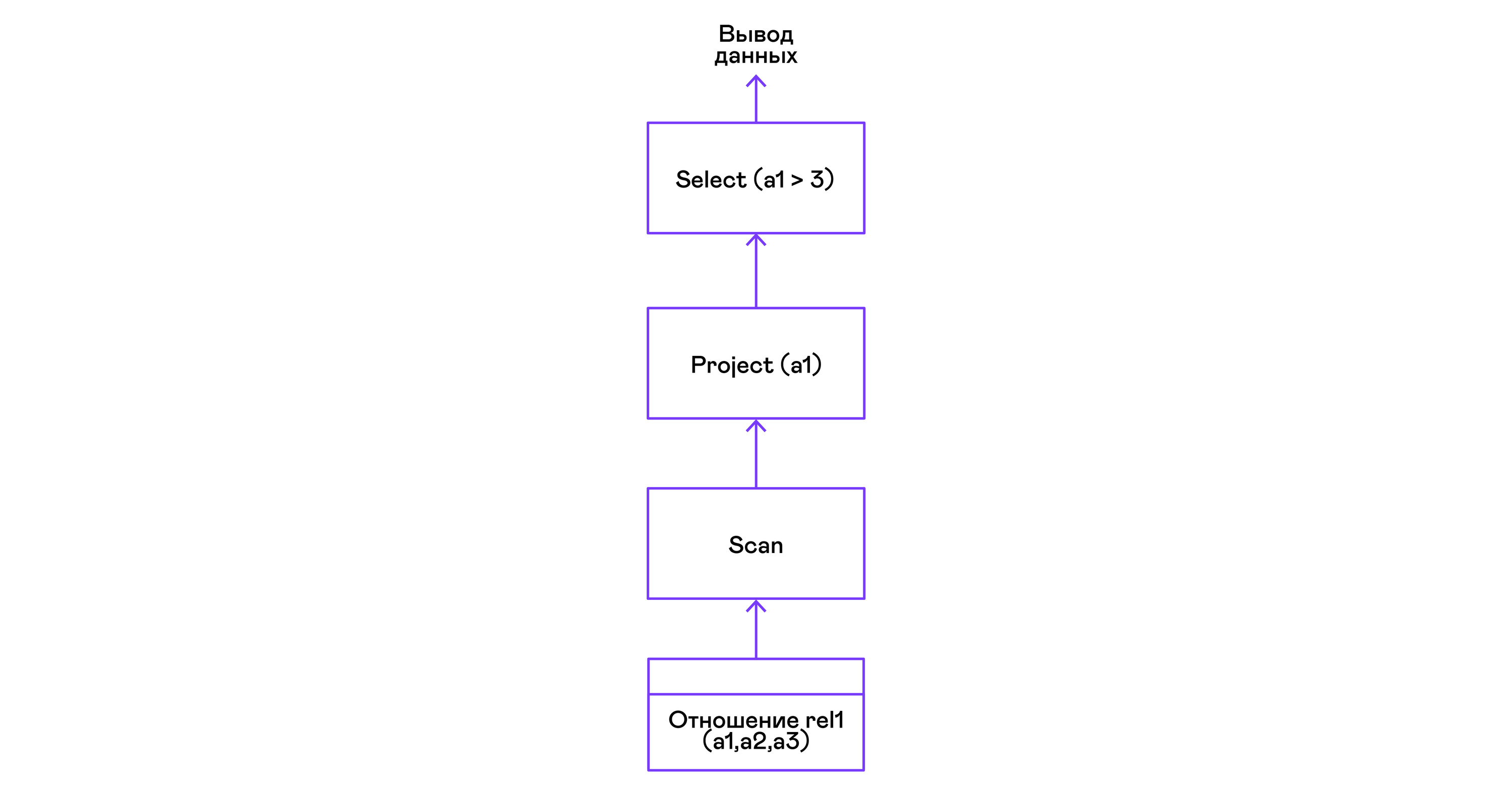
Auswahl von Tupeln mit Sortierung:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 order by a1 desc; a1 4 1 rows: 2
Der Scan-Sortieroperator im offenen Aufruf erstellt ( materialisiert ) eine temporäre Beziehung, platziert alle eingehenden Tupel dort und sortiert das Ganze. Danach werden bei den nächsten Aufrufen Tupel aus der temporären Beziehung in der vom Benutzer angegebenen Reihenfolge abgeleitet:

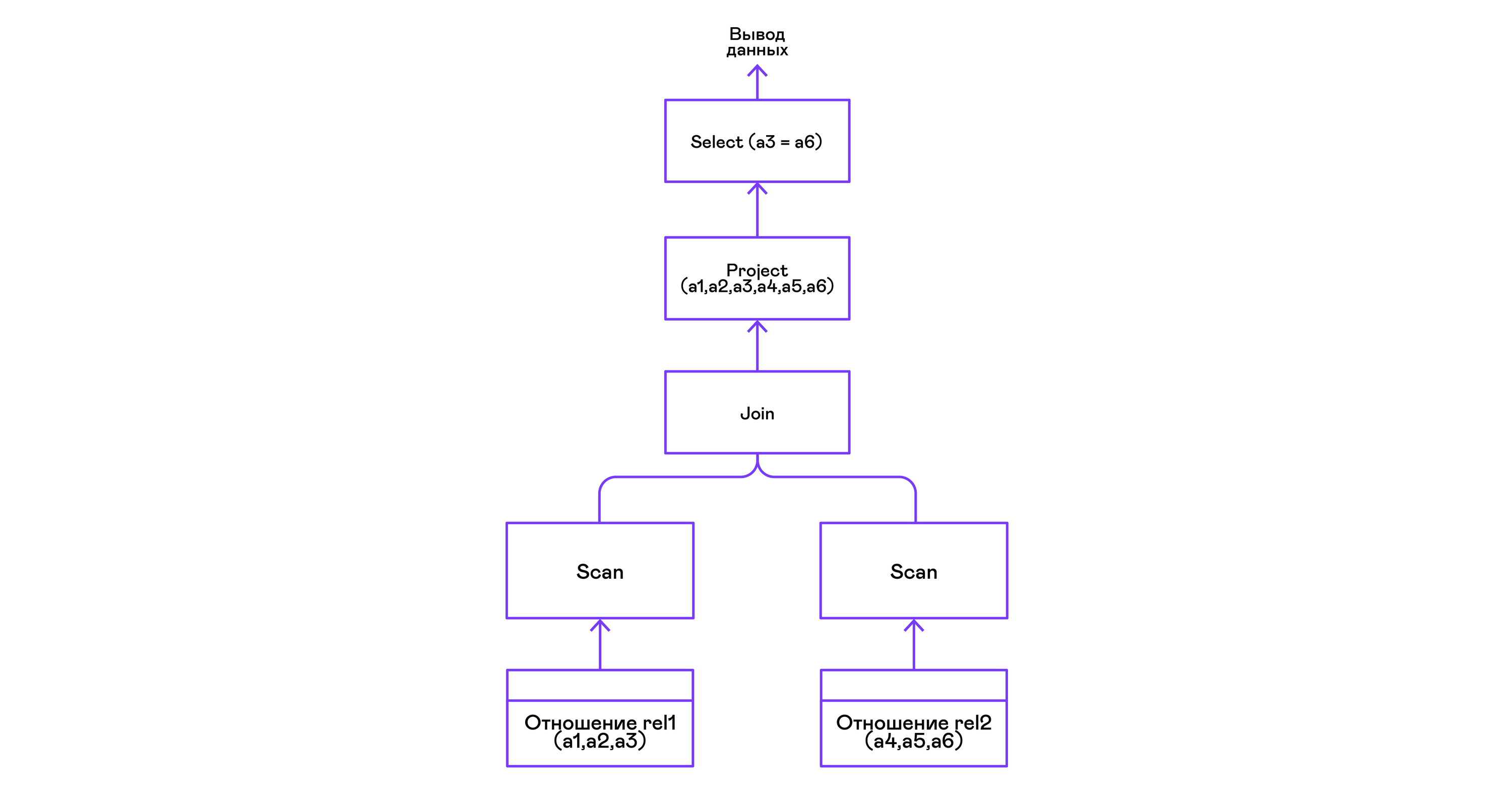
Kombinieren von Tupeln zweier Beziehungen mit einem Prädikat:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > create table rel2 (a4,a5,a6); > insert into rel2 values (7,8,6); > insert into rel2 values (9,10,6); > select a1,a2,a3,a4,a5,a6 from rel1, rel2 where a3=a6; a1 a2 a3 a4 a5 a6 4 5 6 7 8 6 4 5 6 9 10 6 rows: 2
Der Join-Operator in PigletQL verwendet keine komplexen Algorithmen, sondern bildet einfach ein kartesisches Produkt aus den Tupelmengen der linken und rechten Teilbäume. Dies ist sehr ineffizient, aber für einen Demo-Interpreter reicht es aus:
Schlussfolgerungen
Abschließend stelle ich fest, dass Sie, wenn Sie einen Interpreter für eine SQL-ähnliche Sprache erstellen, wahrscheinlich nur eine der vielen verfügbaren relationalen Datenbanken verwenden sollten. Tausende von Personenjahren wurden in moderne Optimierer und Abfragedolmetscher gängiger Datenbanken investiert, und es dauert Jahre, um selbst die einfachsten Allzweckdatenbanken zu entwickeln.
Die Demosprache PigletQL imitiert die Arbeit des SQL-Interpreters, aber in Wirklichkeit verwenden wir nur einzelne Elemente der Volcano-Architektur und nur für diejenigen (seltenen!) Arten von Abfragen, die im Rahmen des relationalen Modells schwer auszudrücken sind.
Trotzdem wiederhole ich: Selbst eine oberflächliche Kenntnis der Architektur solcher Dolmetscher ist nützlich, wenn es notwendig ist, flexibel mit Datenströmen zu arbeiten.
Literatur
Wenn Sie sich für die grundlegenden Probleme der Datenbankentwicklung interessieren, sind Bücher besser als die „Implementierung des Datenbanksystems“ (Garcia-Molina H., Ullman JD, Widom J., 2000).
Der einzige Nachteil ist eine theoretische Ausrichtung. Persönlich gefällt es mir, wenn dem Material konkrete Beispiele für Code oder sogar ein Demo-Projekt beigefügt sind. Informationen hierzu finden Sie im Buch „Datenbankdesign und -implementierung“ (Sciore E., 2008), das den vollständigen Code für eine relationale Datenbank in Java enthält.
Die beliebtesten relationalen Datenbanken verwenden immer noch Variationen des Themas Volcano. Die Originalveröffentlichung ist in einer sehr leicht zugänglichen Sprache verfasst und kann leicht in Google Scholar gefunden werden: "Volcano - ein erweiterbares und paralleles Abfragebewertungssystem" (Graefe G., 1994).
Obwohl sich SQL-Interpreter in den letzten Jahrzehnten im Detail stark verändert haben, hat sich die sehr allgemeine Struktur dieser Systeme seit langem nicht geändert. Eine Vorstellung davon können Sie einem Übersichtsartikel desselben Autors „Abfrageauswertungstechniken für große Datenbanken“ (Graefe G. 1993) entnehmen.