Hallo Habr! Mein Name ist Nikolai und ich beschäftige mich mit der Konstruktion und Implementierung von Modellen für maschinelles Lernen in der Sberbank. Heute werde ich über die Entwicklung eines Empfehlungssystems für Zahlungen und Überweisungen in der Anwendung auf Ihrem Smartphone sprechen.
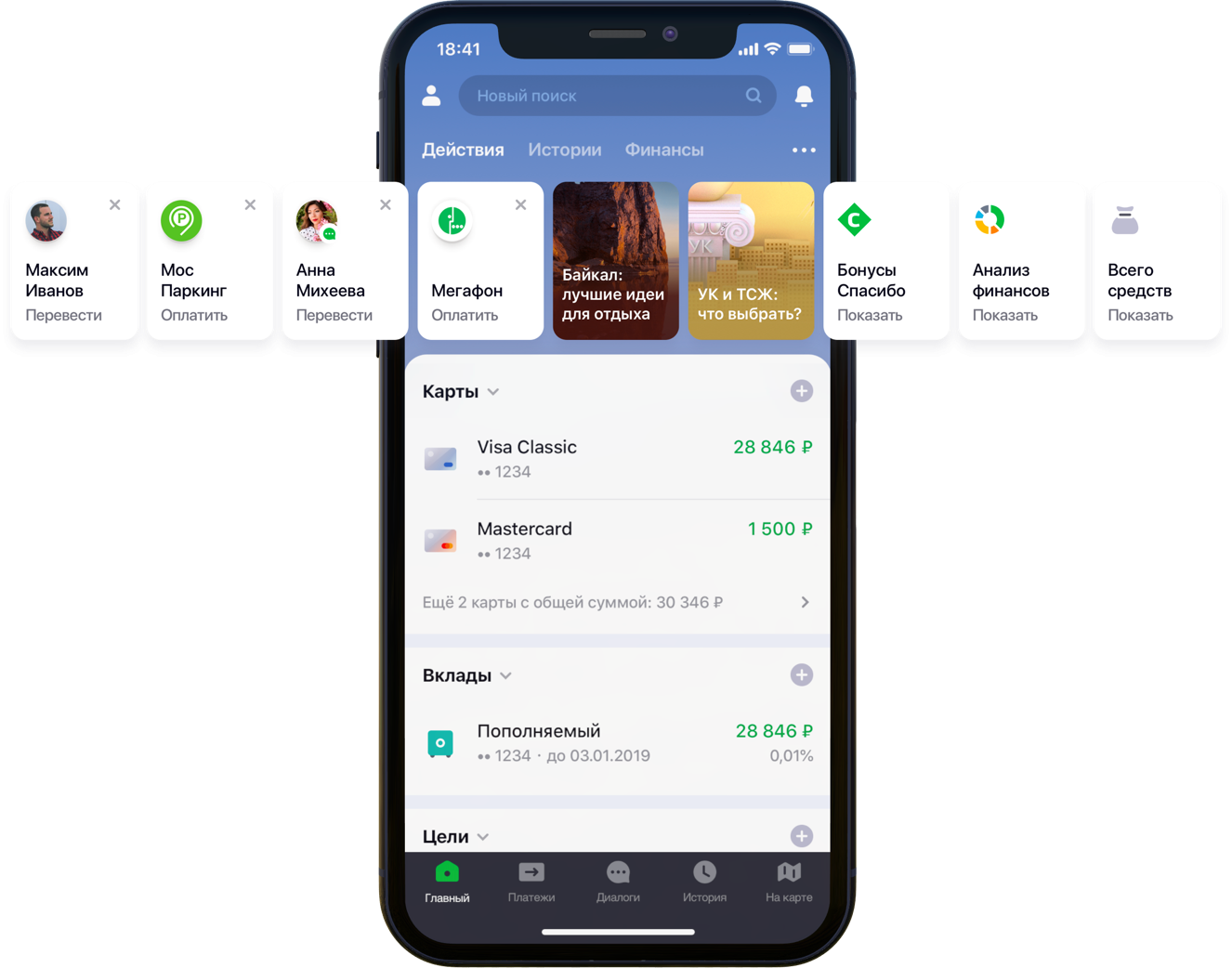 Gestaltung des Hauptbildschirms der mobilen Anwendung mit Empfehlungen
Gestaltung des Hauptbildschirms der mobilen Anwendung mit EmpfehlungenWir hatten zweihunderttausend mögliche Zahlungsoptionen, 55 Millionen Kunden, 5 verschiedene Bankquellen, eine halbe Entwicklersäule und einen Berg von Bankaktivitäten, Algorithmen und all das, alle Farben sowie einen Liter zufälliger Samen, eine Schachtel Hyperparameter, einen halben Liter Korrekturfaktoren und zwei Dutzende von Bibliotheken. Nicht, dass dies alles für die Arbeit notwendig gewesen wäre, aber da er begann, das Leben der Kunden zu verbessern, gehen Sie Ihrem Hobby bis zum Ende nach. Unter dem Schnitt steht die Geschichte des Kampfes um UX, die korrekte Formulierung des Problems, der Kampf gegen die Dimension der Daten, der Beitrag zu Open Source und unsere Ergebnisse.
Erklärung des Problems
Mit der Entwicklung und Skalierung erhält die Sberbank Online-Anwendung nützliche Funktionen und zusätzliche Funktionen. Insbesondere können Sie in der Anwendung Geld überweisen oder für Dienstleistungen verschiedener Organisationen bezahlen.
„Wir haben alle Benutzerpfade in der Anwendung sorgfältig geprüft und festgestellt, dass viele davon erheblich reduziert werden können. Zu diesem Zweck haben wir uns entschlossen, den Hauptbildschirm in mehreren Schritten zu personalisieren. Zuerst haben wir versucht, das, was der Client nicht verwendet, vom Bildschirm zu entfernen, beginnend mit Bankkarten. Dann haben sie die Aktionen in den Vordergrund gerückt, die der Kunde bereits zuvor ausgeführt hatte und für die er jetzt in die Anwendung gehen konnte. Jetzt umfasst die Liste der Aktionen Zahlungen an Organisationen und Überweisungen an Kontakte. Dann wird die Liste dieser Aktionen erweitert “, sagte mein Kollege Sergey Komarov, der die Funktionalität aus Sicht des Kunden im Sberbank Online-Team entwickelt. Es ist erforderlich, ein Modell zu erstellen, das die festgelegten Slots in den Aktions-Widgets (Abbildung oben) mit persönlichen Empfehlungen für Zahlungen und Überweisungen anstelle einfacher Regeln füllt.
Lösung
Wir im Team haben die Aufgabe in zwei Teile zerlegt:
- die Empfehlung der Wiederholung von Operationen zur Bezahlung von Dienstleistungen oder zur Überweisung von Geldern (Block "Empfohlene Operationen")
- Empfehlung von Beispielen für Suchanfragen zur Zahlung für Dienste, die zuvor von diesem Client nicht verwendet wurden (Block „Suchbeispiele“)
Wir haben uns entschlossen, die Funktionalität zuerst auf der Registerkarte "Suchen" zu testen:
Empfohlenes Design des SuchbildschirmsEmpfohlene Operationen
Bewertungsoptimierung
Wenn wir die Unteraufgabe als Empfehlung für die Wiederholung von Vorgängen festlegen, können wir die Berechnung und Auswertung von Billionen von Kombinationen aller möglichen Vorgänge für alle Kunden loswerden und uns auf eine viel geringere Anzahl von Vorgängen konzentrieren. Wenn der hypothetische Kunde mit dem JJJ-Hash von allen unseren Kunden zur Verfügung stehenden Vorgängen nur die Zahlung für Benzin und Parken verwendet hat, wird die Wahrscheinlichkeit bewertet, dass nur diese Vorgänge für diesen Kunden wiederholt werden:
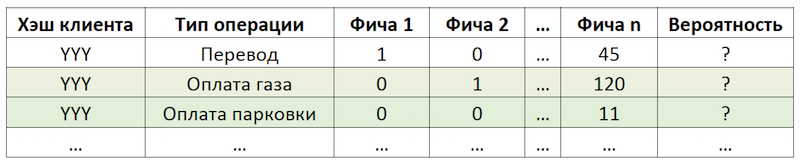 Ein Beispiel für die Reduzierung der Dimension von Daten für die Bewertung
Ein Beispiel für die Reduzierung der Dimension von Daten für die BewertungDatensatz vorbereiten
Die Stichprobe ist eine Transaktionsbeobachtung, angereichert mit Faktoren der Kundendemographie, Finanzaggregaten und verschiedenen Frequenzmerkmalen eines bestimmten Vorgangs.
Die Zielvariable ist in diesem Fall binär und spiegelt die Tatsache des Ereignisses am Tag nach dem Tag wider, an dem die Faktoren berechnet werden. Wenn wir also den Tag der Berechnung der Faktoren iterativ verschieben und das Flag der Zielvariablen setzen, multiplizieren und markieren wir dieselben Operationen und markieren sie je nach Position relativ zu diesem Tag unterschiedlich.
BeobachtungsschemaWenn wir den Schnitt am 17.03.2019 für den Kunden „JJJ“ berechnen, erhalten wir zwei Beobachtungen:
Ein Beispiel für die Beobachtungen für einen Datensatz"Merkmal 1" kann zum Beispiel das Guthaben auf allen Karten des Kunden bedeuten, "Merkmal 2" - das Vorhandensein dieser Art von Operation in der letzten Woche.
Wir nehmen die gleichen Transaktionen vor, bilden jedoch Beobachtungen für das Training zu einem anderen Zeitpunkt:
BeobachtungsschemaWir erhalten Beobachtungen für einen Datensatz mit anderen Werten beider Merkmale und der Zielvariablen:
 Ein Beispiel für die Beobachtungen für einen Datensatz
Ein Beispiel für die Beobachtungen für einen DatensatzIn den obigen Beispielen sind zur Verdeutlichung die tatsächlichen Werte der Faktoren angegeben, aber tatsächlich werden die Werte von einem automatischen Algorithmus verarbeitet: Die Ergebnisse der
WOE-Konvertierung werden der Eingabe des Modells zugeführt. Sie können die Variablen in eine monotone Beziehung zur Zielvariablen bringen und gleichzeitig die Auswirkungen von Ausreißern beseitigen. Zum Beispiel haben wir den Faktor "Anzahl der Karten" und eine Verteilung der Zielvariablen:
 Beispiel für eine WOE-Konvertierung
Beispiel für eine WOE-KonvertierungDie WOE-Transformation ermöglicht es uns, eine nichtlineare Abhängigkeit in mindestens eine monotone Abhängigkeit umzuwandeln. Jeder Wert des analysierten Faktors ist mit einem eigenen WOE-Wert verknüpft, sodass ein neuer Faktor gebildet und der ursprüngliche aus dem Datensatz entfernt wird:
 Die Auswirkung der WOE-Transformation auf die Beziehung zur Zielvariablen
Die Auswirkung der WOE-Transformation auf die Beziehung zur ZielvariablenDas Wörterbuch zum Konvertieren von Variablenwerten in WOE wird gespeichert und später für die Bewertung verwendet. Das heißt, wenn wir die Wahrscheinlichkeiten für morgen berechnen müssen, erstellen wir einen Datensatz wie in den Tabellen mit Beispielen für Beobachtungen oben, konvertieren die erforderlichen Variablen mit dem gespeicherten Code in WOE und wenden das Modell auf diese Daten an.
Schulung
Die Wahl der Methode war streng begrenzt - Interpretierbarkeit. Um die Fristen einzuhalten, wurde daher beschlossen, die Erklärungen in der zweiten Hälfte des Problems mit demselben
SHAP zu verschieben und relativ einfache Methoden zu testen: Regression und flache Neuronen. Das Tool war SAS Miner, eine Software zur Vorverarbeitung, Analyse und Erstellung von Modellen für verschiedene Daten in interaktiver Form, die viel Zeit beim Schreiben von Code spart.
 SAS Miner-Schnittstelle
SAS Miner-SchnittstelleQualitätsbewertung
Ein Vergleich der GINI-Metrik mit einer Stichprobe außerhalb der Zeit ergab, dass das neuronale Netzwerk die Aufgabe am besten bewältigt:
Vergleichstabelle von Qualitätsmodellen und FrequenzregelnDas Modell hat zwei Austrittspunkte. Die Empfehlungen in Form von Widgetkarten auf dem Hauptbildschirm umfassen Vorgänge, deren Prognose über einem bestimmten Schwellenwert liegt (siehe das erste Bild im Beitrag). Die Auswahl der Grenze basiert auf einem Gleichgewicht zwischen Qualität und Abdeckung, das in einer solchen Architektur die Hälfte aller durchgeführten Operationen ausmacht. Die Top-4-Vorgänge werden an den Block „Empfohlene Vorgänge“ des Suchbildschirms gesendet (siehe zweites Bild).
Suchbeispiele
Wenn wir uns dem zweiten Teil der Aufgabe zuwenden, kehren wir zum Problem einer Vielzahl möglicher Zahlungsoptionen für die Dienste von Anbietern zurück, die innerhalb jedes Kunden bewertet und sortiert werden müssen - Billionen von Paaren. Darüber hinaus verfügen wir über implizite Daten, dh es gibt keine Informationen über die Bewertung der geleisteten Zahlungen oder darüber, warum der Kunde keine Zahlungen geleistet hat. Daher wurde zunächst beschlossen, verschiedene Methoden zur Erweiterung der Zahlungsmatrix von Kunden zu Anbietern zu testen: ALS und FM.
ALS
ALS (Alternating Least Squares) oder Alternating Least Squares - bei der kollaborativen Filterung eine der Methoden zur Lösung des Problems der Faktorisierung der Interaktionsmatrix. Wir werden unsere Transaktionsdaten zur Zahlung von Diensten in Form einer Matrix präsentieren, in der Spalten eindeutige Kennungen der Dienste aller Anbieter und Zeilen eindeutige Kunden sind. In den Zellen platzieren wir die Anzahl der Operationen bestimmter Kunden bei bestimmten Anbietern für einen bestimmten Zeitraum:
 Matrixzerlegungsprinzip
MatrixzerlegungsprinzipDie Bedeutung der Methode besteht darin, dass wir zwei solche Matrizen niedrigerer Dimension erstellen, deren Multiplikation das Ergebnis ergibt, das der ursprünglichen großen Matrix in den gefüllten Zellen am nächsten kommt. Das Modell lernt, eine versteckte faktorielle Beschreibung für Kunden und Anbieter zu erstellen. Eine Implementierung der Methode in der
impliziten Bibliothek wurde verwendet. Das Training erfolgt nach folgendem Algorithmus:
- Matrizen von Kunden und Anbietern mit versteckten Faktoren werden initialisiert. Ihre Anzahl ist der Hyperparameter des Modells.
- Die Matrix der versteckten Faktoren der Anbieter wird festgelegt und die Ableitung der Verlustfunktion für die Korrektur der Kundenmatrix berücksichtigt. Der Autor verwendete eine interessante Methode für konjugierte Gradienten , mit der Sie diesen Schritt erheblich beschleunigen können.
- Der vorherige Schritt wird in ähnlicher Weise für die Matrix der verborgenen Faktoren der Kunden wiederholt.
- Die Schritte 2-3 wechseln sich ab, bis der Algorithmus konvergiert.
Vorbereitung
Transaktionsdaten wurden in eine Matrix von Interaktionen mit einem Grad an Spärlichkeit von ~ 99% mit großer Ungleichmäßigkeit zwischen den Anbietern umgewandelt. Um die Daten in Zug- und Validierungsmuster zu unterteilen, haben wir den Anteil der gefüllten Zellen zufällig maskiert:
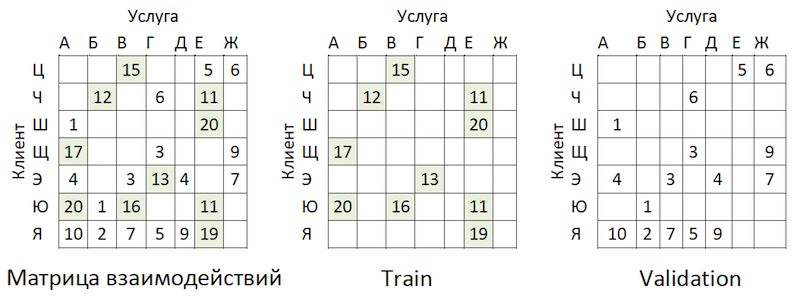 Beispiel für die gemeinsame Nutzung von Daten
Beispiel für die gemeinsame Nutzung von DatenDie Transaktionen wurden als Test für den Zeitraum nach dem Training verwendet und in einer Matrix des gleichen Formats angeordnet - es stellte sich heraus, dass die Zeit abgelaufen war.
Schulung
Das Modell verfügt über mehrere Hyperparameter, die zur Verbesserung der Qualität angepasst werden können:
- Alpha ist der Koeffizient, mit dem die Matrix gewichtet wird, wobei der Grad des Vertrauens ( C_iu ) angepasst wird, dass der angegebene Service vom Kunden wirklich „gemocht“ wird.
- Die Anzahl der Faktoren in den verborgenen Matrizen von Clients und Anbietern ist die Anzahl der Spalten bzw. Zeilen.
- Regularisierungskoeffizient L2 λ.
- Die Anzahl der Iterationen der Methode.
Wir haben die
Hyperopt- Bibliothek verwendet, mit der wir die Auswirkung von Hyperparametern auf die Qualitätsmetrik mithilfe der
TPE- Methode bewerten und ihren optimalen Wert auswählen können. Der Algorithmus beginnt mit einem Kaltstart und führt abhängig von den Werten der analysierten Hyperparameter mehrere Bewertungen der Qualitätsmetrik durch. Dann versucht er im Wesentlichen, eine Reihe von Werten von Hyperparametern auszuwählen, die mit größerer Wahrscheinlichkeit einen guten Wert für die Qualitätsmetrik ergeben. Die Ergebnisse werden in einem Wörterbuch gespeichert, aus dem Sie ein Diagramm erstellen und das Ergebnis des Optimierers visuell auswerten können (Blau ist besser):
Das Diagramm der Abhängigkeit der Qualitätsmetrik von der Kombination der HyperparameterDie Grafik zeigt, dass die Werte der Hyperparameter die Qualität des Modells stark beeinflussen. Da für jeden von ihnen Bereiche auf die Eingabe der Methode angewendet werden müssen, kann das Diagramm weiter bestimmen, ob es sinnvoll ist, den Wertebereich zu erweitern oder nicht. In unserer Aufgabe ist es beispielsweise klar, dass es sinnvoll ist, große Werte für die Anzahl der Faktoren zu testen. In Zukunft hat dies das Modell wirklich verbessert.
Metrik und Komplexität der Qualitätsbewertung
Wie ist die Qualität des Modells zu bewerten? Eine der am häufigsten verwendeten Metriken für Empfehlungssysteme, bei denen die Reihenfolge wichtig ist, ist
MAP @ k oder Mean Average Precision bei K. Diese Metrik schätzt die Genauigkeit des Modells anhand der K-Empfehlungen unter Berücksichtigung der Reihenfolge der Elemente in der Liste dieser Empfehlungen im Durchschnitt für alle Kunden.
Leider dauerte eine Qualitätsbewertung selbst an einer Probe mehrere Stunden. Nachdem wir die Ärmel hochgekrempelt hatten, begannen wir, die Funktion mean_average_pecision_at_k () mit der Bibliothek line_profiler zu profilieren. Die Aufgabe wurde weiter dadurch erschwert, dass die Funktion Cython-Code verwendete und korrekt
berücksichtigt werden musste , da sonst die notwendigen Statistiken einfach nicht erhoben wurden. Infolgedessen standen wir erneut vor dem Problem der Dimensionalität unserer Daten. Um diese Metrik zu berechnen, müssen Sie einige Schätzungen für jeden Service von allen möglichen für jeden Kunden abrufen und die persönlichen Top-K-Empfehlungen auswählen, indem Sie aus dem resultierenden Array sortieren. Selbst unter Berücksichtigung der teilweisen Sortierung von numpy.argpartition () mit O (n) -Komplexität erwies sich das Sortieren der Noten als der längste Schritt, der die Qualitätsbewertung über die Uhr streckte. Da numpy.argpartition () nicht alle Kernel unseres Servers verwendete, wurde beschlossen, den Algorithmus zu verbessern, indem dieser Teil in C ++ und OpenMP über cython neu geschrieben wurde. Ein kurz neuer Algorithmus lautet wie folgt:
- Daten werden von Kunden in Stapel geschnitten.
- Eine leere Matrix und Zeiger auf den Speicher werden initialisiert.
- Batch-Strings nach Zeigern werden auf zwei Arten sortiert: nach der Funktion teilweise_sortieren und dann nach der C ++ - Algorithmusbibliothek.
- Die Ergebnisse werden parallel in die Zellen der leeren Matrix geschrieben.
- Daten werden in Python zurückgegeben.
Dadurch konnten wir die Berechnung der Empfehlungen mehrmals beschleunigen. Die Revision wurde dem offiziellen Repository
hinzugefügt .
OOT-Ergebnisanalyse
Und jetzt ist es Zeit, die Qualität des Modells zu bewerten. Warum brauchen wir eine zeitversetzte Probenahme? Wenn wir uns die Verteilung der Operationen nach Anbietern ansehen, sehen wir das folgende Bild:
Verteilung der Popularität von DienstleisternEs gibt ein Ungleichgewicht. Dies führt dazu, dass das Modell versucht, beliebte Dienste zu empfehlen. Zurück zum obigen Bild:
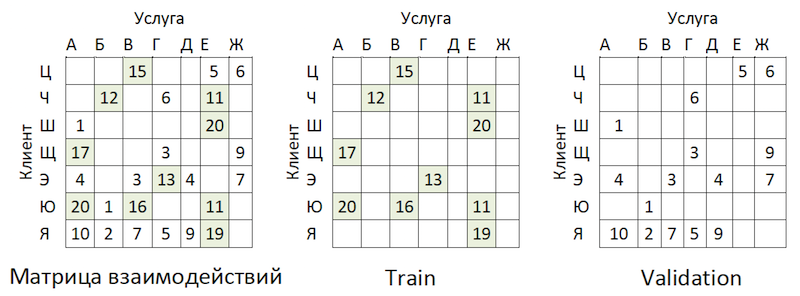
Das Problem ist, dass, wenn Sie die Genauigkeit des Modells überprüfen, indem Sie dieselbe Matrix maskieren, wie es fast überall empfohlen wird, für die meisten Kunden (Randbeispiele: „W“, „E“ und „I“) die Qualität der Validierungsprognosen gilt (wir werden dies so tun) Sie hat nicht an der Auswahl der Hyperparameter teilgenommen.) wird hoch sein, wenn dies die beliebtesten Anbieter sind. Infolgedessen erhalten wir ein falsches Vertrauen in die Stärke des Modells. Daher haben wir wie folgt gehandelt:
- Gebildete Schätzungen der Anbieter nach Modell.
- Die vorhandenen Client-Service-Paare wurden aus den Bewertungen (siehe Abbildung unten) und OOT-Matrizen ausgeschlossen.
- Gebildet aus den verbleibenden Bewertungen der Top-K-Empfehlungen und bewertet MAP @ k auf dem verbleibenden OOT.
 Die Logik der Vorbereitung der Matrix zur Erstellung von Prognosen
Die Logik der Vorbereitung der Matrix zur Erstellung von PrognosenAls Basis haben wir eine Liste von Anbietern zusammengestellt, sortiert nach Beliebtheit, und diese mit allen Kunden multipliziert, wobei wiederum die vorhandenen Kunden-Service-Paare ausgeschlossen wurden. Es stellte sich als traurig heraus und überhaupt nicht das, was wir in den Zug- / Validierungsmustern erwartet und gesehen hatten:
Vergleichstabelle für Benchmark und ModellqualitätHör auf! Wir haben Kundenfaktoren und Parameter von Anbietern. Wir bekommen Faktorisierungsmaschinen.
FM
Faktorisierungsmaschinen (Faktorisierungsmaschine) - ein Lernalgorithmus mit einem Lehrer, der entwickelt wurde, um Beziehungen zwischen Faktoren zu finden, die interagierende Entitäten beschreiben, die in Form von spärlichen Matrizen dargestellt werden. Wir haben die FM-Implementierung aus der
LightFM- Bibliothek verwendet.
Datenformat
Zusätzlich zur normalisierten Interaktionsmatrix verwendet die
Methode zwei zusätzliche Datensätze mit Faktoren für Kunden und für Dienste von Anbietern in Form von One-Hot-Coded-Matrizen, die mit einzelnen verbunden sind:
 Die Logik der Vorbereitung der Matrix zur Erstellung von Prognosen
Die Logik der Vorbereitung der Matrix zur Erstellung von PrognosenQualitätsbewertung
Die Qualität des FM-Modells in unseren Daten war geringer als bei ALS:
Vergleichstabelle der Qualitätsmodelle und der BasislinieModellarchitektur ändern - Boosting
Es wurde beschlossen, von der anderen Seite hereinzukommen. Unter Hinweis auf die Verteilung der Popularität von Diensten haben wir 300 von ihnen identifiziert, Transaktionen, die 80% aller Operationen abdecken, und einen Klassifikator für sie geschult. Hier stellen die Daten Aggregate von Kundentransaktionen dar, die mit Kundenfunktionen angereichert sind:
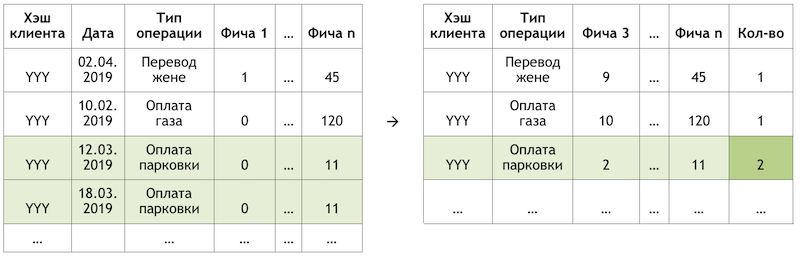 Transaktionsaggregationsschema
TransaktionsaggregationsschemaWarum nur clientseitig? In diesem Fall reicht es aus, eine Zeile pro Kunde zu haben, um Empfehlungen vorzubereiten. Wenn wir das Modell darauf anwenden, erhalten wir den Ausgabevektor der Wahrscheinlichkeiten für alle Klassen, aus denen sich leicht Top-K-Empfehlungen auswählen lassen. Wenn wir die Funktionen von Anbieterservices zum Schulungssatz hinzufügen, müssen wir in der Phase der Anwendung des Modells entweder 300 Zeilen für jeden Kunden vorbereiten - eine für jeden Anbieterservice mit Funktionen, die diese beschreiben, oder ein anderes Modell für die Vorsortierung von Bewertungskandidaten erstellen .
Das Hinzufügen von Funktionen zu Kunden von ALS hat unsere Daten nicht erhöht, da wir bereits Transaktionsaktivitäten berücksichtigt haben - beispielsweise in Abschnitten des Kundencenters oder in Kategorien im Stil von „Spieler“ oder „Theater“. In diesem Format konnten wir gute Ergebnisse erzielen:
Vergleichstabelle der Qualitätsmodelle und der BasislinieRegionalfilter
Trotz der hohen Qualität des Modells bleibt ein weiteres Problem bei diesem Ansatz. Da die Architektur der Daten und des Modells nicht die Verwendung von Merkmalen der Dienste von Anbietern impliziert, berücksichtigt das Modell die Geografie nicht vollständig und empfiehlt möglicherweise, dass Personen für den Dienst eines lokalen Anbieters aus einer anderen Region bezahlen. Um dieses Risiko zu minimieren, haben wir einen kleinen Filter entwickelt, um Optionen vor der Eingabe von Empfehlungen abzuschneiden. Dem Algorithmus wird eine leichte Rekursionsfliege verliehen:
- Wir sammeln Informationen über die Region des Kunden aus Bankprofilen und anderen internen Quellen.
- Wir wählen für jeden Anbieter die wichtigsten Präsenzregionen aus.
- Wir klären / füllen die Informationen über die Region des Kunden nach Regionen der Anbieter aus, die er verwendet.
Nach diesen Manipulationen trennen
wir anhand
des Herfindahl-Index die regionalen Anbieter, die in einer begrenzten Anzahl von Regionen vertreten sind, von den Bundesanbietern:
Trennung der Anbieter nach Präsenz in den RegionenWir bilden eine Maske mit akzeptablen regionalen Anbietern für Kunden und schließen unnötige Elemente von Modellvorhersagen aus, bevor wir eine Liste mit Empfehlungen erstellen.
Fazit
Wir haben zwei Modelle entwickelt, die zusammen einen vollständigen Satz von Empfehlungen zu Zahlungen und Überweisungen bilden. Der Clientpfad für die Hälfte der wiederkehrenden Vorgänge konnte auf einen Klick reduziert werden. In zukünftigen Plänen soll das Modell der „empfohlenen Operationen“ mithilfe von Feedback-Daten (Karten können ausgeblendet werden usw.) verbessert werden, wodurch der Schwellenwert für die Auswahl von Empfehlungen gesenkt und die Abdeckung erhöht wird. Es ist auch geplant, die Abdeckung der empfohlenen Zahlungen im Modell der „Suchbeispiele“ zu erweitern und einen Algorithmus zur Bewertung der Optimierung dafür zu entwickeln.
Wir haben den schwierigen Weg beschritten, ein Empfehlungssystem für Zahlungen und Überweisungen aufzubauen. Unterwegs haben wir Unebenheiten gesammelt und Erfahrungen mit der Zerlegung und Vereinfachung solcher Aufgaben, der korrekten Bewertung solcher Systeme, der Anwendbarkeit von Methoden, der optimalen Arbeit mit großen Datenmengen und der deutlichen Erweiterung unseres Verständnisses der Besonderheiten solcher Aufgaben gesammelt. Unterwegs habe ich es geschafft, zu Open Source beizutragen, das wir selbst nutzen. Ich wünsche Ihnen interessante Aufgaben, realistische Basislinien und einzelne F1. Vielen Dank für Ihre Aufmerksamkeit!