Dieser Artikel ist eine Art Meisterklasse „DVC zur Automatisierung von ML-Experimenten und Datenversionierung“, die am 18. Juni im ML REPA (Machine Learning REPA:
Reproduzierbarkeit, Experimente und Automatisierung von Pipelines) bei uns.
Hier werde ich über die Funktionen der internen Arbeit von DVC und deren Verwendung in Projekten sprechen.
Die im Artikel verwendeten Codebeispiele finden Sie
hier . Der Code wurde unter MacOS und Linux (Ubuntu) getestet.
Inhalt
Teil 1
Teil 2
DVC-Setup
Die Datenversionskontrolle ist ein Tool zum Verwalten von Modell- und Datenversionen in ML-Projekten. Dies ist sowohl in der experimentellen Phase als auch für die Inbetriebnahme Ihrer Modelle nützlich.
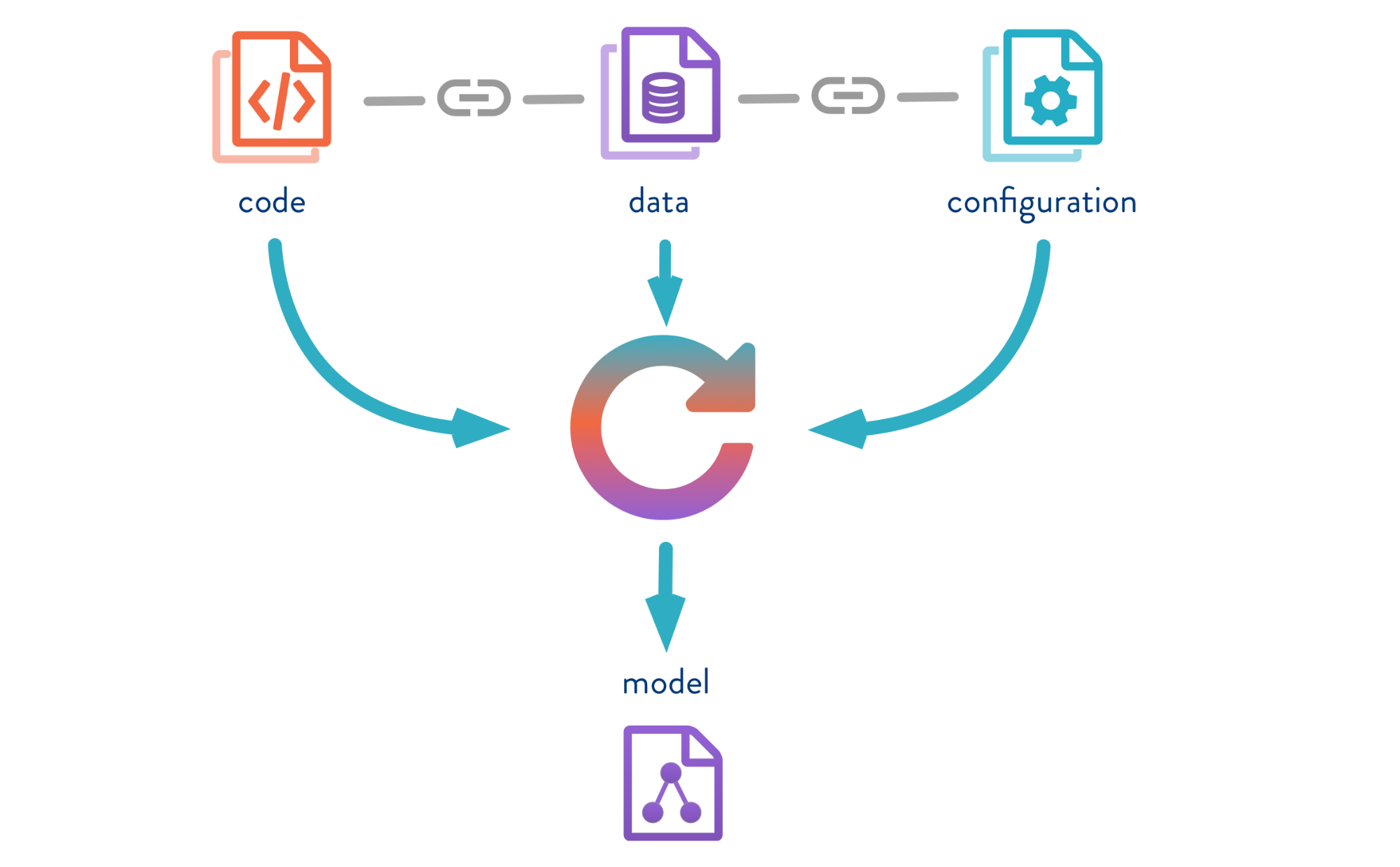
Mit DVC können Sie Modelle, Daten und Pipelines in DS-Projekten versionieren.
Die Quelle ist
hier .
Schauen wir uns die DVC-Operation am Beispiel des Problems der Irisfarbklassifizierung an. Hierzu wird der
Iris-Datensatz verwendet. Weitere
Beispiele für die Arbeit mit DVC zeigt Jupyter Notebook.
Was Sie tun müssen:- ein Repository klonen;
- eine virtuelle Umgebung erstellen;
- Installieren Sie die erforderlichen Python-Pakete.
- DVC initialisieren.
Also klonen wir das Repository, erstellen eine virtuelle Umgebung und installieren die erforderlichen Pakete. Installations- und Startanweisungen befinden sich im README-Repository.
1. Klonen Sie dieses Repository
git clone https://gitlab.com/7labs.ru/tutorials-dvc/dvc-1-get-started.git cd dvc-1-get-started
2. Erstellen und aktivieren Sie die virtuelle Umgebung
pip install virtualenv virtualenv venv source venv/bin/activate
3. Installieren Sie Python-Bibliotheken (einschließlich dvc)
pip install -r requirements.txt
Verwenden Sie zum
pip install dvc Befehl
pip install dvc . Nach der Installation müssen Sie den DVC im
dvc init Projektordner initialisieren, wodurch eine Reihe von Ordnern für die weitere Arbeit von DVC generiert wird.
4. Überprüfen Sie den neuen Zweig im Demo-Repository (um den Inhalt des Hauptzweigs nicht zu löschen).
git checkout -b dvc-tutorial
5. DVC initialisieren
dvc init commit dvc init git commit -m "Initialize DVC"
DVC läuft auf Git, nutzt seine Infrastruktur und hat eine ähnliche Syntax.
Dabei erstellt DVC Metadateien zur Beschreibung von Pipelines und versionierten Dateien, die Sie benötigen, um den Verlauf Ihres Projekts in Git zu speichern. Daher müssen Sie nach dem Ausführen von
dvc init git commit ausführen, um alle vorgenommenen Einstellungen
dvc init .
Der
.dvc Ordner wird in Ihrem Repository
.dvc , in dem sich
cache und
config .
Der Inhalt von
.dvc sieht folgendermaßen aus:
./ ../ .gitignore cache/ config
Config ist die DVC-Konfiguration, und Cache ist der Systemordner, in dem DVC alle Daten und Modelle speichert, die Sie versionieren werden.
DVC erstellt auch eine
.gitignore Datei, in die die Dateien und Ordner geschrieben werden, die nicht in das Repository übernommen werden müssen. Wenn Sie eine Datei zur Versionierung in Git an DVC übertragen, werden Versionen und Metadaten gespeichert und die Datei selbst im Cache gespeichert.
Jetzt müssen Sie alle Abhängigkeiten installieren und dann im neuen Zweig
dvc-tutorial , in dem wir arbeiten werden. Und laden Sie den Iris-Datensatz herunter.
Daten abrufen
wget -P data/ https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
DVC-Funktionen
Versionierung von Modellen und Daten
Die Quelle ist
hier .
Ich möchte Sie daran erinnern, dass, wenn Sie einige Daten unter der Kontrolle von DVC übertragen, alle Änderungen nachverfolgt werden. Und wir können mit diesen Daten genauso arbeiten wie mit Git: Speichern Sie die Version, senden Sie sie an das Remote-Repository, holen Sie sich die richtige Version der Daten, ändern Sie und wechseln Sie zwischen den Versionen. Die Schnittstelle bei DVC ist sehr einfach.
Geben Sie den Befehl
dvc add und geben Sie den Pfad zu der Datei an, die
dvc add . DVC erstellt die Metadatei iris.csv mit der Erweiterung .dvc und schreibt Informationen darüber in den Cache-Ordner. Lassen Sie uns diese Änderungen festschreiben, damit Informationen zu Beginn der Versionierung im Git-Verlauf angezeigt werden.
dvc add data/iris.csv
In der generierten DVC-Datei wird der Hash mit Standardparametern gespeichert.
Output - Der Pfad zur Datei im dvc-Ordner, den wir unter der Kontrolle von DVC hinzugefügt haben. Das System nimmt die Daten, legt sie im Cache ab und erstellt eine Verknüpfung zum Cache im Arbeitsverzeichnis. Diese Datei kann zum Git-Verlauf hinzugefügt und somit versioniert werden. DVC übernimmt die Verwaltung der Daten selbst. Die ersten beiden Zeichen des Hashs werden als Ordner im Cache verwendet, und die verbleibenden Zeichen werden als Name der erstellten Datei verwendet.
 Automatisierung von ML-Pipelines
Automatisierung von ML-PipelinesZusätzlich zur Datenversionskontrolle können wir Pipelines (Pipelines) erstellen - Berechnungsketten, zwischen denen Abhängigkeiten definiert werden. Hier ist die Standard-Pipeline für das Training und die Bewertung von Klassifikatoren:
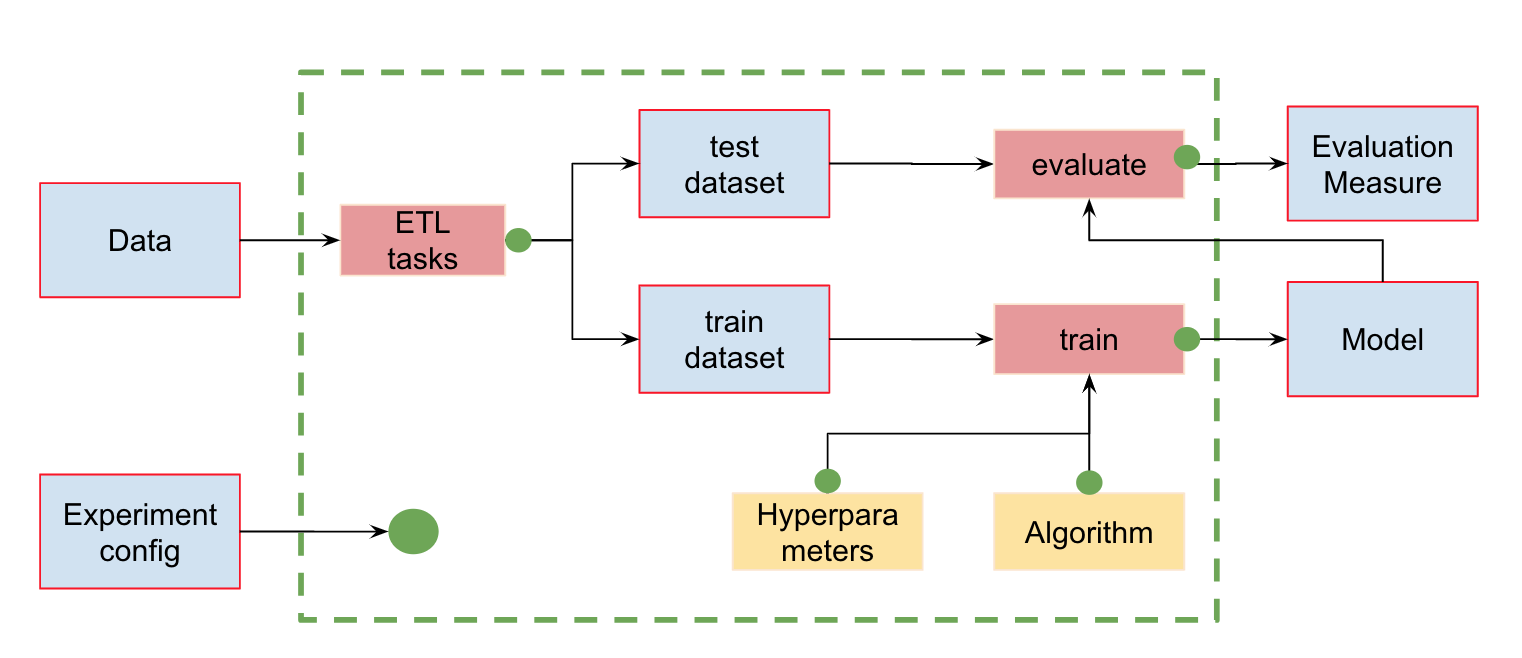
Am Eingang haben wir Daten, die vorverarbeitet, in Zug und Test unterteilt, die Eigenschaften berechnet und erst dann das Modell trainiert und ausgewertet werden müssen. Diese Pipeline kann in separate Teile zerlegt werden. Zum Beispiel, um die Phase des Ladens und Vorverarbeitens von Daten, Aufteilen von Daten, Auswerten usw. und Verbinden dieser Ketten zu unterscheiden.
Zu diesem
dvc run verfügt der DVC über einen wunderbaren
dvc run , in dem wir bestimmte Parameter übergeben und das Python-Modul angeben, das wir ausführen müssen.
Nun - zum Beispiel die Startphase der Zeichenberechnung. Schauen wir uns zunächst den Inhalt des Moduls featureization.py an:
import pandas as pd def get_features(dataset): features = dataset.copy()
Dieser Code nimmt den Datensatz, berechnet die Merkmale und speichert sie in iris_featurized.csv. Wir haben die Berechnung der zusätzlichen Zeichen der nächsten Stufe überlassen.
Um eine Pipeline zu erstellen, müssen Sie den Befehl für jede Stufe der Berechnung ausführen
dvc run .

dvc run Befehl
dvc run den Namen der Metadatei stage_feature_extraction.dvc an, in die der DVC die erforderlichen Metadaten zur Berechnungsstufe schreibt. Über das Argument
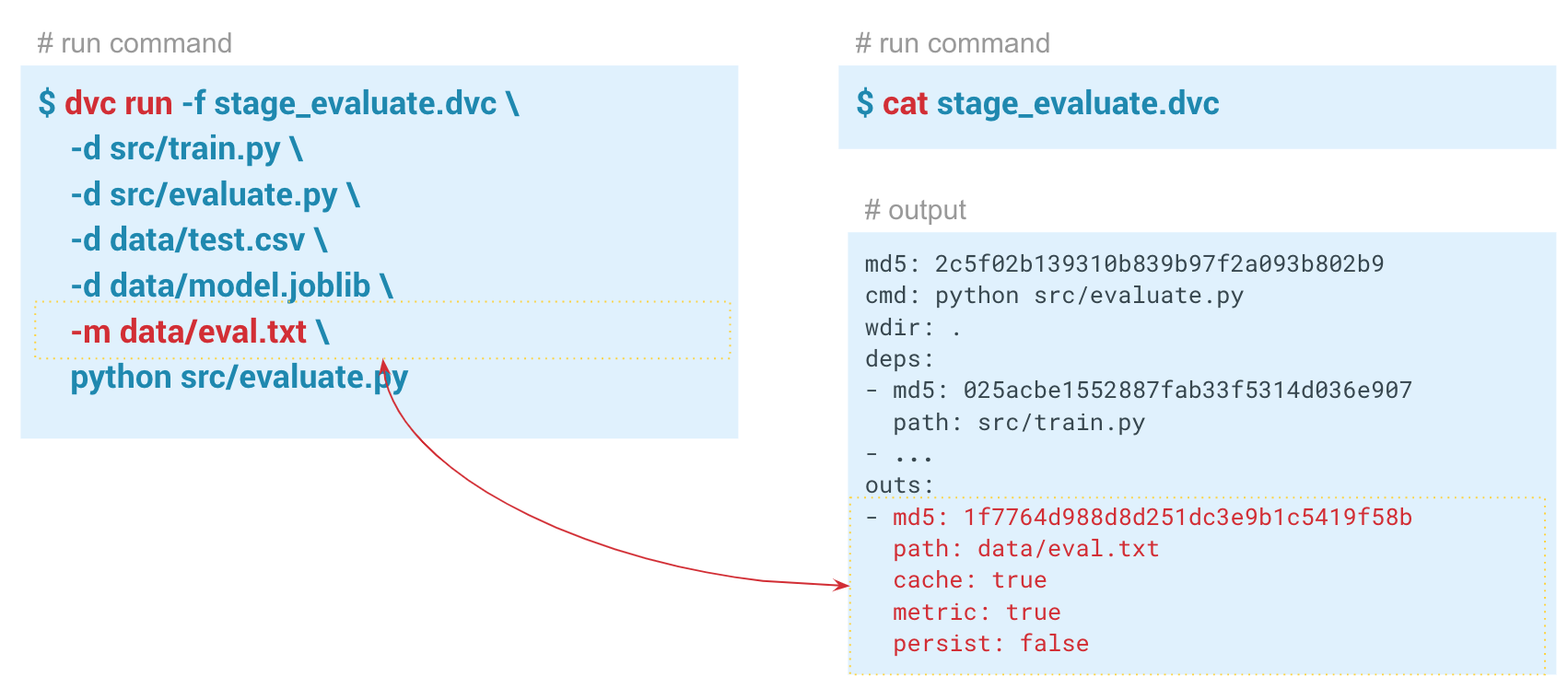
-d geben wir die erforderlichen Abhängigkeiten an: das Modul featureization.py und die Datendatei iris.csv. Wir geben auch die Datei iris_featurized.csv an, in der die Zeichen gespeichert sind, und den Startbefehl python src / featurization.py.
dvc run -f stage_feature_extraction.dvc \ -d src/featurization.py \ -d data/iris.csv \ -o data/iris_featurized.csv \ python src/featurization.py
Der DVC erstellt eine Metadatei und verfolgt Änderungen im Python-Modul und in der Datei iris.csv.
Wenn Änderungen daran auftreten, startet der DVC diesen Berechnungsschritt in der Pipeline neu.
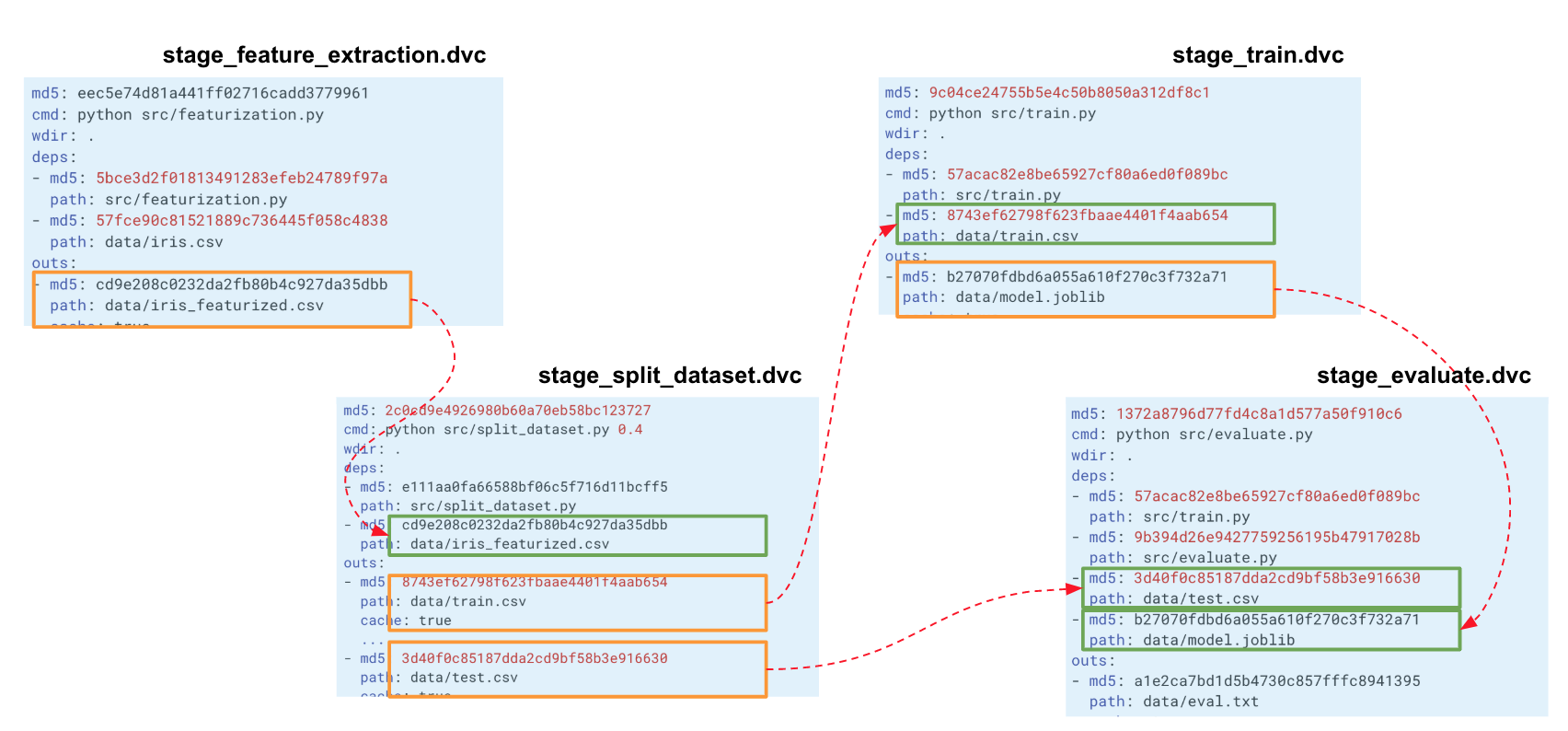
Die resultierende Datei stage_feature_extraction.dvc enthält den Hash, den Startbefehl, die Abhängigkeiten und die Ausgabe (zusätzliche Parameter finden Sie in den Metadaten).
Jetzt müssen Sie diese Datei im Verlauf der Git-Commits speichern. Auf diese Weise können wir einen neuen Zweig erstellen und in das Git-Repository verschieben. Sie können sich auf eine Git-Story festlegen, indem Sie entweder jede Stufe einzeln oder alle Stufen gleichzeitig erstellen.
Wenn wir eine solche Kette für unser gesamtes Experiment erstellen, erstellt DVC einen Berechnungsgraphen (DAG), mit dem entweder die gesamte Pipeline oder ein Teil davon neu berechnet werden kann. Die Hashes des Ausgangs einer Stufe gehen zu den Eingängen einer anderen. Demnach verfolgt DVC Abhängigkeiten und erstellt ein Diagramm mit Berechnungen. Wenn Sie den Code irgendwo in split_dataset.py geändert haben, lädt der DVC die Daten nicht und berechnet möglicherweise die Zeichen neu, sondern startet diese Phase und die nachfolgenden Trainings- und Evaluierungsphasen neu.
 Metrik-Tracking
Metrik-TrackingMit dem Befehl
dvc metrics show können Sie die Metriken des aktuellen Starts anzeigen, des Zweigs, in dem wir uns befinden. Wenn wir die Option
-a , zeigt der DVC alle Metriken an, die sich im Git-Verlauf befinden. Damit DVC mit der Verfolgung von Metriken beginnen kann, übergeben wir beim Erstellen des Auswertungsschritts den Parameter
-m über data / eval.txt. Das Modul evalu.py schreibt Metriken in diese Datei, in diesem Fall
f1 und
confusion metrics . Im Ausgabeordner in der DVC-Datei dieses Schritts werden
cache und
metrics auf true gesetzt. Das heißt, der Befehl dvcmetrics show gibt den Inhalt der Datei eval.txt an die Konsole aus. Mit den Argumenten dieses Befehls können Sie auch nur
f1_score oder nur
confusion_matrix f1_score .
In diesem Beispiel haben wir folgende Ergebnisse erhalten:
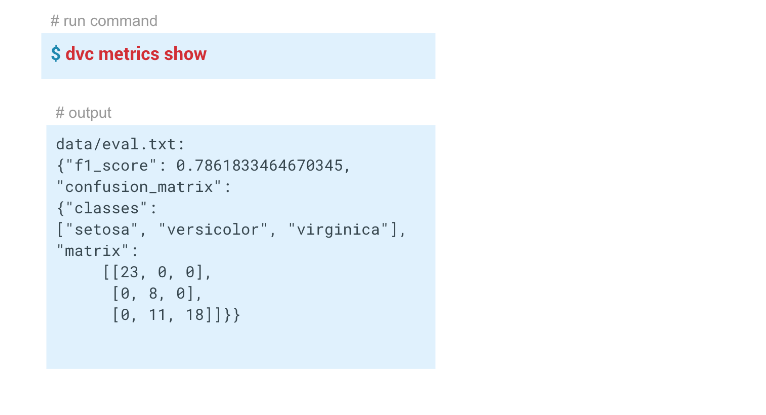 Reproduzierbarkeit der Pipeline
Reproduzierbarkeit der PipelineDiejenigen, die mit diesem Datensatz gearbeitet haben, wissen, dass es sehr schwierig ist, ein gutes Modell darauf aufzubauen.
Jetzt haben wir eine Pipeline mit DVC erstellt. Das System verfolgt den Verlauf der Daten und des Modells, kann sich ganz oder teilweise neu starten und Metriken anzeigen. Wir haben alle notwendigen Automatisierungen abgeschlossen.
Wir hatten ein Modell mit f1 = 0,78. Wir wollen es verbessern, indem wir einige Parameter ändern. Starten Sie dazu im Idealfall die gesamte Pipeline mit einem einzigen Befehl neu. Wenn Sie in einem Team arbeiten, möchten Sie das Modell und den Code möglicherweise an Kollegen weitergeben, damit diese weiter daran arbeiten können.
Mit
dvc repro können
dvc repro Pipelines oder einzelne Stufen neu starten (in diesem Fall müssen Sie die reproduzierte Stufe nach dem Befehl angeben).
dvc repro stage_evaluate versucht die Stufe, die gesamte Pipeline neu zu starten. Wenn wir dies jedoch im aktuellen Status tun, sieht der DVC keine Änderungen und startet nicht neu. Und wenn wir etwas ändern, wird er die Änderung finden und die Pipeline von diesem Moment an neu starten.
$ dvc repro stage_evaluate.dvc Stage 'data/iris.csv.dvc' didn't change. Stage 'stage_feature_extraction.dvc' didn't change. Stage 'stage_split_dataset.dvc' didn't change. Stage 'stage_train.dvc' didn't change. Stage 'stage_evaluate.dvc' didn't change. Pipeline is up to date. Nothing to reproduce.
In diesem Fall hat der DVC keine Änderungen in den Stage_evaluate-Stage-Abhängigkeiten festgestellt und den Neustart abgelehnt. Wenn wir die Option
-f angeben, werden alle vorbereitenden Schritte neu gestartet und eine Warnung angezeigt, dass frühere Versionen der Daten gelöscht werden, aus denen sie verfolgt wurden. Jedes Mal, wenn der DVC die Bühne neu startet, löscht er den vorherigen Cache und überschreibt ihn tatsächlich, um keine Daten zu duplizieren. In dem Moment, in dem die DVC-Datei gestartet wird, wird ihr Hash überprüft. Wenn sie geändert wurde, wird die Pipeline neu gestartet und die gesamte Ausgabe dieser Pipeline überschrieben. Wenn Sie dies vermeiden möchten, müssen Sie zuerst eine bestimmte Version der Daten in einem Remote-Repository ausführen.
Durch die Möglichkeit, Pipelines neu zu starten und die Abhängigkeiten jeder Stufe zu verfolgen, können Sie schneller mit Modellen experimentieren.
Sie können beispielsweise die Merkmale ändern (die Zeilen zur Berechnung der Merkmale in
featurization.py ). DVC erkennt diese Änderungen und startet die gesamte Pipeline neu.
Speichern von Daten in einem Remote-Repository
DVC kann nicht nur mit lokalem Versionsspeicher arbeiten. Wenn Sie den Befehl
dvc push ausführen,
dvc push der DVC die aktuelle Version des Modells und der Daten an ein vorkonfiguriertes Remote-Repository-Repository. Wenn Ihr Kollege dann den
git clone Ihres Repositorys erstellt und
dvc pull , erhält er die Version der Daten und Modelle, die für diesen Zweig bestimmt sind. Die Hauptsache ist, dass jeder Zugriff auf dieses Repository hat.
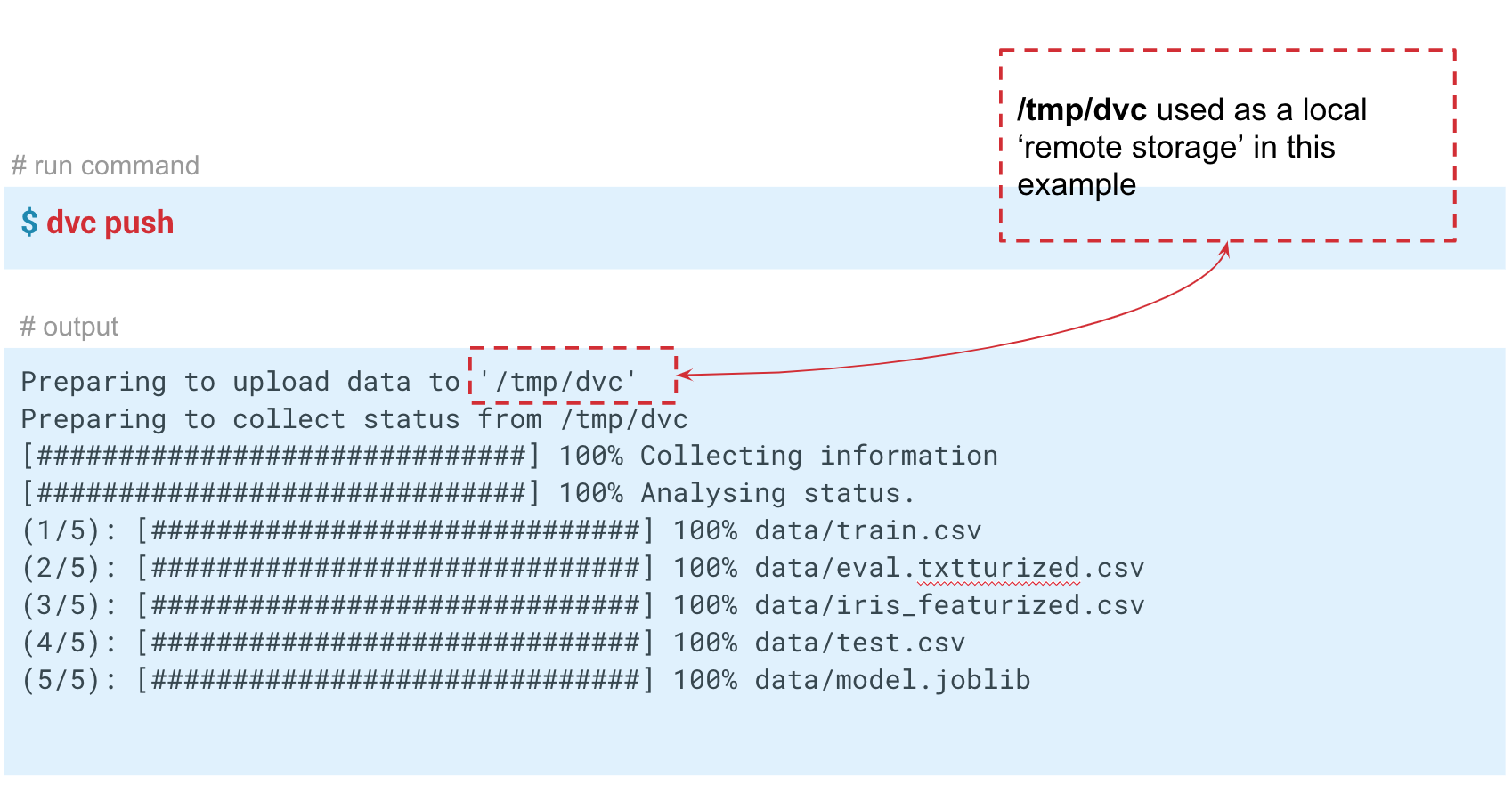
In diesem Fall simulieren wir den „Remote“ -Speicher im Ordner temp / dvc. Auf ungefähr die gleiche Weise wird Remotespeicher in der Cloud erstellt. Übernehmen Sie diese Änderung, damit sie in der Git-Story verbleibt. Jetzt können wir
dvc push um Daten an diesen Speicher zu senden, und Ihr Kollege führt nur
dvc pull , um sie
dvc pull .
Daher haben wir drei Situationen untersucht, in denen DVC und grundlegende Funktionen nützlich sind:
- Versionierung von Daten und Modellen . Wenn Sie keine Pipelines und Remote-Repositorys benötigen, können Sie die Daten für ein bestimmtes Projekt auf dem lokalen Computer versionieren. Mit DVC können Sie schnell mit Daten in zehn Gigabyte arbeiten.
- Austausch von Daten und Modellen zwischen Teams . Sie können Cloud-Lösungen zum Speichern von Daten verwenden. Dies ist eine praktische Option, wenn Sie ein verteiltes Team haben oder die Größe der per E-Mail gesendeten Dateien eingeschränkt ist. Diese Technik kann auch in Situationen verwendet werden, in denen Sie sich gegenseitig ein Notizbuch senden, diese jedoch nicht starten.
- Organisation der Teamarbeit auf einem großen Server . Das Team kann mit der lokalen Version von Big Data arbeiten, z. B. mit mehreren zehn oder hundert Gigabyte, sodass Sie sie nicht hin und her kopieren, sondern einen Remotespeicher verwenden, der nur kritische Versionen von Modellen oder Daten sendet und speichert.
Teil 2
Wie implementiere ich DVC in Ihren Projekten?Um die Reproduzierbarkeit des Projekts zu gewährleisten, müssen bestimmte Anforderungen beachtet werden.
Hier sind die wichtigsten:
- Alle Pipelines sind automatisiert.
- Kontrolle der Startparameter jeder Berechnungsstufe;
- Versionskontrolle von Code, Daten und Modellen;
- Umweltkontrolle;
- die Dokumentation.
Wenn dies alles getan ist, ist es wahrscheinlicher, dass das Projekt reproduzierbar ist. Mit DVC können Sie die ersten drei Anforderungen in dieser Liste erfüllen.
Wenn Sie versuchen, DVC in Ihrem Unternehmen zu implementieren, stoßen Sie möglicherweise auf Zurückhaltung: „Warum brauchen wir das? Wir haben ein Jupyter-Notizbuch. " Vielleicht arbeiten einige Ihrer Kollegen nur mit Jupyter Notebook, und es ist für sie viel schwieriger, solche Pipelines und Code in die IDE zu schreiben. In diesem Fall können Sie eine schrittweise Implementierung durchführen.
- Der einfachste Weg ist die Versionierung des Codes und der Modelle.
Fahren Sie dann mit der Automatisierung der Pipelines fort. - Automatisieren Sie zunächst die Schritte, die häufig neu gestartet und geändert werden.
und dann die ganze Pipeline.
Wenn Sie ein neues Projekt und ein paar Enthusiasten in einem Team haben, ist es besser, sofort DVC zu verwenden. So stellte sich zum Beispiel in unserem Team heraus! Als ich ein neues Projekt startete, unterstützten mich meine Kollegen und wir begannen, DVC selbst zu verwenden. Dann begannen sie mit anderen Kollegen und Teams zu teilen. Jemand hat unser Unternehmen aufgegriffen. DVC ist heute noch kein allgemein anerkanntes Werkzeug in unserer Bank, wird aber in mehreren Projekten eingesetzt.