Hinweis perev. : Wir präsentieren Ihnen technische Details zu den Gründen für den jüngsten Ausfall des Cloud-Dienstes, der von den Entwicklern von Grafana bereitgestellt wird. Dies ist ein klassisches Beispiel dafür, wie eine neue und scheinbar äußerst nützliche Funktion zur Verbesserung der Qualität der Infrastruktur viel Schaden anrichten kann, wenn man die zahlreichen Nuancen ihrer Anwendung in der Realität der Produktion nicht voraussieht. Es ist wunderbar, wenn solche Materialien erscheinen, mit denen Sie nicht nur aus Ihren Fehlern lernen können. Details finden Sie in der Übersetzung dieses Textes vom Vice President of Product von Grafana Labs.
Am Freitag, dem 19. Juli, funktionierte der Hosted Prometheus-Dienst in Grafana Cloud für etwa 30 Minuten nicht mehr. Ich entschuldige mich bei allen Kunden, die unter dem Ausfall gelitten haben. Unsere Aufgabe ist es, die notwendigen Werkzeuge für die Überwachung bereitzustellen, und wir verstehen, dass ihre Unzugänglichkeit Ihr Leben kompliziert. Wir nehmen diesen Vorfall sehr ernst. Dieser Hinweis erklärt, was passiert ist, wie wir darauf reagiert haben und was wir tun, damit dies nicht noch einmal passiert.
Hintergrund
Der von Grafana Cloud gehostete Prometheus-Dienst basiert auf
Cortex , einem CNCF-Projekt zur Erstellung eines horizontal skalierbaren, leicht zugänglichen Prometheus-Dienstes mit mehreren Mandanten. Die Cortex-Architektur besteht aus einer Reihe separater Mikrodienste, von denen jeder seine Funktion erfüllt: Replikation, Speicherung, Anforderungen usw. Cortex wird aktiv weiterentwickelt, bietet ständig neue Möglichkeiten und verbessert die Produktivität. Wir stellen regelmäßig neue Cortex-Releases in Clustern bereit, damit Kunden diese Möglichkeiten nutzen können. Glücklicherweise kann Cortex ohne Ausfallzeiten aktualisiert werden.
Für reibungslose Aktualisierungen benötigt der Ingester Cortex-Dienst während des Aktualisierungsprozesses ein zusätzliches Ingester-Replikat.
( Hinweis : Ingester ist die Kernkomponente von Cortex. Seine Aufgabe besteht darin, einen konstanten Strom von Proben zu sammeln, diese in Prometheus- Blöcken zu gruppieren
und in einer Datenbank wie DynamoDB, BigTable oder Cassandra zu speichern.) Dies ermöglicht älteren Ingestern. Leiten Sie aktuelle Daten an neue Ingester weiter. Es ist erwähnenswert, dass Ingesters Ressourcen fordern. Für ihre Arbeit ist es notwendig, 4 Kerne und 15 GB Speicher pro Pod zu haben, d.h. 25% der Prozessorleistung und des Arbeitsspeichers der Basismaschine bei unseren Kubernetes-Clustern. Im Allgemeinen verfügen wir in einem Cluster normalerweise über viel mehr nicht verwendete Ressourcen als 4 Kerne und 15 GB Arbeitsspeicher, sodass wir diese zusätzlichen Ingester bei Updates problemlos ausführen können.
Es kommt jedoch häufig vor, dass während des normalen Betriebs keine dieser Maschinen über diese 25% der nicht beanspruchten Ressourcen verfügt. Ja, wir streben nicht danach: CPU und Speicher sind für andere Prozesse immer nützlich. Um dieses Problem zu lösen, haben wir uns für die Verwendung von
Kubernetes Pod Priorities entschieden . Die Idee ist, Ingestern eine höhere Priorität als anderen (zustandslosen) Mikrodiensten einzuräumen. Wenn wir einen zusätzlichen (N + 1) Ingester ausführen müssen, zwingen wir vorübergehend andere, kleinere Pods heraus. Diese Pods werden auf freie Ressourcen auf anderen Computern übertragen, sodass ein ausreichend großes „Loch“ zum Starten eines zusätzlichen Ingesters verbleibt.
Am Donnerstag, dem 18. Juli, haben wir vier neue Prioritätsstufen in unseren Clustern eingeführt:
kritisch ,
hoch ,
mittel und
niedrig . Sie wurden etwa eine Woche lang in einem internen Cluster ohne Client-Verkehr getestet. Standardmäßig erhielten Pods ohne bestimmte Priorität eine
mittlere Priorität. Für Ingester wurde eine Klasse mit
hoher Priorität festgelegt.
Kritisch war der Überwachung vorbehalten (Prometheus, Alertmanager, Node-Exporter, Kube-State-Metrics usw.). Unsere Konfiguration ist geöffnet und siehe PR
hier .
Unfall
Am Freitag, dem 19. Juli, startete einer der Ingenieure einen neuen dedizierten Cortex-Cluster für einen großen Kunden. Die Konfiguration für diesen Cluster enthielt nicht die neuen Pod-Prioritäten, daher wurde allen neuen Pods die Standardpriorität "
Medium" zugewiesen.
Der Kubernetes-Cluster verfügte nicht über genügend Ressourcen für den neuen Cortex-Cluster, und der vorhandene Cortex-Produktionscluster wurde nicht aktualisiert (Ingester hatten keine
hohe Priorität). Da die Ingester des neuen Clusters standardmäßig die
mittlere Priorität hatten und die vorhandenen Pods in der Produktion überhaupt ohne Priorität arbeiteten, haben die Ingester des neuen Clusters die Ingester aus dem vorhandenen Cortex-Produktionscluster vertrieben.
ReplicaSet für extrudierten Ingester im Produktionscluster hat einen extrudierten Pod erkannt und einen neuen erstellt, um eine bestimmte Anzahl von Kopien beizubehalten. Der neue Pod wurde standardmäßig auf
mittlere Priorität eingestellt, und der nächste "alte" Ingester in der Produktion verlor Ressourcen. Das Ergebnis war
ein Lawinen-ähnlicher Prozess , der dazu führte, dass alle Pods von Ingester für Cortex-Produktionscluster verdrängt wurden.
Ingester behalten den Status bei und speichern Daten für die letzten 12 Stunden. Dies ermöglicht es uns, sie effizienter zu komprimieren, bevor wir in den Langzeitspeicher schreiben. Zu diesem Zweck sendet Cortex Seriendaten mithilfe einer verteilten Hash-Tabelle (Distributed Hash Table, DHT) und repliziert jede Serie mithilfe der Quorum-Konsistenz im Dynamo-Stil auf drei Ingester. Cortex schreibt keine Daten in Ingesters, die deaktiviert sind. Wenn also eine große Anzahl von Ingestern DHT verlässt, kann Cortex keine ausreichende Replikation der Datensätze bereitstellen, und sie "fallen".
Erkennung und Beseitigung
Neue Prometheus-Benachrichtigungen basierend auf dem "
Fehlerbudget-basierten " (Details erscheinen in einem zukünftigen Artikel) ertönten 4 Minuten nach Beginn des Herunterfahrens. In den nächsten fünf Minuten haben wir eine Diagnose durchgeführt und den zugrunde liegenden Kubernetes-Cluster erweitert, um sowohl neue als auch vorhandene Produktionscluster aufzunehmen.
Fünf Minuten später zeichneten die alten Ingester ihre Daten erfolgreich auf, und die neuen wurden gestartet, und die Cortex-Cluster wurden wieder verfügbar.
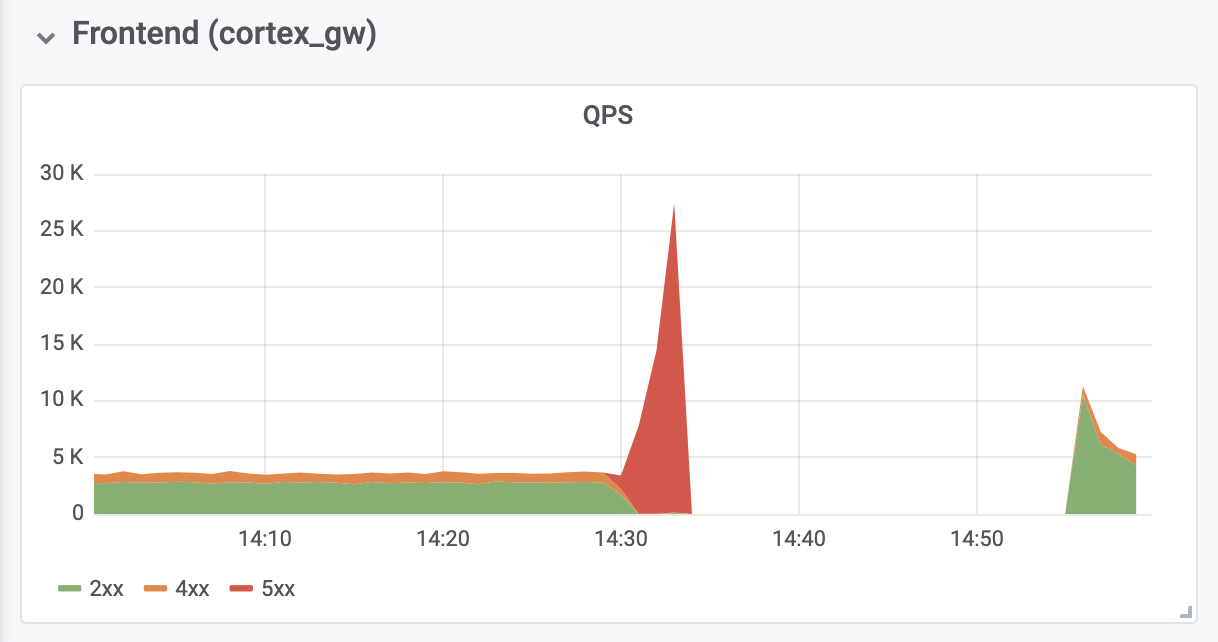
Es dauerte weitere 10 Minuten, um OOM-Fehler (Out-of-Memory) von Reverse-Authentifizierungs-Proxys vor Cortex zu diagnostizieren und zu beheben. OOM-Fehler wurden durch eine Verzehnfachung des QPS verursacht (wie wir glauben, aufgrund übermäßig aggressiver Anforderungen von Prometheus-Client-Servern).
Die Folgen
Die gesamte Ausfallzeit betrug 26 Minuten. Es gingen keine Daten verloren. Ingester haben alle In-Memory-Daten erfolgreich in den Langzeitspeicher hochgeladen. Während eines Herunterfahrens haben die Prometheus-Client-Server die
Remote- Einträge mithilfe der
neuen WAL-basierten
remote_write-API (erstellt von
Callum Styan von Grafana Labs) im
Puffer gespeichert und nach dem Fehler wiederholte fehlgeschlagene Einträge wiederholt.
 Schreibvorgänge für Produktionscluster
Schreibvorgänge für ProduktionsclusterSchlussfolgerungen
Es ist wichtig, aus diesem Vorfall zu lernen und die erforderlichen Schritte zu unternehmen, um eine Wiederholung zu vermeiden.
Rückblickend müssen wir zugeben, dass wir die Standardpriorität nicht auf
mittel setzen sollten, bis alle Ingester in der Produktion eine
hohe Priorität erhalten haben. Außerdem hätten sie sich im Voraus um ihre
hohe Priorität kümmern müssen. Jetzt ist alles repariert. Wir hoffen, dass unsere Erfahrung anderen Organisationen helfen wird, die Verwendung von Pod-Prioritäten in Kubernetes in Betracht zu ziehen.
Wir werden eine zusätzliche Kontrollebene über die Bereitstellung zusätzlicher Objekte hinzufügen, deren Konfigurationen für den Cluster global sind. Von nun an werden solche Änderungen von mehr Personen bewertet. Darüber hinaus wurde die Änderung, die zum Fehler führte, für ein separates Projektdokument als zu unbedeutend angesehen - sie wurde nur in der GitHub-Ausgabe behandelt. Von nun an werden alle derartigen Konfigurationsänderungen von einer entsprechenden Projektdokumentation begleitet.
Schließlich automatisieren wir die Größenänderung des Proxys für die umgekehrte Authentifizierung, um OOM während einer Überlastung zu verhindern, die wir beobachtet haben, und analysieren die Standardeinstellungen von Prometheus in Bezug auf Rollback und Skalierung, um ähnliche Probleme in Zukunft zu vermeiden.
Der erlebte Fehler hatte auch einige positive Konsequenzen: Nach Erhalt der erforderlichen Ressourcen erholte sich Cortex automatisch ohne zusätzliche Intervention. Wir haben auch wertvolle Erfahrungen mit
Grafana Loki gesammelt , unserem neuen Protokollaggregationssystem, mit dessen Hilfe sichergestellt wurde, dass sich alle Ingester während und nach dem Absturz ordnungsgemäß verhalten haben.
PS vom Übersetzer
Lesen Sie auch in unserem Blog: