Vor jedem Dienst, der mindestens 1 MBit / s Internetverkehr generiert, stellt sich die Frage: „Wie? über TCP oder über UDP? " In Anwendungsbereichen, einschließlich Bereitstellungsplattformen, haben sich bereits Präferenzen und Traditionen für solche Entscheidungen entwickelt.
Wenn beispielsweise ein fauler Entwickler nicht einmal versucht hätte, seine ML in Python bereitzustellen (weil er es nur wusste), wäre die Welt theoretisch höchstwahrscheinlich nie von einer solchen Liebe für die verabscheuungswürdige Sprache der „Super-Java-Encoder“ erfüllt worden. Und heute haben die Schwächen dieser Sprache im früheren Anwendungskontext bedingungslos Vorrang bei der Bereitstellung und dem Start zahlreicher Mining-A / B.
Sie können viel vergleichen: ARM mit Intel, iOS und Android und Mortal Kombat mit Injustice. Und stoßen Sie auf einen Weltraum-Holivar, also zurück zum Thema der Bereitstellung großer Mengen von Inhalten mit mehreren Formaten.
Vor zehn Jahren war sich jeder absolut sicher, dass es bei UDP um nicht garantierte Lieferung geht. Wenn Sie ein zuverlässiges Protokoll benötigen, ist es TCP. Und entgegen der Tradition in diesem Artikel werden wir scheinbar unvergleichliche Dinge wie TCP und UDP vergleichen.
 Achtung, unter dem Schnitt 99 Abbildungen und Diagramme und alles Wichtige.
Achtung, unter dem Schnitt 99 Abbildungen und Diagramme und alles Wichtige.Der Vergleich wird vom Entwicklungsleiter der Video- und Tape-Plattformen in OK
Alexander Tobol (
alatobol ) durchgeführt. Die Video- und Newsfeed-Dienste im sozialen Netzwerk OK - ausschließlich über Inhalte und deren Bereitstellung auf allen vorhandenen Client-Plattformen unter schlechten oder ausgezeichneten Netzwerkbedingungen, und die Frage, wie diese über TCP oder UDP bereitgestellt werden sollen, sind von entscheidender Bedeutung.
TCP gegen UDP. Minimale Theorie
Um zum Vergleich zu gelangen, brauchen wir eine kleine Grundtheorie.
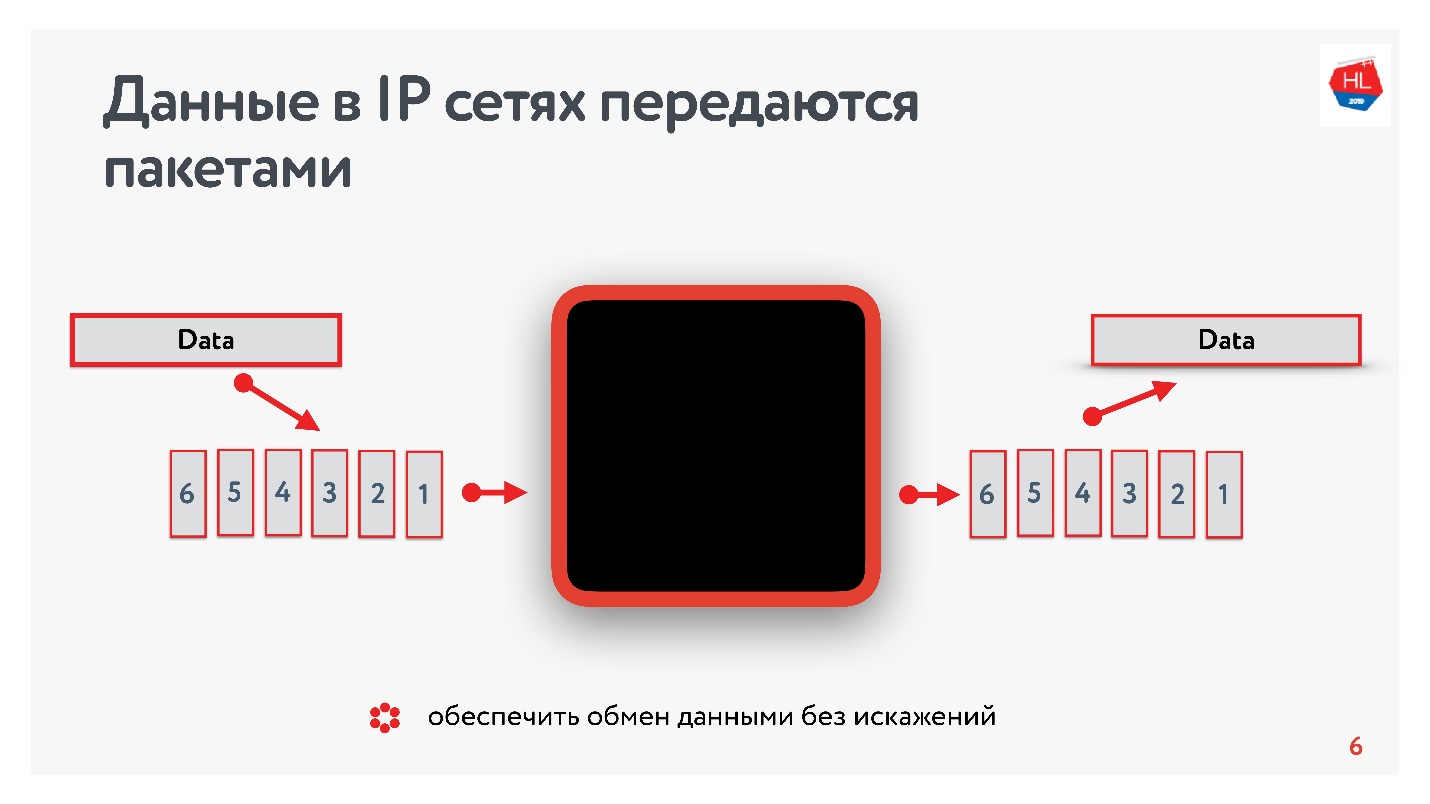
Was wissen wir über IP-Netzwerke? Der von Ihnen gesendete Datenstrom ist in Pakete unterteilt. Eine Art Black Box liefert diese Pakete an den Client. Der Client sammelt Pakete und empfängt einen Datenstrom. Normalerweise ist dies alles transparent und es besteht kein Grund zu überlegen, was sich auf den unteren Ebenen befindet.
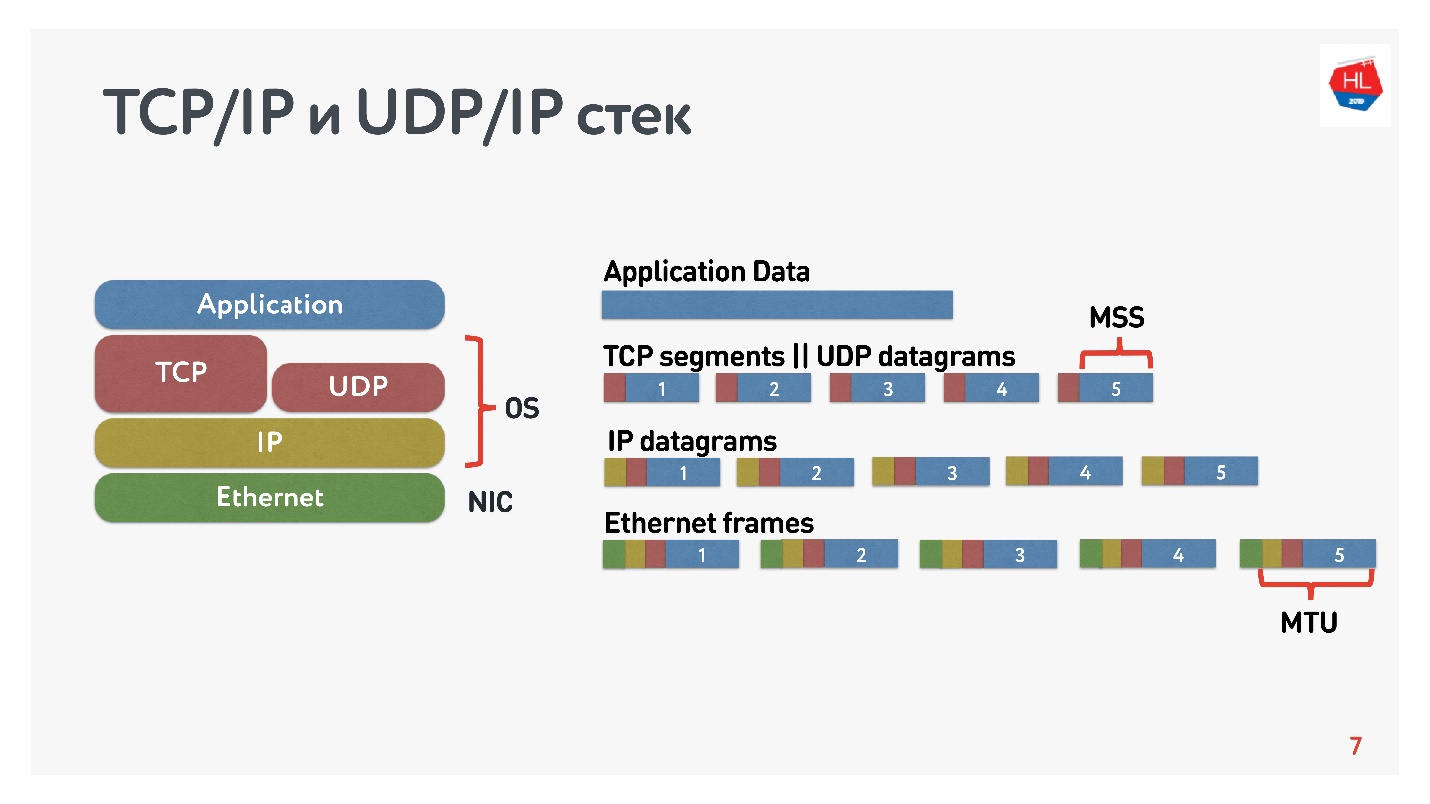
Das Diagramm zeigt den TCP / IP- und UDP / IP-Stack. Unten befinden sich Ethernet-Pakete, IP-Pakete und auf Betriebssystemebene TCP und UDP. TCP und UDP in diesem Stapel unterscheiden sich nicht sehr voneinander. Sie sind in IP-Paketen gekapselt und können von Anwendungen verwendet werden. Um die Unterschiede zu erkennen, müssen Sie sich die TCP- und UDP-Pakete ansehen.
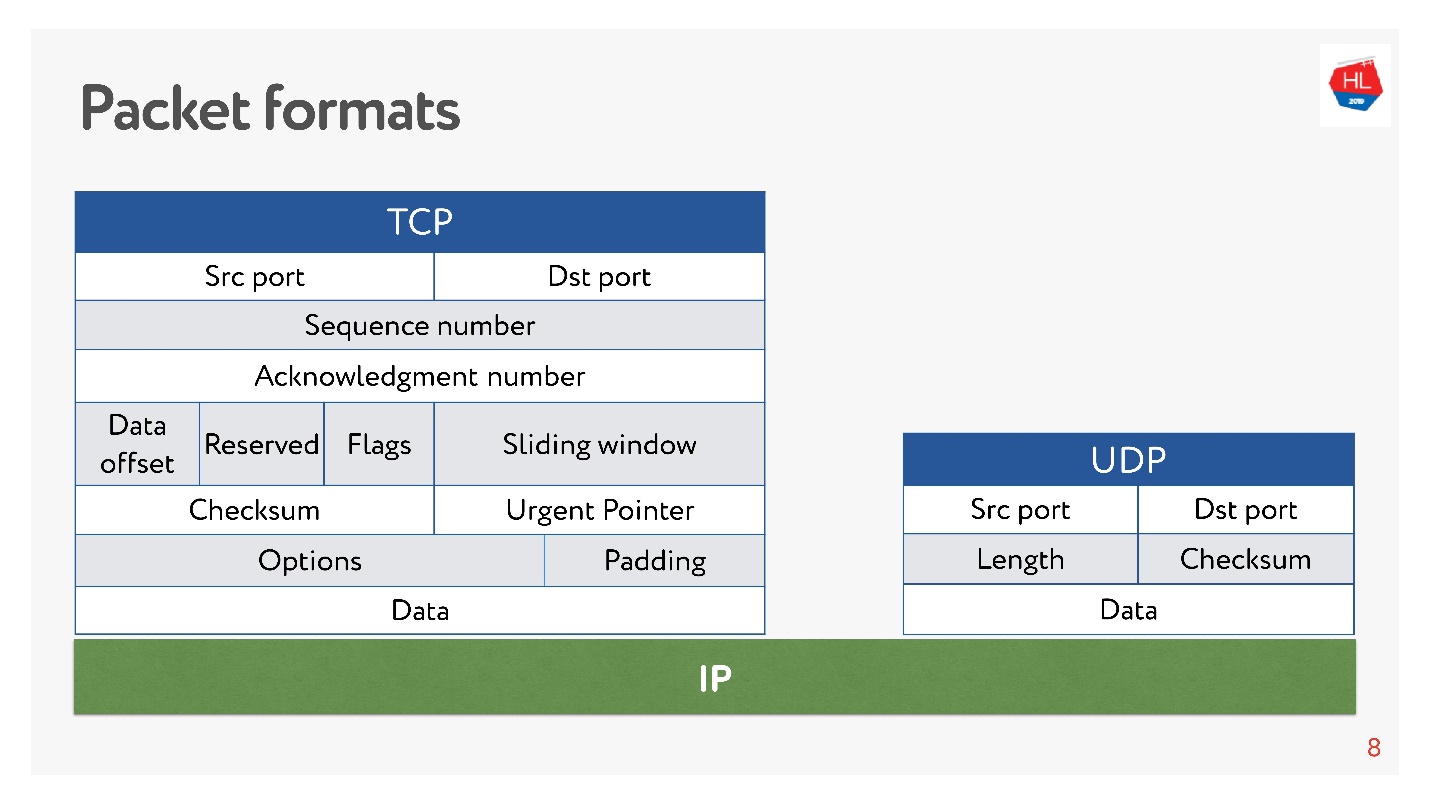
Sowohl dort als auch dort gibt es Ports.
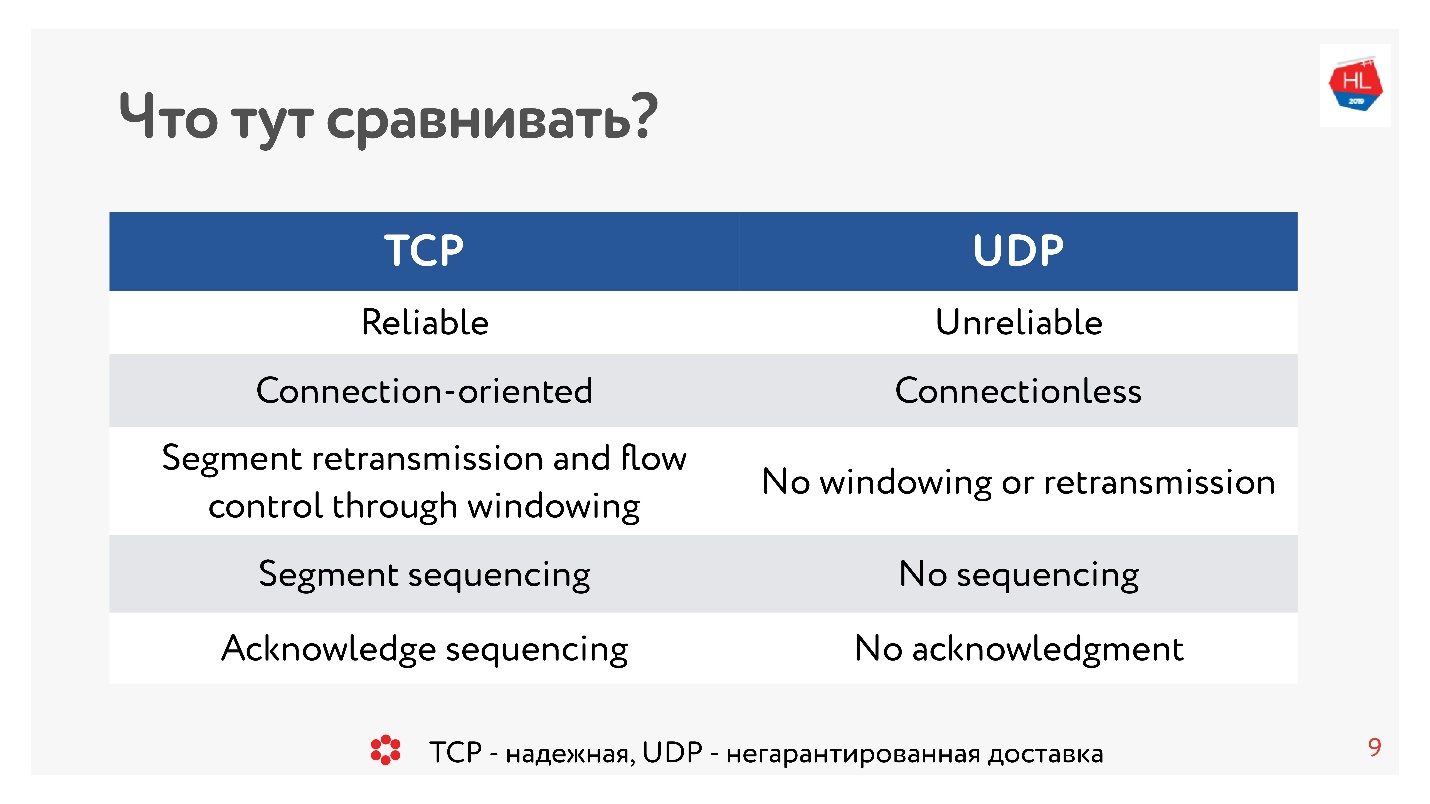
In UDP gibt es jedoch nur eine Prüfsumme - die Paketlänge, dieses Protokoll ist so einfach wie möglich. Und in TCP gibt es viele Daten, die das Fenster, die Bestätigung, die Sequenz, die Pakete usw. klar anzeigen. Offensichtlich ist
TCP komplexer .
Ganz grob gesagt ist TCP ein zuverlässiges Übermittlungsprotokoll und UDP ein unzuverlässiges.
Trotz der angeblichen Unzuverlässigkeit von UDP werden wir herausfinden, ob es möglich ist, Daten schneller und zuverlässiger zu liefern als mit TCP. Lassen Sie uns versuchen, das Netzwerk von innen zu betrachten und zu verstehen, wie es funktioniert. Auf dem Weg werden wir die folgenden Fragen ansprechen:
- Warum TCP vergleichen oder was ist daran falsch?
- womit und womit sollten Sie TCP vergleichen?
- Was hat Google getan und welche Entscheidung hat es getroffen?
- Was erwartet uns die Zukunft der Netzwerkprotokolle?
Dieser Artikel wird keine Theorie haben: OSI-Ebenen und -Modelle, komplexe mathematische Modelle, obwohl alles durch sie gezählt werden kann. Wir werden maximal analysieren, wie man das Netzwerk nicht theoretisch, sondern mit eigenen Händen berührt.
Warum TCP vergleichen oder was daran falsch ist?
TCP wurde 1974 erfunden und 20 Jahre später, als ich zur Schule ging, kaufte ich Internetkarten, löschte den Code und rief irgendwo an. Wenn Sie von 2 Nächten bis 7 Uhr morgens anrufen, war das Internet kostenlos, aber es war schwierig, durchzukommen.
Weitere 20 Jahre vergingen, und Benutzer in mobilen drahtlosen Netzwerken setzten sich gegen „verkabelte“ Benutzer durch, während sich TCP konzeptionell nicht änderte.
Die mobile Welt gewann, drahtlose Protokolle erschienen und TCP blieb unverändert.
Heutzutage verwenden 80% der Benutzer Wi-Fi oder ein drahtloses 3G-4G-Netzwerk.

In drahtlosen Netzwerken gibt es:
- Paketverlust - Ungefähr 0,6% der von uns gesendeten Pakete gehen unterwegs verloren.
- Neuordnung - Neuordnung von Paketen an Orten im wirklichen Leben ist ein eher seltenes Phänomen, das jedoch in 0,2% der Fälle auftritt.
- Jitter - wenn Pakete gleichmäßig gesendet werden und mit einer Verzögerung von ca. 50 ms in Warteschlangen eintreffen.
TCP verbirgt erfolgreich alle diese Funktionen der Datenübertragung in heterogenen Netzwerken vor Ihnen, und Sie müssen nicht eintauchen.
Unten auf der Karte ist die durchschnittliche TCP-Datenrate in Russland angegeben. Wenn Sie den westlichen Teil entfernen, ist klar, dass die Geschwindigkeit mehr in Kilobit als in Megabit gemessen wird.
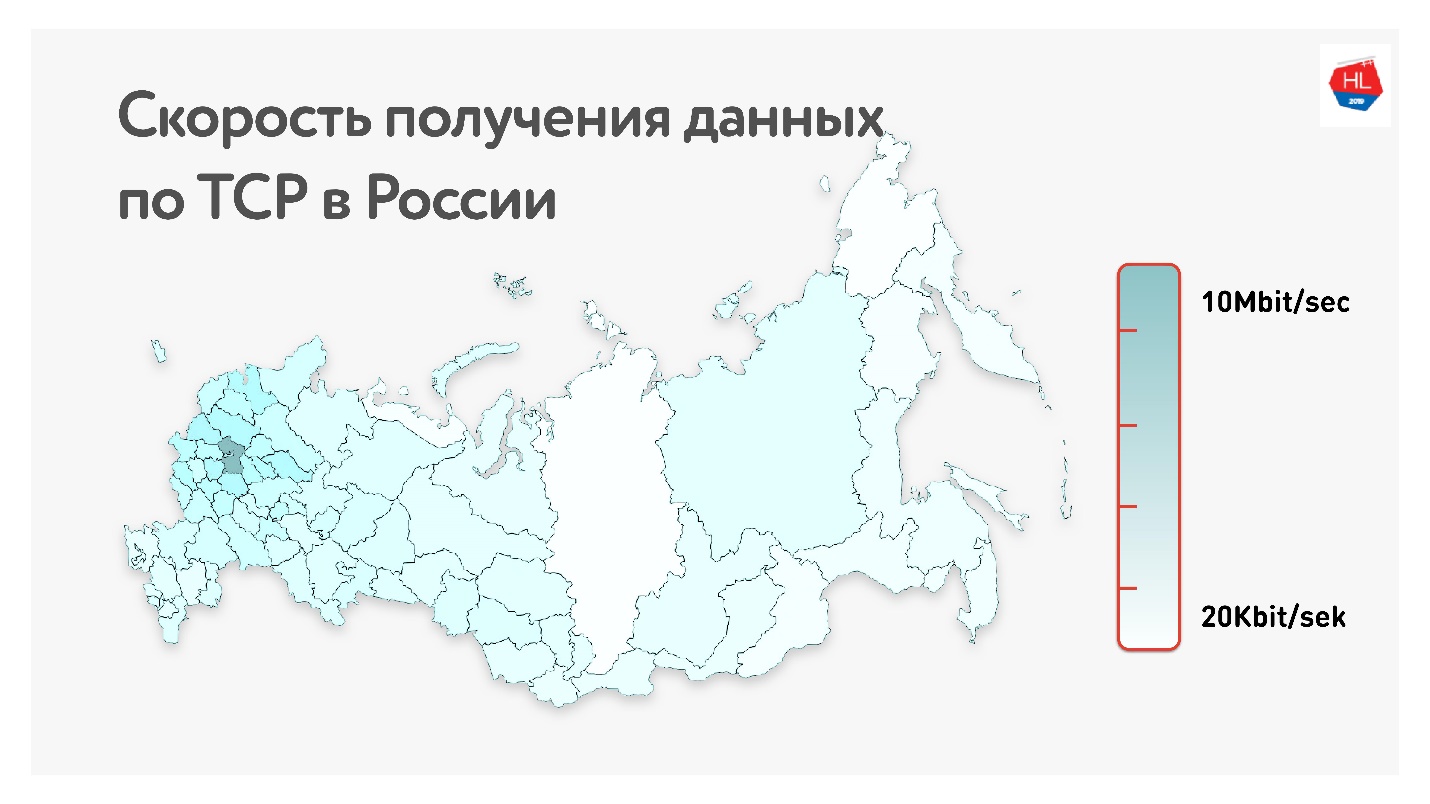
Das ist im Durchschnitt für unsere Benutzer (ohne den westlichen Teil Russlands): Durchsatz 1,1 Mbit / s, 0,6% Paketverlust, RTT (Round-Trip-Zeit) von etwa 200 ms.
Wie berechnet man die RTT?
Als ich den Durchschnitt von 200 ms sah, dachte ich, dass es einen Fehler in der Statistik gab, und entschied mich, die RTT für unsere Server in der MSC auf alternative Weise mithilfe von RIPE Atlas zu messen. Dies ist ein System zum Sammeln von Daten über den Zustand des Internets. Die
RIPE Atlas- Sonde ist kostenlos erhältlich.
Das Fazit ist, dass Sie es mit Ihrem Heim-Internet verbinden und „Karma“ sammeln. Sie arbeitet tagelang, einige Leute erfüllen einige ihrer Anfragen an sie. Dann können Sie selbst verschiedene Aufgaben einstellen. Ein Beispiel für eine solche Aufgabe: Nehmen Sie versehentlich 30 Punkte im Internet und fragen Sie nach der RTT-Messung, dh führen Sie den Ping-Befehl auf der Odnoklassniki-Website aus.
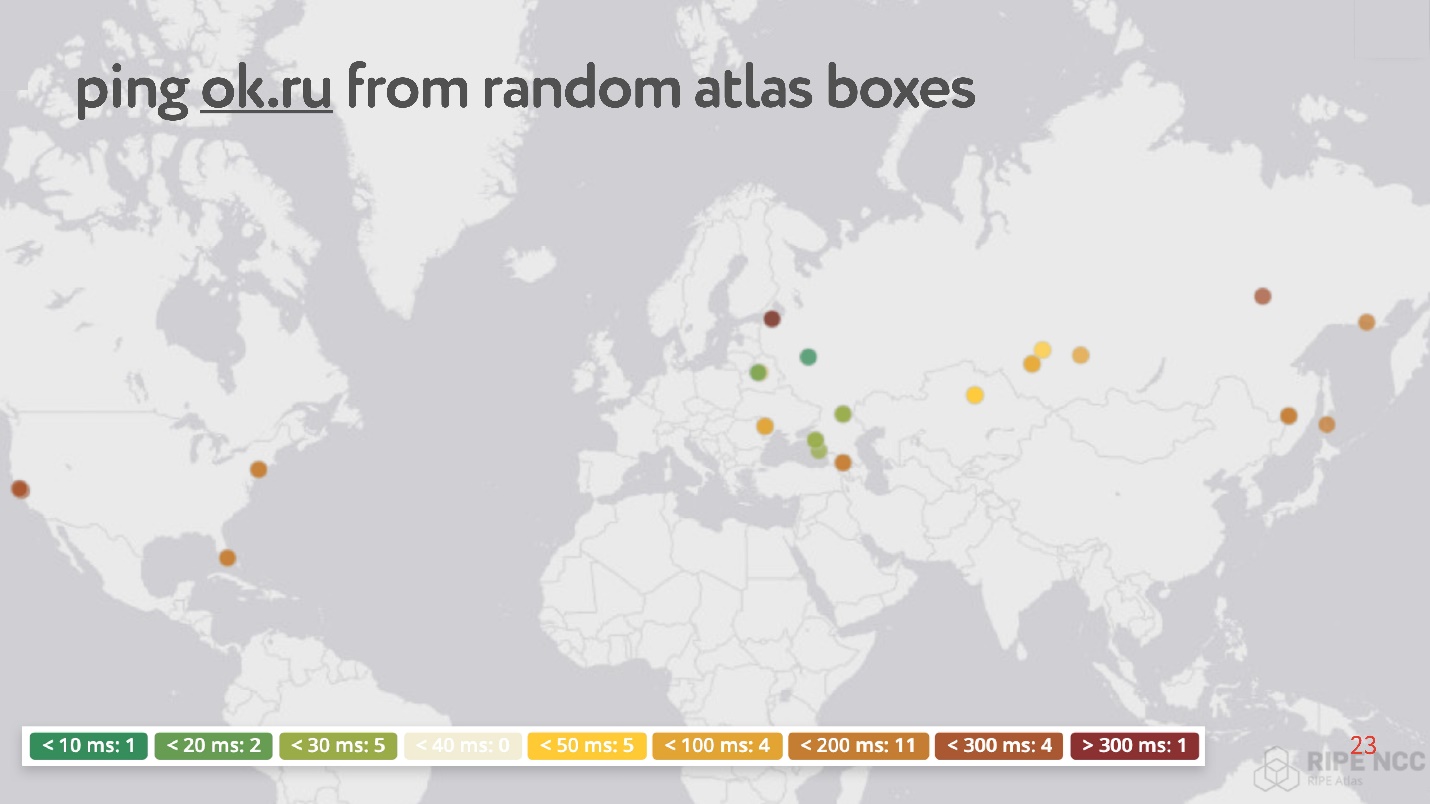
Seltsamerweise gibt es unter zufälligen Punkten viele solche, die einen Ping von 200 bis 300 ms haben.
Insgesamt sind
drahtlose Netzwerke beliebt und instabil (obwohl letzteres normalerweise ignoriert wird, da angenommen wird, dass TCP damit umgehen kann):
- Über 80% der Benutzer nutzen das drahtlose Internet.
- Die Parameter von drahtlosen Netzwerken ändern sich dynamisch, beispielsweise abhängig von der Tatsache, dass der Benutzer um die Ecke gegangen ist.
- Drahtlose Netzwerke weisen eine hohe Rate an Paketverlust, Jitter und Neuordnung auf.
- Asymmetrischer Kanal behoben, Änderung der IP-Adresse.
Der Verbrauch von Inhalten hängt von der Internetgeschwindigkeit ab
Dies ist sehr einfach zu überprüfen - es gibt viele Statistiken. Ich habe
Statistiken zu dem Video erstellt. Je höher die Internetgeschwindigkeit im Land, desto mehr Benutzer sehen sich das Video an.
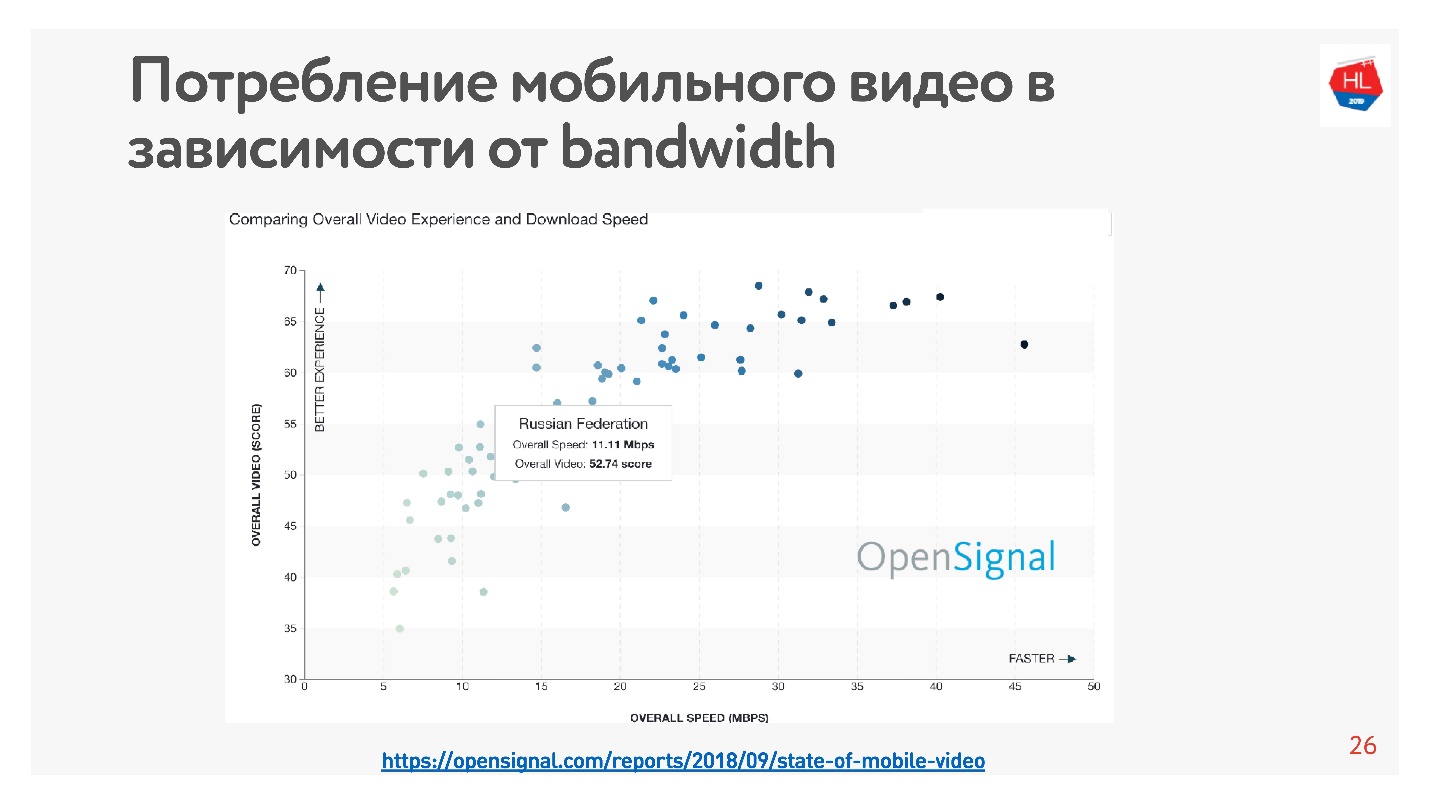
Nach diesen Statistiken hat Russland ein ziemlich schnelles Internet, aber nach unseren internen Daten ist die Durchschnittsgeschwindigkeit etwas niedriger.
Für die Tatsache, dass die Internetgeschwindigkeit insgesamt nicht ausreicht, heißt es, dass alle Entwickler großer Anwendungen, sozialer Netzwerke, Videodienste usw. ihre Dienste für die Arbeit in einem schlechten Netzwerk optimieren. Nach 10 KB empfangener Daten sehen Sie ein Minimum an Informationen auf dem Band, und bei einer Geschwindigkeit von 500 KB können Sie Videos ansehen.
So beschleunigen Sie das Laden
Bei der Entwicklung der Videoplattform haben wir festgestellt, dass TCP in drahtlosen Netzwerken nicht sehr effektiv ist. Wie sind Sie zu diesem Schluss gekommen?
Wir beschlossen, den Download zu beschleunigen und machten den nächsten Trick.
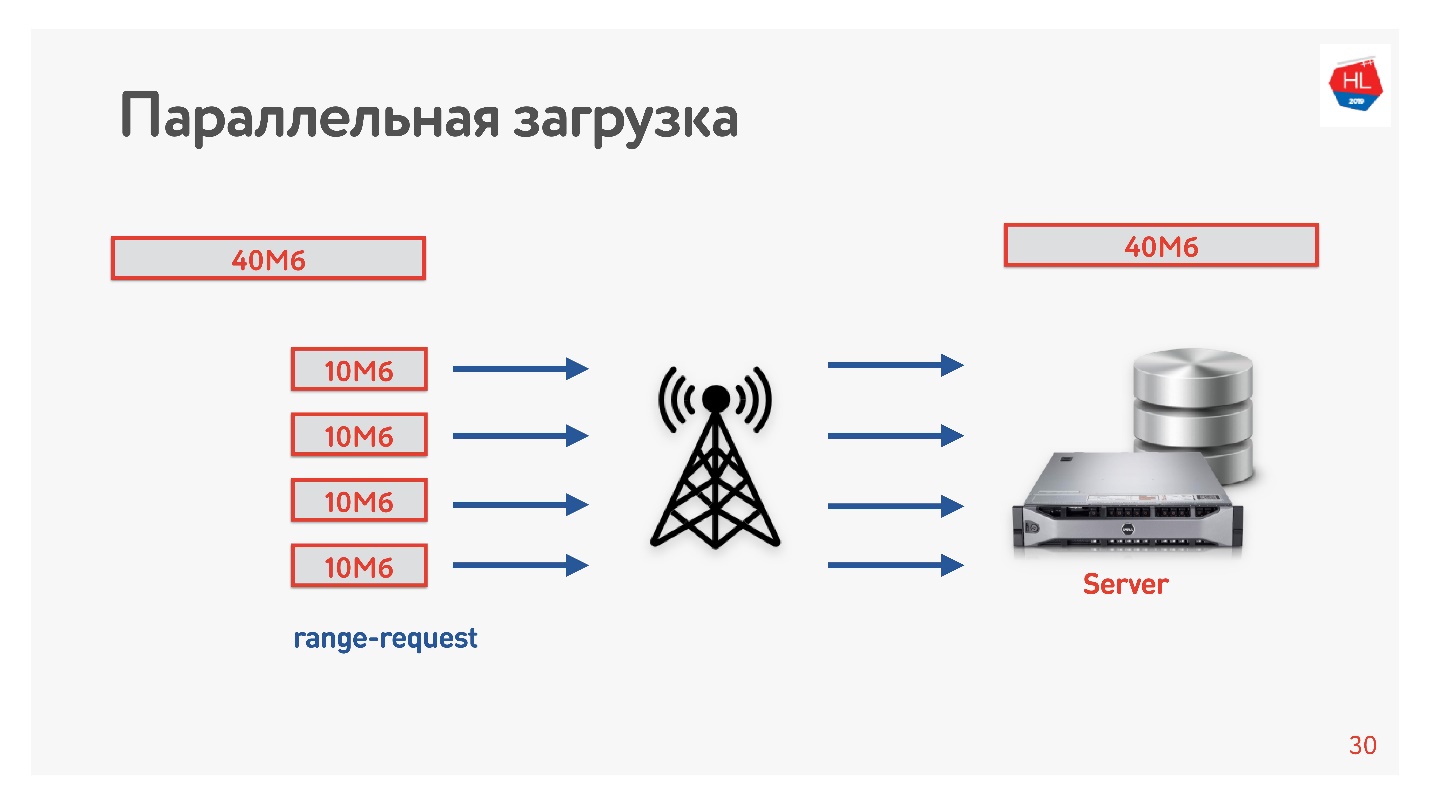
Wir haben das Video in mehreren Streams vom Client auf den Server heruntergeladen, dh 40 MB werden in 4 Teile von 10 MB aufgeteilt und parallel geladen. Wir haben es auf Android gestartet und festgestellt, dass es parallel schneller geladen wird als in einer Verbindung (
Demo im Bericht). Das Interessanteste ist, dass wir bei der Einführung paralleler Downloads in der Produktion festgestellt haben, dass sich die Download-Geschwindigkeit in einigen Regionen verdreifacht hat!
Vier TCP-Verbindungen können tatsächlich dreimal schneller Daten auf den Server hochladen.
Deshalb haben wir die Download-Geschwindigkeit für Videos erhöht und sind zu dem Schluss gekommen, dass der Download parallelisiert werden muss.
TCP in instabilen Netzwerken
Ein unglaublicher Effekt mit Parallelität kann berührt werden. Es reicht aus, einen Geschwindigkeitsmesser zum Empfangen / Senden von Daten (z. B. Geschwindigkeitstest) und Traffic Shaper (z. B. Network Link Conditioner, wenn Sie einen Mac haben) zu verwenden. Wir beschränken das Netzwerk auf 1-Mbit / s-Parameter zum Hoch- und Herunterladen und beginnen, den Paketverlust zu erhöhen.

Die Tabelle zeigt RTT und Verluste. Es ist ersichtlich, dass im Falle eines Verlusts von 0% das Netzwerk zu 100% ausgelastet ist.
Bei der nächsten Iteration erhöhen wir den Paketverlust um 5% und sehen, dass das Netzwerk nur zu 74% ausgelastet ist. Es scheint in Ordnung zu sein - bei einem Paketverlust von 5% gehen 26% des Netzwerks verloren. Wenn Sie jedoch auch den Ping erhöhen, bleibt
weniger als die Hälfte des Kanals übrig.
Wenn der Kanal eine hohe RTT und einen großen Paketverlust aufweist, nutzt eine TCP-Verbindung das Netzwerk nicht vollständig aus.
Ein weiterer Trick zeigt, dass Sie bei Verwendung paralleler TCP-Verbindungen (Sie können nur mehrere Geschwindigkeitstests gleichzeitig ausführen) das umgekehrte Wachstum der Kanalauslastung feststellen können.
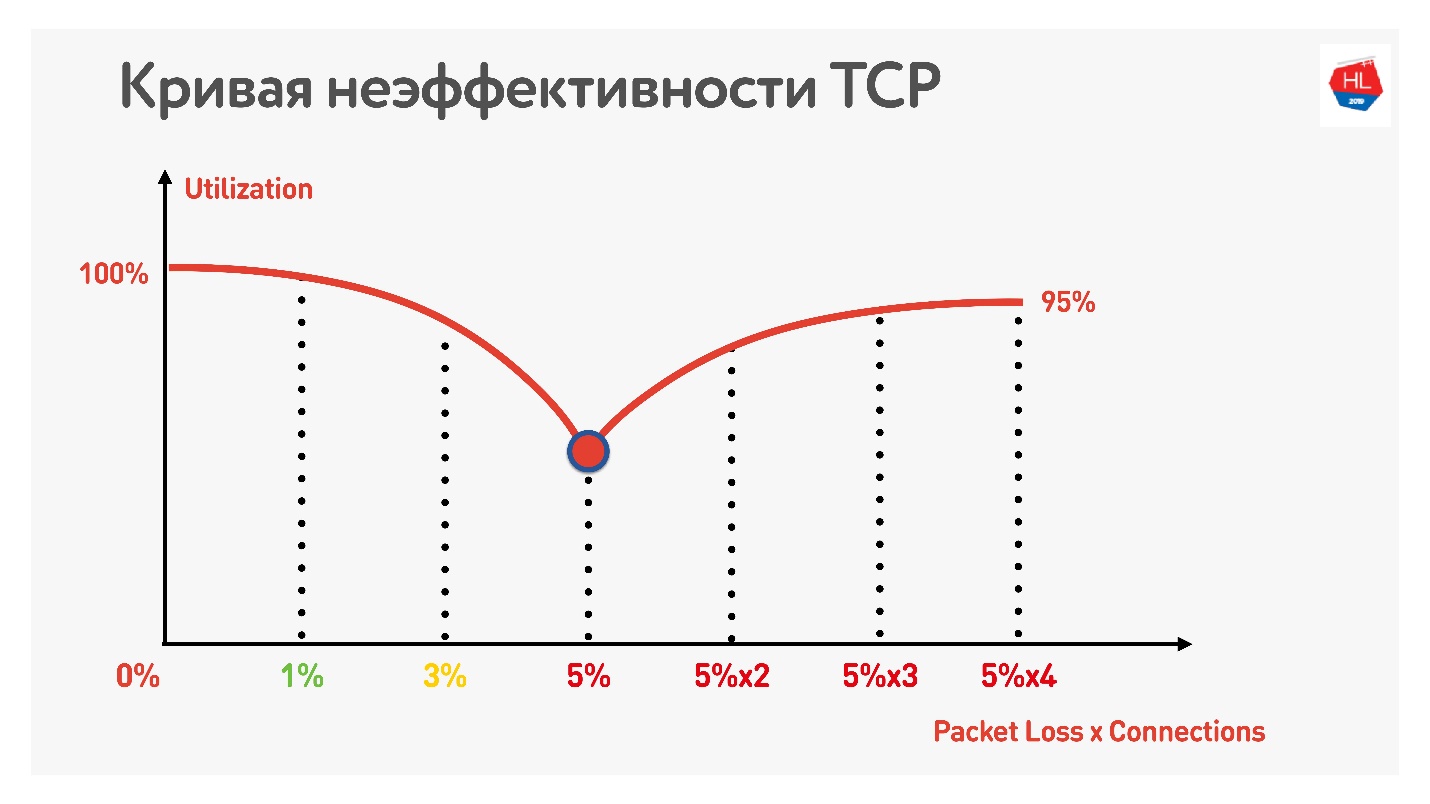
Mit zunehmender Anzahl paralleler TCP-Verbindungen entspricht die Netzwerkauslastung fast dem Durchsatz abzüglich des Prozentsatzes der Verluste.
So stellte sich heraus:
- Drahtlose Mobilfunknetze haben gewonnen und sind instabil.
- TCP nutzt den Kanal in instabilen Netzwerken nicht vollständig aus.
- Der Verbrauch von Inhalten hängt von der Geschwindigkeit des Internets ab: Je höher die Geschwindigkeit des Internets, desto mehr Benutzer sehen zu, und wir lieben unsere Benutzer wirklich und möchten, dass sie mehr sehen.
Natürlich müssen Sie irgendwohin ziehen und Alternativen zu TCP in Betracht ziehen.
TCP gegen nicht TCP
Wie vergleiche ich die Wärme? Es gibt zwei Möglichkeiten.
Die erste Option - auf IP-Ebene gibt es TCP und UDP. Wir können uns ein anderes Protokoll von oben leisten. Wenn Sie Ihr eigenes Protokoll parallel zu TCP und UDP starten, wissen Firewall, Brandmauer, Router und der Rest der Welt, die an der Paketzustellung beteiligt sind, offensichtlich nichts davon. Infolgedessen müssen Sie jahrelang warten, bis alle Geräte aktualisiert sind und mit dem neuen Protokoll arbeiten.
Die zweite Möglichkeit besteht darin, zusätzlich zu unzuverlässigem UDP ein eigenes zuverlässiges Datenübermittlungsprotokoll zu erstellen. Natürlich können Sie lange warten, bis Linux, Android und iOS Ihrem Kernel ein neues Protokoll hinzufügen. Daher müssen Sie das Protokoll in den User Space schneiden.
Diese Lösung scheint interessant zu sein, wir werden sie als selbst erstelltes UDP-Protokoll bezeichnen. Um mit der Entwicklung zu beginnen, benötigen Sie nichts Besonderes: Öffnen Sie einfach den UDP-Socket und senden Sie die Daten.
Wir werden es entwickeln und untersuchen, wie das Netzwerk funktioniert.
TCP gegen selbst erstelltes UDP
Nun, und was zu vergleichen?
Netzwerke sind unterschiedlich:
- Bei Überlastung, wenn es viele Pakete gibt und einige von ihnen aufgrund einer Überlastung von Kanälen oder Geräten fallen.
- Hohe Geschwindigkeit mit großer Hin- und Rückfahrt (z. B. wenn der Server relativ weit entfernt ist).
- Seltsam - wenn im Netzwerk nichts zu passieren scheint, Pakete jedoch immer noch verschwinden, nur weil sich der Wi-Fi-Zugangspunkt hinter der Wand befindet.
Sie können Netzwerkprofile jederzeit selbst berühren: Wählen Sie das eine oder andere Profil auf Ihrem Telefon aus und führen Sie den Geschwindigkeitstest aus.

Neben Netzwerkprofilen müssen Sie auch das Profil des Verkehrsverbrauchs ermitteln. Hier sind die, die wir verwendet haben:
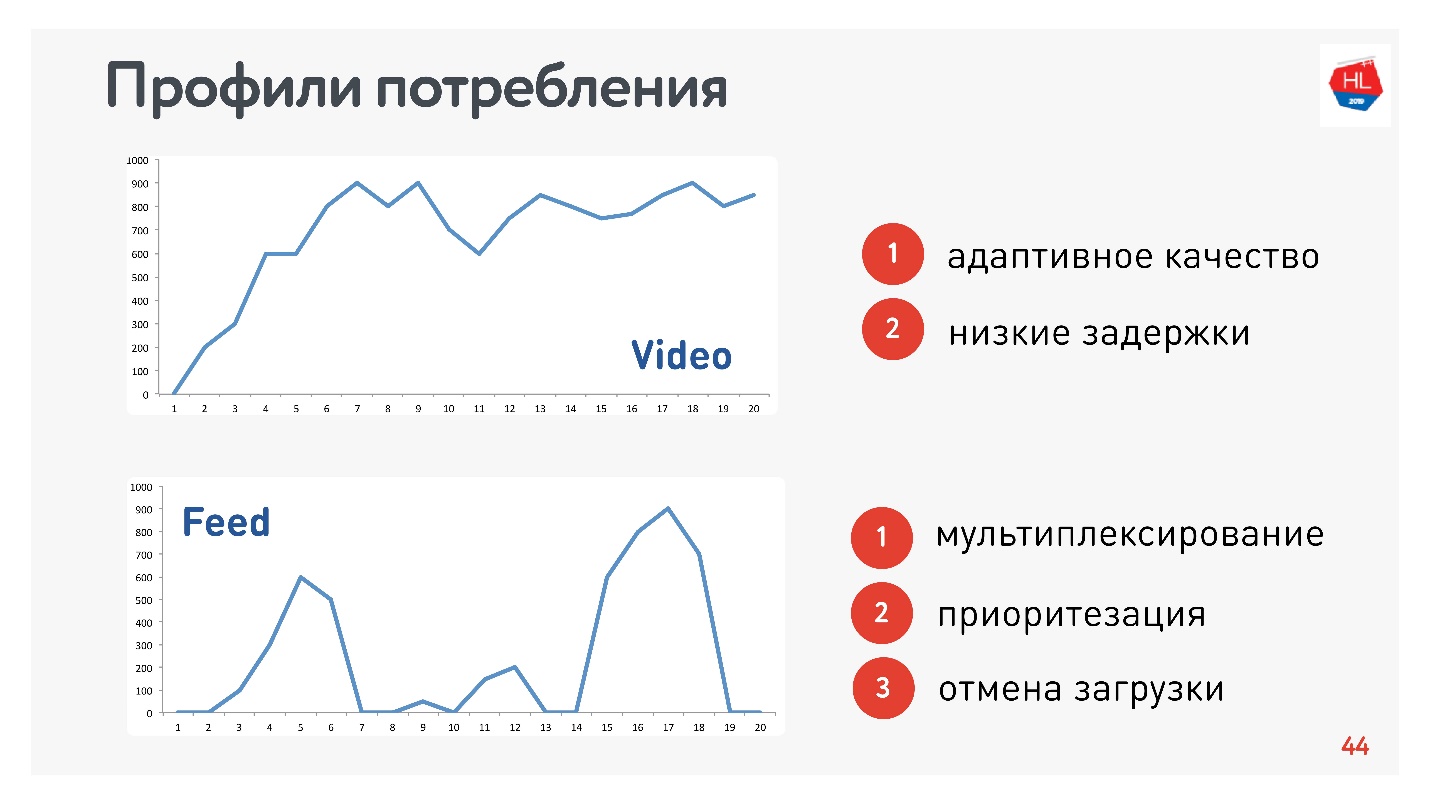
Da ich für das Video und den Stream verantwortlich bin, sind die Profile angemessen:
- Profilvideo, wenn Sie diesen oder jenen Inhalt verbinden und streamen. Die Verbindungsgeschwindigkeit erhöht sich wie in der oberen Grafik. Anforderungen an dieses Protokoll: geringe Latenz und Bitratenanpassung.
- Option für die Bandansicht: Laden von Impulsdaten, Hintergrundabfragen, Ausfallzeiten. Anforderungen an dieses Protokoll: Die empfangenen Daten werden gemultiplext und priorisiert, die Priorität des Benutzerinhalts ist höher als bei Hintergrundprozessen, der Download wird abgebrochen.
Natürlich müssen Sie die Protokolle auf dem beliebtesten HTTP vergleichen.
HTTP 1.1 und HTTP 2.0
Der Standardstapel der 2000er Jahre sah aus wie HTTP 1.1 über SSL. Der moderne Stack ist HTTP 2.0, TLS 1.3 und alles über TCP.
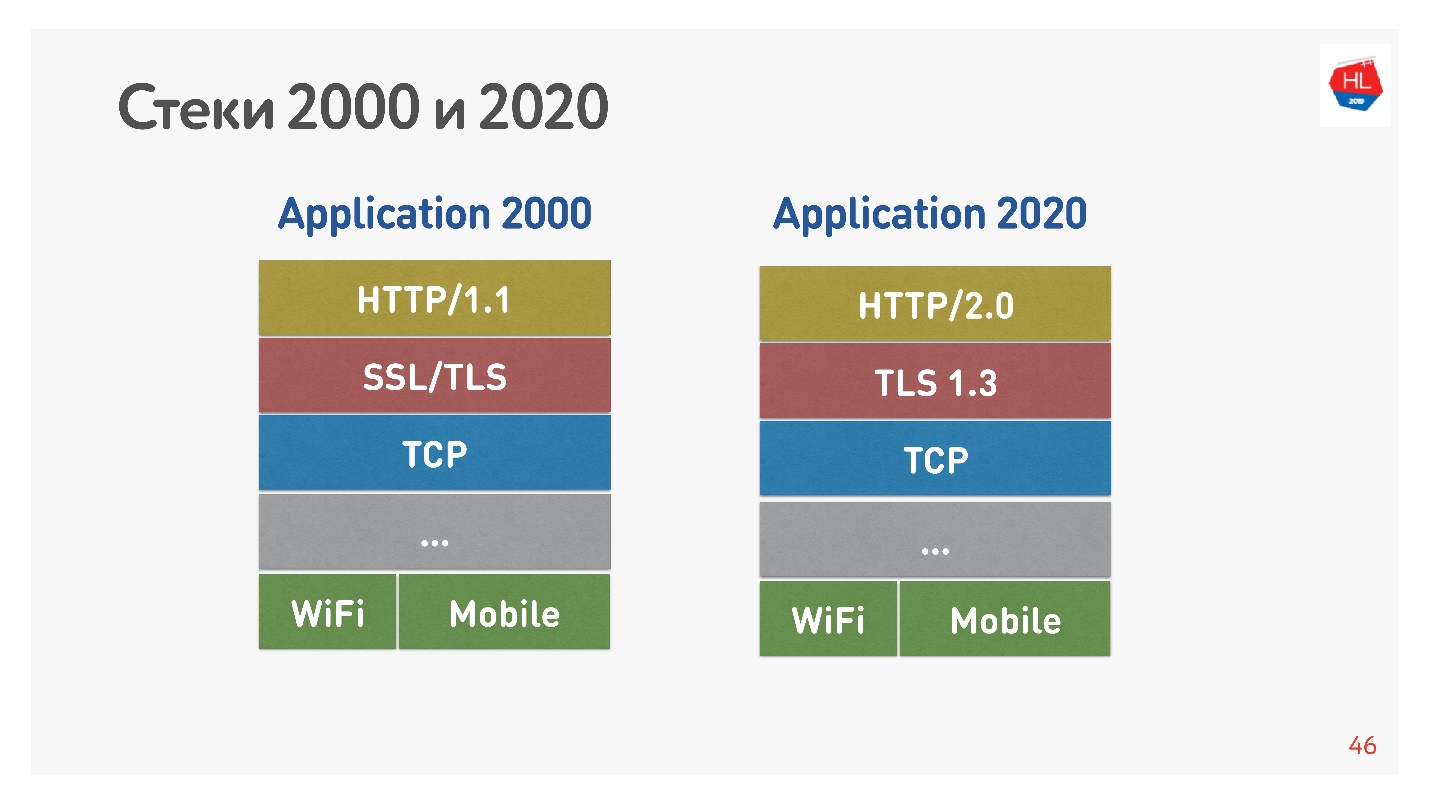
Der Hauptunterschied besteht darin, dass HTTP 1.1 einen begrenzten Pool von Verbindungen im Browser zu einer Domäne verwendet, sodass eine separate Domäne für Bilder, Daten usw. erstellt wird. HTTP 2.0 bietet eine Multiplexverbindung, über die alle diese Daten übertragen werden.
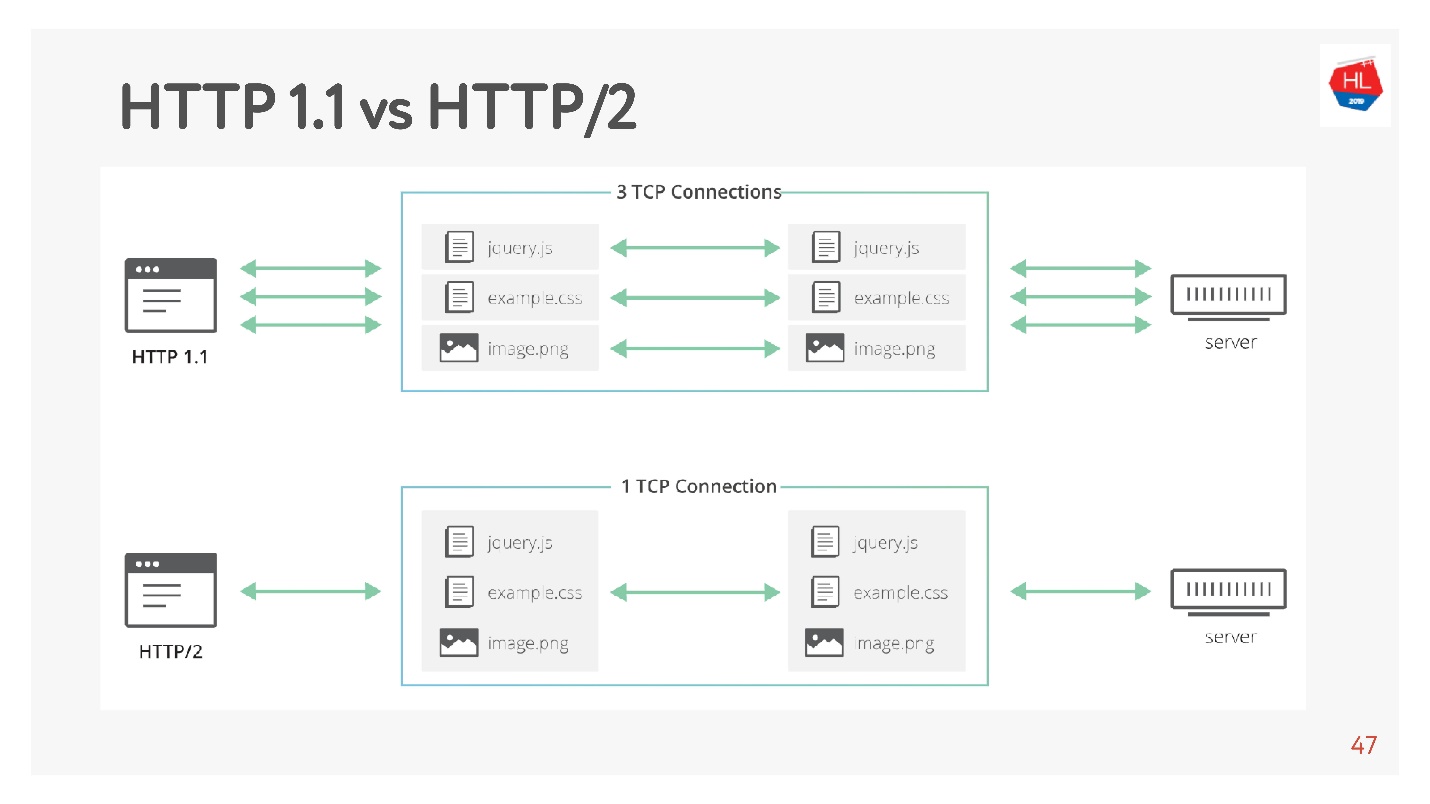
HTTP 1.1 funktioniert folgendermaßen: Anfrage stellen, Daten abrufen, Anfrage stellen, Daten abrufen.
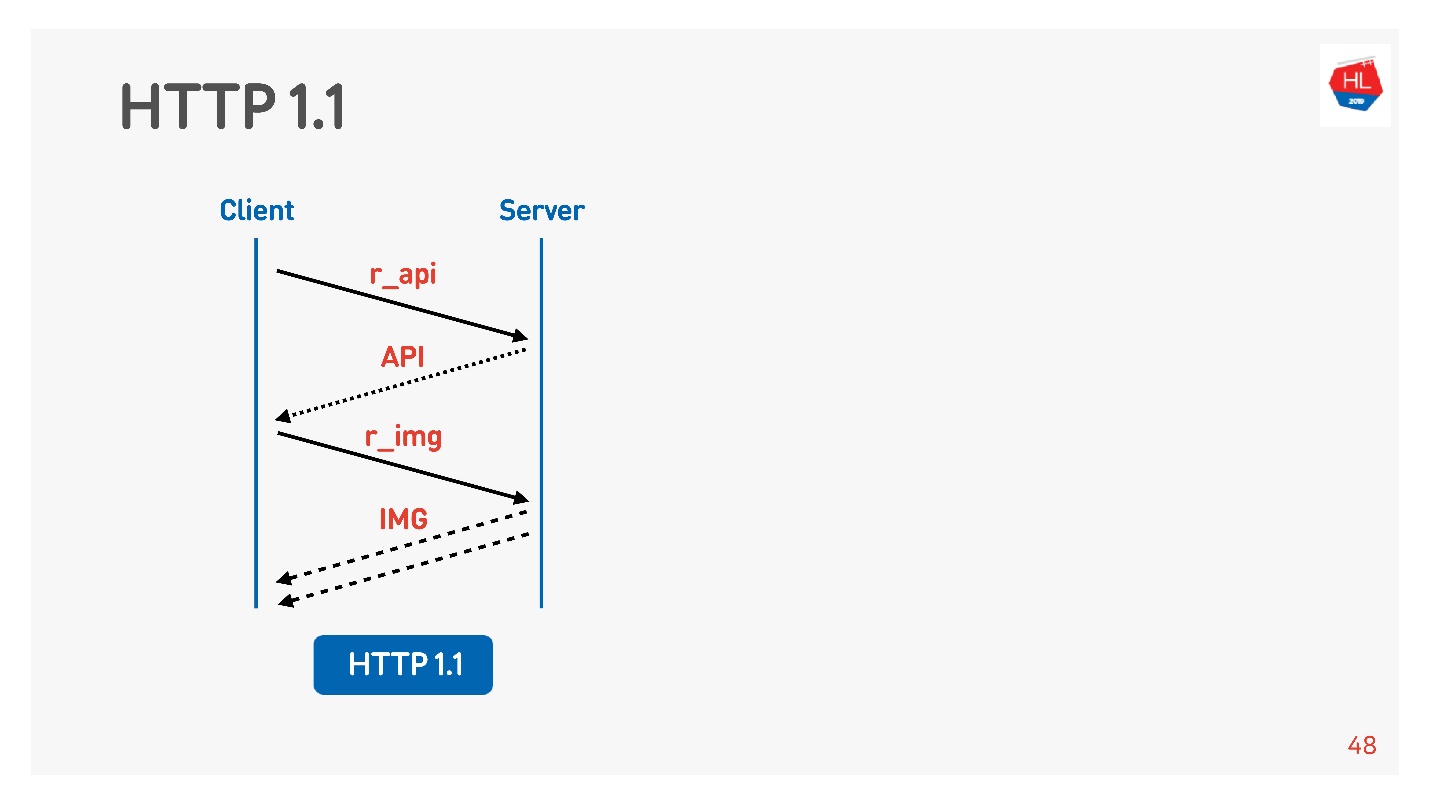
Normalerweise ist ein Browser oder eine mobile Anwendung eine Kugel, dh eine Verbindung zum Empfangen von Bildern, Daten per API, und Sie führen gleichzeitig eine Anforderung für ein Bild, eine API, ein Video usw. aus.
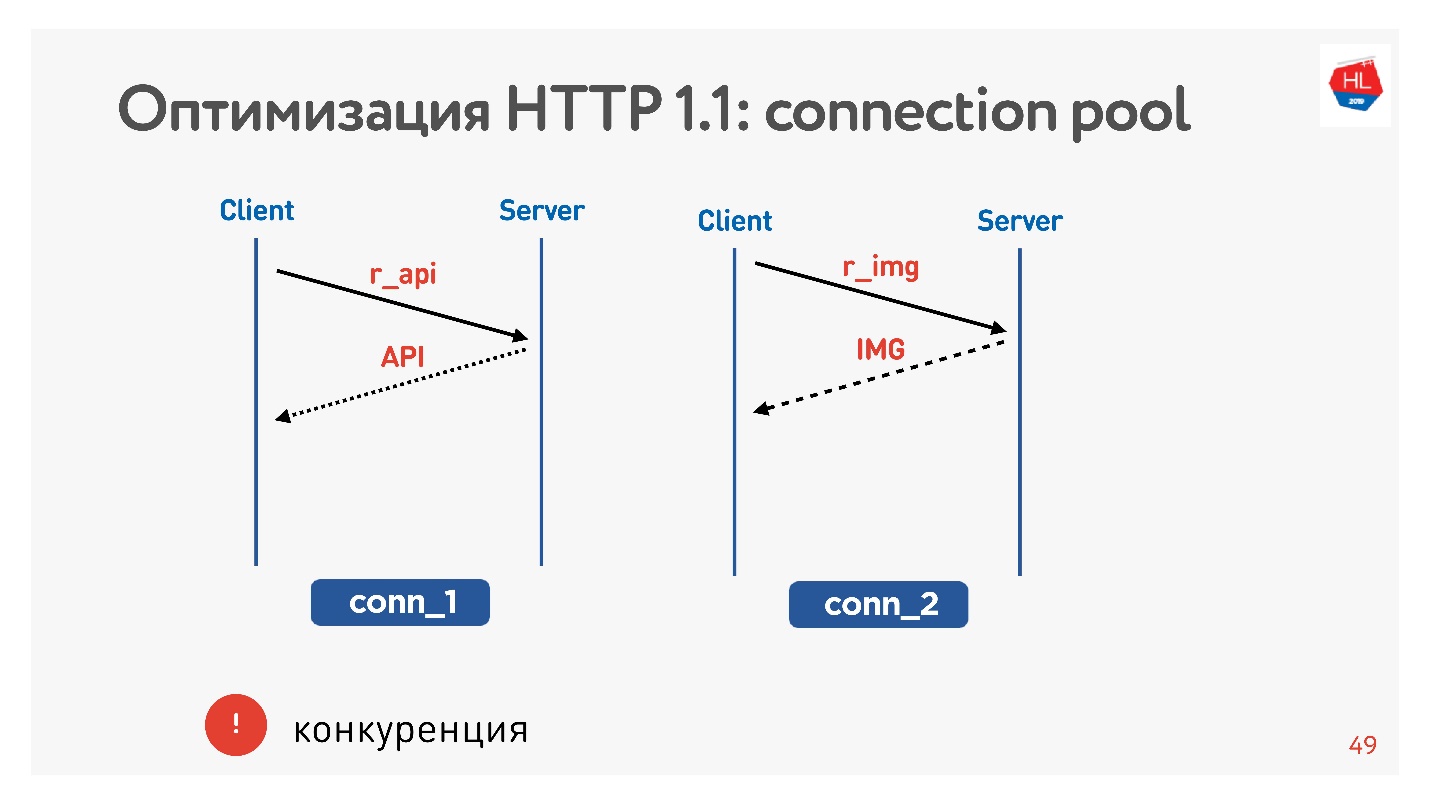
Das Hauptproblem ist der Wettbewerb. Sie haben keine Kontrolle über die übermittelten Anfragen. Sie verstehen, dass der Benutzer das Bild, das er durchgeblättert hat, nicht mehr benötigt, aber nichts mehr tun kann.
Mit HTTP 1.1 erhalten Sie immer noch das, was Sie angefordert haben. Es ist schwierig, den Download abzubrechen.
Die einzige Möglichkeit, die Verbindung zu schließen, besteht darin, die Verbindung zu schließen. Dann werden wir sehen, warum das schlecht ist.
Unterschiede in HTTP 2.0
HTTP 2.0 löst diese Probleme:
- binäre Header-Komprimierung;
- Datenmultiplex;
- Priorisierung;
- Abbrechen des Downloads;
- Server Push
Betrachten wir wichtigere Punkte für uns.
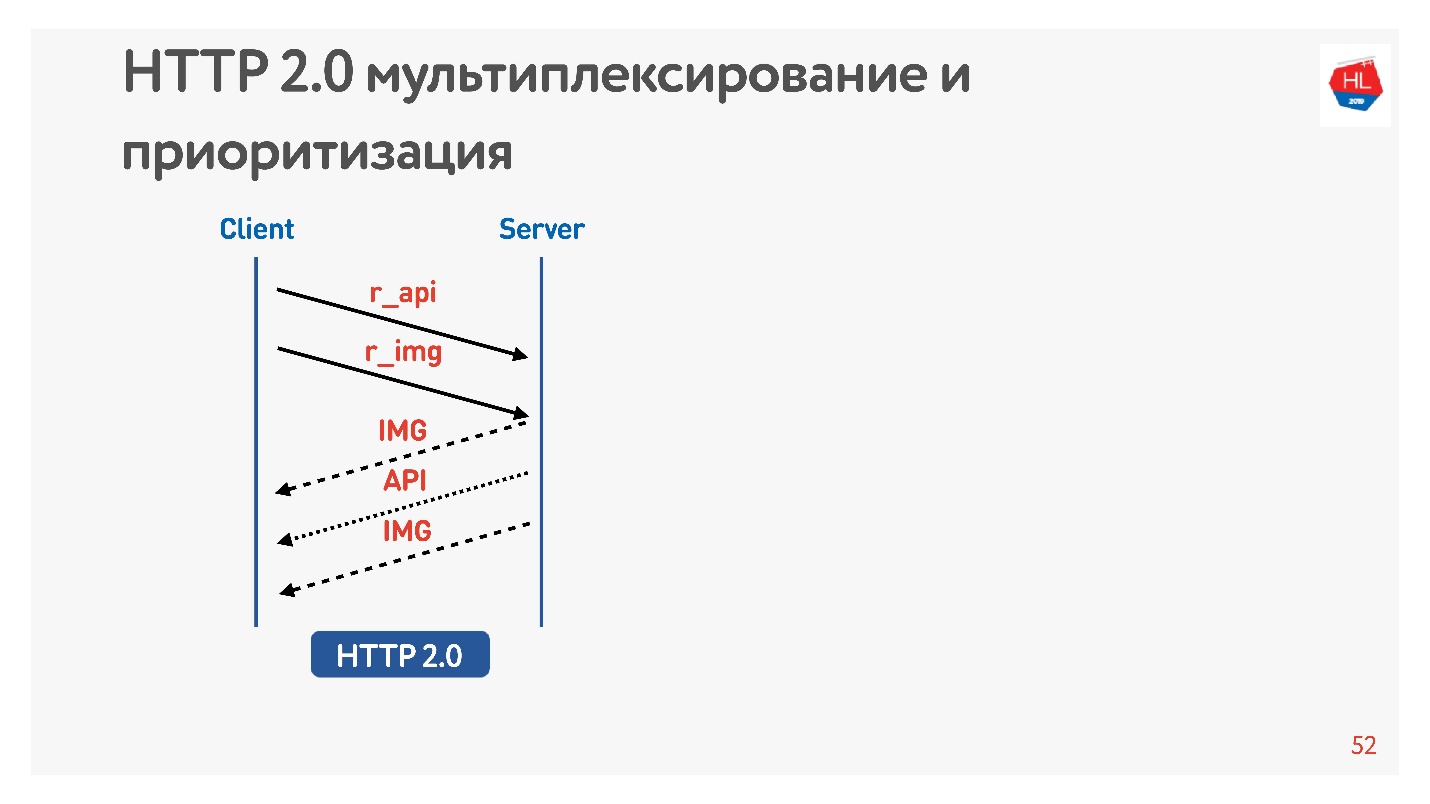
Fordern Sie ein Bild und eine API an. Das Bild wird sofort gegeben, die API nach einer Weile vorbereitet. Die API wurde gegeben - das Bild wurde bis zum Ende gegeben. All dies geschieht transparent.
Inhalte mit hoher Priorität werden früher heruntergeladen.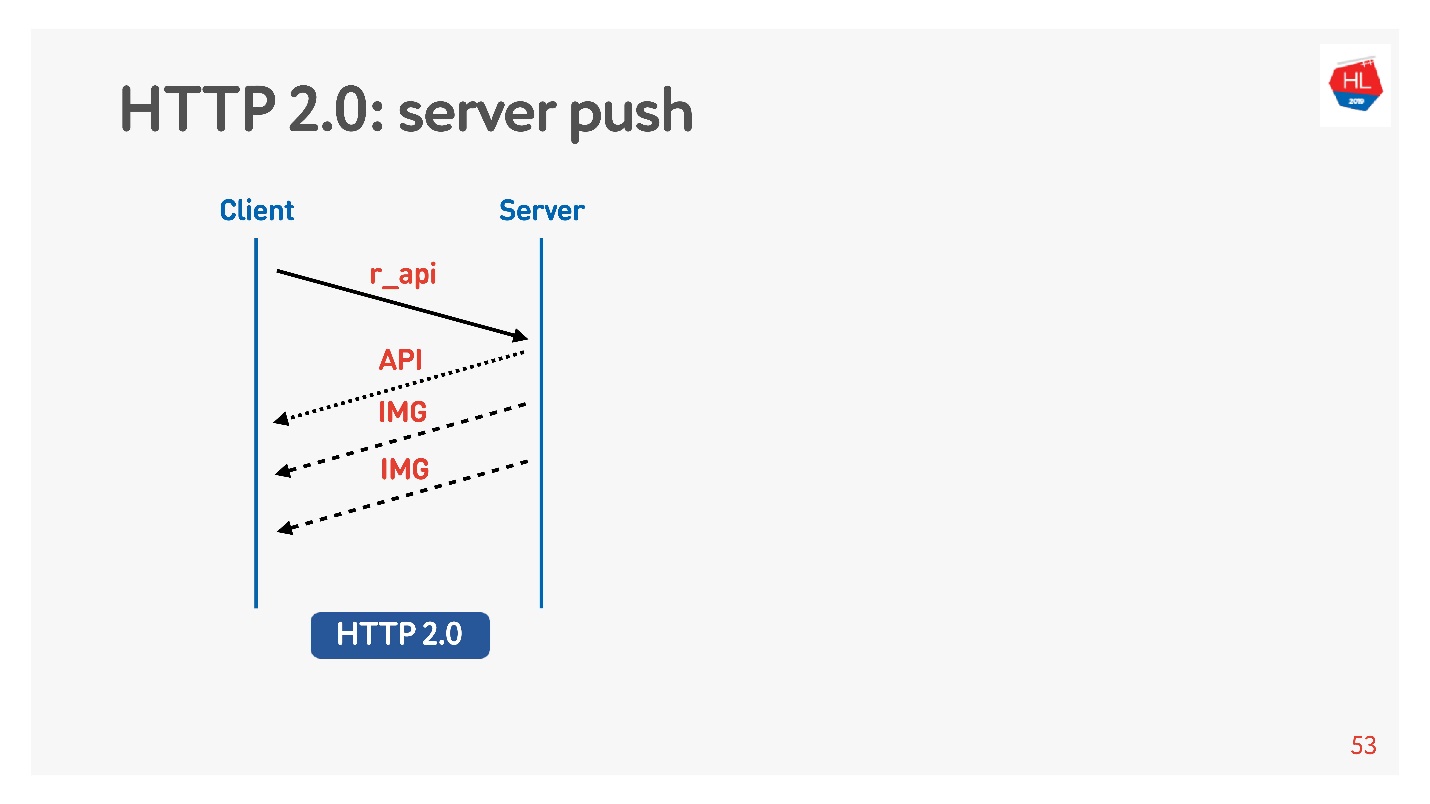 Server-Push
Server-Push ist so etwas, wenn Sie nach etwas Bestimmtem wie einer API gefragt haben, aber selbst beim Laden auf dem Client wurden Bilder zwischengespeichert, die definitiv benötigt würden, um beispielsweise ein Band anzuzeigen.
Es gibt auch einen Befehl zum
Zurücksetzen des Streams , den der Browser selbst ausführt, wenn Sie zwischen Seiten usw. wechseln. Für einen mobilen Client können Sie mit seiner Hilfe den Empfang von Daten verweigern, ohne die Verbindung zu verlieren.
Daher werden wir TCP auf verschiedene vergleichen:
- Netzwerkprofile: Wi-Fi, 3G, LTE.
- Verbrauchsprofile: Streaming (Video), Multiplexing und Priorisierung mit Abbrechen des Downloads (HTTP / 2), um den Inhalt des Bandes zu empfangen.
Verlustfreies Modell
Beginnen wir den Vergleich mit einem einfachen Netzwerk, in dem es nur zwei Parameter gibt: Roundtrip-Zeit und Bandbreite.
RTT ist Ping, die Bearbeitungszeit eines Pakets, der Empfang der Bestätigung oder die Antwortechozeit.
Um die
Bandbreite - die Netzwerkbandbreite - zu messen, senden wir ein Paket von Paketen und zählen die Anzahl der übertragenen Pakete in einem bestimmten Zeitintervall.
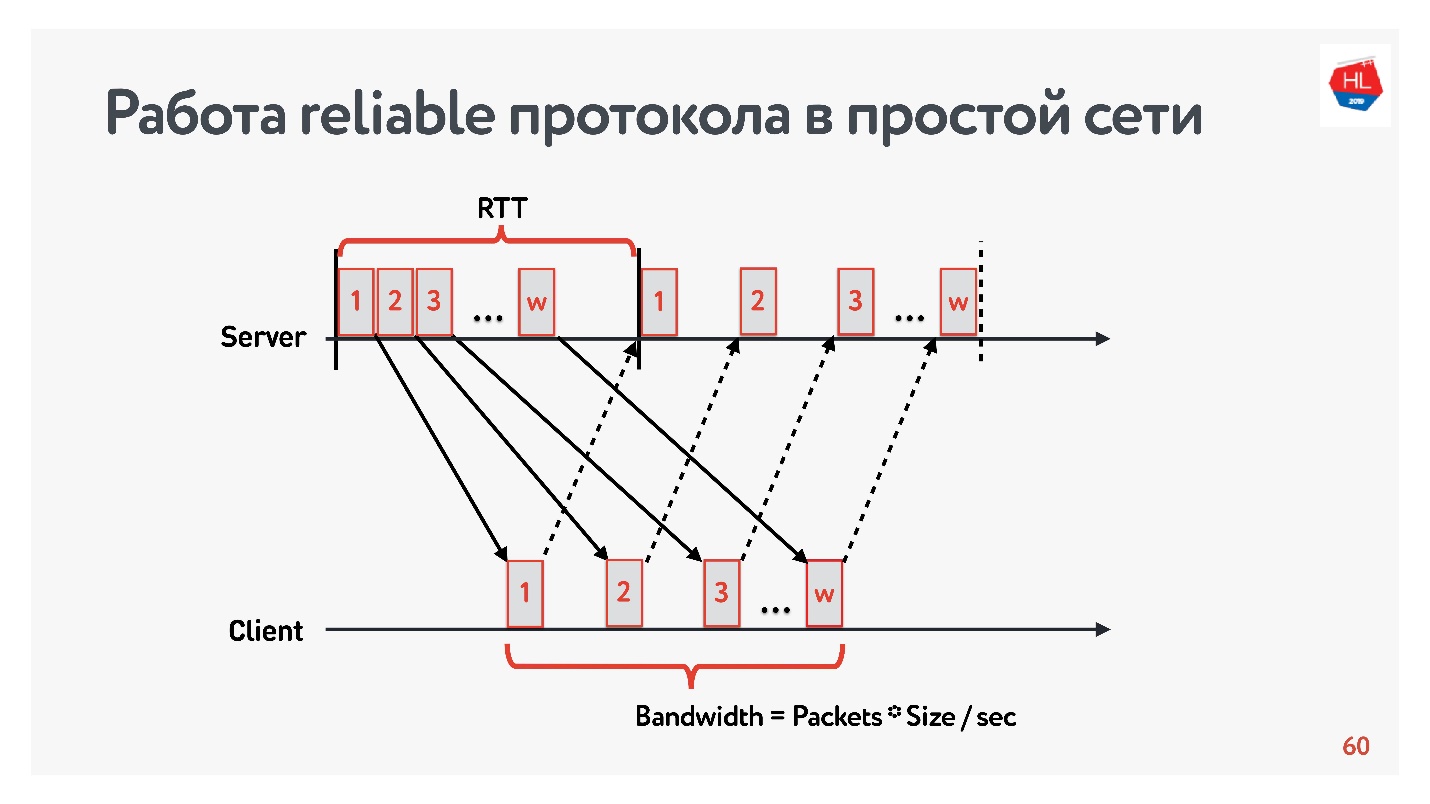
Da wir mit zuverlässigen Protokollen arbeiten, gibt es natürlich eine Bestätigung - wir senden Pakete und erhalten eine Empfangsbestätigung.
Das Problem des langsamen Internets
Zu Beginn der Entwicklung unseres Videodienstes im Jahr 2013 ging mein Freund nach Kalifornien und beschloss, eine neue Serie seiner Lieblingsserien auf Odnoklassniki anzusehen. Er hatte eine 250 ms RTT, perfektes Wi-Fi 400 Mbit / s auf dem Google-Campus, er wollte die neue Serie in FullHD sehen.
Glaubst du, er konnte das Video sehen? Die Antwort hängt von der Konfiguration des Sende- / Empfangspuffers auf unseren Servern ab.
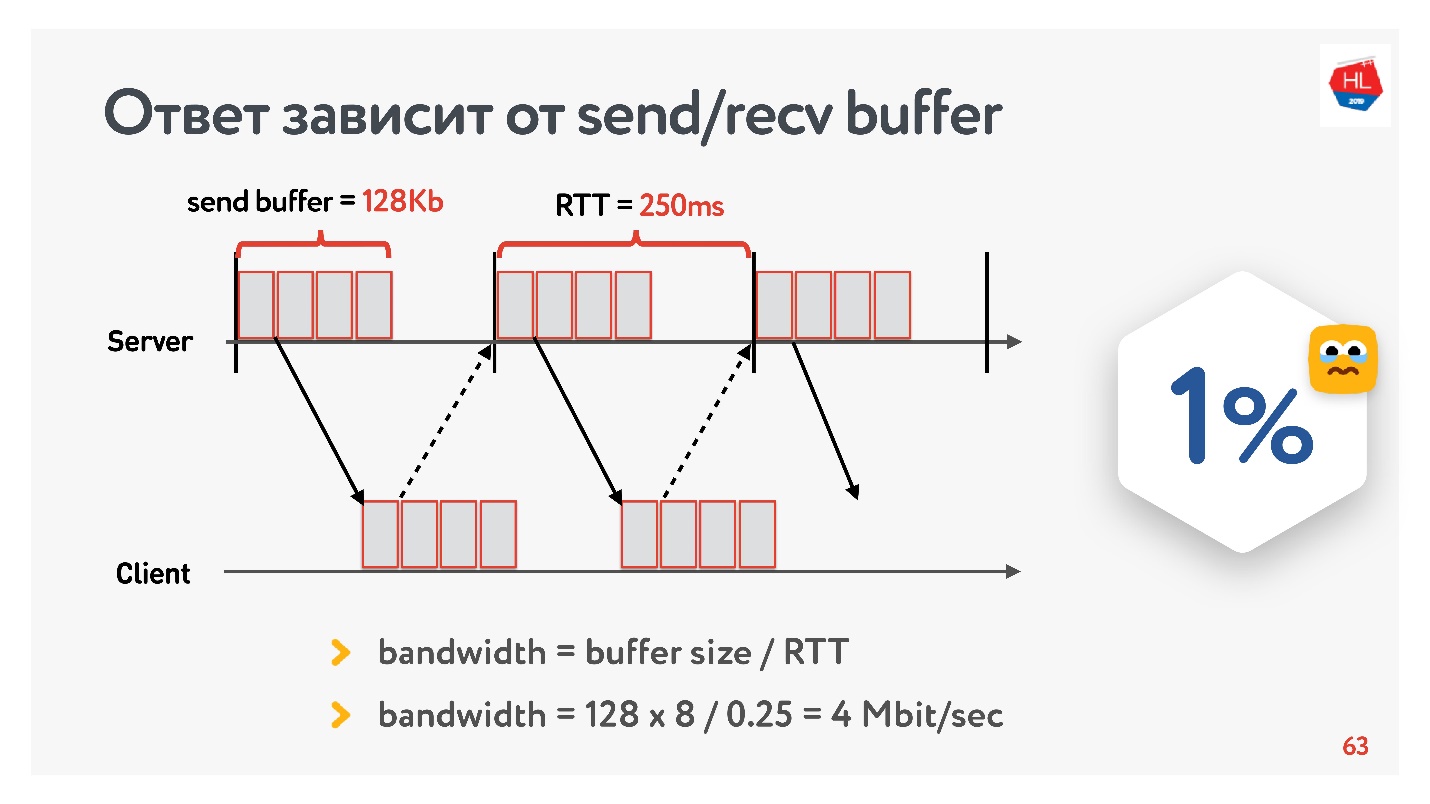
Da wir ein Protokoll mit Bestätigung haben, werden alle Daten, die keine Zustellbestätigung erhalten haben, in einem Puffer gespeichert. Wenn der Sendepuffer auf 128 KB begrenzt ist, sind diese 128 KB geringer als bei RTT. Wir können nicht senden. Somit verbleiben aus unserem Netzwerk von 400 Mbit / s 4 Mbit / s. Dies reicht nicht aus, um Online-Videos in FullHD anzusehen.
Dann habe ich die Größe des Puffers erhöht und mir angesehen, wie sich die Ausgabegeschwindigkeit eines Videosegments in Abhängigkeit von der Änderung der Puffergröße wirklich ändert. Machen Sie sofort eine Reservierung, dass der Recv-Puffer automatisch eingestellt wurde, d. H. Was der Server gesendet hat, konnte der Client immer akzeptieren.

Ein offensichtliches TCP-Rezept: Wenn Sie Hochgeschwindigkeitsdaten über große Entfernungen übertragen, müssen Sie den Sendepuffer erhöhen.
Alles scheint in Ordnung zu sein. Sie können zum Dienst fast.com gehen, der die Geschwindigkeit Ihres Internets zu Netflix-Servern misst. Aus dem Büro bekam ich eine Geschwindigkeit von 210 Mbit / s. Und dann habe ich durch Net Shaper die Bedingungen für die Aufgabe festgelegt und bin wieder auf diese Seite gegangen. Magie - Ich habe genau 4 Mbit / s.
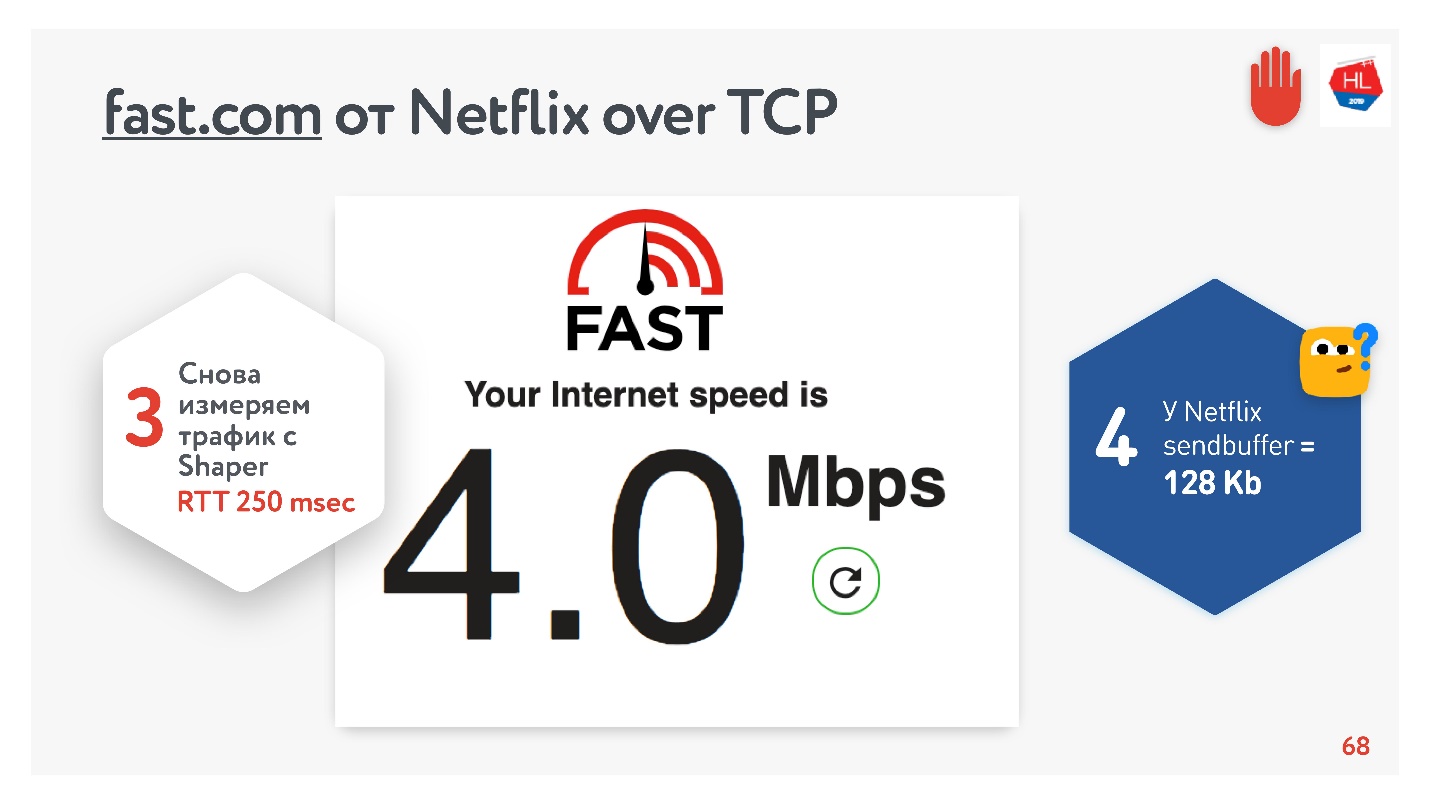
Egal wie ich es verdrehe, Netflix hat es nicht geschafft, einen Puffer größer als 128 KB zu bekommen.
Puffergröße
Um die optimale Puffergröße zu ermitteln, müssen Sie die On-the-Fly-Pakete verstehen.
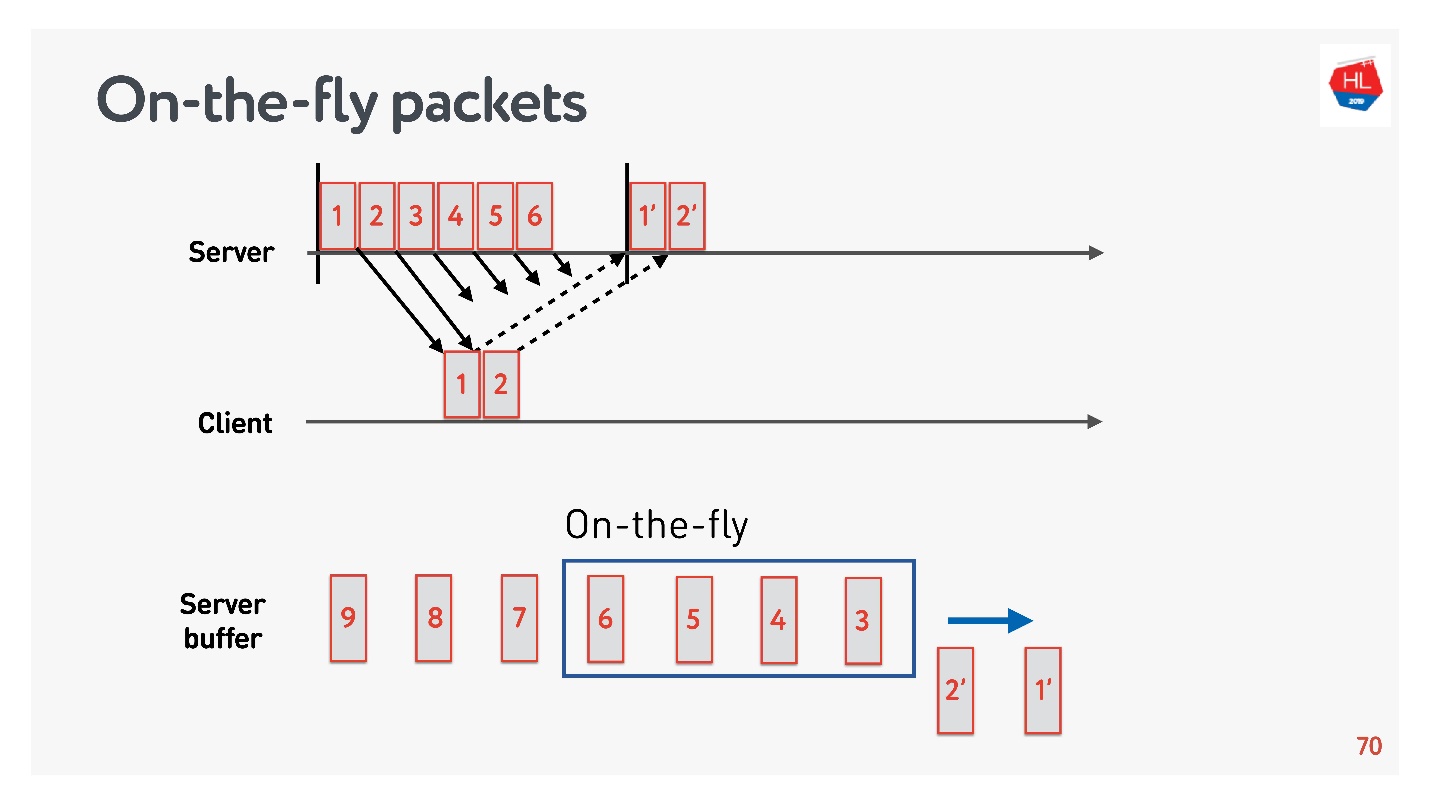
Es gibt einen Netzwerkstatus:
- Pakete 1 und 2 wurden bereits gesendet, eine Bestätigung wurde für sie empfangen;
- Pakete 3, 4, 5, 6 wurden gesendet, aber das Zustellergebnis ist unbekannt (On-the-Fly-Pakete);
- andere Pakete befinden sich in der Warteschlange.
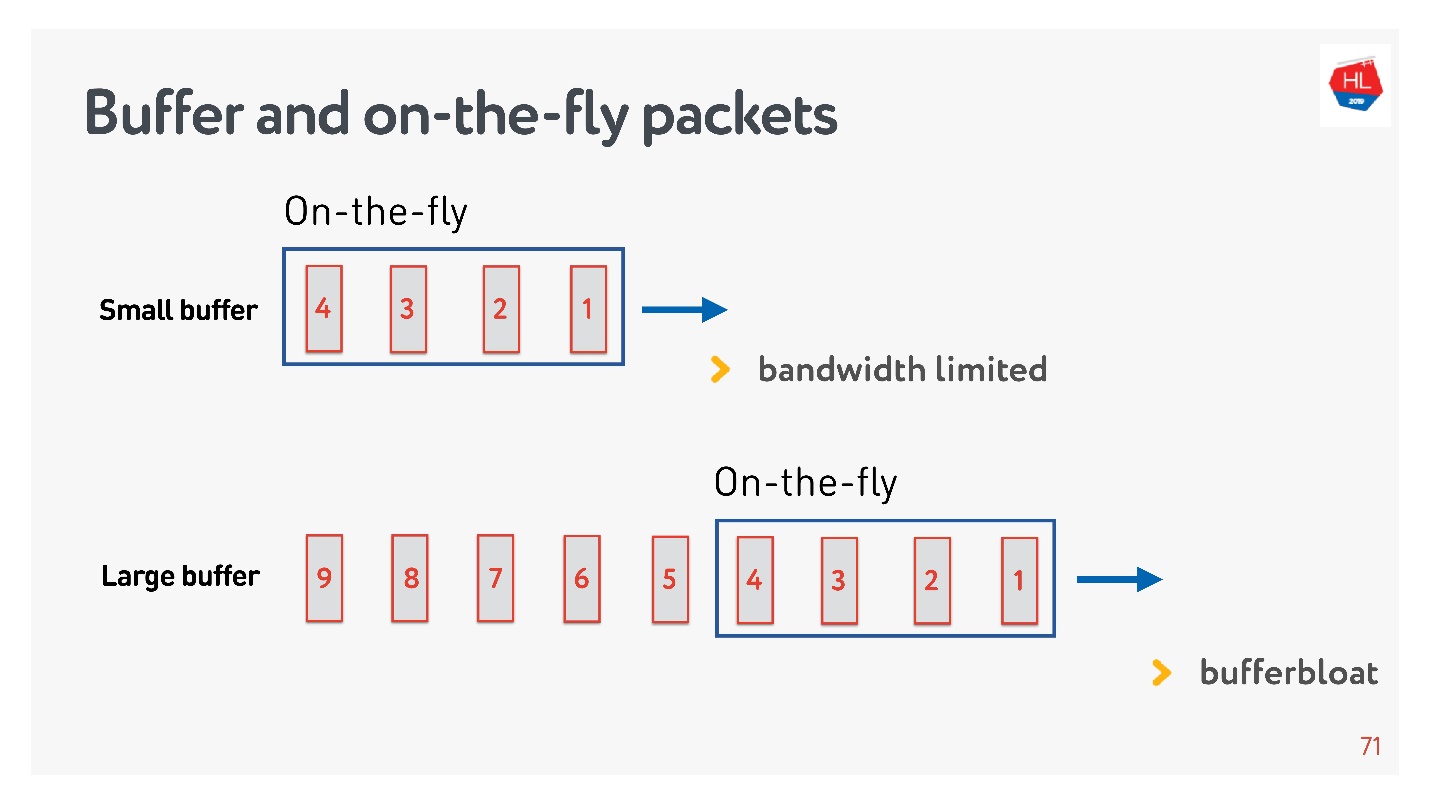
Wenn die Anzahl der Pakete in On-the-Fly der Größe des Puffers entspricht, ist sie nicht groß genug. In diesem Fall ist das Netzwerk ausgehungert und nicht vollständig ausgelastet.
Die umgekehrte Situation ist möglich - der Puffer ist zu groß. In diesem Fall quillt der Puffer auf. Warum ist das so schlimm?

Wenn wir über Datenmultiplex sprechen und mehrere Anforderungen gleichzeitig senden, z. B. Bilder in derselben Verbindung und API, dann schwillt der Puffer an, wenn das gesamte riesige Megabyte-Bild in den Puffer gelangt und wir versuchen, auch die API mit hoher Priorität zu stopfen. Sie müssen sehr lange warten, bis das Bild verschwindet.
Eine einfache Lösung besteht darin, die Puffergröße automatisch anzupassen. Jetzt ist es auf vielen Clients verfügbar und funktioniert in etwa so.
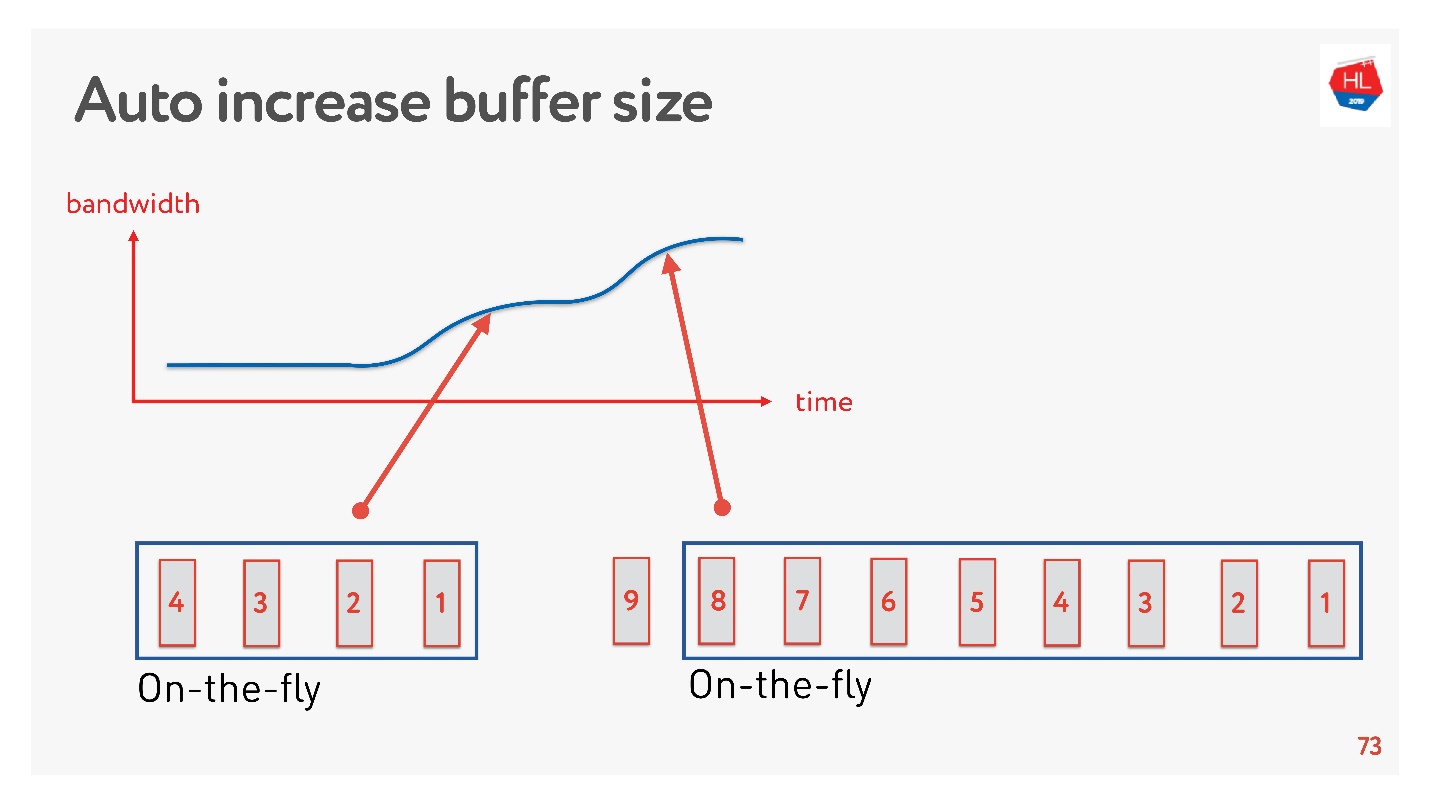
Wenn jetzt viele Pakete gesendet werden können, erhöht sich der Puffer, die Datenübertragung beschleunigt sich, die Größe des Puffers wächst, alles scheint großartig zu sein.
Aber es gibt ein Problem. Wenn der Puffer vergrößert wurde, kann er nicht so einfach reduziert werden. Dies ist eine schwierigere Aufgabe. Wenn die Geschwindigkeit nachlässt, tritt die gleiche Pufferquellung auf. Der Puffer ist ziemlich groß und voll. Wir müssen warten, bis alle Daten an den Client gesendet wurden.
Wenn wir unser eigenes UDP-Protokoll schreiben, ist alles sehr einfach - wir haben Zugriff auf den Puffer.
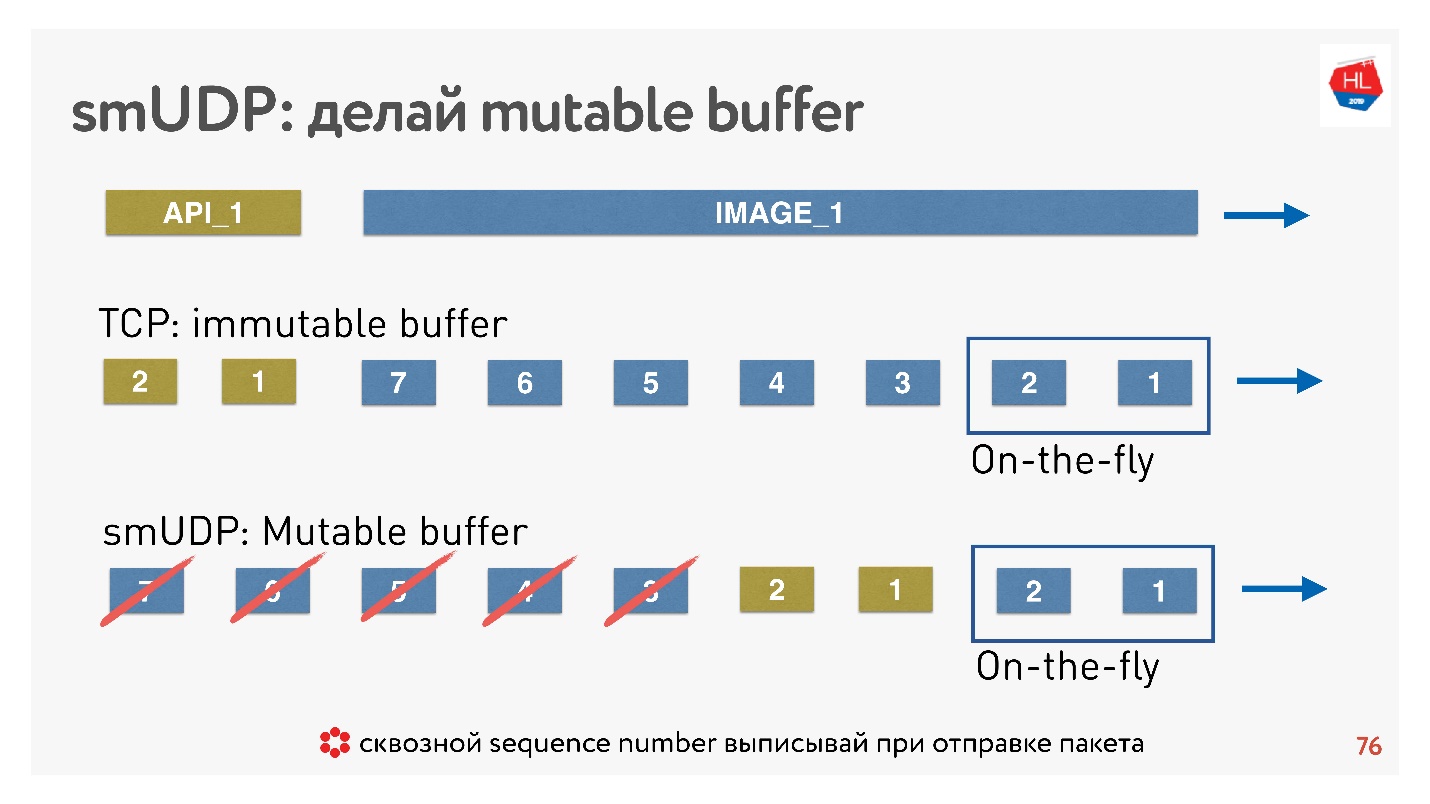
Wenn TCP in solchen Situationen einfach Daten am Ende hinzufügt und Sie nichts tun können, können Sie in einem selbst erstellten Protokoll Daten beispielsweise unmittelbar nach On-the-Fly-Paketen weiterleiten.
Und wenn Abbrechen kommt und der Client sagt, dass dieses Bild nicht mehr benötigt wird, benötigt er die API-Daten, er hat den Inhalt weiter gescrollt, Sie können all dies aus dem Puffer werfen und das erforderliche senden.
Wie wird das gemacht? Es ist bekannt, dass Sie zum Wiederherstellen von Paketen, Verwalten der Zustellung und Empfangen von Bestätigungen eine Sequenz-ID von Paketen benötigen. Sequence_id Wir werden nur für On-the-Fly-Pakete geschrieben, dh wir geben sie nur aus, wenn wir Pakete senden. Alles andere im Puffer kann beliebig verschoben werden, bis die Pakete verschwunden sind.
Fazit: Der TCP-Puffer muss korrekt konfiguriert sein, das Gleichgewicht abfangen, um nicht an das Netzwerk zu stoßen und den Puffer nicht aufzublasen. Für Ihr eigenes UDP-Protokoll ist alles einfach - dies kann gesteuert werden.
Verlustbehaftetes Netzwerkmodell
Wir bewegen uns auf eine höhere Ebene, das Netzwerk wird etwas komplizierter, Paketverlust tritt darin auf. Für Mobilfunknetze ist dies eine häufige Situation. Einige der gesendeten Pakete erreichen den Client nicht. Der Standard-Wiederherstellungsalgorithmus für die erneute Übertragung funktioniert ungefähr so:
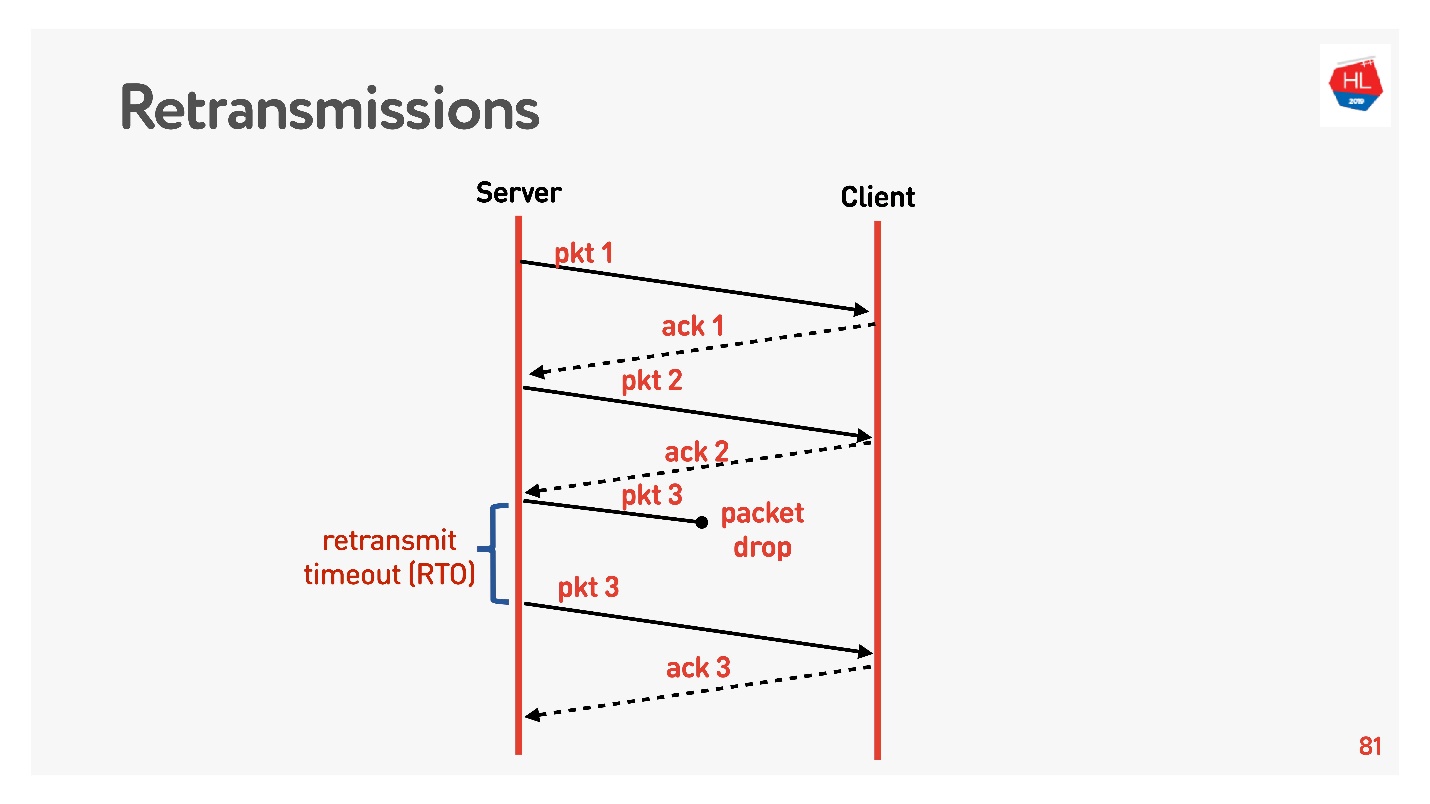
Sendet Pakete, denn jedes Paket erhält eine Bestätigung. Retransmit timeout (RTO) RTT , .
TCP, 5% , 50%.
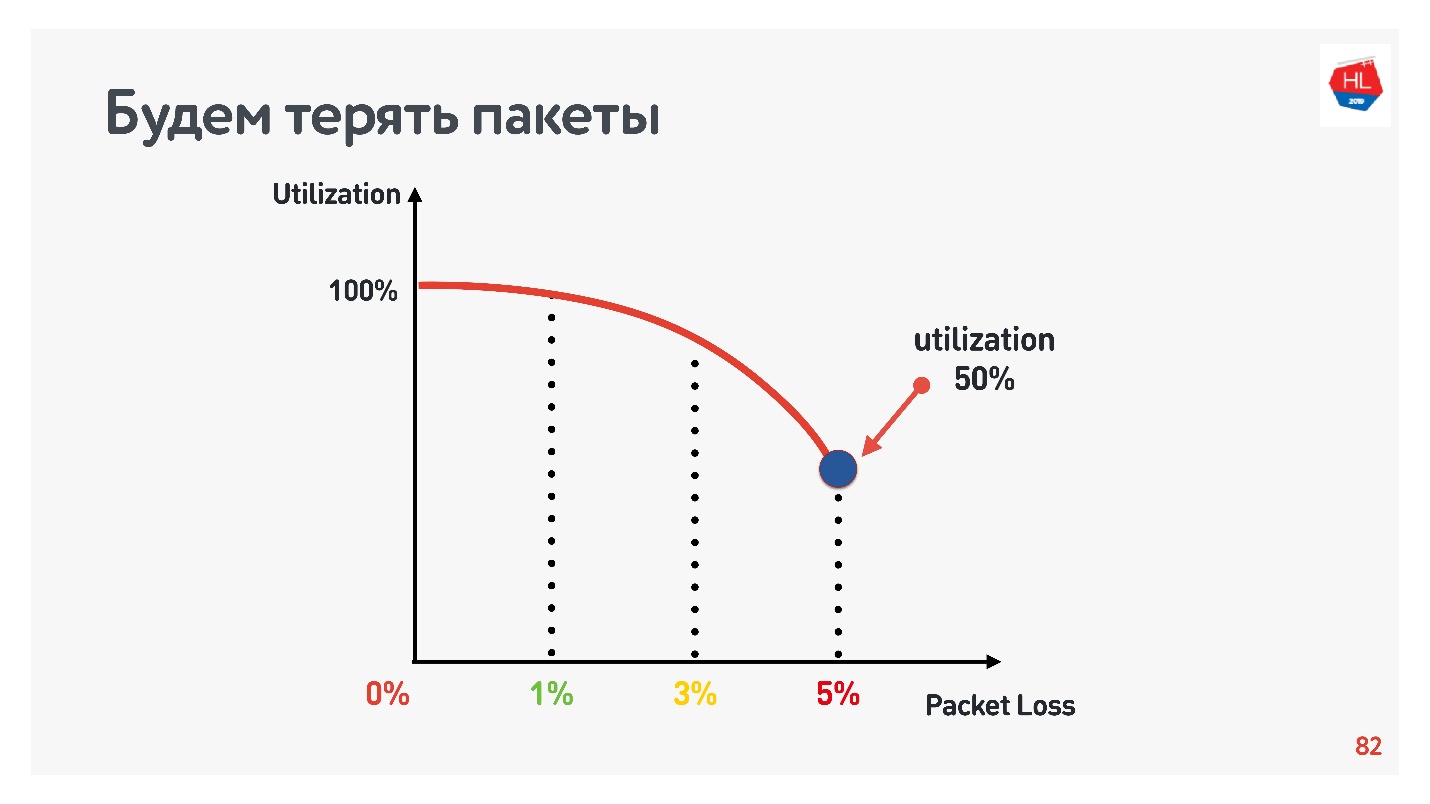
retransmit, , . , , Congestion control.
Congestion control
flow control, .
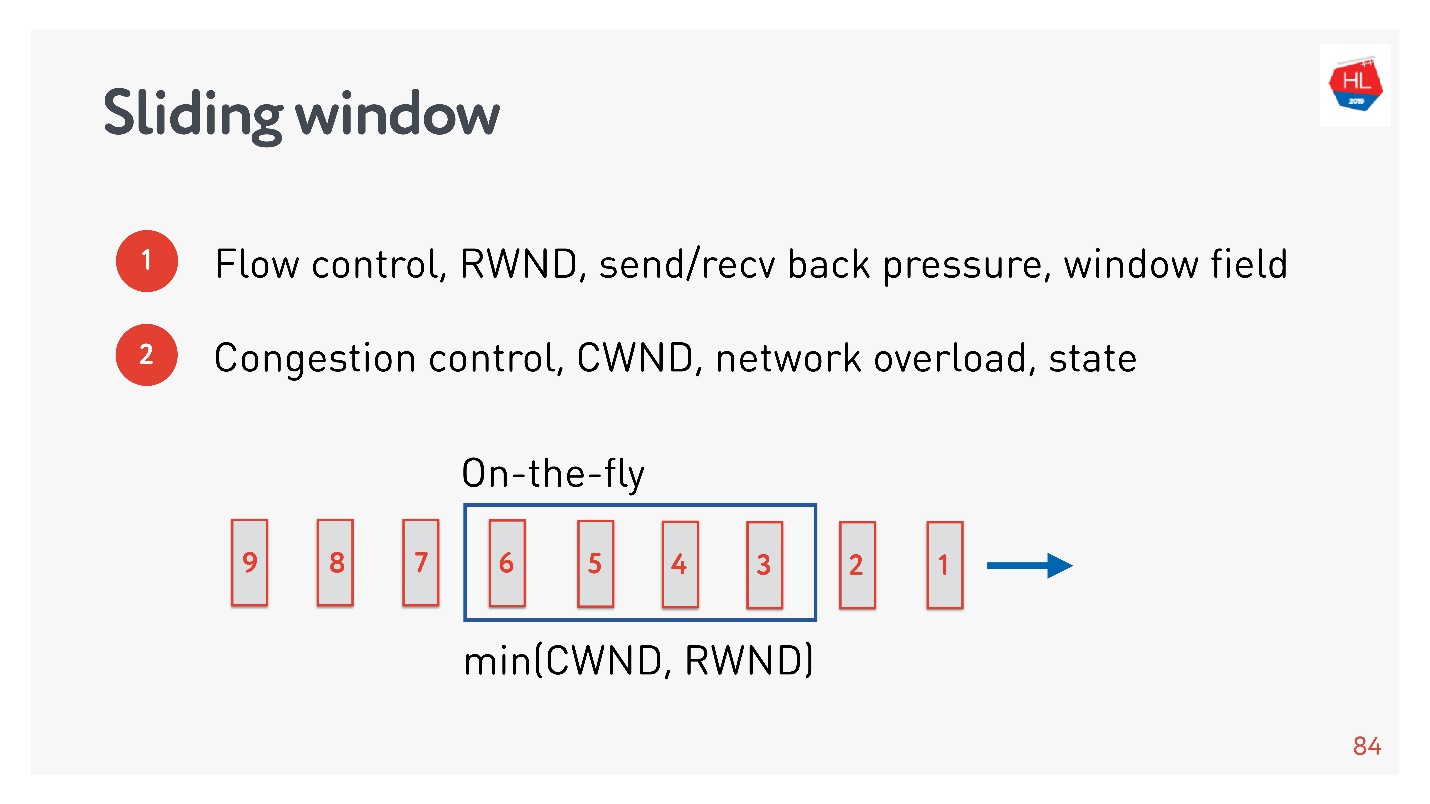
- Flow control — . , , . flow control recv window, . flow control — back pressure , - .
- congestion control . , — .
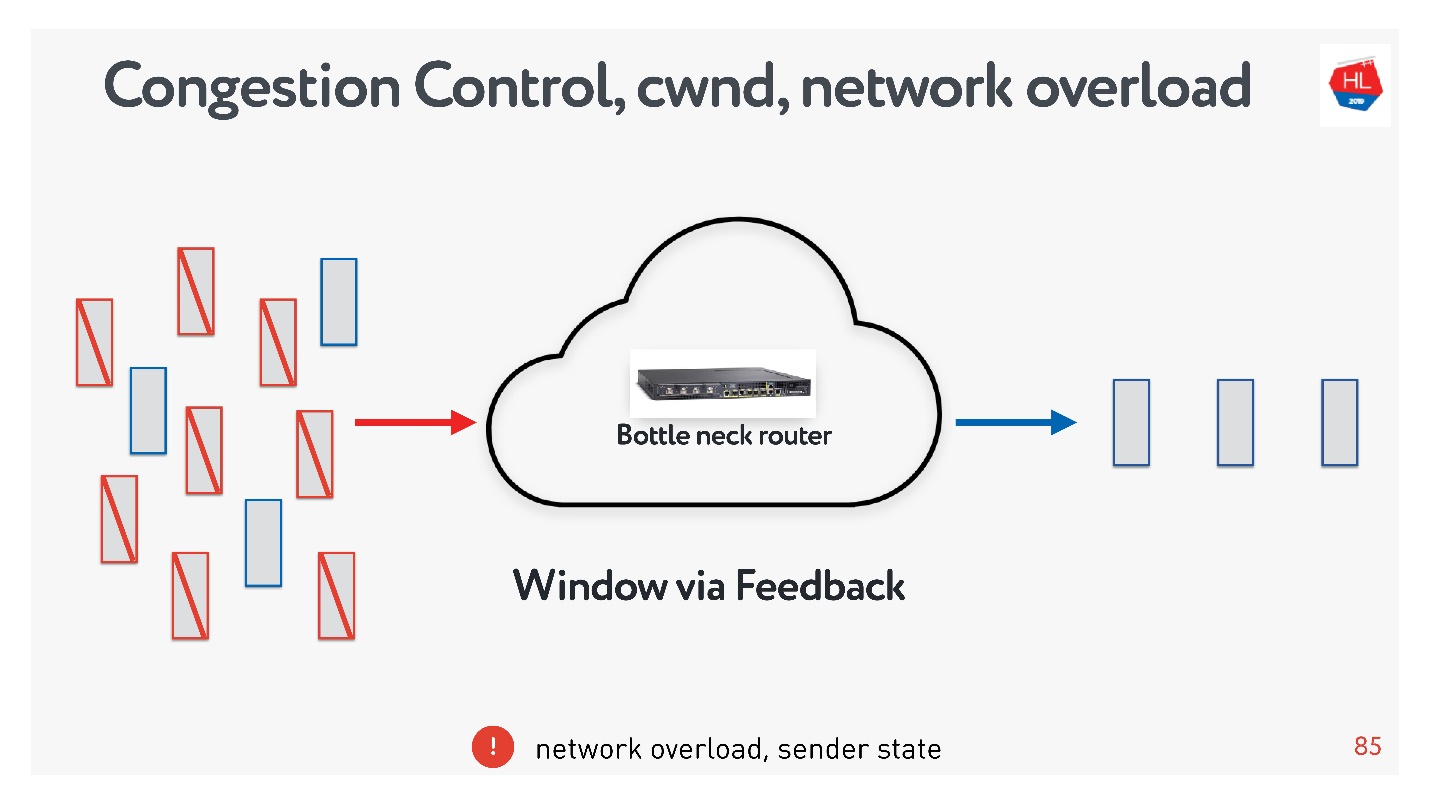
, : , , , . , congestion control.
TCP window.
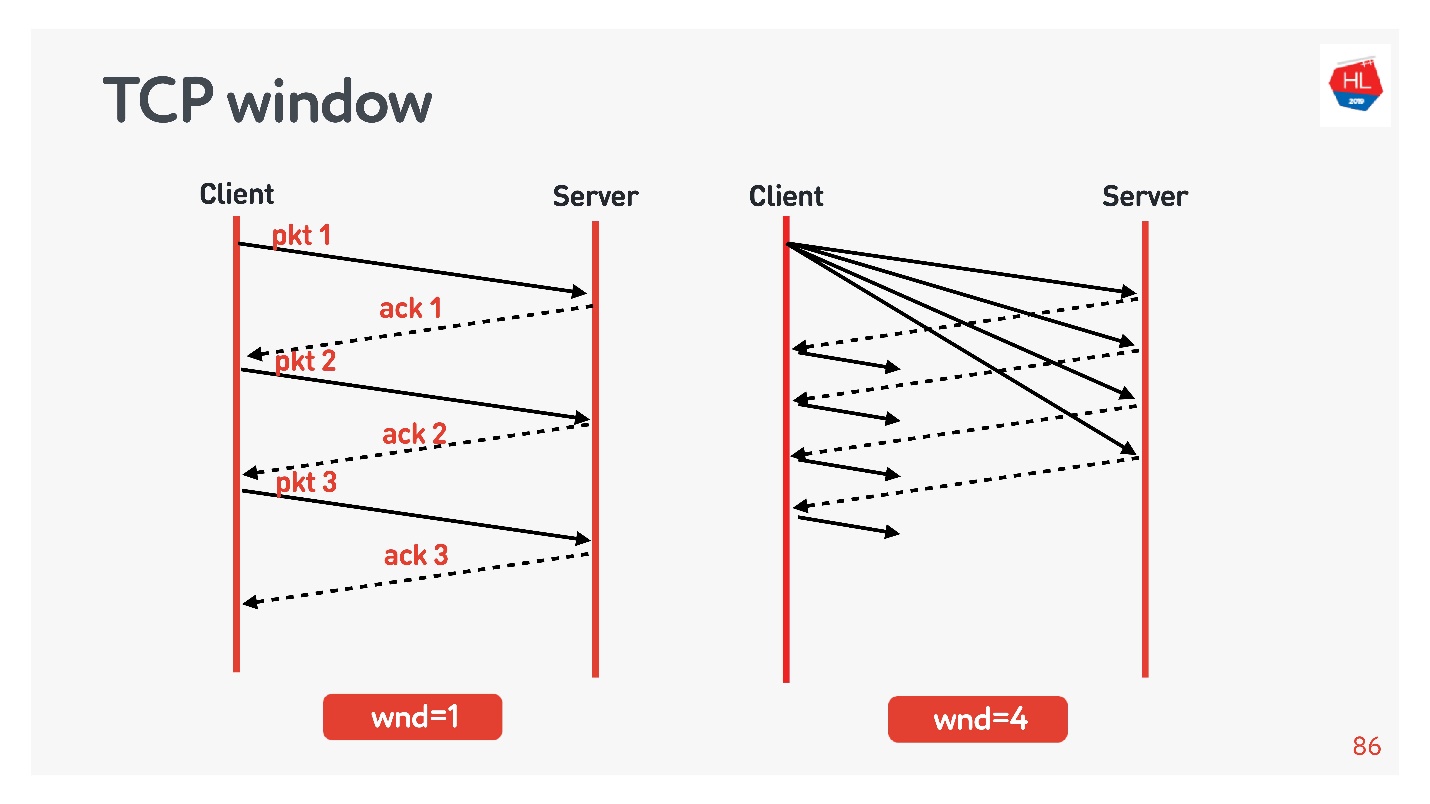
flow control congestion control, .
Beispiele:
- TCP window = 1, : acknowledgement, ..
- TCP window = 4, , acknowledgement .
, . initial window TCP = 10.
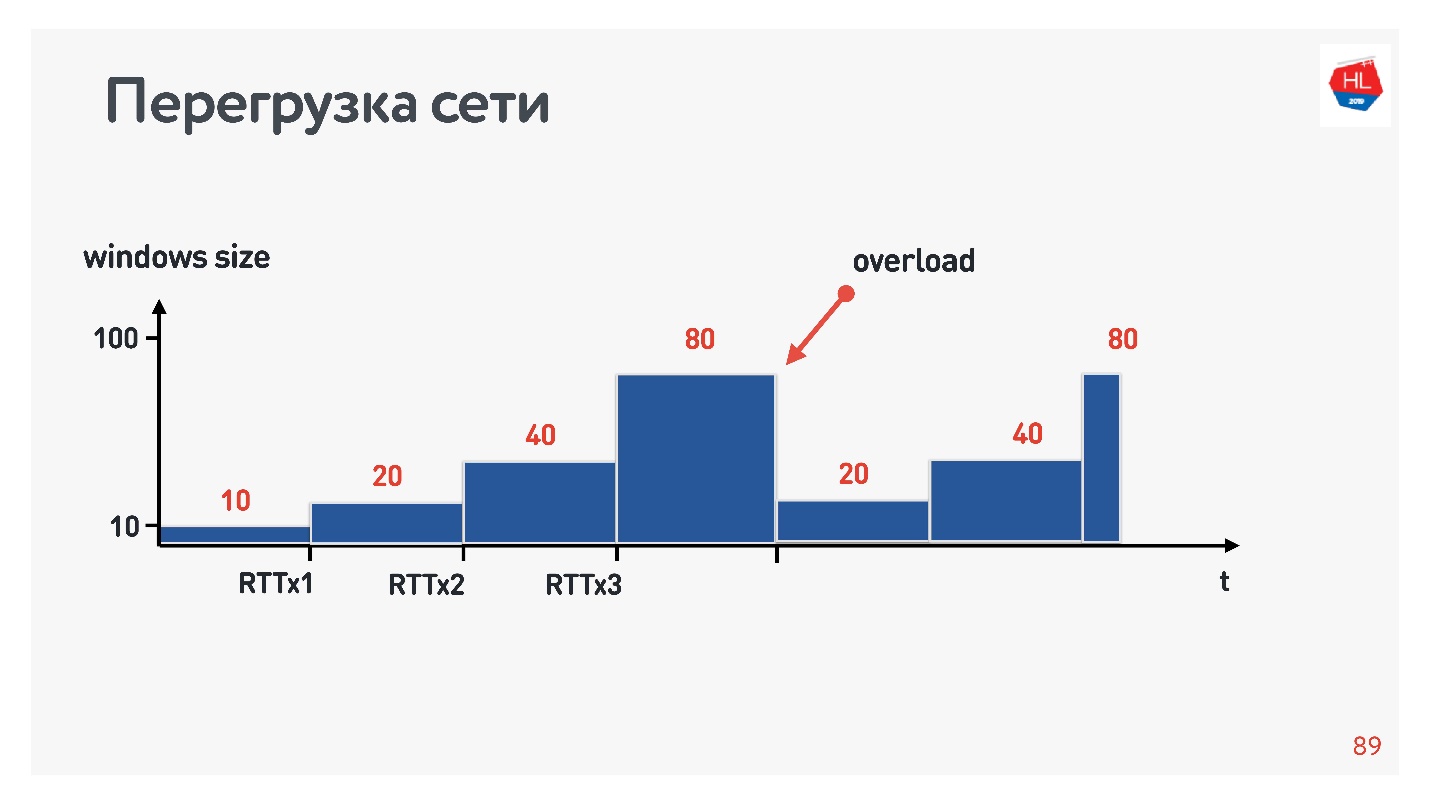
, , .
?
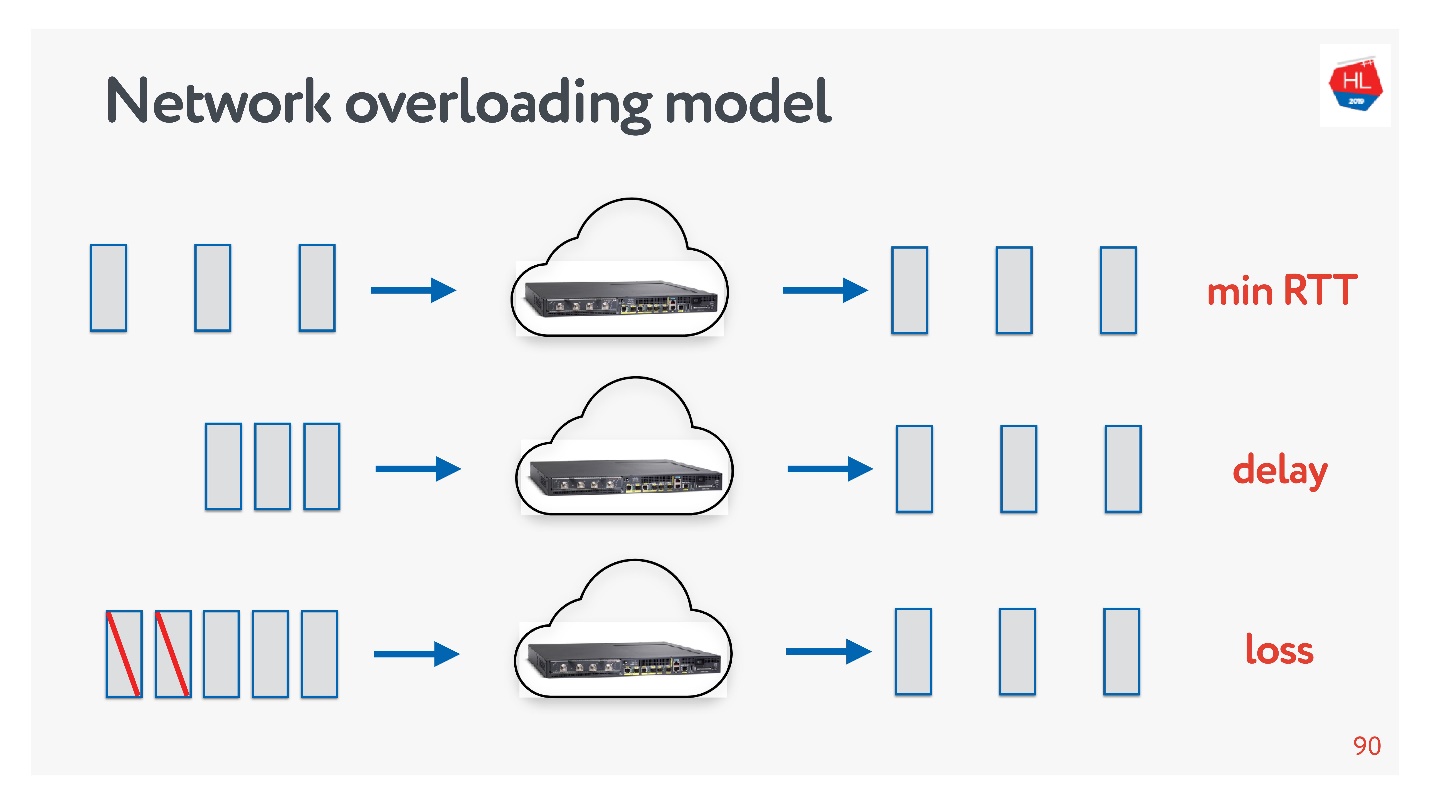
- , . , .
- : , acknowledgements .
- - , acknowledgements ( ).
.
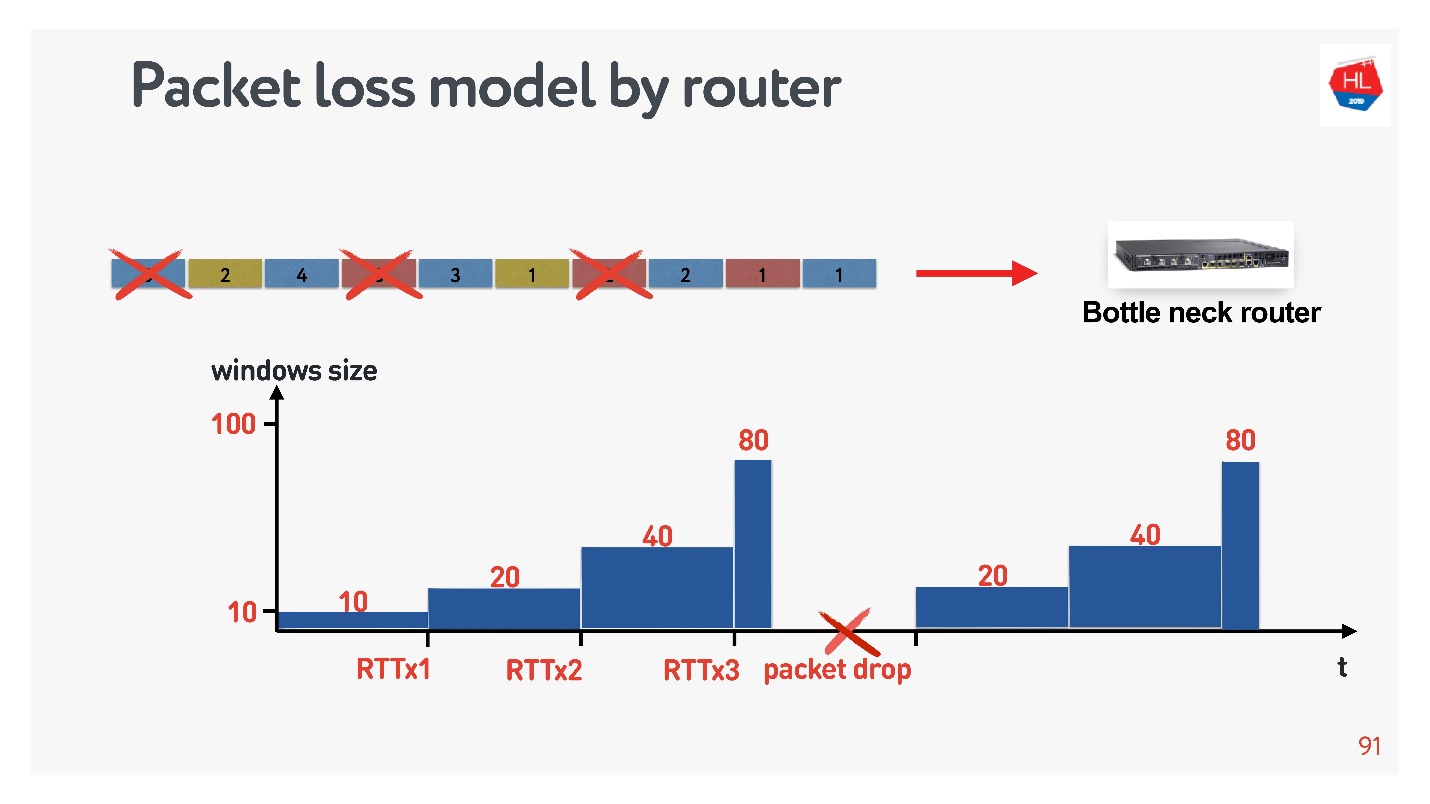
, , . : , .. , . congestion control, TCP window, , .
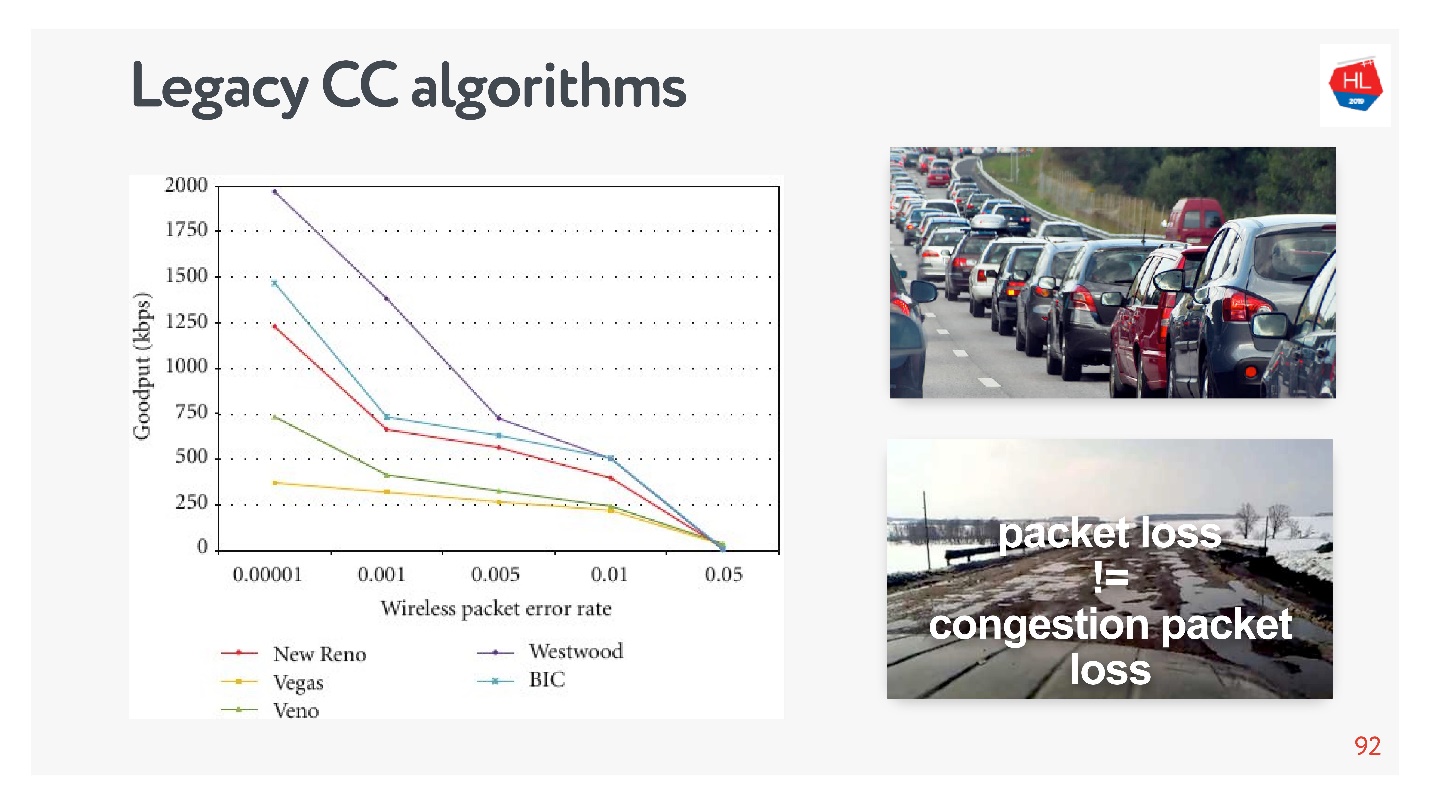
congestion control, , — . packet loss — , . , , — , .
, TCP , , congestion control loss-. congestion control loss delay, , .
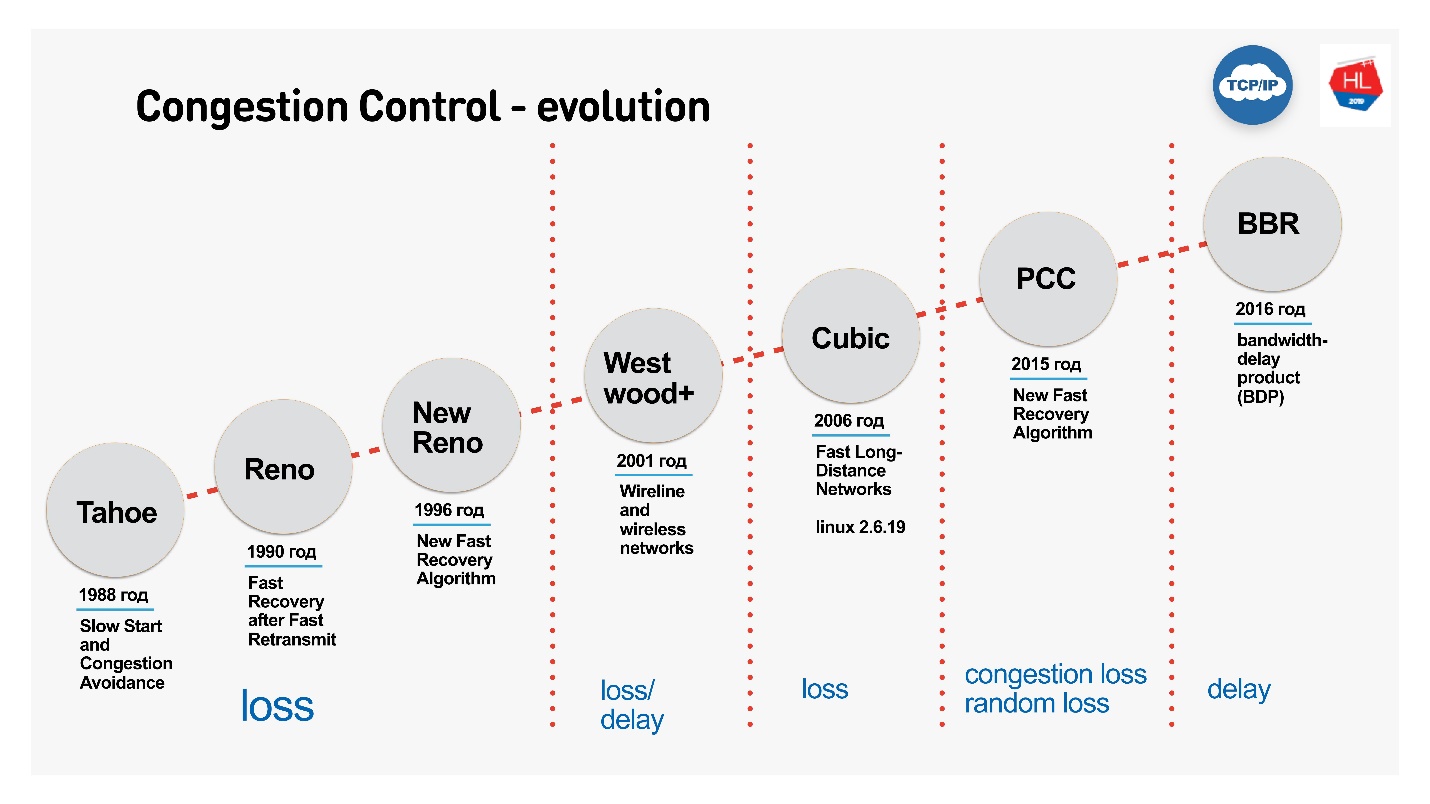
:
- Cubic — Congestion Control Linux 2.6. : — .
- BBR — Congestion Control, Google 2016 . .
BBR Congestion Control
Cubic BBR feedback.
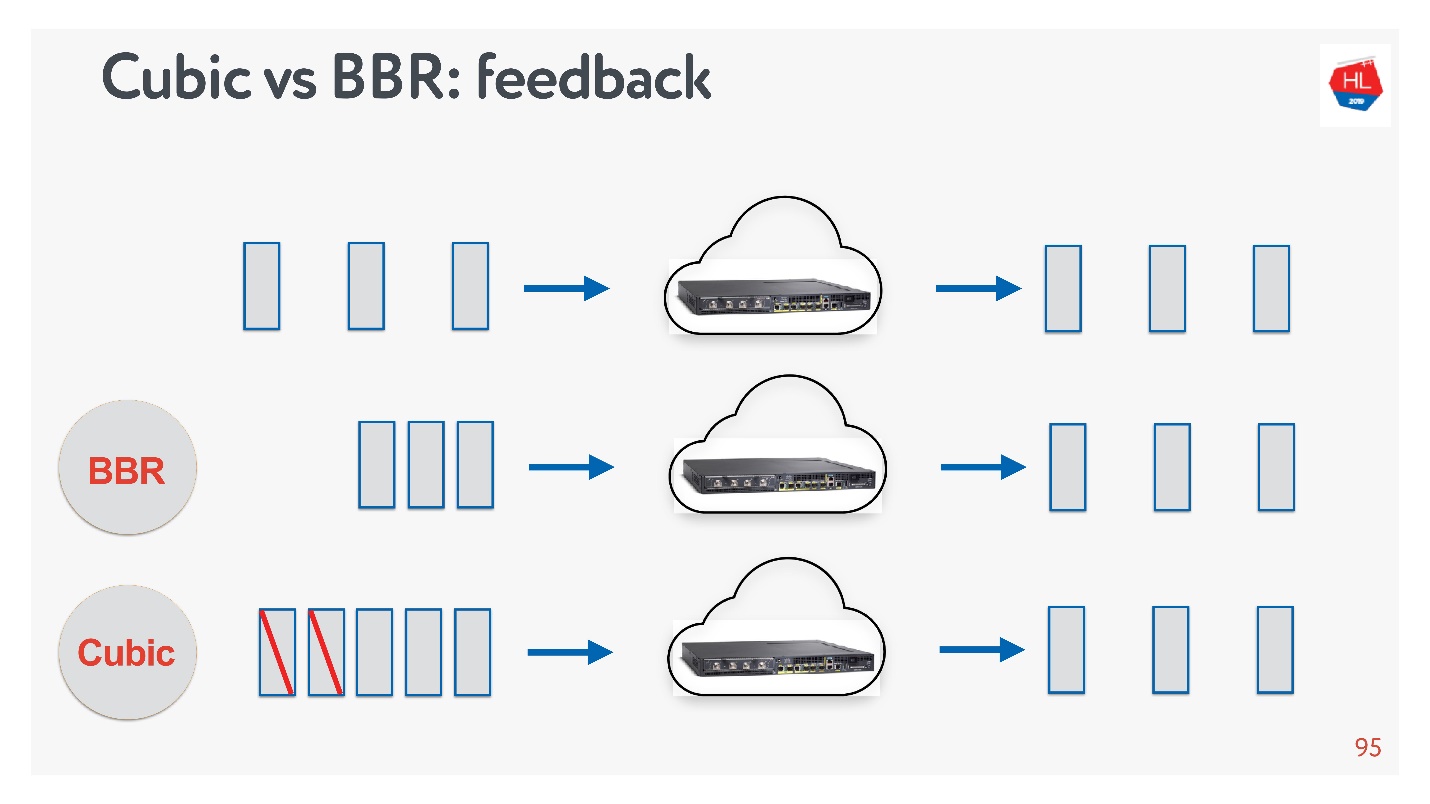
, — acknowledgement . :
Unten sehen Sie eine grafische Darstellung der Verzögerung gegenüber der Verbindungszeit, die zeigt, was bei verschiedenen Überlastungssteuerungen geschieht.
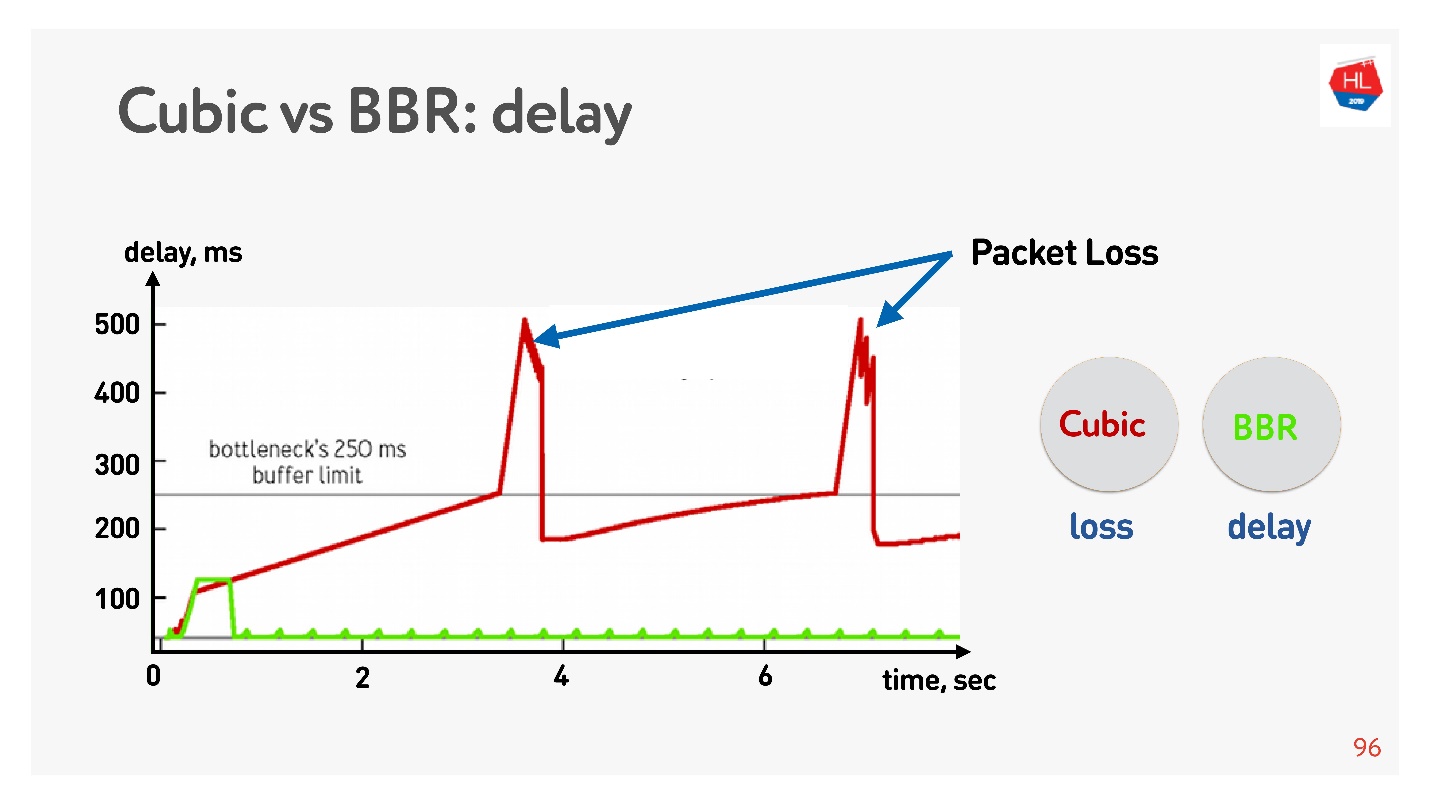
Der BBR erfasst zuerst die Umlaufzeit, sendet immer mehr Pakete, stellt dann fest, dass der Puffer verstopft ist, und wechselt mit minimaler Verzögerung in den Betriebsmodus.
Cubic arbeitet aggressiv - es läuft über den gesamten Puffer, und wenn der Puffer überläuft und Paketverlust auftritt, reduziert Cubic das Fenster.
Es scheint, dass es mit Hilfe von BBR möglich wäre, alle Probleme zu lösen, aber es gibt
Jitter in den Netzwerken - Pakete werden manchmal verzögert, manchmal in Bündeln gruppiert. Sie senden sie mit einer bestimmten Häufigkeit und sie kommen in Gruppen. Schlimmer noch, wenn Sie Bestätigungen zurück zu diesen Paketen erhalten, und sie auch irgendwie "jitter".
Da ich versprochen habe, dass alles von Hand berührt werden kann,
pingen wir zum Beispiel die
HighLoad ++ - Site an, schauen uns Ping an und betrachten Jitter zwischen Paketen.
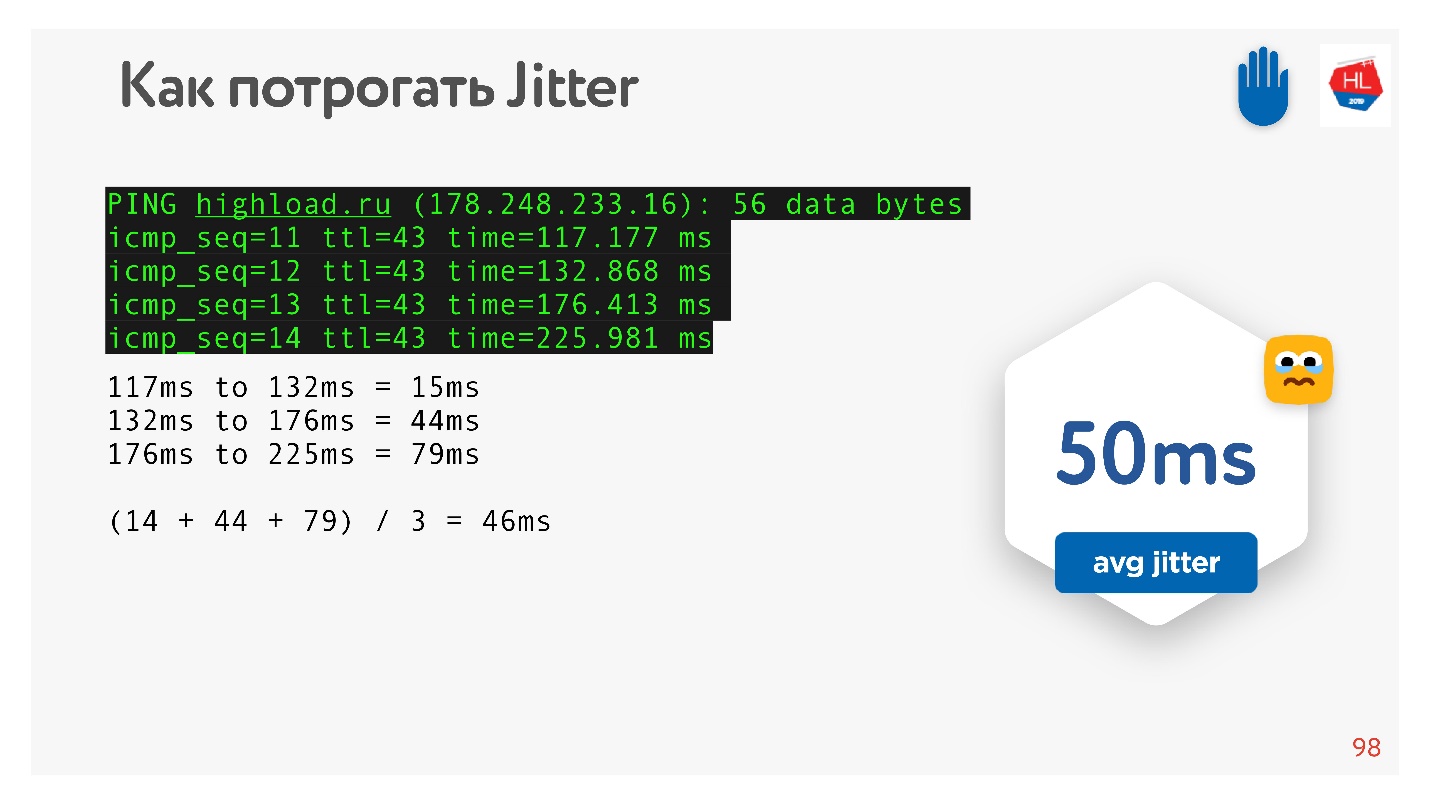
Es ist ersichtlich, dass die Pakete ungleichmäßig kommen, der durchschnittliche Jitter beträgt ca. 50 ms. Natürlich kann BBR falsch sein.
BBR ist gut, weil es unterscheidet zwischen: echtem Überlastungsverlust, Paketverlust aufgrund von Gerätepufferüberläufen und zufälligem Verlust aufgrund eines schlechten drahtlosen Netzwerks. Bei hohem Jitter funktioniert es jedoch nicht gut. Wie kann ich ihm helfen?
So verbessern Sie die Überlastungskontrolle
Tatsächlich hat TCP nicht genügend Informationen zur Bestätigung, sondern nur die Pakete, die es gesehen hat. Es gibt auch eine selektive Bestätigung, die besagt, welche Pakete bestätigt wurden, welche noch nicht angekommen sind. Diese Informationen reichen jedoch nicht aus.
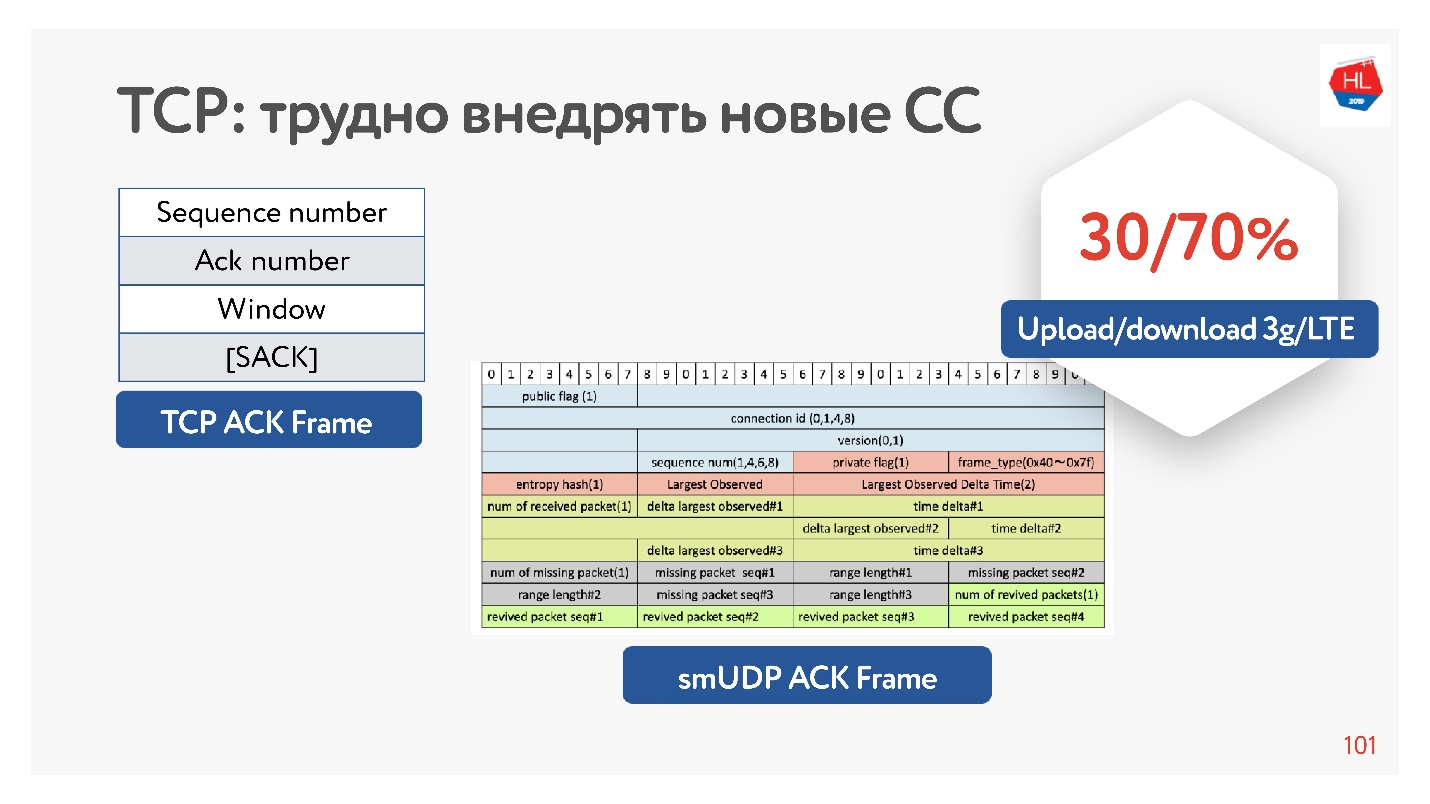
Wenn Sie die Möglichkeit haben, die Bestätigung aufzublähen, können Sie trotzdem die ganze Zeit sparen - nicht nur diese Pakete senden, sondern auch beim Client ankommen. Das ist in der Tat auf dem Server, um den Jitter-Client zu sammeln.
Warum ist es im Allgemeinen effektiv, die Bestätigung zu erhöhen? Weil Mobilfunknetze asymmetrisch sind. Beispielsweise werden normalerweise mit 3G oder LTE 70% der Bandbreite für das Herunterladen von Daten und 30% für das Hochladen zugewiesen. Der Sender wechselt: Upload - Download, Upload - Download, und Sie haben keinerlei Auswirkungen darauf. Wenn Sie nichts entladen, ist es einfach im Leerlauf. Wenn Sie also interessante Ideen haben, erhöhen Sie die Anerkennung, seien Sie nicht schüchtern - dies ist kein Problem.
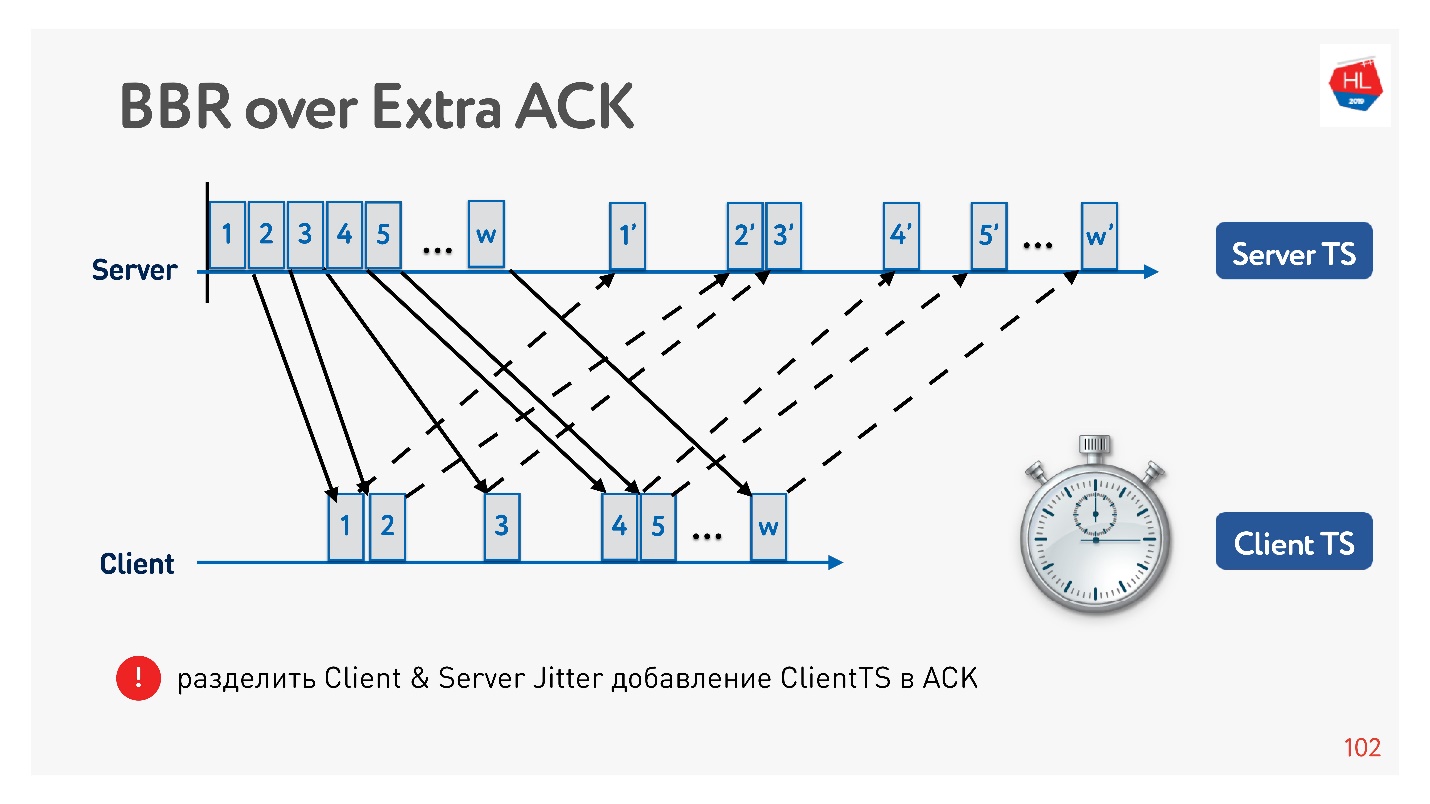
Ein Beispiel dafür, wie Sie mithilfe einer Bestätigung den Jitter in Senden und Empfangen in Jitter unterteilen und separat verfolgen können. Dann werden wir flexibler und verstehen, wann ein Überlastungsverlust aufgetreten ist und wann ein zufälliger Verlust aufgetreten ist. Sie können beispielsweise verstehen, wie viel Jitter in jeder Richtung vorhanden ist, und das Fenster genauer konfigurieren.

Welche Überlastungskontrolle soll man wählen?
Klassenkameraden sind ein großes Netzwerk mit viel unterschiedlichem Verkehr: Video, API, Bilder. Und es gibt Statistiken, für die die Überlastungskontrolle besser zu wählen ist.
BBR ist für Videos immer effektiv, da es Verzögerungen reduziert. In anderen Fällen wird normalerweise Cubic verwendet - es ist gut für Fotos. Es gibt aber auch andere Möglichkeiten.

Es gibt Dutzende verschiedener Optionen zur Überlastungskontrolle. Um die beste auszuwählen, können Sie Statistiken auf dem Client sammeln und die eine oder andere Überlastungskontrolle für verschiedene Arten von Lastprofilen ausprobieren.
Dies ist beispielsweise der Effekt des Startens von BBR für ein Video.
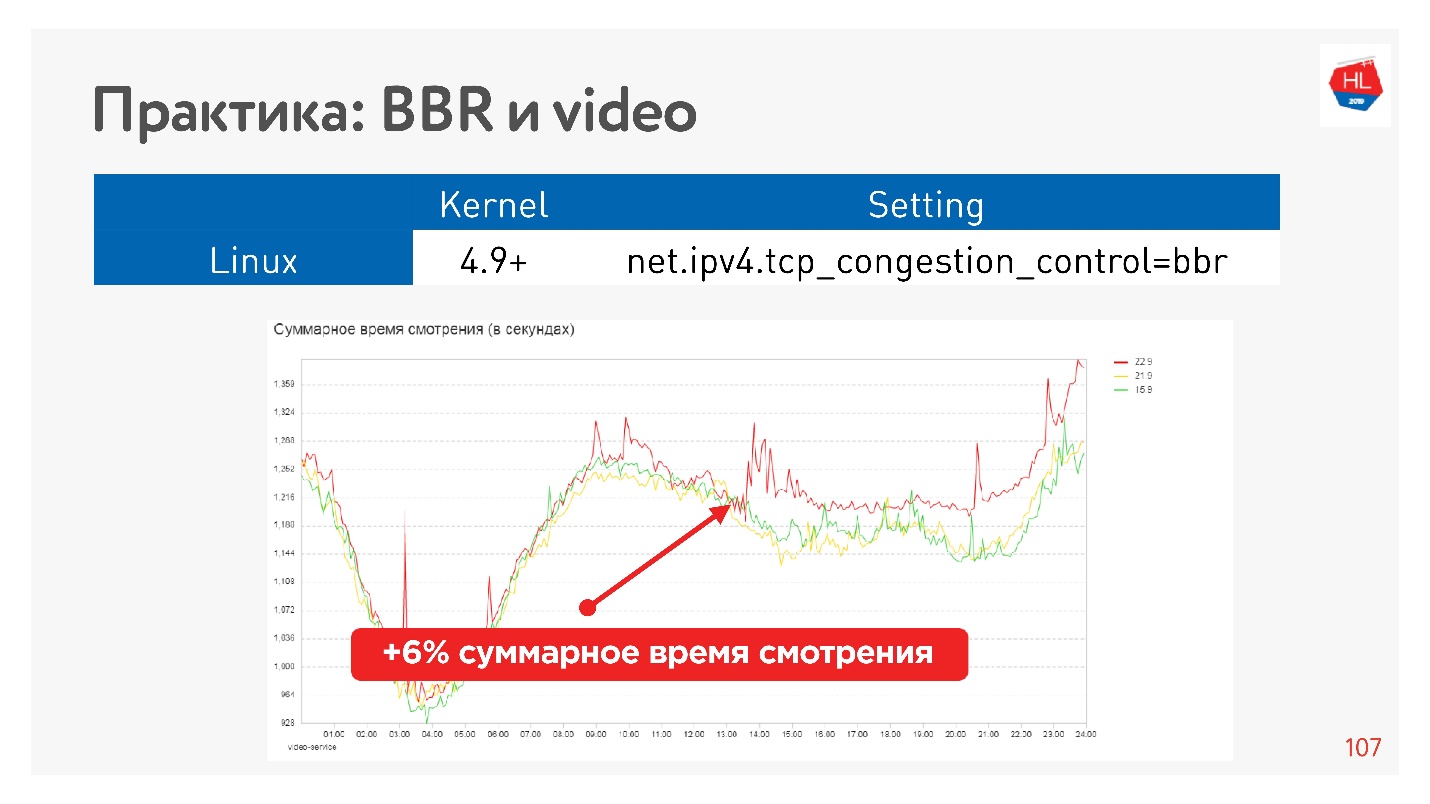
Wir haben es geschafft, die Betrachtungstiefe ernsthaft zu erhöhen. Google sagt, dass der Player bei Verwendung von BBR etwa 10% weniger Puffer enthält.
Großartig, aber was ist mit unseren Kunden?

Kunden sind etwas langsam, sie haben alle Cubic und Sie können es nicht beeinflussen. Aber es ist okay, manchmal können Sie Daten parallelisieren, und es wird gut sein.
Schlussfolgerungen zur Überlastungskontrolle:- BBR ist immer gut für Videos.
- In anderen Fällen können Sie die Überlastungskontrolle mitnehmen, wenn wir unser eigenes UDP-Protokoll verwenden.
- Aus TCP-Sicht können Sie nur die Überlastungskontrolle verwenden, die sich im Kernel befindet. Wenn Sie Ihre Überlastungskontrolle im Kernel implementieren möchten, müssen Sie die TCP-Spezifikation einhalten. Es ist unmöglich, die Bestätigung zu erhöhen, Änderungen vorzunehmen, weil sie einfach nicht auf dem Client liegen.
Wenn Sie Ihr UDP-Protokoll erstellen, haben Sie viel mehr Freiheit bei der Überlastungskontrolle.
Multiplexing und Priorisierung
Dies ist ein neuer Trend, jeder macht es jetzt. Welche Probleme gibt es? Wenn wir TCP verwenden, kennt sicherlich jeder (oder fast jeder) die Head-of-Line-Blockierungssituation.
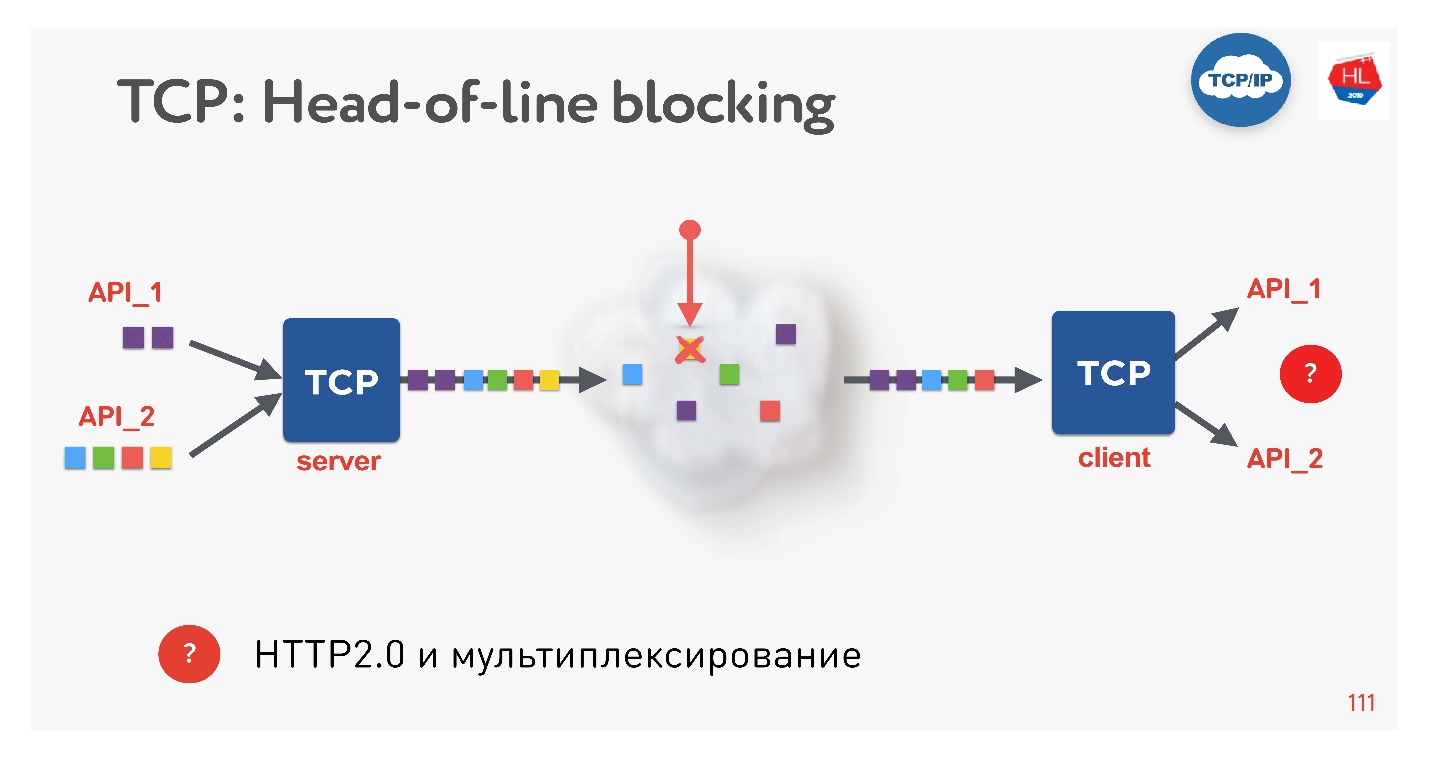
Es gibt mehrere Anforderungen, die über eine einzelne TCP-Verbindung gemultiplext werden. Wir haben sie an das Netzwerk gesendet, aber ein Paket fehlte. Eine TCP-Verbindung überträgt dieses Paket erneut, und zwar in einer Zeit nahe RTT oder länger. Derzeit können wir nichts abrufen, obwohl der TCP-Puffer Daten von einer anderen Anforderung enthält, die vollständig zur Abholung bereit ist.
Es stellt sich heraus, dass Multiplexing über TCP, wenn Sie HTTP 2.0 verwenden, in schlechten Netzwerken nicht immer effektiv ist.
Das nächste Problem ist die Pufferquellung.

Wenn ein Bild an den Client gesendet wird, erhöht sich der Puffer. Wir senden es für eine lange Zeit, und dann erscheint eine API-Anfrage, die in keiner Weise priorisiert werden kann. In solchen Fällen funktioniert die TCP-Priorisierung nicht.
Wenn also ein Paketverlust auftritt, kommt es zu einer Head-of-Line-Blockierung, und wenn der Client eine variable Bitrate hat (und dies passiert häufig bei mobilen Clients), wird der Bufferbloat-Effekt angezeigt. Infolgedessen funktionieren weder Multiplexing noch Priorisierung noch Server-Push oder alles andere, da wir entweder Puffer haben oder der Client etwas erwartet.
Wenn wir unser eigenes Multiplexing durchführen, können wir dort verschiedene Daten ablegen.
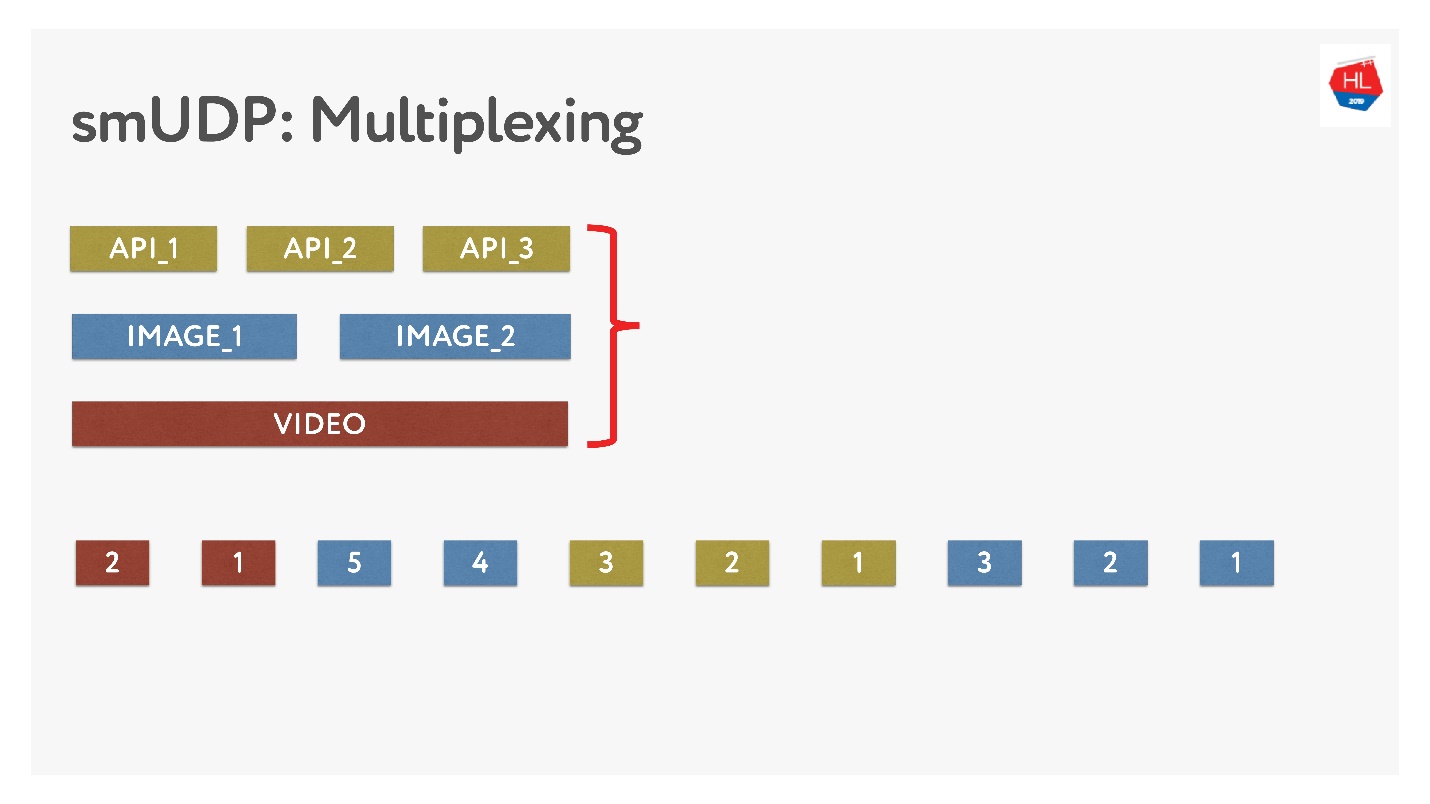
Dies ist nicht schwierig, fügen Sie einfach Pakete mit Zahlen zum Puffer hinzu. On-the-Fly - Berühren Sie nicht, was bereits gesendet wurde, aber was noch nicht gesendet wurde, kann neu angeordnet werden. Es sieht so aus.
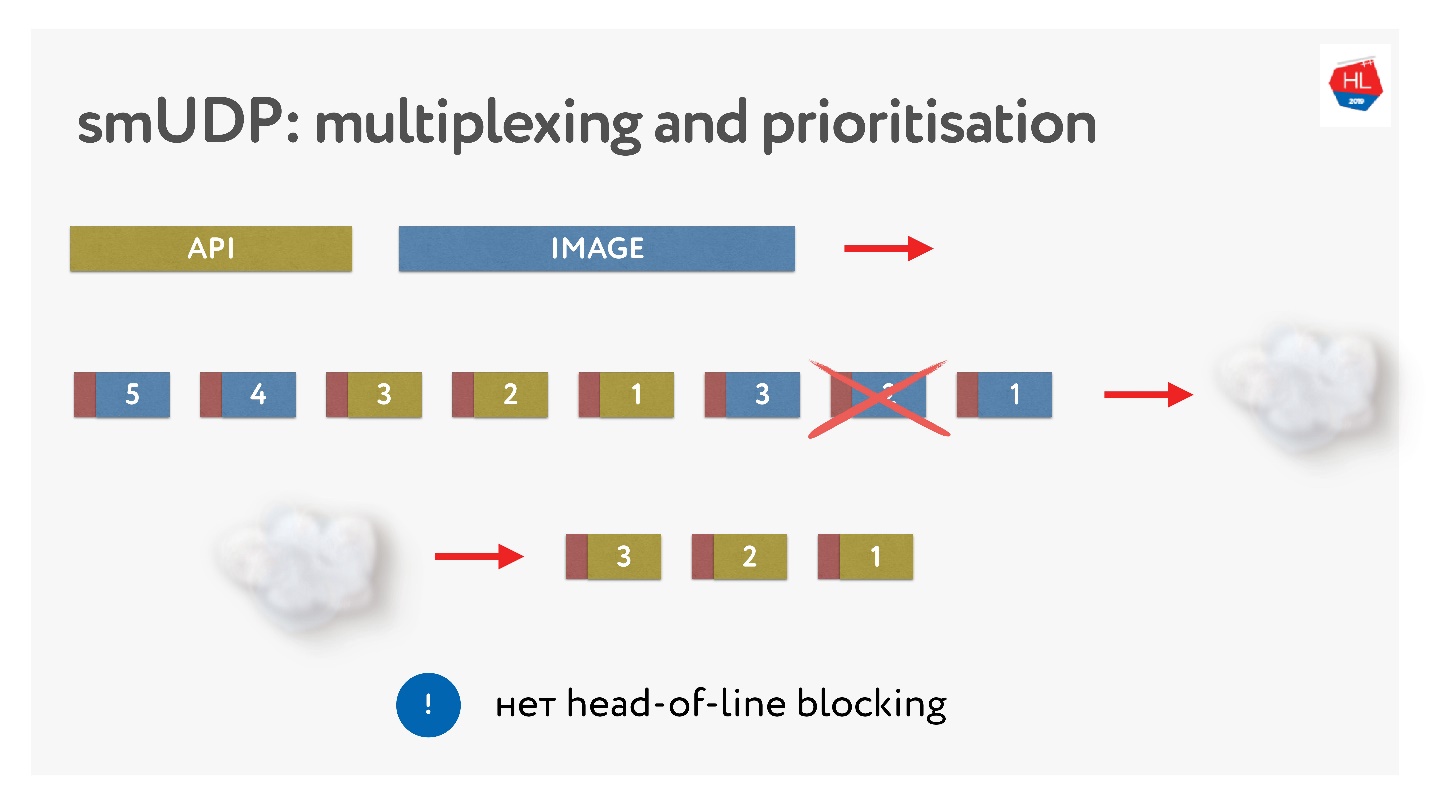
Sie haben Bilder gesendet, sie in Pakete aufgeteilt, eine vorrangige API-Anfrage gestellt: Sie haben sie eingefügt und das Bild gesendet. Selbst wenn ein Paket fehlt, können wir eine vorgefertigte API-Anfrage aus dem Puffer erhalten. Diese hat hohe Priorität und erreicht schnell den Client. In TCP ist per Definition keine Streaming-Datenübertragung möglich.
Stellen Sie eine Verbindung her
Wenn wir unsere Anwendung profilieren, werden wir feststellen, dass das Netzwerk zu Beginn der Anwendung die meiste Zeit inaktiv ist, da die Verbindung zuerst vor der API hergestellt wird, dann die Daten abgerufen werden und die Verbindung vor den Bildern hergestellt wird, diese Daten heruntergeladen werden usw. Dies geschieht immer - das Netzwerk wird von Spitzen genutzt.

Lassen Sie uns sehen, wie die Verbindung hergestellt wird, um damit umzugehen.
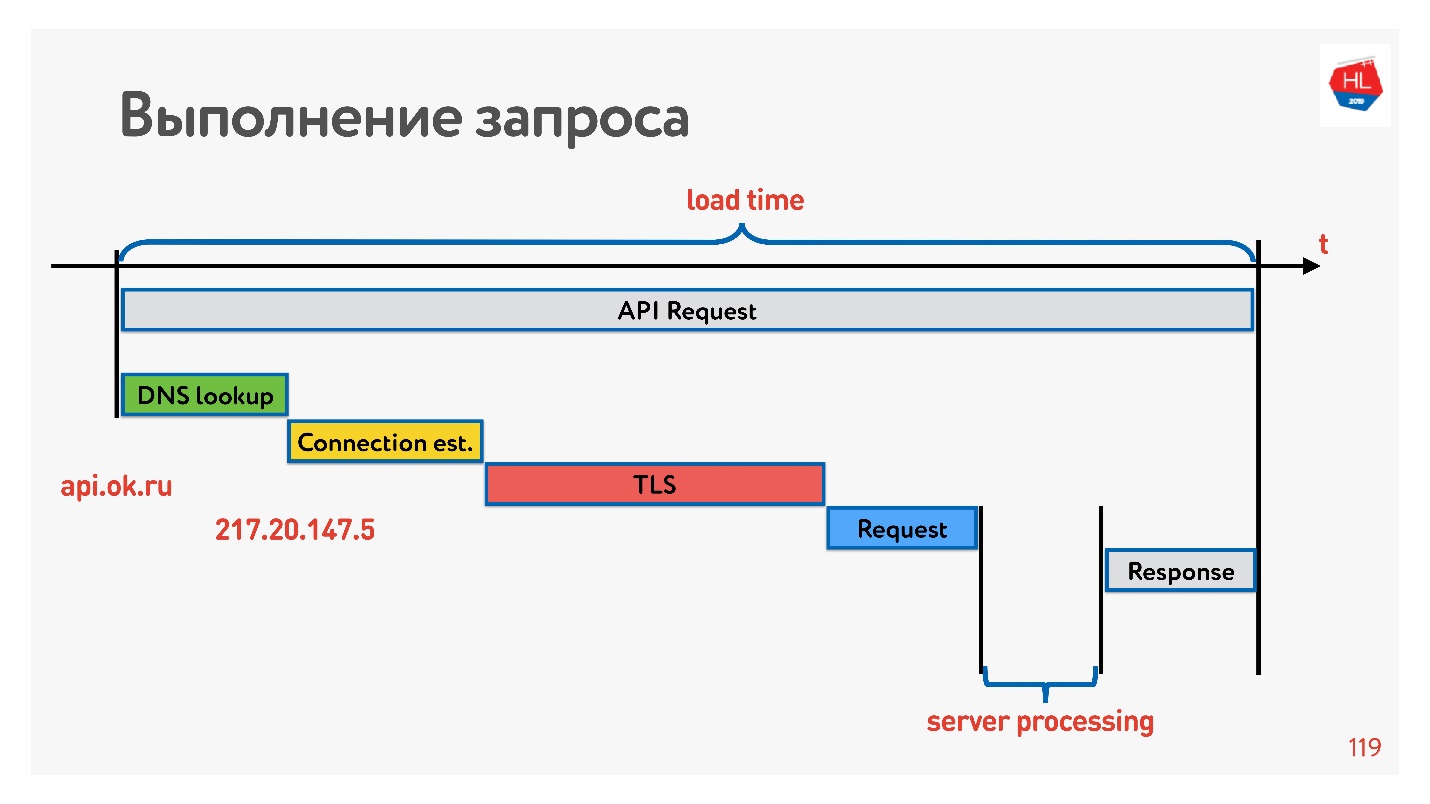
Das erste ist DNS auflösen - wir können damit nichts anfangen. Stellen Sie als Nächstes eine TCP-Verbindung her, stellen Sie eine sichere Verbindung her, führen Sie die Anforderung aus und erhalten Sie eine Antwort. Das Interessanteste ist, dass ein Teil der Arbeit, die der Server bei der Beantwortung einer Anfrage leistet, normalerweise weniger Zeit in Anspruch nimmt als das Herstellen einer Verbindung.
Jetzt ist es sehr modern, Latenzzahlen für Speicher, Festplatten und etwas anderes zu messen. Sie können sie für ein 3G-, 4G-Netzwerk messen und sehen, wie lange es im schlimmsten Fall dauert, eine TCP-Verbindung mit TLS herzustellen.
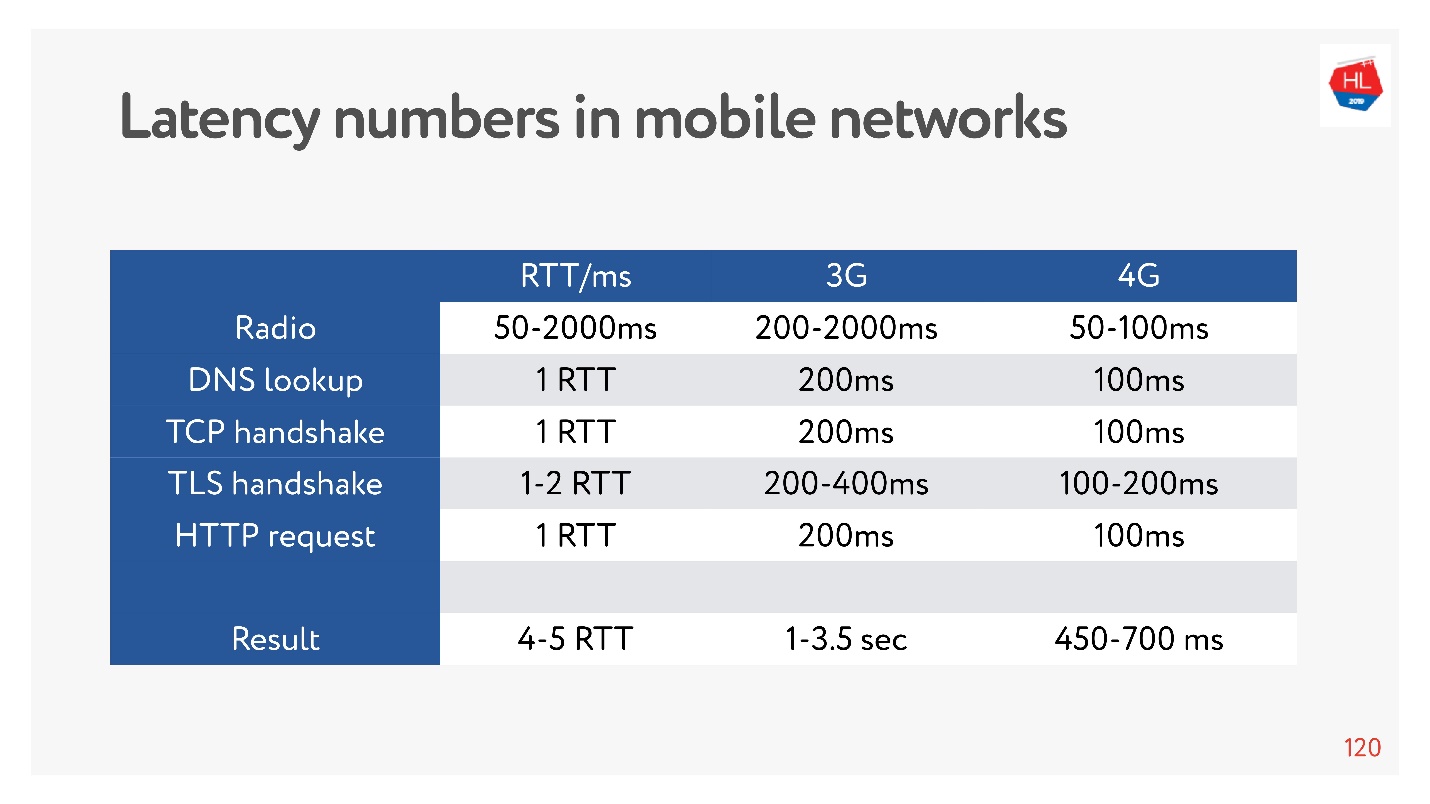
Und es kann Sekunden sein! Auch bei 4G sind bis zu 700 ms von Bedeutung. Aber TCP konnte die ganze Zeit nicht so einfach leben.
Die Verbindung basiert auf dem grundlegenden
TCP-3-Wege-Handshake- Algorithmus. Führen Sie syn, syn + ack aus und korrigieren Sie die Anforderung später (links im Diagramm).
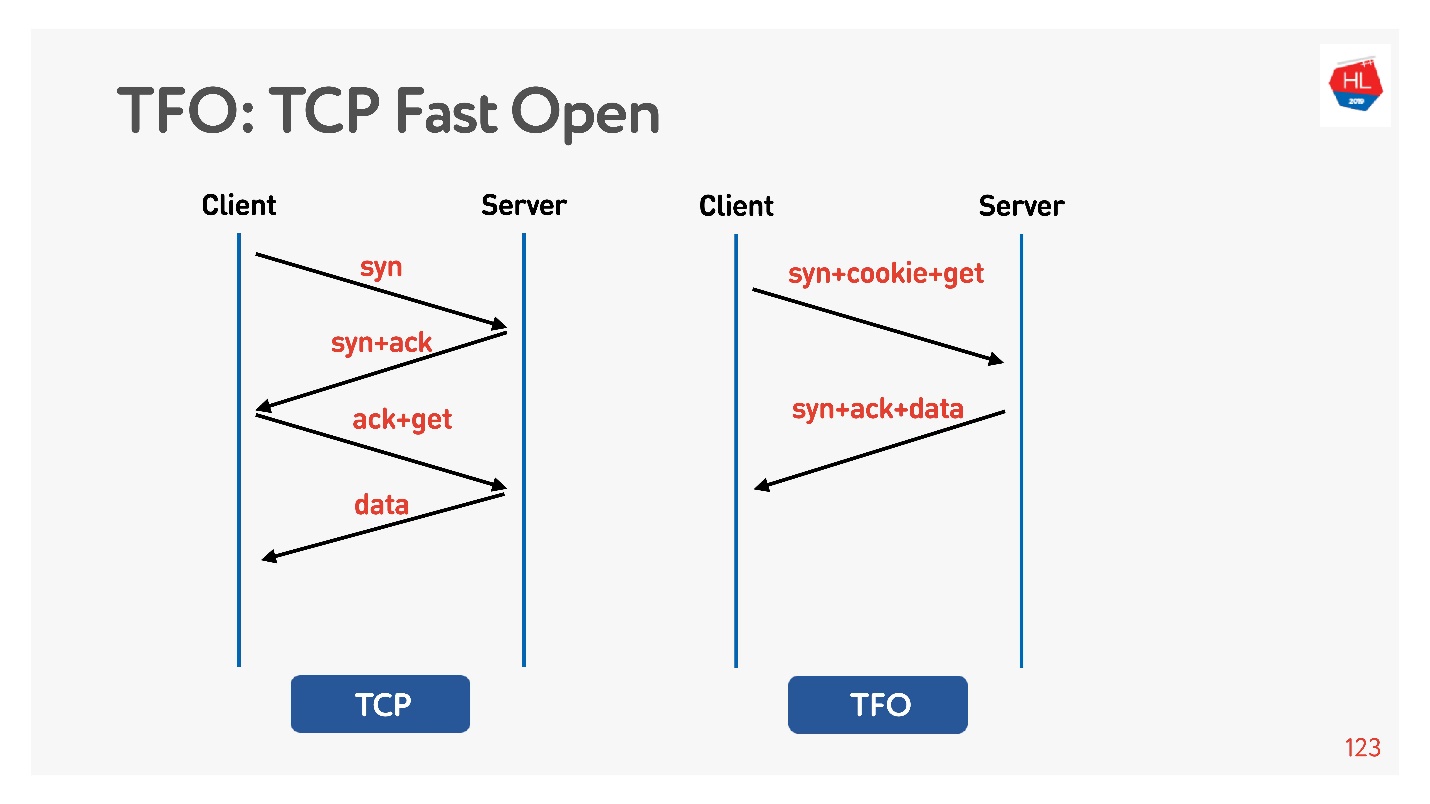
Es gibt
TCP Fast Open (rechts). Wenn Sie bereits mit diesem Server von Hand geschüttelt haben, gibt es ein Cookie. Sie können Ihre Anfrage für Zero-RTT sofort senden. Um dies zu verwenden, müssen Sie einen Socket erstellen, sendto () zu den ersten Daten machen und sagen, dass Sie FASTOPEN möchten.

Nginx kann all dies - schalten Sie es einfach ein, alles wird funktionieren (oder schalten Sie es im Kernel ein).
TLS
Lassen Sie uns überprüfen, ob TLS schlecht ist.
Ich stellte den Net Shaper erneut für 200 ms ein, pingte google.com und sah, dass RTT = 220 mein RTT + RTT Shaper ist. Dann habe ich eine Anfrage über HTTP und HTTPS gestellt. Ich habe herausgefunden, dass es über HTTP möglich ist, während RTT eine Antwort zu erhalten, dh TFO funktioniert für Google von meinem Computer aus. Bei HTTPS dauerte dies länger.

Dies ist ein so häufiger TLS-Overhead, für den Messaging erforderlich ist, um eine sichere Verbindung herzustellen.
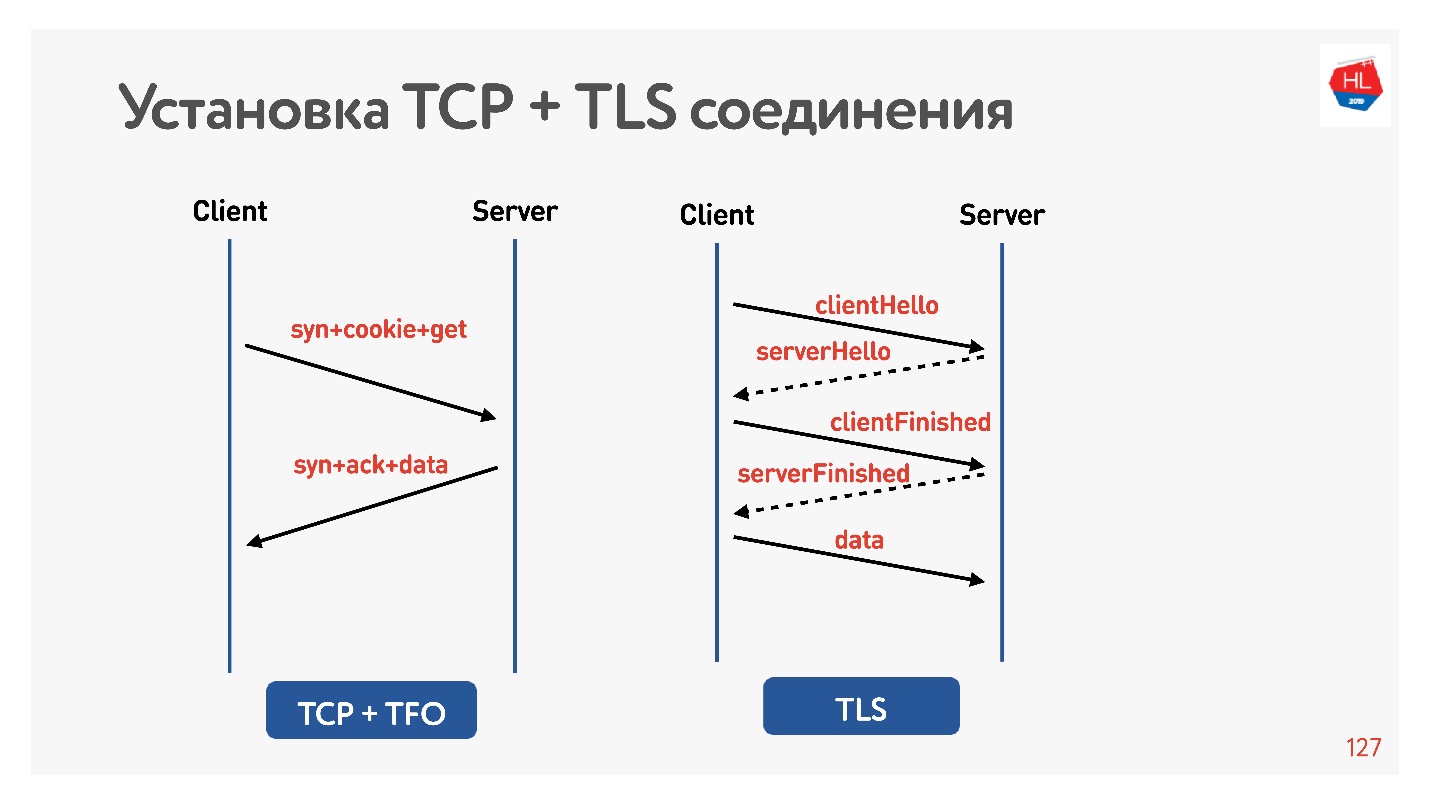
Um dies zu tun, haben sie für uns gedacht, TLS 1.3 hinzugefügt. Es ist auch einfach, in Nginx aufzunehmen.
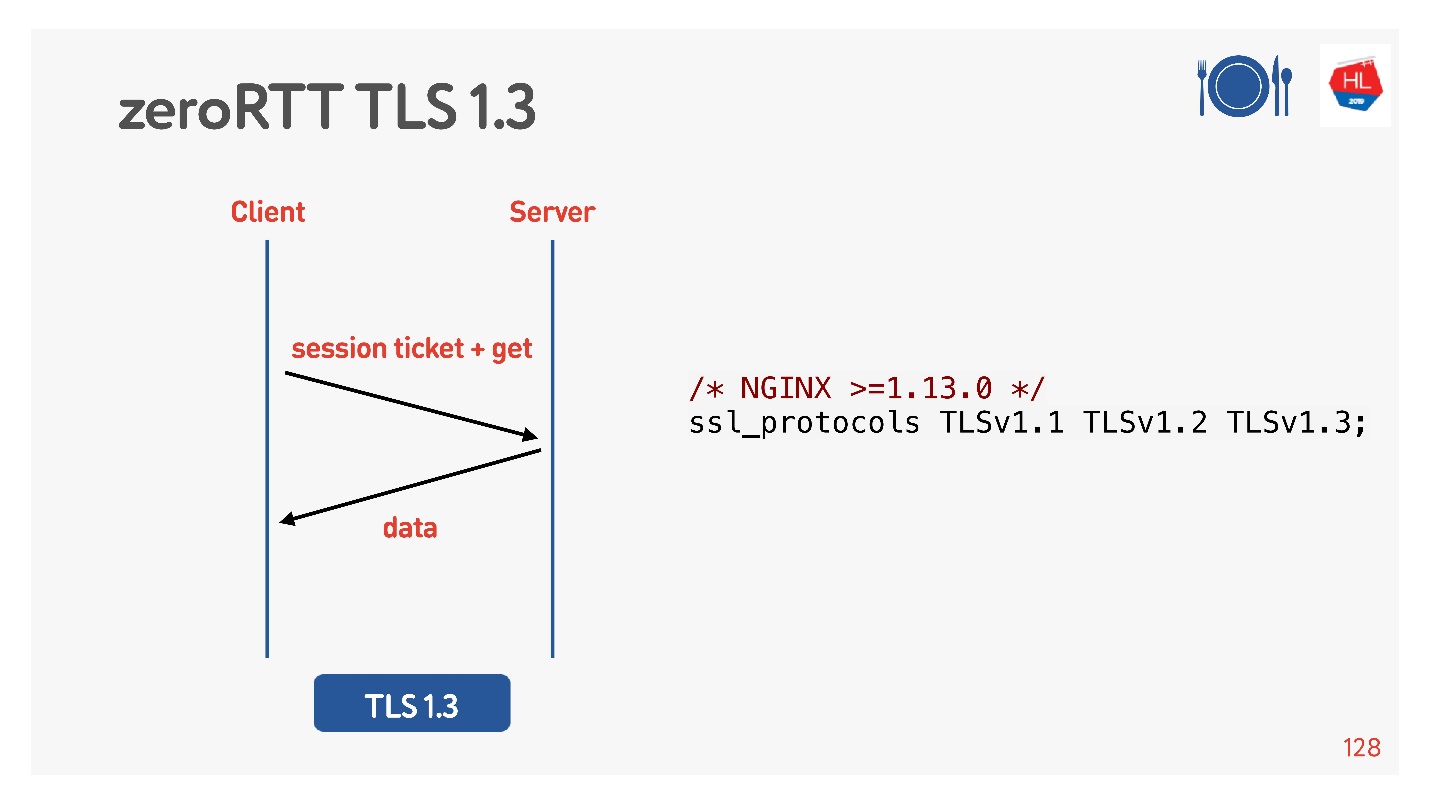
Alles scheint zu funktionieren. Aber mal sehen, was auf unseren mobilen Clients ist, die all dies nutzen.
Was ist mit Kunden los?
TCP Fast Open ist eine coole Sache. Laut Statistik.
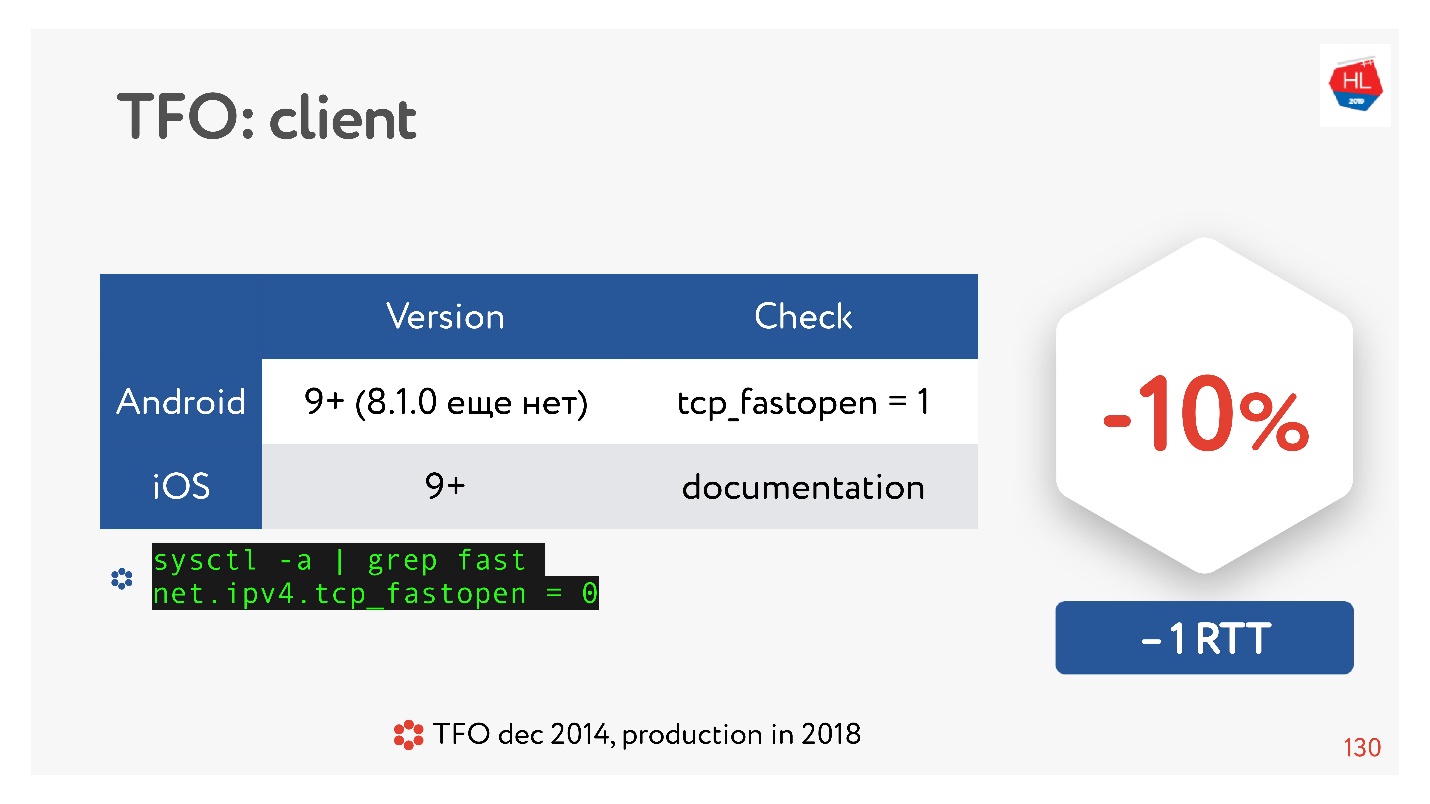
Es gibt viele Artikel, die besagen, dass das Herstellen einer Verbindung garantiert 10% schneller verläuft. Aber auf Android 8.1.0 (ich habe verschiedene Geräte gesehen) hat niemand TFO. Unter Android 9 habe ich TFO auf dem Emulator gesehen, aber nicht auf echten Geräten. IOS ist ein bisschen besser. Hier können Sie es sehen:
sysctl -a | grep fast net.ipv4.tcp_fastopen = 0
Warum ist das passiert? TCP Fast Open wurde bereits 2014 vorgeschlagen, jetzt ist es bereits ein Standard, es wird unter Linux unterstützt und alles ist großartig. Es gibt jedoch ein derartiges Problem, dass der TFO-Handshake in einigen Netzwerken auseinanderzufallen begann. Dies liegt daran, dass einige Anbieter (oder einige Geräte) es gewohnt sind, TCP zu überprüfen und ihre Optimierungen vorzunehmen, und nicht damit gerechnet haben, dass es zu einem TFO-Handshake kommt. Daher hat die Implementierung so viel Zeit in Anspruch genommen, und bis jetzt enthalten mobile Clients sie standardmäßig nicht, zumindest nicht Android.
Mit TLS 1.3, das uns verspricht, dass der Aufbau einer Null-RTT-Verbindung noch besser ist. Ich habe keine Android-Geräte gefunden, auf denen es funktionieren würde. Deshalb hat Facebook die
Fizz- Bibliothek erstellt. Vor ein paar Monaten wurde es in Open Source verfügbar. Sie können es mit sich ziehen und TLS 1.3 verwenden. Es stellt sich heraus, dass sogar Sicherheit mitgeschleppt werden muss, nichts erscheint im Kern davon.
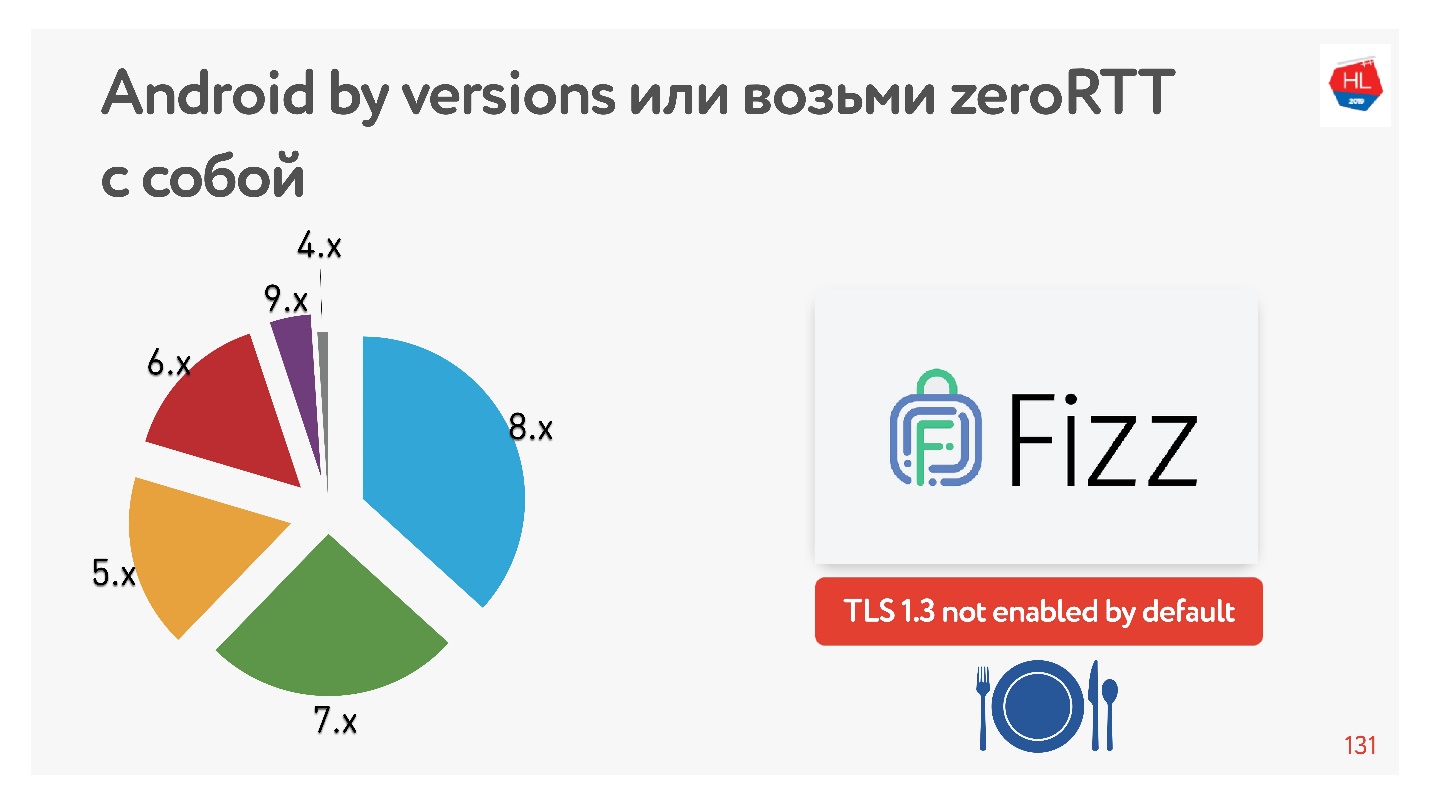
Das Diagramm zeigt die Verwendung verschiedener Android-Versionen durch unsere mobilen Clients. V 9.x ist ziemlich viel - wo TFO erscheinen kann und TLS1.3 nirgendwo anders zu finden ist.
Schlussfolgerungen zum Herstellen einer Verbindung:- TFO ist für 95% der Geräte nicht verfügbar.
- TLS1.3 muss mitgebracht werden.
- Wenn Sie dies in UDP wiederholen müssen, übertragen Sie dies alles auf UDP und wiederholen Sie den Vorgang.
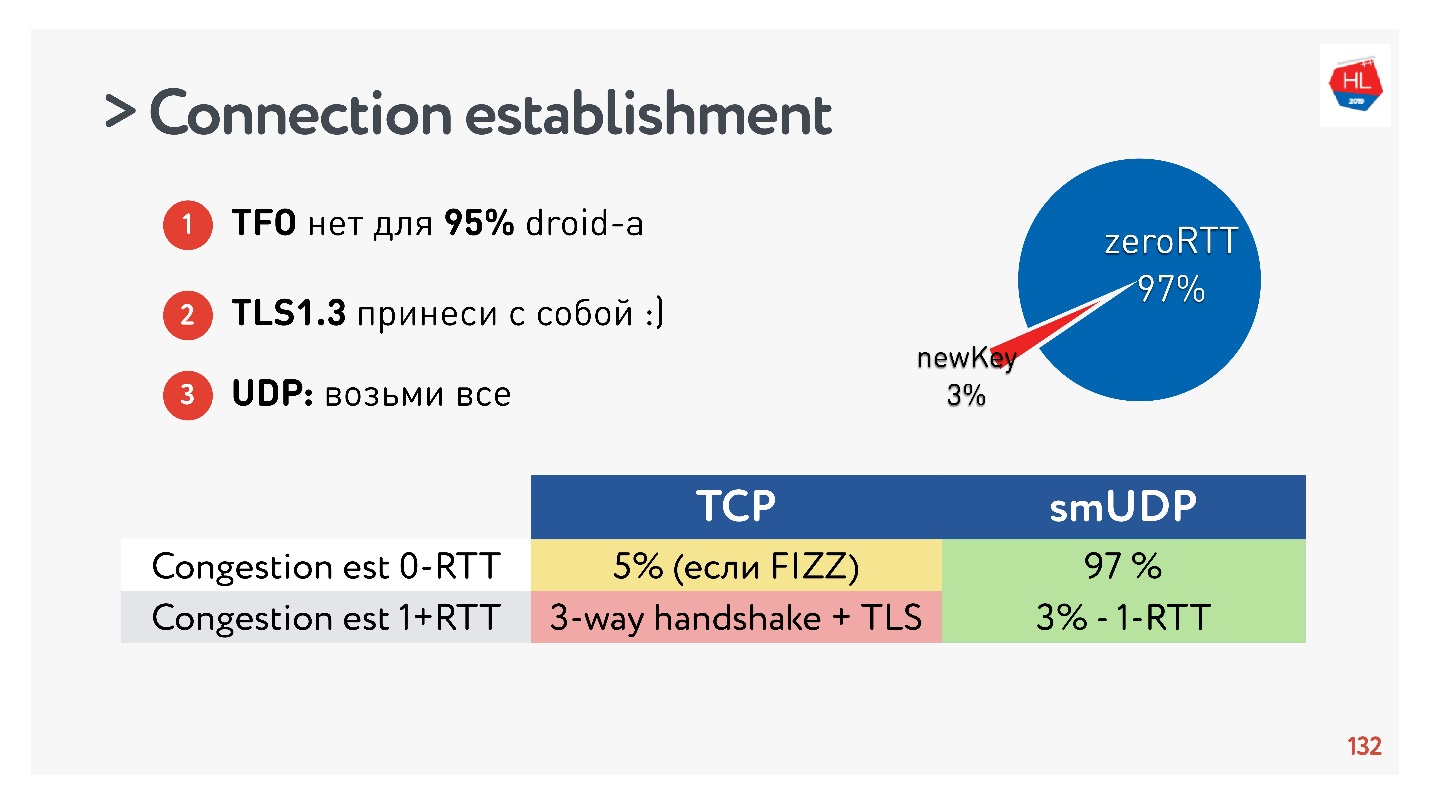
Es stellte sich heraus, dass 97% der erstellten Verbindungen den vorhandenen Schlüssel verwenden, dh 97% werden für RTT Null erstellt und nur 3% sind neu. Der Schlüssel ist einige Zeit auf dem Gerät gespeichert.
TCP kann nicht damit prahlen. In maximal 5% der Fälle können Sie, wenn Sie alles richtig machen, die echte Null-RTT erhalten, über die jetzt alle sprechen.
Änderung der IP-Adresse
Wenn Sie das Haus verlassen, wechselt Ihr Telefon häufig von Wi-Fi zu 4G.
TCP funktioniert folgendermaßen: Die IP-Adresse hat sich geändert - die Verbindung ist fehlgeschlagen.
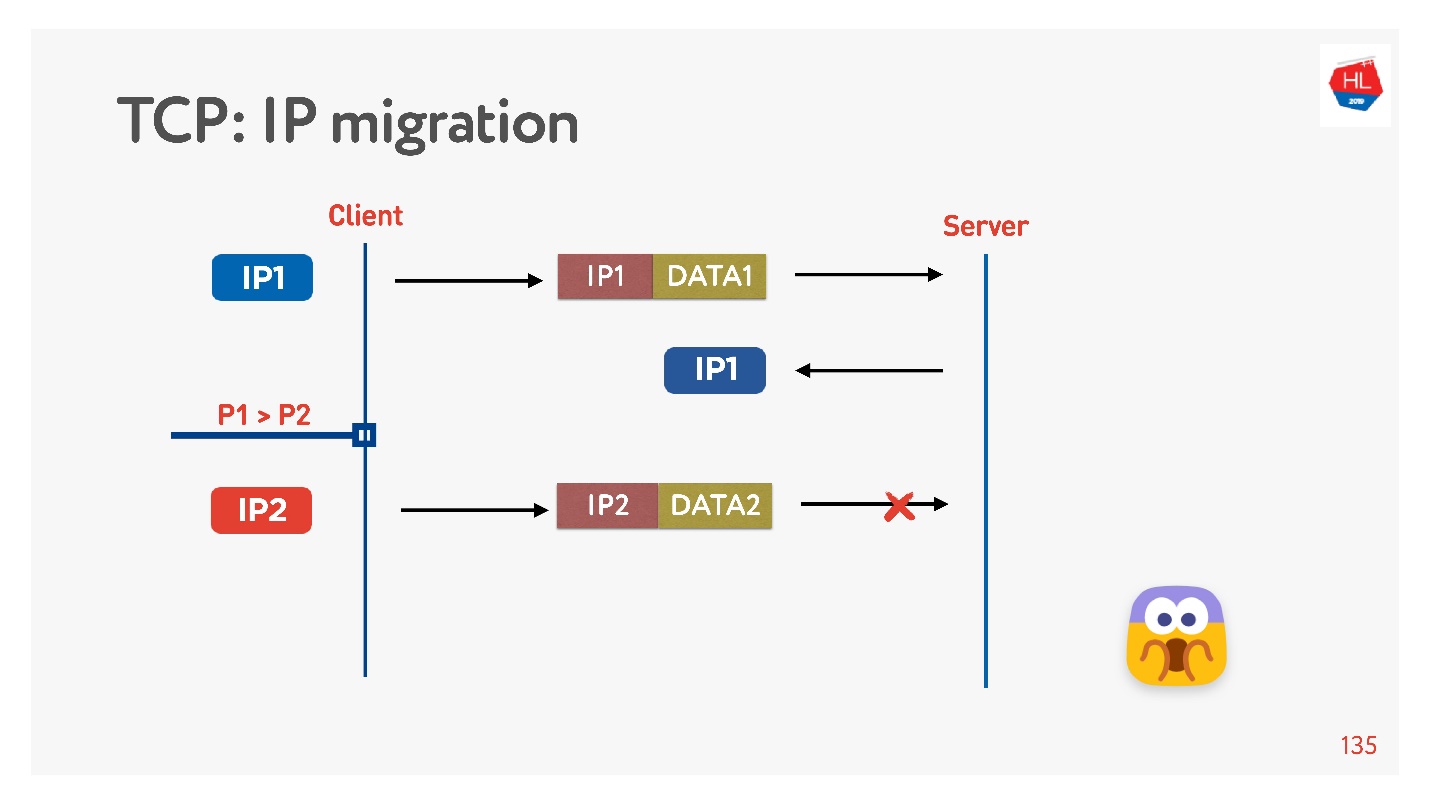
Wenn Sie Ihr UDP-Protokoll schreiben, ist es sehr einfach, indem Sie in jedem Paket eine Verbindungs-ID (CUID) implementieren. Sie können es identifizieren, auch wenn es von einer anderen IP-Adresse stammt.

Es ist klar, dass Sie sicherstellen müssen, dass es den richtigen Schlüssel hat, alles entschlüsselt ist usw. Aber im Prinzip können Sie auf diese Adresse antworten, es wird keine Probleme damit geben.
In TCP ist die IP-Migration unmöglich.
Wenn Sie Ihr UDP erstellen und zum selben Server gekommen sind, müssen Sie ein wenig zaubern, die CID in jedes Paket aufnehmen und die hergestellte Verbindung beim Ändern der IP-Adresse verwenden.
Wiederverwendung der Verbindung
Jeder sagt, dass Sie Verbindungen wiederverwenden müssen, weil Verbindungen eine sehr teure Sache sind.

Die Wiederverwendung von Verbindungen birgt jedoch Fallstricke.
Wahrscheinlich erinnern sich viele Leute (wenn nicht, dann sehen Sie
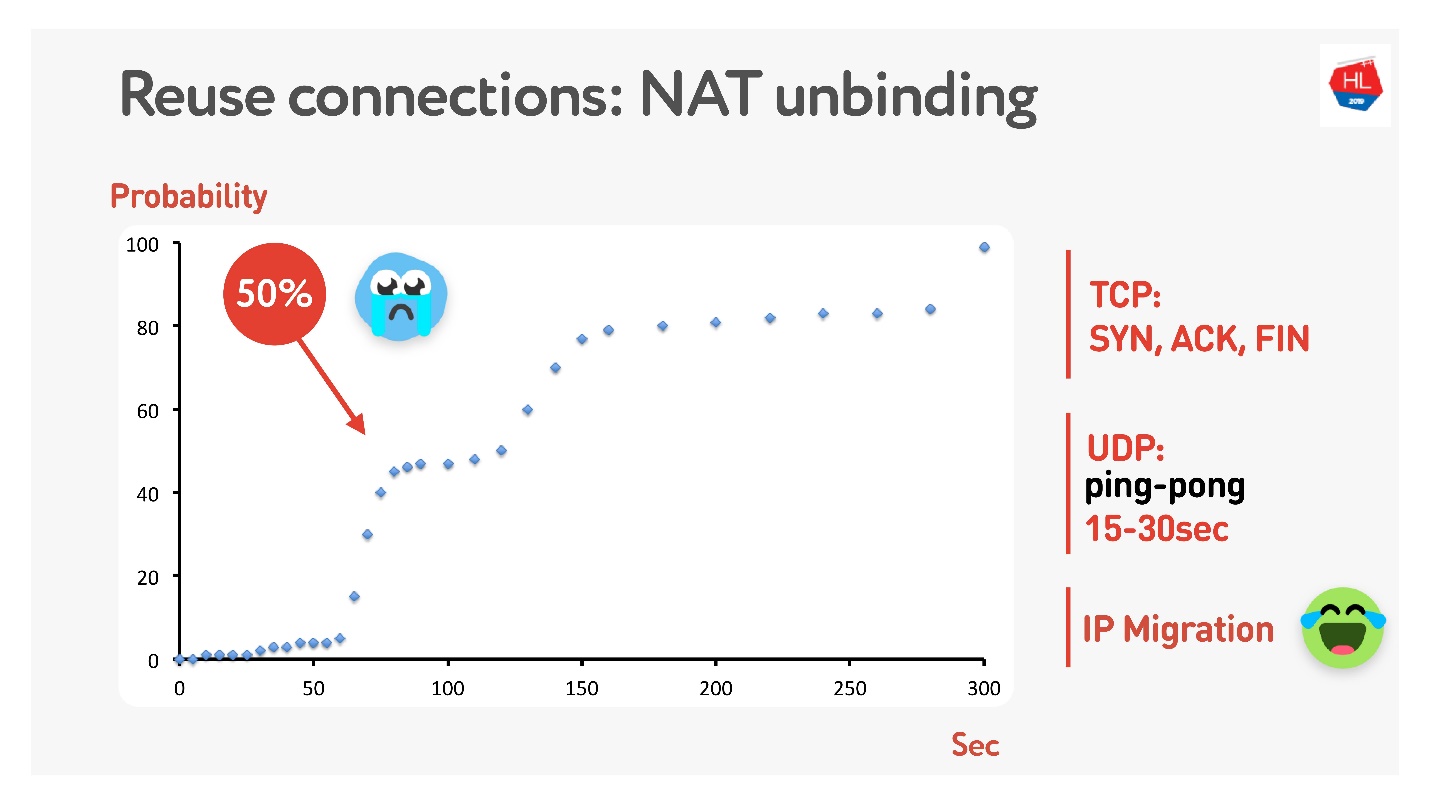
hier ), dass nicht jeder öffentliche Adressen hat, aber es gibt NAT, das normalerweise die Zuordnung für einige Zeit auf dem Heimrouter speichert. Für TCP ist klar, wie viel gespeichert werden soll, für UDP ist jedoch nicht klar. NAT arbeitet mit einem Timeout. Wenn Sie dieses Timeout sorgfältig messen, stellen wir fest, dass in etwa 15 bis 30 Sekunden mehr als 50% der Verbindungen ausfallen.
Es ist okay - wir machen für 15 s ein Ping-Pong-Paket. In Fällen, in denen die Verbindung immer noch unterbrochen ist, gibt es eine IP-Migration, mit der Sie den Port des Routers kostengünstig ändern können.
Paketstimulation
Dies ist sehr wichtig, wenn Sie Ihr UDP-Protokoll ausführen.

Wenn dies sehr einfach ist, ist die Wahrscheinlichkeit eines Paketverlusts umso größer, je länger Sie kontinuierlich Pakete an das Netzwerk senden. Wenn Sie Pakete herausfiltern, ist der Paketverlust geringer.
Es gibt viele verschiedene Theorien, wie das funktioniert, aber ich mag diese.
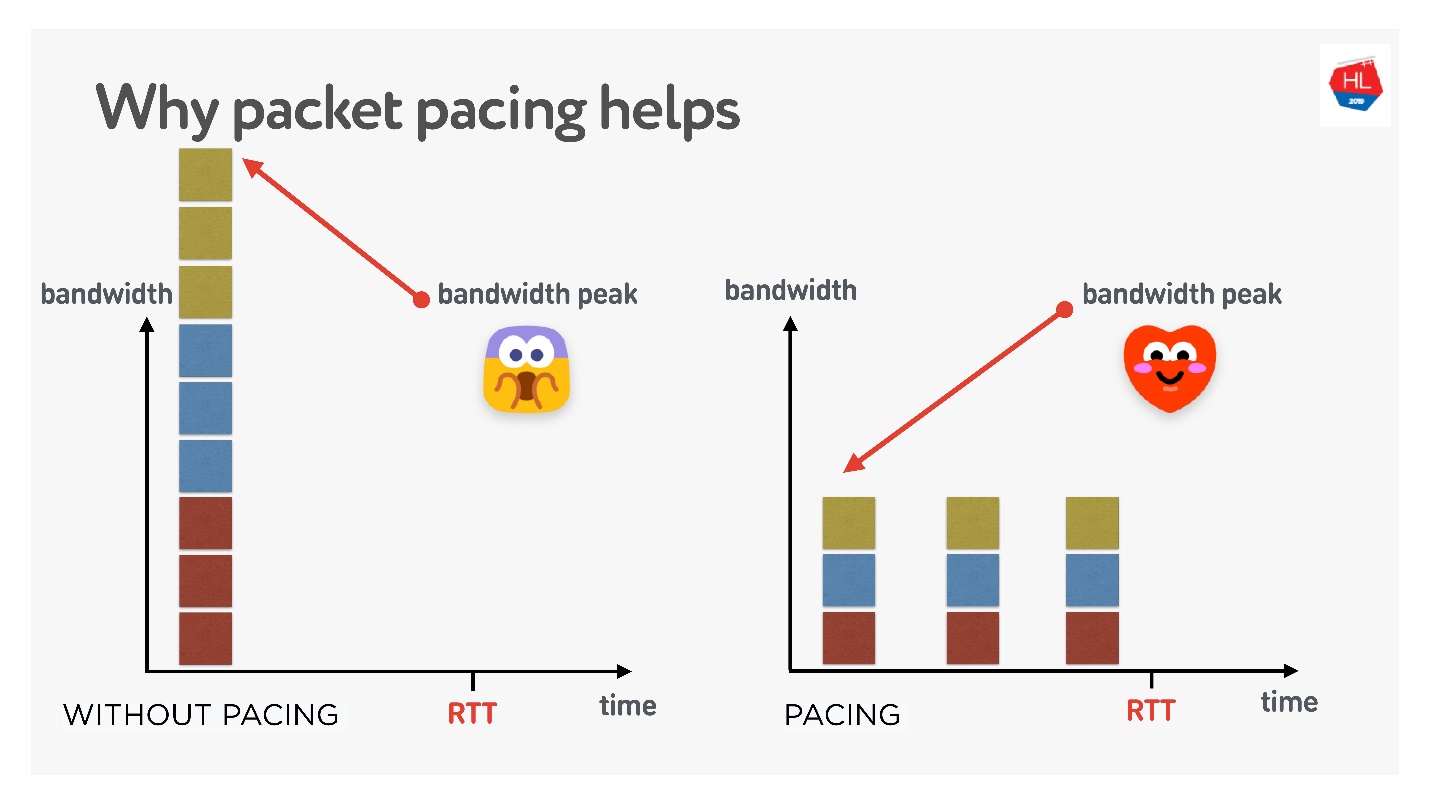
Es gibt 3 Verbindungen, die gleichzeitig erstellt werden. Sie haben das sogenannte Anfangsfenster - 10 Pakete gleichzeitig erstellt. Natürlich reicht die Bandbreite zu diesem Zeitpunkt möglicherweise nicht aus. Wenn Sie sie jedoch sorgfältig verteilen und trennen, ist alles in Ordnung, wie in der richtigen Abbildung dargestellt.
Wenn Sie also eine einheitliche Rate für das Senden von Paketen festlegen und diese ausdünnen, wird die Wahrscheinlichkeit eines gleichzeitigen Pufferüberlaufs geringer. Dies ist nicht bewiesen, aber theoretisch sieht es so aus.

Wenn Sie Pakete durchschneiden müssen (Schritt machen):
- Wenn Sie ein Fenster erstellen.
- Wenn Sie beispielsweise das Fenster vergrößern, wird empfohlen, so viele Pakete hinzuzufügen, wie für RTT / 2 gesendet werden können. Dies verkürzt die Lieferzeit nicht, verringert jedoch den Paketverlust.
- Im Falle eines Überlastungsverlusts müssen Sie die Pakete noch mehr verschmieren, um das Fenster zu verkleinern. 4/5 RTT ist eine empirisch ausgewählte Zahl.
MTU
Denken Sie beim Schreiben Ihres UDP-Protokolls unbedingt an MTU. MTU ist die Größe der Daten, die Sie weiterleiten können.
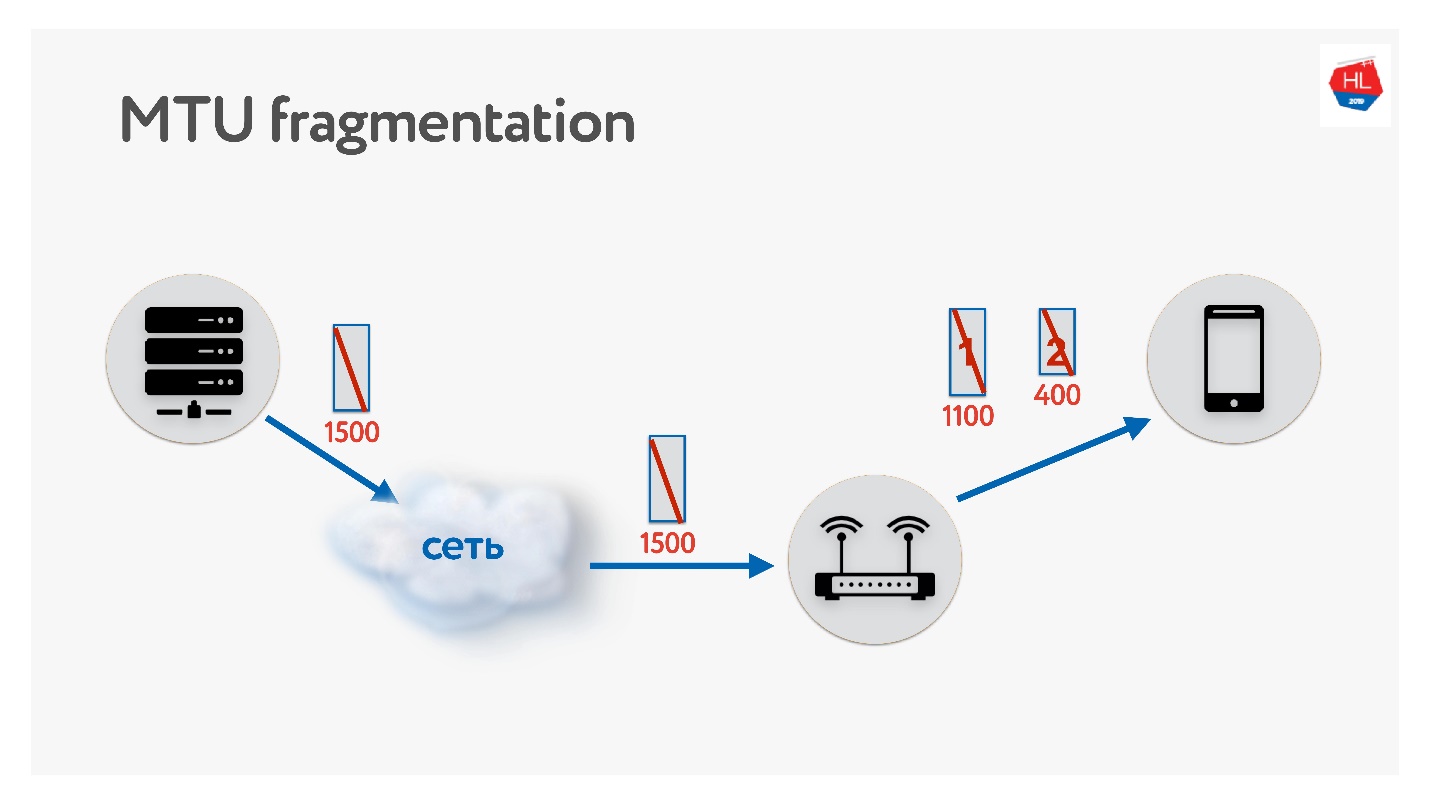
Wir senden beispielsweise Pakete vom Server an den Client mit einer Größe von 1500. Wenn sich auf dem Pfad ein Router befindet, der diese MTU-Größe nicht unterstützt, wird er fragmentiert. Das einzige Fragmentierungsproblem besteht darin, dass bei einem Verlust eines Pakets beide verloren gehen und all dies erneut übertragen werden muss. Daher verfügt TCP über einen Algorithmus zur Bestimmung von MTU - PMTU.

Jeder Router betrachtet die MTU seiner Schnittstelle, sendet sie an einen Client, der andere sendet sie an seinen Client, jeder weiß, wie viele MTUs er auf dem Client hat. Dann wird die Fragmentierung durch das Flag verhindert und Pakete der Größe MTU werden gesendet. Wenn in diesem Moment jemand im Netzwerk feststellt, dass er weniger MTU hat, sagt er über ICMP: "Entschuldigung, das Paket ist verloren gegangen, weil eine Fragmentierung erforderlich ist" und gibt die Größe der MTU an. Wir werden diese Größe ändern und den Versand fortsetzen. Im schlimmsten Fall ist unser kleiner Overhead RTT / 2. Dies ist in TCP.
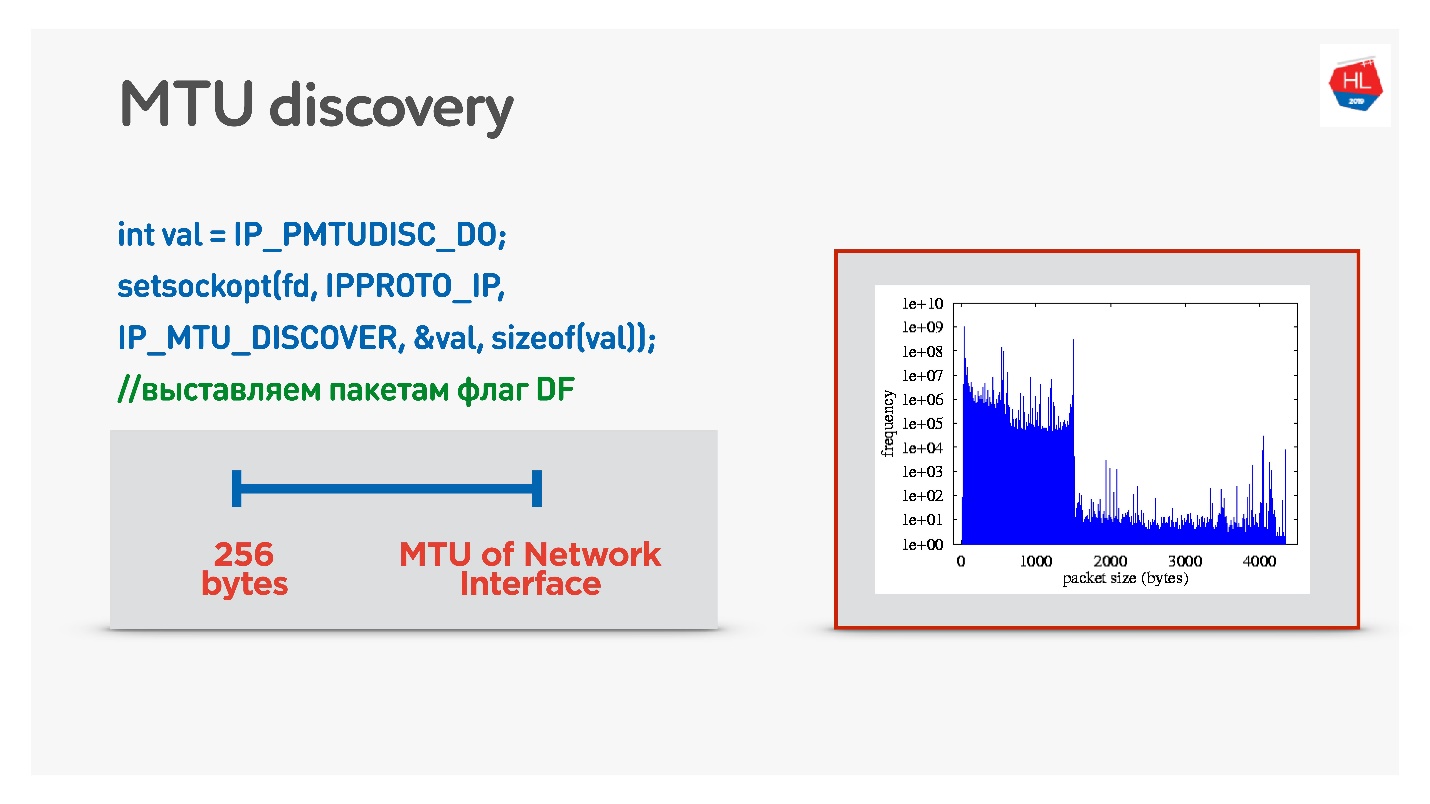
Wenn Sie sich in UDP nicht mit ICMP beschäftigen möchten, können Sie Folgendes tun: Fragmentierung beim Senden normaler Daten zulassen. Das heißt, fragmentierte Pakete senden - lassen Sie sie arbeiten. Parallel zum Auswählen eines Prozesses, der die Fragmentierung verhindert, wird bei einer binären Suche die optimale MTU ausgewählt, zu der wir dann gehen. Dies ist nicht ganz effektiv, da sich die MTU zunächst aufzuwärmen scheint.
Eine schwierigere Option besteht darin, die Verteilung der MTU auf mobile Clients zu untersuchen.

Von allen Kunden haben wir Pakete unterschiedlicher Größe mit dem Verbot der Fragmentierung gesendet. Das heißt, wenn das Paket nicht erreicht wird, fällt es ab und die kleinste MTU sollte 100% erreichen. Da es jedoch einen kleinen Paketverlust gibt, gibt es zwei Folien in der Tabelle:
- 1350 Bytes - statt 98% erhalten wir sofort 95% Lieferung.
- 1500 Bytes - MTU, nach der bereits 80% der Clients solche Pakete nicht empfangen.
In der Tat können wir das sagen: Wir vernachlässigen 1-2% unserer Kunden, lassen sie von fragmentierten Paketen leben. Aber wir werden sofort von dem ausgehen, was wir brauchen - das ist ab 1350.
Fehlerkorrektur (SACK, NACK, FEC)
Wenn Sie Ihr Protokoll erstellen, müssen Sie die Fehler korrigieren. Wenn das Paket fehlt (dies ist normal für drahtlose Netzwerke), muss es wiederhergestellt werden.
Im einfachsten Fall (weitere Details
hier ) gibt es ein Relais über Retransmit Time Out (RTO). Wenn das Paket fehlt, warten Sie auf die Zeit für die erneute Übertragung und senden Sie es erneut.
Der nächste Algorithmus ist
Fast Retransmit . Dies sind alles TCP-Algorithmen, die jedoch problemlos auf UDP portiert werden können.
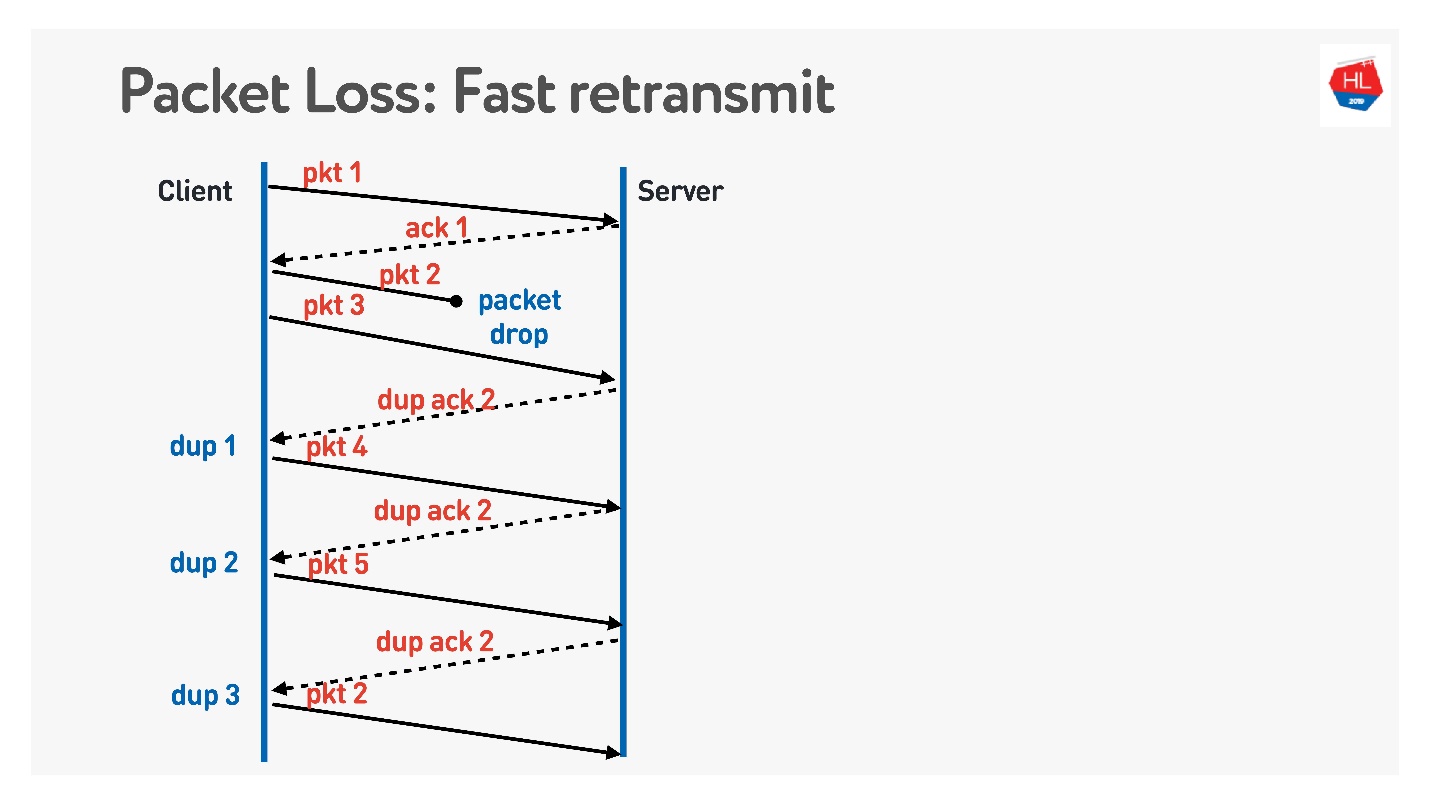
Wenn das Paket weg ist, senden wir weiter - es werden andere Pakete übertragen. Zu diesem Zeitpunkt gibt der Server an, dass er das nächste Paket empfangen hat, aber es gab kein vorheriges. Dazu macht er eine knifflige Bestätigung, die der Paketnummer + 1 entspricht, und setzt das Flag für die doppelte Bestätigung. Er sendet diese Dup Ack so, und am dritten verstehen wir normalerweise, dass das Paket verschwunden ist und senden es erneut.
Was Sie sonst noch edel machen möchten, was nicht in TCP enthalten ist und was sie in UDP tun möchten, ist die
Vorwärtsfehlerkorrektur .

Es scheint, dass wir, wenn wir wissen, dass Pakete verloren gehen können, eine Reihe von Paketen nehmen, ein XOR-Paket hinzufügen und das Problem ohne zusätzliche Neuübertragungen sofort auf dem Client beim Empfang von Daten beheben können. Es gibt jedoch ein Problem, wenn mehrere Pakete verschwinden. Es scheint, dass es durch Paritätsschutz, Reed-Solomon usw. gelöst werden kann.
Wir haben es so versucht, es stellte sich heraus, dass die Pakete tatsächlich in Bündeln verschwinden.
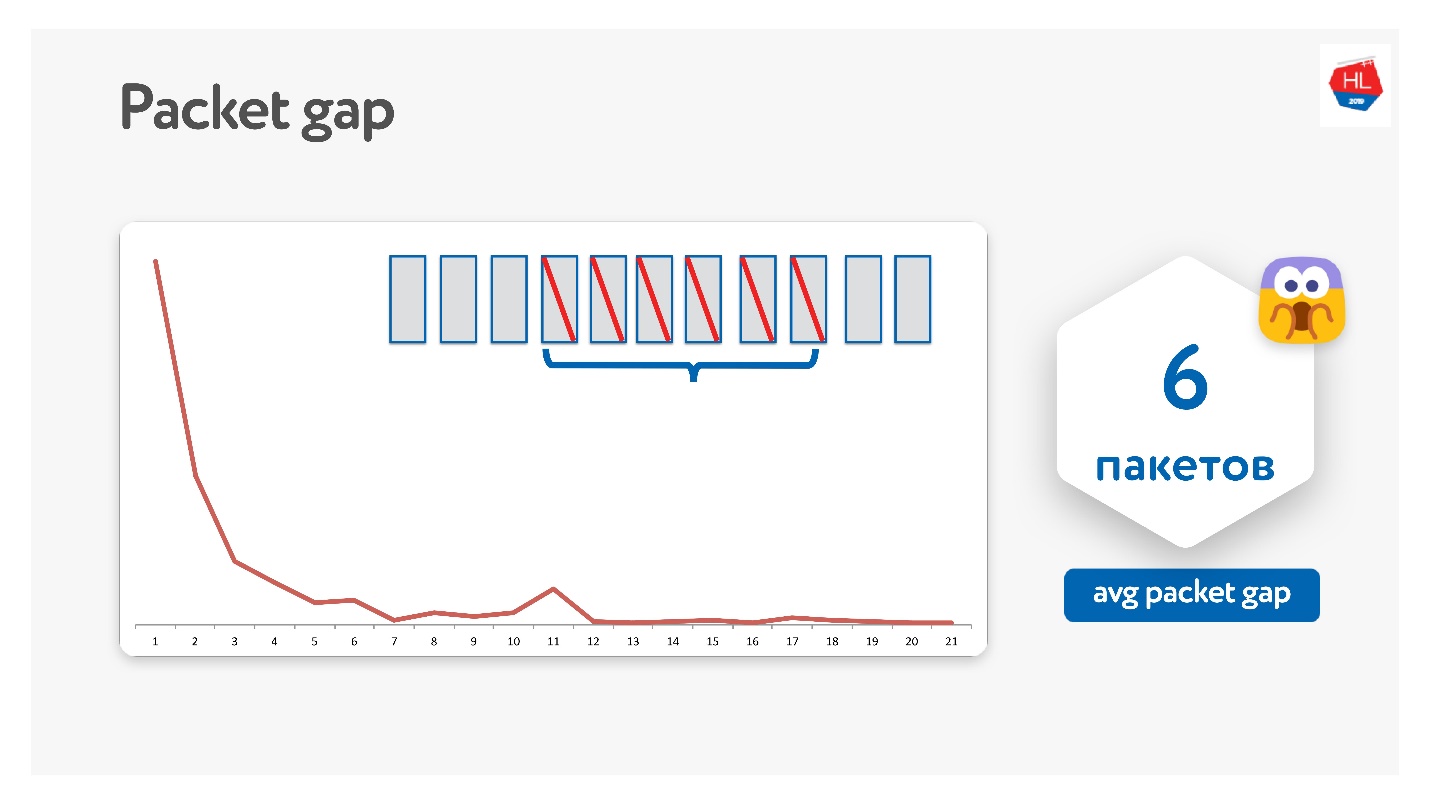
Die durchschnittliche Paketlücke betrug 6. Dies ist eine sehr unpraktische Paketlücke - Sie benötigen viele Fehlerkorrekturcodes. Gleichzeitig gibt es bei 11 eine Art Peak - ich weiß nicht warum, aber Pakete verschwinden manchmal in Paketen von 11. Aufgrund dieser Paketlücke funktioniert dies nicht.
Google hat das auch versucht, jeder träumt von FEC, aber bisher hat niemand gearbeitet.
Es gibt eine andere Option, wenn FEC helfen kann.

Zusätzlich zur erneuten Übertragung durch Retransmit Time Out, Fast Retransmit, gibt es auch eine
Schwanzverlustsonde . Dies ist so etwas, wenn Sie Daten senden und der Schwanz weg ist. Das heißt, Sie haben einen Teil der Daten gesendet und das fünfte Paket gesendet - es ist angekommen. Dann begannen Pakete zu verschwinden, zum Beispiel weil das Netzwerk ausgefallen war. Pakete verschwinden, verschwinden und Sie haben nur für das fünfte Paket eine Bestätigung erhalten.
Um zu verstehen, ob diese Daten erreicht sind, fragen Sie nach einer Weile, ob Sie mit dem TLP (Tail Loss Probe) beginnen, ob das Ende empfangen wurde. Tatsache ist, dass die Datenübertragung beendet wurde und Sie nichts senden, dann funktioniert Fast Retransmit nicht. Um dies zu beheben, führen Sie einen TLP durch.
Sie können TLPs FEC hinzufügen. Sie können alle nicht eingetroffenen Pakete anzeigen, die Parität darauf zählen und TLPs mit einem Paritätspaket senden.
Das ist alles cool, es scheint zu funktionieren. Aber es gibt so ein Problem.
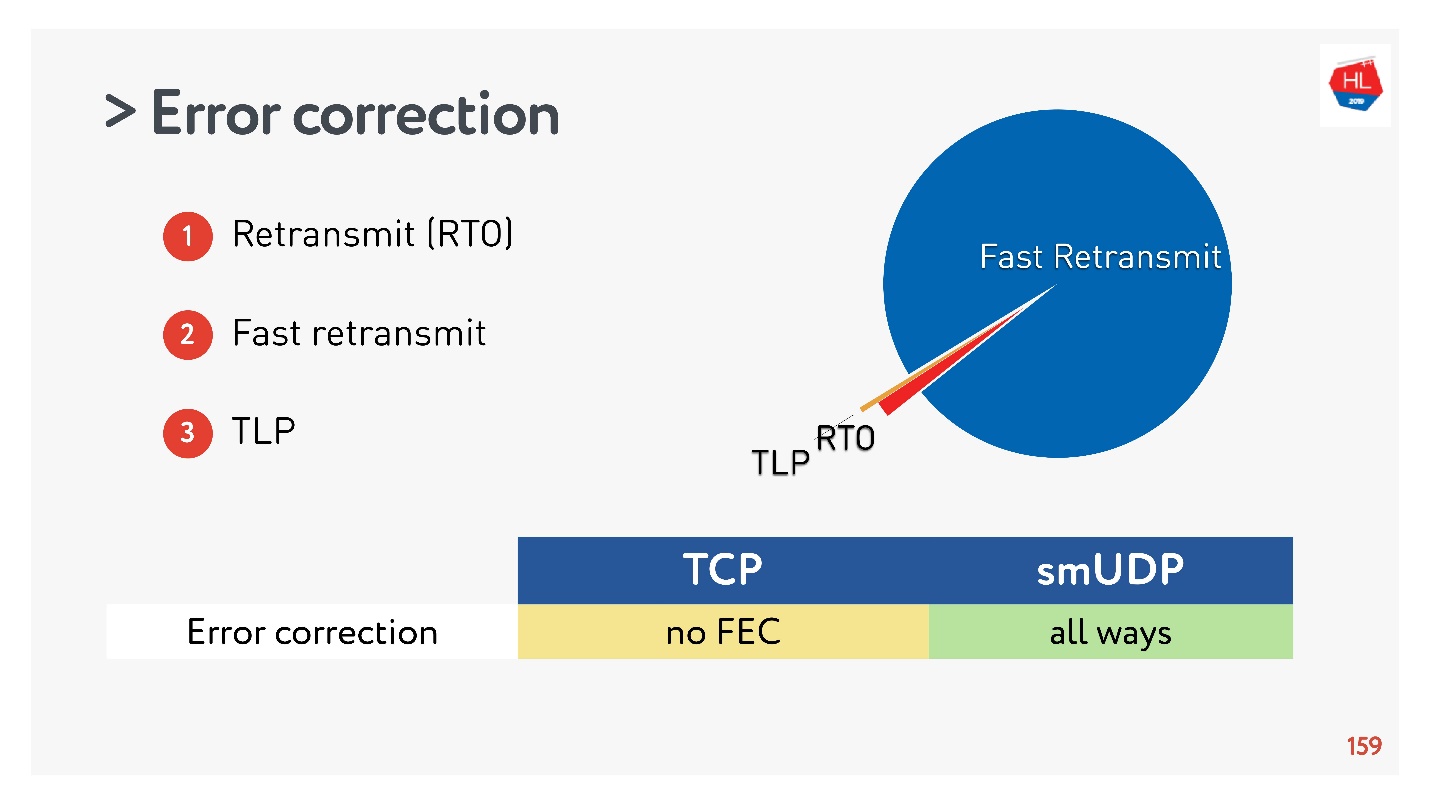
Wir haben Statistiken gesammelt und es stellte sich heraus, dass 98% der Fehler durch Fast Retransmit repariert werden. Der Rest wird über Retransmit Time Out und weniger als 1% über TLP repariert. Wenn Sie etwas anderes FEC reparieren, beträgt es weniger als 0,5%.
TCP unterstützt FEC nicht. In UDP ist dies nicht schwierig, aber im allgemeinen Fall reichen Standard-TCP-Wiederherstellungsalgorithmen aus.
Leistung
Es wäre möglich, die Leistung durch einen Vergleich von TCP mit UDP nicht zu beeinträchtigen.
TCP ist ein sehr altes Protokoll mit vielen verschiedenen Optimierungen, z. B. LSO (Large Segment Offload) und Zerocopy. Jetzt ist für UDP alles nicht verfügbar. Daher beträgt die UDP-Leistung nur 20% im Vergleich zu TCP von denselben Servern. Es gibt jedoch bereits vorgefertigte Lösungen (
UDP GSO ,
Zerocopy ), mit denen Linux dies unterstützen kann.
Das Hauptproblem bei der Optimierung für Nullkopie und LSO besteht darin, dass die Stimulation verloren geht.

Time to Market oder was TCP getötet hat
Vor kurzem, als mobile drahtlose Netzwerke populär wurden, erschienen viele verschiedene TCP-Standards: TLP, TFO, neue Überlastungskontrolle, RACK, BBR und mehr.

Das Hauptproblem ist jedoch, dass viele von ihnen nicht implementiert werden, da TCP angeblich verknöchert ist. In vielen Fällen betrachten Betreiber TCP-Pakete und erwarten, dass sie sehen, was sie erwarten. Daher ist es sehr schwierig zu ändern.
Darüber hinaus werden mobile Clients lange Zeit aktualisiert, und wir können diese Updates nicht bereitstellen. Wenn Sie sich ansehen, welche neuesten Updates auf dem Client verfügbar sind und was sich auf dem Server befindet, können Sie sagen, dass auf dem Client fast nichts vorhanden ist.
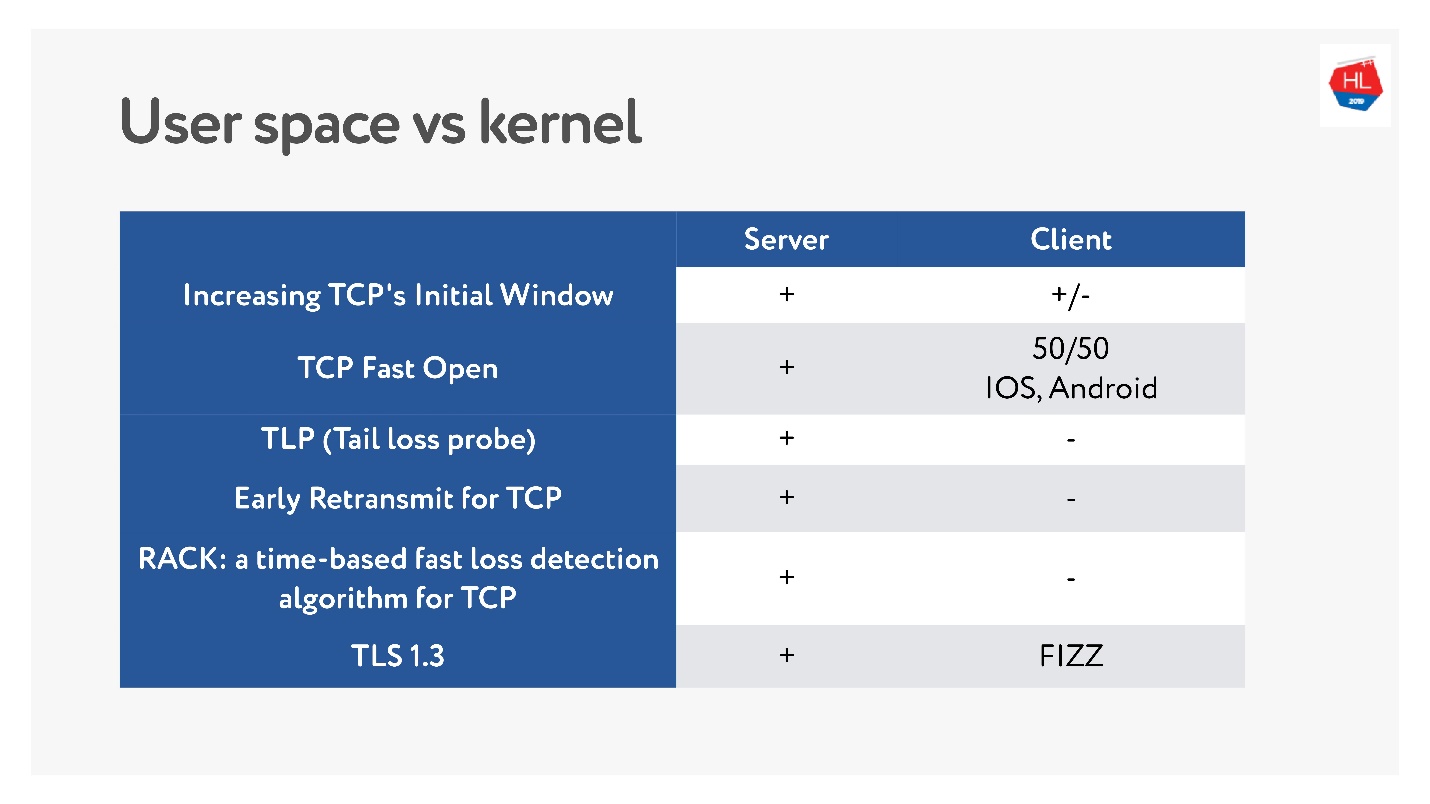
Daher scheint die Entscheidung, ein Protokoll im Benutzerbereich zu schreiben, zumindest solange Sie alle diese Funktionen sammeln, nicht so schlecht zu sein.

Mit TCP rollen Funktionen seit Jahren. Für Ihr UDP-Protokoll können Sie die Version buchstäblich in einem Update von Client und Server aktualisieren. Sie müssen jedoch eine Versionsverhandlung hinzufügen.
TCP gegen selbst erstelltes UDP. Endkämpfe
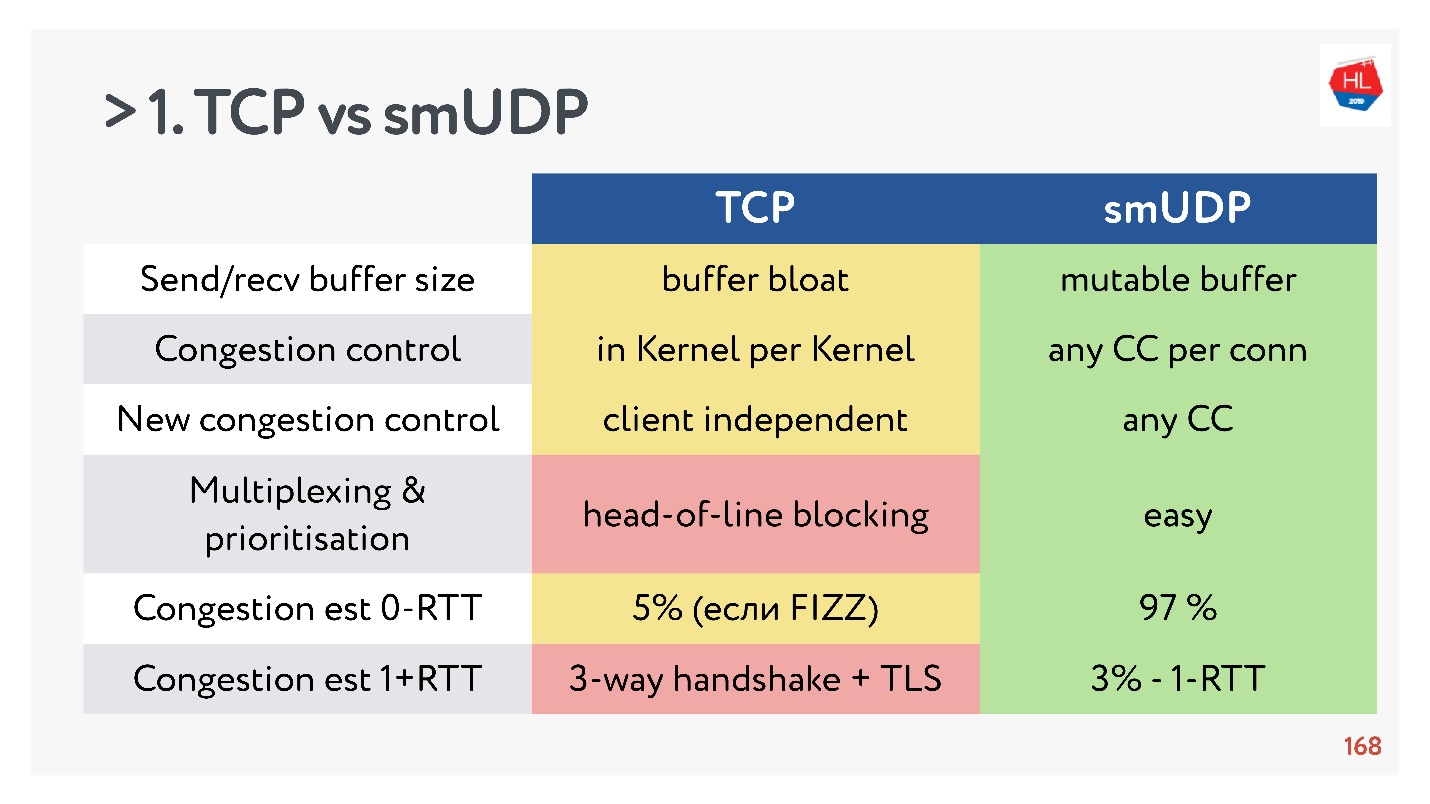
- Sende- / Empfangspuffer: Der veränderbare Puffer kann für Ihr Protokoll erstellt werden. Es treten Probleme mit dem Aufblähen des Puffers mit TCP auf.
- Überlastungskontrolle können Sie vorhandene verwenden. Bei UDP sind sie alle.
- Das neue Überlastungssteuerelement lässt sich nur schwer zu TCP hinzufügen, da Sie die Bestätigung ändern müssen. Dies ist auf dem Client nicht möglich.
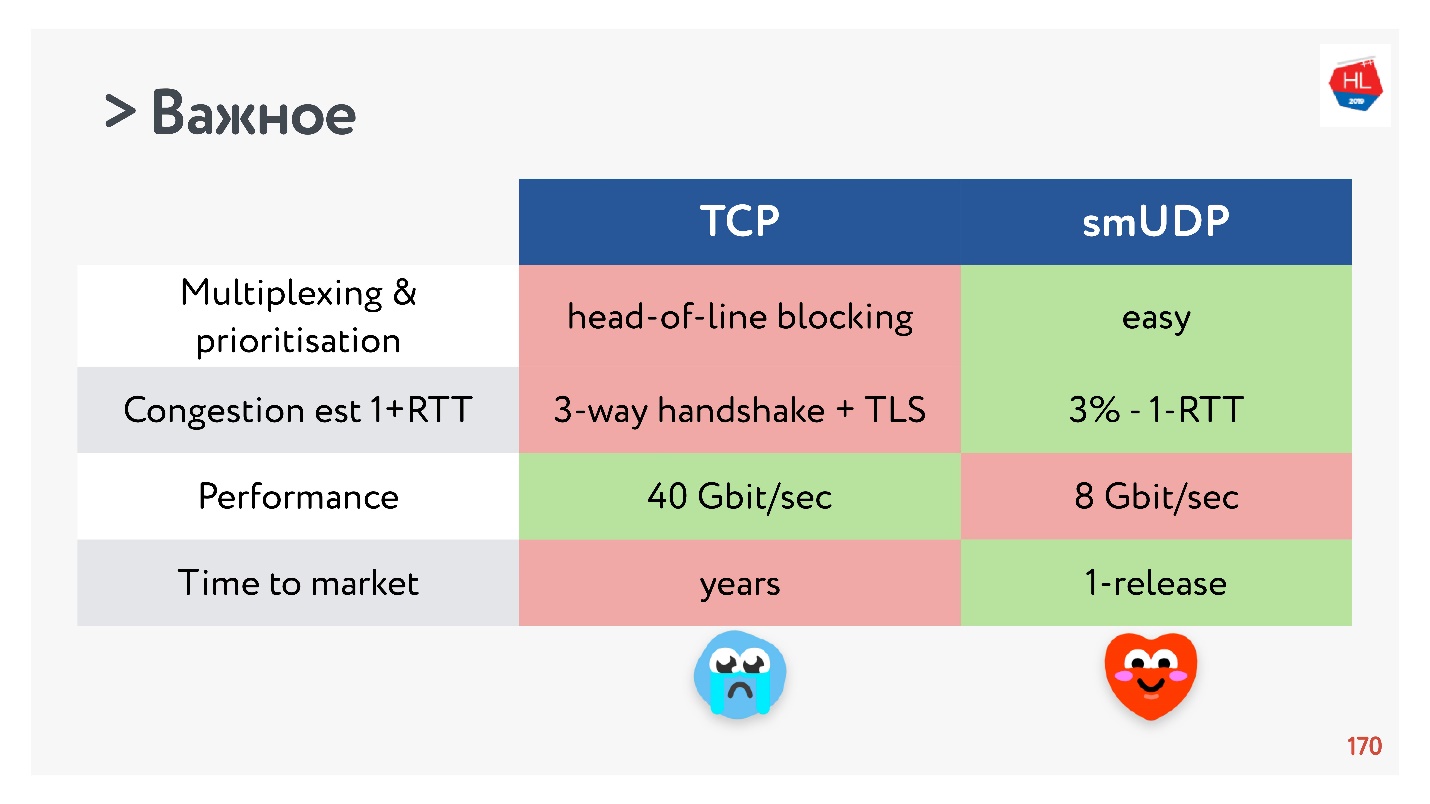
- Multiplexing ist ein kritisches Thema. Head-of-Line-Blockierung tritt auf. Wenn Sie ein Paket verlieren, können Sie nicht zu TCP multiplexen. Daher sollte HTTP2.0 über TCP keinen ernsthaften Anstieg bewirken.
- Fälle, in denen Sie einen Verbindungsaufbau für 0-RTT in TCP erhalten können, sind äußerst selten, in der Größenordnung von 5% und in der Größenordnung von 97% für selbst erstelltes UDP.

- Die IP-Migration ist keine so wichtige Funktion, wird jedoch bei komplexen Abonnements und beim Speichern des Status auf dem Server unbedingt benötigt, ist jedoch nicht in TCP implementiert.
- Nat Unbindung ist nicht für UDP. In diesem Fall muss UDP häufig Ping-Pong-Pakete ausführen.
- Die Paketstimulation in UDP ist einfach, während es keine Optimierung gibt. In TCP funktioniert diese Option nicht.
- MTU und Fehlerkorrektur sind beide vergleichbar.
- Die Geschwindigkeit von TCP ist jetzt natürlich schneller als die von UDP, wenn Sie eine Menge Verkehr verteilen. Einige Optimierungen dauern jedoch sehr lange.
Wenn Sie das Wichtigste sammeln, hat UDP wahrscheinlich mehr Vor- als Nachteile.
 Wählen Sie UDP!
Wählen Sie UDP!Testen von selbst erstelltem UDP an Benutzern
Wir haben einen Prüfstand zusammengestellt.
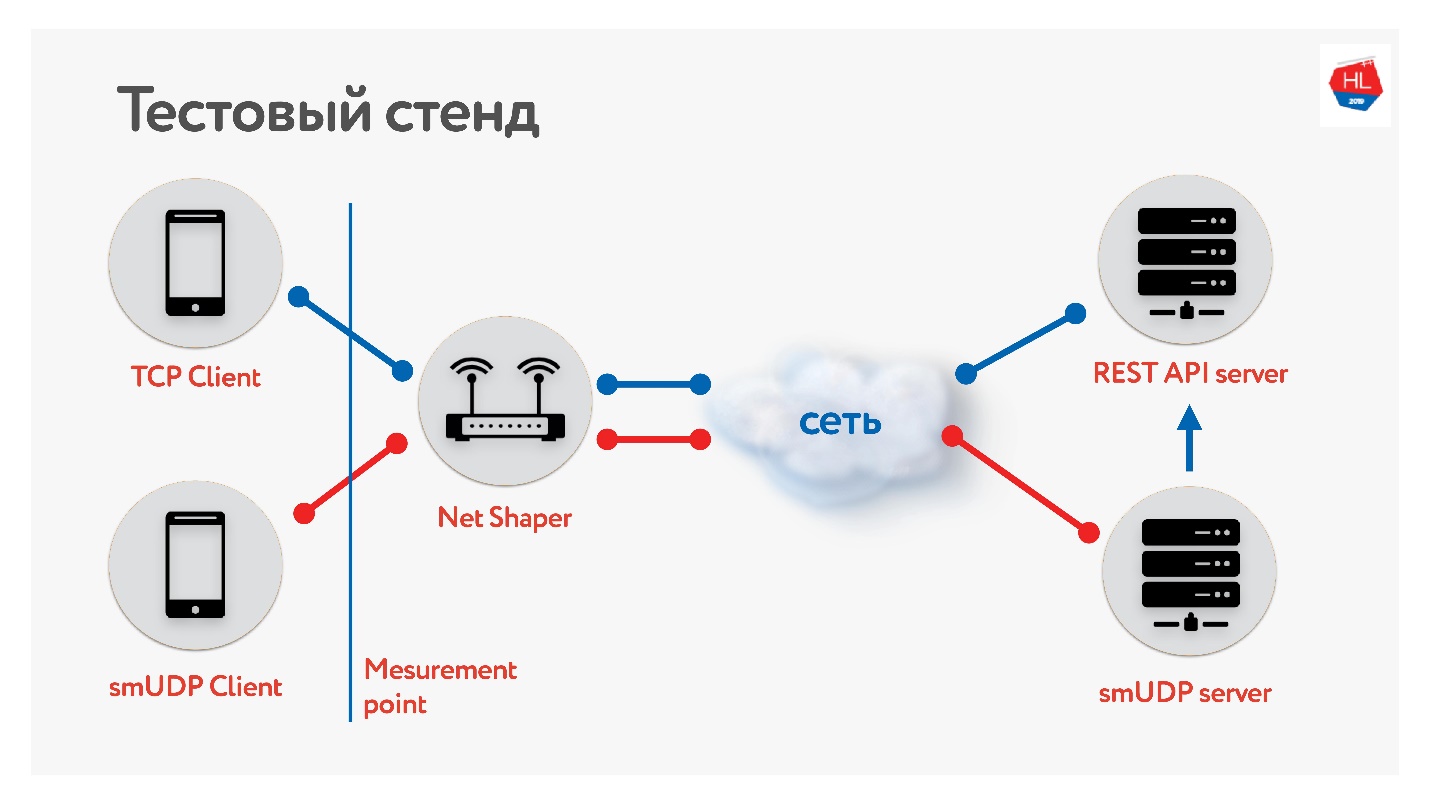
Es gibt einen Client für TCP und UDP. Wir haben den Datenverkehr über Net Shaper normalisiert, an das Internet und an den Server gesendet. Ein REST-API-Service, der zweite mit UDP. Und UDP verwendet dieselbe REST-API im selben Rechenzentrum, um die Daten zu überprüfen. Wir haben verschiedene Profile unserer mobilen Kunden gesammelt und
den Test gestartet .

Bei der Messung des Durchschnitts über das Portal haben wir festgestellt, dass wir die Zeit für den Aufruf der API um 10% und für Bilder um 7% reduzieren konnten. Die Nutzeraktivität wuchs nur um 1%, aber wir geben nicht auf, wir denken, es wird besser.

In Bezug auf die Auslastung haben wir jetzt ungefähr 10 Millionen Benutzer in unserem selbst erstellten UDP, Datenverkehr mit bis zu 80 Gbit / s, 6 Millionen Pakete pro Sekunde und 20 Server, die dies alles bedienen.
UDP-Checkliste
Wenn Sie Ihr Protokoll schreiben möchten, benötigen Sie eine Checkliste:
- Tempo
- MTU-Entdeckung.
- Fehlerbehebungen erforderlich .
- Flusskontrolle und Überlastungskontrolle.
- Optional können Sie die IP-Migration unterstützen. TLP ist einfach.
Denken Sie daran, dass die Kanäle asymmetrisch sind. Während Sie Daten vom Server empfangen, ist Ihr Upload möglicherweise inaktiv. Versuchen Sie es.
QUIC
Es wäre unehrlich zu sagen, dass Google dies nicht getan hat.

Es gibt ein QUIC-Protokoll, das Google unter HTTP 2.0 implementiert hat und das fast dasselbe unterstützt.
Warum QUIC nicht so schnell ist
Als QUIC herauskam, gab es viel Hass gegen die Tatsache, dass Google sagt, dass alles schneller funktioniert, und "ich habe es zu Hause auf einem Computer gemessen - es funktioniert langsamer."

Dieser
Artikel enthält eine Reihe von Bildern und Maßen.
Nun, es stellt sich heraus, dass wir das alles umsonst getan haben, haben die Leute für uns gemessen? Selbst mit Codebeispielen gibt es echte Hausmessungen.

Tatsächlich wird es keine Verbesserung geben, bis Sie Anforderungen parallelisieren, in realen Netzwerken arbeiten und bis Paketverluste in Überlastungsverlust und Zufallsverlust unterteilt sind. Wir brauchen eine echte Emulation eines echten Netzwerks.
Aber es gibt eine positive, sagen sie, QUIC ist weder besser noch schlechter. Somit funktioniert QUIC in perfekten Netzwerken gut.
Die Zukunft
Google hat kürzlich HTTP 2.0 über QUIC HTTP 3 benannt, nicht zu verwechseln, da HTTP 2.0 über TCP und über QUIC stehen könnte. Jetzt ist es HTTP 3.
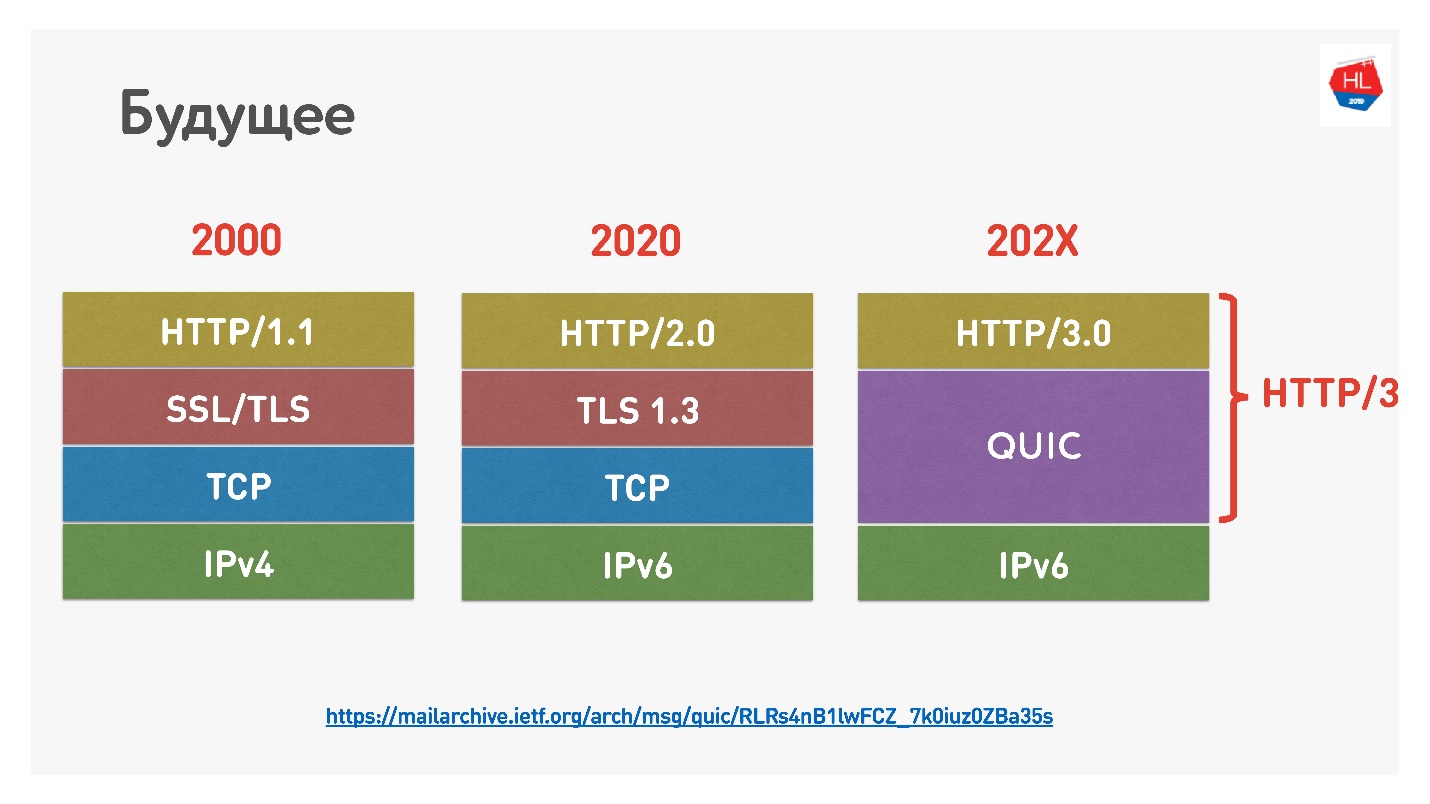
Es gab auch
Google QUIC - dies ist QUIC, das in Chrome implementiert ist, und iQUIC - ein standardisiertes QUIC. Das standardisierte QUIC wurde nirgendwo implementiert, die Standard-iQUIC-Server haben kein Handshake mit Google QUIC durchgeführt. Jetzt versprechen sie, dieses Problem zu lösen, und bald wird es verfügbar sein.
QUIC ist überall
Wenn Sie immer noch nicht glauben, dass TCP tot ist, sage ich Ihnen, dass Sie QUIC und UDP (
Prooflink ) verwenden, wenn Sie Chrome, Android und bald auch iOS verwenden und zu Google, Youtube usw. gehen.
QUIC ist jetzt :
- 1,9% aller Websites;
- 12% des gesamten Verkehrs;
- 30% des Videoverkehrs in Mobilfunknetzen.
Wie können Sie überprüfen, ob Sie QUIC verwenden, wenn Sie nicht glauben? In Chrome Wireshark öffnen. Ich habe nach iQUIC gesucht, ich habe es nirgendwo gefunden, aber GQUIC passiert.
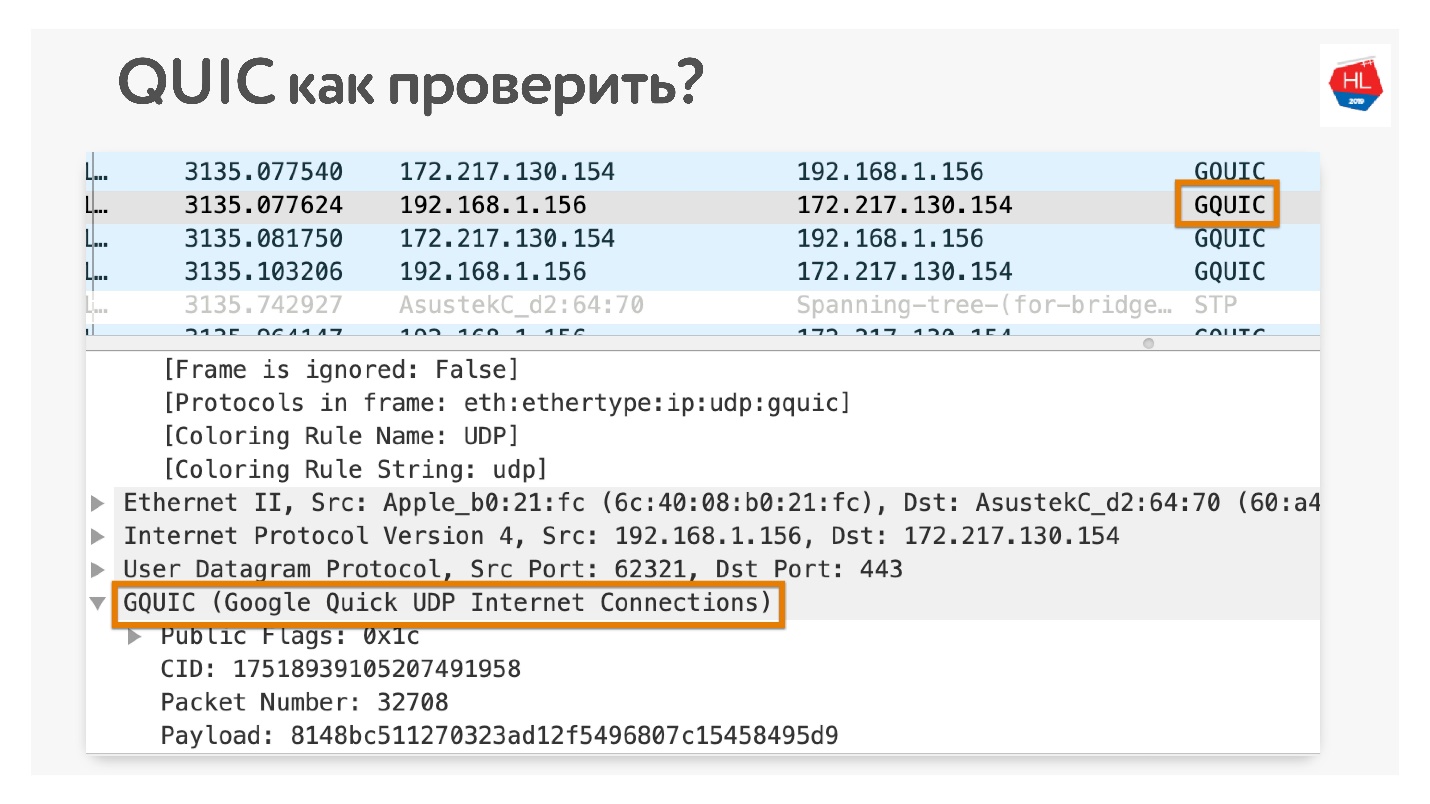
Sie können auch in Ihrem Browser online gehen und sehen, was GQUIC dort ist.

Noch etwas Zukunft
Multipath wartet bald auf uns.
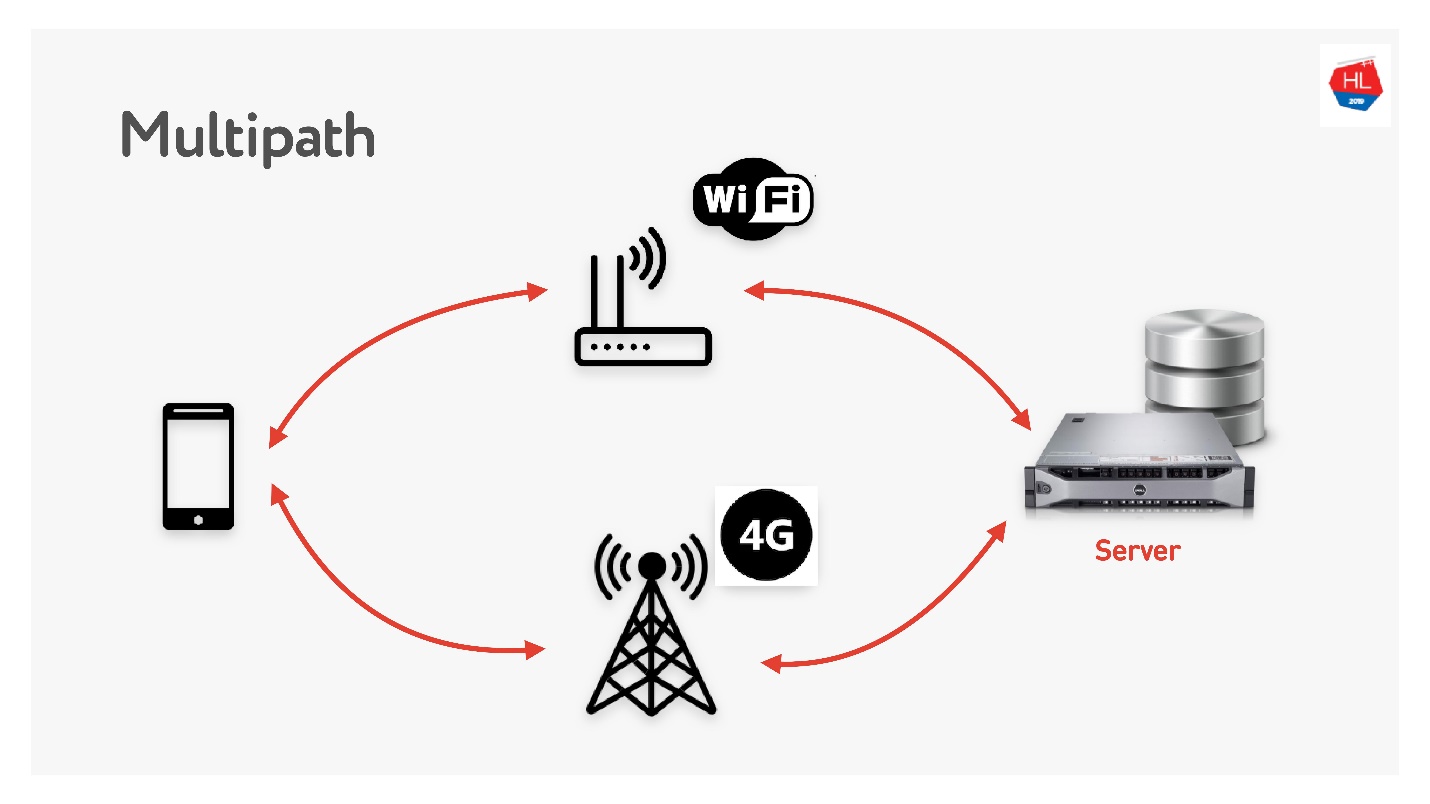
Wenn Sie einen mobilen Client haben, der sowohl über WLAN als auch über 3G verfügt, können Sie beide Kanäle verwenden. Multipath TCP befindet sich derzeit in der Entwicklung und wird in Kürze im Linux-Kernel verfügbar sein. Offensichtlich wird es Kunden nicht bald erreichen, ich denke, es kann auf UDP viel schneller gemacht werden.
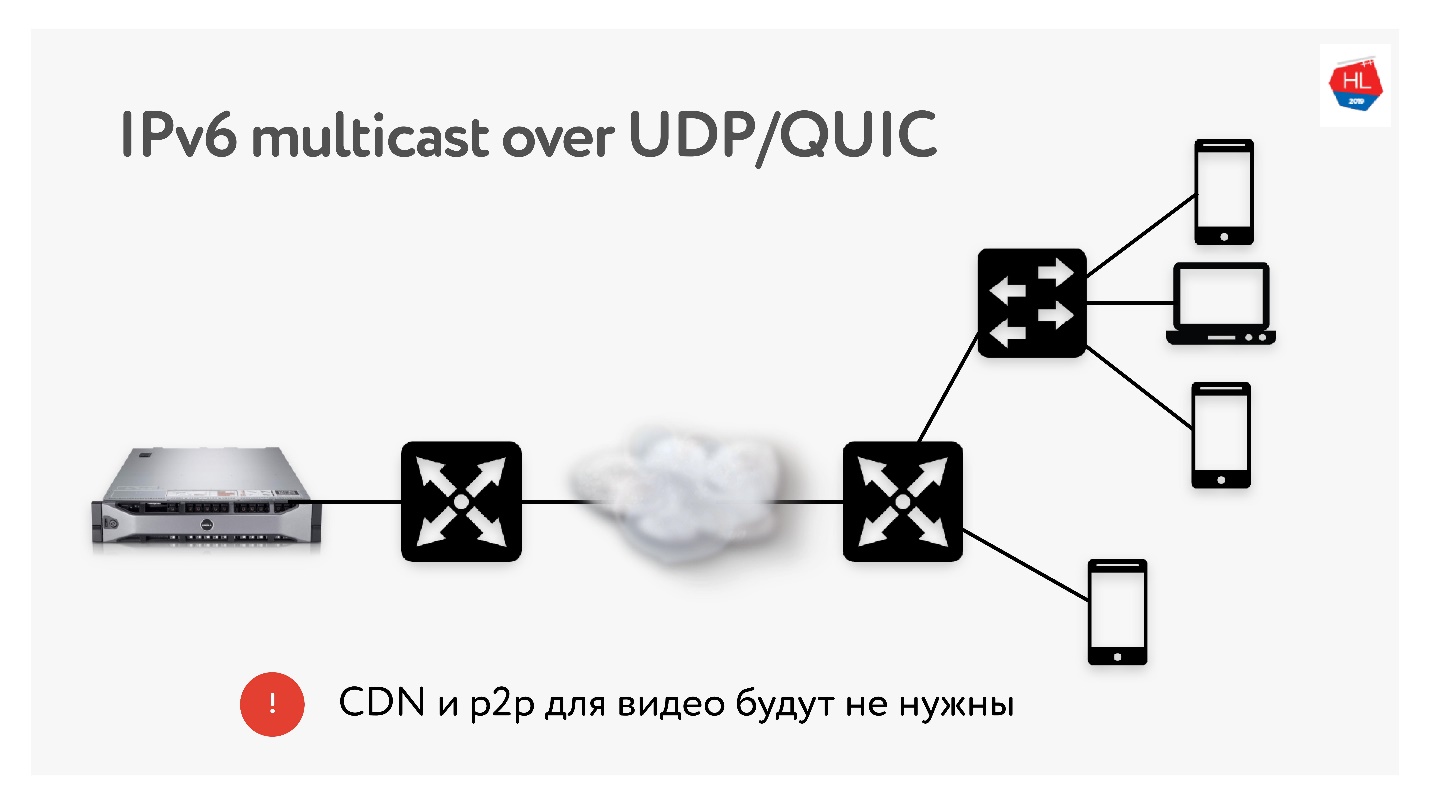
Da wir viele Übersetzungen mit jeweils 3 TB durchführen, verwenden wir sehr häufig Technologien wie CDN- und P2P-Distribution, wenn derselbe Inhalt vielen Benutzern auf der ganzen Welt bereitgestellt werden muss.
In IPv6 gibt es Multicast mit UDP, mit dem Pakete an mehrere abonnierte Benutzer gleichzeitig gesendet werden können. Daher denke ich, dass CDN- und P2P-Technologien in naher Zukunft nicht benötigt werden, wenn wir alle Inhalte mithilfe von Multicast an IPv6 liefern.
Schlussfolgerungen
Ich hoffe du verstehst:
- Wie das Netzwerk wirklich funktioniert und dass TCP über UDP wiederholt und besser gemacht werden kann.
- Das TCP ist nicht so schlecht, wenn Sie es richtig konfigurieren, aber es hat wirklich aufgegeben und entwickelt sich fast nicht mehr.
- Vertrauen Sie keinen UDP-Hassern, die sagen, dass sie nicht im Benutzerbereich arbeiten. All diese Probleme können gelöst werden. Probieren Sie es aus - dies ist die nahe Zukunft.
- Wenn Sie es nicht glauben, können und sollten Sie das Netzwerk mit Ihren Händen berühren. Ich habe gezeigt, wie fast alles überprüft werden kann.
Sie haben alles gelesen und herausgefunden, was als nächstes kommt?
- Konfigurieren Sie das Protokoll (TCP, UDP - es spielt keine Rolle) für die Situation (Netzwerkprofil + Lastprofil).
- Verwenden Sie die TCP-Rezepte, die ich Ihnen gesagt habe: TFO, Sende- / Empfangspuffer, TLS1.3, CC ...
- Erstellen Sie Ihre UDP-Protokolle, wenn Sie über die Ressourcen verfügen.
- Wenn Sie Ihr UDP durchgeführt haben, überprüfen Sie in der UDP-Checkliste, ob Sie alles getan haben, was Sie benötigen. Unsinn wie das Tempo zu vergessen, wird nicht funktionieren.
Wenn Sie nicht über die Ressourcen verfügen, bereiten Sie Ihre Infrastruktur für QUIC vor. Früher oder später wird er zu dir kommen.
Wir bestimmen die Zukunft. Wir entscheiden, welche Protokolle verwendet werden sollen. Wenn Sie QUIC verwenden möchten - verwenden Sie es, wenn Sie Ihr UDP möchten oder auf TCP bleiben - entscheiden Sie selbst über die Zukunft.
Nützliche Links
Bis zum 7. September können Sie weiterhin einen Antrag für Moscow HighLoad ++ stellen und mitteilen, wie Sie Ihre Dienste auf hohe Lasten vorbereiten. Das Programm wird jedoch bereits nach und nach gefüllt. Aus Odnoklassniki-Berichten gingen Berichte über die neue Architektur des Freundesdiagramms, über die Optimierung des Geschenkservices für hohe Lasten und darüber ein, was zu tun ist, wenn Sie alles optimiert haben und die Daten den Benutzer nicht schnell genug erreichen.