
Vor zwei Jahren sagte Sundar Pichai, der Leiter von Google, dass das Unternehmen von Mobile-First zu AI-First wird und sich auf maschinelles Lernen konzentriert. Ein Jahr später wurde das Machine Learning Kit veröffentlicht - eine Reihe von Tools, mit denen Sie ML unter iOS und Android effektiv nutzen können.
In den USA wird viel über das ML-Kit gesprochen, aber auf Russisch gibt es fast keine Informationen. Und da wir es für einige Aufgaben in Yandex.Money verwenden, habe ich beschlossen, meine Erfahrungen zu teilen und anhand von Beispielen zu zeigen, wie man es verwendet, um interessante Dinge zu tun.
Mein Name ist Yura. Letztes Jahr habe ich im Yandex.Money-Team an einer mobilen Geldbörse gearbeitet. Wir werden über maschinelles Lernen in Mobilgeräten sprechen.
Hinweis Redaktion: Dieser Beitrag ist eine Nacherzählung des Berichts von Yuri Chechetkin „Vom Handy zuerst zur KI zuerst“ aus der Yandex.Money-Metapher Android Paranoid .
Was ist das ML Kit?
Dies ist das mobile SDK von Google, mit dem maschinelles Lernen auf Android- und iOS-Geräten problemlos verwendet werden kann. Es ist nicht notwendig, ein Experte für ML oder künstliche Intelligenz zu sein, da Sie in wenigen Codezeilen sehr komplexe Dinge implementieren können. Darüber hinaus ist es nicht erforderlich zu wissen, wie neuronale Netze oder Modelloptimierungen funktionieren.
Was kann das ML Kit?
Die Grundfunktionen sind recht breit. Sie können beispielsweise Text und Gesichter erkennen, Objekte suchen und verfolgen, Beschriftungen für Bilder und Ihre eigenen Klassifizierungsmodelle erstellen, Barcodes und QR-Tags scannen.
Wir haben die QR-Code-Erkennung bereits in der Yandex.Money-Anwendung verwendet.
Es gibt auch ein ML-Kit
- Wahrzeichenerkennung;
- Definition der Sprache, in der der Text geschrieben ist;
- Übersetzung von Texten auf dem Gerät;
- Schnelle Antwort auf einen Brief oder eine Nachricht.
Neben einer Vielzahl von Methoden, die sofort einsatzbereit sind, werden benutzerdefinierte Modelle unterstützt, die praktisch endlose Möglichkeiten bieten. Sie können beispielsweise Schwarzweißfotos einfärben und farbig machen.
Es ist wichtig, dass Sie hierfür keine Dienste, APIs oder Backends verwenden müssen. Alles kann direkt auf dem Gerät ausgeführt werden, sodass wir keinen Benutzerverkehr laden, keine Fehler im Zusammenhang mit dem Netzwerk erhalten und keine Fälle bearbeiten müssen, z. B. mangelndes Internet, Verbindungsverlust usw. Darüber hinaus arbeitet es auf dem Gerät viel schneller als über ein Netzwerk.

Texterkennung
Aufgabe: Bei einem Foto muss der Text in einem Rechteck eingekreist sein.
Wir beginnen mit der Abhängigkeit in Gradle. Es reicht aus, eine Abhängigkeit zu verbinden, und wir sind bereit zu arbeiten.
dependencies {
Es lohnt sich, Metadaten anzugeben, die besagen, dass das Modell beim Herunterladen der Anwendung vom Play Market auf das Gerät heruntergeladen wird. Wenn Sie dies nicht tun und ohne Modell auf die API zugreifen, wird eine Fehlermeldung angezeigt, und das Modell muss im Hintergrund heruntergeladen werden. Wenn Sie mehrere Modelle verwenden müssen, ist es ratsam, diese durch Kommas getrennt anzugeben. In unserem Beispiel verwenden wir das OCR-Modell, und der Name des Restes finden Sie in der Dokumentation .
<application ...> ... <meta-data android:name="com.google.firebase.ml.vision.DEPENDENCIES" android:value="ocr" /> <!-- To use multiple models: android:value="ocr,model2,model3" --> </application>
Nach der Projektkonfiguration müssen Sie die Eingabewerte festlegen. ML Kit funktioniert mit dem FirebaseVisionImage-Typ. Wir haben fünf Methoden, deren Signatur ich unten geschrieben habe. Sie konvertieren die üblichen Android- und Java-Typen in ML Kit-Typen, mit denen bequem gearbeitet werden kann.
fun fromMediaImage(image: Image, rotation: Int): FirebaseVisionImage fun fromBitmap(bitmap: Bitmap): FirebaseVisionImage fun fromFilePath(context: Context, uri: Uri): FirebaseVisionImage fun fromByteBuffer( byteBuffer: ByteBuffer, metadata: FirebaseVisionImageMetadata ): FirebaseVisionImage fun fromByteArray( bytes: ByteArray, metadata: FirebaseVisionImageMetadata ): FirebaseVisionImage
Achten Sie auf die letzten beiden - sie arbeiten mit einem Array von Bytes und einem Bytepuffer, und wir müssen Metadaten angeben, damit ML Kit versteht, wie man mit all dem umgeht. Metadaten beschreiben tatsächlich das Format, in diesem Fall die Breite und Höhe, das Standardformat, IMAGE_FORMAT_NV21 und die Drehung.
val metadata = FirebaseVisionImageMetadata.Builder() .setWidth(480) .setHeight(360) .setFormat(FirebaseVisionImageMetadata.IMAGE_FORMAT_NV21) .setRotation(rotation) .build() val image = FirebaseVisionImage.fromByteBuffer(buffer, metadata)
Wenn die Eingabedaten erfasst werden, erstellen Sie einen Detektor, der den Text erkennt.
Es gibt zwei Arten von Detektoren: Auf dem Gerät und in der Cloud werden sie buchstäblich in einer Zeile erstellt. Es ist erwähnenswert, dass der Detektor am Gerät nur mit Englisch funktioniert. Der Cloud-Detektor unterstützt mehr als 20 Sprachen, die in der speziellen setLanguageHints-Methode angegeben werden müssen.
Die Anzahl der unterstützten Sprachen beträgt mehr als 20, sie befinden sich alle auf der offiziellen Website. In unserem Beispiel nur Englisch und Russisch.
Nachdem Sie eine Eingabe und einen Detektor eingegeben haben, rufen Sie einfach die processImage-Methode für diesen Detektor auf. Wir erhalten das Ergebnis in Form einer Aufgabe, an die wir zwei Rückrufe hängen - für Erfolg und für Fehler. Bei der Standardausnahme tritt ein Fehler auf, und der FirebaseVisionText-Typ wird von onSuccessListener erfolgreich ausgeführt.
val result: Task<FirebaseVisionText> = detector.processImage(image) .addOnSuccessListener { result: FirebaseVisionText ->
Wie arbeite ich mit dem Typ FirebaseVisionText?
Es besteht aus Textblöcken (TextBlock), die wiederum aus Linien (Linie) und Linien von Elementen (Element) bestehen. Sie sind ineinander verschachtelt.
Darüber hinaus verfügt jede dieser Klassen über fünf Methoden, die unterschiedliche Daten zum Objekt zurückgeben. Ein Rechteck ist der Bereich, in dem sich der Text befindet. Vertrauen ist die Genauigkeit des erkannten Textes. Eckpunkte sind die Eckpunkte im Uhrzeigersinn, beginnend mit der oberen linken Ecke, den erkannten Sprachen und dem Text selbst.
FirebaseVisionText contains a list of FirebaseVisionText.TextBlock which contains a list of FirebaseVisionText.Line which is composed of a list of FirebaseVisionText.Element. fun getBoundingBox(): Rect
Wofür ist das?
Wir können sowohl den gesamten Text im Bild als auch die einzelnen Absätze, Teile, Zeilen oder nur Wörter erkennen. Als Beispiel können wir wiederholen, in jeder Phase einen Text nehmen, die Ränder dieses Textes nehmen und zeichnen. Sehr bequem.
Wir planen, dieses Tool in unserer Anwendung zum Erkennen von Bankkarten zu verwenden, deren Etiketten nicht dem Standard entsprechen. Nicht alle Kartenerkennungsbibliotheken funktionieren gut, und für benutzerdefinierte Karten wäre das ML-Kit sehr nützlich. Da wenig Text vorhanden ist, ist die Verarbeitung auf diese Weise sehr einfach.
Erkennung von Objekten auf dem Foto
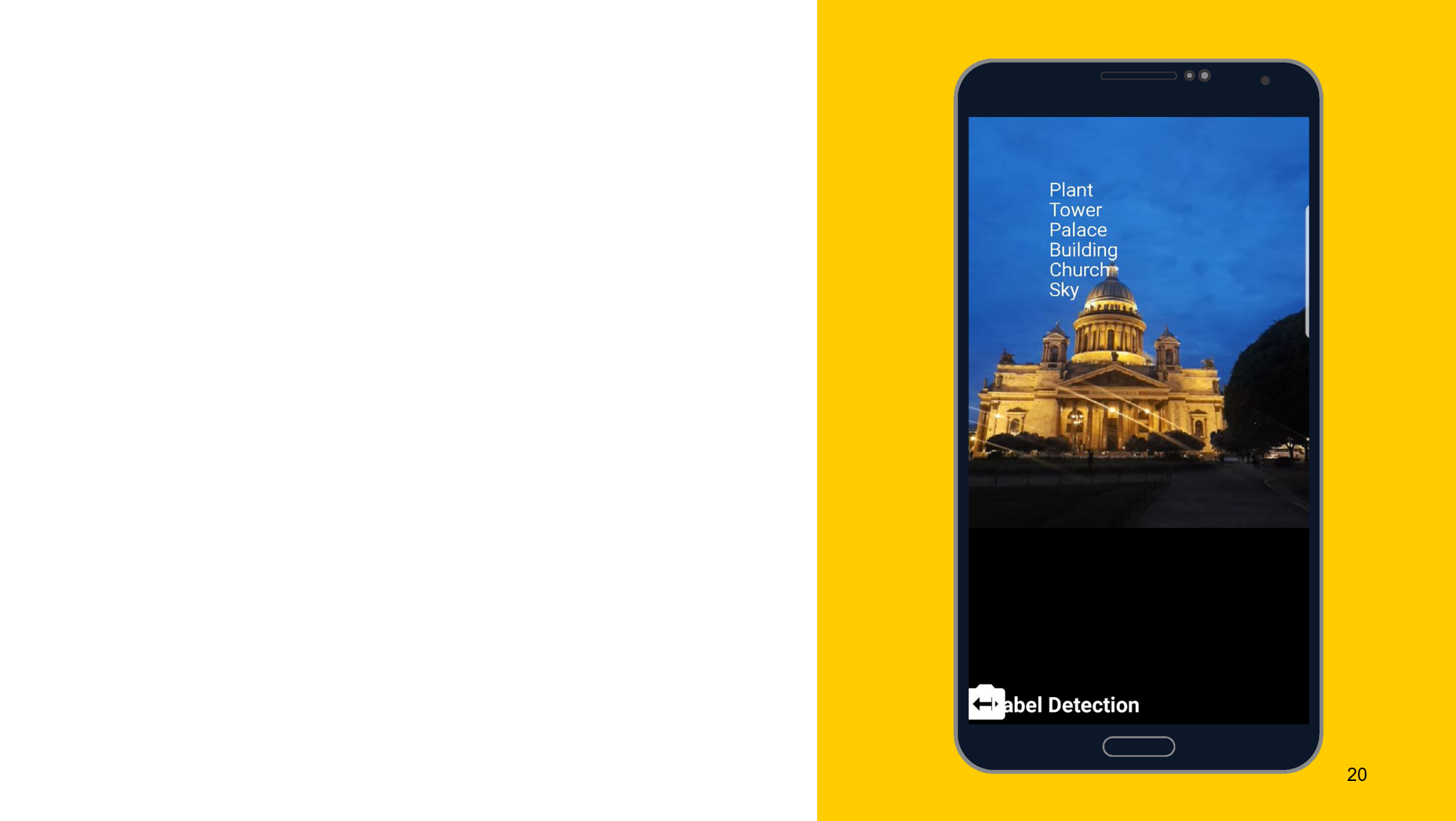
Am Beispiel des folgenden Tools möchte ich zeigen, dass das Funktionsprinzip ungefähr gleich ist. In diesem Fall Erkennung dessen, was auf dem Objekt dargestellt ist. Wir erstellen auch zwei Detektoren, einen auf dem Gerät, den anderen in der Cloud. Wir können die Mindestgenauigkeit als Parameter angeben. Der Standardwert ist 0,5, angegeben 0,7 und einsatzbereit. Wir erhalten das Ergebnis auch in Form von FirebaseImageLabel. Dies ist eine Liste von Labels, von denen jedes eine ID, eine Beschreibung und eine Genauigkeit enthält.
Harold versteckt das Glück

Sie können versuchen zu verstehen, wie gut Harold den Schmerz verbirgt und ob er gleichzeitig glücklich ist. Wir verwenden ein Gesichtserkennungswerkzeug, das neben der Erkennung von Gesichtszügen auch erkennen kann, wie glücklich eine Person ist. Wie sich herausstellte, ist Harold zu 93% glücklich. Oder er versteckt den Schmerz sehr gut.

Von leicht zu leicht, aber etwas komplizierter. Kundenspezifische Modelle.
Aufgabe: Klassifizierung dessen, was auf dem Foto abgebildet ist.
Ich machte ein Foto vom Laptop und erkannte das Modem, den Desktop-Computer und die Tastatur. Klingt nach der Wahrheit. Es gibt tausend Klassifikatoren, von denen er drei nimmt, die dieses Foto am besten beschreiben.

Wenn Sie mit benutzerdefinierten Modellen arbeiten, können wir auch mit ihnen sowohl auf dem Gerät als auch über die Cloud arbeiten.
Wenn wir über die Cloud arbeiten, müssen Sie zur Firebase-Konsole, zur Registerkarte ML Kit und zum benutzerdefinierten Tippen gehen, wo wir unser Modell auf TensorFlow Lite hochladen können, da ML Kit mit Modellen mit dieser Auflösung funktioniert. Wenn wir es auf einem Gerät verwenden, können wir das Modell einfach als Asset in einen beliebigen Teil des Projekts einfügen.
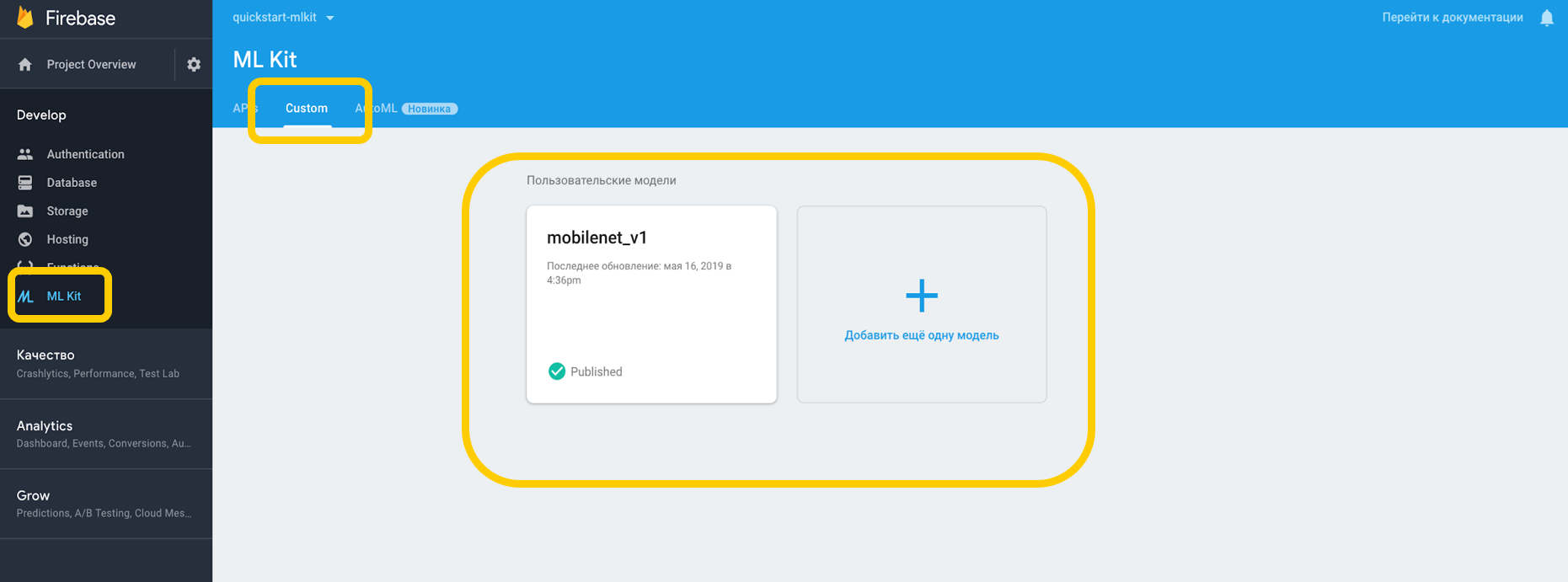
Wir weisen auf die Abhängigkeit vom Dolmetscher hin, der mit benutzerdefinierten Modellen arbeiten kann, und vergessen nicht die Erlaubnis, mit dem Internet zu arbeiten.
<uses-permission android:name="android.permission.INTERNET" /> dependencies {
Für die Modelle auf dem Gerät müssen Sie in Gradle angeben, dass das Modell nicht komprimiert werden soll, da es verzerrt werden kann.
android {
Wenn wir alles in unserer Umgebung konfiguriert haben, müssen wir spezielle Bedingungen festlegen, zu denen beispielsweise die Verwendung von Wi-Fi gehört, die ebenfalls aufgeladen werden müssen und bei Android N Geräte im Leerlauf verfügbar sind. Diese Bedingungen zeigen an, dass das Telefon aufgeladen wird oder sich im Standby-Modus befindet.
var conditionsBuilder: FirebaseModelDownloadConditions.Builder = FirebaseModelDownloadConditions.Builder().requireWifi() if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.N) {
Wenn wir ein Remote-Modell erstellen, legen wir die Initialisierungs- und Aktualisierungsbedingungen sowie das Flag fest, ob unser Modell aktualisiert werden soll. Der Modellname sollte mit dem in der Firebase-Konsole angegebenen übereinstimmen. Wenn wir das Remote-Modell erstellt haben, müssen wir es im Firebase Model Manager registrieren.
val cloudSource: FirebaseRemoteModel = FirebaseRemoteModel.Builder("my_cloud_model") .enableModelUpdates(true) .setInitialDownloadConditions(conditions) .setUpdatesDownloadConditions(conditions) .build() FirebaseModelManager.getInstance().registerRemoteModel(cloudSource)
Wir führen die gleichen Schritte für das lokale Modell aus, geben dessen Namen und den Pfad zum Modell an und registrieren es im Firebase Model Manager.
val localSource: FirebaseLocalModel = FirebaseLocalModel.Builder("my_local_model") .setAssetFilePath("my_model.tflite") .build() FirebaseModelManager.getInstance().registerLocalModel(localSource)
Danach müssen Sie solche Optionen erstellen, in denen wir die Namen unserer Modelle angeben, das Remote-Modell installieren, das lokale Modell installieren und einen Interpreter mit diesen Optionen erstellen. Wir können entweder ein entferntes Modell oder nur ein lokales Modell angeben, und der Interpreter wird selbst verstehen, mit welchem Modell er arbeiten soll.
val options: FirebaseModelOptions = FirebaseModelOptions.Builder() .setRemoteModelName("my_cloud_model") .setLocalModelName("my_local_model") .build() val interpreter = FirebaseModelInterpreter.getInstance(options)
ML Kit weiß nichts über das Format der Eingabe- und Ausgabedaten von benutzerdefinierten Modellen, daher müssen Sie diese angeben.
Eingabedaten sind ein mehrdimensionales Array, wobei 1 die Anzahl der Bilder, 224 x 224 die Auflösung und 3 ein dreikanaliges RGB-Bild ist. Nun, der Datentyp ist Bytes.
val input = intArrayOf(1, 224, 224, 3)
Die Ausgabewerte sind 1000 Klassifikatoren. Wir legen das Format der Eingabe- und Ausgabewerte in Bytes mit den angegebenen mehrdimensionalen Arrays fest. Neben Bytes sind auch float, long, int verfügbar.
Jetzt setzen wir die Eingabewerte. Wir nehmen Bitmap, komprimieren es auf 224 mal 224, konvertieren es in ByteBuffer und erstellen Eingabewerte mit FirebaseModelInput mit einem speziellen Builder.
val bitmap = Bitmap.createScaledBitmap(yourInputImage, 224, 224, true) val imgData = convertBitmapToByteBuffer(bitmap) val inputs: FirebaseModelInputs = FirebaseModelInputs.Builder() .add(imageData) .build()
Und jetzt, wenn es einen Interpreter gibt, das Format der Eingabe- und Ausgabewerte und die Eingabewerte selbst, können wir die Anforderung mit der Ausführungsmethode ausführen. Wir übertragen alle oben genannten Elemente als Parameter und erhalten als Ergebnis FirebaseModelOutput, das ein Generikum des von uns angegebenen Typs enthält. In diesem Fall war es ein Byte-Array, nach dem wir mit der Verarbeitung beginnen können. Dies sind genau die tausend Klassifikatoren, die wir angefordert haben, und wir zeigen zum Beispiel die Top 3 an, die am besten geeignet sind.
interpreter.run(inputs, inputOutputOptions) .addOnSuccessListener { result: FirebaseModelOutputs -> val labelProbArray = result.getOutput<Array<ByteArray>>(0)
Eintägige Implementierung
Alles ist recht einfach zu implementieren und die Erkennung von Objekten mit integrierten Werkzeugen kann in nur einem Tag realisiert werden. Das Tool ist für iOS und Android verfügbar. Außerdem können Sie für beide Plattformen dasselbe TensorFlow-Modell verwenden.
Darüber hinaus stehen unzählige Methoden zur Verfügung, die viele Fälle abdecken können. Die meisten APIs sind auf dem Gerät verfügbar, dh die Erkennung funktioniert auch ohne Internet.
Und vor allem - Unterstützung für benutzerdefinierte Modelle, die für jede Aufgabe nach Belieben verwendet werden können.
Nützliche Links
ML Kit Dokumentation
Github ML Kit Demo-Projekt
Maschinelles Lernen für Handys mit Firebase (Google I / O'19)
Maschinelles Lernen SDK für mobile Entwickler (Google I / O'18)
Erstellen eines Kreditkartenscanners mit dem Firebase ML Kit (Medium.com)