Die erste Aufgabe, mit der Entwickler am häufigsten konfrontiert sind, wenn sie mit der Programmierung in JavaScript beginnen, ist das Protokollieren von Ereignissen im Konsolenprotokoll mithilfe der Methode
console.log . Auf der Suche nach Informationen zum Debuggen von JavaScript-Code finden Sie Hunderte von Blog-Artikeln sowie Anweisungen zu StackOverflow, in denen Sie aufgefordert werden, Daten über die
console.log Methode „einfach“ an die Konsole
console.log . Dies ist eine so übliche Praxis, dass ich Regeln für die Codequalitätskontrolle einführen musste, z. B.
no-console , um keine zufälligen Protokolleinträge im Produktionscode zu hinterlassen. Was aber, wenn Sie eine Veranstaltung speziell registrieren müssen, um zusätzliche Informationen bereitzustellen?
Dieser Artikel beschreibt verschiedene Situationen, in denen Sie Protokolle verwalten müssen. Es zeigt den Unterschied zwischen den Methoden
console.log und
console.error in Node.js und zeigt, wie die Protokollierungsfunktion an Bibliotheken übergeben wird, ohne die Benutzerkonsole zu überlasten.

Theoretische Grundlagen der Arbeit mit Node.js.
Die Methoden
console.log und
console.error können sowohl im Browser als auch in Node.js verwendet werden. Bei der Verwendung von Node.js ist jedoch eines zu beachten. Wenn Sie den folgenden Code in Node.js mit einer Datei namens
index.js ,

und führen Sie es dann im Terminal mit dem
node index.js . Die Ergebnisse der Befehlsausführung befinden sich übereinander:

Trotz der Tatsache, dass sie ähnlich erscheinen, verarbeitet das System sie unterschiedlich. Wenn Sie sich den Abschnitt über den
console in der
Node.js-Dokumentation console.log , stellt sich heraus, dass
console.log das Ergebnis über
stdout und
console.error über
stderr druckt.
Jeder Prozess kann standardmäßig mit drei Streams (
stream ) arbeiten:
stdin ,
stdout und
stderr . Der
stdin Stream verarbeitet Eingaben für einen Prozess, z. B. Tastenklicks oder umgeleitete Ausgaben (mehr dazu weiter unten). Der Standard-Standardausgabestream dient zur Ausgabe von Anwendungsdaten. Schließlich ist der Standard-
stderr Fehlerstrom so ausgelegt, dass Fehlermeldungen angezeigt werden. Wenn Sie herausfinden
stderr , wofür
stderr und wann Sie es verwenden sollen, lesen Sie
diesen Artikel .
Kurz gesagt, es kann verwendet werden, um die Operatoren Umleitung (
> ) und Pipeline (
| ) zu verwenden, um mit Fehlern und Diagnoseinformationen getrennt von den tatsächlichen Ergebnissen der Anwendung zu arbeiten. Wenn Sie mit dem Operator
> die Ausgabe des Befehlsergebnisses in eine Datei umleiten können, können Sie mit dem Operator
2> die Ausgabe des
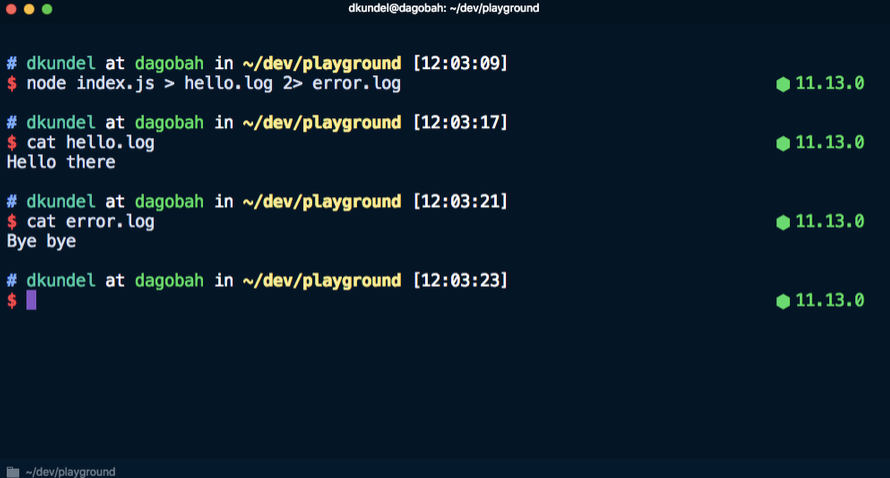
stderr Fehlerstroms in eine Datei umleiten. Dieser Befehl sendet beispielsweise
Hello an die Datei
hello.log und
Bye bye an die Datei
error.log .

Wann muss ich Ereignisse in das Protokoll schreiben?
Nachdem wir die technischen Aspekte der Protokollierung überprüft haben, gehen wir zu verschiedenen Szenarien über, in denen Sie Ereignisse registrieren müssen. In der Regel fallen diese Szenarien in eine von mehreren Kategorien:
Dieser Artikel beschreibt nur die letzten drei Szenarien, die auf Node.js basieren.
Protokollierung für Serveranwendungen
Es gibt mehrere Gründe für die Protokollierung von Ereignissen, die auf dem Server auftreten. Wenn Sie beispielsweise eingehende Anforderungen protokollieren, können Sie Statistiken darüber abrufen, wie oft Benutzer auf 404-Fehler stoßen, was der Grund dafür sein könnte oder welche
User-Agent Clientanwendung verwendet wird. Sie können auch den Zeitpunkt und die Ursache des Fehlers ermitteln.
Um mit dem in diesem Teil des Artikels angegebenen Material zu experimentieren, müssen Sie einen neuen Katalog für das Projekt erstellen. Erstellen
index.js im Projektverzeichnis
index.js für den zu verwendenden Code und führen Sie die folgenden Befehle aus, um das Projekt zu starten und
express installieren:

Wir haben einen Server mit Middleware eingerichtet, der jede Anforderung in der Konsole mithilfe der
console.log Methode
console.log . Wir
index.js die folgenden Zeilen in die Datei
index.js :
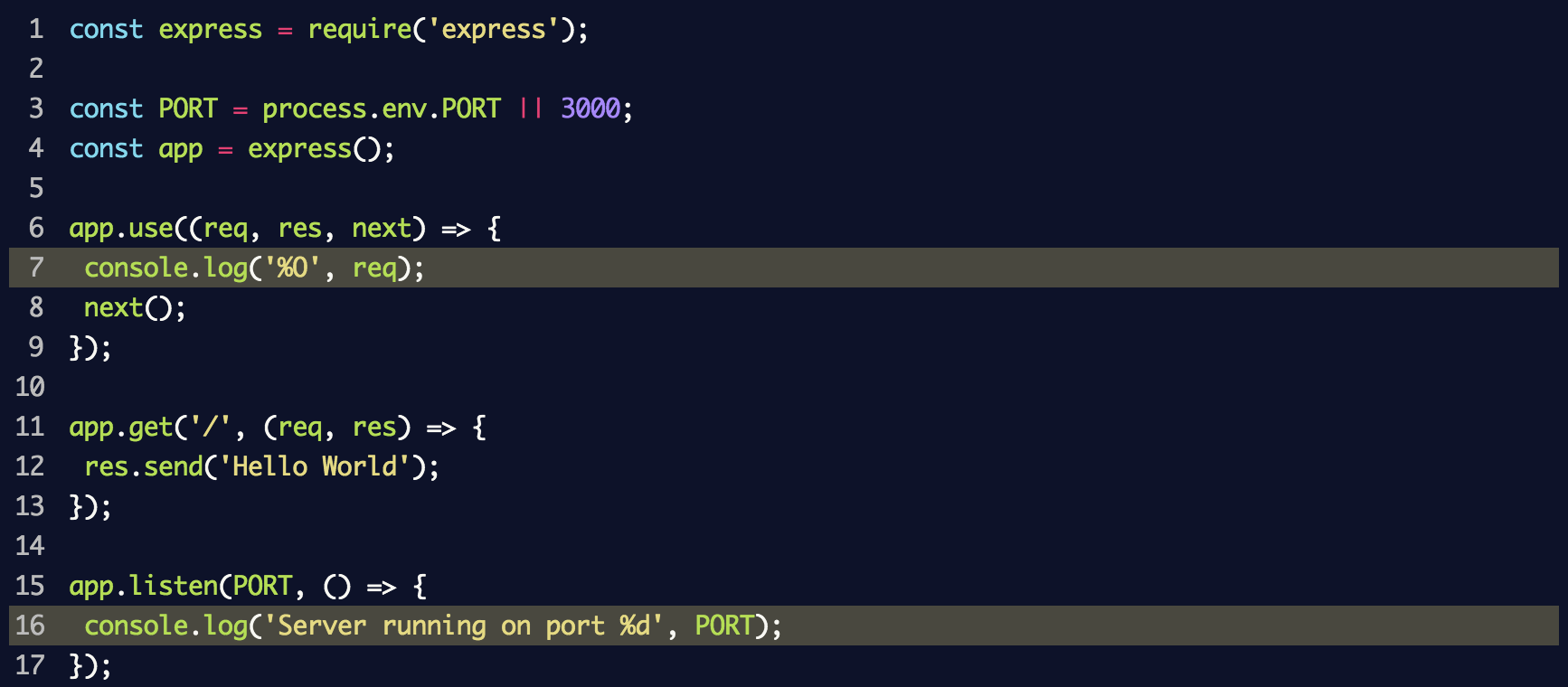
Dies verwendet
console.log('%O', req) , um das gesamte Objekt im Protokoll zu protokollieren. Aus Sicht der internen Struktur verwendet die Methode
util.forma t, das neben
%O auch andere Platzhalter unterstützt. Informationen dazu finden Sie in der
Dokumentation zu Node.js.Wenn Sie den
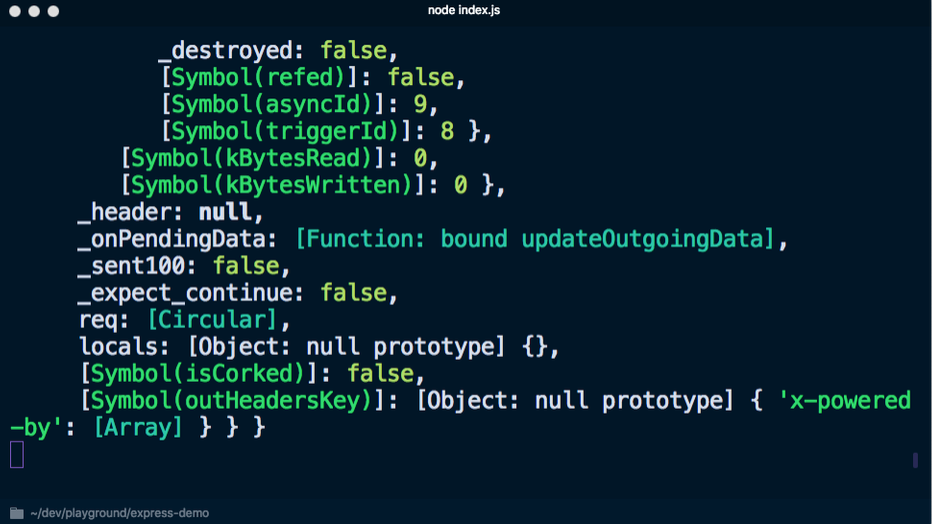
node index.js ausführen, um den Server zu starten und zu
localhost : 3000 zu wechseln, zeigt die Konsole viele unnötige Informationen an:
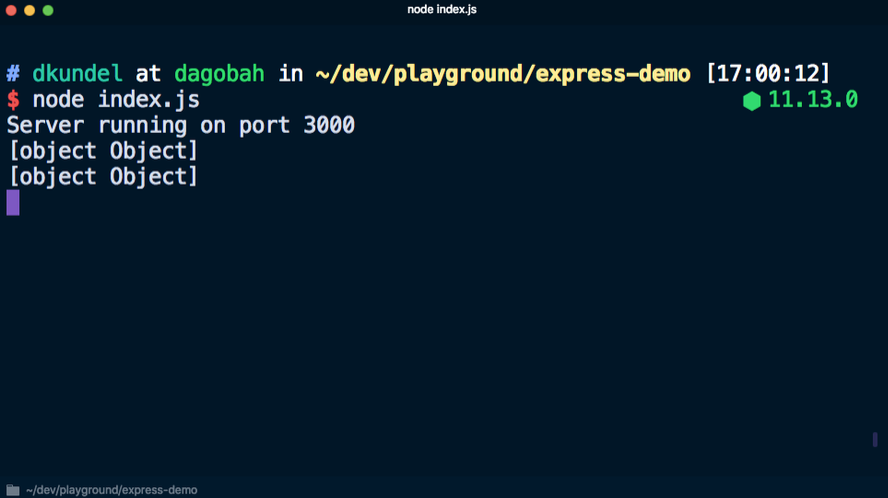
Wenn Sie stattdessen
console.log('%s', req) , um das Objekt nicht vollständig anzuzeigen, erhalten Sie nicht viele Informationen:
Sie können Ihre eigene Protokollierungsfunktion schreiben, die nur die erforderlichen Daten ausgibt. Zunächst müssen Sie jedoch entscheiden, welche Informationen benötigt werden. Trotz der Tatsache, dass der Fokus normalerweise auf dem Inhalt der Nachricht liegt, ist es in der Realität häufig erforderlich, zusätzliche Informationen zu erhalten, darunter:
- Zeitstempel - um zu wissen, wann Ereignisse aufgetreten sind;
- Computer- / Servername - wenn ein verteiltes System ausgeführt wird;
- Prozesskennung - wenn mehrere
pm2 ausgeführt werden, z. B. pm2 ; - Nachricht - eine tatsächliche Nachricht mit einigen Inhalten;
- Stack-Trace - wenn ein Fehler protokolliert wird;
- zusätzliche Variablen / Informationen.
Da in jedem Fall alles in die Streams
stdout und
stderr ausgegeben wird, muss ein Journal auf verschiedenen Ebenen geführt und Journaleinträge je nach Ebene konfiguriert und gefiltert werden.
Dies kann erreicht werden, indem Sie Zugriff auf verschiedene Teile des
process und mehrere Codezeilen in JavaScript schreiben. Node.js ist jedoch insofern bemerkenswert, als es bereits über ein
npm Ökosystem und mehrere Bibliotheken verfügt, die für diese Zwecke verwendet werden können. Dazu gehören:
pino ;winston ;- brüllen ;
- bunyan (diese Bibliothek wurde seit zwei Jahren nicht mehr aktualisiert).
Pino wird oft bevorzugt, weil es schnell ist und ein eigenes Ökosystem hat. Mal sehen, wie
pino bei der Protokollierung helfen kann. Ein weiterer Vorteil dieser Bibliothek ist das
express-pino-logger Paket, mit dem Sie Anforderungen registrieren können.
Installieren Sie
pino und
express-pino-logger :

Danach aktualisieren wir die Datei
index.js , um den Ereignisprotokollierer und die Middleware zu verwenden:
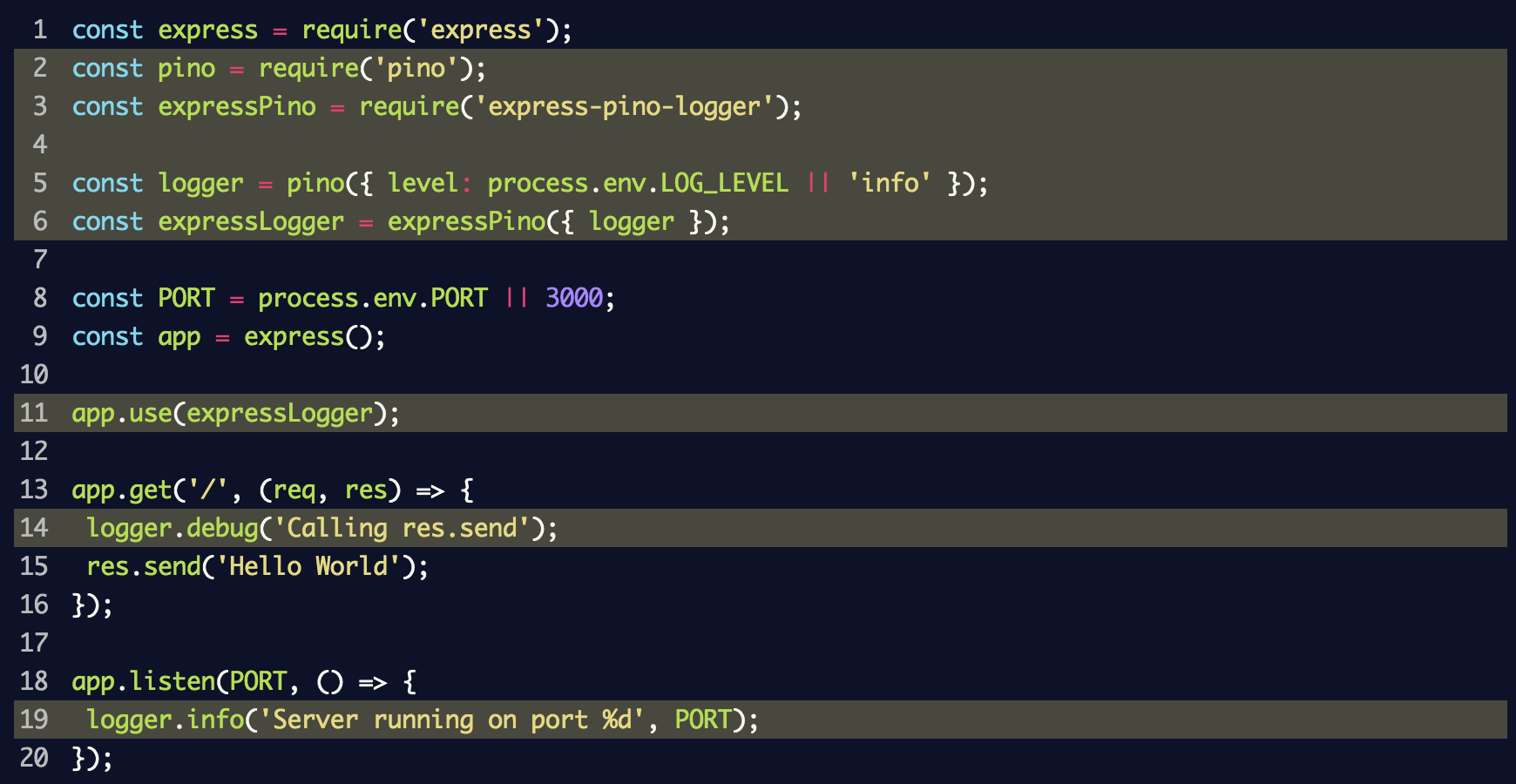
In diesem Fragment haben wir eine Instanz des Ereignisprotokollierers für
pino und an
express-pino-logger , um eine neue plattformübergreifende Ereignisprotokollierungssoftware zu erstellen, mit der Sie
app.use aufrufen
app.use . Außerdem wurde
console.log bei
logger.info durch
logger.info und
logger.debug zur Route hinzugefügt, um verschiedene Ebenen des Protokolls anzuzeigen.
Wenn Sie den Server durch wiederholtes Ausführen von
node index.js , erhalten Sie an der Ausgabe ein anderes Ergebnis, bei dem jede Zeile / Zeile im JSON-Format ausgegeben wird. Gehen Sie erneut zu
localhost : 3000, um eine weitere neue Zeile im JSON-Format anzuzeigen.
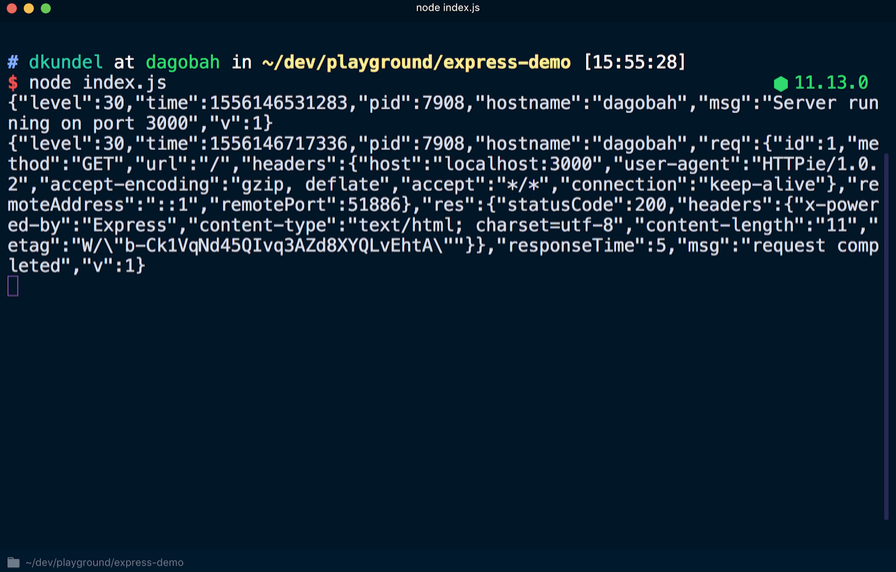
Unter den Daten im JSON-Format finden Sie die zuvor genannten Informationen, z. B. einen Zeitstempel. Beachten Sie auch, dass die Meldung
logger.debug nicht angezeigt wurde. Um es sichtbar zu machen, müssen Sie die Standardprotokollstufe ändern. Nach dem Erstellen einer Instanz der Logger-Ereignisregistrierung wurde der Wert
process.env.LOG_LEVEL festgelegt. Dies bedeutet, dass Sie den Wert ändern oder den Standardinfowert akzeptieren können.
LOG_LEVEL=debug node index.js Ausführen von
LOG_LEVEL=debug node index.js ändern wir die Protokollstufe.
Zuvor muss das Problem des Ausgabeformats gelöst werden, das derzeit für die Wahrnehmung nicht sehr praktisch ist. Dieser Schritt ist beabsichtigt. Gemäß der
pino Philosophie ist es aus Leistungsgründen erforderlich, die Verarbeitung von Journaleinträgen in einen separaten Prozess zu übertragen und die Ausgabe (unter Verwendung des Operators
| ) zu übergeben. Der Prozess umfasst das Übersetzen der Ausgabe in ein für die menschliche Wahrnehmung geeigneteres Format oder das Hochladen in die Cloud. Diese Aufgabe wird von Transferwerkzeugen ausgeführt, die als
transports . Lesen Sie in der
Dokumentation zum
transports Toolkit nach, warum
pino Fehler nicht über
stderr ausgegeben werden.
Verwenden Sie das
pino-pretty Tool, um eine besser lesbare Version des Magazins anzuzeigen. Im Terminal ausführen:

Alle Protokolleinträge werden mit dem
| zur Verfügung von
pino-pretty , wodurch die Ausgabe "gelöscht" wird, die nur wichtige Informationen enthält, die in verschiedenen Farben angezeigt werden. Wenn Sie
localhost : 3000 erneut abfragen, sollte eine
debug Debugging-Meldung angezeigt werden.
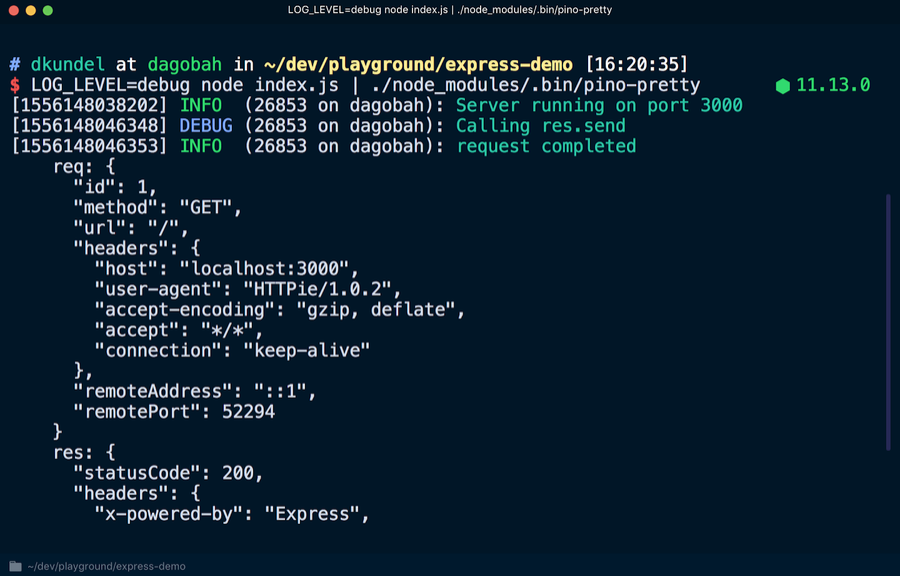
Um Journaleinträge besser lesbar zu machen oder zu konvertieren, gibt es viele Übertragungswerkzeuge. Sie können sogar mit Emojis mit
pino-colada angezeigt werden. Diese Tools sind nützlich für die lokale Entwicklung. Wenn der Server in Produktion ist, müssen Sie möglicherweise Protokolldaten mit
einem anderen Tool übertragen , zur weiteren Verarbeitung mit
> auf die Festplatte schreiben oder zwei Vorgänge gleichzeitig mit einem bestimmten Befehl ausführen, z. B.
tee .
Das
Dokument behandelt auch das Drehen von Protokolldateien, das Filtern und Schreiben von Protokolldaten in andere Dateien.
Bibliotheksjournal
Indem Sie nach Möglichkeiten suchen, die Protokollierung für Serveranwendungen effizient zu organisieren, können Sie dieselbe Technologie für Ihre eigenen Bibliotheken verwenden.
Das Problem ist, dass Sie im Fall der Bibliothek möglicherweise ein Protokoll für Debugging-Zwecke führen müssen, ohne die Client-Anwendung zu laden. Im Gegenteil, der Client sollte in der Lage sein, das Protokoll zu aktivieren, wenn ein Debugging erforderlich ist. Standardmäßig sollte die Bibliothek keine Ausgabe aufzeichnen, wodurch der Benutzer dieses Recht erhält.
Ein gutes Beispiel hierfür ist das
express Framework. Viele Prozesse finden in der internen Struktur des
express Frameworks statt, was das Interesse wecken kann, es während des Debuggens von Anwendungen eingehender zu untersuchen. In der
Dokumentation zum express Framework heißt es, dass Sie
DEBUG=express:* am Anfang des Befehls wie folgt hinzufügen können:

Wenn Sie diesen Befehl auf eine vorhandene Anwendung anwenden, werden viele zusätzliche Ausgaben angezeigt, die beim Debuggen hilfreich sind:
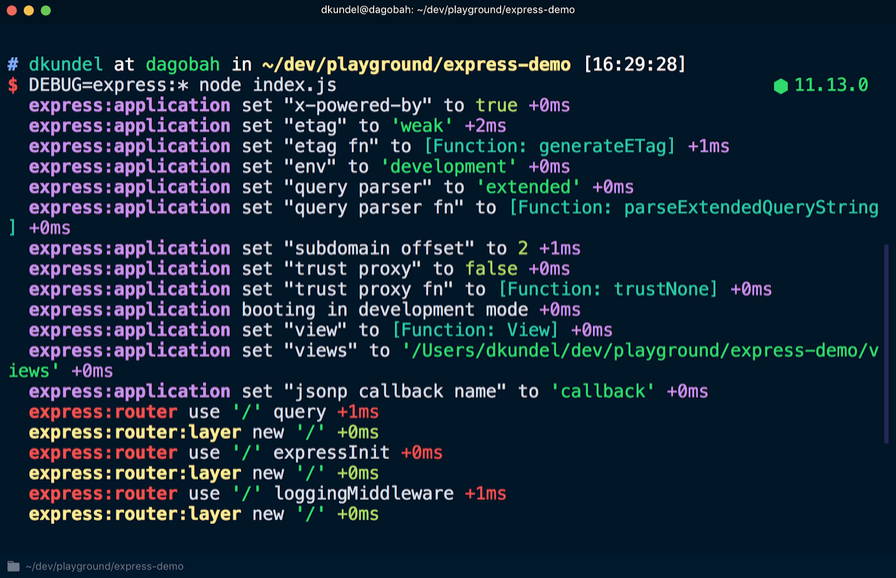
Diese Informationen können nur angezeigt werden, wenn das Debug-Protokoll aktiviert ist.
debug gibt es ein
debug Paket. Es kann verwendet werden, um Nachrichten in den "Namespace" zu schreiben. Wenn der Bibliotheksbenutzer diesen Namespace oder einen Platzhalter, der mit ihm übereinstimmt, in seine
DEBUG Umgebungsvariable einfügt , werden die Nachrichten angezeigt. Zuerst müssen Sie die
debug Bibliothek installieren:

Erstellen Sie eine neue Datei mit dem Namen
random-id.j s, die die Bibliothek simuliert, und
random-id.j den folgenden Code ein:
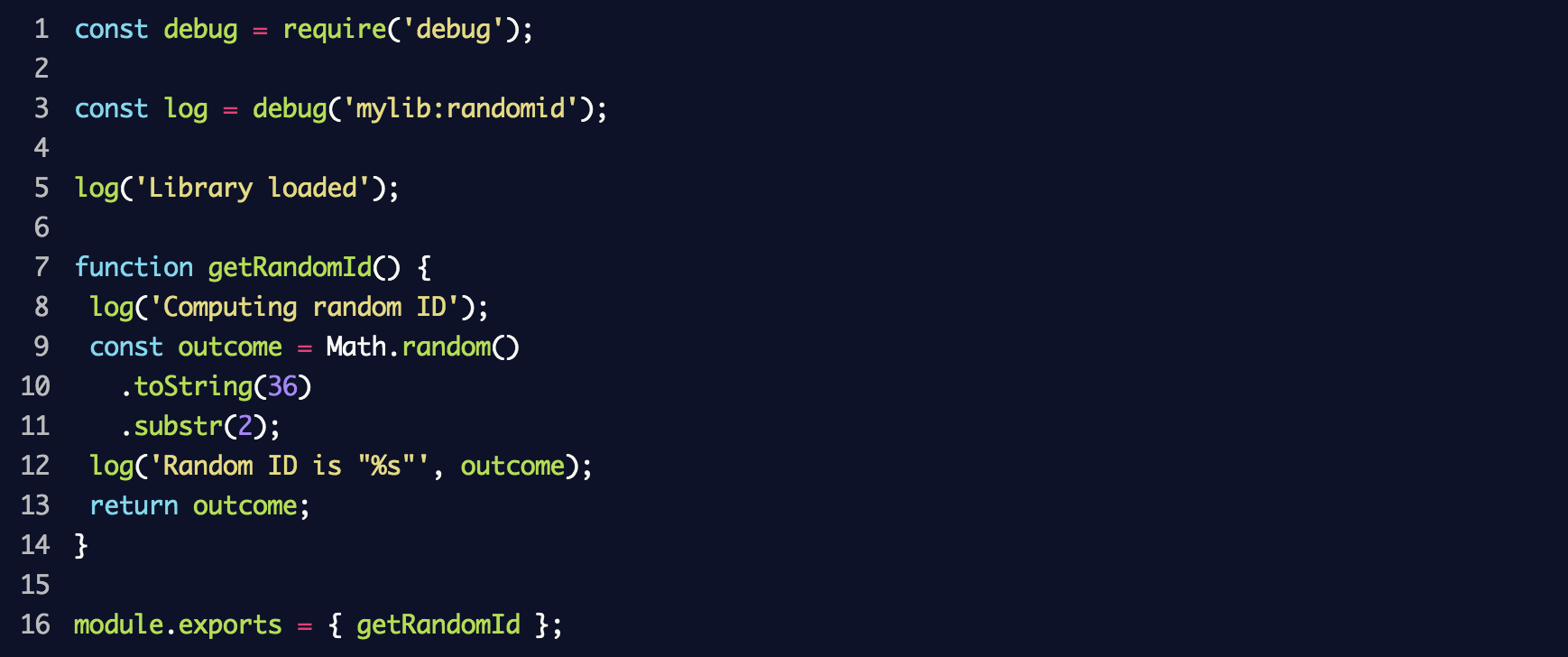
Als Ergebnis wird ein neuer
debug Ereignisprotokollierer mit dem
mylib:randomid , in dem dann zwei Nachrichten registriert werden. Wir verwenden es in
index.js aus dem vorherigen Abschnitt:
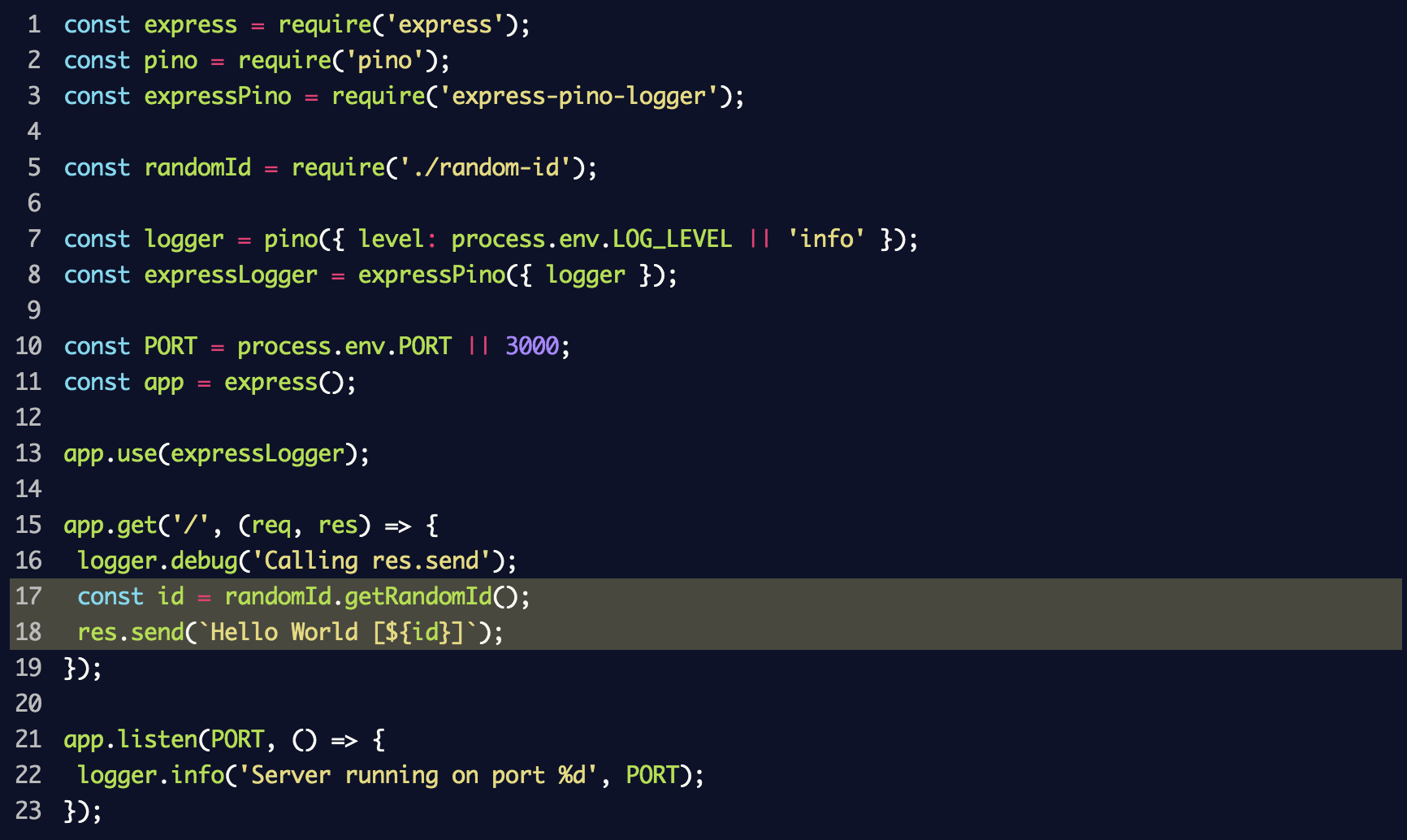
Wenn Sie den Server erneut starten und diesmal
DEBUG=mylib:randomid node index.js , werden die Debug-Protokolleinträge für unsere "Bibliothek" angezeigt:
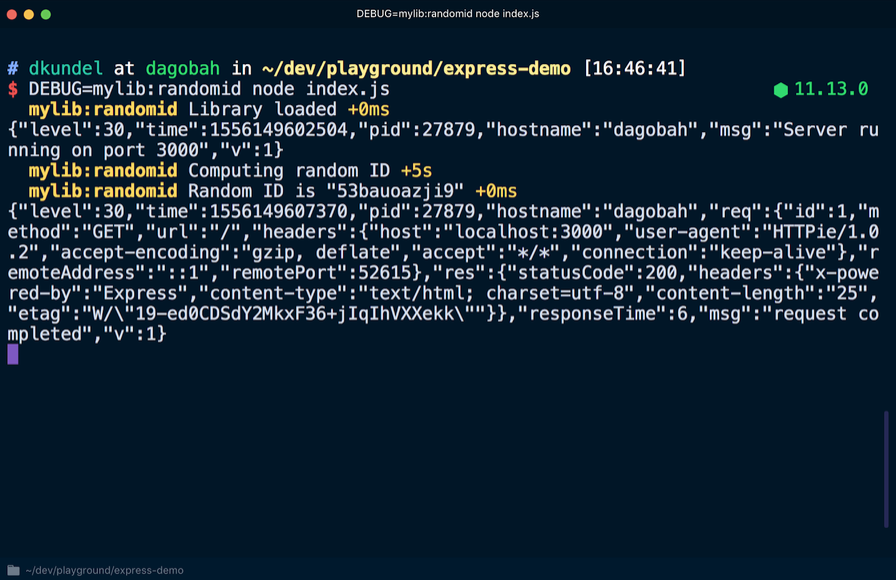
Wenn Bibliotheksbenutzer Debug-Informationen in
pino Protokolleinträge
pino möchten, können sie eine vom Befehl
pino-debug erstellte Bibliothek namens
pino-debug , um diese Einträge korrekt zu formatieren.
Installieren Sie die Bibliothek:

Vor der ersten Verwendung von
debug muss
pino-debug initialisiert werden. Der einfachste Weg, dies zu tun, besteht darin, die
Flags -r oder --require zu verwenden, um ein Modul anzufordern, bevor das Skript ausgeführt wird. Wir starten den Server mit dem Befehl neu (vorausgesetzt,
pino-colada installiert):

Infolgedessen werden die Debug-Protokolleinträge der Bibliothek auf dieselbe Weise wie im Anwendungsprotokoll angezeigt:
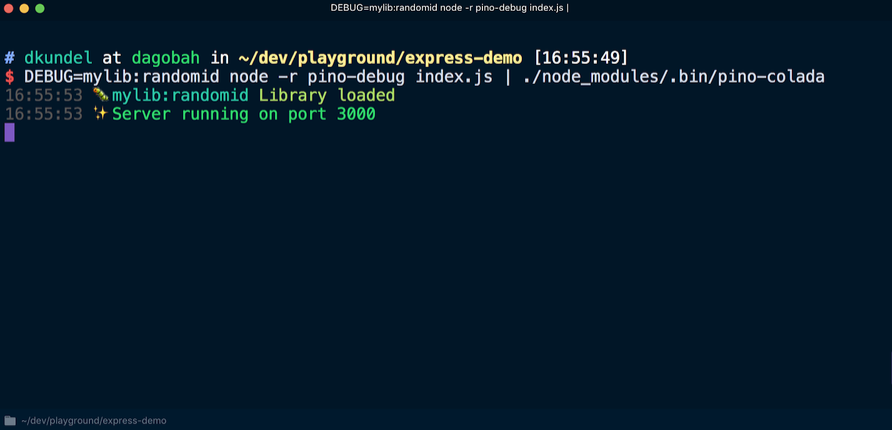
Ausgabe der Befehlszeilenschnittstelle (CLI)
Der letzte Fall, den dieser Artikel behandelt, ist die Protokollierung für die Befehlszeilenschnittstelle. Vorzugsweise wird das Protokoll, das Ereignisse im Zusammenhang mit der Programmlogik aufzeichnet, vom Protokoll zum Registrieren von Befehlszeilenschnittstellendaten getrennt gehalten. Um Ereignisse im Zusammenhang mit der Programmlogik aufzuzeichnen, müssen Sie eine bestimmte Bibliothek verwenden, z. B.
debug . In diesem Fall können Sie die Programmlogik über die Befehlszeilenschnittstelle wiederverwenden, ohne auf ein Szenario beschränkt zu sein.
Durch Erstellen einer Befehlszeilenschnittstelle mit Node.js können Sie verschiedene Farben, Blöcke mit variablen Werten oder Formatierungswerkzeuge hinzufügen, um der Benutzeroberfläche ein optisch ansprechendes Aussehen zu verleihen. Sie müssen jedoch mehrere Szenarien berücksichtigen.
Einer von ihnen zufolge kann die Schnittstelle im Kontext eines kontinuierlichen Integrationssystems (CI) verwendet werden. In diesem Fall ist es besser, auf die Farbformatierung und die visuell überlastete Darstellung der Ergebnisse zu verzichten. Bei einigen kontinuierlichen Integrationssystemen ist das
CI Flag gesetzt. Mit dem
is-ci Paket, das mehrere solcher Systeme unterstützt, können Sie überprüfen, ob Sie sich in einem kontinuierlichen Integrationssystem befinden.
Einige Bibliotheken, wie z. B.
chalk , definieren kontinuierliche Integrationssysteme und überschreiben die Ausgabe von farbigem Text an die Konsole. Mal sehen, wie es funktioniert.
Installieren Sie
chalk mit dem
install chalk npm
install chalk cli.js und erstellen Sie eine Datei mit dem Namen
cli.js Fügen Sie die folgenden Zeilen in die Datei ein:

Wenn Sie dieses Skript jetzt mit dem
node cli.js , werden die Ergebnisse in verschiedenen Farben dargestellt:
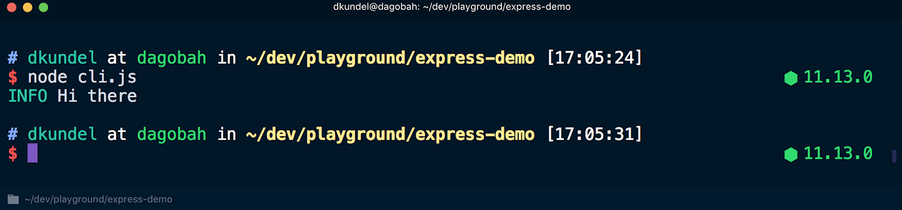
Wenn Sie das Skript jedoch mit
CI=true node cli.js , wird die Farbformatierung der Texte abgebrochen:
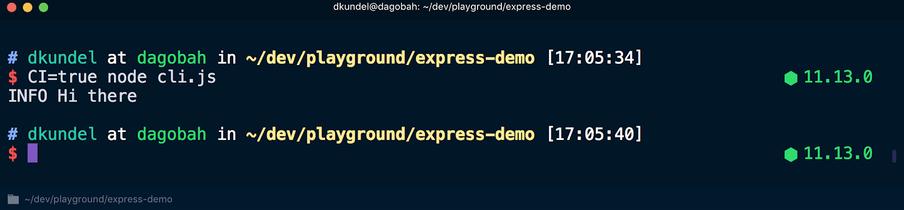
In einem anderen denkwürdigen Szenario wird
stdout im Terminalmodus ausgeführt, d. H. Daten werden an das Terminal ausgegeben. In diesem Fall können die Ergebnisse mit
boxen gut angezeigt werden. Andernfalls wird die Ausgabe höchstwahrscheinlich in eine Datei oder an eine andere Stelle umgeleitet.
Sie können den Betrieb von
stdin ,
stdout oder
stderr Streams im Terminalmodus überprüfen, indem Sie sich das
isTTY Attribut des entsprechenden Streams
isTTY . Zum Beispiel
process.stdout.isTTY .
TTY bedeutet "Teletypewriter" und ist in diesem Fall speziell für das Terminal konzipiert.
Die Werte können für jeden der drei Threads variieren, je nachdem, wie die Node.js-Prozesse gestartet wurden. Detaillierte Informationen hierzu finden Sie in der
Node.js-Dokumentation im Abschnitt „Eingabe / Ausgabe von Prozessen“ .
Mal sehen, wie sich der Wert von
process.stdout.isTTY in verschiedenen Situationen
process.stdout.isTTY .
cli.js Datei
cli.js , um sie zu überprüfen:

Führen Sie nun den
node cli.js im Terminal aus und sehen Sie das Wort
true node cli.js die Nachricht in farbiger Schrift angezeigt:

Danach führen wir den Befehl erneut aus, leiten die Ausgabe jedoch in eine Datei um und zeigen dann den Inhalt an:

Dieses Mal wurde das
undefined Wort im Terminal angezeigt, gefolgt von einer Meldung in farbloser Schrift, da der
stdout Stream es aus dem Terminalmodus umgeleitet hat. Hier verwendet
chalk das
isTTY supports-color Tool, das aus Sicht der internen Struktur die
isTTY entsprechenden Streams überprüft.
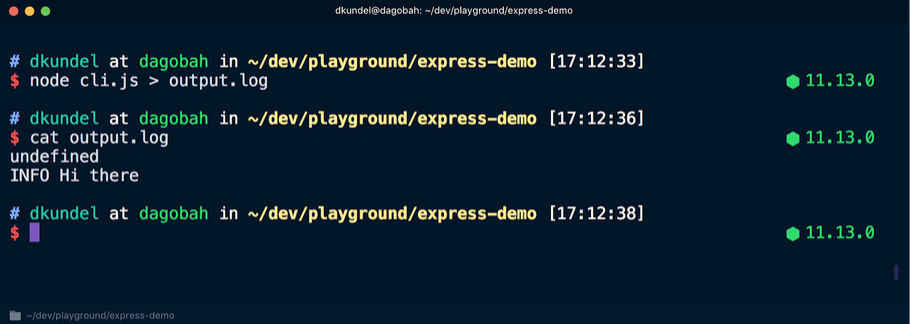
Werkzeuge wie
chalk erledigen diese Dinge selbstständig. Wenn Sie jedoch eine Befehlszeilenschnittstelle entwickeln, sollten Sie immer Situationen berücksichtigen, in denen die Schnittstelle in einem kontinuierlichen Integrationssystem funktioniert oder die Ausgabe umgeleitet wird. Mit diesen Tools können Sie die Befehlszeilenschnittstelle auf einer höheren Ebene verwenden. Beispielsweise können die Daten im Terminal strukturierter organisiert werden. Wenn
isTTY undefined , wechseln Sie zu einer einfacheren Analysemethode.
Fazit
Die Verwendung von JavaScript und die Eingabe der ersten Zeile in das Konsolenprotokoll mit
console.log recht einfach. Bevor Sie den Code in der Produktion bereitstellen, sollten Sie jedoch verschiedene Aspekte der Verwendung des Protokolls berücksichtigen. Dieser Artikel ist nur eine Einführung in die verschiedenen Methoden und Lösungen, die beim Organisieren des Ereignisprotokolls verwendet werden. Es enthält nicht alles, was Sie wissen müssen. Daher wird empfohlen, auf erfolgreiche Open Source-Projekte zu achten und zu überwachen, wie sie das Protokollierungsproblem gelöst haben und welche Tools verwendet werden. Und jetzt versuchen Sie, sich zu protokollieren, ohne Daten an die Konsole auszugeben.
Wenn Sie andere erwähnenswerte Tools kennen, schreiben Sie in den Kommentaren darüber.