Hallo allerseits!
Ich heiße Vitaliy Bendik. Ich bin der Teamleiter für die Entwicklung von Android-Anwendungen bei Lamoda. 2018 sprach ich im Mosdroid Aluminium mit einem
Bericht , dessen Transkript ich teilen möchte.

Es geht darum, wie wir die Stabilität der mobilen Anwendung aufrechterhalten. Dies ist sehr wichtig für uns, da unser mobiles Publikum Millionen von Benutzern umfasst. In Bezug auf den Anteil an den Bestellungen unserer Kunden haben Anwendungen Websites, Desktop- und Mobilversionen insgesamt längst übertroffen, und die iOS-Plattform hat sich vor der Desktop-Website zu einem absoluten Marktführer entwickelt.
In dem Bericht werde ich sagen:
- was wir unter Anwendungsstabilität verstehen;
- Über die Architektur unserer mobilen Anwendung;
- über die Prozesse, Praktiken und Werkzeuge, die wir verwenden.
Was ist eine
stabile Anwendung für uns? Dies ist eine Anwendung, die nicht abstürzt, nicht hängt und vorhersehbar funktioniert. Wenn ich sage, dass es nicht fällt, meine ich, dass es bei mindestens 95% -99% der Benutzer nicht fällt.
Architektur

Wie Sie vielleicht erraten haben, zeigt dieses Bild reine Architektur, an die wir uns halten wollen. Als Präsentationsschicht verwenden wir MVP mit einigen Ergänzungen, die ich unten diskutieren werde.
Unsere mobile Anwendung ist sowohl für Telefone als auch für Tablets geeignet. Daher ist das Layout oft unterschiedlich, besteht jedoch aus ähnlichen oder identischen Blöcken. In dieser Hinsicht haben wir eine Entität wie Widget. Sie können eine Aktivität oder ein Fragment in kleinere Blöcke zerlegen, die in anderen Bildschirmen wiederverwendet werden können. Dies ist sinnvoll, da aus Sicht des Codes im Fragment oder in der Aktivität selten zwischen dem Kontext unterschieden werden muss, in dem die Benutzeroberfläche ausgeführt wird. Und diese Codefragmente können in einige Abstraktionen gerendert und wiederverwendet werden. Dieser Ansatz erinnert etwas an die SoundCloud-Bibliothek -
LightCycle .


 Produktseite. Beispiele für Widget-Elemente
Produktseite. Beispiele für Widget-ElementeWas die Interaktion des Präsentators mit dem Modell betrifft, ist hier alles Standard: Der Präsentator interagiert mit dem Rest der Anwendung über den Interaktor, egal ob es sich um Repositorys oder Manager handelt.
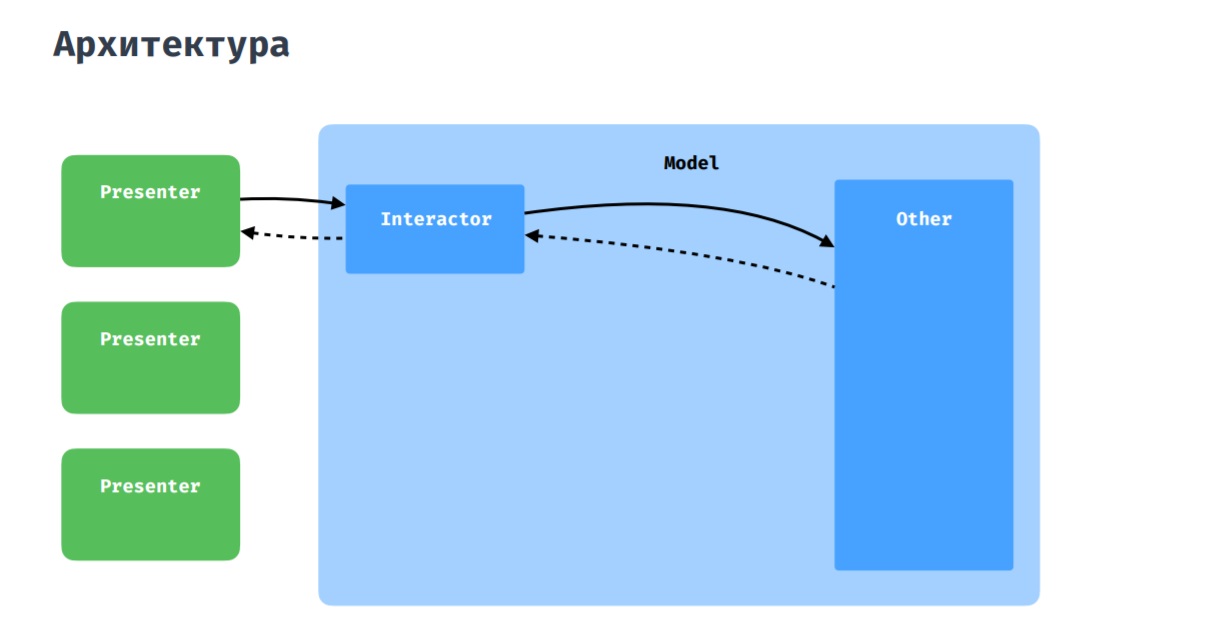
Es kommt vor, dass mehrere Moderatoren miteinander kommunizieren und Daten austauschen müssen. Dafür haben wir einen Koordinator, der als gemeinsamer Interaktor zwischen mehreren Moderatoren wahrgenommen werden kann.

Stapel
- Wir schreiben den gesamten neuen Code in Kotlin und verwenden Moxy als MVP-Implementierung.
- Als DI verwenden wir Dagger2 .
- Mit dem Netzwerk arbeiten - Nachrüsten .
- Zum Arbeiten mit Bildern - Gleiten .
- Wir fügen New Relic Abstürze hinzu.
- Wir benutzen auch Lottie .
- Im Moment setzen wir Kotlin Coroutines aktiv ein .
Entwicklungsprozess
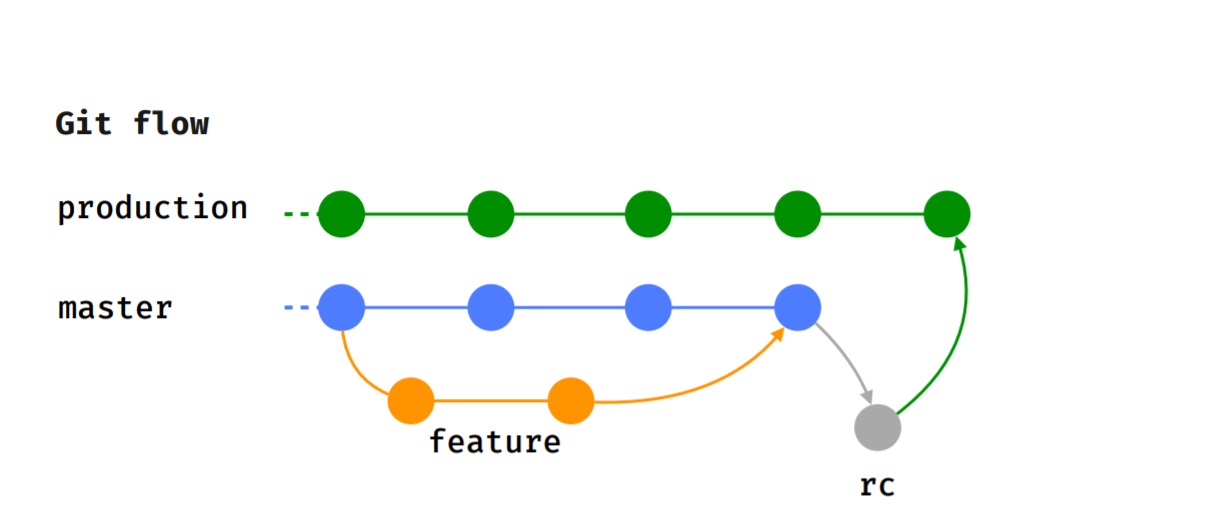
Wir halten uns an den Git-Flow, dh jedes Feature wird in einem separaten Feature-Zweig implementiert, der nach einer Codeüberprüfung zum Testen eingereicht wird.
Nachdem der Tester den Test erfolgreich abgeschlossen hat und wir uns für die Version entschieden haben, für die diese Funktion verwendet werden soll, wird sie in den Master integriert.
Wenn die Freigabezeit kommt (wir werden alle 2 Wochen freigegeben), wird der RC-Zweig, in dem Rauchprüfungen durchgeführt werden, zugewiesen und Testfälle werden ausgeführt. Danach wird die Funktion in den Produktionszweig integriert und in Google Play Beta veröffentlicht.
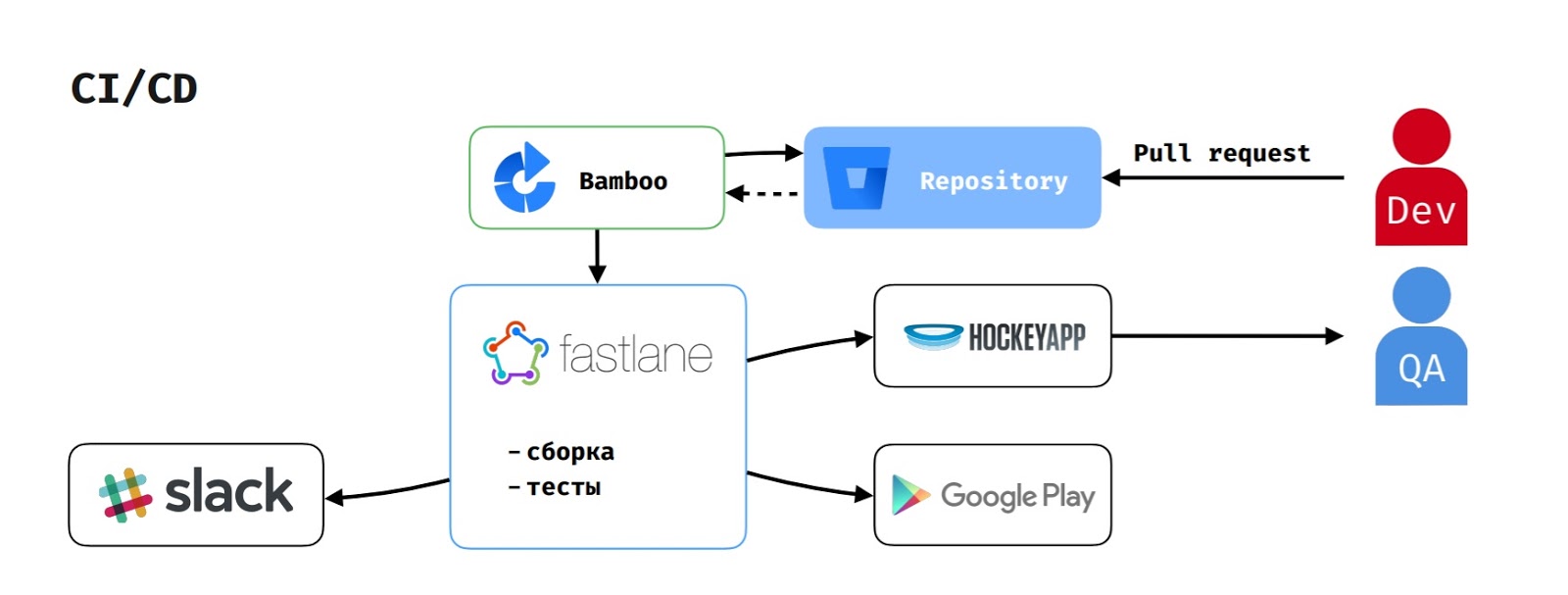
Bei CI / CD fungiert Bamboo als Build-Server, da wir den Atlassian-Stack verwenden.
Wenn ein Entwickler eine Pull-Anfrage erstellt, wird die Build-Aufgabe auf Bamboo gestartet. Sie zieht den Code aus dem Repository, führt das Skript auf Fastlane aus, das die Anwendung sammelt, die Tests ausführt und dies Slack meldet.
Wenn der Tester die Assembly gestartet hat, um die Funktion zu testen, wird apk auch in HockeyApp geladen.
Um die Version in Google Play Beta zu veröffentlichen, startet der Delivery Manager die entsprechende Aufgabe in Bamboo, die denselben Ablauf ausführt, aber auch die Version in Google Play Beta hochlädt.
Angewandte Praktiken
Pre-Release-BuildAnfangs hatten wir zwei Arten der Montage, wie viele:
Debug-Build, in dem ProGuard und SSL Pinning deaktiviert wurden.
Release-Build, in dem ProGuard und SSL Pinning enthalten waren.
Der Prozess sah folgendermaßen aus: Der Entwickler beendet die Arbeit an der Funktion und gibt sie zum Testen. Der Tester sammelt die Debug-Assembly, testet die Testfälle darauf und überprüft die Richtigkeit der von der Anwendung gesendeten Analysen. Wenn alles in Ordnung ist, sendet er die Aufgabe zur Veröffentlichung an Ready, und sie wartet auf den Moment, in dem wir mit der Abholung der Veröffentlichung beginnen.
Wenn die Zeit für die Freigabe der Anwendung gekommen ist, führt der Entwickler alle Aufgaben in Master zusammen, wählt den RC-Zweig aus und gibt ihm die Qualitätssicherung für Rauchtests. QA sammelt die Release-Baugruppe und beginnt mit der Ausführung von Tests. Aber es gibt Zeiten, in denen etwas schief geht. Probleme treten normalerweise aufgrund von ProGuard auf. Natürlich sind sie schnell behoben, aber dies kann die Veröffentlichung verzögern oder für einige Zeit verzögern.
Aus diesem Grund haben wir einen Pre-Release-Build erstellt, in dem ProGuard aktiviert und SSL-Pinning deaktiviert ist. Auf diese Weise können Tester die Richtigkeit der übermittelten Analysen überprüfen (dies war der Grund, warum Tester den Release-Build ursprünglich nicht erstellt haben).
Jetzt erstellen QAs einen Pre-Release-Build. Dies gibt ihnen die Möglichkeit, Analysen zu testen und Probleme, die durch ProGuard verursacht werden, so früh wie möglich zu lösen.
Spezifikation zuerstDies ist ein Ansatz, bei dem die Spezifikation primär ist. Wenn wir ein neues Feature entwickeln und es ein Backend erfordert, wird zuerst eine Spezifikation erstellt, und basierend darauf beginnt die Entwicklung des Features sowohl vom Backend als auch von den Clients. Alle Änderungen durchlaufen die Spezifikation, und erst dann werden Änderungen am Backend und an den Clients vorgenommen. Diese Spezifikation generiert auch eine Swagger-Dokumentation zu API-Methoden.
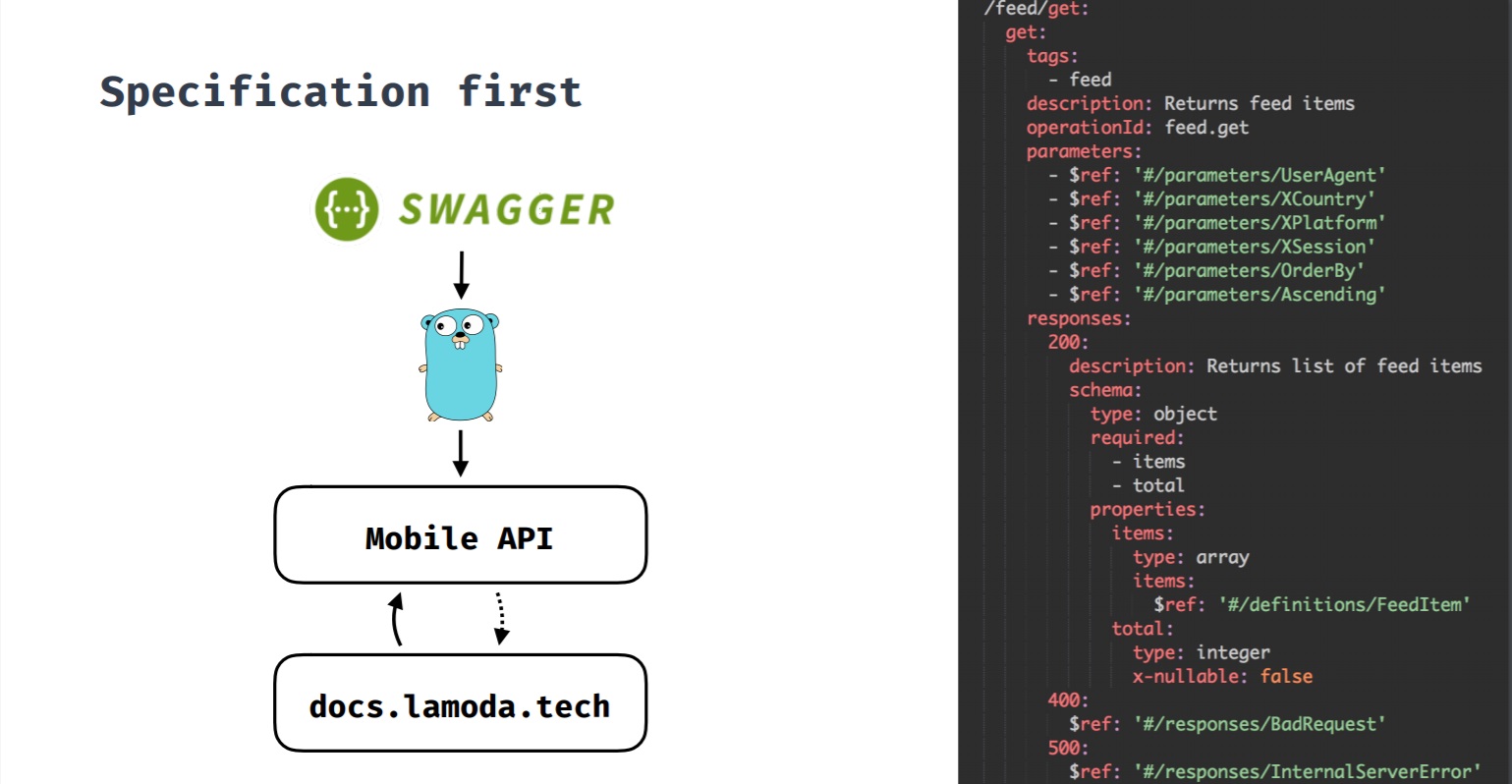
Anfangs hatten wir eine API, deren Clients nicht nur mobile Anwendungen waren. API-Methoden stimmten nicht überein, was häufig Änderungen schwierig machte.
Auch stieß oft auf lustige Fälle. Wenn die Methode beispielsweise eine Liste von Marken zurückgibt, wenn mehrere vorhanden sind, wird ein Array zurückgegeben, und wenn nur eine Marke vorhanden ist, wird ein Objekt zurückgegeben.

Wenn keine Marken vorhanden sind, wurde entweder null oder im Allgemeinen 4 null Zeichen zurückgegeben
(nicht JSON). In diesem Fall war die Anwendung schwierig.

Im Laufe der Zeit kamen wir daher zu dem Schluss, dass mobile Anwendungen eine eigene API benötigen, die ihre Besonderheiten berücksichtigt und die mobile Anwendung mit einer Reihe interner Lamoda-Systeme verknüpft, mit denen Sie interagieren müssen.

Gleichzeitig haben wir uns entschlossen, den ersten Ansatz der Spezifikation (Swagger-Spezifikation) auszuprobieren. Wenn ein Entwickler anfängt, an einem Feature zu arbeiten, das ein Backend benötigt, stellt er eine Pull-Anfrage mit einem Feature-Vertrag. Dann werden alle Interessenten von iOS-, Android- und Backend-Teams zu dieser Pull-Anfrage hinzugefügt. Wenn alle mit dem Vertrag der neuen API-Methode zufrieden sind, wird die Pull-Anforderung in den Backend-Zweig eingespeist und die Backend-Entwickler beginnen mit der Entwicklung von Funktionen. Kunden beginnen auch mit der Entwicklung von Funktionen, da der Vertrag jetzt festgelegt ist und Sie sich darauf verlassen und bei Bedarf Moki erstellen können.
Feature-TogglesDas Unternehmen verfügt über ein eigenes A / B-Entwicklungstool, mit dem Sie sowohl Experimente als auch Feature-Toggles implementieren können. Feature-Toggles schließen wir unkritische Funktionen für den Benutzer, die bei Bedarf deaktiviert werden können. Zum Beispiel, wenn etwas schief gelaufen ist oder wenn wir die Belastung des Backends reduzieren müssen (optional am „Black Friday“).
Mit Feature-Toggles können wir auch Bibliotheken testen, um festzustellen, ob eine andere Bibliothek unser Problem besser löst und sich stabiler verhält. Wenn nicht, können wir jederzeit zu unserer vorherigen Bibliothek zurückkehren.
Echte BenutzerüberwachungMit Real User Monitoring können Sie die Anwendungsleistung aus der Sicht eines Benutzers messen. Beispielsweise hat ein Kunde auf einen Artikel in einem Katalog geklickt. Wie lange muss er warten, bis er das Ergebnis seiner Aktion sieht, dh er sieht eine Produktkarte mit Fotos?
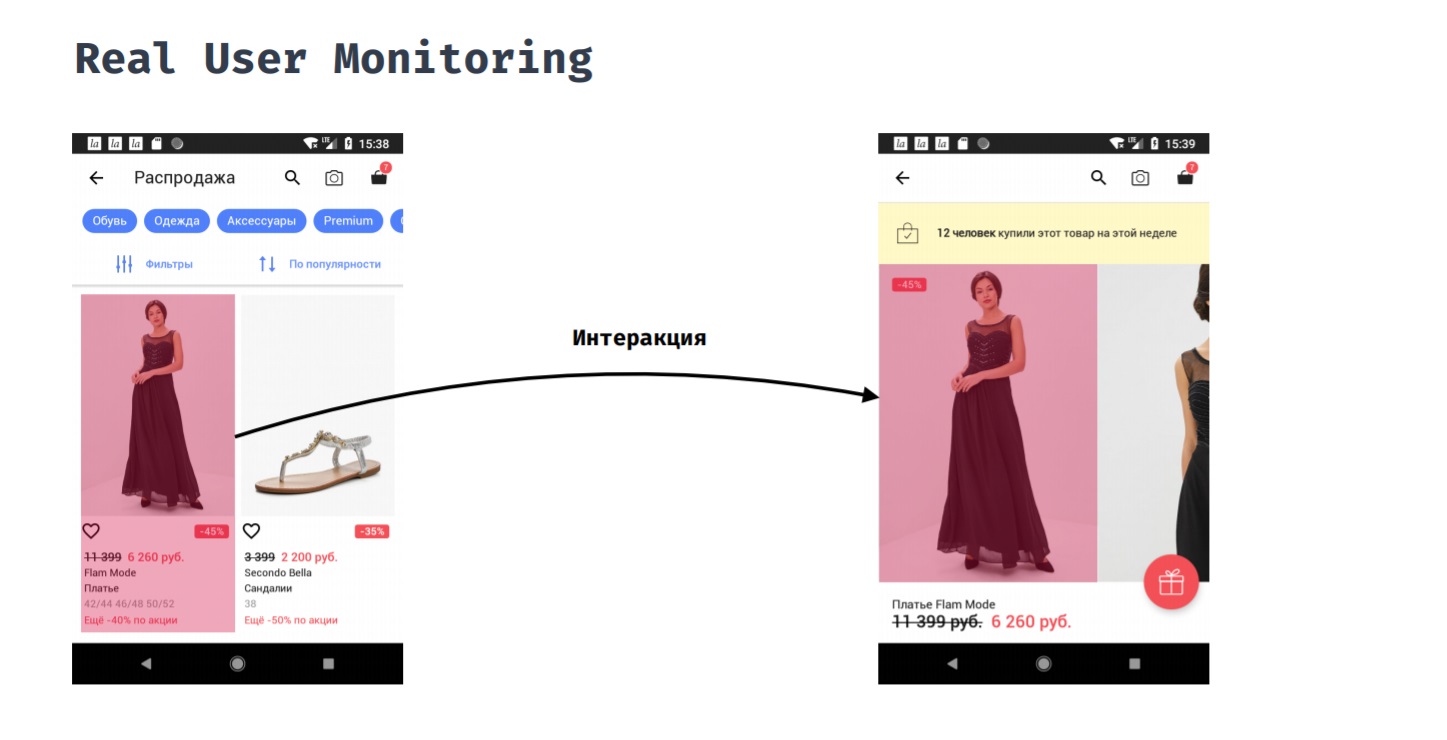
Dies kann nicht automatisch erfolgen, da Start- und Endpunkt dieser Messung manuell eingestellt werden müssen. Nur der Entwickler versteht, wann davon ausgegangen werden kann, dass der Benutzer bereit ist, mit dem neuen Bildschirm zu interagieren. Während dieser Interaktion könnten wir an folgenden Dingen interessiert sein:
1. Speicherverbrauch;
2. CPU-Verbrauch;
3. was im Hauptstrom passiert ist;
4. was aus dem Netzwerk geladen wurde;
5. Was ist in anderen Threads passiert?
Dies gibt uns die Möglichkeit, Probleme zu beheben, wenn sie auftreten, da klar wird, dass es tatsächlich die meiste Zeit gedauert hat und wir es optimieren können, damit die Anwendung besser auf den Benutzer reagiert.
Rückzahlung von technischen Schulden
Vor der Einführung der neuen Version beheben wir die Abstürze, die in der vorherigen Version aufgetreten sind. Hier geht es nicht um kritische Abstürze, da dies definitiv Hotfixes erfordern würde, sondern um Abstürze, die nicht zu oft auftreten, wirken sich nicht auf die Geschäftsleistung aus, sind jedoch für Benutzer unangenehm.
Nach der Veröffentlichung der Version rollen wir sie prozentual aus, überwachen kritische Indikatoren und reagieren auf Vorfälle, wenn sie auftreten. Für das schrittweise Rollen verwenden wir die Google Play Console. Das Walzen wird wie folgt durchgeführt: Um 5% ausgerollt überwachen wir den Indikator; Wenn alles in Ordnung ist, dann rollen Sie weiter. Wenn etwas passiert ist, machen Sie einen Hotfix und rollen Sie ihn bereits aus. Als nächstes rollen wir 10%, 20% und 50%.
Welche kritischen Orte
überwachen wir?
- Netzwerkanforderungen, auch von Bibliotheken von Drittanbietern: Fehler, Antwortzeit, Laden.
- Der Herbst.
- Behandelte Ausnahmen, die sogenannten "verarbeiteten Ausnahmen". Dies sind Ausnahmen, die hätten auftreten können, wenn wir sie nicht in Try-Catch eingewickelt hätten. Dadurch kann die Anwendung nicht fallen, wenn eine Ausnahme bei nicht kritischen Funktionen für den Benutzer aufgetreten ist. Zum Beispiel ist es schlecht, aufgrund von Analysen zu fallen. Für Produkte ist es jedoch wichtig zu verstehen, dass eine Funktion die Konvertierung verbessert oder verschlechtert. Durch die Verwendung von behandelten Ausnahmen können wir weiterhin auf diese Probleme reagieren und sie beheben.
Die Werkzeuge
- A / B-Tool
- NewRelic RPM
- NewRelic Insights.
Das A / B-Tool ist ein Mechanismus zum Durchführen von Experimenten und ein Mechanismus zum Rollen von Variablen, die gleichen Feature-Toggles. Da es sich um eine interne Entwicklung handelt, ist sie gut in viele Systeme integriert: in mobilen Anwendungen, vor Ort, im Back-End. Sie können die Feature-Toggles-Konfiguration nicht in einer separaten Anforderung dahinter, sondern in den Kopfzeilen der Antworten auf Anforderungen der Anwendung übermitteln.
Dies gibt uns die Möglichkeit:
- Führen Sie Experimente im Büro durch, wenn Sie einige Funktionen in unserem Büro testen möchten.
- Führen Sie ein Experiment sowie Feature-Toggles für einen bestimmten Benutzer aus.
Das System ist unabhängig von externen Faktoren. Wenn wir ein Tool eines Drittanbieters verwenden, könnte es irgendwann blockiert werden (Hallo, Roskomnadzor) oder es könnte etwas schief gehen. Für uns wäre dies von entscheidender Bedeutung, da wir in diesem Fall den Feature-Toggle nicht schnell umschalten könnten. Und da dies unsere eigene Entwicklung ist, haben wir kein solches Problem.
NewRelic ist ein Tool, mit dem Sie viele verschiedene Indikatoren in Echtzeit überwachen können. Von der Vielzahl der New Relic-Funktionen verwenden wir beispielsweise die automatische Code-Instrumentierung. Auf diese Weise können wir Netzwerkanforderungen nicht nur an unser Backend, sondern auch an alle anderen (auch aus Bibliotheken von Drittanbietern) überwachen. NewRelic unterstützt eine Reihe von Standardclients für die Arbeit mit dem Netzwerk. Außerdem können Sie Informationen sammeln:
1. über den Speicherverbrauch;
2. über den CPU-Verbrauch;
3. über Operationen im Zusammenhang mit JSON;
4. über Operationen im Zusammenhang mit SQlite.
Darüber hinaus verwenden wir NewRelic, um Absturzberichte, behandelte Ausnahmen und Benutzerinteraktionen zu erfassen - dies ist genau das gleiche
Real User Monitoring . Wir haben es durch den Mechanismus der Benutzerinteraktion NewRelic implementiert.
Aber was ist mit Stabilität?
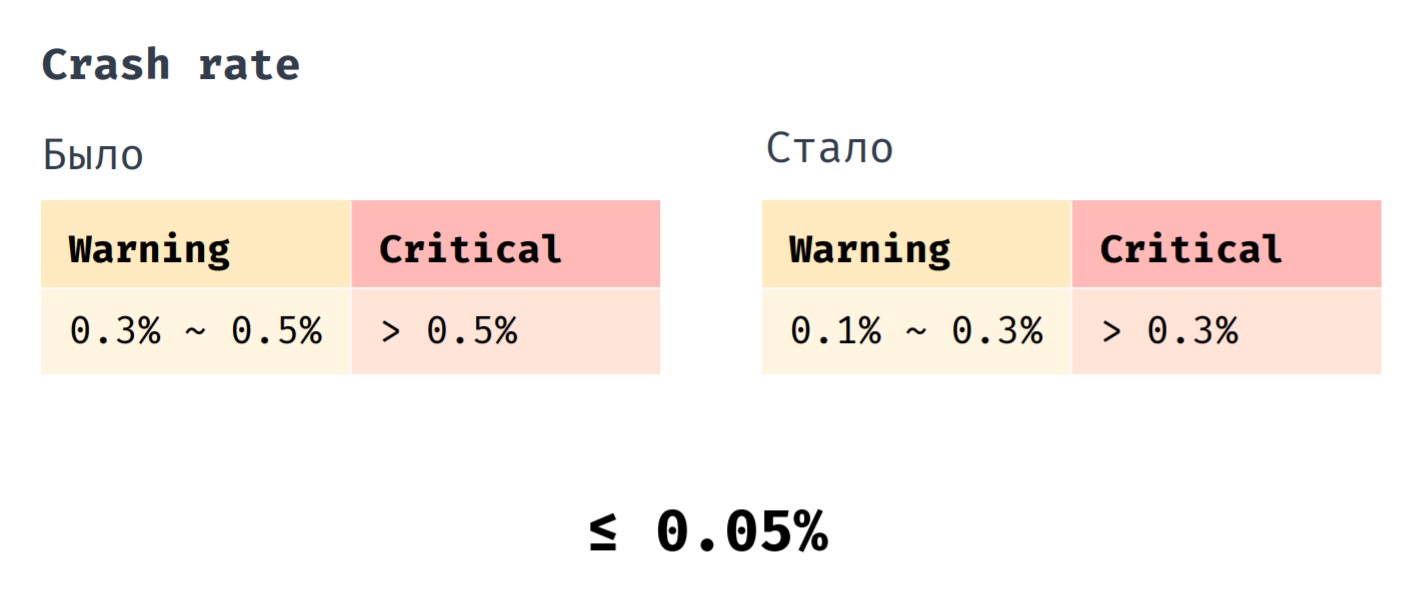
Wir haben einen Indikator wie Crash Rate. Zuvor haben wir Hotfix eingeführt, als sein Indikator im Bereich von 0,3% bis 0,5% lag. Es ist absolut kritisch, wenn sein Wert mehr als 0,5% beträgt. Jetzt führen wir einen Hotfix ein, wenn die Absturzrate im Bereich von 0,1% bis 0,3% liegt. Ein kritischer Wert liegt bei mehr als 0,3%. Wenn die durchschnittliche Absturzrate unserer Anwendung zuvor 0,1% betrug, beträgt sie jetzt 0,05%.
Abschließend möchte ich die wichtigsten Methoden auflisten, die uns bei der Aufrechterhaltung der Anwendungsstabilität helfen. Wir testen die Anwendung so nah wie möglich an der Produktionsversion, schließen die unkritische Funktionalität von Feauture-Toggles und überwachen und reagieren auf Indikatoren, die für uns wichtig sind.