Mit diesem Beitrag eröffne ich eine Reihe, in der meine Kollegen und ich Ihnen erklären werden, wie ML in Mail.ru Search verwendet wird. Heute werde ich erklären, wie das Ranking angeordnet ist und wie wir Informationen über Benutzerinteraktionen mit unserer Suchmaschine verwenden, um die Suchmaschine zu verbessern.
Ranglistenaufgabe
Was versteht man unter Ranglistenaufgabe? Stellen Sie sich vor, dass es im Schulungsbeispiel einige Abfragen gibt, für die die Reihenfolge der Dokumente nach Relevanz bekannt ist. Sie wissen beispielsweise, welches Dokument am relevantesten, welches am zweitrelevantesten usw. ist. Und Sie müssen diese Ordnung für die gesamte Bevölkerung wiederherstellen. Das heißt, für alle Anfragen der allgemeinen Bevölkerung wird der erste Platz das relevanteste Dokument und der letzte das irrelevanteste.
Mal sehen, wie solche Probleme in großen Suchmaschinen gelöst werden.
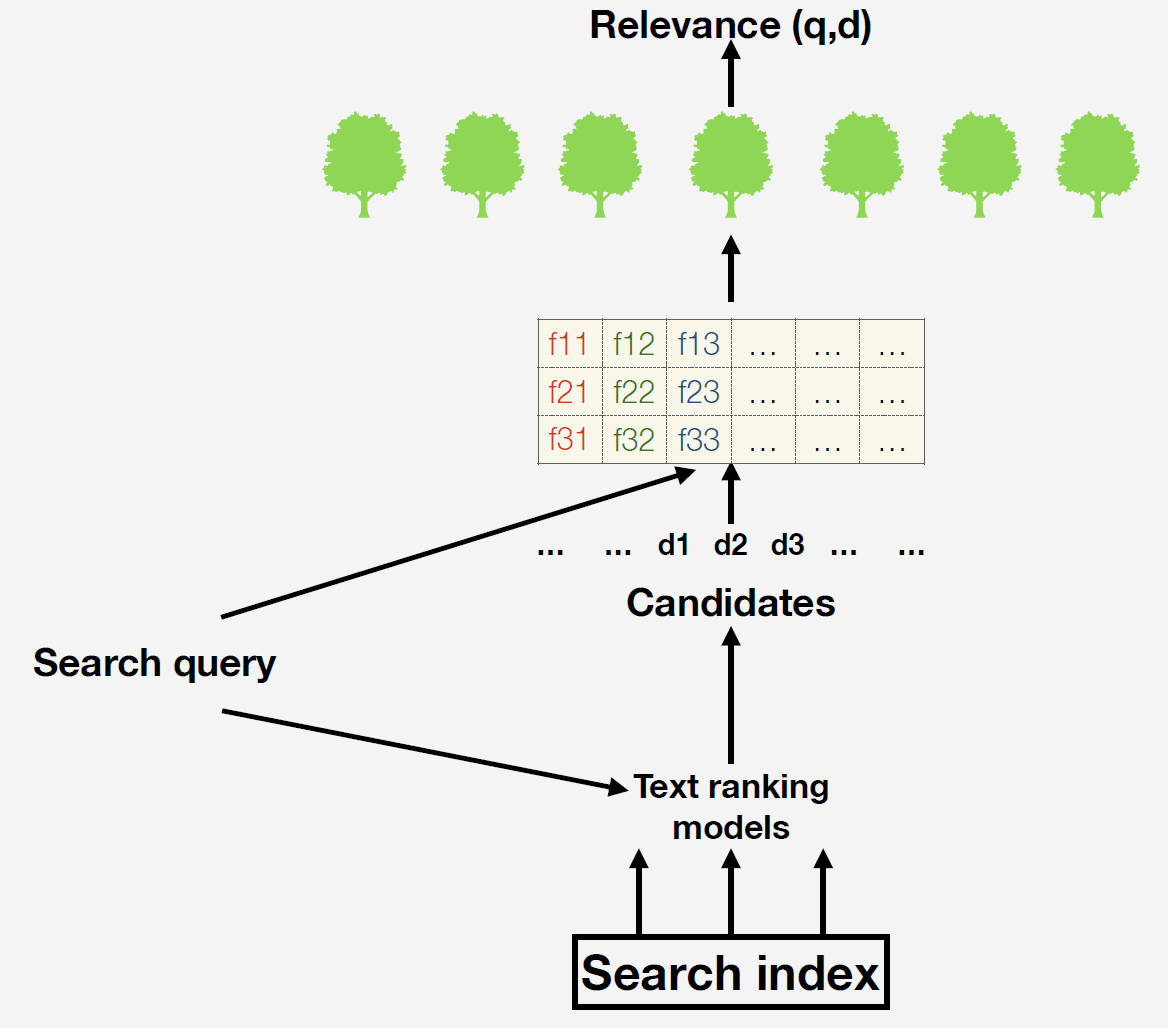
Wir haben einen Suchindex - dies ist eine Datenbank mit vielen Milliarden Dokumenten. Wenn eine Anfrage eingeht, erstellen wir zunächst eine Liste der Kandidaten für das endgültige Ranking mithilfe einfacher Textmodelle. Am einfachsten ist es, Dokumente aufzunehmen, die im Prinzip Wörter aus der Anfrage enthalten. Warum ist dieser Schritt notwendig? Tatsache ist, dass es nicht für alle verfügbaren Dokumente möglich ist, Zeichen zu erstellen und Prognosen für das endgültige Modell zu erstellen. Nachdem wir bereits die Vorzeichen berechnet haben. Welche Zeichen können wir nehmen? Zum Beispiel die Anzahl der Vorkommen von Wörtern aus einer Abfrage in einem Dokument oder die Anzahl der Klicks auf ein bestimmtes Dokument. Sie können komplexe maschinell trainierte Faktoren verwenden: Wir bei der Suche mithilfe neuronaler Netze prognostizieren die Relevanz des Dokuments bei Bedarf und fügen diese Prognose mit einer neuen Spalte in unseren Funktionsbereich ein.
Warum machen wir das alles? Wir möchten die Benutzerkennzahlen maximieren, damit Benutzer die relevanten Ergebnisse in unseren Ergebnissen so einfach wie möglich finden und so oft wie möglich zu uns zurückkehren.
Unser endgültiges Modell verwendet ein Ensemble von Entscheidungsbäumen, die mithilfe von Gradientenverstärkung erstellt wurden. Es gibt zwei Möglichkeiten, eine Zielmetrik für das Training zu erstellen:
- Wir schaffen eine Abteilung von Assessoren - speziell geschulte Personen, an die wir Anfragen richten und sagen: „Leute, bewerten Sie, wie relevant unsere Ausgabe ist.“ Sie antworten mit Zahlen, die die Relevanz messen. Warum ist dieser Ansatz schlecht? In diesem Fall maximieren wir das Modell in Bezug auf die Meinungen von Personen, die nicht unsere Benutzer sind. Wir werden nicht für die Metrik optimieren, die wir wirklich optimieren möchten.
- Aus diesem Grund verwenden wir den zweiten Ansatz für die Zielvariable: Wir zeigen den Benutzern die Ergebnisse, schauen uns an, an welche Dokumente sie übergeben, welche überspringen. Und dann verwenden wir diese Daten, um das endgültige Modell zu trainieren.
Wie wird das Rankingproblem gelöst?
Es gibt drei Ansätze zur Lösung des Ranking-Problems:
- Punktweise ist es punktweise. Wir werden die Relevanz als absolutes Maß betrachten und das Modell für den absoluten Unterschied zwischen der vorhergesagten und der aus der Trainingsstichprobe bekannten Relevanz berechnen. Zum Beispiel gab der Prüfer dem Dokument eine Bewertung von 3, und wir würden 2 sagen, also bestrafen wir das Modell mit 1.
- Paarweise , paarweise. Wir werden Dokumente miteinander vergleichen. Zum Beispiel gibt es im Schulungsbeispiel zwei Dokumente, und wir wissen, welches für diese Anfrage relevanter ist. Dann werden wir das Modell in Ordnung bringen, wenn die Prognose niedriger als die weniger relevante ist, dh das Paar ist falsch angeordnet.
- Listenweise . Es basiert auch auf der relativen Relevanz, jedoch nicht innerhalb der Paare: Wir ordnen das gesamte Problem nach dem Modell und bewerten das Ergebnis. Wenn das relevanteste Dokument nicht an erster Stelle steht, erhalten wir eine hohe Geldstrafe.
Welcher Ansatz ist für unsere Zielvariable besser geeignet? Zu diesem Zweck lohnt es sich, eine wichtige Frage zu diskutieren: „Können Klicks als Maß für die absolute Relevanz eines Dokuments verwendet werden?“ Dies ist unmöglich, da sie von der Position des Dokuments in der Ausgabe abhängen. Nachdem Sie das Problem erhalten haben, klicken Sie höchstwahrscheinlich auf das Dokument, das höher sein wird, da Ihnen die ersten Dokumente relevanter erscheinen.
Wie kann eine solche Hypothese überprüft werden? Wir nehmen zwei Dokumente oben in der Ausgabe und tauschen sie aus. Wenn Klicks ein absolutes Maß für die Relevanz wären, würde ihre Anzahl nur vom Dokument selbst und nicht von der Position abhängen. Aber das ist nicht so. Das obige Dokument erhält immer mehr Klicks. Daher können Klicks niemals als Maß für die absolute Relevanz verwendet werden. Daher können Sie entweder paarweise oder listweise verwenden.
Wir sammeln einen Datensatz
Jetzt extrahieren wir die Daten für den Trainingssatz. Wir hatten diese Sitzung:
Von den vier Dokumenten gab es einen Klick auf das zweite und vierte. In der Regel beobachten die Leute die Ergebnisse von oben nach unten. Sie haben sich das erste Dokument angesehen, es hat Ihnen nicht gefallen, Sie haben auf das zweite geklickt. Dann kehrten sie zur Suche zurück, sahen sich die dritte an und klickten auf die vierte. Offensichtlich hat Ihnen die zweite mehr gefallen als die erste und die vierte mehr als die erste und dritte. Dies sind die Paare, die wir für alle Anfragen generieren, und wir verwenden Modelle für das Training.
Alles scheint in Ordnung zu sein, aber es gibt ein Problem: Die Leute klicken nur ganz oben auf Dokumente. Wenn Sie das Trainingsmuster nur auf diese Weise erstellen, ist die Verteilung darin genau die gleiche wie im Testmuster. Es ist notwendig, die Verteilung irgendwie auszurichten. Wir tun dies, indem wir negative Beispiele hinzufügen: Dies sind Dokumente, die am Ende des Rankings standen, der Benutzer hat sie definitiv nicht gesehen, aber wir wissen, dass sie schlecht sind.

Wir haben also ein solches Schema für das Ranking-Training erhalten: Wir haben den Benutzern die Ergebnisse gezeigt, Klicks von ihnen gesammelt, negative Beispiele hinzugefügt, um die Verteilung auszurichten, und das Ranking-Modell neu trainiert. So berücksichtigen wir die Reaktion der Nutzer auf Ihr aktuelles Ranking, berücksichtigen Fehler und verbessern das Ranking. Wir wiederholen diese Verfahren viele Male bis zur Konvergenz. Es ist wichtig zu beachten, dass wir nicht nur über das Internet, sondern auch über Videos und Bilder suchen und das beschriebene Schema bei jeder Art von Suche perfekt funktioniert. Infolgedessen wachsen die Verhaltensmetriken sehr stark. In der zweiten Iteration ist es etwas kleiner, in der dritten Iteration ist es sogar noch kleiner und konvergiert infolgedessen zu einem lokalen Optimum.
Lassen Sie uns darüber nachdenken, warum wir bei einem lokalen Optimum und nicht bei einem globalen Optimum konvergieren.
Angenommen, Sie sind ein Fußballfan und hatten abends keine Zeit, das Spiel Ihrer Lieblingsmannschaft zu verfolgen. Wachen Sie morgens auf und geben Sie den Namen des Teams in die Suchleiste ein, um das Ergebnis des Spiels herauszufinden. Siehe die ersten drei Dokumente - dies sind die offiziellen Seiten über den Club, es gibt keine nützlichen Informationen. Sie werden nicht die gesamte Ausgabe durchblättern, keine weitere Anfrage entgegennehmen. Vielleicht klicken Sie sogar auf ein irrelevantes Dokument. Aber als Ergebnis ärgern Sie sich, schließen Sie den SERP und öffnen Sie eine andere Suchmaschine.

Obwohl dieses Problem nicht nur in der Suche gefunden wird, ist es hier besonders relevant. Stellen Sie sich einen Online-Shop vor, bei dem es sich um ein großes Band handelt, ohne sagen zu können, welche bestimmte Produktkategorie Sie sehen möchten. Genau das passiert mit den Suchergebnissen: Nach dem Absenden der Anfrage können Sie nicht mehr erklären, was Sie wirklich brauchen: Informationen über die Fußballmannschaft oder das Ergebnis des letzten Spiels.
Stellen Sie sich vor, ein brutaler Mann ging zu einem so seltsamen Online-Shop, der aus einem Band von Empfehlungen besteht, und in seinen Empfehlungen sieht er nur typisch weibliche Waren. Vielleicht klickt er sogar auf ein Kleid, weil es bei einem schönen Mädchen getragen wird. Wir werden diesen Klick an das Trainingsset senden und entscheiden, dass der Mann dieses Kleid mehr mag als Schwamm. Wenn er zurück in unser System kommt, wird er bereits einige Kleider sehen. Anfangs hatten wir keine Produkte, die für den Benutzer gültig waren, daher können wir diesen Fehler mit diesem Ansatz nicht beheben. Wir waren in einem lokalen Optimum, in dem der arme Mensch uns nicht mehr sagen kann, dass er weder Schwämme noch Kleider mag. Oft wird dieses Problem als positives Rückkopplungsproblem bezeichnet.
Weitere Verbesserung
Wie kann man eine Suchmaschine verbessern? Wie komme ich aus einem lokalen Optimum heraus? Neue Faktoren müssen hinzugefügt werden. Angenommen, wir haben einen sehr guten Faktor festgelegt, der auf Anfrage mit dem Namen der Fußballmannschaft ein relevantes Dokument, dh die Ergebnisse des letzten Spiels, erstellt. Was könnte hier das Problem sein? Wenn Sie das Modell mit alten Daten und Offline-Daten trainieren, nehmen Sie das alte Dataset mit Klicks und fügen Sie dieses Attribut dort hinzu. Es mag relevant sein, aber Sie haben es zuvor noch nicht im Ranking verwendet, und daher haben die Benutzer nicht auf die Dokumente geklickt, für die dieses Attribut geeignet ist. Es korreliert nicht mit Ihrer Zielvariablen, daher wird es vom Modell einfach nicht verwendet.
In solchen Fällen verwenden wir häufig diese Lösung: Um das endgültige Modell zu umgehen, zwingen wir unser Ranking, diese Funktion zu verwenden. Wir zeigen das Ergebnis des letzten Spiels auf Anfrage zwangsweise mit dem Namen der Mannschaft an. Wenn der Benutzer darauf geklickt hat, sind dies für uns die Informationen, die es uns ermöglichen zu verstehen, dass das Zeichen gut ist.
Schauen wir uns ein Beispiel an. Kürzlich haben wir wunderschöne Bilder für Instagram-Dokumente gemacht:

Es scheint, dass so schöne Bilder unsere Benutzer so zufrieden wie möglich stellen sollten. Natürlich müssen wir ein Zeichen dafür setzen, dass das Dokument ein solches Bild hat. Wir ergänzen den Datensatz, trainieren das Ranking-Modell neu und sehen, wie diese Funktion verwendet wird. Und dann analysieren wir die Änderung der Verhaltensmetriken. Sie haben sich ein bisschen verbessert, aber ist das die beste Lösung?
Nein, denn für viele Anfragen zeigen Sie keine schönen Bilder. Sie haben dem Benutzer nicht die Möglichkeit gegeben, zu zeigen, wie er sie mag. Um dieses Problem zu lösen, haben wir bei einigen Anfragen, bei denen Instagram-Dokumente angezeigt und das Modell gewaltsam umgangen wurden, wunderschöne Bilder gezeigt und geprüft, ob sie darauf geklickt haben. Sobald die Benutzer die Innovation zu schätzen wussten, begannen sie, das Modell für Datensätze neu zu trainieren, in denen die Benutzer die Möglichkeit hatten, die Bedeutung dieses Faktors zu demonstrieren. Nach diesem Verfahren wurde der Faktor in einem neuen Datensatz um ein Vielfaches häufiger verwendet und die Benutzerkennzahlen wurden erheblich erhöht.
Daher haben wir die Aussage zum Ranking-Problem untersucht und die Fallstricke besprochen, die Sie beim Lernen von Feedback von Benutzern erwarten. Die Hauptsache, die Sie aus diesem Artikel herausnehmen sollten: Verwenden Sie Feedback als Trainingsziel. Denken Sie daran, dass der Benutzer dieses Feedback nur dort lassen kann, wo es das aktuelle Modell zulässt. Ein solches Feedback kann Ihnen beim Versuch, ein neues Modell für maschinelles Lernen zu erstellen, einen Streich spielen.