
Je schneller der Entwicklungsprozess ist, desto schneller entwickelt sich das Technologieunternehmen.
Leider arbeiten moderne Anwendungen gegen uns - unsere Systeme müssen in Echtzeit aktualisiert werden und gleichzeitig niemanden stören und dürfen nicht zu Ausfallzeiten und Unterbrechungen führen. Die Bereitstellung in solchen Systemen wird zu einer komplexen Aufgabe und erfordert komplexe Pipelines für die kontinuierliche Lieferung, selbst in kleinen Teams.
Diese Pipelines haben normalerweise eine enge Anwendung, arbeiten langsam und sind nicht zuverlässig. Entwickler müssen sie zuerst manuell erstellen und dann verwalten, und Unternehmen stellen häufig ganze DevOps-Teams dafür ein.
Die Entwicklungsgeschwindigkeit hängt von der Geschwindigkeit dieser Pipelines ab. Für die besten Teams dauert die Bereitstellung 5-10 Minuten, normalerweise jedoch viel länger und für eine Bereitstellung mehrere Stunden.
In Dark dauert es 50 ms. Fünfzig. Millisekunden Dark ist eine Komplettlösung mit einer Programmiersprache, einem Editor und einer Infrastruktur, die speziell für die kontinuierliche Bereitstellung entwickelt wurden. Alle Aspekte von Dark, einschließlich der Sprache selbst, wurden im Hinblick auf eine sichere sofortige Bereitstellung erstellt.
Warum sind kontinuierliche Förderer so langsam?
Angenommen, wir haben eine Python-Webanwendung und haben bereits eine wunderbare und moderne Pipeline für die kontinuierliche Bereitstellung erstellt. Für einen Entwickler, der jeden Tag mit diesem Projekt beschäftigt ist, sieht die Bereitstellung einer geringfügigen Änderung ungefähr so aus:
Änderungen vornehmen
- Erstellen eines neuen Zweigs in Git
- Änderungen hinter dem Funktionsschalter vornehmen
- Unit-Test zur Überprüfung von Änderungen mit und ohne Funktionsschalter
Poolanfrage
- Commit Commit
- Veröffentlichen von Änderungen in einem Remote-Repository auf github
- Poolanfrage
- CI wird automatisch im Hintergrund erstellt
- Codeüberprüfung
- Falls erforderlich, noch ein paar Bewertungen
- Änderungen mit dem Git-Assistenten zusammenführen.
CI wird auf dem Assistenten ausgeführt
- Festlegen von Frontend-Abhängigkeiten über npm
- Erstellen und Optimieren von HTML + CSS + JS-Ressourcen
- Führen Sie das vordere Ende der Geräte- und Funktionstests aus
- Installieren Sie Python-Abhängigkeiten von PyPI
- Führen Sie das Backend von Unit- und Funktionstests aus
- Integrationstests an beiden Enden
- Senden Sie Frontend-Ressourcen an CDN
- Erstellen eines Containers für ein Python-Programm
- Senden eines Containers an die Registrierung
- Kubernetes Manifest Update
Alten Code durch neuen ersetzen
- Kubernetes startet mehrere Instanzen eines neuen Containers
- Kubernetes wartet darauf, dass Instanzen betriebsbereit werden
- Kubernetes fügt dem HTTP Load Balancer Instanzen hinzu
- Kubernetes wartet darauf, dass alte Instanzen nicht mehr verwendet werden
- Kubernetes stoppt alte Instanzen
- Kubernetes wiederholt diese Vorgänge, bis neue Instanzen alle alten ersetzen
Schalten Sie den neuen Funktionsschalter ein
- Der neue Code ist nur für mich enthalten, um sicherzustellen, dass alles in Ordnung ist
- Für 10% der Benutzer ist neuer Code enthalten, Betriebs- und Geschäftsmetriken werden nachverfolgt
- Für 50% der Benutzer ist neuer Code enthalten, Betriebs- und Geschäftsmetriken werden nachverfolgt
- Der neue Code ist für 100% der Benutzer enthalten. Betriebs- und Geschäftsmetriken werden nachverfolgt
- Schließlich wiederholen Sie den gesamten Vorgang, um den alten Code zu entfernen und zu wechseln
Der Prozess hängt von den Tools, der Sprache und der Verwendung serviceorientierter Architekturen ab, sieht aber im Allgemeinen so aus. Ich habe die Bereitstellung von Datenbankmigrationen nicht erwähnt, da dies eine sorgfältige Planung erfordert. Im Folgenden werde ich jedoch beschreiben, wie Dark damit umgeht.
Hier gibt es viele Komponenten, von denen viele leicht langsamer werden, abstürzen, vorübergehende Konkurrenz verursachen oder das funktionierende System zum Erliegen bringen können.
Und da diese Pipelines fast immer für einen besonderen Anlass erstellt werden, ist es schwierig, sich auf sie zu verlassen. Viele Menschen haben Tage, an denen der Code nicht bereitgestellt werden kann, weil es Probleme in der Docker-Datei gibt, einer der Dutzenden von Diensten abgestürzt ist oder der richtige Spezialist im Urlaub.
Schlimmer noch, viele dieser Schritte bewirken überhaupt nichts. Wir haben sie früher benötigt, als wir den Code sofort für Benutzer bereitgestellt haben, aber jetzt haben wir Schalter für den neuen Code, und diese Prozesse sind unterteilt. Infolgedessen ist der Schritt, in dem der Code bereitgestellt wird (der alte wird durch den neuen ersetzt), nur noch ein zusätzliches Risiko.
Dies ist natürlich eine sehr durchdachte Pipeline. Das Team, das es erstellt hat, brauchte Zeit und Geld, um es schnell bereitzustellen. Normalerweise sind Bereitstellungspipelines viel langsamer und unzuverlässiger.
Kontinuierliche Lieferung im Dunkeln implementieren
Die kontinuierliche Lieferung ist für Dark so wichtig, dass wir die Zeit in weniger als einer Sekunde im Visier haben. Wir gingen alle Schritte der Pipeline durch, um alles Unnötige zu entfernen, und erinnerten uns an den Rest. So haben wir die Schritte entfernt.
Jessie Frazelle prägte das neue Wort Deployless auf der Future of Software Development-Konferenz in Reykjavik
Wir entschieden sofort, dass Dark auf dem Konzept von „Deployless“ basieren würde (danke an Jesse Frazel für den Neologismus). Deployless bedeutet, dass jeder Code sofort bereitgestellt und für die Produktion bereit ist. Natürlich werden wir keinen fehlerhaften oder unvollständigen Code verpassen (ich werde die Sicherheitsprinzipien unten beschreiben).
Bei der Dark-Demo wurden wir oft gefragt, wie wir die Bereitstellung beschleunigen konnten. Komische Frage. Die Leute denken wahrscheinlich, dass wir eine Art Supertechnologie entwickelt haben, die den Code vergleicht, kompiliert, in einen Container packt, eine virtuelle Maschine startet, einen Container auf eine kalte startet und ähnliches - und das alles in 50 ms. Das ist kaum möglich. Wir haben jedoch eine spezielle Deployment-Engine erstellt, die all dies nicht benötigt.
Dark startet Dolmetscher in der Cloud. Angenommen, Sie schreiben Code in eine Funktion oder einen Handler für HTTP oder Ereignisse. Wir senden diff an den abstrakten Syntaxbaum (die Implementierung des von unserem Editor und unseren Servern intern verwendeten Codes) an unsere Server und führen diesen Code dann aus, wenn Anforderungen eingehen. Die Bereitstellung sieht also wie ein bescheidener Datensatz in der Datenbank aus - sofort und elementar. Die Bereitstellung ist so schnell, weil sie das Nötigste beinhaltet.
In Zukunft planen wir, aus Dark einen Infrastruktur-Compiler zu machen, der die ideale Infrastruktur für hohe Leistung und Zuverlässigkeit von Anwendungen erstellt und ausführt. Die sofortige Bereitstellung geht natürlich nirgendwo hin.
Sichere Bereitstellung
Strukturierter Editor
Der Code in Dark wird im Dark-Editor geschrieben. Der strukturierte Editor macht keine Syntaxfehler. Tatsächlich hat Dark nicht einmal einen Analysator. Während der Eingabe arbeiten wir direkt mit dem Abstract Syntax Tree (AST) wie Paredit , Sketch-n-Sketch , Tofu , Prune und MPS .
Jeder unvollständige Code in Dark hat eine gültige Ausführungssemantik, ähnlich wie typisierte Löcher in Hazel . Wenn Sie beispielsweise einen Funktionsaufruf ändern, behalten wir die alte Funktion bei, bis die neue verwendbar wird.
Jedes Programm in Dark hat seine eigene Bedeutung, sodass unvollständiger Code die fertige Arbeit nicht beeinträchtigt.
Bearbeitungsmodi
Sie schreiben in zwei Fällen Code in Dark. Erstens: Sie schreiben neuen Code und sind der einzige Benutzer. Beispielsweise befindet es sich in der REPL, und andere Benutzer erhalten niemals Zugriff darauf, oder es handelt sich um eine neue HTTP-Route, auf die Sie nirgendwo verweisen. Sie können hier ohne Vorsichtsmaßnahmen arbeiten, und jetzt arbeiten Sie ungefähr in der Entwicklungsumgebung.
Zweite Situation: Der Code wird bereits verwendet. Wenn der Datenverkehr durch den Code geleitet wird (Funktionen, Ereignishandler, Datenbanken, Typ), muss vorsichtig vorgegangen werden. Zu diesem Zweck blockieren wir den gesamten verwendeten Code und benötigen strukturiertere Tools, um ihn zu bearbeiten. Im Folgenden werde ich auf strukturelle Tools eingehen: Funktionsschalter für HTTP- und Ereignishandler, eine leistungsstarke Migrationsplattform für Datenbanken und eine neue Versionskontrollmethode für Funktionen und Typen.
Funktionsschalter
Eine Möglichkeit , die zusätzliche Komplexität in Dark zu beseitigen, besteht darin, mehrere Probleme mit einer Lösung zu beheben. Funktionsschalter führen viele verschiedene Aufgaben aus: Ersetzen der lokalen Entwicklungsumgebung, Git-Zweige, Bereitstellen von Code und natürlich die traditionelle langsame und kontrollierte Freigabe von neuem Code.
Die Erstellung und Bereitstellung eines Funktionsschalters erfolgt in unserem Editor in einem Arbeitsgang. Es erstellt einen leeren Bereich für neuen Code und bietet Zugriffssteuerungen für alten und neuen Code sowie Schaltflächen und Befehle für den schrittweisen Übergang zu neuem Code oder dessen Ausschluss.
Funktionsschalter sind in die dunkle Sprache integriert, und selbst unvollständige Schalter erfüllen ihre Aufgabe. Wenn die Bedingung im Schalter nicht erfüllt ist, wird der alte blockierte Code ausgeführt.
Entwicklungsumgebung
Funktionsschalter ersetzen die lokale Entwicklungsumgebung. Heutzutage ist es für Teams schwierig sicherzustellen, dass alle Benutzer dieselben Versionen von Tools und Bibliotheken verwenden (Code-Formatierer, Linters, Paketmanager, Compiler, Präprozessoren, Testtools usw.). Mit Dark müssen Sie keine Abhängigkeiten lokal installieren, die lokale Installation von Docker oder steuern Ergreifen Sie andere Maßnahmen, um zumindest einen Anschein von Gleichheit zwischen Entwicklungsumgebung und Produktion zu gewährleisten. Angesichts der Tatsache, dass eine solche Gleichstellung immer noch unmöglich ist , werden wir nicht einmal so tun, als würden wir danach streben.
Anstatt eine geklonte lokale Umgebung zu erstellen, erstellen die Switches in Dark eine neue Sandbox in der Produktion, die die Entwicklungsumgebung ersetzt. In Zukunft planen wir auch, eine Sandbox für andere Teile der Anwendung zu erstellen (z. B. sofortige Datenbankklone), obwohl dies derzeit nicht so wichtig erscheint.
Niederlassungen und Bereitstellungen
Jetzt gibt es verschiedene Möglichkeiten, neuen Code in Systeme einzugeben: Git-Zweige, Bereitstellungsphase und Funktionsschalter. Sie lösen ein Problem in verschiedenen Teilen des Workflows: git - in den Phasen vor der Bereitstellung, Bereitstellung - zum Zeitpunkt des Übergangs vom alten zum neuen Code und Funktionswechsel - für die kontrollierte Freigabe von neuem Code.
Der effektivste Weg sind Funktionsschalter (gleichzeitig am einfachsten zu verstehen und zu verwenden). Mit ihnen können Sie die beiden anderen Methoden vollständig aufgeben. Es ist besonders nützlich, die Bereitstellung zu entfernen. Wenn wir ohnehin Funktionsschalter verwenden, um den Code einzuschließen, birgt der Schritt der Übertragung der Server auf den neuen Code nur unnötige Risiken.
Git ist schwer zu benutzen, besonders für Anfänger, und es schränkt es wirklich ein, aber es hat praktische Zweige. Wir haben viele der Git-Mängel behoben. Dark wird in Echtzeit bearbeitet und bietet die Möglichkeit, im Stil von Google Text & Tabellen zusammenzuarbeiten, sodass Sie keinen Code senden müssen und weniger häufig Umzüge und Zusammenführungen durchführen können.
Funktionsschalter unterstützen die sichere Bereitstellung. Zusammen mit sofortigen Bereitstellungen können Sie Konzepte in kleinen Fragmenten mit geringem Risiko schnell testen, anstatt eine größere Änderung vorzunehmen, die das System zum Erliegen bringen kann.
Versionierung
Um Funktionen und Typen zu ändern, verwenden wir die Versionierung. Wenn Sie eine Funktion ändern möchten, erstellt Dark eine neue Version dieser Funktion. Anschließend können Sie diese Version über den Schalter im HTTP- oder Ereignishandler aufrufen. (Wenn es sich um eine Funktion handelt, die sich tief im Aufrufdiagramm befindet, wird unterwegs eine neue Version jeder Funktion erstellt. Es scheint, als wäre sie zu viel, aber die Funktionen stören nicht, wenn Sie sie nicht verwenden, sodass Sie sie nicht einmal bemerken.)
Aus den gleichen Gründen versionieren wir Typen. Wir haben in einem früheren Beitrag ausführlich über unser Typensystem gesprochen.
Durch die Versionierung von Funktionen und Typen können Sie schrittweise Änderungen an der Anwendung vornehmen. Sie können überprüfen, ob jeder einzelne Handler mit der neuen Version funktioniert. Sie müssen nicht sofort alle Änderungen an den Anwendungen vornehmen (wir haben jedoch Tools, um dies schnell zu tun, wenn Sie möchten).
Dies ist viel sicherer, als alles auf einmal vollständig bereitzustellen.
Neue Paketversionen und Standardbibliothek
Wenn Sie ein Paket in Dark aktualisieren, ersetzen wir nicht sofort die Verwendung jeder Funktion oder jedes Typs in der gesamten Codebasis. Das ist nicht sicher. Der Code verwendet weiterhin dieselbe Version wie er, und Sie aktualisieren die Verwendung von Funktionen und Typen mithilfe der Schalter für jeden Einzelfall auf eine neue Version.

Ein Screenshot eines Teils eines automatischen Prozesses in Dark mit zwei Versionen der Dict :: get-Funktion. Dict :: get_v0 gab den Typ Any zurück (den wir ablehnen), und Dict :: get_v1 gab den Typ Option zurück.
Wir stellen häufig eine neue Funktion in der Standardbibliothek bereit und schließen ältere Versionen aus. Benutzer mit alten Versionen im Code behalten den Zugriff auf sie, aber neue Benutzer können sie nicht erhalten. Wir werden Tools bereitstellen, mit denen Benutzer in einem Schritt von alten auf neue Versionen übertragen und wieder Funktionsschalter verwenden können.
Dark bietet auch eine einzigartige Möglichkeit: Sobald wir Ihren Arbeitscode ausgeführt haben, können wir die neuen Versionen selbst testen und die Ausgabe für neue und alte Anforderungen vergleichen, um Sie über die Änderungen zu informieren. Infolgedessen stellen Paketaktualisierungen, die häufig blind durchgeführt werden (oder strenge Sicherheitstests erfordern), weitaus weniger Risiken dar und können automatisch erfolgen.
Neue dunkle Versionen
Der Übergang von Python 2 zu Python 3 hat sich über ein Jahrzehnt erstreckt und ist nach wie vor ein Problem. Sobald wir Dark für die kontinuierliche Bereitstellung erstellt haben, müssen diese Sprachänderungen berücksichtigt werden.
Wenn wir kleine Änderungen an der Sprache vornehmen, erstellen wir eine neue Version von Dark. Der alte Code bleibt in der alten Version von Dark und der neue Code wird in der neuen Version verwendet. Um zur neuen Version von Dark zu wechseln, können Sie die Schalter oder Versionen von Funktionen verwenden.
Dies ist besonders nützlich, wenn man bedenkt, dass Dark kürzlich aufgetaucht ist. Viele Änderungen an der Sprache oder Bibliothek können fehlschlagen. Die schrittweise Versionierung der Sprache ermöglicht es uns, kleinere Aktualisierungen vorzunehmen, dh wir können nicht viele Entscheidungen über die Sprache beschleunigen, bis wir mehr Benutzer und damit mehr Informationen haben.
Datenbankmigrationen
Es gibt eine Standardformel für die sichere Datenbankmigration:
- Schreiben Sie den Code neu, um neue und alte Formate zu unterstützen
- Konvertieren Sie alle Daten in ein neues Format
- Alten Datenzugriff löschen
Infolgedessen verzögert sich die Datenbankmigration und erfordert viele Ressourcen. Und wir sammeln veraltete Schemata an, weil selbst einfache Aufgaben wie das Korrigieren des Namens einer Tabelle oder Spalte die Mühe nicht wert sind.
Dark verfügt über eine effektive Datenbankmigrationsplattform, die (wir hoffen) den Prozess so stark vereinfacht, dass Sie keine Angst mehr davor haben. Alle Datenspeicher in Dark (Schlüssel-Wert-Paare oder persistente Hash-Tabellen) sind vom Typ. Um ein Data Warehouse zu migrieren, weisen Sie ihm einfach einen neuen Typ und eine Rollback- und Rollback-Funktion zu, um Werte zwischen den beiden Typen zu konvertieren.
Der Zugriff auf Data Warehouses in Dark erfolgt über versionierte Variablennamen. Beispielsweise würde der Benutzerdatenspeicher zunächst als Benutzer-v0 bezeichnet. Wenn eine neue Version mit einem anderen Typ erstellt wird, ändert sich der Name in Users-v1. Wenn die Daten über Users-v0 gespeichert werden und Sie über Users-v1 darauf zugreifen, wird die Rollover-Funktion angewendet. Wenn die Daten über Users-v1 gespeichert werden und Sie über Users-v0 darauf zugreifen, wird die Rollback-Funktion verwendet.
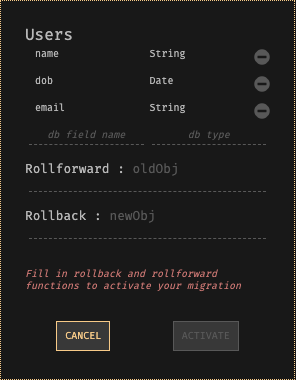
Bildschirm für die Datenbankmigration mit Feldnamen für die alte Datenbank, Rollback- und Rollback-Ausdrücken sowie Anweisungen zum Aktivieren der Migration.
Verwenden Sie die Funktionsschalter, um Anrufe an Users-v0 an Users-v1 weiterzuleiten. Sie können jeweils einen HTTP-Handler ausführen, um Risiken zu reduzieren. Die Switches funktionieren auch für einzelne Benutzer, sodass Sie überprüfen können, ob alles wie erwartet funktioniert. Wenn Users-v0 nicht verlassen wird, konvertiert Dark alle verbleibenden Daten im Hintergrund vom alten Format in das neue. Sie werden es nicht einmal bemerken.
Testen
Dark ist eine funktionale Programmiersprache mit statischer Typisierung und unveränderlichen Werten. Daher ist ihre Testfläche im Vergleich zu objektorientierten Sprachen mit dynamischer Typisierung erheblich kleiner. Aber Sie müssen noch testen.
In Dark führt der Editor automatisch Unit-Tests im Hintergrund für bearbeitbaren Code aus und führt diese Tests standardmäßig für alle Funktionsschalter aus. In Zukunft möchten wir die statischen Typen verwenden, um den Code automatisch zu fuzzeln, um Fehler zu finden.
Darüber hinaus betreibt Dark Ihre Infrastruktur in der Produktion, was neue Möglichkeiten eröffnet. Wir speichern HTTP-Anforderungen automatisch in der Dark-Infrastruktur (im Moment speichern wir alle Anforderungen, möchten dann aber zum Abrufen wechseln). Wir testen neuen Code auf ihnen und führen Unit-Tests durch. Wenn Sie möchten, können Sie interessante Abfragen problemlos in Unit-Tests umwandeln.
Was wir losgeworden sind
Da wir keine Bereitstellung haben, aber Funktionsschalter vorhanden sind, bleiben etwa 60% der Bereitstellungspipeline über Bord. Wir benötigen keine Git-Zweige oder Pool-Anforderungen, um Backend-Ressourcen und -Container zu erstellen, Ressourcen und Container an Registries oder Bereitstellungsschritte in Kubernetes zu senden.
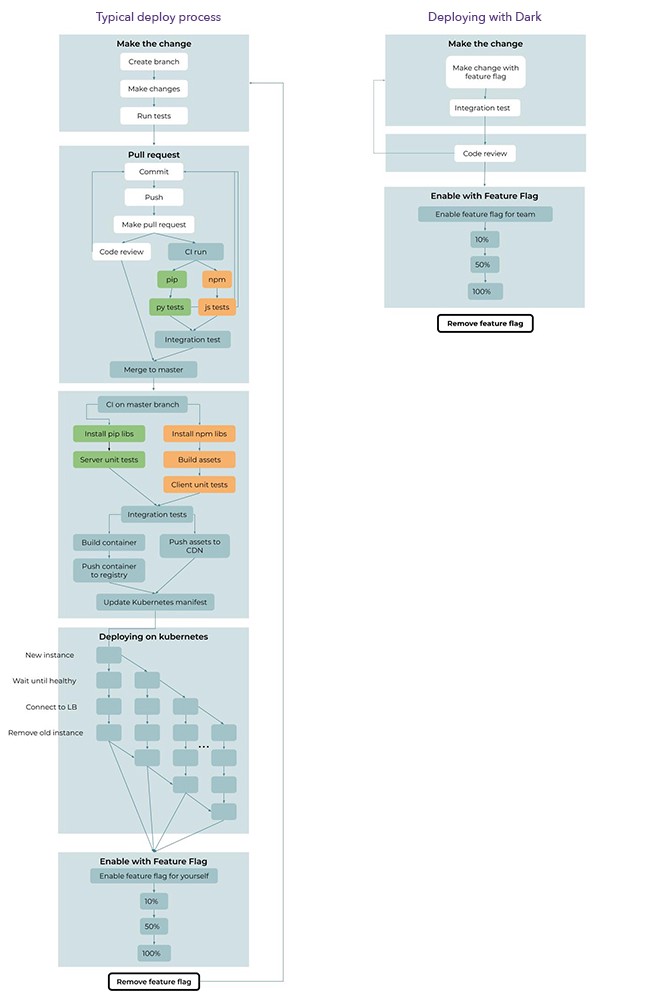
Vergleich der Standard-Pipeline für die kontinuierliche Lieferung (links) und der kontinuierlichen Versorgung mit Dark (rechts). In Dark besteht die Lieferung aus 6 Schritten und einem Zyklus, während die traditionelle Version 35 Schritte und 3 Zyklen umfasst.
In Dark gibt es nur 6 Schritte und 1 Zyklus in der Bereitstellung (Schritte, die mehrmals wiederholt werden), während die moderne Pipeline für die kontinuierliche Versorgung aus 35 Schritten und 3 Zyklen besteht. In Dark werden Tests automatisch ausgeführt und Sie sehen sie nicht einmal. Abhängigkeiten werden automatisch installiert. Alles, was mit Git oder Github zu tun hat, wird nicht mehr benötigt. Es ist nicht erforderlich, Docker-Container zu sammeln, zu testen und zu senden. Die Bereitstellung von Kubernetes wird nicht mehr benötigt.
Sogar die verbleibenden Schritte in Dark sind einfacher geworden. Da Funktionsschalter in einer Aktion gesteuert werden können, müssen Sie nicht ein zweites Mal die gesamte Bereitstellungspipeline durchlaufen, um den alten Code zu entfernen.
Wir haben die Codebereitstellung so weit wie möglich vereinfacht und so die Zeit und das Risiko einer kontinuierlichen Bereitstellung reduziert. Wir haben außerdem Paketaktualisierungen, Datenbankmigrationen, Tests, Versionskontrolle, Abhängigkeitsinstallation, Gleichheit zwischen Entwicklungsumgebung und Produktion sowie schnelle und sichere Sprachversionsaktualisierungen erheblich vereinfacht.
Ich beantworte Fragen dazu auf HackerNews .
Um mehr über das Dark-Gerät zu erfahren, lesen Sie den Dark-Artikel , folgen Sie uns auf Twitter (oder mir ) oder melden Sie sich für eine Beta-Version an und erhalten Sie Benachrichtigungen über die folgenden Beiträge . Wenn Sie im September zu StrangeLoop kommen , kommen Sie zu unserer Einführung .