Der Titel dieses Artikels mag etwas seltsam erscheinen. In der Tat: Wenn Sie 2019 im Bereich Data Science arbeiten, sind Sie bereits gefragt. Die Nachfrage nach Spezialisten auf diesem Gebiet wächst stetig: Zum Zeitpunkt dieses Schreibens wurden 144.527 Stellen mit dem Stichwort „Data Science“ auf LinkedIn veröffentlicht.
Trotzdem lohnt es sich auf jeden Fall, die neuesten Nachrichten und Trends der Branche zu verfolgen. Um Ihnen dabei zu helfen, haben das
CV Compiler- Team und ich im Juni 2019 mehrere hundert Data Science-Jobs analysiert und festgestellt, welche Fähigkeiten Arbeitgeber von Kandidaten am meisten erwarten.
Die gefragtesten Data Science-Kenntnisse im Jahr 2019
Diese Grafik zeigt die Fähigkeiten, die Arbeitgeber 2019 in Data Science-Jobs am häufigsten erwähnen:
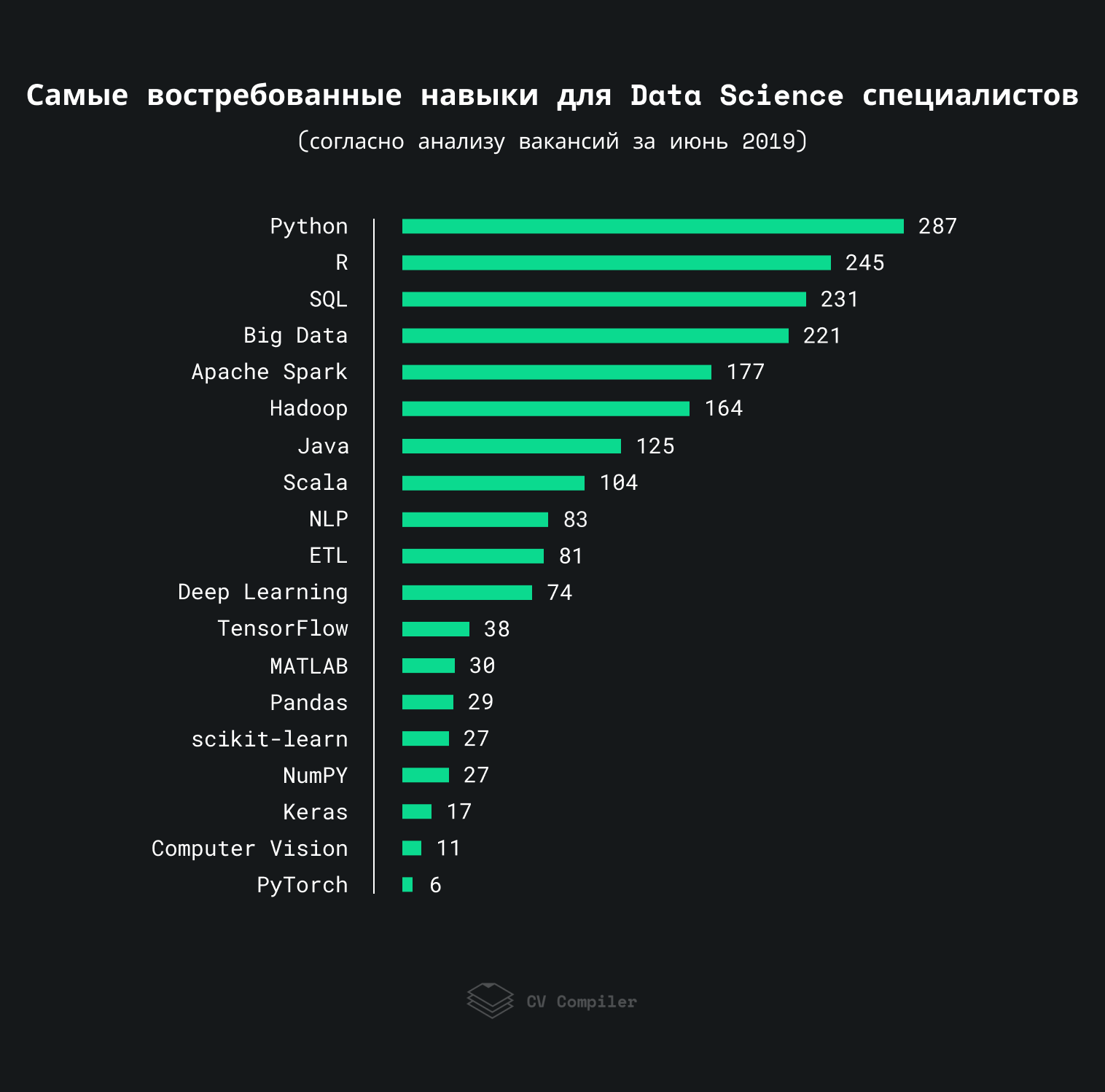
Wir haben ungefähr 300 Jobs mit StackOverflow, AngelList und ähnlichen Ressourcen analysiert. Einige Begriffe können innerhalb derselben Stelle mehrmals wiederholt werden.
Wichtig: Diese Bewertung zeigt die Präferenzen von Arbeitgebern und nicht von Spezialisten auf dem Gebiet der Datenwissenschaft.
Schlüsseltrends in der Datenwissenschaft
Offensichtlich handelt es sich bei Data Science nicht in erster Linie um Frameworks und Bibliotheken, sondern um grundlegendes Wissen. Einige Trends und Technologien sind jedoch noch erwähnenswert.
Big Data
Laut
Marktforschung zu Big Data im Jahr 2018 stieg der Einsatz von Big Data in Unternehmen von 17% im Jahr 2015 auf 59% im Jahr 2018. Dementsprechend hat die Popularität von Tools für die Arbeit mit Big Data zugenommen. Wenn Sie Apache Spark und Hadoop nicht berücksichtigen (wir werden näher auf Letzteres eingehen), sind
MapReduce (36) und
Redshift (29) die beliebtesten Tools.
Hadoop
Trotz der Popularität von Spark- und Cloud-Speicher ist die
Hadoop-Ära noch nicht vorbei. Daher erwarten einige Unternehmen, dass Kandidaten
Apache Pig (30),
HBase (32) und ähnliche Technologien kennen.
HDFS (20) ist auch in einigen Jobs zu finden.
Echtzeit-Datenverarbeitung
Angesichts des allgegenwärtigen Einsatzes verschiedener Sensoren und mobiler Geräte sowie der Beliebtheit des
Internet der
Dinge (18) versuchen Unternehmen zu lernen, wie Daten in Echtzeit verarbeitet werden. Threading-Plattformen wie
Apache Flink (21) sind daher bei Arbeitgebern beliebt.
Feature Engineering und Hyperparameter-Tuning
Die Aufbereitung von Daten und die Auswahl von Modellparametern ist ein wichtiger Teil der Arbeit eines jeden Spezialisten auf dem Gebiet der Datenwissenschaft. Daher ist der Begriff
Data Mining (128) bei Arbeitgebern sehr beliebt. Einige Unternehmen achten auch auf
Hyperparameter Tuning (21) (ein Begriff wie
Feature Engineering sollte ebenfalls nicht vergessen werden ). Die Auswahl der optimalen Parameter für das Modell ist wichtig, da die Gesamtleistung des Modells vom Erfolg dieser Operation abhängt.
Datenvisualisierung
Die Fähigkeit, Daten korrekt zu verarbeiten und die erforderlichen Muster anzuzeigen, ist wichtig. Die
Datenvisualisierung (55) ist jedoch eine ebenso wichtige Fähigkeit. Sie müssen in der Lage sein, die Ergebnisse Ihrer Arbeit in einem Format darzustellen, das für jedes Teammitglied oder jeden Kunden verständlich ist. In Bezug auf Datenvisualisierungstools bevorzugen Arbeitgeber
Tableau (54).
Allgemeine Trends
Bei offenen Stellen
stießen wir auch
auf Begriffe wie
AWS (86),
Docker (36) sowie
Kubernetes (24). Es kann gefolgert werden, dass allgemeine Trends aus dem Bereich der Softwareentwicklung langsam in den Bereich der Datenwissenschaft übergegangen sind.
Expertenmeinung
Diese Liste von Technologien spiegelt wirklich den tatsächlichen Stand der Dinge in der Welt der Datenwissenschaft wider. Es gibt jedoch nicht weniger wichtige Dinge als das Schreiben von Code. Dies ist die Fähigkeit, die Ergebnisse ihrer Arbeit richtig zu interpretieren sowie sie in verständlicher Form zu visualisieren und zu präsentieren. Es hängt alles vom Publikum ab - wenn Sie mit Wissenschaftskandidaten über Ihre Leistungen sprechen, ihre Sprache sprechen, aber wenn Sie dem Kunden die Ergebnisse präsentieren, kümmert er sich nicht um den Code - nur um das Ergebnis, das Sie erzielt haben.
Carla Gentry
Data Scientist, Inhaber von
Analytical SolutionLinkedIn |
TwitterDiese Grafik zeigt aktuelle Trends auf dem Gebiet der Datenwissenschaft, aber es ist ziemlich schwierig, die Zukunft darauf basierend vorherzusagen. Ich neige dazu zu glauben, dass die Popularität von R abnehmen wird (wie die Popularität von MATLAB), während die Popularität von Python nur zunehmen wird. Hadoop und Big Data landeten ebenfalls aufgrund der Trägheit auf der Liste: Hadoop wird bald verschwinden (niemand investiert mehr ernsthaft in diese Technologie), und Big Data ist kein zunehmender Trend mehr. Die Zukunft von Scala ist nicht ganz klar: Google unterstützt offiziell Kotlin, das viel einfacher zu erlernen ist. Ich bin auch skeptisch gegenüber der Zukunft von TensorFlow: Die wissenschaftliche Gemeinschaft bevorzugt PyTorch, und der Einfluss der wissenschaftlichen Gemeinschaft auf dem Gebiet der Datenwissenschaft ist viel höher als in allen anderen Bereichen. (Dies ist meine persönliche Meinung, die möglicherweise nicht mit der Meinung von Gartner übereinstimmt).
Andrey Burkov,
Direktor für maschinelles Lernen bei Gartner,
Autor des
Hundertseitigen Buches über maschinelles Lernen .
LinkedInPyTorch ist die treibende Kraft für verstärktes Lernen sowie ein starkes Framework für die parallele Codeausführung auf mehreren GPUs (was über TensorFlow nicht gesagt werden kann). PyTorch hilft auch beim Erstellen dynamischer Diagramme, die bei der Arbeit mit wiederkehrenden neuronalen Netzen effektiv sind. TensorFlow arbeitet mit statischen Graphen und ist schwieriger zu untersuchen, wird jedoch von mehr Entwicklern und Forschern verwendet. PyTorch ist Python jedoch in Bezug auf das Debuggen von Code und Bibliotheken für die Datenvisualisierung (matplotlib, seaborn) näher. Die meisten Python-Code-Debugging-Tools können zum Debuggen von PyTorch-Code verwendet werden. TensorFlow hat auch ein eigenes Debugging-Tool - tfdbg.
Ganapati Pulipaka,
Chief Data Scientist bei Accenture,
Top 50 Tech Leader Award Gewinner.
LinkedIn |
TwitterMeiner Meinung nach sind Arbeit und Karriere in Data Science nicht dasselbe. Um arbeiten zu können, benötigen Sie die oben genannten Fähigkeiten. Um jedoch eine erfolgreiche Karriere in Data Science aufzubauen, ist die Fähigkeit zu lernen die wichtigste Fähigkeit. Data Science ist ein unbeständiges Gebiet, und Sie müssen lernen, neue Technologien, Tools und Ansätze zu beherrschen, um mit der Zeit Schritt zu halten. Stellen Sie ständig neue Herausforderungen und versuchen Sie, sich nicht mit wenig zufrieden zu geben.
Lon Riesberg
Gründer / Kurator von
Data Elixir ,
Ex-NASA.
Twitter |
LinkedInData Science ist ein sich schnell entwickelndes und komplexes Gebiet, in dem Grundkenntnisse ebenso wichtig sind wie Erfahrungen mit bestimmten Tools. Wir hoffen, dass dieser Artikel Ihnen dabei hilft, festzustellen, welche Fähigkeiten erforderlich sind, um 2019 ein gefragter Spezialist auf dem Gebiet der Datenwissenschaft zu werden. Viel Glück!
Dieser Artikel wurde vom CV Compiler- Team verfasst, einem Tool zur Verbesserung der Lebensläufe für Data Science und andere IT-Experten.